
Kurs
Datenbankdesign
4 Std.
125.2K
Stell dir vor: Es ist 2:00 Uhr morgens und der Datenbankserver deines Unternehmens ist abgestürzt. Während dein Incident-Response-Team fieberhaft versucht, den Betrieb wiederherzustellen, dominieren zwei Fragen: „Wie schnell sind wir wieder online?“ und „Wie viele Daten haben wir verloren?“ Diese Fragen stehen für die zwei entscheidenden Kennzahlen in der Notfallwiederherstellung: Recovery Time Objective (RTO) und Recovery Point Objective (RPO).
Bei durchschnittlichen Kosten einer Datenschutzverletzung von 10,22 Millionen US-Dollar laut IBM brauchen Organisationen robuste Strategien für die Notfallwiederherstellung. In diesem Tutorial führe ich dich durch die Grundlagen von RTO und RPO – inklusive Berechnungsmethoden, Implementierungsstrategien, Testansätzen und Branchenanwendungen.
Wenn du neu bei Datenbanken und Cloud Computing bist, empfehle ich dir unsere Einstiegskurse, insbesondere Understanding Cloud Computing und Database Design.
Beide Kennzahlen sind entscheidend für die Geschäftsfortführungsplanung und die Datensicherheit. Sie sind KPIs, die Unternehmen helfen, Risikotoleranz zu quantifizieren, Ressourcen zuzuweisen und fundierte Entscheidungen über die Wiederherstellungsinfrastruktur zu treffen.
Das Recovery Time Objective (RTO) steht für die maximal akzeptable Zeitspanne, in der ein System nach einem Störfall nicht verfügbar sein darf. Es beantwortet: „Wie schnell müssen wir den Betrieb wiederherstellen?“
Hat dein Bezahlsystem zum Beispiel ein RTO von zwei Stunden, musst du die volle Funktionsfähigkeit innerhalb dieses Zeitfensters wiederherstellen.
Das Recovery Point Objective (RPO) definiert dagegen den maximal akzeptablen Datenverlust, gemessen in Zeit. Es beantwortet: „Wie viele Daten können wir uns leisten zu verlieren?“
Hat deine Datenbank ein RPO von 15 Minuten, müssen Backups mindestens alle 15 Minuten Daten erfassen.
Obwohl beide ein ähnliches Ziel verfolgen, messen RTO und RPO grundlegend unterschiedliche Aspekte der Wiederherstellung. RTO blickt nach vorn und misst die Zeit von der Störung bis zur Wiederherstellung. RPO blickt zurück und misst die Zeit von der Störung bis zum letzten akzeptablen Wiederherstellungspunkt.
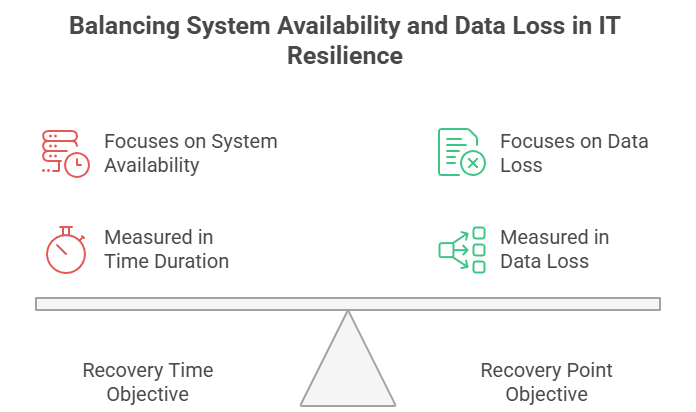
Auch die Art der Auswirkungen unterscheidet sich. RTO fokussiert Verfügbarkeit: Verfehlte Ziele bedeuten längere Ausfallzeiten und Produktivitätsverlust. RPO fokussiert Datenintegrität: Verfehlte Ziele führen zu dauerhaftem Datenverlust mit möglichen regulatorischen und finanziellen Folgen.
Investitionen in Infrastruktur folgen unterschiedlichen Mustern. Ambitionierte RTOs erfordern Hochverfügbarkeitssysteme und automatisches Failover. Strenge RPOs verlangen kontinuierlichen Datenschutz und häufige Backups sowie ausreichende Speicherkapazität.
Wichtig: Beide Kennzahlen sind unabhängig voneinander. Du kannst ein RTO von vier Stunden mit einem RPO von einer Stunde haben – oder ein RTO von 30 Minuten mit einem RPO von sechs Stunden. Es hängt vollständig von den Geschäftsanforderungen ab.
Hier ist eine Vergleichstabelle:
|
Aspekt |
RTO |
RPO |
|
Zeitliche Richtung |
Vorwärtsgerichtet |
Rückwärtsgerichtet |
|
Primärer Fokus |
Systemverfügbarkeit |
Datenintegrität |
|
Schlüsselfrage |
„Wie schnell müssen wir wiederherstellen?“ |
„Wie viele Daten dürfen wir verlieren?“ |
|
Priorität der Infrastruktur |
Failover-Systeme, Redundanz |
Backup-Frequenz, Replikation |
|
Unabhängigkeit |
Unabhängig vom RPO festgelegt |
Unabhängig vom RTO festgelegt |
Passende RTO- und RPO-Ziele erfordern ein methodisches Vorgehen, das Geschäftsbedarf und technische Möglichkeiten mit Kostengrenzen in Einklang bringt. Der Prozess beginnt damit, das individuelle Risikoprofil und die Prioritäten deiner Organisation zu verstehen.
Die Basis der Zieldefinition ist eine umfassende Business-Impact-Analyse (BIA), die systematisch bewertet, wie sich Störungen auf dein Unternehmen auswirken.
Für eine BIA befragst du Stakeholder in allen Abteilungen, um Geschäftsprozesse und die Folgen von Nichtverfügbarkeit zu erfassen. So spiegeln die Wiederherstellungsprioritäten die tatsächlichen Geschäftsauswirkungen wider – und nicht nur IT-Annahmen.
Service Level Agreements (SLAs) beeinflussen die Zielsetzung stark. Wenn du 99,9 % Verfügbarkeit zusagst, muss dein RTO dazu passen – sonst drohen Vertragsstrafen und Kundenabwanderung.
Störungen betreffen Organisationen in vier Dimensionen:
BIA-Ergebnisse leiten Priorisierung und kosteneffiziente Ressourcenallokation. Systeme mit Umsatzbezug, Kunden-Transaktionen oder regulatorischen Anforderungen brauchen ambitionierte Ziele. Unterstützende Systeme wie Mitarbeiterverzeichnisse verkraften längere Wiederherstellungszeiten.
Mit den BIA-Erkenntnissen kannst du die Geschäftsfolgen in quantitative Zielwerte übersetzen.
Für das RTO brauchst du das Verständnis von Geschäftstoleranz und technischer Leistungsfähigkeit. Starte mit der Maximum Tolerable Period of Disruption (MTPD) – der absolut längsten Zeit, die ein Prozess ausfallen darf, bevor irreversibler Schaden entsteht. Setze das RTO niedriger als die MTPD, um einen Puffer zu haben.
So berechnest du das RTO Schritt für Schritt:
Die RPO-Berechnung fokussiert Datencharakteristika:
Ein gestuftes Modell ist oft am kosteneffizientesten:
Vermeide diese typischen Fehler:
Mit diesen Berechnungen hast du konkrete Zielwerte, die deine Technologie- und Prozessentscheidungen leiten.
Die richtige Umsetzungsstrategie und Technologiewahl entscheidet darüber, ob du deine Ziele erreichst – oder bei einem Notfall scheiterst.
Schauen wir uns die Kerntechnologien für die Wiederherstellung an – von grundlegenden Ansätzen bis hin zu ausgereiften Lösungen.
Backup- und Restore-Strategien bilden das Fundament der Notfallwiederherstellung. Vollbackups erstellen vollständige Datenkopien, benötigen aber viel Speicher. Inkrementelle Backups erfassen nur Änderungen seit dem letzten Backup. Differentielle Backups erfassen Änderungen seit dem letzten Vollbackup.0
Für strenge RPO-Anforderungen kombiniere tägliche Vollbackups mit stündlichen inkrementellen.
Über klassische Backups hinaus sorgen Replikation und Continuous Data Protection für nahezu Echtzeit-Kopien.
Synchrone Replikation schreibt gleichzeitig in Primär- und Sekundärstandort und erreicht ein nahezu null RPO, führt jedoch zu Latenz. Asynchrone Replikation schreibt erst auf den Primärstandort und repliziert dann mit geringer Verzögerung. Continuous Data Protection (CDP) erfasst jede Änderung und ermöglicht Wiederherstellung zu beliebigen Zeitpunkten.

Neben Datenschutzmechanismen richten sich DR-Standorte an den RTO-Anforderungen aus.
Cold Sites bieten grundlegende Infrastruktur, benötigen aber Tage bis Wochen zur Aktivierung. Warm Sites verfügen über vorinstallierte Hardware und tägliche/wöchentliche Synchronisierung, um innerhalb von Stunden aktivieren zu können. Hot Sites hingegen halten voll funktionsfähige Echtzeit-Replikas vor und ermöglichen Failover in Minuten – für missionskritische Anwendungen.
Unabhängig vom gewählten Standortansatz verbessern Automatisierungs- und Orchestrierungs-Tools RTO und RPO erheblich.
Konfigurationsmanagement-Tools ermöglichen den schnellen Wiederaufbau von Servern. Ebenso automatisieren DR-Orchestrierungsplattformen Failover-Prozesse. Runbook-Automation sorgt zudem für konsistente Abläufe im Ernstfall.
Neben klassischen On-Premises-Ansätzen hat die Cloud die Notfallwiederherstellung transformiert. Sie bietet Fähigkeiten, die früher nur Unternehmen mit großen Budgets vorbehalten waren.
Cloudbasierte Disaster-Recovery-Services sind flexible, kosteneffiziente Alternativen zu physischen Wiederherstellungsstandorten. Disaster Recovery as a Service (DRaaS) von AWS, Azure und Google Cloud macht separate physische Infrastruktur überflüssig. Einen Vergleich der drei populärsten Cloud-Anbieter findest du in unserem Leitfaden AWS vs Azure vs GCP.
Darüber hinaus ermöglicht Infrastructure as Code (IaC) eine schnelle Wiederherstellung, indem die gesamte Infrastruktur als Code definiert wird. Tools wie Terraform oder AWS CloudFormation stellen vollständige Umgebungen in Minuten wieder her und reduzieren das RTO drastisch.
Bei der Wahl von Cloud-Lösungen spielt das Bereitstellungsmodell eine Rolle. Public Cloud bietet Flexibilität und geringe Einstiegskosten mit nutzungsbasierter Abrechnung. Eine Private Cloud bietet dagegen mehr Kontrolle und kann für Compliance nötig sein – insbesondere in sensiblen Branchen wie Finanzwesen oder Gesundheitswesen. Hybride Ansätze kombinieren On-Premises- und Cloud-Ressourcen für maximale Flexibilität.
Zu den gängigen Cloud-Backup-Typen zählen
Wer die finanziellen Auswirkungen von RTO- und RPO-Zielen versteht, kann besser über Investitionen in Wiederherstellung entscheiden. Jedes Unternehmen muss Schutz und Kosten ausbalancieren. So näherst du dich diesem kritischen Trade-off.
Die Beziehung zwischen Wiederherstellungszielen und Kosten folgt einem erwartbaren Muster – die Optimierung erfordert jedoch strategisches Denken.
Zwischen RTO-/RPO-Zielen und Kosten besteht eine inverse Beziehung. Ein 15-minütiges RTO zu erreichen kostet zum Beispiel exponentiell mehr als ein 24-Stunden-RTO. Ebenso erfordert ein 15-minütiges RPO häufigere Backups und mehr Speicher als ein 24-Stunden-RPO. Nahezu Null-Wiederherstellung verlangt redundante Systeme, kontinuierliche Replikation und automatisches Failover.
Ein gestuftes Modell optimiert jedoch die Investitionen. Statt überall aggressive Ziele anzusetzen, verteilst du Ressourcen nach Kritikalität.
Ein Beispiel: Eine E-Commerce-Plattform sollte stark in Hot-Site-Replikation investieren, um lange Ausfallzeiten zu vermeiden (minimales RTO), während für interne Wikis tägliche Cloud-Backups ausreichen (mittleres RPO). Einsparungen bei weniger kritischen Systemen finanzieren den robusten Schutz für missionskritische Systeme.
In der Praxis braucht die Balance aus Kritikalität, Risiko und Kosten: die Quantifizierung von Ausfallkosten, die Einschätzung der Eintrittswahrscheinlichkeit von Desasterszenarien, die Bewertung der Kosten verschiedener Wiederherstellungsansätze und die Identifikation optimaler Balancepunkte.
Angenommen, jede Ausfallstunde kostet dein Unternehmen 50.000 US-Dollar Umsatz und es gibt eine 10%ige jährliche Chance auf einen vierstündigen Ausfall. Die erwarteten jährlichen Kosten dieses Ausfalls sind 0,1 × 4 × 50.000 $ = 20.000 $.
Investierst du 10.000 $ pro Jahr in bessere Infrastruktur und reduzierst damit den Ausfall auf eine Stunde, betragen die erwarteten jährlichen Ausfallkosten 0,1 × 1 × 50.000 $ = 5.000 $. Deine gesamten erwarteten Jahreskosten liegen nun bei 5.000 $ (Ausfall) + 10.000 $ (Investition) = 15.000 $ und damit unter den ursprünglichen 20.000 $. In diesem Fall sicherst du nicht nur den Ruf deines Unternehmens, sondern senkst auch die erwarteten Kosten.
RTO- und RPO-Ziele zu definieren ist erst der Anfang. Regelmäßige Tests stellen sicher, dass du sie im Ernstfall auch einhalten kannst. Ohne Validierung bleiben Wiederherstellungsziele bloße Hoffnung.
Tests gibt es in mehreren Formen – mit unterschiedlicher Validierungstiefe und Risiken. Ich empfehle einen gestaffelten Ansatz, der von risikoarmen Übungen bis zu umfassenden Produktivtests reicht.
Tabletop-Übungen sind gesprächsbasierte Tests: Man geht Desasterszenarien durch, um Lücken in Verfahren und Verantwortlichkeiten zu finden. Sie sind wertvoll zur Planvalidierung, testen aber keine technischen Fähigkeiten.
Über Tabletop-Übungen hinaus führen Simulationen echte Wiederherstellungen in isolierten Testumgebungen durch. Etwa das Wiederherstellen von Datenbanken auf separaten Servern oder das Failover nicht-kritischer Anwendungen. So validierst du Backups und Abläufe, ohne Produktivsysteme zu gefährden.
Vollständige Disaster-Recovery-Tests liefern die höchste Sicherheit, da sie komplette Produktiv-Failover durchführen. Dazu kann gehören, dein Primär-Rechenzentrum herunterzufahren, um den Betrieb am Recovery-Standort zu verifizieren. So störend sie sind: Nur vollständige DR-Tests validieren RTO- und RPO-Ziele wirklich.
Unabhängig von der Testmethode zeigen Messungen von Recovery Time Actual (RTA) und Recovery Point Actual (RPA) während der Tests die Lücke zur Realität. Wenn dein RTO vier Stunden beträgt, die Wiederherstellung aber konstant sechs Stunden dauert, musst du die Fähigkeiten verbessern oder das RTO anpassen.
Über die Testevents hinaus stellt laufendes Monitoring sicher, dass Ziele erreichbar bleiben. Verfolge diese Kennzahlen:
Moderne Plattformen bieten Dashboards, die diese Kennzahlen sichtbar machen und proaktives Handeln ermöglichen.
Tests decken Lücken auf – der eigentliche Mehrwert entsteht durch die Ableitung von Maßnahmen. So wird Disaster Recovery von einem statischen Plan zu einer dynamischen Fähigkeit.
Führe nach jedem Test strukturierte Debriefs durch: Was hat funktioniert, was nicht, Ursachenanalyse und konkrete To-dos. Verfolge diese Punkte mit Verantwortlichen und Fristen.
Über Verbesserungen nach Tests hinaus solltest du RTO- und RPO-Ziele mindestens jährlich überprüfen – oder wenn sich Geschäftsprozesse, Technologie, Regulierung oder das Risikoumfeld wesentlich ändern. Beurteile Geschäftsauswirkungen neu, validiere aktuelle Fähigkeiten und identifiziere neue Anforderungen.
Zudem erfordern neue Bedrohungen eine entsprechende Weiterentwicklung. Ransomware hat RPO-Überlegungen grundlegend verändert. Klassische Backups, die frühere Versionen überschreiben, können nur noch verschlüsselte Daten hinterlassen. Moderne Planung muss unveränderliche Backups, längere Aufbewahrung und die Identifikation sauberer Wiederherstellungspunkte berücksichtigen.
Ebenso beeinflusst verstärkte regulatorische Kontrolle sowohl Wiederherstellungsorte als auch die Geschwindigkeit der Meldung von Datenschutzverletzungen.
Unterschiedliche Branchen haben je nach Betrieb, Regulierung und Risikotoleranz verschiedene RTO- und RPO-Anforderungen. Hier siehst du, wie typische Zielwerte branchenweit variieren:
|
Branche |
Typisches RTO |
Typisches RPO |
Wesentliche Treiber |
|
Finanzdienstleistungen |
0–4 Stunden |
Minuten bis Sekunden |
Basel III, SEC-Regularien, Transaktionsintegrität, Umsatzwirkung |
|
Gesundheitswesen |
2–4 Stunden |
15 Minuten–1 Stunde |
HIPAA-Compliance, Patientensicherheit, lebenswichtige Systeme |
|
E-Commerce |
1–4 Stunden |
15–30 Minuten |
Direkte Umsatzeinbußen, Kund:innenvertrauen, Spitzenlasten |
|
Fertigung |
4–8 Stunden |
1–4 Stunden |
Lieferkettenabhängigkeiten, Produktionsnachweise, Just-in-Time-Modelle |
Institute der Finanzbranche haben aufgrund von Basel III und SEC-Vorgaben die strengsten Anforderungen. Börsenplattformen können RTOs von 15 Minuten und nahezu null RPOs haben, um Transaktionsverluste zu verhindern.
Ebenso kritisch balanciert das Gesundheitswesen Patientensicherheit und HIPAA-Compliance. Elektronische Gesundheitsakten erlauben im Notfall Papier-Workflows, ohne die Versorgung wesentlich zu beeinträchtigen.
E-Commerce-Plattformen spüren hingegen direkte Umsatzeinbußen bei Ausfällen. Onlinehändler, die 10.000 US-Dollar pro Minute umsetzen, müssen Ausfallzeiten minimieren – vor allem in Peak-Phasen.
Die Fertigung kämpft derweil mit physischen Lieferkettenabhängigkeiten. Manufacturing-Execution-Systeme müssen massive Bestandsstörungen verhindern und gleichzeitig Produktions- und Qualitätsdaten sichern.
Über alle Branchen hinweg prägen regulatorische Standards die Zielwerte stark. PCI DSS betrifft Kreditkartenverarbeiter. HIPAA verlangt Notfallplanung im Gesundheitswesen. FFIEC gibt Finanzinstituten Leitlinien. Frameworks wie das NIST Cybersecurity Framework und ISO 22301 bieten strukturierte Ansätze für Business Continuity, die RTO und RPO integrieren.
Recovery Time Objective und Recovery Point Objective sind grundlegende Kennzahlen der Notfallwiederherstellung. RTO definiert, wie schnell Systeme nach einer Störung wiederhergestellt sein müssen, RPO legt den akzeptablen Datenverlust fest. Zusammen übersetzen sie Business Continuity in konkrete, messbare Ziele – und verhindern große Katastrophen.
Strikte Planung zahlt sich weit über Compliance hinaus aus: Organisationen mit klar definierten, gründlich getesteten Zielwerten erholen sich schneller, haben geringere finanzielle Schäden und behalten das Vertrauen ihrer Kundschaft. Regelmäßige Tests decken Probleme auf, bevor sie kritisch werden.
Nutze RTO und RPO schließlich für die laufende Bewertung. Plane regelmäßige Reviews, führe aussagekräftige Tests durch, lerne aus jedem Test und prüfe ehrlich, ob die aktuellen Fähigkeiten zu den Zielen passen. Wer Krisen am besten übersteht, hat vorher am gründlichsten vorbereitet.
Wenn du mit praxisnahem Lernen auf der populärsten Cloud-Plattform starten willst, empfehle ich dir unseren Kurs AWS Concepts.
Relevante Kurse
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
