ETL là gì?
ETL là một cách tiếp cận phổ biến để tích hợp dữ liệu và tổ chức các tầng dữ liệu. Một quy trình ETL điển hình gồm các giai đoạn sau:
- Trích xuất dữ liệu từ các nguồn
- Biến đổi dữ liệu thành các mô hình dữ liệu
- Tải dữ liệu vào các kho dữ liệu
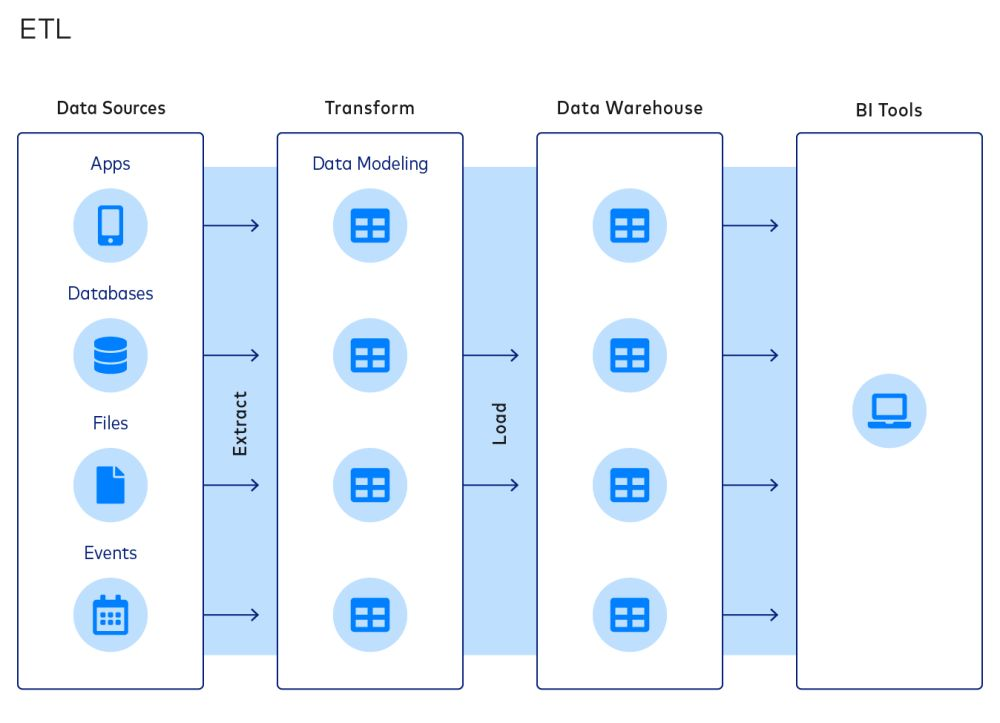
Mô hình ETL phổ biến vì cho phép công ty giảm kích thước kho dữ liệu, qua đó tiết kiệm chi phí tính toán, lưu trữ và băng thông.
Tuy nhiên, khi những ràng buộc này dần biến mất, lợi ích tiết kiệm chi phí trở nên kém quan trọng hơn. Do đó, ELT (Extract, Load, Transform) ngày càng phổ biến. Trong quy trình ELT, dữ liệu được tải đến đích sau khi trích xuất, và biến đổi là bước cuối cùng. Dù vậy, nhiều công ty vẫn dựa vào ETL.
Công cụ ETL là gì?
Đúng như tên gọi, công cụ ETL là tập hợp phần mềm dùng để trích xuất, biến đổi và tải dữ liệu từ một hoặc nhiều nguồn vào hệ thống hay cơ sở dữ liệu đích. Công cụ ETL được thiết kế để tự động hóa và đơn giản hóa quy trình trích xuất dữ liệu từ nhiều nguồn, biến đổi chúng thành định dạng thống nhất và sạch, rồi tải vào hệ thống đích một cách kịp thời và hiệu quả. Ở phần tiếp theo, chúng ta sẽ xem các yếu tố chính đội ngũ dữ liệu cần cân nhắc khi đánh giá công cụ ETL.
Các yếu tố cần cân nhắc khi chọn công cụ ETL
Dưới đây là ba yếu tố then chốt cần xét đến khi lựa chọn công cụ ETL:
- Mức độ tích hợp dữ liệu. Công cụ ETL có thể kết nối tới nhiều nguồn và đích dữ liệu. Đội ngũ dữ liệu nên chọn công cụ ETL cung cấp dải tích hợp rộng. Ví dụ, đội muốn chuyển dữ liệu từ Google Sheets sang Amazon Redshift nên chọn công cụ hỗ trợ các connector này.
- Mức độ tùy biến. Doanh nghiệp nên chọn công cụ ETL dựa trên yêu cầu về khả năng tùy biến và trình độ kỹ thuật của đội IT. Start-up có thể thấy các connector và biến đổi dựng sẵn là đủ; doanh nghiệp lớn với thu thập dữ liệu đặc thù có lẽ cần linh hoạt để tạo biến đổi theo yêu cầu với sự hỗ trợ của đội kỹ sư mạnh.
- Cấu trúc chi phí. Khi chọn công cụ ETL, tổ chức không chỉ nên cân nhắc chi phí công cụ mà còn cả chi phí hạ tầng và nhân sự để vận hành dài hạn. Trong một số trường hợp, công cụ ETL có chi phí ban đầu cao hơn nhưng ít downtime và ít bảo trì có thể hiệu quả chi phí hơn về lâu dài. Ngược lại, có các công cụ ETL mã nguồn mở miễn phí nhưng chi phí bảo trì cao.
Một số cân nhắc khác gồm:
- Mức độ tự động hóa
- Mức độ bảo mật và tuân thủ
- Hiệu năng và độ tin cậy của công cụ.
Các loại công cụ ETL
Trước khi đi vào các công cụ cụ thể, sẽ hữu ích khi hiểu các nhóm chính. Công cụ ETL có vài loại, mỗi loại phù hợp với các trường hợp sử dụng và cấu trúc đội nhóm khác nhau:
| Loại | Mô tả | Ví dụ |
|---|---|---|
| ETL mã nguồn mở | Miễn phí sử dụng, khả năng tùy biến cao, được cộng đồng hỗ trợ. Cần nhiều công sức kỹ thuật để triển khai và bảo trì. | Apache Airflow, Airbyte, Hadoop, Pentaho PDI |
| ETL dựa trên đám mây / SaaS | Được quản lý hoàn toàn, không cần hạ tầng vận hành. Tính phí theo mức sử dụng hoặc thuê bao. Chi phí vận hành thấp. | Fivetran, Stitch, Hevo, Matillion |
| ETL cho doanh nghiệp | Giàu tính năng, xây dựng cho môi trường quy mô lớn, phức tạp. Quản trị, quản lý siêu dữ liệu và tuân thủ mạnh. | Informatica PowerCenter, IBM Infosphere Datastage, SAP Data Services |
| ETL thuần đám mây (ELT) | Thiết kế cho kho dữ liệu đám mây. Đẩy logic biến đổi vào engine của kho thay vì thực hiện giữa pipeline. | AWS Glue, Azure Data Factory, Google Cloud Dataflow, Databricks DLT |
| ETL no-code / low-code | Giao diện kéo-thả cho phép người không phải kỹ sư xây pipeline. Thiết lập nhanh, nhưng kém linh hoạt cho biến đổi phức tạp. | Integrate.io, Astera Centerprise, Portable.io, Hevo |
| ETL thời gian thực / streaming | Xử lý dữ liệu khi đến thay vì theo lô theo lịch. Thiết yếu cho phân tích nhạy thời gian. | Estuary, Hevo, AWS Glue (chế độ streaming) |
24 Công Cụ ETL Hàng Đầu
Với các cân nhắc trên, dưới đây là 24 công cụ ETL hàng đầu trên thị trường năm 2026. Lưu ý các công cụ không được sắp xếp theo chất lượng, vì mỗi công cụ có điểm mạnh và điểm yếu khác nhau.
1. Apache Airflow
Apache Airflow là nền tảng mã nguồn mở để lập trình tạo, lập lịch và giám sát workflow. Nền tảng có giao diện web và giao diện dòng lệnh để quản lý và kích hoạt workflow.
Các workflow được định nghĩa bằng đồ thị có hướng không chu trình (DAG), cho phép trực quan hóa rõ ràng và quản lý tác vụ cùng phụ thuộc. Airflow cũng tích hợp với các công cụ thường dùng trong kỹ thuật dữ liệu và khoa học dữ liệu, như Apache Spark và Pandas.
Các công ty dùng Airflow có thể hưởng lợi từ khả năng mở rộng và quản lý workflow phức tạp, cùng cộng đồng mã nguồn mở năng động và tài liệu phong phú. Bạn có thể tìm hiểu thêm trong hướng dẫn Xây dựng pipeline ETL với Airflow hoặc khóa học Giới thiệu Apache Airflow bằng Python.
2. Databricks Delta Live Tables
Databricks Delta Live Tables (DLT) là một khung ETL xây dựng trên Apache Spark, tự động hóa pipeline dữ liệu (tạo và quản lý). Nó cho phép đội dữ liệu xây pipeline đáng tin cậy, dễ bảo trì và có tính khai báo với nỗ lực tối thiểu.
Delta Live Tables đơn giản hóa ETL bằng cách tiếp cận khai báo: người dùng định nghĩa cái gì (các biến đổi và phụ thuộc), và hệ thống xử lý như thế nào (thực thi, tối ưu hóa và phục hồi).
Điểm mạnh lớn của DLT nằm ở khả năng đảm bảo chất lượng và độ tin cậy dữ liệu. Các expectation dựng sẵn cho phép người dùng định nghĩa quy tắc chất lượng dữ liệu để xác thực bản ghi theo thời gian thực. Các bản ghi lỗi có thể được cách ly để xem xét sau.
3. Portable.io
Portable.io tự mô tả là "nền tảng ELT đầu tiên xây connector theo yêu cầu cho các đội dữ liệu." Đúng với sứ mệnh này, đội ngũ Portable xây các tích hợp no-code tùy chỉnh, ingest dữ liệu từ nhà cung cấp SaaS và nhiều nguồn dữ liệu khác có thể không được hỗ trợ do bị các nhà cung cấp ETL khác bỏ qua. Khách hàng tiềm năng có thể tự xem danh mục connector hơn 1.300 connector ETL khó tìm của họ.
Portable hoạt động với niềm tin rằng doanh nghiệp nên có dữ liệu từ mọi ứng dụng kinh doanh trong tầm tay mà không cần code. Đội ngũ Portable đã tạo ra sản phẩm cho phép quản lý dữ liệu hiệu quả và kịp thời, cung cấp khả năng mở rộng mạnh mẽ và hiệu năng cao. Ngoài ra, sản phẩm còn có mức giá hiệu quả chi phí phù hợp mọi quy mô doanh nghiệp và tính năng bảo mật nâng cao để đảm bảo bảo vệ dữ liệu và tuân thủ các tiêu chuẩn phổ biến.
4. IBM Infosphere Datastage
Infosphere Datastage là công cụ ETL do IBM cung cấp trong hệ sinh thái Infosphere Information Server. Với khung đồ họa, người dùng có thể thiết kế pipeline trích xuất dữ liệu từ nhiều nguồn, thực hiện biến đổi phức tạp và chuyển dữ liệu đến ứng dụng đích.
IBM Infosphere được biết đến với tốc độ, nhờ các tính năng như cân bằng tải và song song hóa. Nó cũng hỗ trợ siêu dữ liệu, phát hiện lỗi tự động và nhiều dịch vụ dữ liệu, từ kho dữ liệu đến ứng dụng AI.
Giống các công cụ ETL doanh nghiệp khác, Infosphere Datastage cung cấp nhiều connector để tích hợp các nguồn dữ liệu khác nhau. Nó cũng tích hợp mượt với các thành phần khác của IBM Infosphere Information Server, cho phép người dùng phát triển, kiểm thử, triển khai và giám sát các job ETL.
5. Oracle Data Integrator
Oracle Data Integrator là công cụ ETL giúp người dùng xây dựng, triển khai và quản lý các kho dữ liệu phức tạp. Nó có sẵn các connector cho nhiều cơ sở dữ liệu, bao gồm Hadoop, EREP, CRM, XML, JSON, LDAP, JDBC và ODBC.
ODI bao gồm Data Integrator Studio, cung cấp cho người dùng nghiệp vụ và nhà phát triển quyền truy cập nhiều hiện vật qua giao diện đồ họa. Các hiện vật này bao trùm mọi yếu tố tích hợp dữ liệu, từ di chuyển, đồng bộ, chất lượng đến quản trị dữ liệu.
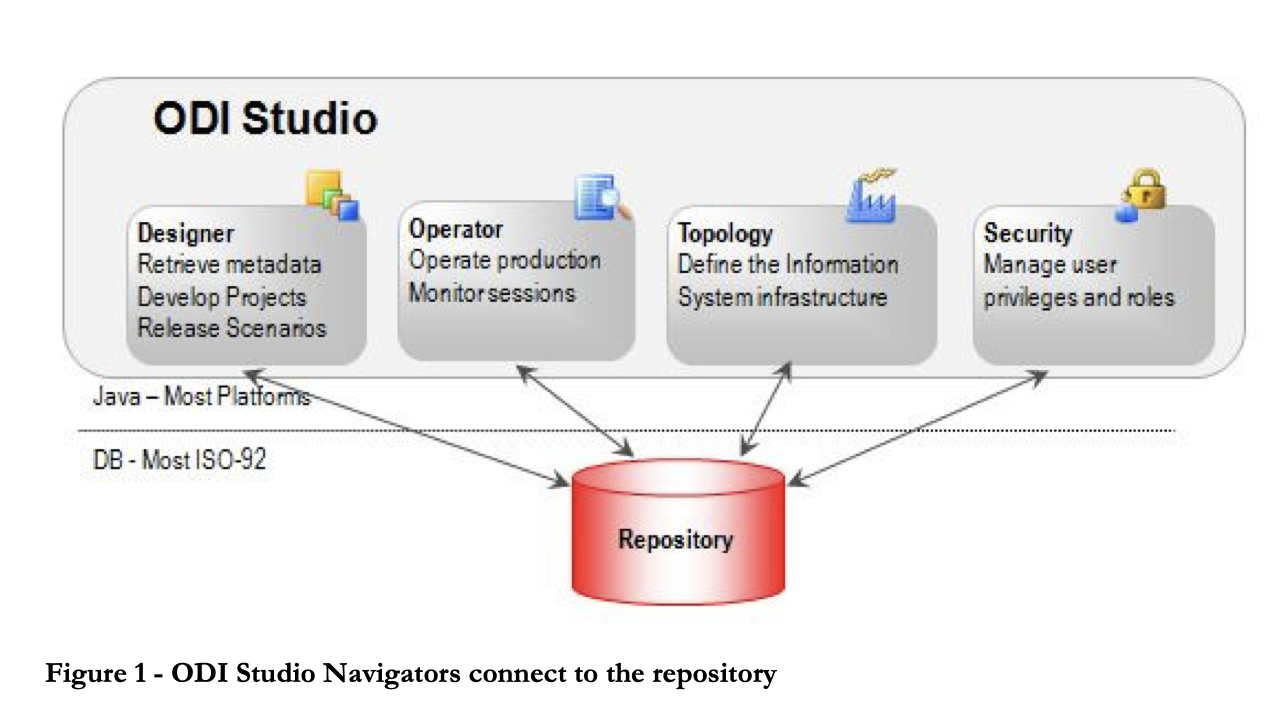
6. Microsoft SQL Server Integration Services (SSIS)
SSIS là nền tảng cấp doanh nghiệp cho tích hợp và biến đổi dữ liệu. Nó đi kèm các connector để trích xuất dữ liệu từ các nguồn như tệp XML, tệp phẳng và cơ sở dữ liệu quan hệ. Người thực hành có thể dùng giao diện đồ họa của SSIS Designer để xây luồng dữ liệu và biến đổi.
Nền tảng có thư viện biến đổi dựng sẵn giúp giảm lượng code cần cho phát triển. SSIS cũng cung cấp tài liệu toàn diện để xây workflow tùy chỉnh. Tuy nhiên, đường cong học tập dốc và độ phức tạp của nền tảng có thể khiến người mới nản lòng khi tạo pipeline ETL nhanh chóng.
7. dbt (data build tool)
dbt (data build tool) đã trở thành tiêu chuẩn ngành cho lớp biến đổi trong pipeline ELT hiện đại. Thay vì biến đổi dữ liệu giữa chừng khi trích xuất, dbt biến đổi dữ liệu bên trong kho dữ liệu bằng SQL — cách tiếp cận được gọi là “T trong ELT”.
dbt cho phép data engineer và analytics engineer viết các mô hình SQL dạng mô-đun, kiểm soát phiên bản và được kiểm thử. Mỗi mô hình đều có tài liệu, phụ thuộc được theo dõi, và mỗi lần chạy tạo một đồ thị phả hệ dữ liệu cho thấy chính xác luồng dữ liệu từ nguồn thô đến bảng cuối. Tìm hiểu thêm trong giới thiệu dbt, hướng dẫn khái niệm dbt cho data engineer, và hướng dẫn dbt Cloud.
dbt có sẵn dạng mã nguồn mở (dbt Core, miễn phí) hoặc dịch vụ đám mây quản lý đầy đủ (dbt Cloud). Nó tích hợp với mọi kho dữ liệu đám mây lớn — Snowflake, BigQuery, Redshift và Databricks — và kết hợp tự nhiên với công cụ ingestion như Fivetran và Airbyte để tạo thành một stack ELT hiện đại hoàn chỉnh.
8. Pentaho Data Integration (PDI)
Pentaho Data Integration (PDI) là công cụ ETL do Hitachi cung cấp. Nó thu thập dữ liệu từ nhiều nguồn, làm sạch và lưu trữ theo định dạng thống nhất, nhất quán.
Trước đây gọi là Kettle, PDI có nhiều giao diện đồ họa để định nghĩa pipeline dữ liệu. Người dùng có thể thiết kế job và biến đổi bằng client PDI, Spoon, rồi chạy bằng Kitchen. Ví dụ, client PDI có thể dùng cho ETL thời gian thực với Pentaho Reporting.
9. Hadoop
Hadoop là khung mã nguồn mở để xử lý và lưu trữ dữ liệu lớn trên các cụm máy chủ. Nó được coi là nền tảng của big data và cho phép lưu trữ, xử lý lượng dữ liệu khổng lồ.
Khung Hadoop gồm nhiều module, bao gồm Hệ thống tệp phân tán Hadoop (HDFS) để lưu trữ, MapReduce để đọc và biến đổi dữ liệu, và YARN để quản lý tài nguyên. Hive thường được dùng để chuyển truy vấn SQL thành các tác vụ MapReduce.
Các công ty cân nhắc Hadoop nên lưu ý chi phí của nó. Phần chi phí lớn khi triển khai Hadoop đến từ sức mạnh tính toán cần cho xử lý và chuyên môn để vận hành ETL trên Hadoop, hơn là từ công cụ hay lưu trữ.
10. AWS Glue
AWS Glue là công cụ ETL serverless do Amazon cung cấp. Nó phát hiện, chuẩn bị, tích hợp và biến đổi dữ liệu từ nhiều nguồn cho các trường hợp phân tích. Không cần thiết lập hay quản lý hạ tầng, AWS Glue hứa hẹn giảm mạnh chi phí tích hợp dữ liệu.
Hơn nữa, khi tương tác với AWS Glue, người dùng có thể chọn giữa GUI kéo-thả, Jupyter notebook, hoặc code Python/Scala. AWS Glue cũng hỗ trợ nhiều kiểu xử lý dữ liệu và khối lượng công việc đáp ứng các nhu cầu khác nhau, bao gồm ETL, ELT, batch và streaming.
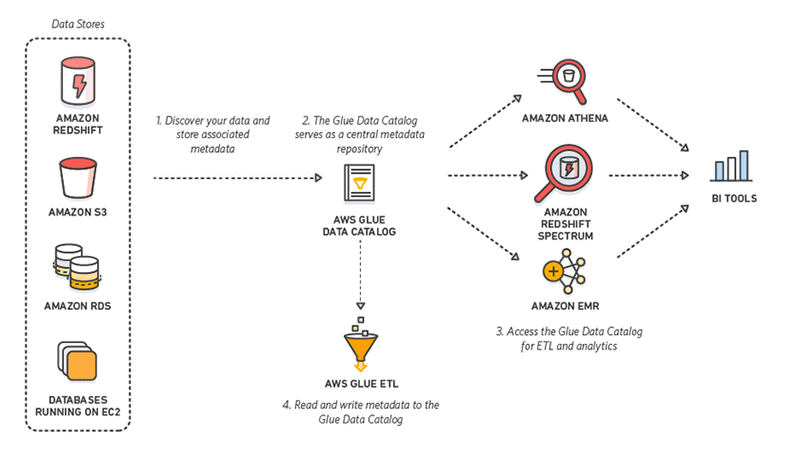
11. AWS Data Pipeline
AWS Data Pipeline là dịch vụ ETL được quản lý, cho phép di chuyển dữ liệu giữa các dịch vụ AWS hoặc tài nguyên on-premises. Người dùng có thể chỉ định dữ liệu cần di chuyển, các job biến đổi hoặc truy vấn, và lịch thực hiện biến đổi.
Data Pipeline được biết đến nhờ độ tin cậy, linh hoạt, khả năng mở rộng, cũng như khả năng chịu lỗi và cấu hình. Nền tảng còn có bảng điều khiển kéo-thả dễ dùng. Thêm vào đó, chi phí tương đối thấp.
Một trường hợp sử dụng phổ biến của AWS Data Pipeline là sao chép dữ liệu từ Relational Database Service (RDS) và tải lên Amazon Redshift.
Tuy nhiên, cần lưu ý rằng AWS đang dần chuyển trọng tâm khỏi AWS Data Pipeline để ưu tiên các giải pháp hiện đại hơn như AWS Glue. AWS Glue cung cấp tích hợp dữ liệu tự động, serverless, hỗ trợ cả batch và streaming. Ngoài ra, AWS đang khám phá khái niệm zero-ETL (và Reverse ETL), nơi các dịch vụ như Amazon Aurora và Amazon Redshift có thể tích hợp mà không cần pipeline ETL truyền thống. Khi các tiến bộ này tiếp diễn, AWS Data Pipeline được kỳ vọng sẽ dần bị loại bỏ, khuyến khích người dùng chuyển sang các giải pháp đổi mới và hiệu quả hơn trong hệ sinh thái AWS.
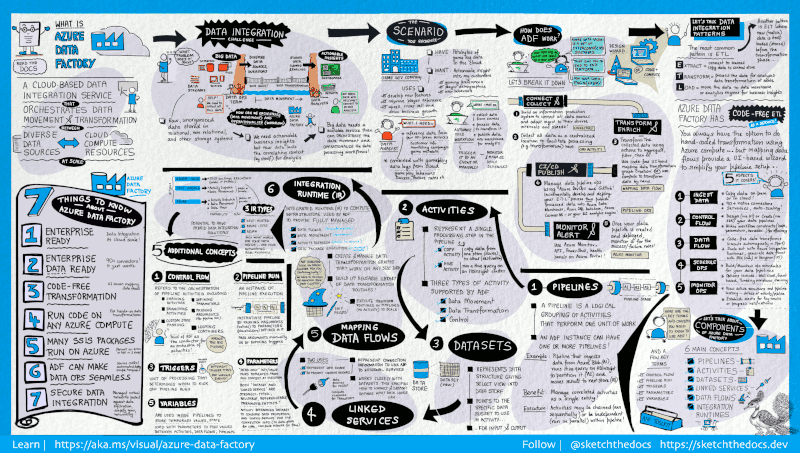
12. Azure Data Factory
Azure Data Factory là dịch vụ ETL trên đám mây do Microsoft cung cấp, dùng để tạo workflow di chuyển và biến đổi dữ liệu ở quy mô lớn.
Nó gồm một chuỗi các hệ thống liên kết. Kết hợp lại, các hệ thống này cho phép kỹ sư không chỉ ingest và biến đổi dữ liệu mà còn thiết kế, lập lịch và giám sát pipeline dữ liệu.
Điểm mạnh của Data Factory nằm ở số lượng connector sẵn có khổng lồ, từ MySQL đến AWS, MongoDB, Salesforce và SAP. Nó cũng được đánh giá cao về tính linh hoạt; người dùng có thể chọn giao diện đồ họa no-code hoặc giao diện dòng lệnh.
13. Google Cloud Dataflow
Dataflow là dịch vụ ETL serverless do Google Cloud cung cấp. Nó cho phép xử lý dữ liệu cả streaming và batch, và không yêu cầu doanh nghiệp sở hữu server hay cụm máy. Thay vào đó, người dùng chỉ trả tiền cho tài nguyên tiêu thụ, tự động mở rộng theo nhu cầu và khối lượng công việc.
Google Dataflow chạy các pipeline Apache Beam trong hệ sinh thái Google Cloud Platform. Apache cung cấp SDK Java, Python và Go để biểu diễn và truyền tập dữ liệu, cả batch và streaming. Điều này cho phép người dùng chọn SDK phù hợp để định nghĩa pipeline dữ liệu.
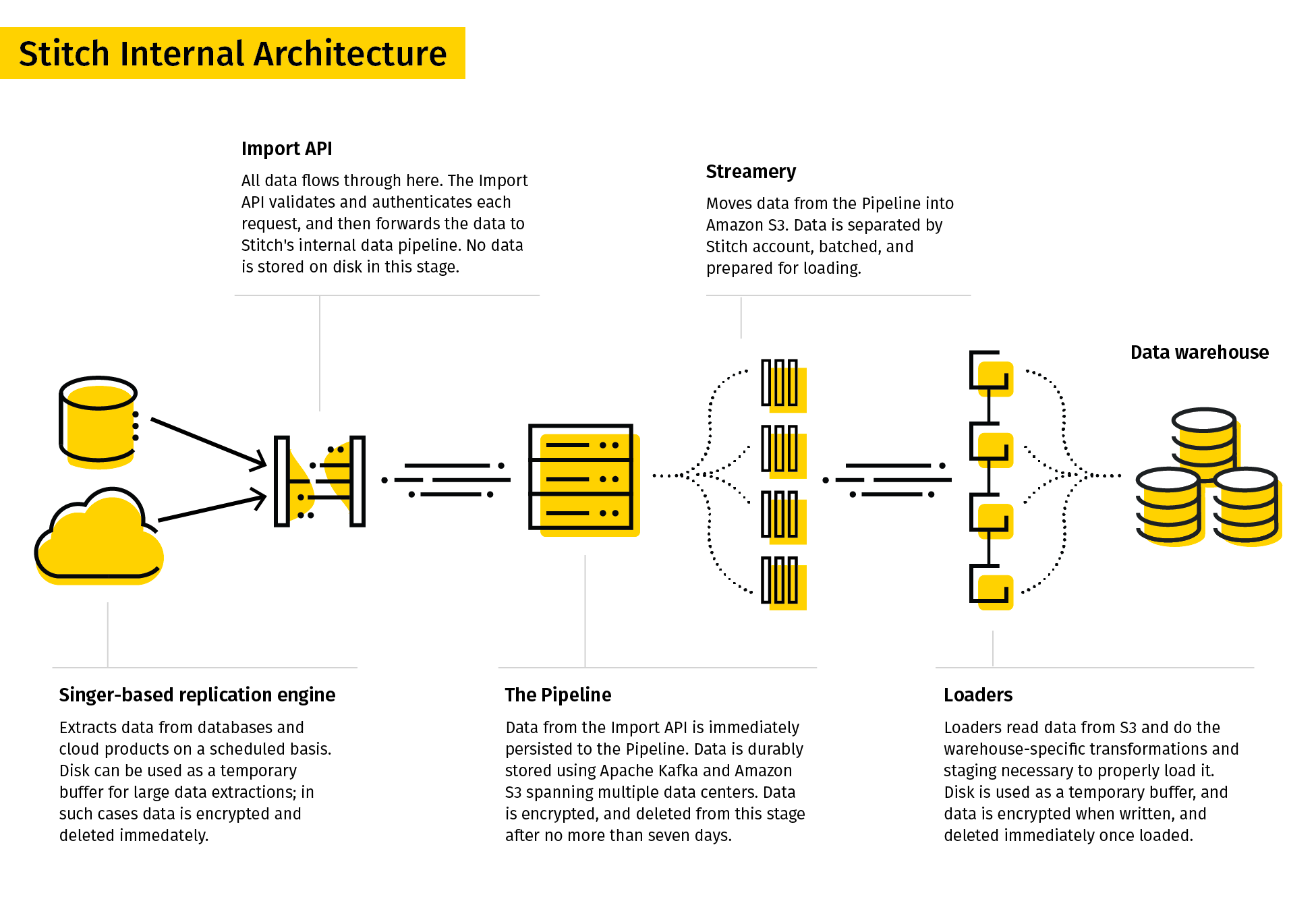
14. Stitch
Stitch tự mô tả là công cụ ETL đơn giản, dễ mở rộng, xây dựng cho đội dữ liệu.
Quy trình sao chép của Stitch trích xuất dữ liệu từ nhiều nguồn, biến đổi thành định dạng thô hữu ích, và tải vào đích. Các connector dữ liệu của nó bao gồm cơ sở dữ liệu và ứng dụng SaaS. Đích có thể là data lake, kho dữ liệu và nền tảng lưu trữ.
Do tính đơn giản, Stitch chỉ hỗ trợ biến đổi đơn giản và không hỗ trợ biến đổi do người dùng định nghĩa.
15. SAP BusinessObjects Data Services
SAP BusinessObjects Data Services là công cụ ETL cấp doanh nghiệp cho phép người dùng trích xuất dữ liệu từ nhiều hệ thống, biến đổi và tải vào kho dữ liệu.
Data Services Designer cung cấp giao diện đồ họa để định nghĩa pipeline và chỉ định biến đổi dữ liệu. Quy tắc và siêu dữ liệu được lưu trong kho, và máy chủ job chạy job theo lô hoặc thời gian thực.
Tuy nhiên, SAP Data Services có thể tốn kém, vì chi phí công cụ, máy chủ, phần cứng và đội kỹ sư có thể tăng nhanh.
SAP Data Services phù hợp với công ty dùng SAP làm hệ thống ERP (Enterprise Resource Planning), vì nó tích hợp mượt với SAP Data Services
16. Hevo
Hevo là nền tảng tích hợp dữ liệu cho ETL và ELT, đi kèm hơn 150 connector để trích xuất dữ liệu từ nhiều nguồn. Đây là công cụ low-code, giúp người dùng dễ dàng thiết kế pipeline mà không cần nhiều kinh nghiệm lập trình.
Hevo cung cấp nhiều tính năng và lợi ích, bao gồm tích hợp dữ liệu thời gian thực, tự động phát hiện schema, và khả năng xử lý khối lượng dữ liệu lớn. Nền tảng cũng có giao diện thân thiện và hỗ trợ khách hàng 24/7.
17. Qlik Compose
Qlik Compose là giải pháp kho dữ liệu tự động thiết kế kho dữ liệu và tạo mã ETL. Công cụ này tự động hóa việc phát triển và bảo trì ETL vốn dễ lặp lại và dễ lỗi, giúp rút ngắn thời gian triển khai dự án kho dữ liệu.
Để làm được điều đó, Qlik Compose chạy mã sinh tự động, tải dữ liệu từ nguồn và chuyển sang kho dữ liệu. Các workflow có thể được thiết kế và lập lịch bằng Workflow Designer và Scheduler.
Qlik Compose cũng có khả năng xác thực dữ liệu và đảm bảo chất lượng dữ liệu. Người dùng cần dữ liệu thời gian thực có thể tích hợp Compose với Qlik Replicate.
18. Integrate.io
Integrate.io, trước đây là Xplenty, xứng đáng góp mặt trong danh sách công cụ ETL hàng đầu. Giao diện thân thiện, trực quan của nó mở ra khả năng quản trị dữ liệu toàn diện, ngay cả với thành viên ít chuyên môn kỹ thuật. Là nền tảng đám mây, Integrate.io loại bỏ nhu cầu cài đặt phần cứng hay phần mềm cồng kềnh và cung cấp giải pháp có khả năng mở rộng cao theo nhu cầu doanh nghiệp.
Khả năng kết nối với nhiều nguồn dữ liệu, từ cơ sở dữ liệu đến hệ thống CRM, khiến nó trở thành lựa chọn linh hoạt cho nhiều nhu cầu tích hợp. Ưu tiên bảo mật dữ liệu, nó cung cấp tính năng như mã hóa cấp trường và tuân thủ các tiêu chuẩn quan trọng như GDPR và HIPAA. Với năng lực biến đổi dữ liệu mạnh mẽ, người dùng có thể dễ dàng làm sạch, định dạng và làm giàu dữ liệu trong quy trình ETL.
19. Airbyte
Airbyte là nền tảng ELT mã nguồn mở hàng đầu. Airbyte cung cấp hơn 400 connector dữ liệu — và đang tăng — với hơn 40.000 kỹ sư dữ liệu sử dụng.
Airbyte tích hợp với dbt cho biến đổi dữ liệu và Airflow / Prefect / Dagster cho điều phối. Nó có giao diện dễ dùng, cùng API và Terraform Provider sẵn có.
Điểm khác biệt của Airbyte là tính mã nguồn mở; chỉ mất 20 phút để tạo connector mới với công cụ xây connector no-code, và bạn có thể chỉnh sửa bất kỳ connector đóng gói sẵn nào nếu có quyền truy cập mã. Bên cạnh bản mã nguồn mở, Airbyte còn cung cấp bản cloud (Airbyte Cloud) và bản tự triển khai trả phí (Airbyte Enterprise) khi bạn muốn đưa pipeline vào vận hành sản xuất.
20. Astera Centerprise
Astera Centerprise là công cụ ETL/ELT cấp doanh nghiệp, 100% không cần code. Là một phần của Astera Data Stack, Centerprise có giao diện trực quan, thân thiện, dễ học và cho phép người dùng ở mọi mức kỹ thuật xây pipeline trong vài phút.
Công cụ tích hợp dữ liệu tự động này cung cấp nhiều khả năng như kết nối sẵn đến nhiều nguồn và đích dữ liệu, trích xuất dữ liệu dùng AI, ánh xạ tự động bằng AI, các biến đổi nâng cao dựng sẵn và tính năng chất lượng dữ liệu. Người dùng có thể dễ dàng trích xuất dữ liệu phi cấu trúc và có cấu trúc, biến đổi và tải vào đích mong muốn bằng dataflow. Các dataflow này có thể tự động chạy theo khoảng thời gian, điều kiện hoặc khi có tệp mới nhờ bộ lập lịch job tích hợp.
21. Informatica PowerCenter
Informatica PowerCenter là một trong những công cụ ETL tốt nhất trên thị trường. Nó có dải connector rộng cho kho và hồ dữ liệu đám mây, bao gồm AWS, Azure, Google Cloud và Salesforce. Các công cụ low-code và no-code của nó được thiết kế để tiết kiệm thời gian và đơn giản hóa workflow.
Informatica PowerCenter bao gồm nhiều dịch vụ cho phép người dùng thiết kế, triển khai và giám sát pipeline dữ liệu. Ví dụ, Repository Manager hỗ trợ quản lý người dùng, Designer cho phép chỉ định dòng chảy dữ liệu từ nguồn đến đích, và Workflow Manager định nghĩa trình tự các tác vụ.
22. Estuary
Estuary là nền tảng tích hợp dữ liệu thời gian thực tiên tiến, đơn giản hóa việc tạo và quản lý pipeline dữ liệu. Thiết kế để xử lý cả batch và streaming, Estuary cho phép bạn xây dựng workflow ETL mạnh mẽ. Giao diện trực quan giúp cả người dùng kỹ thuật và không kỹ thuật dễ tiếp cận, cho phép đội ngũ tập trung khai thác giá trị từ dữ liệu thay vì vật lộn với cấu hình phức tạp.
Khả năng tự động hóa của nền tảng nổi bật, tự động quản lý tiến hóa schema và thích ứng với thay đổi cấu trúc dữ liệu một cách dễ dàng. Với tích hợp đến nhiều nguồn và đích dữ liệu, Estuary phù hợp với các đội cần phân tích thời gian thực, dù là theo dõi xu hướng bán hàng trong thương mại điện tử hay phân tích dữ liệu cảm biến trong ứng dụng IoT.
23. Fivetran
Fivetran đã nổi lên như giải pháp ETL hàng đầu cho tích hợp dữ liệu tự động hoàn toàn, cho phép doanh nghiệp tập trung hóa dữ liệu. Tận dụng thư viện connector dựng sẵn, Fivetran rút ngắn thời gian thiết lập, kết nối cơ sở dữ liệu, ứng dụng SaaS và luồng sự kiện tới kho dữ liệu đám mây. Nền tảng nổi bật ở khả năng tự động xử lý thay đổi schema, đảm bảo dữ liệu luân chuyển mượt mà ngay cả khi hệ thống nguồn thay đổi.
Với khả năng sao chép gần thời gian thực, Fivetran hỗ trợ khả dụng dữ liệu gần như tức thời. Tối ưu cho môi trường thuần đám mây như Snowflake, BigQuery và Redshift, Fivetran là lựa chọn hàng đầu cho đội cần đơn giản hóa pipeline dữ liệu nhưng vẫn đảm bảo khả năng mở rộng. Nó đặc biệt hữu ích cho đội marketing và bán hàng cần hợp nhất nhiều nguồn dữ liệu vào các bảng điều khiển phân tích thống nhất.
24. Matillion
Matillion là công cụ ETL thuần đám mây được thiết kế để biến đổi dữ liệu trực tiếp trong kho dữ liệu đám mây. Tối ưu cho các nền tảng như Snowflake, AWS Redshift, Google BigQuery và Azure Synapse, Matillion cung cấp cách thực hiện biến đổi dữ liệu ở quy mô lớn. Giao diện trực quan giúp người dùng dễ dàng thiết kế workflow qua môi trường kéo-thả, trong khi người dùng nâng cao có thể tận dụng biến đổi dựa trên SQL để xử lý tác vụ phức tạp.
Với trọng tâm vào khả năng mở rộng và hiệu năng, Matillion phù hợp với các đội cần xử lý biến đổi quy mô lớn một cách hiệu quả. Từ việc tạo góc nhìn khách hàng 360 độ chi tiết đến tối ưu phân tích chuỗi cung ứng, Matillion giúp chuyên gia dữ liệu khai thác tối đa hạ tầng dữ liệu đám mây mà không gặp nút thắt cổ chai thường thấy ở quy trình ETL truyền thống.
So sánh các công cụ ETL hàng đầu
Bảng sau so sánh các công cụ ETL được đề cập theo nhiều hạng mục khác nhau:
| Công cụ ETL | Mã nguồn mở | Tương thích đám mây | Dễ sử dụng | Số lượng tích hợp | Tính năng và lưu ý | Trường hợp sử dụng lý tưởng |
|---|---|---|---|---|---|---|
| Apache Airflow | Có | Có | Trung bình | Cao | Workflow dựa trên DAG, khả năng mở rộng, cộng đồng hỗ trợ lớn | Workflow phức tạp và điều phối pipeline dữ liệu nhiều bước, quy mô lớn |
| Databricks Delta Live Tables | Không | Có | Cao | Cao | Thiết kế pipeline khai báo, quản lý phụ thuộc tự động, kiểm tra chất lượng dữ liệu tích hợp | Doanh nghiệp dùng Databricks Lakehouse cần ETL tự động, tin cậy với chất lượng dữ liệu tích hợp và xử lý thời gian thực |
| Portable.io | Không | Có | Cao | Rất cao | Connector theo yêu cầu, no-code, giá thành hiệu quả | Công ty nhỏ đến vừa cần connector tùy chỉnh cho nguồn dữ liệu ít phổ biến |
| IBM Infosphere Datastage | Không | Có | Trung bình | Cao | Xử lý tốc độ cao, hỗ trợ siêu dữ liệu, cấp doanh nghiệp | Doanh nghiệp có pipeline dữ liệu đa dạng, khối lượng lớn cần quản lý siêu dữ liệu mạnh |
| Oracle Data Integrator | Không | Có | Trung bình | Cao | Nhiều connector, giao diện đồ họa, quản trị mạnh | Công ty dùng hệ sinh thái Oracle hoặc cần hỗ trợ cơ sở dữ liệu phong phú |
| Microsoft SSIS | Không | Giới hạn | Trung bình | Trung bình | Biến đổi dựng sẵn, tài liệu toàn diện | Tổ chức đã đầu tư vào Microsoft SQL Server |
| dbt (data build tool) | Có | Có | Cao | Cao | Biến đổi trong kho bằng SQL, mô hình có kiểm soát phiên bản, phả hệ dữ liệu, dbt Core (miễn phí) + dbt Cloud (quản lý) | Đội dữ liệu cần lớp biến đổi có thể kiểm thử, có tài liệu, bên trong kho dữ liệu đám mây (kết hợp với Fivetran hoặc Airbyte) |
| Pentaho Data Integration | Có | Có | Trung bình | Cao | ETL thời gian thực, giao diện đồ họa, client Spoon/Kitchen | Xử lý ETL thời gian thực cho công ty cần workflow linh hoạt dựa trên GUI |
| Hadoop | Có | Có | Thấp | Cao | Xử lý big data, HDFS, MapReduce, chi phí triển khai cao | Doanh nghiệp lớn xử lý bộ dữ liệu khổng lồ, cần lưu trữ và xử lý phân tán |
| AWS Glue | Không | Có | Cao | Cao | Serverless, hỗ trợ Python/Scala, khối lượng xử lý linh hoạt | Công ty thuần đám mây cần ETL serverless cho dữ liệu có cấu trúc và phi cấu trúc |
| AWS Data Pipeline | Không | Có | Cao | Trung bình | Dịch vụ quản lý, chịu lỗi, chi phí thấp | Quy trình ETL cơ bản trong AWS (nhưng người dùng nên cân nhắc chuyển sang AWS Glue hoặc giải pháp zero-ETL) |
| Azure Data Factory | Không | Có | Cao | Rất cao | Nhiều connector, giao diện linh hoạt, thuần đám mây | Doanh nghiệp có nguồn dữ liệu đa dạng trong hệ sinh thái Azure của Microsoft |
| Google Cloud Dataflow | Không | Có | Cao | Cao | Serverless, tích hợp Apache Beam, tiết kiệm chi phí | Xử lý dữ liệu streaming hoặc batch trong hệ sinh thái Google Cloud |
| Stitch | Không | Có | Cao | Trung bình | Biến đổi đơn giản, connector SaaS, thân thiện người dùng | Startup và đội nhỏ tập trung vào sao chép dữ liệu đơn giản vào kho dữ liệu |
| SAP BusinessObjects | Không | Có | Trung bình | Cao | Cấp doanh nghiệp, tích hợp với SAP, chi phí cao | Người dùng hệ thống SAP ERP cần tích hợp liền mạch |
| Hevo | Không | Có | Cao | Cao | Low-code, tích hợp thời gian thực, tự động phát hiện schema | Doanh nghiệp nhỏ đến vừa cần phân tích thời gian thực |
| Qlik Compose | Không | Có | Trung bình | Cao | Tự động hóa phát triển ETL, tích hợp thời gian thực với Qlik Replicate | Doanh nghiệp cần pipeline ETL tự động và tích hợp với Qlik Replicate |
| Integrate.io | Không | Có | Cao | Cao | Giao diện trực quan, không cần phần cứng, tính năng bảo mật mạnh | Công ty ưu tiên dễ sử dụng và bảo mật dữ liệu |
| Airbyte | Có | Có | Cao | Rất cao | Mã nguồn mở, tạo connector dễ dàng, tích hợp với dbt | Tổ chức tìm kiếm giải pháp ELT mã nguồn mở, có thể tùy biến |
| Astera Centerprise | Không | Có | Cao | Cao | Không cần code, trích xuất dữ liệu dùng AI, thân thiện người dùng | Doanh nghiệp cần công cụ ETL no-code với tự động hóa nhờ AI |
| Informatica PowerCenter | Không | Có | Cao | Rất cao | Công cụ low/no-code, nhiều connector, cấp doanh nghiệp | Doanh nghiệp xử lý pipeline phức tạp với nhu cầu connector rộng |
| Estuary | Không | Có | Cao | Trung bình | Tích hợp dữ liệu thời gian thực, tự động hóa, tiến hóa schema, hỗ trợ batch và streaming | Doanh nghiệp cần phân tích thời gian thực cho dữ liệu IoT hoặc thương mại điện tử |
| Fivetran | Không | Có | Cao | Rất cao | Cập nhật schema tự động, connector dựng sẵn, sao chép thời gian thực, tối ưu cho đám mây | Công ty cần sao chép dữ liệu tự động, tin cậy với can thiệp thủ công tối thiểu |
| Matillion | Không | Có | Cao | Cao | Thuần đám mây, giao diện kéo-thả, biến đổi SQL phức tạp, mở rộng theo hạ tầng đám mây | Đội tối đa hóa workflow biến đổi dữ liệu trên đám mây |
Cách chọn công cụ ETL phù hợp
Với 24 công cụ trong danh sách, việc thu hẹp lựa chọn có thể khiến bạn choáng ngợp. Dưới đây là khung ra quyết định dựa trên các hồ sơ đội ngũ phổ biến:
- Mới bắt đầu / đội nhỏ: Bắt đầu với Stitch hoặc Airbyte cho ingestion và dbt Core cho biến đổi. Cả hai đều miễn phí nếu tự triển khai và có chi phí vận hành tối thiểu.
- Đang mở rộng / công ty quy mô vừa: Fivetran + dbt Cloud là stack sản xuất phổ biến nhất năm 2026. Thêm Apache Airflow để điều phối.
- Doanh nghiệp / môi trường phức tạp: Informatica PowerCenter, IBM Infosphere Datastage hoặc Azure Data Factory cho tổ chức có hệ thống kế thừa, yêu cầu tuân thủ nghiêm ngặt và đội kỹ sư lớn.
- Hệ sinh thái AWS: AWS Glue cho ETL serverless; cân nhắc tích hợp zero-ETL giữa Amazon Aurora và Redshift để loại bỏ hoàn toàn pipeline.
- Hệ sinh thái Google Cloud: Google Cloud Dataflow cho xử lý streaming và batch trong GCP.
- Hệ sinh thái Microsoft / Azure: Azure Data Factory cho điều phối và di chuyển, kết hợp với Azure Synapse cho biến đổi.
- Người dùng không kỹ thuật / no-code: Hevo, Integrate.io hoặc Astera Centerprise cung cấp giao diện kéo-thả, gần như không cần code.
Nâng cao chuyên môn ETL cho đội ngũ của bạn
Khi dữ liệu trở thành trung tâm hoạt động kinh doanh, quy trình ETL hiệu quả là tối quan trọng. Để duy trì sức cạnh tranh, việc liên tục nâng cao kỹ năng kỹ thuật dữ liệu và quản trị là điều thiết yếu. DataCamp for Business cung cấp giải pháp phù hợp để giúp tổ chức nâng tầm kỹ năng nhân sự, đảm bảo họ được trang bị tốt để xử lý sự phức tạp của phân tích dữ liệu hiện đại. Với DataCamp for Business, đội ngũ của bạn có thể truy cập:
- Lộ trình học tập tập trung: Cung cấp cho đội ngũ khóa đào tạo nhắm mục tiêu về các công cụ ETL như Apache Airflow, AWS, và nhiều hơn nữa để cải thiện khả năng thiết kế và quản lý pipeline dữ liệu hiệu quả.
- Kinh nghiệm thực hành: Khuyến khích các dự án thực tế phản ánh thách thức dữ liệu của tổ chức bạn, giúp đội xây dựng tự tin và chuyên môn cần thiết để xử lý tác vụ phức tạp.
- Giải pháp đào tạo có khả năng mở rộng: Chọn nền tảng đào tạo có thể mở rộng, cung cấp nhiều tài nguyên về ETL và quản trị dữ liệu, đảm bảo đội có thể thích ứng khi tổ chức phát triển.
- Theo dõi tiến độ: Sử dụng công cụ theo dõi sự phát triển của đội, cung cấp phản hồi thường xuyên để đảm bảo cải thiện liên tục.
Đầu tư vào kỹ năng của đội dữ liệu không chỉ nâng cao hiệu quả ETL mà còn thúc đẩy chiến lược dữ liệu tốt hơn, góp phần vào thành công của tổ chức. Yêu cầu demo ngay hôm nay để biết thêm.
Tài nguyên bổ sung
Kết luận, có rất nhiều công cụ ETL và tích hợp dữ liệu khác nhau, mỗi công cụ có tính năng và năng lực riêng. Một số lựa chọn phổ biến gồm SSIS, Talend Open Studio, Pentaho Data Integration, Hadoop, Airflow, AWS Data Pipeline, Google Dataflow, SAP BusinessObjects Data Services và Hevo. Các công ty đang cân nhắc những công cụ này nên đánh giá cẩn thận yêu cầu cụ thể và ngân sách để chọn giải pháp phù hợp với nhu cầu. Để có thêm tài nguyên về công cụ ETL và nhiều nội dung khác, hãy xem các liên kết sau:
- ETL vs ELT: Hiểu sự khác biệt và đưa ra lựa chọn đúng
- Giải thích ELT: Tích hợp dữ liệu cho kỷ nguyên đám mây
- Reverse ETL là gì? Hướng dẫn hữu ích
- Zero-ETL là gì? Giới thiệu các cách tiếp cận mới cho tích hợp dữ liệu
- Kiến trúc kho dữ liệu: Xu hướng, công cụ và kỹ thuật
- 17 Câu hỏi phỏng vấn ETL hàng đầu và câu trả lời
- Xây dựng pipeline ETL với Airflow