
Curso
Projeto de banco de dados
4 h
125.2K
Imagine a cena: são 2h da manhã e o servidor de banco de dados da sua empresa caiu. Enquanto o time de resposta a incidentes corre para restabelecer as operações, duas perguntas dominam a conversa: "Em quanto tempo conseguimos voltar ao ar?" e "Quanto de dado a gente perdeu?" Essas perguntas representam as duas métricas mais críticas no planejamento de recuperação de desastres: Recovery Time Objective (RTO) e Recovery Point Objective (RPO).
Com o custo médio de uma violação de dados chegando a US$ 10,22 milhões, segundo a IBM, as organizações precisam de estratégias robustas de recuperação de desastres. Neste tutorial, vou apresentar os fundamentos de RTO e RPO, incluindo como calcular, estratégias de implementação, abordagens de teste e aplicações por indústria.
Se você está começando com bancos de dados e computação em nuvem, recomendo nossos cursos de fundamentos, especialmente Understanding Cloud Computing e Database Design.
Ambas as métricas são essenciais para o planejamento de continuidade de negócios e para a segurança de dados. Elas são indicadores-chave de desempenho que ajudam as organizações a quantificar a tolerância a riscos, alocar recursos e tomar decisões informadas sobre a infraestrutura de recuperação.
Recovery Time Objective (RTO) representa o tempo máximo aceitável que um sistema pode ficar indisponível após um evento disruptivo. Responde à pergunta: "Em quanto tempo precisamos restaurar as operações?"
Por exemplo, se o seu sistema de pagamentos tem um RTO de duas horas, você precisa restabelecer a funcionalidade completa dentro desse prazo.
Já o Recovery Point Objective (RPO) define a perda de dados máxima aceitável medida em tempo. Responde à pergunta: "Quanto de dado podemos nos dar ao luxo de perder?"
Se o seu banco de dados tem um RPO de 15 minutos, os backups precisam capturar dados pelo menos a cada 15 minutos.
Embora tenham propósitos semelhantes, RTO e RPO medem aspectos de recuperação fundamentalmente distintos. RTO olha para frente, medindo o tempo desde a interrupção até a recuperação. RPO olha para trás, medindo da interrupção até o último ponto de recuperação aceitável.
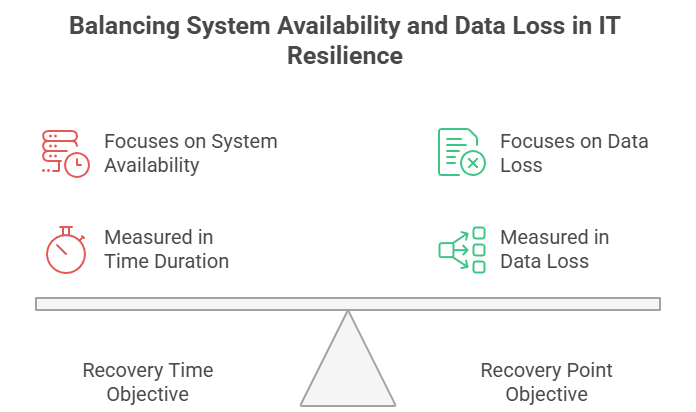
A natureza do impacto também difere. RTO foca na disponibilidade: metas não cumpridas significam mais tempo de inatividade e perda de produtividade. RPO foca na integridade dos dados: metas não cumpridas resultam em perda permanente de dados, com potenciais consequências regulatórias e financeiras.
Os investimentos em infraestrutura seguem padrões diferentes. RTOs agressivos exigem sistemas de alta disponibilidade e failover automatizado. RPOs rigorosos demandam proteção contínua de dados e backups frequentes, além de capacidade de armazenamento suficiente.
Importante: as duas métricas são independentes. Você pode ter um RTO de quatro horas com um RPO de uma hora, ou um RTO de 30 minutos com um RPO de seis horas. Tudo depende dos requisitos do negócio.
Veja uma tabela comparativa:
|
Aspecto |
RTO |
RPO |
|
Direção temporal |
Perspectiva futura |
Perspectiva passada |
|
Foco principal |
Disponibilidade do sistema |
Integridade dos dados |
|
Pergunta-chave |
"Em quanto tempo precisamos recuperar?" |
"Quanto de dado podemos perder?" |
|
Prioridade de infraestrutura |
Sistemas de failover, redundância |
Frequência de backup, replicação |
|
Independência |
Definido independentemente do RPO |
Definido independentemente do RTO |
Definir metas adequadas de RTO e RPO exige uma abordagem metódica que equilibra necessidades do negócio e capacidades técnicas com restrições de custo. O processo começa entendendo o perfil de risco e as prioridades únicas da sua organização.
A base da definição de metas começa com uma Business Impact Analysis (BIA) abrangente, que avalia de forma sistemática como interrupções afetam sua organização.
Conduzir uma BIA envolve entrevistar stakeholders de todos os departamentos para mapear funções de negócio e as consequências da indisponibilidade. Isso garante que as prioridades de recuperação reflitam o impacto real no negócio, e não apenas suposições de TI.
Service Level Agreements (SLAs) influenciam fortemente a definição de metas. Se você prometeu 99,9% de uptime, seu RTO precisa estar alinhado a esse compromisso para evitar multas e perda de clientes.
As interrupções afetam as organizações em quatro dimensões:
Os resultados da BIA orientam a priorização e a alocação de recursos de forma econômica. Sistemas que geram receita, processam transações de clientes ou atendem a exigências regulatórias exigem metas agressivas. Sistemas de apoio, como diretórios de funcionários, podem tolerar tempos de recuperação maiores.
Com os insights da BIA em mãos, você está pronto para traduzir o impacto de negócio em metas quantitativas.
Calcular RTO requer entender a tolerância do negócio e as capacidades técnicas. Comece identificando o Maximum Tolerable Period of Disruption (MTPD), o período máximo que um processo pode ficar indisponível antes de causar danos irreversíveis. Defina o RTO abaixo do MTPD para ter uma margem de segurança.
Para calcular o RTO, siga estes passos:
O cálculo do RPO foca nas características dos dados:
Uma abordagem em camadas oferece uma estratégia econômica:
Evite estes erros comuns:
Com esses cálculos concluídos, você terá metas concretas para orientar suas decisões de tecnologia e processos.
A estratégia certa de implementação e as escolhas tecnológicas podem ser a diferença entre cumprir seus objetivos ou ficar aquém quando o desastre acontecer.
Vamos explorar as tecnologias essenciais que viabilizam a recuperação, começando pelas abordagens fundamentais até soluções mais sofisticadas.
Estratégias de backup e restauração formam a base da recuperação de desastres. Backups completos criam cópias integrais dos dados, mas consomem muito armazenamento. Backups incrementais capturam apenas mudanças desde o último backup. Backups diferenciais capturam mudanças desde o último backup completo.
Para requisitos agressivos de RPO, combine backups completos diários com incrementais por hora.
Além dos backups tradicionais, replicação e proteção contínua de dados mantêm cópias quase em tempo real.
A replicação síncrona grava simultaneamente nos locais primário e secundário, alcançando RPO quase zero, mas introduzindo latência. Já a replicação assíncrona grava primeiro no primário e replica com um pequeno atraso. Continuous Data Protection (CDP) captura cada alteração, permitindo recuperação em pontos específicos no tempo.

Além dos mecanismos de proteção de dados, sites de recuperação de desastres devem estar alinhados ao RTO exigido.
Cold sites oferecem infraestrutura básica, mas exigem de dias a semanas para ativação. Warm sites incluem hardware pré-instalado e sincronização diária/semanal para ativar em horas. Hot sites, por sua vez, mantêm réplicas totalmente operacionais em tempo real, com failover em minutos para aplicações críticas.
Independentemente da abordagem de site adotada, ferramentas de automação e orquestração melhoram significativamente RTO e RPO.
Ferramentas de gestão de configuração permitem reconstrução rápida de servidores. Da mesma forma, plataformas de orquestração de recuperação de desastres automatizam procedimentos de failover. Enquanto isso, runbooks automatizados garantem consistência na recuperação durante incidentes.
Além das abordagens tradicionais on-premises, a nuvem transformou a recuperação de desastres. Ela oferece capacidades que antes estavam disponíveis apenas para empresas com orçamentos enormes.
Serviços de recuperação de desastres baseados em nuvem oferecem alternativas flexíveis e econômicas a sites físicos. Disaster Recovery as a Service (DRaaS) da AWS, Azure e Google Cloud elimina a necessidade de infraestrutura física separada. Para comparar os três provedores de nuvem mais populares, confira nosso guia AWS vs Azure vs GCP.
Além disso, Infrastructure as Code (IaC) acelera a recuperação ao definir toda a infraestrutura em código. Ferramentas como Terraform ou AWS CloudFormation recriam ambientes completos em minutos, reduzindo drasticamente o RTO.
Ao escolher soluções em nuvem, considere o modelo de implantação. Nuvem pública oferece flexibilidade e baixo custo inicial com precificação pay-as-you-go. Já uma nuvem privada fornece mais controle e pode ser necessária para conformidade, especialmente em setores sensíveis como finanças ou saúde. Abordagens híbridas combinam recursos on-premises e de nuvem para maior flexibilidade.
Por fim, tipos comuns de backup em nuvem incluem
Entender as implicações financeiras das metas de RTO e RPO permite tomar decisões embasadas sobre investimentos em recuperação. Toda organização enfrenta o desafio de equilibrar proteção e custo. Veja como abordar esse trade-off crítico.
A relação entre objetivos de recuperação e custos segue padrões previsíveis, mas otimizar essa relação exige estratégia.
Existe uma relação inversa entre metas de RTO/RPO e custos. Por exemplo, alcançar um RTO de 15 minutos custa exponencialmente mais do que um RTO de 24 horas. Da mesma forma, atingir um RPO de 15 minutos requer backups mais frequentes e mais armazenamento do que um RPO de 24 horas. Recuperação quase zero exige sistemas redundantes, replicação contínua e failover automatizado.
No entanto, abordagens em camadas otimizam o investimento. Em vez de aplicar metas agressivas a todos os sistemas, aloque recursos conforme a criticidade.
Como exemplo, uma plataforma de e-commerce deve investir pesado em replicação em hot site para evitar longas indisponibilidades (RTO mínimo), enquanto usa apenas backups diários em nuvem para wikis internas (RPO médio). As economias de metas razoáveis em sistemas menos críticos financiam proteções robustas para sistemas essenciais.
Na prática, equilibrar criticidade, risco e custo requer quantificar o custo do downtime, avaliar a probabilidade de cenários de desastre, estimar os custos das abordagens de recuperação e identificar pontos ótimos de equilíbrio.
Por exemplo, suponha que cada hora de indisponibilidade custe US$ 50.000 em perda de receita e haja 10% de chance anual de uma interrupção de quatro horas. O custo anual esperado dessa interrupção é 0,1 × 4 × US$ 50.000 = US$ 20.000.
Se você investir US$ 10.000 por ano em melhor infraestrutura e isso reduzir a interrupção para uma hora, o custo anual esperado de indisponibilidade passa a ser 0,1 × 1 × US$ 50.000 = US$ 5.000. Seu custo anual total agora é US$ 5.000 (downtime) + US$ 10.000 (investimento) = US$ 15.000, menor que os US$ 20.000 originais. Nesse caso, além de proteger a reputação da empresa, você também reduziu o custo esperado.
Definir metas de RTO e RPO é só o começo. Testes regulares garantem que você realmente consegue cumpri-las quando o desastre acontecer. Sem validação, seus objetivos de recuperação são apenas suposições otimistas.
Os testes assumem várias formas, cada uma com níveis diferentes de validação e risco. Recomendo uma abordagem em camadas que avance de exercícios de baixo risco até testes abrangentes em produção.
Exercícios de mesa são testes baseados em discussão: percorrem cenários de desastre para identificar lacunas de procedimento e responsabilidades pouco claras. Embora úteis para validar o planejamento, não testam as capacidades técnicas de fato.
Além dos exercícios de mesa, simulações de recuperação executam operações reais de recuperação em ambientes de teste isolados. Podem incluir restaurar bancos de dados em servidores separados ou promover failover de aplicações não críticas. Elas validam sistemas e procedimentos de backup sem arriscar a produção.
Já os testes completos de recuperação de desastres oferecem o maior nível de confiança ao realizar failover total de produção. Podem envolver desligar seu data center primário para verificar a operação no site de recuperação. Embora disruptivos, são a única forma de realmente validar metas de RTO e RPO alcançáveis.
Independentemente do método de teste, validar o Recovery Time Actual (RTA) e o Recovery Point Actual (RPA) durante os testes revela a distância entre o planejado e a realidade. Se seu RTO é de quatro horas, mas a recuperação leva seis, é preciso melhorar as capacidades ou ajustar o RTO.
Além dos próprios eventos de teste, o monitoramento contínuo garante que as metas permaneçam viáveis. Acompanhe estes indicadores:
Plataformas modernas oferecem dashboards que trazem esses indicadores para identificar problemas de forma proativa.
Os testes revelam lacunas, mas o verdadeiro valor vem do que você faz com os resultados. É aqui que a melhoria contínua transforma a recuperação de desastres de um plano estático em uma capacidade dinâmica.
Após cada teste, conduza debriefings estruturados cobrindo o que funcionou, o que falhou, causas-raiz e ações específicas. Acompanhe essas ações formalmente, com responsáveis e prazos de conclusão.
Além das melhorias pós-teste, revise as metas de RTO e RPO pelo menos anualmente, ou sempre que houver mudanças significativas em processos de negócio, tecnologia, regulações ou cenário de risco. Reavalie o impacto no negócio, valide as capacidades atuais e identifique novos requisitos.
A propósito, ameaças em evolução exigem evolução correspondente. Ransomware mudou profundamente as considerações de RPO. Backups tradicionais que sobrescrevem versões anteriores podem deixar apenas dados criptografados. O planejamento moderno deve prever backups imutáveis, maior retenção e identificação de pontos de recuperação limpos.
Da mesma forma, o aumento da vigilância regulatória afeta tanto o local de recuperação dos dados quanto a velocidade de notificação de incidentes.
Setores diferentes têm requisitos distintos de RTO e RPO, conforme necessidades operacionais, ambiente regulatório e tolerância a riscos. Aqui está como as metas típicas variam entre os segmentos:
|
Indústria |
RTO típico |
RPO típico |
Principais fatores |
|
Serviços financeiros |
0–4 horas |
Minutos a segundos |
Basel III, regulações da SEC, integridade de transações, impacto em receita |
|
Saúde |
2–4 horas |
15 minutos–1 hora |
Conformidade HIPAA, segurança do paciente, sistemas críticos à vida |
|
E-commerce |
1–4 horas |
15–30 minutos |
Perda direta de receita, confiança do cliente, picos de demanda |
|
Manufatura |
4–8 horas |
1–4 horas |
Dependências da cadeia de suprimentos, registros de produção, modelos just-in-time |
Instituições de serviços financeiros enfrentam exigências mais rígidas por conta de Basel III e regulações da SEC. Plataformas de negociação de ações podem ter RTO de 15 minutos e RPO quase zero para evitar perda de transações.
Da mesma forma, organizações de saúde equilibram segurança do paciente com conformidade HIPAA. Sistemas de prontuário eletrônico permitem fluxos emergenciais em papel enquanto evitam impacto significativo no cuidado.
Em contraste, plataformas de e-commerce sofrem impacto direto na receita durante interrupções. Varejistas online que geram US$ 10.000 por minuto precisam minimizar o downtime, especialmente em períodos de pico.
Enquanto isso, operações de manufatura lidam com dependências físicas da cadeia de suprimentos. Sistemas de execução de manufatura precisam evitar grandes rupturas de estoque enquanto mantêm registros de produção e dados de qualidade.
Em todos esses setores, padrões regulatórios influenciam significativamente as metas. PCI DSS afeta organizações que processam cartões de crédito. A HIPAA exige planos de contingência em saúde. O FFIEC fornece orientação para instituições financeiras. Frameworks como o NIST Cybersecurity Framework e a ISO 22301 oferecem abordagens estruturadas de continuidade de negócios que incorporam RTO e RPO.
Recovery Time Objective e Recovery Point Objective são métricas fundamentais de recuperação de desastres. RTO define em quanto tempo você precisa recuperar os sistemas após uma interrupção, enquanto RPO determina a perda de dados aceitável. Juntas, elas traduzem a continuidade de negócios em metas concretas e mensuráveis para evitar grandes prejuízos.
Os benefícios de um planejamento rigoroso vão muito além da conformidade: organizações com metas bem definidas e amplamente testadas se recuperam mais rápido, sofrem menor impacto financeiro e mantêm a confiança dos clientes. Testes regulares revelam problemas antes que eles importem.
Por fim, use RTO e RPO como instrumentos de avaliação contínua. Agende revisões regulares, faça testes significativos, aprenda com cada rodada e mantenha uma avaliação honesta se as capacidades atuais atendem às metas. As organizações que melhor atravessam desastres são as que mais se prepararam antes.
Se quer começar com prática no provedor de nuvem mais popular, recomendo o curso AWS Concepts.
Cursos recomendados
Curso
Curso
Curso
blog
Vinita Silaparasetty
14 min
blog
Elena Kosourova
14 min
blog
Mike Shakhomirov
11 min
blog
Matt Crabtree
9 min
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita

