
Kursus
Perancangan Basis Data
4 Hr
125.4K
Bayangkan ini: Pukul 2:00 pagi, dan server basis data perusahaan Anda mengalami kerusakan. Saat tim respons insiden Anda bergegas memulihkan operasional, dua pertanyaan mendominasi: "Seberapa cepat kita bisa kembali online?" dan "Berapa banyak data yang kita hilangkan?" Pertanyaan-pertanyaan ini mewakili dua metrik paling krusial dalam perencanaan pemulihan bencana: Recovery Time Objective (RTO) dan Recovery Point Objective (RPO).
Dengan biaya rata-rata kebocoran data mencapai $10,22 juta, menurut IBM, organisasi harus memiliki strategi pemulihan bencana yang tangguh. Dalam tutorial ini, saya akan memandu Anda melalui dasar-dasar RTO dan RPO, termasuk metode perhitungan, strategi implementasi, pendekatan pengujian, dan penerapan di industri.
Jika Anda baru dalam basis data dan komputasi awan, saya merekomendasikan mengikuti salah satu kursus fundamental kami, khususnya Understanding Cloud Computing dan Database Design.
Kedua metrik ini penting untuk perencanaan kesinambungan bisnis dan Keamanan Data. Keduanya adalah indikator kinerja utama yang membantu organisasi mengkuantifikasi toleransi risiko, mengalokasikan sumber daya, dan membuat keputusan yang tepat tentang infrastruktur pemulihan.
Recovery Time Objective (RTO) mewakili durasi maksimum yang dapat diterima suatu sistem tidak tersedia setelah terjadi gangguan. Ini menjawab pertanyaan: "Seberapa cepat kita harus memulihkan operasi?"
Misalnya, jika sistem pembayaran Anda memiliki RTO dua jam, Anda harus memulihkan fungsionalitas penuh dalam jangka waktu tersebut.
Di sisi lain, Recovery Point Objective (RPO) mendefinisikan kehilangan data maksimum yang dapat diterima yang diukur dalam waktu. Ini menjawab pertanyaan: "Seberapa banyak data yang dapat kita toleransi untuk hilang?"
Jika basis data Anda memiliki RPO 15 menit, pencadangan harus menangkap data setidaknya setiap 15 menit.
Meski tujuannya serupa, RTO dan RPO mengukur aspek pemulihan yang secara fundamental berbeda. RTO bersifat ke depan, mengukur waktu dari gangguan hingga pemulihan. RPO bersifat ke belakang, mengukur dari gangguan ke titik pemulihan terakhir yang dapat diterima.
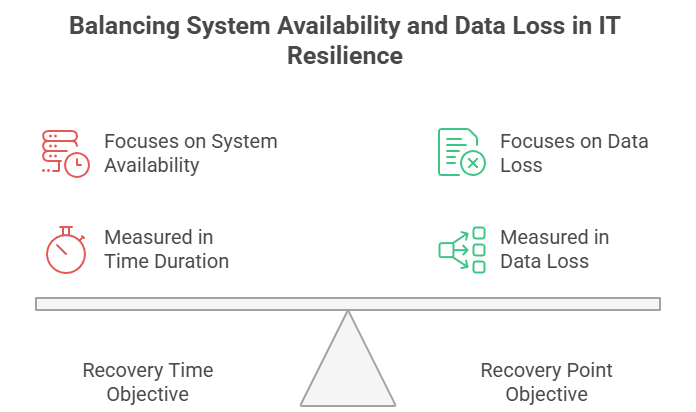
Sifat dampaknya juga berbeda. RTO berfokus pada ketersediaan: target yang terlewat berarti waktu henti lebih lama dan produktivitas hilang. RPO berfokus pada integritas data: target yang terlewat menyebabkan kehilangan data permanen dengan potensi konsekuensi regulasi dan finansial.
Investasi infrastruktur mengikuti pola yang berbeda. RTO yang agresif memerlukan sistem high-availability dan failover otomatis. RPO yang ketat menuntut perlindungan data berkelanjutan dan pencadangan yang sering, serta kapasitas penyimpanan yang memadai.
Penting: Kedua metrik ini independen. Anda mungkin memiliki RTO empat jam dengan RPO satu jam, atau RTO 30 menit dengan RPO enam jam. Semuanya bergantung pada kebutuhan bisnis.
Berikut tabel perbandingan:
|
Aspek |
RTO |
RPO |
|
Arah Temporal |
Ke depan |
Ke belakang |
|
Fokus Utama |
Ketersediaan sistem |
Integritas data |
|
Pertanyaan Kunci |
"Seberapa cepat kita harus pulih?" |
"Seberapa banyak data yang bisa kita hilangkan?" |
|
Prioritas Infrastruktur |
Sistem failover, redundansi |
Frekuensi backup, replikasi |
|
Independensi |
Ditetapkan terlepas dari RPO |
Ditetapkan terlepas dari RTO |
Menetapkan target RTO dan RPO yang tepat memerlukan pendekatan metodis yang menyeimbangkan kebutuhan bisnis dan kapabilitas teknis dengan kendala biaya. Prosesnya dimulai dengan memahami profil risiko dan prioritas unik organisasi Anda.
Dasar penetapan target dimulai dengan Business Impact Analysis (BIA) komprehensif, yang secara sistematis mengevaluasi bagaimana gangguan memengaruhi organisasi Anda.
Melakukan BIA melibatkan wawancara pemangku kepentingan di setiap departemen untuk memetakan fungsi bisnis dan konsekuensi ketidaktersediaan. Ini memastikan prioritas pemulihan mencerminkan dampak bisnis nyata, bukan hanya asumsi TI.
Service Level Agreement (SLA) sangat memengaruhi penetapan target. Jika Anda menjanjikan uptime 99,9%, RTO Anda harus selaras dengan komitmen ini untuk menghindari penalti finansial dan hilangnya pelanggan.
Gangguan memengaruhi organisasi dalam empat dimensi:
Hasil BIA memandu prioritas dan alokasi sumber daya yang hemat biaya. Sistem yang menghasilkan pendapatan, menangani transaksi pelanggan, atau memenuhi persyaratan regulasi layak mendapatkan target agresif. Sistem pendukung seperti direktori karyawan dapat mentoleransi waktu pemulihan yang lebih lama.
Dengan wawasan BIA di tangan, Anda siap menerjemahkan dampak bisnis ke target kuantitatif.
Menghitung RTO memerlukan pemahaman toleransi bisnis dan kapabilitas teknis. Mulailah dengan mengidentifikasi Maximum Tolerable Period of Disruption (MTPD), batas waktu terlama absolut suatu proses dapat tidak tersedia sebelum menyebabkan kerusakan yang tidak dapat diperbaiki. Tetapkan RTO lebih rendah dari MTPD untuk memberi margin keamanan.
Untuk menghitung RTO, ikuti langkah-langkah ini:
Menghitung RPO berfokus pada karakteristik data:
Pendekatan bertingkat memberikan strategi yang hemat biaya:
Hindari kesalahan umum ini:
Dengan perhitungan ini selesai, kini Anda memiliki target konkret untuk memandu keputusan teknologi dan proses.
Strategi implementasi yang tepat dan pilihan teknologi Anda dapat menjadi pembeda antara memenuhi tujuan atau gagal saat bencana terjadi.
Mari jelajahi teknologi inti yang memungkinkan pemulihan, dimulai dari pendekatan dasar hingga solusi yang lebih canggih.
Strategi backup dan pemulihan membentuk fondasi pemulihan bencana. Pencadangan penuh membuat salinan data lengkap namun mengonsumsi penyimpanan signifikan. Pencadangan inkremental hanya menangkap perubahan sejak backup terakhir. Pencadangan diferensial menangkap perubahan sejak backup penuh terakhir.0
Untuk kebutuhan RPO yang agresif, gabungkan pencadangan penuh harian dengan inkremental per jam.
Melampaui pencadangan tradisional, replikasi dan perlindungan data berkelanjutan mempertahankan salinan hampir real-time.
Replikasi sinkron menulis ke lokasi primer dan sekunder secara bersamaan, mencapai RPO hampir nol namun memperkenalkan latensi. Sebaliknya, replikasi asinkron menulis ke primer terlebih dahulu, lalu mereplikasi dengan sedikit penundaan. Continuous Data Protection (CDP) menangkap setiap perubahan, memungkinkan pemulihan titik waktu.

Selain mekanisme perlindungan data, lokasi pemulihan bencana menyesuaikan kapabilitas dengan kebutuhan RTO.
Cold site menyediakan infrastruktur dasar namun memerlukan waktu berhari-hari hingga berminggu-minggu untuk aktivasi. Warm site menyertakan perangkat keras terpasang sebelumnya dan sinkronisasi harian/mingguan sehingga dapat diaktifkan dalam hitungan jam. Hot site, di sisi lain, mempertahankan replika real-time yang sepenuhnya operasional dengan failover dalam hitungan menit untuk aplikasi misi-kritis.
Apa pun pendekatan lokasi pemulihan yang Anda pilih, alat otomasi dan orkestrasi sangat meningkatkan RTO dan RPO.
Alat manajemen konfigurasi memungkinkan rekonstruksi server dengan cepat. Demikian pula, platform orkestrasi pemulihan bencana mengotomatiskan prosedur failover. Sementara itu, otomasi runbook memastikan pemulihan yang konsisten selama insiden.
Selain pendekatan tradisional di lokasi (on-premises), teknologi cloud telah mentransformasi pemulihan bencana. Ini menawarkan kapabilitas yang dulunya hanya tersedia bagi perusahaan dengan anggaran besar.
Layanan pemulihan bencana berbasis cloud menyediakan alternatif yang fleksibel dan hemat biaya dibanding lokasi pemulihan fisik. Disaster Recovery as a Service (DRaaS) dari AWS, Azure, dan Google Cloud menghilangkan kebutuhan infrastruktur fisik terpisah. Untuk perbandingan tiga penyedia cloud paling populer, lihat panduan AWS vs Azure vs GCP kami.
Selain itu, Infrastructure as Code (IaC) memungkinkan pemulihan cepat dengan mendefinisikan seluruh infrastruktur dalam kode. Alat seperti Terraform atau AWS CloudFormation menciptakan ulang lingkungan lengkap dalam hitungan menit, secara drastis mengurangi RTO.
Saat memilih solusi cloud, pertimbangkan model deploymen. Public cloud menawarkan fleksibilitas dan biaya awal rendah dengan penetapan harga pay-as-you-go. Alternatifnya, private cloud memberikan kontrol lebih besar dan mungkin diperlukan untuk kepatuhan, terutama di industri sensitif seperti keuangan atau layanan kesehatan. Pendekatan hibrida menggabungkan sumber daya on-premises dan cloud untuk fleksibilitas.
Terakhir, jenis backup cloud yang umum meliputi
Memahami implikasi finansial dari target RTO dan RPO memungkinkan pengambilan keputusan yang tepat tentang investasi pemulihan. Setiap organisasi menghadapi tantangan menyeimbangkan perlindungan dengan biaya. Berikut cara mendekati pertukaran kritis ini.
Hubungan antara tujuan pemulihan dan biaya mengikuti pola yang dapat diprediksi, tetapi mengoptimalkannya memerlukan pemikiran strategis.
Ada hubungan terbalik antara target RTO/RPO dan biaya. Misalnya, mencapai RTO 15 menit biayanya jauh lebih besar dibanding RTO 24 jam. Demikian pula, mencapai RPO 15 menit membutuhkan backup lebih sering dan penyimpanan lebih banyak dibanding RPO 24 jam. Pemulihan mendekati nol memerlukan sistem redundan, replikasi berkelanjutan, dan failover otomatis.
Namun, pendekatan bertingkat mengoptimalkan investasi. Alih-alih menerapkan target agresif ke semua sistem, alokasikan sumber daya berdasarkan tingkat kekritisan.
Sebagai contoh, platform e-commerce sebaiknya berinvestasi besar dalam replikasi hot-site untuk menghindari waktu henti lama (RTO minimal), sementara hanya menggunakan backup cloud harian untuk wiki internal (RPO menengah). Penghematan dari target yang wajar pada sistem kurang kritis mendanai perlindungan kuat untuk sistem misi-kritis.
Untuk mempraktikkannya, menyeimbangkan kekritisan, risiko, dan biaya memerlukan pengkuantifikasian biaya waktu henti, menilai kemungkinan skenario bencana, mengevaluasi biaya pendekatan pemulihan, dan mengidentifikasi titik keseimbangan optimal.
Misalnya, anggap setiap jam waktu henti menelan biaya $50.000 dalam kehilangan pendapatan, dan ada kemungkinan 10% per tahun terjadi gangguan empat jam. Biaya tahunan yang diharapkan dari gangguan tersebut adalah 0,1 × 4 × $50.000 = $20.000.
Jika Anda berinvestasi $10.000 per tahun dalam infrastruktur yang lebih baik dan itu mengurangi gangguan menjadi satu jam, maka biaya tahunan yang diharapkan dari waktu henti menjadi 0,1 × 1 × $50.000 = $5.000. Total biaya tahunan yang diharapkan kini $5.000 (waktu henti) + $10.000 (investasi) = $15.000, lebih rendah daripada $20.000 semula. Dalam kasus ini, Anda tidak hanya mengamankan reputasi perusahaan tetapi juga menurunkan biaya yang diharapkan.
Menetapkan target RTO dan RPO hanyalah permulaan. Pengujian rutin memastikan Anda benar-benar dapat mencapainya saat bencana terjadi. Tanpa validasi, tujuan pemulihan Anda hanyalah asumsi penuh harap.
Pengujian hadir dalam berbagai bentuk, masing-masing menawarkan tingkat validasi dan risiko yang berbeda. Saya merekomendasikan pendekatan berlapis yang berkembang dari latihan berisiko rendah hingga pengujian produksi yang komprehensif.
Latihan tabletop menyediakan pengujian berbasis diskusi, menelusuri skenario bencana untuk mengidentifikasi celah prosedur dan tanggung jawab yang tidak jelas. Meski berharga untuk validasi perencanaan, ini tidak menguji kapabilitas teknis yang sebenarnya.
Melampaui latihan tabletop, simulasi pemulihan melakukan operasi pemulihan nyata di lingkungan uji terisolasi. Ini mencakup pemulihan basis data ke server terpisah atau failover aplikasi non-kritis. Simulasi memvalidasi sistem dan prosedur backup tanpa mempertaruhkan sistem produksi.
Namun, uji pemulihan bencana penuh memberikan tingkat kepercayaan tertinggi dengan melakukan failover produksi secara lengkap. Pengujian ini mungkin melibatkan mematikan pusat data utama Anda untuk memverifikasi operasi di lokasi pemulihan. Meski mengganggu, uji DR penuh adalah satu-satunya cara untuk benar-benar memvalidasi target RTO dan RPO yang bisa dicapai.
Apa pun metode pengujian yang digunakan, validasi Recovery Time Actual (RTA) dan Recovery Point Actual (RPA) selama pengujian mengungkap kesenjangan kenyataan objektif. Jika RTO Anda empat jam tetapi pemulihan secara konsisten memakan waktu enam jam, Anda harus meningkatkan kapabilitas atau menyesuaikan RTO.
Selain menguji kejadian itu sendiri, pemantauan berkelanjutan memastikan tujuan tetap dapat dicapai. Lacak metrik kunci berikut:
Platform modern menyediakan dasbor yang menampilkan metrik ini untuk identifikasi masalah secara proaktif.
Pengujian mengungkap celah, tetapi nilai sebenarnya berasal dari apa yang Anda lakukan terhadap hasilnya. Di sinilah perbaikan berkelanjutan mengubah pemulihan bencana dari rencana statis menjadi kapabilitas dinamis.
Setelah setiap pengujian, lakukan debrief terstruktur yang mencakup apa yang berhasil, apa yang gagal, akar penyebab, dan butir tindakan spesifik. Lacak butir-butir ini secara formal dengan penanggung jawab dan tenggat penyelesaian.
Di luar perbaikan pascapengujian, tinjau target RTO dan RPO setidaknya setiap tahun, atau ketika terjadi perubahan signifikan pada proses bisnis, teknologi, regulasi, atau lanskap risiko. Tinjau ulang dampak bisnis, validasi kapabilitas saat ini, dan identifikasi persyaratan yang berubah.
Selain itu, ancaman yang berubah memerlukan evolusi yang sesuai. Ransomware secara fundamental telah mengubah pertimbangan RPO. Backup tradisional yang menimpa versi sebelumnya dapat menyisakan hanya data yang terenkripsi. Perencanaan modern harus memperhitungkan backup yang tidak dapat diubah, retensi lebih lama, dan identifikasi titik pemulihan yang bersih.
Demikian pula, peningkatan pengawasan regulasi memengaruhi lokasi pemulihan data dan kecepatan pemberitahuan pelanggaran.
Setiap industri memiliki kebutuhan RTO dan RPO yang berbeda berdasarkan kebutuhan operasional, lingkungan regulasi, dan toleransi risiko. Berikut cara target tipikal bervariasi di berbagai sektor:
|
Industri |
RTO Tipikal |
RPO Tipikal |
Pendorong Utama |
|
Layanan Keuangan |
0-4 jam |
Menit hingga detik |
Regulasi Basel III, SEC, integritas transaksi, dampak pendapatan |
|
Layanan Kesehatan |
2-4 jam |
15 menit-1 jam |
Kepatuhan HIPAA, keselamatan pasien, sistem yang kritis terhadap nyawa |
|
E-commerce |
1-4 jam |
15-30 menit |
Kehilangan pendapatan langsung, kepercayaan pelanggan, kebutuhan periode puncak |
|
Manufaktur |
4-8 jam |
1-4 jam |
Ketergantungan rantai pasok, catatan produksi, model just-in-time |
Lembaga layanan keuangan menghadapi persyaratan paling ketat karena regulasi Basel III dan SEC. Platform perdagangan saham mungkin memiliki RTO 15 menit dan RPO hampir nol untuk mencegah kehilangan transaksi.
Sama kritisnya, organisasi layanan kesehatan menyeimbangkan keselamatan pasien dengan kepatuhan HIPAA. Sistem rekam medis elektronik memungkinkan alur kerja darurat berbasis kertas sekaligus mencegah dampak signifikan pada perawatan.
Sebaliknya, platform e-commerce menghadapi dampak pendapatan langsung saat terjadi gangguan. Peritel online yang menghasilkan $10.000 per menit harus meminimalkan waktu henti, terutama selama periode puncak.
Sementara itu, operasi manufaktur berhadapan dengan ketergantungan fisik rantai pasok. Sistem eksekusi manufaktur harus mencegah gangguan inventaris besar sambil mempertahankan catatan produksi dan data mutu.
Di semua industri ini, standar regulasi sangat memengaruhi target. PCI DSS memengaruhi organisasi pemrosesan kartu kredit. HIPAA mewajibkan perencanaan kontinjensi layanan kesehatan. FFIEC memberikan panduan untuk lembaga keuangan. Kerangka kerja seperti NIST Cybersecurity Framework dan ISO 22301 menyediakan pendekatan kesinambungan bisnis terstruktur yang menggabungkan RTO dan RPO.
Recovery Time Objective dan Recovery Point Objective adalah metrik dasar pemulihan bencana. RTO mendefinisikan seberapa cepat Anda harus memulihkan sistem setelah gangguan, sementara RPO menentukan kehilangan data yang dapat diterima. Bersama-sama, keduanya menerjemahkan kesinambungan bisnis ke target konkret dan terukur untuk menghindari bencana besar.
Manfaat perencanaan yang ketat sangat besar melampaui kepatuhan: Organisasi dengan target yang terdefinisi jelas dan diuji menyeluruh pulih lebih cepat dari gangguan, mengalami dampak finansial lebih rendah, dan mempertahankan kepercayaan pelanggan. Pengujian rutin mengungkap masalah sebelum berdampak nyata.
Pada akhirnya, gunakan RTO dan RPO untuk evaluasi berkelanjutan. Jadwalkan tinjauan rutin, lakukan pengujian yang bermakna, pelajari dari setiap pengujian, dan pertahankan penilaian jujur apakah kapabilitas saat ini memenuhi target yang dinyatakan. Organisasi yang paling mampu bertahan dari bencana adalah yang paling matang dalam persiapan sebelumnya.
Jika Anda ingin mulai belajar langsung untuk platform cloud paling populer, saya merekomendasikan mengikuti kursus AWS Concepts kami.
Kursus Terkait
Kursus
Kursus
Kursus
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
