Wat is ETL?
ETL is een gangbare aanpak voor het integreren van data en het organiseren van datastacks. Een typisch ETL-proces bestaat uit de volgende stappen:
- Extractie van data uit bronnen
- Transformatie van data naar datamodellen
- Laden van data in datawarehouses
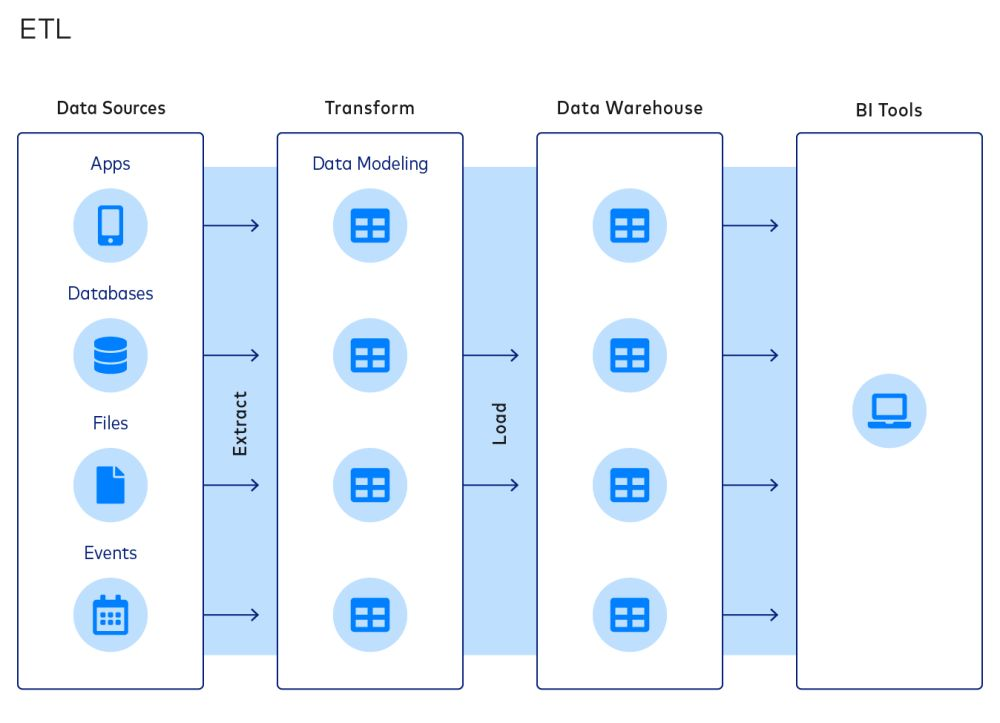
Het ETL-paradigma is populair omdat het bedrijven in staat stelt de omvang van hun datawarehouses te verkleinen, wat kan besparen op rekenkracht, opslag en bandbreedte.
Deze kostenbesparingen worden echter minder belangrijk nu deze beperkingen verdwijnen. Daardoor wordt ELT (Extract, Load, Transform) populairder. In het ELT-proces wordt data na extractie naar een bestemming geladen en is transformatie de laatste stap. Desondanks vertrouwen veel bedrijven nog steeds op ETL.
Wat zijn ETL-tools?
Zoals de naam al doet vermoeden, is een ETL-tool een set softwaretools die worden gebruikt om data te extracten, te transformeren en te laden van één of meer bronnen naar een doelsysteem of -database. ETL-tools zijn ontworpen om het proces van het extraheren van data uit verschillende bronnen te automatiseren en te vereenvoudigen, deze om te zetten naar een consistent en schoon formaat, en ze tijdig en efficiënt in het doelsysteem te laden. In de volgende sectie bekijken we de belangrijkste overwegingen die datateams moeten meenemen bij het kiezen van een ETL-tool.
Overwegingen bij het kiezen van een ETL-tool
Hier zijn drie belangrijke overwegingen om rekening mee te houden bij het selecteren van een ETL-tool:
- De mate van dataintegratie. ETL-tools kunnen verbinden met uiteenlopende databronnen en bestemmingen. Datateams zouden moeten kiezen voor ETL-tools die een breed scala aan integraties bieden. Teams die bijvoorbeeld data van Google Sheets naar Amazon Redshift willen verplaatsen, moeten ETL-tools selecteren die dergelijke connectors ondersteunen.
- Niveau van aanpasbaarheid. Bedrijven moeten hun ETL-tools kiezen op basis van hun behoefte aan maatwerk en de technische expertise van het IT-team. Een start-up vindt de ingebouwde connectors en transformaties in de meeste ETL-tools wellicht voldoende; een grote onderneming met maatwerkdataverzameling heeft waarschijnlijk de flexibiliteit nodig om eigen transformaties te bouwen met hulp van een sterk team van engineers.
- Kostenstructuur. Bij het kiezen van een ETL-tool moeten organisaties niet alleen kijken naar de kosten van de tool zelf, maar ook naar de kosten van infrastructuur en personele inzet om de oplossing op de lange termijn te onderhouden. In sommige gevallen kan een ETL-tool met hogere initiële kosten maar minder uitval en minder onderhoud op de lange termijn kostenefficiënter zijn. Omgekeerd kunnen gratis, open-source ETL-tools hoge onderhoudskosten hebben.
Andere overwegingen zijn onder meer:
- Het niveau van automatisering
- Het niveau van beveiliging en compliance
- De prestaties en betrouwbaarheid van de tool.
Types ETL-tools
Voordat we in specifieke tools duiken, helpt het om de hoofdcategorieën te begrijpen. ETL-tools vallen in verschillende types, elk geschikt voor andere usecases en teamstructuren:
| Type | Beschrijving | Voorbeelden |
|---|---|---|
| Open-source ETL | Gratis te gebruiken, sterk aanpasbaar, community-ondersteund. Vereist meer engineeringinspanning om te implementeren en te onderhouden. | Apache Airflow, Airbyte, Hadoop, Pentaho PDI |
| Cloudgebaseerde / SaaS ETL | Volledig beheerd, geen infrastructuur nodig. Pay-per-use of abonnementsprijzen. Lage operationele overhead. | Fivetran, Stitch, Hevo, Matillion |
| Enterprise ETL | Rijk aan features, gebouwd voor grootschalige, complexe omgevingen. Sterke governance, metadatabeheer en compliance-mogelijkheden. | Informatica PowerCenter, IBM Infosphere Datastage, SAP Data Services |
| Cloud-native ETL (ELT) | Ontworpen voor cloud datawarehouses. Duwt de transformatielogica naar de warehouse-engine in plaats van midden in de pipeline. | AWS Glue, Azure Data Factory, Google Cloud Dataflow, Databricks DLT |
| No-code / Low-code ETL | Drag-and-drop interfaces waarmee niet-engineers pipelines kunnen bouwen. Snel in te richten, maar minder flexibel voor complexe transformaties. | Integrate.io, Astera Centerprise, Portable.io, Hevo |
| Realtime / Streaming ETL | Verwerkt data zodra die binnenkomt in plaats van in geplande batches. Essentieel voor tijdkritische analytics. | Estuary, Hevo, AWS Glue (streamingmodus) |
De top 24 ETL-tools
Met die overwegingen in gedachten presenteren we de top 24 ETL-tools die in 2026 op de markt beschikbaar zijn. Let op: de tools zijn niet op kwaliteit gerangschikt, omdat verschillende tools verschillende sterktes en zwaktes hebben.
1. Apache Airflow
Apache Airflow is een open-sourceplatform om workflows programmeerbaar te definiëren, te plannen en te monitoren. Het platform heeft een webgebaseerde gebruikersinterface en een command-line interface om workflows te beheren en te triggeren.
Workflows worden gedefinieerd met gerichte acyclische grafen (DAG’s), die zorgen voor duidelijke visualisatie en beheer van taken en afhankelijkheden. Airflow integreert ook met andere tools die vaak worden gebruikt in data engineering en data science, zoals Apache Spark en Pandas.
Bedrijven die Airflow gebruiken profiteren van de mogelijkheid om complexe workflows op te schalen en te beheren, evenals van de actieve open-sourcecommunity en uitgebreide documentatie. Leer meer in onze tutorial Een ETL-pipeline bouwen met Airflow of de cursus Introductie tot Apache Airflow in Python.
2. Databricks Delta Live Tables
Databricks Delta Live Tables (DLT) is een ETL-framework boven op Apache Spark dat datapijplijnen automatiseert (ze maken en beheren). Het stelt datateams in staat om betrouwbare, onderhoudbare en declaratieve pipelines te bouwen met minimale inspanning.
Delta Live Tables vereenvoudigt ETL door een declaratieve aanpak te gebruiken: gebruikers definiëren het wat (de transformaties en afhankelijkheden), en het systeem handelt het hoe af (uitvoering, optimalisatie en herstel).
Een grote kracht van DLT is het waarborgen van datakwaliteit en betrouwbaarheid. Ingebouwde expectations laten gebruikers datakwaliteitsregels definiëren die records in realtime valideren. Mislukte records kunnen in quarantaine worden geplaatst voor later onderzoek.
3. Portable.io
Portable.io omschrijft zichzelf als "het eerste ELT-platform dat on-demand connectors bouwt voor datateams." Trouw aan deze missie bouwt het team van Portable maatwerk no-code integraties, waarbij data wordt binnengehaald van SaaS-providers en vele andere databronnen die mogelijk niet worden ondersteund omdat ze door andere ETL-aanbieders over het hoofd worden gezien. Potentiële klanten kunnen zelf de uitgebreide connectorcatalogus bekijken met meer dan 1.300 lastig te vinden ETL-connectors.
Portable werkt vanuit de overtuiging dat bedrijven zonder code data van elke bedrijfsapplicatie binnen handbereik moeten hebben. Het team van Portable heeft een product gecreëerd dat efficiënte en tijdige datamanagement mogelijk maakt en robuuste schaalbaarheid en hoge prestaties biedt. Daarnaast heeft het een kosteneffectieve prijsstelling voor bedrijven van elke omvang en geavanceerde beveiligingsfuncties om dataprotectie en compliance met gangbare standaarden te waarborgen.
4. IBM Infosphere Datastage
Infosphere Datastage is een ETL-tool van IBM als onderdeel van het Infosphere Information Server-ecosysteem. Met het grafische framework kunnen gebruikers datapijplijnen ontwerpen die data uit meerdere bronnen extraheren, complexe transformaties uitvoeren en de data aanleveren bij doelapplicaties.
IBM Infosphere staat bekend om zijn snelheid, dankzij functies als load balancing en parallelisatie. Het ondersteunt ook metadata, automatische foutdetectie en een breed scala aan dataservices, van datawarehousing tot AI-toepassingen.
Net als andere enterprise ETL-tools biedt Infosphere Datastage een reeks connectors voor het integreren van verschillende databronnen. Het integreert ook naadloos met andere componenten van de IBM Infosphere Information Server, waardoor gebruikers ETL-jobs kunnen ontwikkelen, testen, implementeren en monitoren.
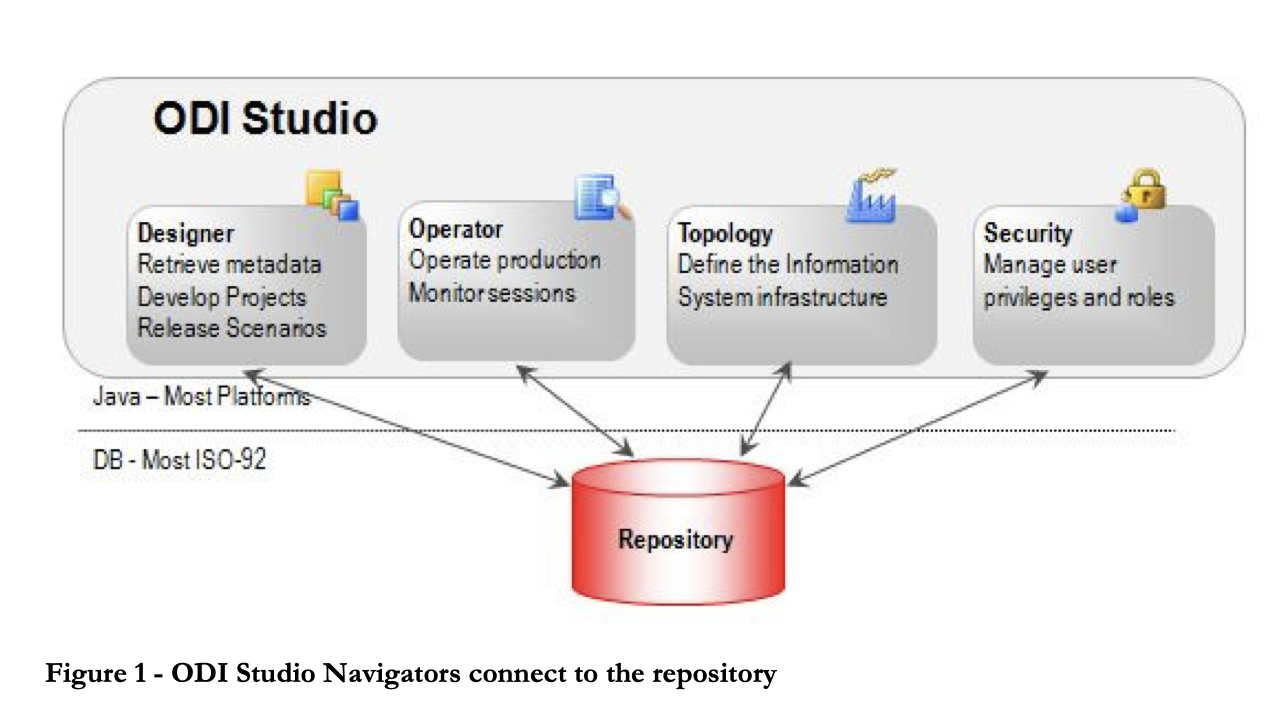
5. Oracle Data Integrator
Oracle Data Integrator is een ETL-tool die gebruikers helpt complexe datawarehouses te bouwen, te implementeren en te beheren. Het wordt geleverd met kant-en-klare connectors voor veel databases, waaronder Hadoop, EREPs, CRM’s, XML, JSON, LDAP, JDBC en ODBC.
ODI bevat Data Integrator Studio, dat zowel zakelijke gebruikers als ontwikkelaars via een grafische interface toegang geeft tot meerdere artefacten. Deze artefacten bieden alle onderdelen van dataintegratie, van databeweging tot synchronisatie, kwaliteit en beheer.
6. Microsoft SQL Server Integration Services (SSIS)
SSIS is een platform op enterprise-niveau voor dataintegratie en -transformatie. Het wordt geleverd met connectors om data te extraheren uit bronnen zoals XML-bestanden, flat files en relationele databases. Practitioners kunnen de grafische gebruikersinterface van SSIS Designer gebruiken om datastromen en transformaties te bouwen.
Het platform bevat een bibliotheek met ingebouwde transformaties die de hoeveelheid benodigde code voor ontwikkeling minimaliseren. SSIS biedt ook uitgebreide documentatie voor het bouwen van aangepaste workflows. De steile leercurve en complexiteit kunnen beginners echter ontmoedigen om snel ETL-pipelines te maken.
7. dbt (data build tool)
dbt (data build tool) is de industriestandaard geworden voor de transformatielaag in moderne ELT-pipelines. In plaats van data tijdens de extractie te transformeren, transformeert dbt data binnen het datawarehouse met SQL — een aanpak die nu bekendstaat als de “T in ELT”.
Met dbt kunnen data engineers en analytics engineers modulaire, versiebeheerde en geteste SQL-modellen schrijven. Elk model is gedocumenteerd, afhankelijkheden worden gevolgd en elke run levert een data lineage-grafiek op die precies laat zien hoe data van ruwe bronnen naar uiteindelijke tabellen stroomt. Leer meer in onze introductie tot dbt, de dbt-conceptengids voor data engineers en onze dbt Cloud-gids.
dbt is beschikbaar als open source (dbt Core, gratis) of als volledig beheerde cloudservice (dbt Cloud). Het integreert met alle grote cloud datawarehouses — Snowflake, BigQuery, Redshift en Databricks — en combineert natuurlijk met ingestietools zoals Fivetran en Airbyte tot een complete, moderne ELT-stack.
8. Pentaho Data Integration (PDI)
Pentaho Data Integration (PDI) is een ETL-tool van Hitachi. Het vangt data uit verschillende bronnen, schoont die op en slaat ze op in een uniform en consistent formaat.
Voorheen bekend als Kettle, bevat PDI meerdere grafische gebruikersinterfaces voor het definiëren van datapijplijnen. Gebruikers kunnen datajobs en transformaties ontwerpen met de PDI-client, Spoon, en ze vervolgens uitvoeren met Kitchen. Zo kan de PDI-client worden gebruikt voor realtime ETL met Pentaho Reporting.
9. Hadoop
Hadoop is een open-source framework voor het verwerken en opslaan van big data in clusters van servers. Het wordt gezien als de basis van big data en maakt opslag en verwerking van grote hoeveelheden data mogelijk.
Het Hadoop-framework bestaat uit verschillende modules, waaronder het Hadoop Distributed File System (HDFS) voor opslag, MapReduce voor het lezen en transformeren van data en YARN voor resourcebeheer. Hive wordt vaak gebruikt om SQL-queries te converteren naar MapReduce-bewerkingen.
Bedrijven die Hadoop overwegen, moeten zich bewust zijn van de kosten. Een aanzienlijk deel van de kosten van het implementeren van Hadoop komt voort uit de rekenkracht die nodig is voor verwerking en de expertise die nodig is om Hadoop ETL te onderhouden, niet zozeer uit de tools of opslag zelf.
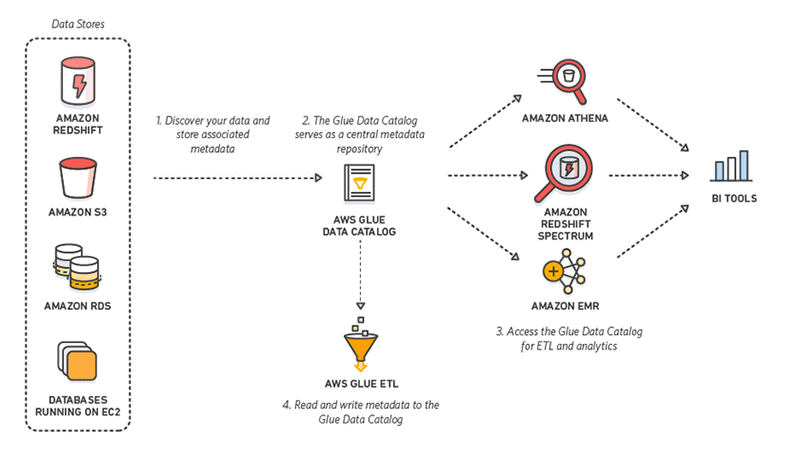
10. AWS Glue
AWS Glue is een serverloze ETL-tool van Amazon. Het ontdekt, bereidt, integreert en transformeert data uit meerdere bronnen voor analytics-doeleinden. Zonder dat je infrastructuur hoeft in te richten of te beheren, belooft AWS Glue de forse kosten van dataintegratie te verlagen.
Nog beter: bij interactie met AWS Glue kunnen practitioners kiezen tussen een drag-and-drop GUI, een Jupyter-notebook of Python/Scala-code. AWS Glue biedt ook ondersteuning voor diverse dataverwerking en workloads die aan verschillende zakelijke behoeften voldoen, waaronder ETL, ELT, batch en streaming.
11. AWS Data Pipeline
AWS’s Data Pipeline is een beheerde ETL-service die het mogelijk maakt data te verplaatsen tussen AWS-services of on-premises resources. Gebruikers kunnen de te verplaatsen data specificeren, transformatietaken of queries en een schema voor het uitvoeren van de transformaties.
Data Pipeline staat bekend om zijn betrouwbaarheid, flexibiliteit en schaalbaarheid, evenals fouttolerantie en configureerbaarheid. Het platform heeft ook een drag-and-drop console voor gebruiksgemak. Bovendien is het relatief goedkoop.
Een veelvoorkomende usecase voor AWS Data Pipeline is het repliceren van data van Relational Database Service (RDS) en die laden naar Amazon Redshift.
Het is echter belangrijk op te merken dat AWS de focus geleidelijk verlegt van AWS Data Pipeline naar modernere oplossingen zoals AWS Glue. AWS Glue biedt serverloze, geautomatiseerde dataintegratie met ondersteuning voor zowel batch- als streamingworkloads. Daarnaast verkent AWS het zero-ETL-concept (en Reverse ETL), waarbij services zoals Amazon Aurora en Amazon Redshift kunnen integreren zonder traditionele ETL-pipelines. Naarmate deze ontwikkelingen doorgaan, wordt verwacht dat AWS Data Pipeline wordt uitgefaseerd, waardoor gebruikers worden aangemoedigd om innovatievere en efficiëntere oplossingen binnen het AWS-ecosysteem te omarmen.
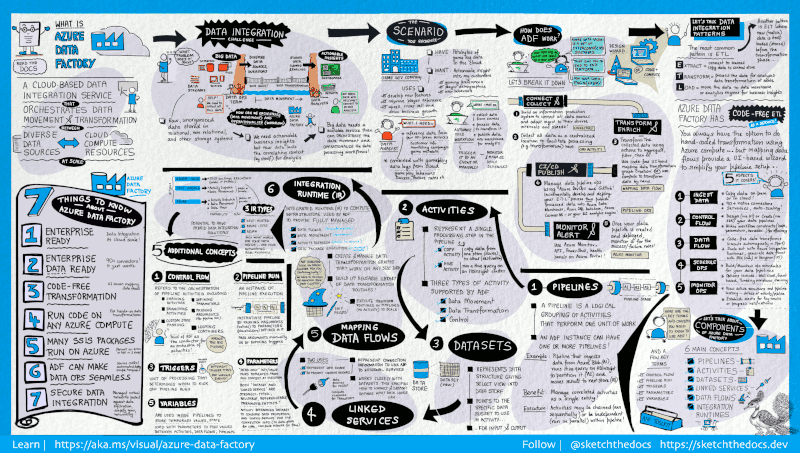
12. Azure Data Factory
Azure Data Factory is een cloudgebaseerde ETL-service van Microsoft waarmee je workflows maakt die data op schaal verplaatsen en transformeren.
Het bestaat uit een reeks onderling verbonden systemen. Samen stellen deze systemen engineers in staat om niet alleen data te ingesten en te transformeren, maar ook datapijplijnen te ontwerpen, plannen en monitoren.
De kracht van Data Factory zit in het grote aantal beschikbare connectors, van MySQL tot AWS, MongoDB, Salesforce en SAP. Het staat ook bekend om zijn flexibiliteit; gebruikers kunnen kiezen voor een no-code grafische gebruikersinterface of een command-line interface.
13. Google Cloud Dataflow
Dataflow is de serverloze ETL-service van Google Cloud. Het ondersteunt zowel stream- als batchverwerking en vereist geen eigen server of cluster. In plaats daarvan betaal je alleen voor de gebruikte resources, die automatisch schalen op basis van vereisten en workload.
Google Dataflow voert Apache Beam-pijplijnen uit binnen het Google Cloud Platform-ecosysteem. Apache biedt Java-, Python- en Go-SDK’s voor het representeren en overbrengen van datasets, zowel batch als streaming. Dit stelt gebruikers in staat de juiste SDK te kiezen om hun datapijplijnen te definiëren.
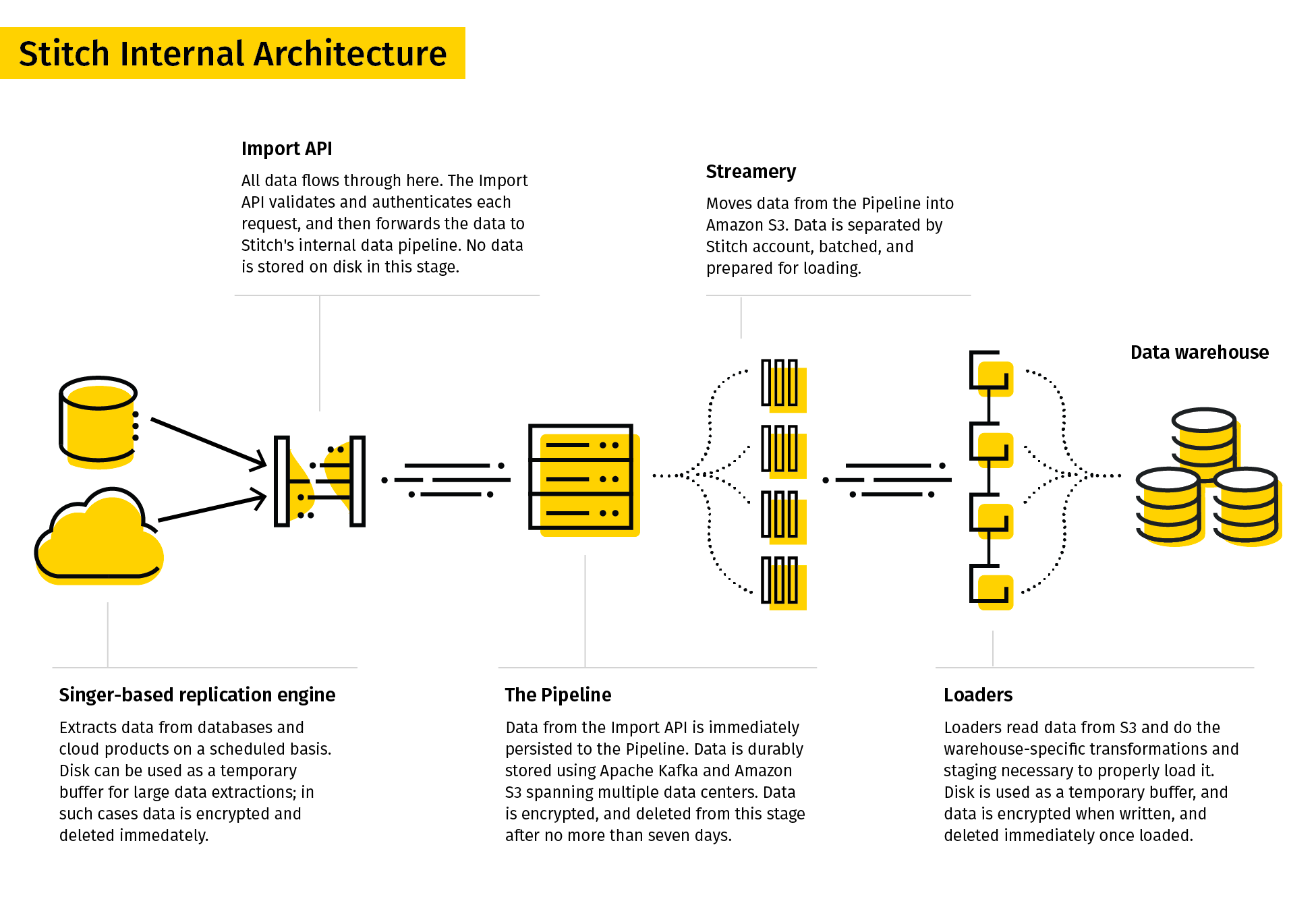
14. Stitch
Stitch omschrijft zichzelf als een eenvoudige, uitbreidbare ETL-tool gebouwd voor datateams.
Het replicatieproces van Stitch extraheert data uit diverse databronnen, zet deze om naar een bruikbaar ruw formaat en laadt ze in de bestemming. De dataconnectors omvatten databases en SaaS-applicaties. Bestemmingen kunnen data lakes, datawarehouses en opslagplatformen zijn.
Gezien de eenvoud ondersteunt Stitch alleen eenvoudige transformaties en geen door gebruikers gedefinieerde transformaties.
15. SAP BusinessObjects Data Services
SAP BusinessObjects Data Services is een enterprise ETL-tool waarmee gebruikers data uit meerdere systemen kunnen extraheren, transformeren en laden in datawarehouses.
De Data Services Designer biedt een grafische gebruikersinterface voor het definiëren van datapijplijnen en het specificeren van datatransformaties. Regels en metadata worden opgeslagen in een repository en een jobserver voert de job uit in batch of in realtime.
Wel kunnen de kosten van SAP Data Services hoog oplopen, aangezien de prijs van de tool, de server, de hardware en het engineeringteam snel kan optellen.
SAP Data Services is een goede match voor bedrijven die SAP gebruiken als hun Enterprise Resource Planning (ERP)-systeem, omdat het naadloos integreert met SAP Data Services
16. Hevo
Hevo is een dataintegratieplatform voor ETL en ELT met meer dan 150 connectors om data uit meerdere bronnen te extraheren. Het is een low-code tool, waardoor gebruikers eenvoudig datapijplijnen kunnen ontwerpen zonder uitgebreide codeerervaring.
Hevo biedt een reeks functies en voordelen, waaronder realtime dataintegratie, automatische schema-detectie en het vermogen om grote hoeveelheden data te verwerken. Het platform heeft ook een gebruiksvriendelijke interface en 24/7 klantenondersteuning.
17. Qlik Compose
Qlik Compose is een datawarehousingoplossing die automatisch datawarehouses ontwerpt en ETL-code genereert. Deze tool automatiseert tijdrovende en foutgevoelige ETL-ontwikkeling en -onderhoud, wat de doorlooptijd van datawarehousingprojecten verkort.
Hiervoor voert Qlik Compose de automatisch gegenereerde code uit, die data uit bronnen laadt en verplaatst naar hun datawarehouses. Dergelijke workflows kunnen worden ontworpen en gepland met de Workflow Designer en Scheduler.
Qlik Compose kan ook data valideren en datakwaliteit borgen. Practitioners die data in realtime nodig hebben, kunnen Compose integreren met Qlik Replicate.
18. Integrate.io
Integrate.io, voorheen bekend als Xplenty, verdient een plek op onze lijst met top ETL-tools. De gebruiksvriendelijke, intuïtieve interface opent de deur naar uitgebreid databeheer, zelfs voor teamleden met minder technische kennis. Als cloudgebaseerd platform neemt Integrate.io de noodzaak weg voor zware hardware of software-installaties en biedt het een zeer schaalbare oplossing die meegroeit met de behoeften van je bedrijf.
Dankzij de mogelijkheid om te verbinden met een grote verscheidenheid aan databronnen, van databases tot CRM-systemen, is het een veelzijdige keuze voor uiteenlopende dataintegratiebehoeften. Met prioriteit voor databeveiliging biedt het functies als versleuteling op veldniveau en voldoet het aan belangrijke standaarden zoals GDPR en HIPAA. Met krachtige datatransformatiecapaciteiten kunnen gebruikers hun data eenvoudig opschonen, formatteren en verrijken als onderdeel van het ETL-proces.
19. Airbyte
Airbyte is een toonaangevend open-source ELT-platform. Airbyte biedt meer dan 400 dataconnectors — en dat aantal groeit — en heeft meer dan 40.000 data engineers die het gebruiken.
Airbyte integreert met dbt voor datatransformatie en met Airflow / Prefect / Dagster voor orkestratie. Het heeft een gebruiksvriendelijke interface en een API en Terraform Provider zijn beschikbaar.
Airbyte onderscheidt zich door zijn open-sourcekarakter; het kost 20 minuten om een nieuwe connector te maken met hun no-code connector builder, en je kunt elke standaardconnector bewerken, mits je toegang hebt tot de code. Naast de open-sourceversie biedt Airbyte zowel een cloudgehoste (Airbyte Cloud) als een betaalde zelfgehoste versie (Airbyte Enterprise) voor wanneer je je pipelines in productie wilt brengen.
20. Astera Centerprise
Astera Centerprise is een enterprise-grade, 100% codevrije ETL/ELT-tool. Als onderdeel van de Astera Data Stack biedt Centerprise een intuïtieve en gebruiksvriendelijke interface met een korte leercurve, waarmee gebruikers van elk technisch niveau binnen enkele minuten datapijplijnen kunnen bouwen.
De geautomatiseerde dataintegratietool biedt diverse mogelijkheden, zoals out-of-the-box connectiviteit met verschillende databronnen en bestemmingen, AI-aangedreven data-extractie, AI-automapping, ingebouwde geavanceerde transformaties en datakwaliteitsfuncties. Gebruikers kunnen eenvoudig ongestructureerde en gestructureerde data extraheren, transformeren en laden in de bestemming van hun keuze met dataflows. Deze dataflows kunnen worden geautomatiseerd om te draaien op specifieke intervallen, voorwaarden of bestanddrops met behulp van de ingebouwde jobscheduler.
21. Informatica PowerCenter
Informatica PowerCenter is een van de beste ETL-tools op de markt. Het heeft een breed scala aan connectors voor cloud datawarehouses en -lakes, waaronder AWS, Azure, Google Cloud en Salesforce. De low- en no-code tools zijn ontworpen om tijd te besparen en workflows te vereenvoudigen.
Informatica PowerCenter bevat verschillende services waarmee gebruikers datapijplijnen kunnen ontwerpen, implementeren en monitoren. Zo helpt de Repository Manager bij gebruikersbeheer, stelt de Designer gebruikers in staat de stroom van data van bron naar doel te specificeren en definieert de Workflow Manager de volgorde van taken.
22. Estuary
Estuary is een geavanceerd platform voor realtime dataintegratie dat het maken en beheren van datapijplijnen vereenvoudigt. Ontworpen om zowel batch- als streamingdata te verwerken, stelt Estuary je in staat robuuste ETL-workflows te bouwen. De intuïtieve gebruikersinterface maakt het toegankelijk voor zowel technische als niet-technische gebruikers, zodat teams zich kunnen richten op het halen van waarde uit data in plaats van te worstelen met complexe configuraties.
De automatiseringsmogelijkheden van het platform springen eruit: het beheert schema-evolutie automatisch en past zich eenvoudig aan veranderende datastructuren aan. Met integratie naar een breed scala aan databronnen en bestemmingen is Estuary geschikt voor teams die realtime analytics zoeken, of het nu gaat om het monitoren van verkooptrends in e-commerce of het analyseren van sensordata in IoT-toepassingen.
23. Fivetran
Fivetran is uitgegroeid tot een toonaangevende ETL-oplossing voor volledig geautomatiseerde dataintegratie, waarmee bedrijven hun data kunnen centraliseren. Door gebruik te maken van een bibliotheek met kant-en-klare connectors minimaliseert Fivetran de insteltijd en verbindt het databases, SaaS-applicaties en eventstreams met cloud datawarehouses. Het platform blinkt uit in het automatisch afhandelen van schemawijzigingen, zodat data soepel blijft stromen, zelfs als bronsystemen evolueren.
Met realtime replicatie ondersteunt Fivetran bijna directe datatoegang. Geoptimaliseerd voor cloud-native omgevingen zoals Snowflake, BigQuery en Redshift, is Fivetran een favoriete keuze voor teams die datapijplijnen willen vereenvoudigen en toch schaalbaarheid willen behouden. Het is vooral waardevol voor marketing- en salesteams die uiteenlopende databronnen willen integreren in uniforme analyticsdashboards.
24. Matillion
Matillion is een cloud-native ETL-tool die is ontworpen om data direct binnen cloud datawarehouses te transformeren. Toegesneden op platforms zoals Snowflake, AWS Redshift, Google BigQuery en Azure Synapse, biedt Matillion een manier om datatransformaties op schaal uit te voeren. De visuele interface maakt het eenvoudig om workflows te ontwerpen via een drag-and-drop omgeving, terwijl meer gevorderde gebruikers SQL-gebaseerde transformaties kunnen inzetten voor complexe datataken.
Met de focus op schaalbaarheid en prestaties is Matillion goed geschikt voor teams die grootschalige transformaties efficiënt moeten verwerken. Van het creëren van gedetailleerde 360-graden klantoverzichten tot het optimaliseren van supplychain-analyses: Matillion stelt dataprofessionals in staat het volledige potentieel van hun cloudgebaseerde datainfrastructuren te benutten zonder de typische knelpunten van traditionele ETL-processen.
Vergelijking van top ETL-tools
De volgende tabel zet de genoemde ETL-tools naast elkaar af op verschillende categorieën:
| ETL-tool | Open-source beschikbaarheid | Cloud-compatibiliteit | Gebruiksgemak | Aantal integraties | Functies en overwegingen | Ideale usecase |
|---|---|---|---|---|---|---|
| Apache Airflow | Ja | Ja | Gemiddeld | Hoog | DAG-gebaseerde workflow, schaalbaarheid, uitgebreide community-ondersteuning | Complexe workflows en orkestratie van grootschalige, meerstapsdatapijplijnen |
| Databricks Delta Live Tables | Nee | Ja | Hoog | Hoog | Declaratief pipelineontwerp, automatische afhankelijkheidsbeheer, ingebouwde datakwaliteitscontroles | Enterprises die de Databricks Lakehouse gebruiken en geautomatiseerde, betrouwbare ETL met geïntegreerde datakwaliteit en realtime verwerking zoeken |
| Portable.io | Nee | Ja | Hoog | Zeer hoog | On-demand connectors, no-code, kosteneffectieve prijsstelling | Kleine tot middelgrote bedrijven die maatwerkconnectors nodig hebben voor minder gangbare databronnen |
| IBM Infosphere Datastage | Nee | Ja | Gemiddeld | Hoog | Hoge verwerkingssnelheid, metadatasteun, enterprise-grade | Enterprises met diverse en high-volume datapijplijnen die robuust metadatabeheer vereisen |
| Oracle Data Integrator | Nee | Ja | Gemiddeld | Hoog | Uitgebreide connectors, grafische interface, robuust beheer | Bedrijven in het Oracle-ecosysteem of met behoefte aan uitgebreide database-ondersteuning |
| Microsoft SSIS | Nee | Beperkt | Gemiddeld | Gemiddeld | Ingebouwde transformaties, uitgebreide documentatie | Organisaties die al investeren in Microsoft SQL Server |
| dbt (data build tool) | Ja | Ja | Hoog | Hoog | SQL-gebaseerde transformatie in het warehouse, versiebeheerde modellen, data lineage, dbt Core (gratis) + dbt Cloud (beheerd) | Datateams die een testbare, gedocumenteerde transformatielaag binnen een cloud datawarehouse nodig hebben (combineert met Fivetran of Airbyte) |
| Pentaho Data Integration | Ja | Ja | Gemiddeld | Hoog | Realtime ETL, grafische interface, Spoon/Kitchen-clients | Realtime ETL-verwerking voor bedrijven die flexibele, GUI-gebaseerde workflows nodig hebben |
| Hadoop | Ja | Ja | Laag | Hoog | Big data-verwerking, HDFS, MapReduce, hoge implementatiekosten | Grote ondernemingen die enorme datasets verwerken en gedistribueerde opslag en verwerking nodig hebben |
| AWS Glue | Nee | Ja | Hoog | Hoog | Serverloos, Python/Scala-ondersteuning, flexibele verwerkingsworkloads | Cloud-native bedrijven die serverloze ETL nodig hebben voor gestructureerde en ongestructureerde data |
| AWS Data Pipeline | Nee | Ja | Hoog | Gemiddeld | Beheerde service, fouttolerant, goedkoop | Basale ETL-processen binnen AWS (maar overstappende gebruikers zouden AWS Glue of zero-ETL-oplossingen moeten verkennen) |
| Azure Data Factory | Nee | Ja | Hoog | Zeer hoog | Veel connectors, flexibele interfaces, cloudgebaseerd | Enterprises met diverse databronnen binnen Microsofts Azure-ecosysteem |
| Google Cloud Dataflow | Nee | Ja | Hoog | Hoog | Serverloos, Apache Beam-integratie, kostenefficiënt | Stream- of batchverwerking binnen het Google Cloud-ecosysteem |
| Stitch | Nee | Ja | Hoog | Gemiddeld | Eenvoudige transformaties, SaaS-connectors, gebruiksvriendelijk | Start-ups en kleine teams met focus op eenvoudige datareplicatie naar datawarehouses |
| SAP BusinessObjects | Nee | Ja | Gemiddeld | Hoog | Enterprise-grade, integreert met SAP, duur | Gebruikers van SAP ERP die naadloze integratie zoeken |
| Hevo | Nee | Ja | Hoog | Hoog | Low-code, realtime integratie, automatische schema-detectie | Kleine tot middelgrote bedrijven die realtime analytics nodig hebben |
| Qlik Compose | Nee | Ja | Gemiddeld | Hoog | Automatiseert ETL-ontwikkeling, realtime integratie met Qlik Replicate | Bedrijven die geautomatiseerde ETL-pipelines en integratie met Qlik Replicate nodig hebben |
| Integrate.io | Nee | Ja | Hoog | Hoog | Intuïtieve interface, geen hardware nodig, sterke beveiligingsfuncties | Bedrijven die gebruiksgemak en databeveiliging prioriteren |
| Airbyte | Ja | Ja | Hoog | Zeer hoog | Open source, eenvoudig connectors maken, integreert met dbt | Organisaties die open-source, aanpasbare ELT-oplossingen zoeken |
| Astera Centerprise | Nee | Ja | Hoog | Hoog | Codevrij, AI-aangedreven data-extractie, gebruiksvriendelijk | Enterprises die no-code ETL-tools met AI-automatisering zoeken |
| Informatica PowerCenter | Nee | Ja | Hoog | Zeer hoog | Low/no-code tools, breed scala aan connectors, enterprise-grade | Enterprises die complexe datapijplijnen verwerken met uitgebreide connectorbehoeften |
| Estuary | Nee | Ja | Hoog | Gemiddeld | Realtime dataintegratie, automatisering, schema-evolutie, ondersteuning voor batch en streaming | Bedrijven die realtime analytics nodig hebben voor IoT- of e-commercedata |
| Fivetran | Nee | Ja | Hoog | Zeer hoog | Automatische schema-updates, kant-en-klare connectors, realtime replicatie, geoptimaliseerd voor de cloud | Bedrijven die geautomatiseerde, betrouwbare datareplicatie met minimale handmatige tussenkomst nodig hebben |
| Matillion | Nee | Ja | Hoog | Hoog | Cloud-native, drag-and-drop interface, complexe SQL-transformaties, schaalt met cloudinfrastructuren | Teams die cloudgebaseerde datatransformatieworkflows maximaal willen benutten |
Hoe kies je de juiste ETL-tool
Met 24 tools op deze lijst kan het overweldigend zijn om je opties te beperken. Hier is een besliskader op basis van de meest voorkomende teamprofielen:
- Net gestart / klein team: Begin met Stitch of Airbyte voor ingestie en dbt Core voor transformatie. Beide zijn gratis om zelf te hosten en hebben minimale operationele overhead.
- Schaalvergroting / middelgroot bedrijf: Fivetran + dbt Cloud is in 2026 de meest populaire productiestack. Voeg Apache Airflow toe voor orkestratie.
- Enterprise / complexe omgevingen: Informatica PowerCenter, IBM Infosphere Datastage of Azure Data Factory voor organisaties met legacy-systemen, strikte compliance en grote engineeringteams.
- AWS-ecosysteem: AWS Glue voor serverloze ETL; evalueer zero-ETL-integraties tussen Amazon Aurora en Redshift om pipelines geheel te elimineren.
- Google Cloud-ecosysteem: Google Cloud Dataflow voor stream- en batchverwerking binnen GCP.
- Microsoft / Azure-ecosysteem: Azure Data Factory voor orkestratie en verplaatsing, gecombineerd met Azure Synapse voor transformaties.
- Niet-technische / no-code gebruikers: Hevo, Integrate.io of Astera Centerprise bieden drag-and-drop interfaces met minimale code.
De ETL-expertise van je team versterken
Naarmate data centraler staat in bedrijfsvoering, zijn effectieve ETL-processen cruciaal. Om concurrerend te blijven, is het essentieel om de vaardigheden van je team in data engineering en -beheer continu te verbeteren. DataCamp for Business biedt op maat gemaakte oplossingen om organisaties te helpen hun medewerkers te upskillen, zodat ze goed zijn toegerust voor de complexiteit van moderne data-analyse. Met DataCamp for Business krijgt je team toegang tot:
- Gerichte leerpaden: Geef je team gerichte training in ETL-tools zoals Apache Airflow, AWS en meer om hun vermogen te vergroten om efficiënte datapijplijnen te ontwerpen en te beheren.
- Praktische ervaring: Stimuleer hands-on projecten die de data-uitdagingen van je organisatie weerspiegelen, zodat je team het vertrouwen en de expertise opbouwt om complexe datataken aan te kunnen.
- Schaalbare trainingsoplossingen: Kies schaalbare trainingsplatforms met een breed aanbod aan resources in ETL en datamanagement, zodat je team kan meebewegen met de groei van je organisatie.
- Voortgangstracking: Gebruik tools om de ontwikkeling van je team te monitoren en geef regelmatige feedback om continue verbetering te waarborgen.
Investeren in de skills van je datateam verbetert niet alleen de ETL-efficiëntie, maar drijft ook betere datastrategieën aan en draagt zo bij aan het succes van je organisatie. Vraag vandaag nog een demo aan om meer te leren.
Extra bronnen
Samengevat: er zijn veel verschillende ETL- en dataintegratietools beschikbaar, elk met eigen unieke features en mogelijkheden. Populaire opties zijn onder andere SSIS, Talend Open Studio, Pentaho Data Integration, Hadoop, Airflow, AWS Data Pipeline, Google Dataflow, SAP BusinessObjects Data Services en Hevo. Bedrijven die deze tools overwegen, moeten hun specifieke vereisten en budget zorgvuldig evalueren om de juiste oplossing voor hun behoeften te kiezen. Voor meer resources over ETL-tools en meer, bekijk de volgende links:
- ETL vs ELT: de verschillen begrijpen en de juiste keuze maken
- ELT uitgelegd: dataintegratie voor het cloudera
- Wat is Reverse ETL? Een handige gids
- Wat is Zero-ETL? Nieuwe benaderingen van dataintegratie
- Data warehouse-architectuur: trends, tools en technieken
- Top 17 ETL-sollicitatievragen en -antwoorden
- Een ETL-pipeline bouwen met Airflow
