
Cours
Conception de bases de données
4 h
125.3K
Imaginez : il est 2 h du matin et le serveur de base de données de votre entreprise vient de tomber. Tandis que votre équipe de réponse à incident s’active pour relancer l’activité, deux questions s’imposent : « À quelle vitesse pouvons-nous revenir en ligne ? » et « Combien de données avons-nous perdu ? » Ces questions renvoient aux deux indicateurs les plus cruciaux de la reprise après sinistre : le Recovery Time Objective (RTO) et le Recovery Point Objective (RPO).
Avec un coût moyen d’une fuite de données qui atteint 10,22 millions $, selon IBM, les organisations doivent disposer de stratégies solides de reprise après sinistre. Dans ce tutoriel, je vous présente les fondamentaux du RTO et du RPO : méthodes de calcul, stratégies de mise en œuvre, approches de test et cas d’usage sectoriels.
Si vous débutez avec les bases de données et le cloud, je vous recommande nos cours d’introduction, notamment Understanding Cloud Computing et Database Design.
Ces deux indicateurs sont essentiels pour la continuité d’activité et la sécurité des données. Ce sont des KPI qui aident les organisations à quantifier leur tolérance au risque, allouer les ressources et prendre des décisions éclairées sur l’infrastructure de reprise.
Le Recovery Time Objective (RTO) représente la durée maximale acceptable pendant laquelle un système peut rester indisponible après un incident. Il répond à la question : « À quelle vitesse devons-nous restaurer les opérations ? »
Par exemple, si votre système de paiement a un RTO de deux heures, vous devez en restaurer la pleine fonctionnalité dans ce délai.
Le Recovery Point Objective (RPO) définit, quant à lui, la perte de données maximale acceptable, mesurée en temps. Il répond à la question : « Combien de données pouvons-nous nous permettre de perdre ? »
Si votre base de données a un RPO de 15 minutes, les sauvegardes doivent capturer les données au moins toutes les 15 minutes.
Bien que poursuivant un objectif similaire, le RTO et le RPO mesurent des dimensions de reprise différentes. Le RTO est prospectif : il mesure le temps entre la perturbation et le retour à la normale. Le RPO est rétrospectif : il mesure l’écart entre la perturbation et le dernier point de reprise acceptable.
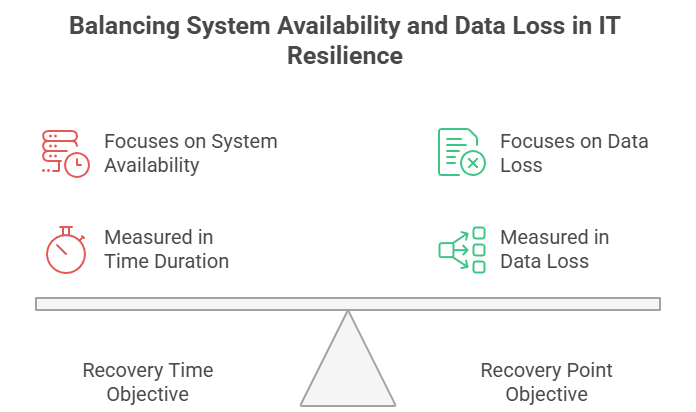
La nature de l’impact diffère également. Le RTO se concentre sur la disponibilité : un objectif manqué signifie plus de temps d’arrêt et une productivité en baisse. Le RPO porte sur l’intégrité des données : un objectif non tenu entraîne une perte de données irréversible, avec des conséquences réglementaires et financières potentielles.
Les investissements d’infrastructure suivent des logiques différentes. Des RTO ambitieux exigent des systèmes hautement disponibles et un basculement automatique. Des RPO stricts nécessitent une protection continue des données, des sauvegardes fréquentes et une capacité de stockage suffisante.
Important : ces deux indicateurs sont indépendants. Vous pouvez avoir un RTO de 4 heures avec un RPO d’1 heure, ou un RTO de 30 minutes avec un RPO de 6 heures. Tout dépend des besoins métiers.
Voici un tableau comparatif :
|
Aspect |
RTO |
RPO |
|
Orientation temporelle |
Prospective |
Rétrospective |
|
Focus principal |
Disponibilité des systèmes |
Intégrité des données |
|
Question clé |
"À quelle vitesse devons-nous récupérer ?" |
"Quelle quantité de données pouvons-nous perdre ?" |
|
Priorité d’infrastructure |
Systèmes de basculement, redondance |
Fréquence des sauvegardes, réplication |
|
Indépendance |
Défini indépendamment du RPO |
Défini indépendamment du RTO |
Fixer des objectifs RTO et RPO pertinents suppose une démarche méthodique, à l’équilibre entre besoins métiers, capacités techniques et contraintes budgétaires. Le processus commence par la compréhension du profil de risque et des priorités propres à votre organisation.
La base de la définition des objectifs est une Business Impact Analysis (BIA) exhaustive, qui évalue systématiquement l’impact des perturbations sur votre organisation.
Mener une BIA implique d’interviewer des parties prenantes dans chaque service pour cartographier les fonctions métiers et les conséquences de l’indisponibilité. Vous vous assurez ainsi que les priorités de reprise reflètent l’impact business réel, et pas seulement des hypothèses IT.
Les Service Level Agreements (SLA) influencent fortement la définition des objectifs. Si vous vous engagez sur 99,9 % de disponibilité, votre RTO doit être aligné sur cet engagement pour éviter pénalités financières et attrition client.
Les perturbations affectent les organisations selon quatre dimensions :
Les résultats de la BIA guident la prioritisation et une allocation des ressources au meilleur coût. Les systèmes générateurs de revenus, gérant les transactions clients ou liés à la conformité justifient des objectifs ambitieux. Des systèmes de support comme les annuaires internes tolèrent des délais de reprise plus longs.
Avec les enseignements de la BIA, vous pouvez traduire l’impact métier en objectifs quantitatifs.
Le calcul du RTO exige de comprendre la tolérance métier et les capacités techniques. Commencez par identifier la période maximale de perturbation tolérable (MTPD), c’est-à-dire la durée au-delà de laquelle un processus subit des dommages irréversibles. Fixez un RTO inférieur à la MTPD pour conserver une marge de sécurité.
Pour calculer le RTO, suivez ces étapes :
Le calcul du RPO se concentre sur les caractéristiques des données :
Une approche par niveaux permet d’optimiser les coûts :
Erreurs fréquentes à éviter :
Avec ces calculs, vous disposez d’objectifs concrets pour guider vos choix technologiques et vos processus.
La stratégie de mise en œuvre et vos choix technologiques font la différence entre atteindre vos objectifs ou les manquer le jour J.
Passons en revue les technologies clés de la reprise, des approches fondamentales aux solutions les plus avancées.
Les stratégies de sauvegarde et de restauration constituent le socle de la reprise. Les sauvegardes complètes créent des copies intégrales mais consomment beaucoup de stockage. Les sauvegardes incrémentielles ne capturent que les changements depuis la dernière sauvegarde. Les sauvegardes différentielles capturent les changements depuis la dernière sauvegarde complète.
Pour des exigences de RPO très serrées, combinez des sauvegardes complètes quotidiennes et des incrémentales horaires.
Au-delà des sauvegardes traditionnelles, la réplication et la protection continue des données maintiennent des copies quasi temps réel.
La réplication synchrone écrit simultanément sur les sites primaire et secondaire, offrant un RPO quasi nul mais au prix d’une latence accrue. À l’inverse, la réplication asynchrone écrit d’abord sur le primaire, puis réplique avec un léger décalage. La Continuous Data Protection (CDP) capture chaque changement et permet une restauration à un point dans le temps.

Au-delà des mécanismes de protection des données, les sites de reprise s’adaptent aux objectifs de RTO.
Les cold sites offrent l’infrastructure de base mais nécessitent des jours voire des semaines pour être opérationnels. Les warm sites disposent de matériels préinstallés et d’une synchronisation quotidienne/hebdomadaire pour une activation en quelques heures. Les hot sites, eux, maintiennent des réplicas temps réel pleinement opérationnels avec un basculement en quelques minutes pour les applications critiques.
Quel que soit le type de site choisi, l’automatisation et l’orchestration améliorent fortement RTO et RPO.
Les outils de gestion de configuration permettent de reconstruire rapidement des serveurs. Les plateformes d’orchestration de PRA automatisent les procédures de basculement. Les runbooks automatisés garantissent une exécution homogène en incident.
Au-delà des approches on-premises, le cloud a transformé la reprise après sinistre, en offrant des capacités autrefois réservées aux grandes entreprises.
Les services de reprise sur le cloud proposent des alternatives flexibles et économiques aux sites physiques. Le Disaster Recovery as a Service (DRaaS) d’AWS, d’Azure et de Google Cloud supprime le besoin d’infrastructures physiques distinctes. Pour comparer les trois principaux fournisseurs cloud, consultez notre guide AWS vs Azure vs GCP.
Par ailleurs, l’Infrastructure as Code (IaC) accélère la reprise en définissant toute l’infrastructure sous forme de code. Des outils comme Terraform ou AWS CloudFormation recréent des environnements complets en quelques minutes, réduisant fortement le RTO.
Lors du choix de solutions cloud, considérez le modèle de déploiement. Le cloud public offre flexibilité et faibles coûts initiaux avec une tarification à l’usage. À l’inverse, un cloud privé apporte plus de contrôle et peut être nécessaire pour la conformité, notamment dans la finance ou la santé. Les approches hybrides combinent ressources on-premises et cloud pour plus de flexibilité.
Enfin, les principaux types de sauvegardes cloud incluent :
Comprendre l’impact financier des objectifs RTO et RPO aide à orienter les investissements de reprise. Chaque organisation doit arbitrer entre niveau de protection et coûts. Voici comment aborder ce compromis clé.
La relation entre objectifs de reprise et coûts suit des tendances prévisibles, mais l’optimiser suppose une approche stratégique.
Il existe une relation inverse entre le niveau des objectifs RTO/RPO et les coûts. Par exemple, atteindre un RTO de 15 minutes coûte exponentiellement plus cher qu’un RTO de 24 heures. De même, un RPO de 15 minutes exige des sauvegardes plus fréquentes et plus de stockage qu’un RPO de 24 heures. Une reprise quasi instantanée suppose des systèmes redondants, une réplication continue et un basculement automatisé.
En revanche, une approche par niveaux optimise l’investissement. Plutôt que d’appliquer des objectifs agressifs partout, allouez les ressources selon la criticité.
Par exemple, une plateforme e-commerce investira fortement dans un hot site répliqué pour éviter un long arrêt (RTO minimal), tout en se contentant de sauvegardes cloud quotidiennes pour ses wikis internes (RPO moyen). Les économies réalisées sur les systèmes moins critiques financent une protection robuste pour les systèmes vitaux.
Concrètement, équilibrer criticité, risque et coût demande de quantifier le coût du temps d’arrêt, d’évaluer la probabilité des scénarios de sinistre, d’estimer les coûts des approches de reprise et d’identifier les points d’équilibre optimaux.
Par exemple, si chaque heure d’arrêt coûte 50 000 $ à votre entreprise, avec 10 % de probabilité annuelle d’une panne de 4 heures, le coût annuel attendu est de 0,1 × 4 × 50 000 $ = 20 000 $.
Si vous investissez 10 000 $ par an dans une meilleure infrastructure et que cela réduit la panne à 1 heure, le coût annuel attendu du temps d’arrêt devient 0,1 × 1 × 50 000 $ = 5 000 $. Votre coût annuel total est alors de 5 000 $ (arrêt) + 10 000 $ (investissement) = 15 000 $, inférieur aux 20 000 $ initiaux. Vous protégez ainsi la réputation de votre entreprise tout en réduisant le coût attendu.
Définir des objectifs RTO et RPO n’est qu’un début. Des tests réguliers vérifient que vous pouvez effectivement les atteindre en cas de crise. Sans validation, vos objectifs de reprise restent des hypothèses optimistes.
Plusieurs formes de tests existent, avec des niveaux de validation et de risque différents. Je recommande une approche progressive, des exercices peu risqués jusqu’aux tests complets en production.
Les exercices sur table sont des tests basés sur la discussion : on passe en revue des scénarios de sinistre pour identifier les lacunes de procédure et les responsabilités floues. Utiles pour valider la planification, ils ne testent toutefois pas les capacités techniques réelles.
Au-delà des exercices sur table, les simulations de reprise réalisent de vraies opérations de récupération en environnement isolé : restauration de bases de données sur des serveurs distincts, basculement d’applications non critiques, etc. Elles valident systèmes de sauvegarde et procédures sans risquer la production.
Les tests de reprise complets apportent la plus grande confiance en effectuant un basculement total de la production. Ils peuvent impliquer la mise à l’arrêt du datacenter principal pour vérifier le fonctionnement du site de secours. Bien que perturbants, ce sont les seuls à vraiment valider vos objectifs RTO et RPO.
Quelle que soit la méthode, la mesure du Recovery Time Actual (RTA) et du Recovery Point Actual (RPA) pendant les tests met en lumière l’écart avec la réalité. Si votre RTO est de 4 heures mais que la reprise prend systématiquement 6 heures, vous devez améliorer vos capacités ou revoir le RTO.
Au-delà des tests eux-mêmes, une supervision continue garantit la tenue des objectifs. Suivez ces indicateurs :
Les plateformes modernes proposent des tableaux de bord pour détecter proactivement les problèmes.
Les tests révèlent des lacunes, mais la valeur naît de l’exploitation des résultats. C’est là que l’amélioration continue transforme la reprise après sinistre d’un plan statique en une capacité vivante.
Après chaque test, organisez des debriefings structurés : succès, échecs, causes racines, actions correctives. Suivez ces actions avec des responsables et des échéances définis.
Au-delà des améliorations post-test, revoyez vos objectifs RTO et RPO au moins une fois par an, ou lors de changements majeurs des processus métiers, technologies, réglementations ou panorama des risques. Réévaluez l’impact métier, validez les capacités actuelles et identifiez les nouvelles exigences.
Par ailleurs, l’évolution des menaces impose d’adapter vos plans. Les ransomwares ont bouleversé les considérations de RPO. Des sauvegardes traditionnelles qui écrasent les versions précédentes peuvent ne laisser que des données chiffrées. Une planification moderne doit prévoir des sauvegardes immuables, des rétentions plus longues et l’identification de points de reprise sains.
De même, le renforcement de la réglementation impacte à la fois l’emplacement de reprise des données et la rapidité de notification en cas de violation.
Chaque secteur a des exigences RTO et RPO différentes selon ses besoins opérationnels, ses contraintes réglementaires et sa tolérance au risque. Voici comment les objectifs typiques varient selon les secteurs :
|
Secteur |
RTO typique |
RPO typique |
Facteurs clés |
|
Services financiers |
0–4 heures |
Minutes à secondes |
Bâle III, réglementations SEC, intégrité des transactions, impact sur les revenus |
|
Santé |
2–4 heures |
15 minutes–1 heure |
Conformité HIPAA, sécurité des patients, systèmes vitaux |
|
E-commerce |
1–4 heures |
15–30 minutes |
Perte de revenus directe, confiance client, pics d’activité |
|
Industrie manufacturière |
4–8 heures |
1–4 heures |
Dépendances supply chain, historiques de production, flux tendus |
Les institutions de services financiers font face aux exigences les plus strictes du fait de Bâle III et des réglementations de la SEC. Les plateformes de trading peuvent viser un RTO de 15 minutes et un RPO quasi nul pour éviter toute perte de transaction.
Tout aussi critiques, les organisations de santé arbitrent entre sécurité des patients et conformité HIPAA. Les dossiers médicaux électroniques permettent des workflows papier d’urgence tout en évitant un impact majeur sur les soins.
A contrario, les plateformes e-commerce subissent immédiatement l’impact sur les revenus en cas d’arrêt. Des e-commerçants générant 10 000 $ par minute doivent minimiser le downtime, surtout en période de pic.
De leur côté, les sites industriels gèrent des dépendances physiques de chaîne logistique. Les systèmes d’exécution de fabrication doivent éviter les perturbations massives des stocks tout en conservant historiques de production et données qualité.
Dans tous ces secteurs, les exigences réglementaires influencent fortement les objectifs. PCI DSS touche les organismes de traitement des cartes. HIPAA impose une planification de contingence en santé. Le FFIEC émet des recommandations pour les institutions financières. Des cadres comme le NIST Cybersecurity Framework et l’ISO 22301 proposent des approches structurées de continuité intégrant RTO et RPO.
Le Recovery Time Objective et le Recovery Point Objective sont des indicateurs fondamentaux de la reprise après sinistre. Le RTO définit la vitesse de restauration des systèmes après une perturbation, tandis que le RPO détermine la perte de données acceptable. Ensemble, ils traduisent la continuité d’activité en objectifs concrets et mesurables pour éviter les grosses catastrophes.
Au-delà de la conformité, les bénéfices d’une planification rigoureuse sont majeurs : les organisations avec des objectifs bien définis et testés régulièrement se relèvent plus vite, subissent moins d’impact financier et conservent la confiance de leurs clients. Les tests réguliers permettent d’anticiper les problèmes.
En définitive, servez-vous du RTO et du RPO pour une évaluation continue : prévoyez des revues périodiques, menez des tests pertinents, capitalisez sur chaque enseignement et évaluez honnêtement si vos capacités actuelles tiennent vos objectifs. Les organisations qui surmontent le mieux les crises sont celles qui se sont le mieux préparées.
Pour vous lancer dans une mise en pratique sur la plateforme cloud la plus populaire, je vous recommande notre cours AWS Concepts.
Cours recommandés
Cours
Cours
Cours
blog
Lynn Heidmann
blog
Kurtis Pykes
15 min
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
9 min
Tutoriel
Samuel Shaibu

