
Curso
Diseño de bases de datos
4 h
125.2K
Imagina esto: son las 2:00 a. m. y el servidor de bases de datos de tu empresa se ha caído. Mientras tu equipo de respuesta a incidentes se apresura para restablecer el servicio, dos preguntas lo acaparan todo: «¿Cuánto tardaremos en volver a estar en línea?» y «¿Cuántos datos hemos perdido?». Estas preguntas representan las dos métricas más críticas en la planificación de la recuperación ante desastres: Recovery Time Objective (RTO) y Recovery Point Objective (RPO).
Con un coste medio de violación de datos que alcanza los 10,22 millones de dólares, según IBM, las organizaciones necesitan estrategias de recuperación sólidas. En este tutorial, te guiaré por los fundamentos de RTO y RPO, incluidos métodos de cálculo, estrategias de implementación, enfoques de prueba y aplicaciones por industria.
Si eres nuevo en bases de datos y computación en la nube, te recomiendo empezar por alguno de nuestros cursos de fundamentos, en especial Understanding Cloud Computing y Database Design.
Ambas métricas son clave para la continuidad del negocio y la seguridad de los datos. Son indicadores que ayudan a cuantificar la tolerancia al riesgo, asignar recursos y tomar decisiones informadas sobre la infraestructura de recuperación.
Recovery Time Objective (RTO) representa el tiempo máximo aceptable que un sistema puede estar no disponible tras un evento disruptivo. Responde a: «¿Con qué rapidez debemos restaurar las operaciones?»
Por ejemplo, si tu sistema de pagos tiene un RTO de dos horas, debes recuperar la funcionalidad completa dentro de ese plazo.
Por su parte, Recovery Point Objective (RPO) define la pérdida máxima de datos aceptable medida en tiempo. Responde a: «¿Cuántos datos nos podemos permitir perder?»
Si tu base de datos tiene un RPO de 15 minutos, las copias de seguridad deben capturar datos al menos cada 15 minutos.
Aunque persiguen un objetivo similar, RTO y RPO miden aspectos de recuperación distintos. RTO mira hacia adelante: el tiempo desde la interrupción hasta la recuperación. RPO mira hacia atrás: el tiempo desde la interrupción hasta el último punto de recuperación aceptable.
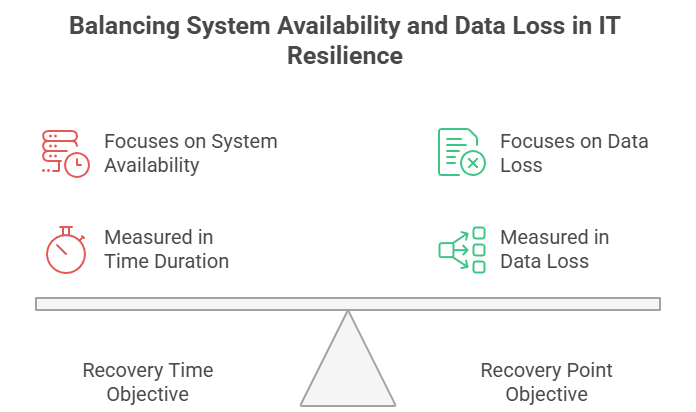
También difiere la naturaleza del impacto. RTO se centra en la disponibilidad: incumplir los objetivos implica más tiempo de inactividad y pérdida de productividad. RPO se centra en la integridad de los datos: incumplirlo provoca pérdida permanente de datos con posibles consecuencias regulatorias y financieras.
Las inversiones en infraestructura siguen patrones diferentes. RTO agresivos requieren sistemas de alta disponibilidad y conmutación por error automatizada. RPO estrictos exigen protección continua de datos y copias frecuentes, además de capacidad de almacenamiento suficiente.
Importante: ambas métricas son independientes. Puedes tener un RTO de cuatro horas con un RPO de una hora, o un RTO de 30 minutos con un RPO de seis horas. Depende por completo de los requisitos del negocio.
Aquí tienes una tabla comparativa:
|
Aspecto |
RTO |
RPO |
|
Dirección temporal |
Hacia adelante |
Hacia atrás |
|
Enfoque principal |
Disponibilidad del sistema |
Integridad de los datos |
|
Pregunta clave |
«¿Con qué rapidez debemos recuperarnos?» |
«¿Cuántos datos podemos perder?» |
|
Prioridad de infraestructura |
Sistemas de conmutación por error, redundancia |
Frecuencia de copias, replicación |
|
Independencia |
Se define independientemente de RPO |
Se define independientemente de RTO |
Fijar objetivos adecuados de RTO y RPO exige un enfoque metódico que equilibre necesidades del negocio y capacidades técnicas con las restricciones de coste. El proceso empieza por entender el perfil de riesgo y las prioridades de tu organización.
La base para definir objetivos es un Business Impact Analysis (BIA) completo, que evalúa de forma sistemática cómo afectan las interrupciones a tu organización.
Realizar un BIA implica entrevistar a personas clave de todos los departamentos para mapear funciones de negocio y consecuencias de la indisponibilidad. Así te aseguras de que las prioridades de recuperación reflejan el impacto real en el negocio y no solo suposiciones de TI.
Los Service Level Agreements (SLA) influyen directamente en la definición de objetivos. Si has prometido un 99,9% de disponibilidad, tu RTO debe alinearse con ese compromiso para evitar penalizaciones y la fuga de clientes.
Las interrupciones impactan a las organizaciones en cuatro dimensiones:
Los resultados del BIA guían la priorización y la asignación eficiente de recursos. Sistemas que generan ingresos, gestionan transacciones o cumplen requisitos regulatorios requieren objetivos agresivos. Sistemas de soporte, como directorios de empleados, pueden tolerar tiempos de recuperación mayores.
Con el BIA en la mano, ya puedes traducir el impacto de negocio en objetivos cuantitativos.
Calcular el RTO exige comprender la tolerancia del negocio y las capacidades técnicas. Empieza identificando el Maximum Tolerable Period of Disruption (MTPD), el tiempo máximo absoluto que un proceso puede estar inactivo antes de causar un daño irreversible. Fija un RTO inferior al MTPD para dejar margen de seguridad.
Para calcular el RTO, sigue estos pasos:
El cálculo del RPO se centra en las características de los datos:
Un enfoque por niveles es una estrategia rentable:
Evita estos errores habituales:
Con estos cálculos, ya tienes objetivos concretos para guiar tus decisiones tecnológicas y de procesos.
La estrategia adecuada y las tecnologías elegidas pueden marcar la diferencia entre cumplir tus objetivos o quedarte corto cuando llegue el desastre.
Vamos a ver las tecnologías clave que habilitan la recuperación, empezando por los enfoques básicos y llegando a soluciones más avanzadas.
Las estrategias de backup y restauración son la base de la recuperación ante desastres. Las copias completas generan duplicados íntegros de los datos, pero consumen mucho almacenamiento. Las incrementales capturan solo los cambios desde la última copia. Las diferenciales capturan los cambios desde la última copia completa.
Para RPO exigentes, combina copias completas diarias con incrementales por hora.
Más allá del backup tradicional, la replicación y la protección continua de datos mantienen copias casi en tiempo real.
La replicación síncrona escribe en la ubicación primaria y secundaria a la vez, logrando un RPO casi nulo pero introduciendo latencia. En cambio, la replicación asíncrona escribe primero en el primario y replica con un pequeño retraso. La Continuous Data Protection (CDP) captura cada cambio y permite recuperar a puntos específicos en el tiempo.

Además de los mecanismos de protección de datos, los sitios de recuperación se ajustan a los requisitos de RTO.
Los sitios fríos ofrecen la infraestructura básica, pero requieren días o semanas para activarse. Los sitios templados incluyen hardware preinstalado y sincronización diaria/semanal para activarse en horas. Los sitios calientes mantienen réplicas operativas en tiempo real con conmutación por error en minutos para aplicaciones críticas.
Elijas el enfoque que elijas, las herramientas de automatización y orquestación mejoran drásticamente RTO y RPO.
Las herramientas de gestión de configuración permiten reconstruir servidores rápidamente. Del mismo modo, las plataformas de orquestación de recuperación automatizan la conmutación por error. Y la automatización de runbooks garantiza recuperaciones consistentes durante incidentes.
Más allá de los enfoques on‑prem tradicionales, la nube ha transformado la recuperación ante desastres. Ofrece capacidades antes reservadas a empresas con grandes presupuestos.
Los servicios de recuperación ante desastres en la nube son alternativas flexibles y rentables a los sitios físicos. Disaster Recovery as a Service (DRaaS) de AWS, Azure y Google Cloud elimina la necesidad de infraestructura física separada. Para comparar los tres proveedores más populares, consulta nuestra guía AWS vs Azure vs GCP.
Además, Infrastructure as Code (IaC) acelera la recuperación al definir toda la infraestructura como código. Herramientas como Terraform o AWS CloudFormation recrean entornos completos en minutos, reduciendo drásticamente el RTO.
Al elegir soluciones cloud, considera el modelo de despliegue. La nube pública ofrece flexibilidad y bajos costes iniciales con pago por uso. La nube privada, en cambio, aporta mayor control y puede ser necesaria para el cumplimiento, especialmente en sectores sensibles como finanzas o salud. Los enfoques híbridos combinan recursos on‑prem y en la nube para mayor flexibilidad.
Por último, los tipos de backup en la nube más comunes incluyen
Comprender las implicaciones financieras de los objetivos de RTO y RPO te permite tomar decisiones informadas sobre inversiones en recuperación. Todas las organizaciones deben equilibrar protección y coste. Así puedes abordar este equilibrio crítico.
La relación entre objetivos de recuperación y costes sigue patrones previsibles, pero optimizarla requiere visión estratégica.
Existe una relación inversa entre los objetivos de RTO/RPO y los costes. Por ejemplo, lograr un RTO de 15 minutos cuesta exponencialmente más que un RTO de 24 horas. Del mismo modo, un RPO de 15 minutos exige copias más frecuentes y más almacenamiento que un RPO de 24 horas. La recuperación casi en cero requiere sistemas redundantes, replicación continua y conmutación por error automatizada.
Sin embargo, los enfoques por niveles optimizan la inversión. En lugar de aplicar objetivos agresivos a todos los sistemas, asigna recursos según la criticidad.
Por ejemplo, una plataforma de e‑commerce debería invertir mucho en replicación en sitio caliente para evitar largos tiempos de inactividad (RTO mínimo), mientras que podría usar solo copias diarias en la nube para wikis internas (RPO medio). El ahorro en sistemas menos críticos financia una protección robusta para los críticos.
Para llevarlo a la práctica, equilibrar criticidad, riesgo y coste requiere cuantificar el coste del downtime, estimar la probabilidad de escenarios de desastre, evaluar los costes de las opciones de recuperación e identificar puntos óptimos de equilibrio.
Por ejemplo, supón que cada hora de inactividad cuesta a tu negocio 50.000 $ en ingresos perdidos y que hay un 10% de probabilidad anual de una parada de cuatro horas. El coste anual esperado de ese incidente es 0,1 × 4 × 50.000 $ = 20.000 $.
Si inviertes 10.000 $ al año en mejor infraestructura y reduces la parada a una hora, el coste anual esperado del downtime pasa a ser 0,1 × 1 × 50.000 $ = 5.000 $. Tu coste anual total esperado será ahora 5.000 $ (inactividad) + 10.000 $ (inversión) = 15.000 $, menor que los 20.000 $ iniciales. En este caso, no solo proteges la reputación de tu empresa, sino que también reduces el coste esperado.
Definir objetivos de RTO y RPO es solo el principio. Las pruebas periódicas garantizan que realmente podrás cumplirlos cuando ocurra un desastre. Sin validación, tus objetivos son meras suposiciones.
Las pruebas adoptan múltiples formas, con distintos niveles de validación y riesgo. Te recomiendo un enfoque por capas que avance desde ejercicios de bajo riesgo hasta pruebas completas en producción.
Los ejercicios de mesa son pruebas basadas en discusión: se recorren escenarios de desastre para identificar lagunas de procedimiento y responsabilidades difusas. Aunque útiles para validar la planificación, no prueban las capacidades técnicas reales.
Más allá de los ejercicios de mesa, las simulaciones ejecutan operaciones reales de recuperación en entornos aislados de prueba. Por ejemplo, restaurar bases de datos en servidores separados o conmutar por error aplicaciones no críticas. Validan sistemas y procedimientos de backup sin arriesgar producción.
Las pruebas completas de recuperación aportan la mayor confianza al realizar conmutaciones por error de producción de extremo a extremo. Pueden implicar apagar tu centro de datos principal para verificar el funcionamiento del sitio de recuperación. Aunque son disruptivas, son la única forma de validar de verdad los objetivos de RTO y RPO.
Independientemente del método, medir el Recovery Time Actual (RTA) y el Recovery Point Actual (RPA) durante las pruebas revela brechas con la realidad. Si tu RTO es de cuatro horas pero la recuperación tarda seis, debes mejorar capacidades o ajustar el RTO.
Más allá de los propios eventos de prueba, la monitorización continua garantiza que los objetivos sigan siendo alcanzables. Controla estas métricas clave:
Las plataformas modernas ofrecen paneles con estas métricas para detectar problemas de forma proactiva.
Las pruebas revelan brechas, pero el valor real está en lo que haces con los resultados. Aquí es donde la mejora continua convierte la recuperación ante desastres de un plan estático en una capacidad dinámica.
Después de cada prueba, realiza sesiones estructuradas para revisar qué funcionó, qué falló, causas raíz y acciones concretas. Haz seguimiento formal con responsables y fechas de cierre.
Además de las mejoras posteriores a las pruebas, revisa los objetivos de RTO y RPO al menos una vez al año o cuando haya cambios significativos en procesos, tecnología, normativa o el panorama de riesgos. Reevalúa el impacto, valida capacidades actuales e identifica nuevos requisitos.
Asimismo, las amenazas cambian y los planes deben evolucionar. El ransomware ha cambiado de raíz las consideraciones de RPO. Los backups tradicionales que sobrescriben versiones anteriores pueden dejar solo datos cifrados. La planificación moderna debe contemplar copias inmutables, mayor retención e identificación de puntos de recuperación limpios.
Del mismo modo, el creciente escrutinio regulatorio afecta tanto a la ubicación de la recuperación de datos como a la rapidez de notificación de brechas.
Cada industria tiene requisitos distintos de RTO y RPO según sus operaciones, regulación y tolerancia al riesgo. A continuación verás cómo suelen variar los objetivos por sector:
|
Industria |
RTO típico |
RPO típico |
Impulsores clave |
|
Servicios financieros |
0-4 horas |
Minutos a segundos |
Basilea III, normativas de la SEC, integridad de transacciones, impacto en ingresos |
|
Sanidad |
2-4 horas |
15 minutos-1 hora |
Cumplimiento de HIPAA, seguridad del paciente, sistemas críticos para la vida |
|
E‑commerce |
1-4 horas |
15-30 minutos |
Pérdida directa de ingresos, confianza del cliente, picos de demanda |
|
Manufactura |
4-8 horas |
1-4 horas |
Dependencias de la cadena de suministro, registros de producción, modelos just‑in‑time |
Las entidades de servicios financieros afrontan los requisitos más estrictos por Basilea III y la SEC. Las plataformas de trading pueden tener RTO de 15 minutos y RPO casi nulo para evitar pérdida de transacciones.
De forma similar, las organizaciones sanitarias equilibran la seguridad del paciente con el cumplimiento de HIPAA. Los historiales clínicos electrónicos permiten flujos de trabajo en papel en emergencias sin afectar gravemente a la atención.
En cambio, las plataformas de e‑commerce sufren impacto directo en ingresos durante caídas. Minoristas que generan 10.000 $ por minuto deben minimizar el downtime, especialmente en picos.
Mientras tanto, las operaciones de manufactura lidian con dependencias físicas de la cadena de suministro. Los sistemas de ejecución de manufactura deben evitar grandes disrupciones de inventario y mantener registros y datos de calidad.
En todos estos sectores, las normativas influyen notablemente en los objetivos. PCI DSS afecta a organizaciones que procesan tarjetas. HIPAA exige planes de contingencia en sanidad. FFIEC orienta a instituciones financieras. Marcos como NIST Cybersecurity Framework e ISO 22301 aportan enfoques estructurados de continuidad que incorporan RTO y RPO.
Recovery Time Objective y Recovery Point Objective son métricas fundamentales de recuperación ante desastres. RTO define cuán rápido debes recuperar los sistemas tras una interrupción, mientras que RPO determina la pérdida de datos aceptable. Juntas, traducen la continuidad del negocio en objetivos concretos y medibles para evitar grandes desastres.
Los beneficios de una planificación rigurosa van más allá del cumplimiento: las organizaciones con objetivos bien definidos y probados se recuperan más rápido, sufren menos impacto financiero y mantienen la confianza del cliente. Las pruebas periódicas sacan a la luz problemas antes de que importen.
En última instancia, usa RTO y RPO para la evaluación continua. Programa revisiones periódicas, realiza pruebas con sentido, aprende de cada una y mantén una evaluación honesta de si tus capacidades actuales cumplen los objetivos. Las organizaciones que mejor sobreviven a los desastres son las que más se han preparado de antemano.
Si quieres empezar a aprender de forma práctica en la plataforma cloud más popular, te recomiendo nuestro curso AWS Concepts.
Cursos relacionados
Curso
Curso
Curso
blog
Vinita Silaparasetty
14 min
blog
Elena Kosourova
14 min
blog
Abid Ali Awan
15 min
blog
Mike Shakhomirov
11 min
Tutorial
Łukasz Deryło
Tutorial
Arunn Thevapalan

