Werde Dateningenieur
Was ist ETL?
ETL ist ein gängiger Ansatz, um Daten zu integrieren und Datenstapel zu organisieren. Ein typischer ETL-Prozess umfasst die folgenden Phasen:
- Daten aus Quellen extrahieren
- Daten in Datenmodelle umwandeln
- Laden von Daten in Data Warehouses
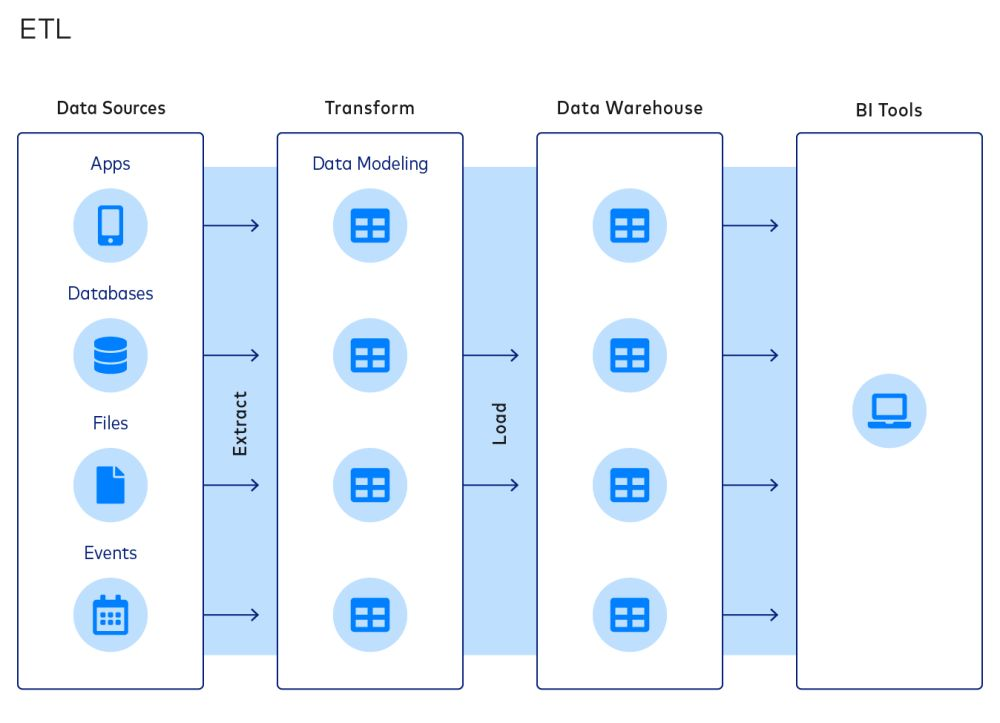
Das ETL-Paradigma ist beliebt, weil es den Unternehmen ermöglicht, die Größe ihrer Data Warehouses zu reduzieren, wodurch sie Rechen-, Speicher- und Bandbreitenkosten sparen können.
Diese Kosteneinsparungen werden jedoch immer unwichtiger, je mehr diese Zwänge verschwinden. Deshalb wird ELT (Extract, Load, Transform) immer beliebter. Beim ELT-Prozess werden die Daten nach der Extraktion in ein Ziel geladen, und die Transformation ist der letzte Schritt im Prozess. Trotzdem setzen viele Unternehmen immer noch auf ETL.
Was sind ETL-Tools?
Wie der Name schon sagt, handelt es sich bei ETL-Tools um eine Reihe von Softwarewerkzeugen, die zum Extrahieren, Transformieren und Laden von Daten aus einer oder mehreren Quellen in ein Zielsystem oder eine Datenbank verwendet werden. ETL-Tools wurden entwickelt, um den Prozess der Extraktion von Daten aus verschiedenen Quellen zu automatisieren und zu vereinfachen, sie in ein einheitliches und sauberes Format umzuwandeln und sie zeitnah und effizient in das Zielsystem zu laden. Im nächsten Abschnitt sehen wir uns die wichtigsten Überlegungen an, die Datenteams anstellen sollten, wenn sie ein ETL-Tool in Betracht ziehen.
Wichtige Überlegungen zu ETL-Tools
Hier sind drei wichtige Überlegungen zu den ETL-Tools eines Unternehmens.
- Das Ausmaß der Datenintegration. ETL-Tools können sich mit einer Vielzahl von Datenquellen und -zielen verbinden. Datenteams sollten sich für ETL-Tools entscheiden, die eine breite Palette an Integrationen bieten. Teams, die zum Beispiel Daten von Google Sheets zu Amazon Redshift übertragen wollen, sollten ETL-Tools wählen, die solche Konnektoren unterstützen.
- Grad der Anpassungsfähigkeit. Unternehmen sollten ihre ETL-Tools auf der Grundlage ihrer Anforderungen an die Anpassungsfähigkeit und der technischen Kompetenz ihres IT-Teams auswählen. Einem Start-up reichen die in den meisten ETL-Tools eingebauten Konnektoren und Transformationen vielleicht aus; ein großes Unternehmen mit einer maßgeschneiderten Datensammlung braucht wahrscheinlich die Flexibilität, mit Hilfe eines starken Teams von Ingenieuren maßgeschneiderte Transformationen zu erstellen.
- Kostenstruktur. Bei der Auswahl eines ETL-Tools sollten Unternehmen nicht nur die Kosten für das Tool selbst berücksichtigen, sondern auch die Kosten für die Infrastruktur und die personellen Ressourcen, die für die langfristige Wartung der Lösung erforderlich sind. In manchen Fällen kann ein ETL-Tool mit höheren Anschaffungskosten, aber geringeren Ausfallzeiten und Wartungsanforderungen auf lange Sicht kostengünstiger sein. Auf der anderen Seite gibt es kostenlose Open-Source-ETL-Tools, die hohe Wartungskosten verursachen können.
Einige andere Überlegungen sind:
- Der Grad der Automatisierung
- Das Niveau von Sicherheit und Compliance
- Die Leistung und Zuverlässigkeit des Werkzeugs.
Die 20 wichtigsten ETL-Tools für Datenteams
Mit diesen Überlegungen im Hinterkopf stellen wir dir die 16 besten ETL-Tools vor, die es auf dem Markt gibt. Beachte, dass die Werkzeuge nicht nach Qualität geordnet sind, da verschiedene Werkzeuge unterschiedliche Stärken und Schwächen haben.
1. Apache Airflow
Apache Airflow ist eine Open-Source-Plattform, mit der du Workflows programmatisch erstellen, planen und überwachen kannst. Die Plattform verfügt über eine webbasierte Benutzeroberfläche und eine Befehlszeilenschnittstelle zur Verwaltung und Auslösung von Arbeitsabläufen.
Workflows werden mithilfe von gerichteten azyklischen Graphen (DAGs) definiert, die eine klare Visualisierung und Verwaltung von Aufgaben und Abhängigkeiten ermöglichen. Airflow lässt sich auch mit anderen Tools integrieren, die häufig im Data Engineering und in der Datenwissenschaft verwendet werden, wie Apache Spark und Pandas.
Unternehmen, die Airflow einsetzen, profitieren von der Skalierbarkeit und der Verwaltung komplexer Arbeitsabläufe sowie von der aktiven Open-Source-Community und der umfangreichen Dokumentation. Du kannst im folgenden DataCamp-Kurs mehr über Airflow erfahren.
2. Portable.io
Portable.io beschreibt sich selbst als "die erste ELT-Plattform, die Konnektoren für Datenteams auf Abruf erstellt". Getreu dieser Mission entwickelt das Team von Portable benutzerdefinierte No-Code-Integrationen, die Daten von SaaS-Anbietern und vielen anderen Datenquellen aufnehmen, die von anderen ETL-Anbietern möglicherweise nicht unterstützt werden, weil sie übersehen werden. Potenzielle Kunden können sich selbst ein Bild von dem umfangreichen Katalog mit über 1.300 schwer zu findenden ETL-Steckern machen.
Portable basiert auf der Überzeugung, dass Unternehmen Daten aus jeder Geschäftsanwendung ohne Code zur Hand haben sollten. Das Team von Portable hat ein Produkt entwickelt, das eine effiziente und zeitnahe Datenverwaltung ermöglicht und robuste Skalierbarkeit und hohe Leistung bietet. Außerdem bietet es kostengünstige Preise für Unternehmen jeder Größe und fortschrittliche Sicherheitsfunktionen, die den Datenschutz und die Einhaltung gängiger Standards gewährleisten.
3. IBM Infosphere Datastage
Infosphere Datastage ist ein ETL-Tool, das von IBM als Teil des Infosphere Information Server Ecosystems angeboten wird. Mit dem grafischen Framework können Nutzer/innen Datenpipelines entwerfen, die Daten aus verschiedenen Quellen extrahieren, komplexe Transformationen durchführen und die Daten an die Zielanwendungen liefern.
IBM Infosphere ist für seine Geschwindigkeit bekannt, dank Funktionen wie Lastverteilung und Parallelisierung. Außerdem unterstützt es Metadaten, automatische Fehlererkennung und eine breite Palette von Datendiensten, von Data Warehousing bis hin zu KI-Anwendungen.
Wie andere ETL-Werkzeuge für Unternehmen bietet Infosphere Datastage eine Reihe von Konnektoren für die Integration verschiedener Datenquellen. Es lässt sich auch nahtlos in andere Komponenten des IBM Infosphere Information Server integrieren, so dass Benutzer ETL-Jobs entwickeln, testen, einsetzen und überwachen können.
4. Oracle Data Integrator
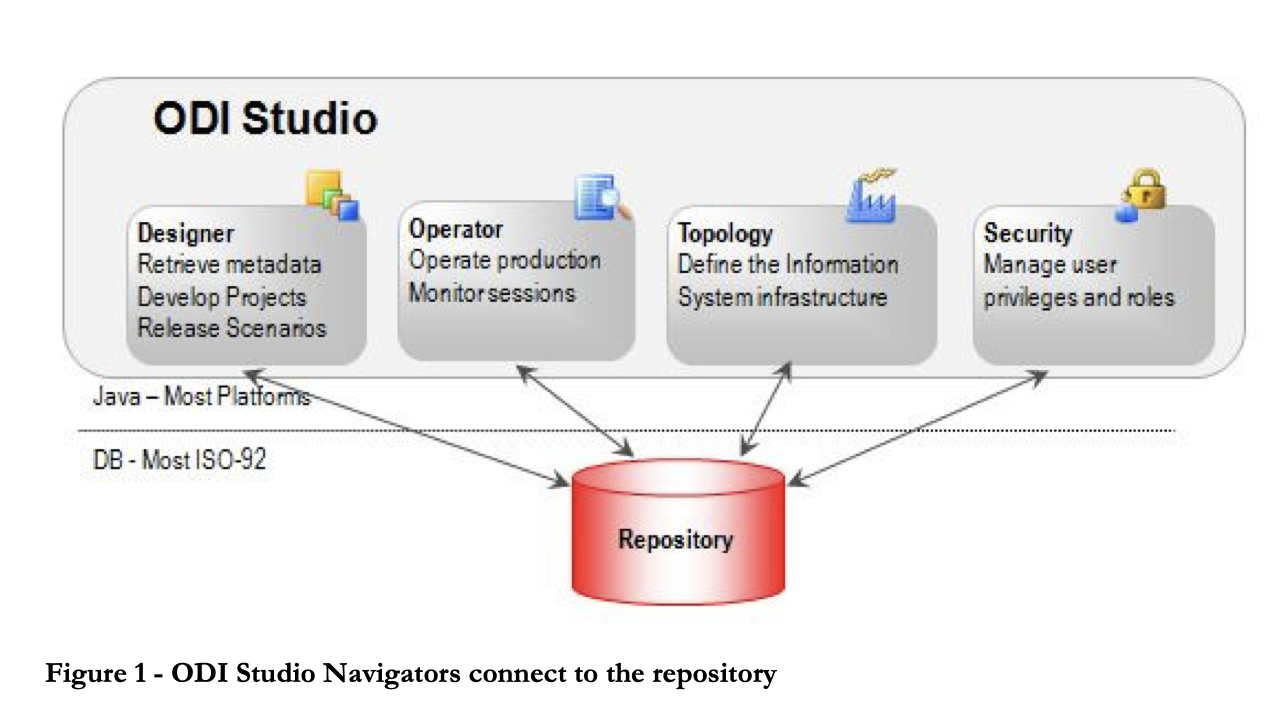
Der Oracle Data Integrator ist ein ETL-Tool, das den Benutzern hilft, komplexe Data Warehouses zu erstellen, einzusetzen und zu verwalten. Es verfügt über sofort einsetzbare Konnektoren für viele Datenbanken, darunter Hadoop, EREPs, CRMs, XML, JSON, LDAP, JDBC und ODBC.
ODI umfasst das Data Integrator Studio, das Geschäftsanwendern und Entwicklern über eine grafische Benutzeroberfläche Zugang zu verschiedenen Artefakten bietet. Diese Artefakte bieten alle Elemente der Datenintegration, von der Datenbewegung bis zur Synchronisierung, Qualität und Verwaltung.
5. Microsoft SQL Server Integration Services (SSIS)
SSIS ist eine Plattform für die Datenintegration und -umwandlung auf Unternehmensebene. Es verfügt über Konnektoren zum Extrahieren von Daten aus Quellen wie XML-Dateien, Flat Files und relationalen Datenbanken. Praktiker können die grafische Benutzeroberfläche des SSIS-Designers nutzen, um Datenflüsse und Transformationen zu konstruieren.
Die Plattform enthält eine Bibliothek mit eingebauten Transformationen, die den Umfang des für die Entwicklung erforderlichen Codes minimieren. SSIS bietet auch eine umfassende Dokumentation für die Erstellung benutzerdefinierter Workflows. Die steile Lernkurve und die Komplexität der Plattform können Anfänger jedoch davon abhalten, schnell ETL-Pipelines zu erstellen.
6. Talend Open Studio (TOS)
Talend Open Studio ist eine beliebte Open-Source-Datenintegrationssoftware mit einer benutzerfreundlichen GUI. Du kannst die Komponenten per Drag & Drop verschieben, konfigurieren und miteinander verbinden, um Datenpipelines zu erstellen. Hinter den Kulissen wandelt Open Studio die grafische Darstellung in Java- und Perl-Code um.
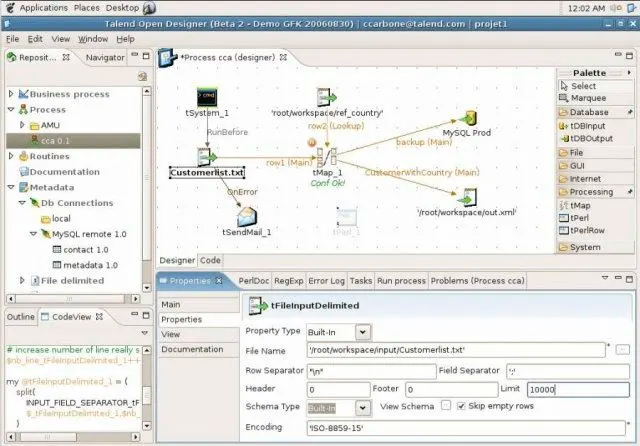
Als Open-Source-Tool ist TOS eine erschwingliche Option mit einer Vielzahl von Datenverbindungen, einschließlich RDBMS- und SaaS-Verbindungen. Die Plattform profitiert außerdem von einer aktiven Open-Source-Community, die regelmäßig zur Dokumentation beiträgt und Support leistet.
7. Pentaho Datenintegration (PDI)
Pentaho Data Integration (PDI) ist ein ETL-Tool, das von Hitachi angeboten wird. Es erfasst Daten aus verschiedenen Quellen, bereinigt sie und speichert sie in einem einheitlichen und konsistenten Format.
PDI war früher unter dem Namen Kettle bekannt und bietet mehrere grafische Benutzeroberflächen zur Definition von Datenpipelines. Mit dem PDI-Client Spoon kannst du Datenaufträge und -transformationen entwerfen und sie dann mit Kitchen ausführen. Der PDI-Client kann zum Beispiel für Echtzeit-ETL mit Pentaho Reporting verwendet werden.
8. Hadoop
Hadoop ist ein Open-Source-Framework zur Verarbeitung und Speicherung von Big Data in Clustern von Computerservern. Sie gilt als die Grundlage von Big Data und ermöglicht die Speicherung und Verarbeitung großer Datenmengen.
Das Hadoop-Framework besteht aus mehreren Modulen, darunter das Hadoop Distributed File System (HDFS) zum Speichern von Daten, MapReduce zum Lesen und Umwandeln von Daten und YARN für die Ressourcenverwaltung. Hive wird häufig verwendet, um SQL-Abfragen in MapReduce-Operationen umzuwandeln.
Unternehmen, die Hadoop in Betracht ziehen, sollten sich über die Kosten im Klaren sein. Ein erheblicher Teil der Kosten für die Implementierung von Hadoop entsteht durch die für die Verarbeitung benötigte Rechenleistung und das für die Wartung von Hadoop ETL erforderliche Fachwissen, nicht durch die Tools oder den Speicher selbst.
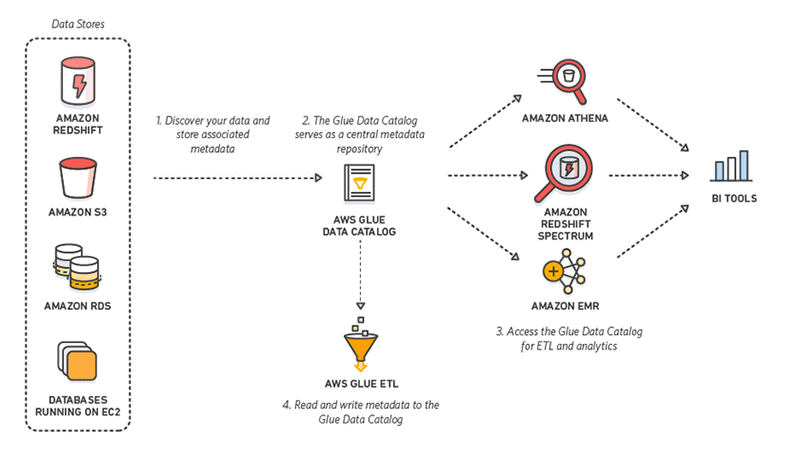
9. AWS-Kleber
AWS Glue ist ein serverloses ETL-Tool, das von Amazon angeboten wird. Sie entdeckt, bereitet auf, integriert und transformiert Daten aus verschiedenen Quellen für Analysezwecke. Da keine Infrastruktur eingerichtet oder verwaltet werden muss, verspricht AWS Glue, die hohen Kosten der Datenintegration zu senken.
Noch besser: Bei der Interaktion mit AWS Glue können Praktiker zwischen einer Drag-and-Down-GUI, einem Jupyter-Notizbuch oder Python/Scala-Code wählen. AWS Glue bietet außerdem Unterstützung für verschiedene Datenverarbeitungs- und Arbeitslasten, die unterschiedlicheGeschäftsanforderungen erfüllen, darunter ETL, ELT, Batch und Streaming.
10. AWS Daten-Pipeline
Die AWS Data Pipeline ist ein verwalteter ETL-Service, der die Übertragung von Daten zwischen AWS-Diensten und lokalen Ressourcen ermöglicht. Die Nutzer können die zu verschiebenden Daten, Transformationsjobs oder Abfragen und einen Zeitplan für die Durchführung der Transformationen festlegen.
Die Data Pipeline ist knannt für ihre Zuverlässigkeit, Flexibilität und Skalierbarkeit sowie ihre Fehlertoleranz und Konfigurierbarkeit. Die Plattform bietet außerdem eine Drag-and-Drop-Konsole für eine einfache Nutzung. Außerdem ist es relativ preiswert.
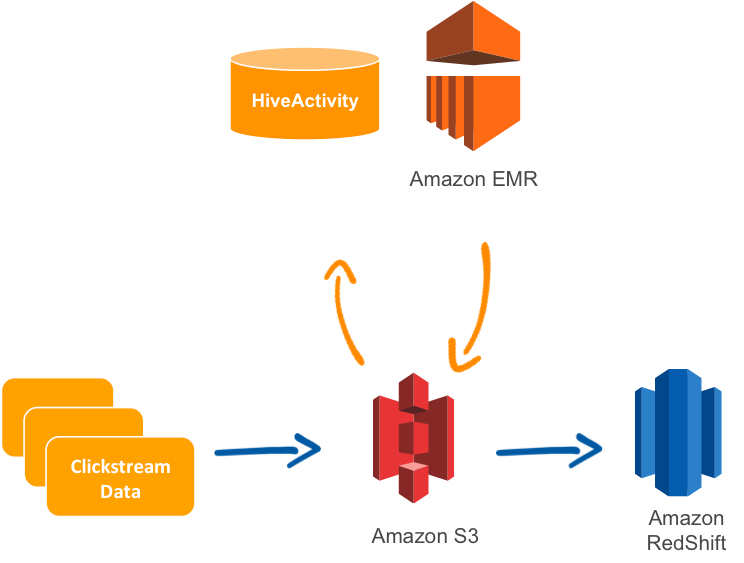
Ein häufiger Anwendungsfall für die AWS Data Pipeline ist die Replikation von Daten aus dem Relational Database Service (RDS) und das Laden in Amazon Redshift.
Es ist erwähnenswert, dass AWS im Jahr 2022 das Konzept der Zero-ETL eingeführt hat, was bedeutet, dass einige der Dienste ohne Datenpipelines integriert werden können. Amazon Aurora kann zum Beispiel automatisch Daten mit Redshift synchronisieren.
11. Azure Data Factory
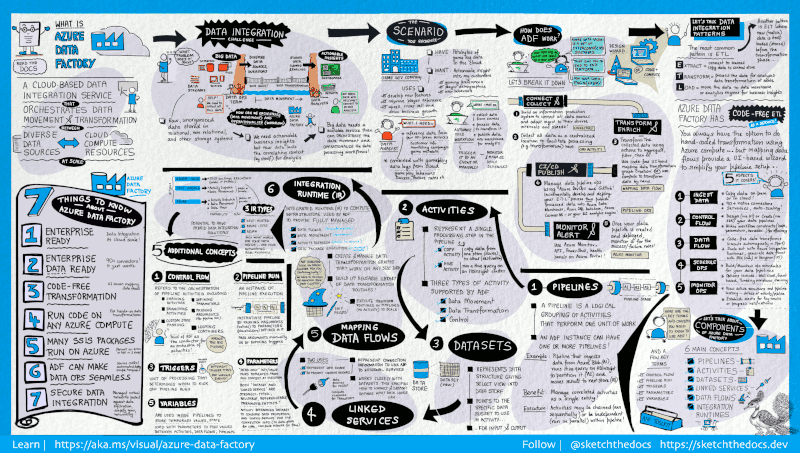
Azure Data Factory ist ein cloudbasierter ETL-Dienst von Microsoft, mit dem Workflows erstellt werden können, die Daten in großem Umfang bewegen und umwandeln.
Es besteht aus einer Reihe miteinander verbundenerstems. Mit diesen Systemen können Ingenieurinnen und Ingenieure nicht nurDaten in einlesenund umwandeln, sondern auch Datenpipelines entwerfen, planen und überwachen .
Die Stärke von Data Factory liegt in der schieren Anzahl der verfügbaren Konnektoren, von MySQL über AWS und MongoDB bis hin zu Salesforce und SAP. Außerdem wird es für seine Flexibilität gelobt: Die Nutzer können wählen, ob sie mit einer grafischen Benutzeroberfläche ohne Code oder mit einer Befehlszeilenschnittstelle arbeiten möchten.
12. Google Cloud Dataflow
Dataflow ist der serverlose ETL-Dienst, der von Google Cloud angeboten wird. Es ermöglicht sowohl die Stream- als auch die Stapelverarbeitung von Daten und erfordert nicht, dass Unternehmen einen eigenen Server oder Cluster besitzen. Stattdessen zahlen die Nutzer nur für die verbrauchten Ressourcen, die automatisch je nach Bedarf und Arbeitslast skaliert werden.
Google Dataflow führt Apache Beam-Pipelines innerhalb des Google Cloud Platform-Ökosystems aus. Apache bietet Java-, Python- und Go-SDKs für die Darstellung und Übertragung von Datensätzen, sowohl für Batch als auch für Streaming. So können die Nutzer das passende SDK für die Definition ihrer Datenpipelines wählen.
13. Stitch
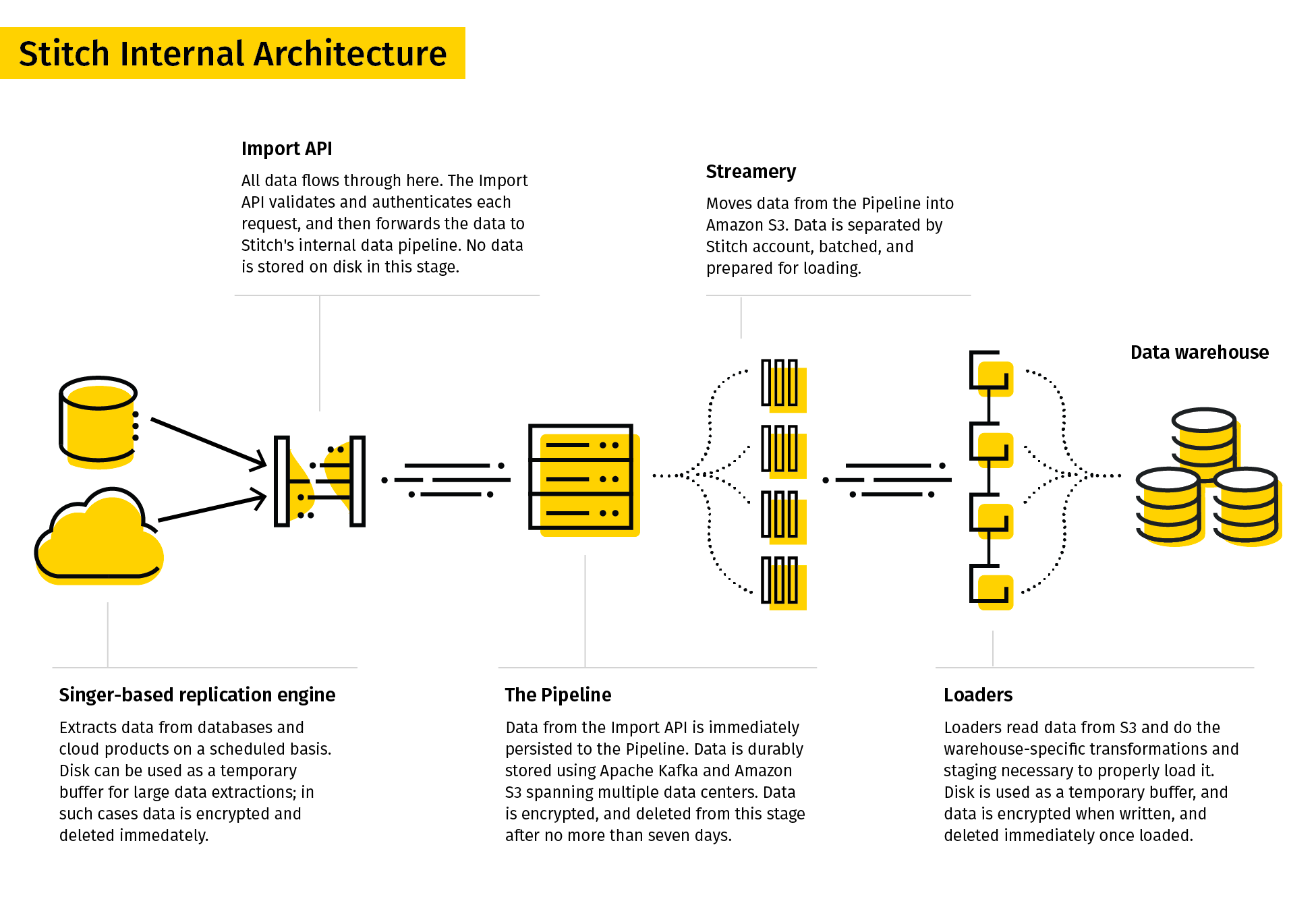
Stitch beschreibt sich selbst als ein einfaches, erweiterbares ETL-Tool, das für Datenteams entwickelt wurde.
Der Replikationsprozess von Stitch extrahiert Daten aus verschiedenen Datenquellen, wandelt sie in ein brauchbares Rohformat um und lädt sie in das Ziel. Die Datenverbindungen umfassten Datenbanken und SaaS-Anwendungen. Zu den Zielen können Data Lakes, Data Warehousesund Speicherplattformen gehören.
Aufgrund seiner Einfachheit unterstützt Stitch nur einfache Transformationen und keine benutzerdefinierten Transformationen.
14. SAP BusinessObjects Data Services
SAP BusinessObjects Data Services ist ein ETL-Tool für Unternehmen, mit dem Benutzer Daten aus verschiedenen Systemen extrahieren, umwandeln und in Data Warehouses laden können.
Der Data Services Designer bietet eine grafische Benutzeroberfläche zur Definition von Datenpipelines und zur Festlegung von Datentransformationen. Regeln und Metadaten werden in einem Repository gespeichert, und ein Jobserver führt den Job im Batch oder in Echtzeit aus.
SAP-Datendienste können jedoch teuer sein, denn die Kosten für das Tool, den Server, die Hardware und das Entwicklungsteam können sich schnell summieren.
SAP Data Services eignet sich gut für Unternehmen, die SAP als ihr Enterprise Resource Planning (ERP)-System verwenden, da es sich nahtlos in SAP Data Services integrieren lässt
15. Hevo
Hevo ist eine Datenintegrationsplattform für ETL und ELT, die mit über 150 Konnektoren für die Extraktion von Daten aus verschiedenen Quellen ausgestattet ist. Es ist ein Low-Code-Tool, das es den Nutzern leicht macht, Datenpipelines zu entwerfen, ohne dass sie umfangreiche Programmierkenntnisse benötigen.
Hevo bietet eine Reihe von Funktionen und Vorteilen, darunter Datenintegration in Echtzeit, automatische Schemaerkennung und die Fähigkeit, große Datenmengen zu verarbeiten. Die Plattform verfügt außerdem über eine benutzerfreundliche Oberfläche und einen 24/7-Kundenservice.
16. Qlik Compose
Qlik Compose ist eine Data Warehousing-Lösung, die automatisch Data Warehouses entwirft und ETL-Code generiert. Dieses Tool automatisiert die mühsame und fehleranfällige ETL-Entwicklung und -Wartung. Dadurch verkürzt sich die Vorlaufzeit von Data-Warehousing-Projekten.
Dazu führt Qlik Compose den automatisch generierten Code aus, der die Daten aus den Quellen lädt und sie in die Data Warehouses verschiebt. Solche Workflows können mit dem Workflow Designer und dem Scheduler entworfen und geplant werden.
Qlik Compose bietet außerdem die Möglichkeit, die Daten zu validieren und die Datenqualität sicherzustellen. Praktiker, die Daten in Echtzeit benötigen, können Compose auch mit Qlik Replicate integrieren .
17. Integrate.io
Integrate.io, früher bekannt als Xplenty, hat sich einen wohlverdienten Platz auf unserer Liste der besten ETL-Tools verdient. Seine benutzerfreundliche, intuitive Oberfläche öffnet die Tür zu einem umfassenden Datenmanagement, auch für Teammitglieder mit weniger technischem Know-how. Als Cloud-basierte Plattform macht Integrate.io sperrige Hardware- oder Software-Installationen überflüssig und bietet eine hoch skalierbare Lösung, die sich mit den Anforderungen deines Unternehmens weiterentwickelt.
Seine Fähigkeit, sich mit einer Vielzahl von Datenquellen zu verbinden, von Datenbanken bis hin zu CRM-Systemen, macht es zu einer vielseitigen Wahl für verschiedene Datenintegrationsanforderungen. Da die Datensicherheit im Vordergrund steht, bietet sie Funktionen wie Verschlüsselung auf Feldebene und erfüllt wichtige Standards wie GDPR und HIPAA. Mit den leistungsstarken Funktionen zur Datenumwandlung können Nutzer ihre Daten im Rahmen des ETL-Prozesses problemlos bereinigen, formatieren und anreichern.
18. Airbyte
Airbyte ist eine führende Open-Source-ELT-Plattform. Airbyte bietet den größten Katalog an Datenkonnektoren - 350 mit steigender Tendenz - und wird ab Juni 2023 von 40.000 Dateningenieuren genutzt.
Airbyte ist mit dbt für die Datenumwandlung und Airflow / Prefect / Dagster für die Orchestrierung integriert. Es hat eine einfach zu bedienende Benutzeroberfläche und verfügt über eine API und einen Terraform Provider.
Airbyte unterscheidet sich von anderen Anbietern durch seine Offenheit: Es dauert nur 20 Minuten, um einen neuen Connector mit dem No-Code-Connector-Builder zu erstellen, und du kannst jeden Standard-Connector bearbeiten, wenn du Zugang zu seinem Code hast. Zusätzlich zu seiner Open-Source-Version bietet Airbyte sowohl eine in der Cloud gehostete (Airbyte Cloud) als auch eine kostenpflichtige, selbst gehostete Version (Airbyte Enterprise) an, wenn du deine Pipelines produktiv machen willst.
19. Astera Centerprise
Astera Centerprise ist ein 100% codefreies ETL/ELT-Tool der Enterprise-Klasse. Als Teil des Astera Data Stack verfügt Centerprise über eine intuitive und benutzerfreundliche Oberfläche, die eine kurze Lernkurve aufweist und es Nutzern aller technischen Niveaus ermöglicht, innerhalb weniger Minuten Datenpipelines zu erstellen.
Das automatisierte Datenintegrationstool bietet eine Reihe von Funktionen, wie z. B. eine sofortige Verbindung zu verschiedenen Datenquellen und -zielen, KI-gestützte Datenextraktion, KI-Auto-Mapping, integrierte erweiterte Transformationen und Datenqualitätsfunktionen. Nutzer können unstrukturierte und strukturierte Daten einfach extrahieren, umwandeln und mithilfe von Datenflüssen in das Ziel ihrer Wahl laden. Diese Datenflüsse können mit dem eingebauten Job Scheduler automatisiert werden, so dass sie in bestimmten Intervallen, unter bestimmten Bedingungen oder mit bestimmten Dateien ablaufen.
20. Informatica PowerCenter
Informatica PowerCenter ist eines der besten ETL-Tools auf dem Markt. Es gibt eine große Auswahl an Konnektoren für Cloud Data Warehouses und Cloud Lakes, darunter AWS, Azure, Google Cloud und SalesForce. Die Low- und No-Code-Tools sind darauf ausgelegt, Zeit zu sparen und Arbeitsabläufe zu vereinfachen.
Informatica PowerCenter umfasst mehrere Dienste, mit denen Benutzer Datenpipelines entwerfen, einsetzen und überwachen können. Der Repository Manager hilft zum Beispiel bei der Benutzerverwaltung, der Designer ermöglicht es den Benutzern, den Datenfluss von der Quelle zum Ziel festzulegen, und der Workflow Manager definiert die Reihenfolge der Aufgaben.
Verbesserung der ETL-Kompetenz deines Teams
Da Daten für den Geschäftsbetrieb immer wichtiger werden, sind effektive ETL-Prozesse entscheidend. Um wettbewerbsfähig zu bleiben, ist es wichtig, die Fähigkeiten deines Teams in Sachen Datentechnik und -management ständig zu verbessern. DataCamp for Business bietet maßgeschneiderte Lösungen, um Unternehmen dabei zu helfen, ihre Mitarbeiter/innen weiterzubilden, damit sie für die Komplexität moderner Datenanalyse gut gerüstet sind. Mit DataCamp for business kann dein Team darauf zugreifen:
- Fokussierte Lernwege: Biete deinem Team gezielte Schulungen zu ETL-Tools wie Apache Airflow, AWS und anderen an, damit es effiziente Datenpipelines entwickeln und verwalten kann.
- Praktische Erfahrung: Fördern Sie praktische Projekte, die die Datenherausforderungen Ihres Unternehmens widerspiegeln, und helfen Sie Ihrem Team, das Vertrauen und die Kompetenz aufzubauen, die es braucht, um komplexe Datenaufgaben zu bewältigen.
- Skalierbare Schulungslösungen: Entscheide dich für skalierbare Schulungsplattformen, die eine Reihe von Ressourcen im Bereich ETL und Datenmanagement anbieten, damit sich dein Team an das Wachstum deines Unternehmens anpassen kann.
- Fortschrittskontrolle: Nutze Tools, um die Entwicklung deines Teams zu überwachen und gib regelmäßig Feedback, um eine kontinuierliche Verbesserung zu gewährleisten.
Wenn du in die Fähigkeiten deines Datenteams investierst, kannst du nicht nur die ETL-Effizienz steigern, sondern auch bessere Datenstrategien entwickeln und so zum Erfolg deines Unternehmens beitragen. Fordere noch heute eine Demo an, um mehr zu erfahren.
Zusätzliche Ressourcen
Zusammenfassend lässt sich sagen, dass es viele verschiedene ETL- und Datenintegrationstools gibt, jedes mit seinen eigenen einzigartigen Funktionen und Möglichkeiten. Einige beliebte Optionen sind SSIS, Talend Open Studio, Pentaho Data Integration, Hadoop, Airflow, AWS Data Pipeline, Google Dataflow, SAP BusinessObjects Data Services und Hevo. Unternehmen, die diese Tools in Erwägung ziehen, sollten ihre spezifischen Anforderungen und ihr Budget sorgfältig prüfen, um mit die richtige Lösung für ihre Bedürfnisse zu finden. Weitere Ressourcen zu ETL-Tools und mehr findest du unter den folgenden Links:
Lass dich für deine Traumrolle als Data Engineer zertifizieren
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.

