Che cos’è l’ETL?
L’ETL è un approccio comune per integrare i dati e organizzare gli stack dati. Un tipico processo ETL comprende le seguenti fasi:
- Estrazione dei dati dalle fonti
- Trasformazione dei dati in modelli
- Caricamento dei dati nei data warehouse
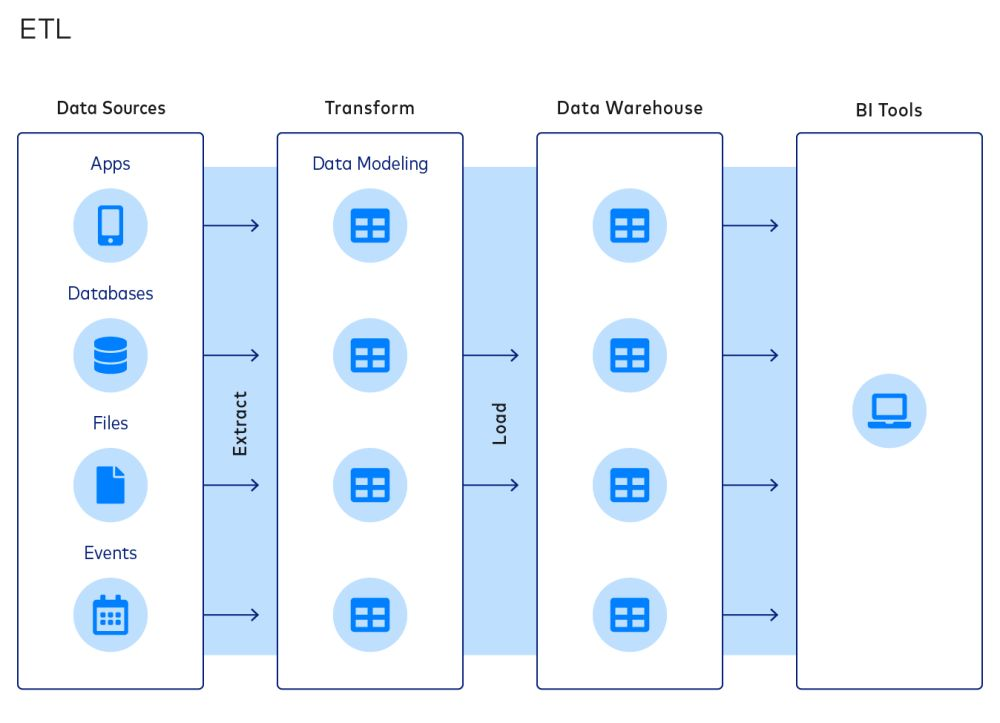
Il paradigma ETL è popolare perché consente alle aziende di ridurre le dimensioni dei loro data warehouse, con conseguente risparmio sui costi di calcolo, archiviazione e larghezza di banda.
Tuttavia, questi risparmi stanno diventando meno rilevanti man mano che tali vincoli si attenuano. Di conseguenza, ELT (Extract, Load, Transform) sta guadagnando popolarità. Nel processo ELT, i dati vengono caricati nella destinazione dopo l’estrazione, e la trasformazione è l’ultimo passaggio. Nonostante ciò, molte aziende fanno ancora affidamento sull’ETL.
Cosa sono gli strumenti ETL?
Come suggerisce il nome, gli strumenti ETL sono un insieme di software utilizzati per estrarre, trasformare e caricare dati da una o più fonti in un sistema o database di destinazione. Gli strumenti ETL sono progettati per automatizzare e semplificare l’estrazione da varie fonti, trasformare i dati in un formato coerente e pulito e caricarli nel sistema di destinazione in modo tempestivo ed efficiente. Nella prossima sezione vedremo le considerazioni chiave che i team dati dovrebbero applicare quando valutano uno strumento ETL.
Considerazioni nella scelta di uno strumento ETL
Ecco tre considerazioni chiave da tenere presenti nella selezione di uno strumento ETL:
- Estensione dell’integrazione dati. Gli strumenti ETL possono connettersi a una varietà di fonti e destinazioni. I team dovrebbero optare per strumenti con un’ampia gamma di integrazioni. Ad esempio, chi vuole spostare dati da Google Sheets ad Amazon Redshift dovrebbe scegliere strumenti che supportano tali connettori.
- Livello di personalizzazione. Le aziende dovrebbero scegliere gli strumenti ETL in base ai requisiti di personalizzazione e alle competenze tecniche del team IT. Una start-up potrebbe trovare sufficienti i connettori e le trasformazioni predefinite presenti nella maggior parte degli strumenti ETL; una grande impresa con raccolta dati su misura probabilmente avrà bisogno della flessibilità per creare trasformazioni ad hoc con l’aiuto di un solido team di ingegneri.
- Struttura dei costi. Nella scelta di uno strumento ETL, le organizzazioni dovrebbero considerare non solo il costo dello strumento in sé, ma anche i costi di infrastruttura e risorse umane necessari per mantenere la soluzione nel lungo periodo. In alcuni casi, uno strumento con costo iniziale più alto ma minori tempi di fermo e manutenzione può risultare più conveniente nel lungo termine. Al contrario, esistono strumenti ETL open source e gratuiti che possono comportare costi di manutenzione elevati.
Altre considerazioni includono:
- Il livello di automazione offerto
- Il livello di sicurezza e compliance
- Le prestazioni e l’affidabilità dello strumento.
Tipi di strumenti ETL
Prima di entrare nei singoli strumenti, è utile conoscere le principali categorie. Gli strumenti ETL rientrano in vari tipi, ciascuno adatto a casi d’uso e strutture di team differenti:
| Tipo | Descrizione | Esempi |
|---|---|---|
| ETL open source | Gratuiti, altamente personalizzabili, supportati dalla community. Richiedono più lavoro ingegneristico per il deployment e la manutenzione. | Apache Airflow, Airbyte, Hadoop, Pentaho PDI |
| ETL cloud-based / SaaS | Completamente gestiti, senza infrastruttura da eseguire. Prezzi a consumo o in abbonamento. Basso overhead operativo. | Fivetran, Stitch, Hevo, Matillion |
| ETL enterprise | Ricchi di funzionalità, progettati per ambienti su larga scala e complessi. Forte governance, gestione dei metadati e capacità di compliance. | Informatica PowerCenter, IBM Infosphere Datastage, SAP Data Services |
| ETL cloud-native (ELT) | Progettati per i data warehouse cloud. Spostano la logica di trasformazione nel motore del warehouse invece che nel mezzo della pipeline. | AWS Glue, Azure Data Factory, Google Cloud Dataflow, Databricks DLT |
| ETL no-code / low-code | Interfacce drag-and-drop che consentono anche ai non ingegneri di costruire pipeline. Configurazione rapida, ma meno flessibili per trasformazioni complesse. | Integrate.io, Astera Centerprise, Portable.io, Hevo |
| ETL in tempo reale / streaming | Elaborano i dati al loro arrivo anziché in batch schedulati. Essenziali per analisi time-sensitive. | Estuary, Hevo, AWS Glue (modalità streaming) |
I 24 migliori strumenti ETL
Tenendo conto di queste considerazioni, presentiamo i 24 migliori strumenti ETL disponibili sul mercato nel 2026. Nota: gli strumenti non sono ordinati per qualità, poiché ciascuno ha punti di forza e debolezze diversi.
1. Apache Airflow
Apache Airflow è una piattaforma open source per creare, schedulare e monitorare i workflow in modo programmatico. La piattaforma offre un’interfaccia utente web e una riga di comando per gestire e avviare i workflow.
I workflow sono definiti tramite grafi aciclici diretti (DAG), che consentono una visualizzazione chiara e la gestione di task e dipendenze. Airflow si integra anche con altri strumenti comunemente usati in data engineering e data science, come Apache Spark e Pandas.
Le aziende che usano Airflow possono beneficiare della sua capacità di scalare e gestire workflow complessi, oltre che della community open source attiva e dell’ampia documentazione. Puoi saperne di più nel nostro tutorial Costruire una pipeline ETL con Airflow o nel corso Introduzione ad Apache Airflow in Python.
2. Databricks Delta Live Tables
Databricks Delta Live Tables (DLT) è un framework ETL basato su Apache Spark che automatizza la creazione e la gestione delle pipeline dati. Consente ai team dati di costruire pipeline affidabili, manutenibili e dichiarative con il minimo sforzo.
Delta Live Tables semplifica l’ETL adottando un approccio dichiarativo: gli utenti definiscono il cosa (trasformazioni e dipendenze) e il sistema gestisce il come (esecuzione, ottimizzazione e ripristino).
Un grande punto di forza di DLT è la garanzia di qualità e affidabilità dei dati. Le aspettative integrate permettono di definire regole di qualità che validano i record in tempo reale. I record non conformi possono essere messi in quarantena per revisioni successive.
3. Portable.io
Portable.io si definisce "la prima piattaforma ELT che costruisce connettori on-demand per i team dati". Fedele a questa missione, il team di Portable crea integrazioni personalizzate no-code, acquisendo dati da fornitori SaaS e molte altre fonti che potrebbero non essere supportate perché trascurate da altri provider ETL. I potenziali clienti possono consultare il loro ampio catalogo di connettori con oltre 1.300 connettori ETL difficili da trovare.
Portable parte dall’idea che le aziende debbano avere a portata di mano i dati di ogni applicazione business senza scrivere codice. Il team ha creato un prodotto che abilita una gestione dei dati efficiente e tempestiva, offre scalabilità robusta e alte prestazioni. Inoltre, propone prezzi convenienti per aziende di tutte le dimensioni e funzionalità avanzate di sicurezza per garantire protezione dei dati e conformità agli standard più comuni.
4. IBM Infosphere Datastage
Infosphere Datastage è uno strumento ETL offerto da IBM come parte dell’ecosistema Infosphere Information Server. Con il suo framework grafico, gli utenti possono progettare pipeline che estraggono dati da più fonti, eseguono trasformazioni complesse e consegnano i dati alle applicazioni target.
IBM Infosphere è noto per la velocità, grazie a funzionalità come il bilanciamento del carico e la parallelizzazione. Supporta anche metadati, rilevamento automatico dei guasti e un’ampia gamma di servizi dati, dal data warehousing alle applicazioni di AI.
Come altri strumenti ETL enterprise, Infosphere Datastage offre una gamma di connettori per integrare diverse fonti. Si integra inoltre perfettamente con gli altri componenti di IBM Infosphere Information Server, consentendo di sviluppare, testare, distribuire e monitorare i job ETL.
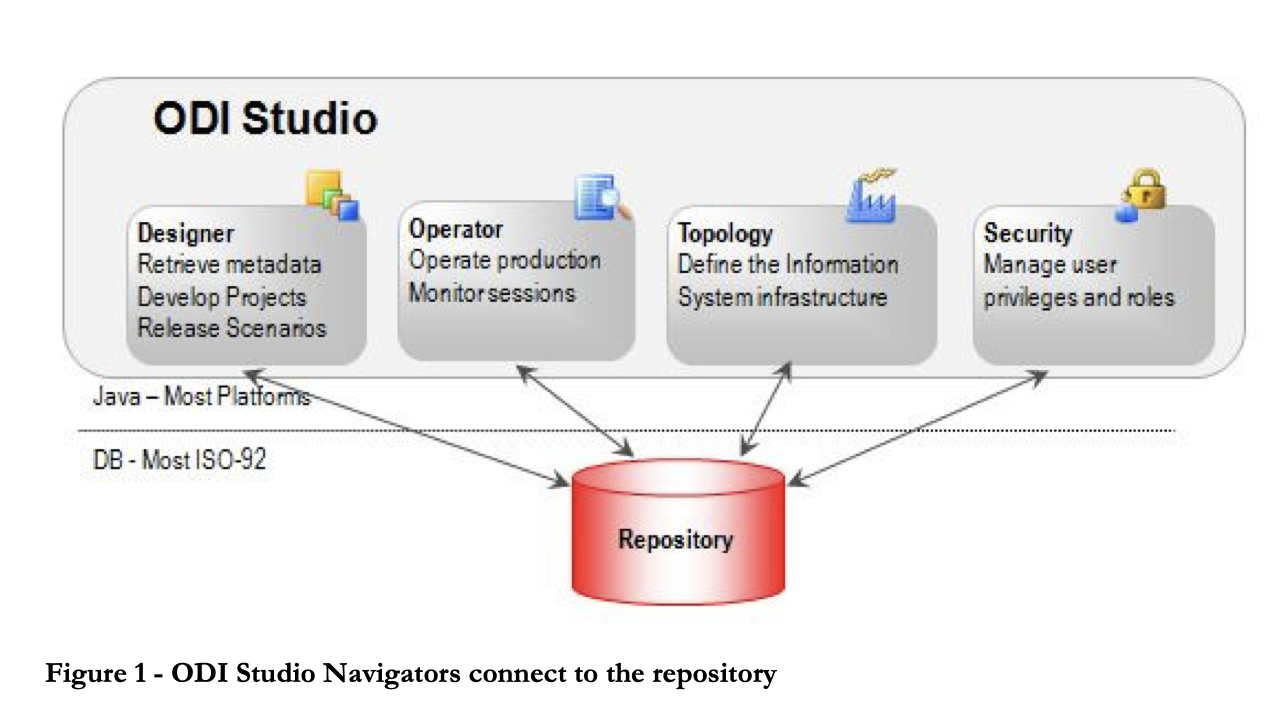
5. Oracle Data Integrator
Oracle Data Integrator è uno strumento ETL che aiuta a costruire, distribuire e gestire data warehouse complessi. Include connettori pronti all’uso per molti database, tra cui Hadoop, EREP, CRM, XML, JSON, LDAP, JDBC e ODBC.
ODI include il Data Integrator Studio, che fornisce a business user e sviluppatori l’accesso a molteplici artefatti tramite un’interfaccia grafica. Questi artefatti offrono tutti gli elementi dell’integrazione dati, dal movimento alla sincronizzazione, qualità e gestione.
6. Microsoft SQL Server Integration Services (SSIS)
SSIS è una piattaforma di livello enterprise per l’integrazione e la trasformazione dei dati. Include connettori per estrarre dati da fonti come file XML, flat file e database relazionali. I professionisti possono usare l’interfaccia grafica di SSIS Designer per costruire flussi e trasformazioni.
La piattaforma include una libreria di trasformazioni integrate che riducono la quantità di codice necessario per lo sviluppo. SSIS offre anche una documentazione completa per costruire workflow personalizzati. Tuttavia, la ripida curva di apprendimento e la complessità possono scoraggiare i principianti dal creare rapidamente pipeline ETL.
7. dbt (data build tool)
dbt (data build tool) è diventato lo standard di settore per il livello di trasformazione nelle moderne pipeline ELT. Anziché trasformare i dati “in volo” durante l’estrazione, dbt trasforma i dati all’interno del data warehouse usando SQL — un approccio noto come la “T in ELT”.
dbt consente a data engineer e analytics engineer di scrivere modelli SQL modulari, versionati e testati. Ogni modello è documentato, le dipendenze sono tracciate e ogni esecuzione produce un grafo di lineage che mostra esattamente come i dati fluiscono dalle fonti grezze alle tabelle finali. Scopri di più nella nostra introduzione a dbt, nella guida ai concetti dbt per data engineer e nella nostra guida a dbt Cloud.
dbt è disponibile come open source (dbt Core, gratuito) o come servizio cloud completamente gestito (dbt Cloud). Si integra con tutti i principali data warehouse cloud — Snowflake, BigQuery, Redshift e Databricks — e si abbina naturalmente a strumenti di ingestione come Fivetran e Airbyte per formare uno stack ELT moderno completo.
8. Pentaho Data Integration (PDI)
Pentaho Data Integration (PDI) è uno strumento ETL offerto da Hitachi. Acquisisce dati da varie fonti, li pulisce e li archivia in un formato uniforme e coerente.
In precedenza noto come Kettle, PDI offre più interfacce grafiche per definire le pipeline. Gli utenti possono progettare job e trasformazioni con il client PDI, Spoon, ed eseguirli con Kitchen. Ad esempio, il client PDI può essere usato per ETL in tempo reale con Pentaho Reporting.
9. Hadoop
Hadoop è un framework open source per l’elaborazione e l’archiviazione di big data in cluster di server. È considerato la base dei big data e consente l’archiviazione e l’elaborazione di grandi quantità di dati.
Il framework Hadoop è composto da diversi moduli, tra cui l’Hadoop Distributed File System (HDFS) per l’archiviazione, MapReduce per la lettura e trasformazione dei dati e YARN per la gestione delle risorse. Hive è comunemente usato per convertire query SQL in operazioni MapReduce.
Le aziende che considerano Hadoop dovrebbero essere consapevoli dei costi. Una parte significativa deriva dalla potenza di calcolo richiesta per l’elaborazione e dalle competenze necessarie per mantenere l’ETL su Hadoop, più che dagli strumenti o dallo storage in sé.
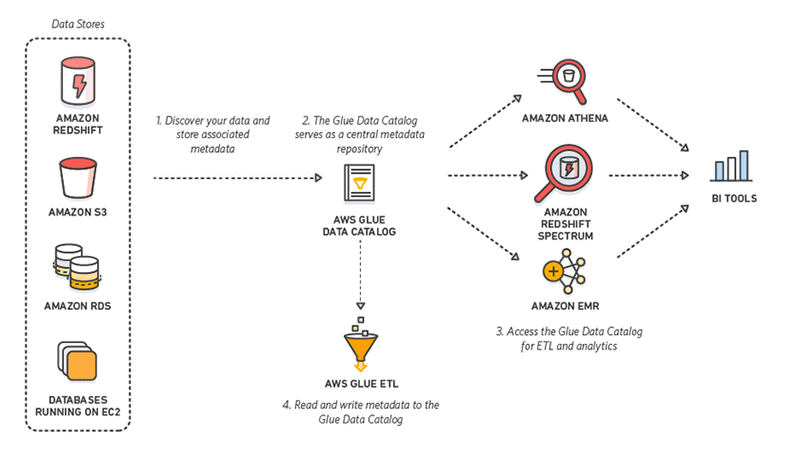
10. AWS Glue
AWS Glue è uno strumento ETL serverless offerto da Amazon. Scopre, prepara, integra e trasforma dati da più fonti per casi d’uso analitici. Senza necessità di configurare o gestire infrastrutture, AWS Glue promette di ridurre i costi elevati dell’integrazione dati.
Ancora meglio, interagendo con AWS Glue si può scegliere tra una GUI drag-and-drop, un notebook Jupyter o codice Python/Scala. AWS Glue supporta inoltre vari carichi di lavoro di elaborazione dati che rispondono a diverse esigenze, tra cui ETL, ELT, batch e streaming.
11. AWS Data Pipeline
Data Pipeline di AWS è un servizio ETL gestito che abilita lo spostamento dei dati tra servizi AWS o risorse on-premise. Gli utenti possono specificare i dati da spostare, i job o le query di trasformazione e una pianificazione per eseguirle.
Data Pipeline è conosciuto per affidabilità, flessibilità e scalabilità, oltre che per tolleranza ai guasti e configurabilità. La piattaforma include anche una console drag-and-drop per facilità d’uso. Inoltre, è relativamente economica.
Un caso d’uso comune per AWS Data Pipeline è la replica dei dati da Relational Database Service (RDS) e il loro caricamento su Amazon Redshift.
Tuttavia, è importante notare che AWS sta gradualmente spostando l’attenzione da AWS Data Pipeline verso soluzioni più moderne come AWS Glue. AWS Glue offre integrazione dati serverless e automatizzata con supporto per carichi batch e streaming. Inoltre, AWS sta esplorando il concetto di zero-ETL (e di Reverse ETL), in cui servizi come Amazon Aurora e Amazon Redshift possono integrarsi senza pipeline ETL tradizionali. Con questi progressi, è previsto il phase-out di AWS Data Pipeline, incoraggiando gli utenti ad adottare soluzioni più innovative ed efficienti nell’ecosistema AWS.
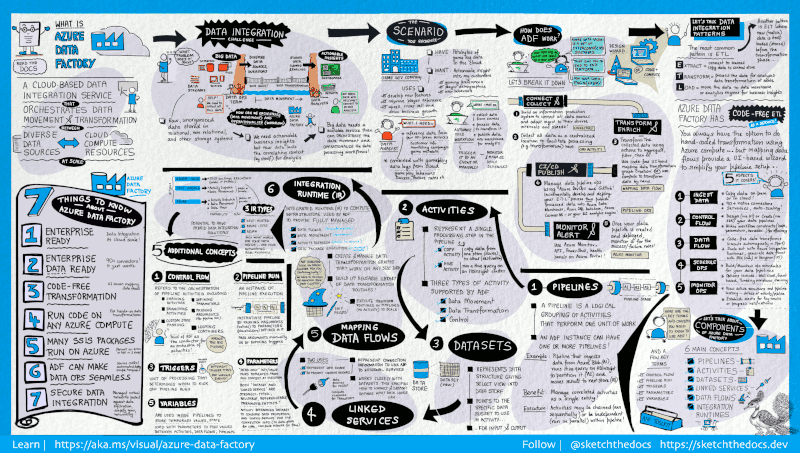
12. Azure Data Factory
Azure Data Factory è un servizio ETL cloud offerto da Microsoft, usato per creare workflow che spostano e trasformano dati su larga scala.
È composto da una serie di sistemi interconnessi. Insieme, questi sistemi permettono agli ingegneri non solo di ingerire e trasformare i dati, ma anche di progettare, schedulare e monitorare le pipeline.
Il punto di forza di Data Factory risiede nel grande numero di connettori disponibili, da MySQL ad AWS, MongoDB, Salesforce e SAP. È apprezzato anche per la flessibilità: gli utenti possono scegliere tra un’interfaccia grafica no-code o un’interfaccia a riga di comando.
13. Google Cloud Dataflow
Dataflow è il servizio ETL serverless offerto da Google Cloud. Supporta l’elaborazione sia in streaming sia in batch e non richiede che le aziende gestiscano server o cluster. Gli utenti pagano solo per le risorse consumate, che si scalano automaticamente in base a requisiti e carico di lavoro.
Google Dataflow esegue pipeline Apache Beam all’interno dell’ecosistema Google Cloud Platform. Apache offre SDK Java, Python e Go per rappresentare e trasferire set di dati in batch e in streaming. Ciò consente di scegliere l’SDK più adatto per definire le proprie pipeline.
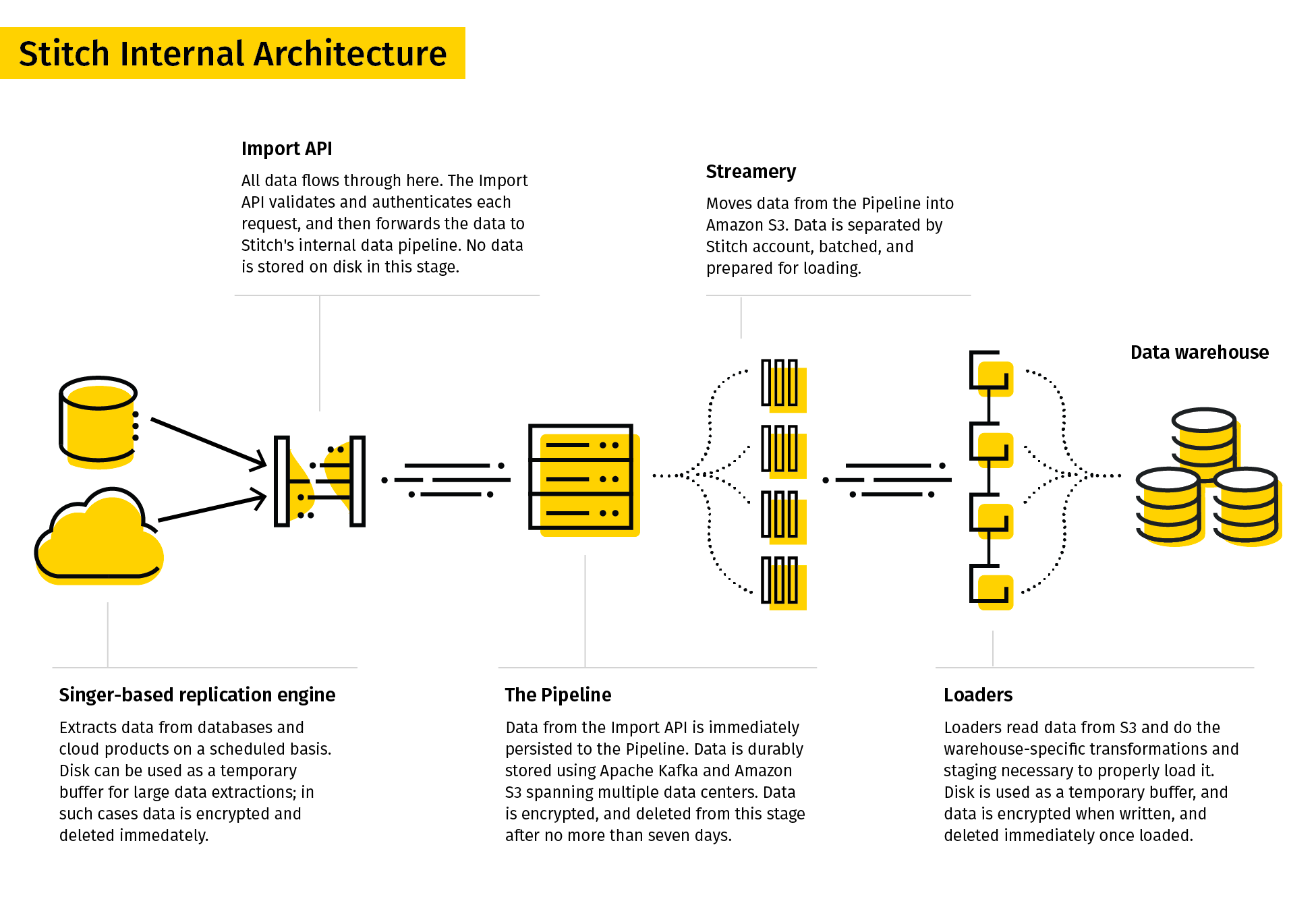
14. Stitch
Stitch si descrive come uno strumento ETL semplice ed estensibile, pensato per i team dati.
Il processo di replica di Stitch estrae dati da varie fonti, li trasforma in un formato grezzo utile e li carica nella destinazione. I suoi connettori includono database e applicazioni SaaS. Le destinazioni possono essere data lake, data warehouse e piattaforme di storage.
Data la sua semplicità, Stitch supporta solo trasformazioni semplici e non trasformazioni definite dall’utente.
15. SAP BusinessObjects Data Services
SAP BusinessObjects Data Services è uno strumento ETL enterprise che permette di estrarre dati da più sistemi, trasformarli e caricarli nei data warehouse.
Il Data Services Designer fornisce un’interfaccia grafica per definire pipeline e specificare le trasformazioni. Regole e metadati sono memorizzati in un repository, e un job server esegue i job in batch o in tempo reale.
Tuttavia, i servizi dati SAP possono essere costosi, poiché il costo dello strumento, del server, dell’hardware e del team di ingegneri può aumentare rapidamente.
SAP Data Services è ideale per le aziende che usano SAP come sistema ERP (Enterprise Resource Planning), poiché si integra perfettamente con SAP Data Services
16. Hevo
Hevo è una piattaforma di integrazione dati per ETL ed ELT con oltre 150 connettori per estrarre dati da più fonti. È uno strumento low-code, che rende semplice progettare pipeline senza grandi competenze di programmazione.
Hevo offre varie funzionalità e vantaggi, tra cui integrazione in tempo reale, rilevamento automatico degli schemi e capacità di gestire grandi volumi di dati. La piattaforma include anche un’interfaccia intuitiva e assistenza clienti 24/7.
17. Qlik Compose
Qlik Compose è una soluzione di data warehousing che progetta automaticamente i data warehouse e genera codice ETL. Questo strumento automatizza lo sviluppo e la manutenzione ETL, attività spesso noiose e soggette a errori, riducendo i tempi di avvio dei progetti di data warehousing.
Per farlo, Qlik Compose esegue il codice generato automaticamente, che carica i dati dalle fonti e li sposta nei data warehouse. Tali workflow possono essere progettati e schedulati usando il Workflow Designer e lo Scheduler.
Qlik Compose offre anche la possibilità di validare i dati e garantirne la qualità. Chi ha bisogno di dati in tempo reale può integrare Compose con Qlik Replicate.
18. Integrate.io
Integrate.io, precedentemente noto come Xplenty, merita un posto nella nostra lista dei migliori strumenti ETL. La sua interfaccia intuitiva e facile da usare apre le porte a una gestione dati completa anche per i membri del team con minori competenze tecniche. In quanto piattaforma cloud, Integrate.io elimina la necessità di installazioni hardware o software ingombranti e offre una soluzione altamente scalabile che cresce con le esigenze del business.
La capacità di connettersi a un’ampia varietà di fonti, dai database ai sistemi CRM, lo rende una scelta versatile per diverse esigenze di integrazione. Dando priorità alla sicurezza, offre funzionalità come la cifratura a livello di campo ed è conforme a standard chiave come GDPR e HIPAA. Con potenti capacità di trasformazione, gli utenti possono facilmente pulire, formattare e arricchire i dati come parte del processo ETL.
19. Airbyte
Airbyte è una piattaforma ELT open source di riferimento. Offre oltre 400 connettori — in costante crescita — ed è utilizzata da più di 40.000 data engineer.
Airbyte si integra con dbt per le trasformazioni e con Airflow / Prefect / Dagster per l’orchestrazione. Ha un’interfaccia utente semplice e mette a disposizione un’API e un Terraform Provider.
Airbyte si distingue per l’open source: con il builder no-code di connettori bastano 20 minuti per crearne uno nuovo, e puoi modificare qualsiasi connettore “off-the-shelf” se hai accesso al codice. Oltre alla versione open source, Airbyte offre una versione cloud-hosted (Airbyte Cloud) e una versione self-hosted a pagamento (Airbyte Enterprise) per portare in produzione le pipeline.
20. Astera Centerprise
Astera Centerprise è uno strumento ETL/ELT enterprise, 100% senza codice. Parte dell’Astera Data Stack, Centerprise offre un’interfaccia intuitiva e user-friendly con curva di apprendimento breve, che consente agli utenti di qualunque livello tecnico di costruire pipeline in pochi minuti.
Lo strumento di integrazione dati automatizzato offre funzionalità come connettività out-of-the-box verso diverse fonti e destinazioni, estrazione dati potenziata dall’AI, mappatura automatica con AI, trasformazioni avanzate integrate e funzioni di qualità dei dati. Gli utenti possono facilmente estrarre dati non strutturati e strutturati, trasformarli e caricarli nella destinazione scelta tramite dataflow. Questi dataflow possono essere automatizzati per l’esecuzione a intervalli specifici, al verificarsi di condizioni o al drop di file tramite lo scheduler integrato.
21. Informatica PowerCenter
Informatica PowerCenter è uno dei migliori strumenti ETL sul mercato. Dispone di un’ampia gamma di connettori per data warehouse e data lake cloud, tra cui AWS, Azure, Google Cloud e Salesforce. I suoi strumenti low- e no-code sono progettati per far risparmiare tempo e semplificare i workflow.
Informatica PowerCenter include diversi servizi che consentono di progettare, distribuire e monitorare le pipeline. Ad esempio, il Repository Manager aiuta con la gestione degli utenti, il Designer consente di specificare il flusso dei dati dalla fonte al target e il Workflow Manager definisce la sequenza dei task.
22. Estuary
Estuary è una piattaforma all’avanguardia per l’integrazione dati in tempo reale che semplifica la creazione e la gestione delle pipeline. Progettata per gestire dati sia batch sia in streaming, Estuary consente di costruire workflow ETL robusti. La sua interfaccia intuitiva la rende accessibile sia a utenti tecnici sia non tecnici, permettendo ai team di concentrarsi sul valore dei dati invece che su configurazioni complesse.
Le capacità di automazione della piattaforma spiccano: gestisce automaticamente l’evoluzione degli schemi e si adatta con facilità a strutture dati in cambiamento. Con l’integrazione verso un’ampia gamma di fonti e destinazioni, Estuary è ideale per team che cercano analytics in tempo reale, sia per monitorare trend di vendita nell’e-commerce sia per analizzare dati da sensori in applicazioni IoT.
23. Fivetran
Fivetran si è affermata come una soluzione ETL leader per l’integrazione dati completamente automatizzata, consentendo alle aziende di centralizzare i propri dati. Sfruttando una libreria di connettori predefiniti, Fivetran riduce i tempi di configurazione, collegando database, applicazioni SaaS e stream di eventi ai data warehouse cloud. La piattaforma eccelle nella gestione automatica dei cambi di schema, garantendo flussi dati fluidi anche quando i sistemi sorgente evolvono.
Con funzionalità di replica in tempo reale, Fivetran supporta una disponibilità quasi istantanea dei dati. Ottimizzata per ambienti cloud-native come Snowflake, BigQuery e Redshift, è una scelta di riferimento per i team che vogliono semplificare le pipeline mantenendo la scalabilità. È particolarmente preziosa per i team marketing e sales che devono integrare fonti eterogenee in dashboard analitiche unificate.
24. Matillion
Matillion è uno strumento ETL cloud-native progettato per trasformare i dati direttamente all’interno dei data warehouse cloud. Pensato per piattaforme come Snowflake, AWS Redshift, Google BigQuery e Azure Synapse, Matillion consente di eseguire trasformazioni su larga scala. La sua interfaccia visuale rende semplice progettare workflow in un ambiente drag-and-drop, mentre gli utenti più avanzati possono sfruttare trasformazioni basate su SQL per gestire task complessi.
Con il suo focus su scalabilità e prestazioni, Matillion è adatto ai team che devono elaborare trasformazioni su larga scala in modo efficiente. Dalla creazione di customer 360 dettagliati all’ottimizzazione delle analytics sulla supply chain, Matillion consente ai professionisti dei dati di sfruttare al massimo le infrastrutture cloud senza i tipici colli di bottiglia dei processi ETL tradizionali.
Confronto tra i migliori strumenti ETL
La seguente tabella confronta affiancati gli strumenti ETL citati su molte categorie diverse:
| Strumento ETL | Disponibilità open source | Compatibilità cloud | Facilità d’uso | Numero di integrazioni | Caratteristiche e considerazioni | Caso d’uso ideale |
|---|---|---|---|---|---|---|
| Apache Airflow | Sì | Sì | Moderata | Alta | Workflow basati su DAG, scalabilità, ampio supporto della community | Workflow complessi e orchestrazione di pipeline multi-step su larga scala |
| Databricks Delta Live Tables | No | Sì | Alta | Alta | Design dichiarativo delle pipeline, gestione automatica delle dipendenze, controlli qualità integrati | Enterprise che usano il Databricks Lakehouse e cercano ETL affidabile e automatizzato con qualità dei dati integrata e processing in tempo reale |
| Portable.io | No | Sì | Alta | Molto alta | Connettori on-demand, no-code, prezzi convenienti | Aziende piccole/medie che necessitano di connettori personalizzati per fonti meno comuni |
| IBM Infosphere Datastage | No | Sì | Moderata | Alta | Elaborazione ad alta velocità, supporto metadati, livello enterprise | Enterprise con pipeline ad alto volume e diversificate che richiedono gestione robusta dei metadati |
| Oracle Data Integrator | No | Sì | Moderata | Alta | Connettori estesi, interfaccia grafica, gestione robusta | Aziende che usano ecosistemi Oracle o che necessitano di ampio supporto ai database |
| Microsoft SSIS | No | Limitata | Moderata | Moderata | Trasformazioni integrate, documentazione completa | Organizzazioni già investite in Microsoft SQL Server |
| dbt (data build tool) | Sì | Sì | Alta | Alta | Trasformazione SQL in-warehouse, modelli versionati, data lineage, dbt Core (gratis) + dbt Cloud (gestito) | Team dati che necessitano di un livello di trasformazione testabile e documentato dentro un data warehouse cloud (in abbinata a Fivetran o Airbyte) |
| Pentaho Data Integration | Sì | Sì | Moderata | Alta | ETL in tempo reale, interfaccia grafica, client Spoon/Kitchen | Elaborazione ETL in tempo reale per aziende che necessitano di workflow flessibili basati su GUI |
| Hadoop | Sì | Sì | Bassa | Alta | Big data processing, HDFS, MapReduce, alti costi di implementazione | Grandi imprese con dataset enormi che richiedono archiviazione ed elaborazione distribuite |
| AWS Glue | No | Sì | Alta | Alta | Serverless, supporto Python/Scala, carichi di lavoro flessibili | Aziende cloud-native che necessitano di ETL serverless per dati strutturati e non |
| AWS Data Pipeline | No | Sì | Alta | Moderata | Servizio gestito, tollerante ai guasti, economico | Processi ETL di base su AWS (ma chi migra dovrebbe valutare AWS Glue o soluzioni zero-ETL) |
| Azure Data Factory | No | Sì | Alta | Molto alta | Numerosi connettori, interfacce flessibili, basato sul cloud | Enterprise con fonti dati diversificate che usano l’ecosistema Azure di Microsoft |
| Google Cloud Dataflow | No | Sì | Alta | Alta | Serverless, integrazione con Apache Beam, costo efficiente | Elaborazione dati in streaming o batch nell’ecosistema Google Cloud |
| Stitch | No | Sì | Alta | Moderata | Trasformazioni semplici, connettori SaaS, user-friendly | Startup e piccoli team focalizzati su replica dati semplice verso data warehouse |
| SAP BusinessObjects | No | Sì | Moderata | Alta | Enterprise, integrazione con SAP, costoso | Utenti di sistemi ERP SAP che cercano integrazione senza soluzione di continuità |
| Hevo | No | Sì | Alta | Alta | Low-code, integrazione in tempo reale, rilevamento schema automatico | PMI che necessitano di analytics in tempo reale |
| Qlik Compose | No | Sì | Moderata | Alta | Automatizza lo sviluppo ETL, integrazione real-time con Qlik Replicate | Aziende che richiedono pipeline ETL automatizzate e integrazione con Qlik Replicate |
| Integrate.io | No | Sì | Alta | Alta | Interfaccia intuitiva, nessun hardware richiesto, forte sicurezza | Aziende che privilegiano facilità d’uso e sicurezza dei dati |
| Airbyte | Sì | Sì | Alta | Molto alta | Open source, creazione connettori facile, integrazione con dbt | Organizzazioni che cercano soluzioni ELT open source e personalizzabili |
| Astera Centerprise | No | Sì | Alta | Alta | Senza codice, estrazione dati con AI, user-friendly | Enterprise che cercano strumenti ETL no-code con automazione AI |
| Informatica PowerCenter | No | Sì | Alta | Molto alta | Strumenti low/no-code, ampia gamma di connettori, livello enterprise | Enterprise con pipeline complesse e ampie necessità di connettori |
| Estuary | No | Sì | Alta | Moderata | Integrazione dati in tempo reale, automazione, evoluzione degli schemi, supporto batch e streaming | Aziende che necessitano di analytics in tempo reale per dati IoT o e-commerce |
| Fivetran | No | Sì | Alta | Molto alta | Aggiornamenti schema automatici, connettori predefiniti, replica in tempo reale, ottimizzato per il cloud | Aziende che necessitano di replica dati automatizzata e affidabile con minimo intervento manuale |
| Matillion | No | Sì | Alta | Alta | Cloud-native, interfaccia drag-and-drop, trasformazioni SQL complesse, scala con le infrastrutture cloud | Team che vogliono massimizzare i workflow di trasformazione dati basati sul cloud |
Come scegliere lo strumento ETL giusto
Con 24 strumenti in elenco, restringere le opzioni può sembrare impegnativo. Ecco un framework decisionale basato sui profili di team più comuni:
- Inizio / team piccolo: Parti con Stitch o Airbyte per l’ingestione e dbt Core per la trasformazione. Entrambi sono gratuiti da self-hostare e hanno overhead operativo minimo.
- In crescita / azienda di medie dimensioni: Fivetran + dbt Cloud è lo stack di produzione più popolare nel 2026. Aggiungi Apache Airflow per l’orchestrazione.
- Enterprise / ambienti complessi: Informatica PowerCenter, IBM Infosphere Datastage o Azure Data Factory per organizzazioni con sistemi legacy, requisiti di compliance stringenti e grandi team di ingegneri.
- Ecosistema AWS: AWS Glue per ETL serverless; valuta le integrazioni zero-ETL tra Amazon Aurora e Redshift per eliminare del tutto le pipeline.
- Ecosistema Google Cloud: Google Cloud Dataflow per elaborazione streaming e batch all’interno di GCP.
- Ecosistema Microsoft / Azure: Azure Data Factory per orchestrazione e movimento, abbinato ad Azure Synapse per le trasformazioni.
- Utenti non tecnici / no-code: Hevo, Integrate.io o Astera Centerprise offrono interfacce drag-and-drop con minimo codice richiesto.
Rafforzare le competenze ETL del tuo team
Man mano che i dati diventano centrali nelle operazioni aziendali, processi ETL efficaci sono cruciali. Per restare competitivi, è fondamentale migliorare continuamente le competenze del tuo team in data engineering e gestione. DataCamp for Business offre soluzioni su misura per aiutare le organizzazioni a potenziare le competenze dei dipendenti, assicurando che siano pronti a gestire le complessità dell’analisi dati moderna. Con DataCamp for Business, il tuo team può accedere a:
- Percorsi di apprendimento mirati: Fornisci al team una formazione focalizzata su strumenti ETL come Apache Airflow, AWS e altri per migliorare la capacità di progettare e gestire pipeline efficienti.
- Esperienza pratica: Promuovi progetti hands-on che riflettano le sfide dati della tua organizzazione, aiutando il team a sviluppare sicurezza ed esperienza nella gestione di task complessi.
- Soluzioni formative scalabili: Scegli piattaforme formative scalabili che offrano una gamma di risorse su ETL e gestione dati, garantendo l’adattabilità del team con la crescita dell’organizzazione.
- Monitoraggio dei progressi: Utilizza strumenti per monitorare lo sviluppo del team, fornendo feedback regolari per assicurare un miglioramento continuo.
Investire nelle competenze del team dati non solo aumenta l’efficienza dell’ETL, ma guida anche strategie dati migliori, contribuendo al successo dell’organizzazione. Richiedi una demo per saperne di più.
Risorse aggiuntive
In conclusione, esistono molti strumenti di integrazione dati ed ETL, ciascuno con funzionalità e capacità uniche. Alcune opzioni popolari includono SSIS, Talend Open Studio, Pentaho Data Integration, Hadoop, Airflow, AWS Data Pipeline, Google Dataflow, SAP BusinessObjects Data Services e Hevo. Le aziende che valutano questi strumenti dovrebbero esaminare attentamente requisiti specifici e budget per scegliere la soluzione giusta per le proprie esigenze. Per altre risorse sugli strumenti ETL e non solo, consulta i seguenti link:
- ETL vs ELT: capire le differenze e fare la scelta giusta
- ELT spiegato: l’integrazione dati nell’era del cloud
- Che cos’è il Reverse ETL? Una guida utile
- Che cos’è lo Zero-ETL? Nuovi approcci all’integrazione dati
- Architettura dei Data Warehouse: trend, strumenti e tecniche
- Le 17 principali domande e risposte su ETL nei colloqui
- Costruire una pipeline ETL con Airflow

