
Cursus
Databaseontwerp
4 Hr
125.2K
Stel je voor: het is 2.00 uur ’s nachts en de databaseserver van je bedrijf is gecrasht. Terwijl je incidentresponsteam alles op alles zet om de operatie te herstellen, dringen twee vragen zich op: "Hoe snel kunnen we weer online?" en "Hoeveel data zijn we kwijtgeraakt?" Deze vragen staan voor de twee belangrijkste kengetallen in disaster recovery-planning: Recovery Time Objective (RTO) en Recovery Point Objective (RPO).
Met de gemiddelde kosten van een datalek die oplopen tot $10,22 miljoen, volgens IBM, moeten organisaties robuuste disaster recovery-strategieën hebben. In deze tutorial neem ik je mee door de basisprincipes van RTO en RPO, inclusief rekenmethoden, implementatiestrategieën, testaanpakken en toepassingen per sector.
Als je nieuw bent met databases en cloudcomputing, raad ik aan een van onze basiscursussen te volgen, in het bijzonder Understanding Cloud Computing en Database Design.
Beide kengetallen zijn cruciaal voor business continuity-planning en gegevensbeveiliging. Het zijn KPI’s die organisaties helpen om risicotolerantie te kwantificeren, middelen toe te wijzen en weloverwogen beslissingen te nemen over recovery-infrastructuur.
Recovery Time Objective (RTO) staat voor de maximaal acceptabele periode dat een systeem onbeschikbaar mag zijn na een verstoring. Het beantwoordt de vraag: "Hoe snel moeten we de operatie herstellen?"
Als je betaalsysteem bijvoorbeeld een RTO van twee uur heeft, moet volledige functionaliteit binnen die tijd worden hersteld.
Recovery Point Objective (RPO) daarentegen definieert het maximaal acceptabele dataverlies, uitgedrukt in tijd. Het beantwoordt de vraag: "Hoeveel data kunnen we ons permitteren te verliezen?"
Als je database een RPO van 15 minuten heeft, moeten back-ups minimaal elke 15 minuten gegevens vastleggen.
Hoewel ze een vergelijkbaar doel hebben, meten RTO en RPO fundamenteel verschillende aspecten van herstel. RTO is toekomstgericht: het meet de tijd van verstoring tot herstel. RPO is terugkijkend: het meet van verstoring tot het laatst acceptabele herstelpunt.
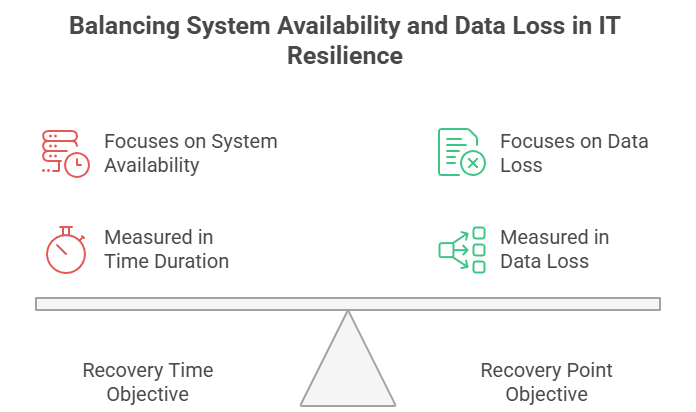
Ook de aard van de impact verschilt. RTO richt zich op beschikbaarheid: gemiste doelen betekenen extra downtime en productiviteitsverlies. RPO richt zich op dataintegriteit: gemiste doelen leiden tot permanent dataverlies met mogelijke juridische en financiële gevolgen.
Investeringen in infrastructuur volgen verschillende patronen. Agressieve RTO’s vereisen high-availability-systemen en automatische failover. Strenge RPO’s vragen om continue gegevensbescherming en frequente back-ups, plus voldoende opslagcapaciteit.
Belangrijk: beide kengetallen zijn onafhankelijk. Je kunt een RTO van vier uur hebben met een RPO van één uur, of een RTO van 30 minuten met een RPO van zes uur. Het hangt volledig af van de bedrijfsbehoeften.
Hier is een vergelijkende tabel:
|
Aspect |
RTO |
RPO |
|
Tijdsdimensie |
Toekomstgericht |
Terugkijkend |
|
Primair focuspunt |
Systeembeschikbaarheid |
Dataintegriteit |
|
Belangrijkste vraag |
"Hoe snel moeten we herstellen?" |
"Hoeveel data kunnen we verliezen?" |
|
Infraprioriteit |
Failover-systemen, redundantie |
Back-upfrequentie, replicatie |
|
Onafhankelijkheid |
Wordt los van RPO vastgesteld |
Wordt los van RTO vastgesteld |
Het instellen van passende RTO- en RPO-doelen vraagt om een methodische aanpak die zakelijke behoeften en technische mogelijkheden afstemt op kostenbeperkingen. Het proces begint met inzicht in het unieke risicoprofiel en de prioriteiten van je organisatie.
De basis voor het bepalen van doelen begint met een uitgebreide Business Impact Analysis (BIA), die systematisch beoordeelt hoe verstoringen je organisatie raken.
Een BIA uitvoeren betekent dat je belanghebbenden in alle afdelingen interviewt om bedrijfsfuncties en de gevolgen van onbeschikbaarheid in kaart te brengen. Zo zorg je dat herstelprioriteiten de werkelijke zakelijke impact weerspiegelen en niet alleen IT-aannames.
Service Level Agreements (SLA’s) hebben grote invloed op het stellen van doelen. Als je 99,9% uptime hebt beloofd, moet je RTO hiermee in lijn zijn om boetes en klantverloop te voorkomen.
Verstoringen raken organisaties op vier dimensies:
BIA-resultaten sturen de prioritering en kosteneffectieve toewijzing van middelen. Systemen die omzet genereren, klanttransacties afhandelen of aan wettelijke vereisten voldoen, rechtvaardigen agressieve doelen. Ondersteunende systemen zoals medewerkerdirectories kunnen langere hersteltijden verdragen.
Met BIA-inzichten op zak kun je de zakelijke impact vertalen naar kwantitatieve doelen.
RTO berekenen vereist begrip van zakelijke tolerantie en technische mogelijkheden. Begin met het identificeren van de Maximum Tolerable Period of Disruption (MTPD), de absoluut langste periode dat een proces onbeschikbaar kan zijn zonder onherstelbare schade te veroorzaken. Stel RTO lager in dan MTPD om een veiligheidsmarge te houden.
Volg deze stappen om RTO te berekenen:
RPO berekenen richt zich op data-eigenschappen:
Een getrapte aanpak biedt een kosteneffectieve strategie:
Vermijd deze veelvoorkomende valkuilen:
Met deze berekeningen afgerond heb je concrete doelen om je technologische en procesbeslissingen te sturen.
De juiste implementatiestrategie en technologiekeuzes maken het verschil tussen je doelen halen of falen wanneer het misgaat.
Laten we de kerntechnologieën verkennen die herstel mogelijk maken, te beginnen met de basisaanpakken en vervolgens naar geavanceerdere oplossingen.
Back-up- en herstelstrategieën vormen de basis van disaster recovery. Full backups maken volledige kopieën van data maar vergen veel opslag. Incrementele back-ups leggen alleen wijzigingen vast sinds de laatste back-up. Differentiële back-ups leggen wijzigingen vast sinds de laatste volledige back-up.0
Combineer voor agressieve RPO-eisen dagelijkse full backups met uurlijkse incrementele back-ups.
Verder dan traditionele back-ups zorgen replicatie en continue gegevensbescherming voor bijna realtime kopieën.
Synchrone replicatie schrijft tegelijkertijd naar primaire en secundaire locaties en bereikt een RPO dicht bij nul, maar introduceert latency. Asynchrone replicatie daarentegen schrijft eerst naar de primaire locatie en repliceert daarna met een kleine vertraging. Continuous Data Protection (CDP) legt elke wijziging vast, waardoor herstel op tijdstip mogelijk is.

Naast gegevensbeschermingsmechanismen sluiten disaster recovery-sites aan op RTO-vereisten.
Cold sites bieden basisinfrastructuur maar hebben dagen tot weken nodig om te activeren. Warm sites bevatten voorgeïnstalleerde hardware en dagelijkse/wekelijkse synchronisatie, zodat ze binnen enkele uren kunnen activeren. Hot sites daarentegen houden volledig operationele realtime replica’s in stand met failover op minuteniveau voor missiekritische applicaties.
Ongeacht welke sitebenadering je kiest, verbeteren automatiserings- en orkestratietools RTO en RPO drastisch.
Configuration management-tools maken snelle reconstructie van servers mogelijk. Evenzo automatiseren disaster recovery-orkestratieplatforms failoverprocedures. Runbook-automatisering zorgt intussen voor consistent herstel tijdens incidenten.
Naast traditionele on-premises aanpakken heeft cloudtechnologie disaster recovery getransformeerd. Het biedt mogelijkheden die ooit alleen beschikbaar waren voor ondernemingen met enorme budgetten.
Cloudgebaseerde disaster recovery-diensten bieden flexibele, kosteneffectieve alternatieven voor fysieke recoverysites. Disaster Recovery as a Service (DRaaS) van AWS, Azure en Google Cloud elimineert aparte fysieke infrastructuur. Voor een vergelijking van de drie populairste cloudproviders, bekijk onze gids AWS vs Azure vs GCP.
Bovendien maakt Infrastructure as Code (IaC) snel herstel mogelijk door de volledige infrastructuur in code te definiëren. Tools zoals Terraform of AWS CloudFormation zetten complete omgevingen in minuten opnieuw op, wat RTO drastisch verlaagt.
Houd bij het kiezen van cloudoplossingen rekening met het implementatiemodel. Public cloud biedt flexibiliteit en lage instapkosten met pay-as-you-go-prijzen. Een private cloud biedt daarentegen meer controle en kan nodig zijn voor compliance, vooral in gevoelige sectoren zoals financiën of gezondheidszorg. Hybride aanpakken combineren on-premises en cloudresources voor flexibiliteit.
Tot slot zijn veelvoorkomende cloudback-ups:
Als je de financiële implicaties van RTO- en RPO-doelen begrijpt, kun je weloverwogen beslissingen nemen over herstelinvesteringen. Elke organisatie staat voor de uitdaging om bescherming en kosten in balans te houden. Zo pak je deze cruciale afweging aan.
De relatie tussen hersteldoelen en kosten volgt voorspelbare patronen, maar optimaliseren vraagt om strategisch denken.
Er bestaat een omgekeerde relatie tussen RTO/RPO-doelen en kosten. Zo kost een RTO van 15 minuten exponentieel meer dan een RTO van 24 uur. Evenzo vereist een RPO van 15 minuten vaker back-uppen en meer opslag dan een RPO van 24 uur. Herstel dicht bij nul vraagt om redundante systemen, continue replicatie en automatische failover.
Een getrapte aanpak optimaliseert echter de investering. In plaats van agressieve doelen op alle systemen toe te passen, wijs je middelen toe op basis van criticaliteit.
Een e-commerceplatform kan bijvoorbeeld zwaar investeren in hot-site-replicatie om langdurige downtime te voorkomen (minimale RTO), terwijl het voor interne wiki’s volstaat om dagelijkse cloudback-ups te gebruiken (gemiddelde RPO). Besparingen door redelijke doelen op minder kritieke systemen financieren robuuste bescherming voor missiekritieke systemen.
Om dit in de praktijk te brengen, vereist het balanceren van criticaliteit, risico en kosten het kwantificeren van downtime-kosten, het inschatten van de kans op rampscenario’s, het evalueren van kosten van herstelbenaderingen en het identificeren van optimale balanspunten.
Stel bijvoorbeeld dat elk uur downtime je bedrijf $50.000 aan omzet kost en er jaarlijks 10% kans is op een storing van vier uur. De verwachte jaarlijkse kosten van die storing zijn 0,1 × 4 × $50.000 = $20.000.
Als je $10.000 per jaar investeert in betere infrastructuur en daarmee de storing terugbrengt naar één uur, worden de verwachte jaarlijkse downtime-kosten 0,1 × 1 × $50.000 = $5.000. Je totale verwachte jaarkosten zijn nu $5.000 (downtime) + $10.000 (investering) = $15.000, wat lager is dan de oorspronkelijke $20.000. In dit geval heb je niet alleen de reputatie van je bedrijf veiliggesteld, maar ook de verwachte kosten verlaagd.
RTO- en RPO-doelen vaststellen is nog maar het begin. Regelmatig testen zorgt ervoor dat je ze daadwerkelijk kunt halen wanneer het erop aankomt. Zonder validatie blijven je hersteldoelen slechts hoopvolle aannames.
Testen kent meerdere vormen, elk met een ander niveau van validatie en risico. Ik raad een gelaagde aanpak aan die oploopt van laagrisico-oefeningen tot uitgebreide productietests.
Tabletop-oefeningen zijn discussiegedreven tests waarin je rampscenario’s doorloopt om gaten in procedures en onduidelijke verantwoordelijkheden te identificeren. Ze zijn waardevol voor planningsvalidatie, maar testen geen daadwerkelijke technische capaciteiten.
Verder dan tabletop-oefeningen voeren herstelsimulaties echte herstelhandelingen uit in geïsoleerde testomgevingen. Denk aan het herstellen van databases op aparte servers of het laten overnemen van niet-kritische applicaties. Deze valideren back-ups en procedures zonder productiesystemen te riskeren.
Volledige disaster recovery-tests bieden echter de grootste zekerheid door complete productie-failovers uit te voeren. Deze tests kunnen inhouden dat je je primaire datacenter uitschakelt om de werking van de recoverysite te verifiëren. Hoewel verstorend, zijn volledige DR-tests de enige manier om haalbare RTO- en RPO-doelen echt te valideren.
Ongeacht de gebruikte testmethode laten Recovery Time Actual (RTA) en Recovery Point Actual (RPA) tijdens tests de kloof met de realiteit zien. Als je RTO vier uur is maar herstel consequent zes uur duurt, moet je de capaciteiten verbeteren of de RTO aanpassen.
Naast de testmomenten zelf zorgt doorlopende monitoring ervoor dat doelen haalbaar blijven. Volg deze kerncijfers:
Moderne platforms bieden dashboards die deze metrics inzichtelijk maken om issues proactief te signaleren.
Testen brengt hiaten aan het licht, maar de echte waarde zit in wat je met de resultaten doet. Daar maakt continue verbetering van disaster recovery een statisch plan tot een dynamische capaciteit.
Voer na elke test gestructureerde debriefs uit over wat goed ging, wat misging, de grondoorzaken en concrete actiepunten. Volg deze formeel op met eigenaren en deadlines.
Naast verbeteringen na tests, beoordeel je RTO- en RPO-doelen minimaal jaarlijks, of wanneer er grote veranderingen zijn in bedrijfsprocessen, technologie, regelgeving of het risicolandschap. Beoordeel de zakelijke impact opnieuw, valideer de huidige capaciteiten en identificeer gewijzigde eisen.
Bovendien vereisen veranderende dreigingen een overeenkomstige evolutie. Ransomware heeft RPO-overwegingen fundamenteel veranderd. Traditionele back-ups die eerdere versies overschrijven kunnen ertoe leiden dat alleen versleutelde data overblijft. Moderne planning moet rekening houden met onveranderlijke (immutable) back-ups, langere bewaartermijnen en identificatie van schone herstelpunten.
Ook toegenomen toezicht door toezichthouders beïnvloedt zowel de locatie van gegevensherstel als de snelheid van datalekmeldingen.
Verschillende sectoren hebben uiteenlopende RTO- en RPO-vereisten op basis van operationele behoeften, regelgeving en risicotolerantie. Hier zie je hoe typische doelen per sector verschillen:
|
Sector |
Typische RTO |
Typische RPO |
Belangrijkste drijfveren |
|
Financiële dienstverlening |
0–4 uur |
Minuten tot seconden |
Basel III, SEC-regels, transactie-integriteit, omzetimpact |
|
Gezondheidszorg |
2–4 uur |
15 minuten–1 uur |
HIPAA-compliance, patiëntveiligheid, levensreddende systemen |
|
E-commerce |
1–4 uur |
15–30 minuten |
Direct omzetverlies, klantvertrouwen, piekdrukte |
|
Productie |
4–8 uur |
1–4 uur |
Ketenafhankelijkheden, productieregistraties, just-in-time-modellen |
Instellingen in de financiële dienstverlening hebben de strengste eisen door Basel III en SEC-regelgeving. Aandelenhandelsplatforms kunnen RTO’s van 15 minuten en RPO’s dicht bij nul hebben om transactieverlies te voorkomen.
Even cruciaal is dat zorgorganisaties patiëntveiligheid en HIPAA-compliance in balans brengen. Elektronische patiëntendossiers maken noodpapieren workflows mogelijk terwijl significante zorgimpact wordt voorkomen.
Daarentegen ervaren e-commerceplatforms direct omzetverlies bij storingen. Webwinkels die $10.000 per minuut genereren, moeten downtime minimaliseren, vooral tijdens piekperiodes.
Intussen kampen productieomgevingen met fysieke ketenafhankelijkheden. Manufacturing execution-systemen moeten grote voorraadverstoringen voorkomen en tegelijk productieregistraties en kwaliteitsdata bijhouden.
In al deze sectoren beïnvloeden normen de doelen aanzienlijk. PCI DSS raakt organisaties die creditcardbetalingen verwerken. HIPAA verplicht noodplannen in de zorg. FFIEC geeft richtlijnen voor financiële instellingen. Raamwerken zoals het NIST Cybersecurity Framework en ISO 22301 bieden gestructureerde continuïteitsaanpakken waarin RTO en RPO zijn opgenomen.
Recovery Time Objective en Recovery Point Objective zijn fundamentele metrics voor disaster recovery. RTO bepaalt hoe snel je systemen moeten herstellen na een verstoring, terwijl RPO bepaalt hoeveel dataverlies acceptabel is. Samen vertalen ze bedrijfscontinuïteit naar concrete, meetbare doelen om grote problemen te voorkomen.
De voordelen van rigoureuze planning gaan veel verder dan compliance: organisaties met goed gedefinieerde en grondig geteste doelen herstellen sneller van verstoringen, hebben een lagere financiële impact en behouden klantvertrouwen. Regelmatig testen brengt issues aan het licht voordat ze ertoe doen.
Gebruik RTO en RPO uiteindelijk voor voortdurende evaluatie. Plan regelmatige reviews, voer betekenisvolle tests uit, leer van elke test en beoordeel eerlijk of de huidige capaciteiten overeenkomen met de gestelde doelen. Organisaties die rampen het beste doorstaan, zijn degenen die vooraf het grondigst hebben voorbereid.
Als je praktisch aan de slag wilt met het populairste cloudplatform, raad ik onze cursus AWS Concepts aan.
Relevante cursussen
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
