
Course
Database Design
4 hr
125.2K
Picture this: It's 2:00 a.m., and your company's database server has crashed. As your incident response team scrambles to restore operations, two questions dominate: "How quickly can we get back online?" and "How much data did we lose?" These questions represent the two most critical metrics in disaster recovery planning: Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
With the average cost of a data breach reaching $10.22 million, according to IBM, organizations must have robust disaster recovery strategies. In this tutorial, I'll walk you through the fundamentals of RTO and RPO, including calculation methods, implementation strategies, testing approaches, and industry applications.
If you are new to databases and cloud computing, I recommend taking one of our fundamental courses, especially Understanding Cloud Computing and Database Design.
Both metrics are crucial for business continuity planning and Data Security. They are key performance indicators that help organizations quantify risk tolerance, allocate resources, and make informed decisions about recovery infrastructure.
Recovery Time Objective (RTO) represents the maximum acceptable duration that a system can remain unavailable following a disruptive event. It answers: "How quickly must we restore operations?"
For instance, if your payment system has an RTO of two hours, you must restore full functionality within that timeframe.
On the other hand, Recovery Point Objective (RPO) defines the maximum acceptable data loss measured in time. It answers: "How much data can we afford to lose?"
If your database has an RPO of 15 minutes, backups must capture data at least every 15 minutes.
While both have a similar purpose, RTO and RPO measure fundamentally different recovery aspects. RTO is forward-looking, measuring time from disruption until recovery. RPO is backward-looking, measuring from disruption to the last acceptable recovery point.
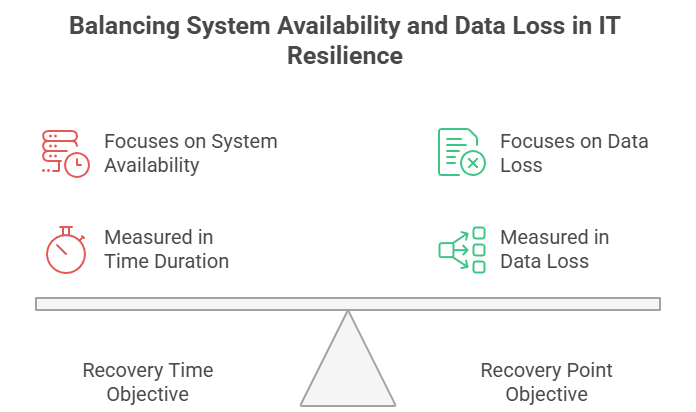
The nature of impact differs, too. RTO focuses on availability: missed targets mean extended downtime and lost productivity. RPO focuses on data integrity: missed targets result in permanent data loss with potential regulatory and financial consequences.
Infrastructure investments follow different patterns. Aggressive RTOs require high-availability systems and automated failover. Stringent RPOs demand continuous data protection and frequent backups, as well as sufficient storage capacity.
Important: Both metrics are independent. You might have an RTO of four hours with an RPO of one hour, or an RTO of 30 minutes with an RPO of six hours. It depends entirely on business requirements.
Here's a comparison table:
|
Aspect |
RTO |
RPO |
|
Temporal Direction |
Forward-looking |
Backward-looking |
|
Primary Focus |
System availability |
Data integrity |
|
Key Question |
"How quickly must we recover?" |
"How much data can we lose?" |
|
Infrastructure Priority |
Failover systems, redundancy |
Backup frequency, replication |
|
Independence |
Set independently of RPO |
Set independently of RTO |
Setting appropriate RTO and RPO targets requires a methodical approach that balances business needs and technical capabilities with cost constraints. The process begins with understanding your organization's unique risk profile and priorities.
The foundation of target-setting starts with a comprehensive Business Impact Analysis (BIA), which systematically evaluates how disruptions affect your organization.
Conducting a BIA involves interviewing stakeholders across every department to map business functions and the consequences of unavailability. This makes sure that recovery priorities reflect actual business impact rather than IT assumptions alone.
Service Level Agreements (SLAs) significantly influence target setting. If you've promised 99.9% uptime, your RTO must align with this commitment to avoid financial penalties and customer churn.
Disruptions affect organizations across four dimensions:
BIA outcomes guide prioritization and cost-effective resource allocation. Systems generating revenue, handling customer transactions, or satisfying regulatory requirements warrant aggressive targets. Supporting systems like employee directories can tolerate longer recovery times.
With BIA insights in hand, you're ready to translate business impact into quantitative targets.
Calculating RTO requires understanding business tolerance and technical capabilities. Begin by identifying the Maximum Tolerable Period of Disruption (MTPD), the absolute longest a process can be unavailable before causing irreversible damage. Set RTO lower than MTPD to provide a safety margin.
To calculate RTO, follow these steps:
Calculating RPO focuses on data characteristics:
A tiered approach provides a cost-effective strategy:
Avoid these common pitfalls:
With these calculations complete, you now have the concrete targets needed to guide your technology and process decisions.
The right implementation strategy and your technology choices can mean the difference between meeting your objectives and falling short when disaster strikes.
Let's explore the core technologies that enable recovery, starting with the foundational approaches and building up to more sophisticated solutions.
Backup and restore strategies form the disaster recovery foundation. Full backups create complete data copies but consume significant storage. Incremental backups capture only changes since the last backup. Differential backups capture changes since the last full backup.0
For aggressive RPO requirements, combine daily full backups with hourly incrementals.
Moving beyond traditional backups, replication, and continuous data protection maintains near-real-time copies.
Synchronous replication writes to both primary and secondary locations simultaneously, achieving near-zero RPO but introducing latency. In contrast, asynchronous replication writes to the primary first, then replicates with a small delay. Continuous Data Protection (CDP) captures every change, enabling point-in-time recovery.

Besides data protection mechanisms, disaster recovery sites match capabilities to RTO requirements.
Cold sites provide basic infrastructure but require days to weeks for activation. Warm sites include pre-installed hardware and daily/weekly synchronization to be able to activate within hours. Hot sites, on the other hand, maintain fully operational real-time replicas with minute-level failover for mission-critical applications.
Regardless of which recovery site approach you choose, automation and orchestration tools dramatically improve RTO and RPO.
Configuration management tools enable rapid server reconstruction. Similarly, disaster recovery orchestration platforms automate failover procedures. Meanwhile, runbook automation ensures consistent recovery during incidents.
Apart from traditional on-premises approaches, cloud technology has transformed disaster recovery. It offers capabilities that were once available only to enterprises with massive budgets.
Cloud-based disaster recovery services provide flexible, cost-effective alternatives to physical recovery sites. Disaster Recovery as a Service (DRaaS) from AWS, Azure, and Google Cloud eliminates separate physical infrastructure. For a comparison of the three most popular cloud providers, check out our AWS vs Azure vs GCP guide.
Furthermore, Infrastructure as Code (IaC) enables rapid recovery by defining the entire infrastructure in code. Tools like Terraform or AWS CloudFormation recreate complete environments in minutes, dramatically reducing RTO.
When choosing cloud solutions, consider the deployment model. Public cloud offers flexibility and low upfront costs with pay-as-you-go pricing. Alternatively, a private cloud provides greater control and may be necessary for compliance, especially in sensitive industries like finance or healthcare. Hybrid approaches combine on-premises and cloud resources for flexibility.
Finally, common cloud backup types include
Understanding the financial implications of RTO and RPO targets enables informed decision-making about recovery investments. Every organization faces the challenge of balancing protection against cost. Here's how to approach this critical trade-off.
The relationship between recovery objectives and costs follows predictable patterns, but optimizing this relationship requires strategic thinking.
An inverse relationship exists between RTO/RPO targets and costs. For example, achieving a 15-minute RTO costs exponentially more than a 24-hour RTO. Similarly, achieving a 15-minute RPO requires more frequent backups and storage than a 24-hour RPO. Near-zero recovery requires redundant systems, continuous replication, and automated failover.
However, tiered approaches optimize investment. Rather than applying aggressive targets to all systems, allocate resources based on criticality.
As an example, an e-commerce platform should invest heavily in hot-site replication to avoid a long downtime (minimal RTO), while using only daily cloud backups for internal wikis (medium RPO). Savings from reasonable targets on less-critical systems fund robust protection for mission-critical systems.
To put this into practice, balancing criticality, risk, and cost requires quantifying downtime costs, assessing disaster scenario likelihood, evaluating recovery approach costs, and identifying optimal balance points.
For example, suppose every hour of downtime costs your business $50,000 in lost revenue, and there is a 10% annual chance of a four-hour outage. The expected annual cost of that outage is 0.1 × 4 × $50,000 = $20,000.
If you invest $10,000 per year in better infrastructure and that reduces the outage to one hour, the expected annual cost of downtime becomes 0.1 × 1 × $50,000 = $5,000. Your total expected annual cost is now $5,000 (downtime) + $10,000 (investment) = $15,000, which is lower than the original $20,000. In this case, you not only secured your company’s reputation but also reduced expected cost.
Establishing RTO and RPO targets is only the beginning. Regular testing ensures you can actually meet them when disaster strikes. Without validation, your recovery objectives are just hopeful assumptions.
Testing comes in multiple forms, each offering different levels of validation and risk. I recommend a layered approach that progresses from low-risk exercises to comprehensive production tests.
Tabletop exercises provide discussion-based testing, walking through disaster scenarios to identify procedure gaps and unclear responsibilities. While valuable for planning validation, they don't test actual technical capabilities.
Beyond tabletop exercises, recovery simulations perform actual recovery operations in isolated test environments. They are restoring databases to separate servers or failing over non-critical applications. These validate backup systems and procedures without risking production systems.
However, full disaster recovery tests provide the highest confidence by conducting complete production failovers. These tests might involve shutting down your primary data center to verify recovery site operations. While disruptive, full DR tests are the only way to truly validate achievable RTO and RPO targets.
Regardless of the testing method used, Recovery Time Actual (RTA) and Recovery Point Actual (RPA) validation during tests reveals objective-reality gaps. If your RTO is four hours but recovery consistently takes six hours, you must improve capabilities or adjust the RTO.
Beyond testing events themselves, ongoing monitoring ensures objectives remain achievable. Track these key metrics:
Modern platforms provide dashboards surfacing these metrics for proactive issue identification.
Testing reveals gaps, but the real value comes from what you do with the results. This is where continuous improvement transforms disaster recovery from a static plan into a dynamic capability.
After each test, conduct structured debriefs covering what succeeded, what failed, root causes, and specific action items. Track these items formally with owners and completion deadlines.
Beyond post-test improvements, review RTO and RPO targets at least annually, or when significant changes occur in business processes, technology, regulations, or risk landscape. Reassess business impact, validate current capabilities, and identify changed requirements.
Moreover, changing threats require corresponding evolution. Ransomware has fundamentally changed RPO considerations. Traditional backups that overwrite previous versions can leave only encrypted data. Modern planning must account for immutable backups, longer retention, and clean recovery point identification.
Similarly, increased regulatory scrutiny affects both data recovery location and breach notification speed.
Different industries have varying RTO and RPO requirements based on their operational needs, regulatory environment, and risk tolerance. Here's how typical targets vary across sectors:
|
Industry |
Typical RTO |
Typical RPO |
Key Drivers |
|
Financial Services |
0-4 hours |
Minutes to seconds |
Basel III, SEC regulations, transaction integrity, revenue impact |
|
Healthcare |
2-4 hours |
15 minutes-1 hour |
HIPAA compliance, patient safety, life-critical systems |
|
E-commerce |
1-4 hours |
15-30 minutes |
Direct revenue loss, customer trust, peak period demands |
|
Manufacturing |
4-8 hours |
1-4 hours |
Supply chain dependencies, production records, just-in-time models |
Financial services institutions face the strictest requirements due to Basel III and SEC regulations. Stock trading platforms might have 15-minute RTOs and near-zero RPOs to prevent transaction loss.
Similarly critical, healthcare organizations balance patient safety with HIPAA compliance. Electronic health record systems allow emergency paper workflows while preventing significant care impact.
In contrast, e-commerce platforms face direct revenue impact during outages. Online retailers generating $10,000 per minute must minimize downtime, especially during peak periods.
Meanwhile, manufacturing operations contend with physical supply chain dependencies. Manufacturing execution systems must prevent massive inventory disruptions while maintaining production records and quality data.
Across all these industries, regulatory standards significantly influence targets. PCI DSS affects credit card processing organizations. HIPAA mandates healthcare contingency planning. FFIEC provides financial institution guidance. Frameworks like NIST Cybersecurity Framework and ISO 22301 provide structured business continuity approaches incorporating RTO and RPO.
Recovery Time Objective and Recovery Point Objective are foundational disaster recovery metrics. RTO defines how quickly you must recover systems after a disruption, while RPO determines acceptable data loss. Together, they translate business continuity into concrete, measurable targets to avoid big disasters.
The benefits of rigorous planning are huge beyond compliance: Organizations with well-defined, thoroughly tested targets recover faster from disruptions, experience lower financial impact, and maintain customer trust. Regular testing surfaces issues before they matter.
Ultimately, use RTO and RPO for ongoing evaluation. Schedule regular reviews, conduct meaningful tests, learn from each test, and maintain honest assessments of whether current capabilities meet stated targets. Organizations that best survive disasters have prepared most thoroughly beforehand.
If you want to get started with hands-on learning for the most popular cloud platform, I recommend taking our AWS Concepts course.
Relevant Courses
Course
Course
Course
blog
Benito Martin
12 min
blog
Flavio Matos
15 min
blog
Dario Radečić
15 min
blog
Vinita Silaparasetty
14 min
blog
Patrick Brus
11 min
Tutorial
Moez Ali