Devenez ingénieur en données
Qu'est-ce que l'ETL ?
L'ETL est une approche courante de l'intégration des données et de l'organisation des piles de données. Un processus ETL typique comprend les étapes suivantes :
- Extraction de données à partir de sources
- Transformer les données en modèles de données
- Chargement des données dans les entrepôts de données
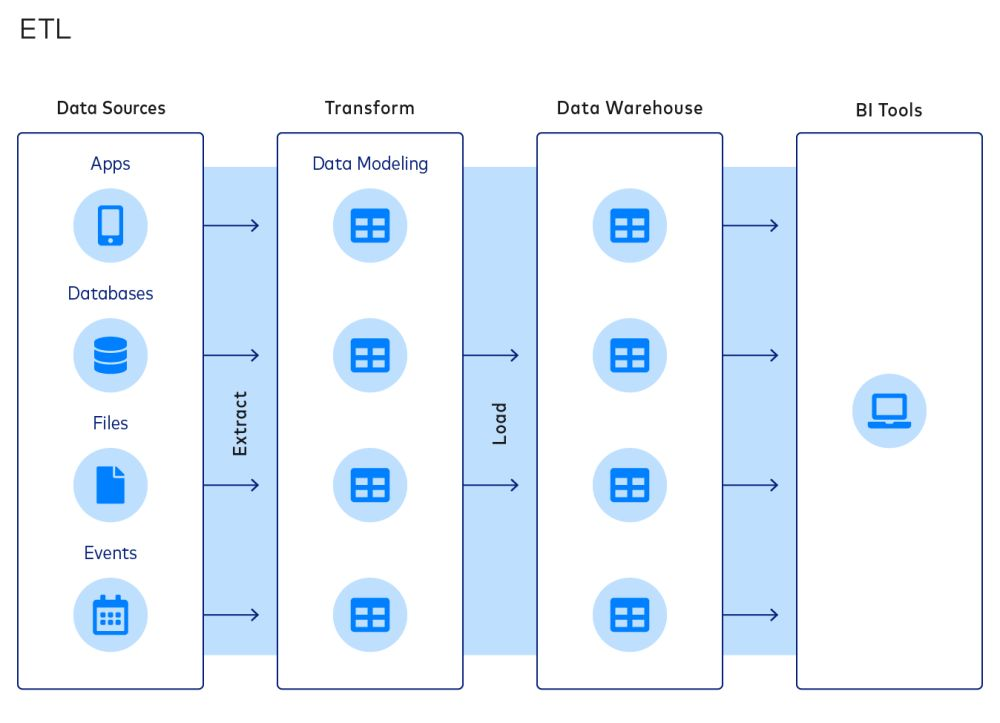
Le paradigme ETL est populaire parce qu'il permet aux entreprises de réduire la taille de leurs entrepôts de données, ce qui permet d'économiser sur les coûts de calcul, de stockage et de bande passante.
Toutefois, ces économies deviennent moins importantes à mesure que ces contraintes disparaissent. Par conséquent, l'ELT (Extract, Load, Transform) devient de plus en plus populaire. Dans le processus ELT, les données sont chargées vers une destination après extraction, et la transformation est l'étape finale du processus. Malgré cela, de nombreuses entreprises s'appuient encore sur l'ETL.
Que sont les outils ETL ?
Comme leur nom l'indique, les outils ETL sont un ensemble d'outils logiciels utilisés pour extraire, transformer et charger des données à partir d'une ou de plusieurs sources dans un système ou une base de données cible. Les outils ETL sont conçus pour automatiser et simplifier le processus d'extraction des données à partir de diverses sources, leur transformation dans un format cohérent et propre, et leur chargement dans le système cible en temps voulu et de manière efficace. Dans la section suivante, nous verrons les considérations clés que les équipes chargées des données doivent appliquer lorsqu'elles envisagent d'utiliser un outil ETL.
Considérations clés sur les outils ETL
Voici trois éléments clés à prendre en compte pour les outils ETL d'une entreprise.
- L'étendue de l'intégration des données. Les outils ETL peuvent se connecter à un grand nombre de sources de données et de destinations. Les équipes chargées des données devraient opter pour des outils ETL offrant un large éventail d'intégrations. Par exemple, les équipes qui souhaitent transférer des données de Google Sheets vers Amazon Redshift doivent choisir des outils ETL qui prennent en charge de tels connecteurs.
- Niveau de personnalisation. Les entreprises doivent choisir leurs outils ETL en fonction de leurs besoins de personnalisation et de l'expertise technique de leur équipe informatique. Une start-up peut trouver suffisants les connecteurs et les transformations intégrés dans la plupart des outils ETL ; une grande entreprise avec une collecte de données sur mesure aura probablement besoin de la flexibilité nécessaire pour créer des transformations sur mesure avec l'aide d'une solide équipe d'ingénieurs.
- Structure des coûts. Lors du choix d'un outil ETL, les organisations doivent prendre en compte non seulement le coût de l'outil lui-même, mais aussi les coûts de l'infrastructure et des ressources humaines nécessaires pour maintenir la solution à long terme. Dans certains cas, un outil ETL dont le coût initial est plus élevé mais dont les exigences en matière de temps d'arrêt et de maintenance sont moindres peut s'avérer plus rentable à long terme. À l'inverse, il existe des outils ETL gratuits et libres dont les coûts de maintenance peuvent être élevés.
D'autres considérations sont à prendre en compte :
- Le niveau d'automatisation fourni
- Le niveau de sécurité et de conformité
- La performance et la fiabilité de l'outil.
Les 20 meilleurs outils ETL pour les équipes chargées des données
En gardant ces considérations à l'esprit, nous vous présentons les 16 meilleurs outils ETL disponibles sur le marché. Notez que les outils ne sont pas classés par ordre de qualité, car ils présentent des forces et des faiblesses différentes.
1. Flux d'air Apache
Apache Airflow est une plateforme open-source qui permet de créer, planifier et contrôler des flux de travail de manière programmatique. La plateforme comporte une interface utilisateur basée sur le web et une interface de ligne de commande pour la gestion et le déclenchement des flux de travail.
Les flux de travail sont définis à l'aide de graphes acycliques dirigés (DAG), qui permettent une visualisation et une gestion claires des tâches et des dépendances. Airflow s'intègre également à d'autres outils couramment utilisés dans l'ingénierie et la science des données, tels qu'Apache Spark et Pandas.
Les entreprises qui utilisent Airflow peuvent bénéficier de sa capacité à s'adapter et à gérer des flux de travail complexes, ainsi que de sa communauté open-source active et de sa documentation complète. Vous pouvez découvrir Airflow dans le cours DataCamp suivant.
2. Portable.io
Portable.io se décrit comme "la première plateforme ELT à construire des connecteurs à la demande pour les équipes de données". Fidèle à cette mission, l'équipe de Portable construit des intégrations personnalisées sans code, ingérant des données provenant de fournisseurs SaaS et de nombreuses autres sources de données qui pourraient ne pas être prises en charge parce qu'elles sont négligées par d'autres fournisseurs d'ETL. Les clients potentiels peuvent voir par eux-mêmes leur vaste catalogue de connecteurs, qui comprend plus de 1 300 connecteurs ETL difficiles à trouver.
Portable part du principe que les entreprises devraient avoir à portée de main des données provenant de toutes les applications commerciales, sans aucun code. L'équipe de Portable a créé un produit qui permet une gestion efficace et opportune des données et qui offre une grande évolutivité et de hautes performances. En outre, il propose des prix avantageux pour les entreprises de toutes tailles et des fonctions de sécurité avancées pour garantir la protection des données et la conformité aux normes communes.
3. IBM Infosphere Datastage
Infosphere Datastage est un outil ETL proposé par IBM dans le cadre de son écosystème Infosphere Information Server. Grâce à son cadre graphique, les utilisateurs peuvent concevoir des pipelines de données qui extraient des données de sources multiples, effectuent des transformations complexes et transmettent les données aux applications cibles.
IBM Infosphere est réputé pour sa rapidité, grâce à des fonctionnalités telles que l'équilibrage de la charge et la parallélisation. Il prend également en charge les métadonnées, la détection automatisée des défaillances et une large gamme de services de données, de l'entreposage de données aux applications d'intelligence artificielle.
Comme d'autres outils ETL d'entreprise, Infosphere Datastage offre une gamme de connecteurs pour l'intégration de différentes sources de données. Il s'intègre également de manière transparente aux autres composants d'IBM Infosphere Information Server, ce qui permet aux utilisateurs de développer, de tester, de déployer et de surveiller les travaux ETL.
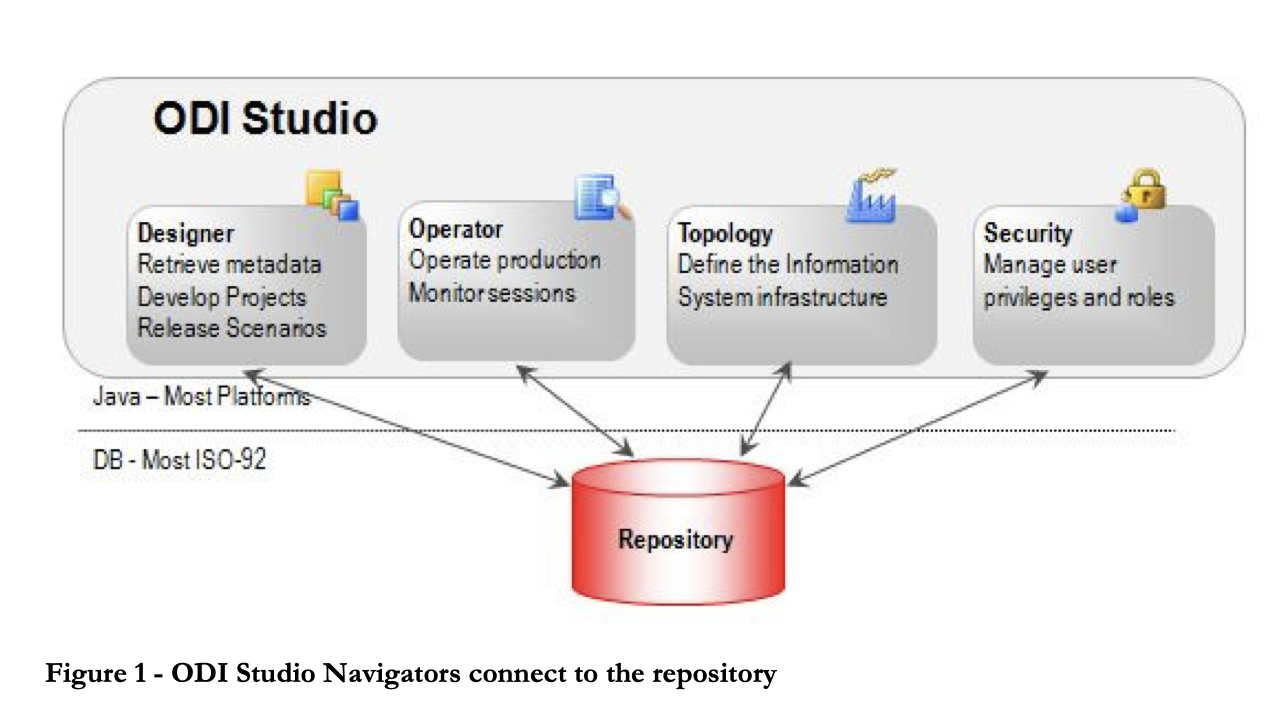
4. Oracle Data Integrator
Oracle Data Integrator est un outil ETL qui aide les utilisateurs à construire, déployer et gérer des entrepôts de données complexes. Il est livré avec des connecteurs prêts à l'emploi pour de nombreuses bases de données, y compris Hadoop, EREP, CRM, XML, JSON, LDAP, JDBC et ODBC.
ODI comprend Data Integrator Studio, qui permet aux utilisateurs professionnels et aux développeurs d'accéder à de multiples artefacts par le biais d'une interface utilisateur graphique. Ces artefacts offrent tous les éléments de l'intégration des données, du mouvement des données à la synchronisation, à la qualité et à la gestion.
5. Services d'intégration Microsoft SQL Server (SSIS)
SSIS est une plate-forme d'entreprise pour l'intégration et la transformation des données. Il est livré avec des connecteurs permettant d'extraire des données de sources telles que des fichiers XML, des fichiers plats et des bases de données relationnelles. Les praticiens peuvent utiliser l 'interface utilisateur graphique du concepteur SSIS pour construire des flux de données et des transformations.
La plateforme comprend une bibliothèque de transformations intégrées qui minimisent la quantité de code nécessaire au développement. SSIS offre également une documentation complète pour la création de flux de travail personnalisés. Cependant, la courbe d'apprentissage abrupte et la complexité de la plateforme peuvent décourager les débutants de créer rapidement des pipelines ETL.
6. Talend Open Studio (TOS)
Talend Open Studio est un logiciel d'intégration de données open-source très répandu, doté d'une interface graphique conviviale. Les utilisateurs peuvent glisser et déposer des composants, les configurer et les connecter pour créer des pipelines de données. En coulisses, Open Studio convertit la représentation graphique en code Java et Perl.
En tant qu'outil open-source, TOS est une option abordable avec une grande variété de connecteurs de données, y compris des connecteurs RDBMS et SaaS. La plateforme bénéficie également d'une communauté active de logiciels libres qui contribue régulièrement à la documentation et fournit une assistance.
7. Pentaho Data Integration (PDI)
Pentaho Data Integration (PDI) est un outil ETL proposé par Hitachi. Il capture des données provenant de diverses sources, les nettoie et les stocke dans un format uniforme et cohérent.
Anciennement connu sous le nom de Kettle, PDI dispose de plusieurs interfaces graphiques pour définir les pipelines de données. Les utilisateurs peuvent concevoir des travaux et des transformations de données à l'aide du client PDI, Spoon, puis les exécuter à l'aide de Kitchen. Par exemple, le client PDI peut être utilisé pour l'ETL en temps réel avec Pentaho Reporting.
8. Hadoop
Hadoop est un cadre open-source pour le traitement et le stockage de données volumineuses dans des grappes de serveurs informatiques. Il est considéré comme le fondement du big data et permet le stockage et le traitement de grandes quantités de données.
Le cadre Hadoop se compose de plusieurs modules, notamment le système de fichiers distribués Hadoop (HDFS) pour le stockage des données, MapReduce pour la lecture et la transformation des données, et YARN pour la gestion des ressources. Hive est couramment utilisé pour convertir des requêtes SQL en opérations MapReduce.
Les entreprises qui envisagent d'utiliser Hadoop doivent être conscientes de ses coûts. Une part importante du coût de la mise en œuvre d'Hadoop provient de la puissance de calcul requise pour le traitement et de l'expertise nécessaire pour maintenir l'ETL Hadoop, plutôt que des outils ou du stockage eux-mêmes.
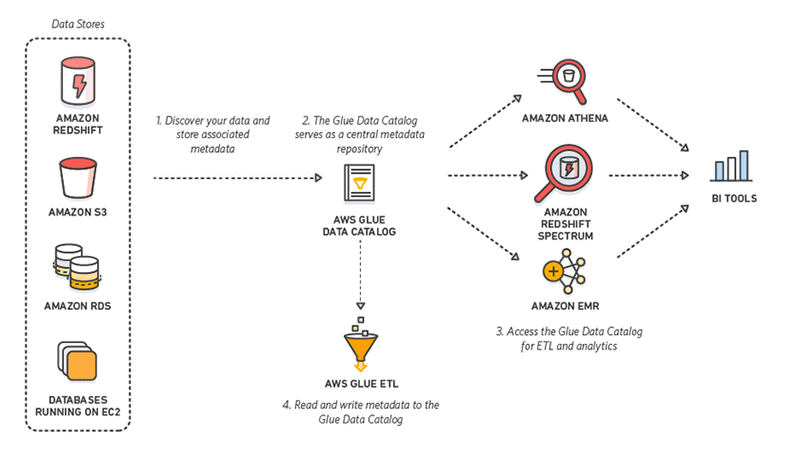
9. Colle AWS
AWS Glue est un outil ETL sans serveur proposé par Amazon. Il découvre, prépare, intègre et transforme des données provenant de sources multiples pour des cas d'utilisation analytiques. Sans avoir à mettre en place ou à gérer une infrastructure, AWS Glue promet de réduire le coût élevé de l'intégration des données.
Mieux encore, lorsqu'ils interagissent avec AWS Glue, les praticiens peuvent choisir entre une interface graphique à glisser-déposer, un carnet Jupyter ou un code Python/Scala. AWS Glue prend également en charge divers traitements de données et charges de travail répondant aux différentsbesoins des entreprises, notamment ETL, ELT, batch et streaming.
10. AWS Data Pipeline
Le Data Pipeline d'AWS est un service ETL géré qui permet de déplacer des données entre les services AWS ou les ressources sur site. Les utilisateurs peuvent spécifier les données à déplacer, les travaux de transformation ou les requêtes, ainsi qu'un calendrier pour l'exécution des transformations.
Data Pipeline est knnu pour sa fiabilité, sa flexibilité et son évolutivité, ainsi que pour sa tolérance aux pannes et sa configurabilité. La plateforme est également dotée d'une console "glisser-déposer" qui facilite l'utilisation. En outre, il est relativement peu coûteux.
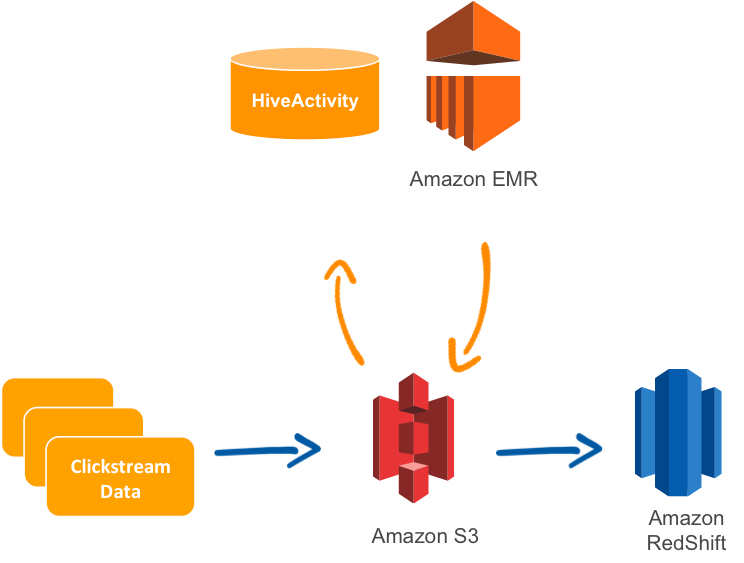
Un cas d'utilisation courant d'AWS Data Pipeline est la réplication de données à partir de Relational Database Service (RDS) et leur chargement sur Amazon Redshift.
Il convient de mentionner qu'en 2022, AWS a introduit le concept de zero-ETL, ce qui signifie que certains services peuvent être intégrés sans qu'il soit nécessaire de mettre en place des pipelines de données. Par exemple, Amazon Aurora peut synchroniser automatiquement les données avec Redshift.
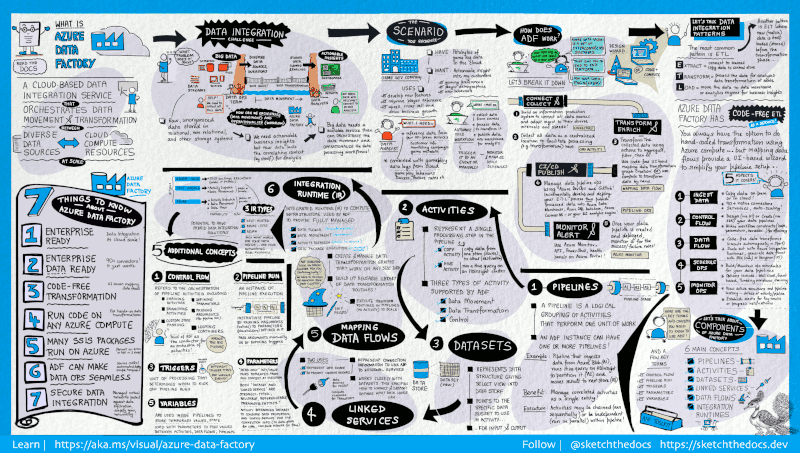
11. Azure Data Factory
Azure Data Factory est un service ETL basé sur le cloud offert par Microsoft, utilisé pour créer des flux de travail qui déplacent et transforment les données à grande échelle.
Il comprend une série de systems interconnectés. Ensemble, ces systèmes permettent aux ingénieurs non seulement d'ingérer et detransformer les données, mais aussi de concevoir, de planifier et de contrôler les pipelines de données.
La force de Data Factory réside dans le nombre de ses connecteurs disponibles, de MySQL à AWS, MongoDB, Salesforce et SAP. Il est également loué pour sa flexibilité ; les utilisateurs peuvent choisir d'interagir avec une interface utilisateur graphique sans code ou une interface de ligne de commande.
12. Google Cloud Dataflow
Dataflow est le service ETL sans serveur proposé par Google Cloud. Il permet le traitement des données en flux et par lots et n'exige pas que les entreprises possèdent un serveur ou une grappe. Au lieu de cela, les utilisateurs ne paient que pour les ressources consommées, qui évoluent automatiquement en fonction des besoins et de la charge de travail.
Google Dataflow exécute les pipelines Apache Beam au sein de l'écosystème Google Cloud Platform. Apache propose des SDK Java, Python et Go pour représenter et transférer des ensembles de données, à la fois par lots et en continu. Cela permet aux utilisateurs de choisir le SDK approprié pour définir leurs pipelines de données.
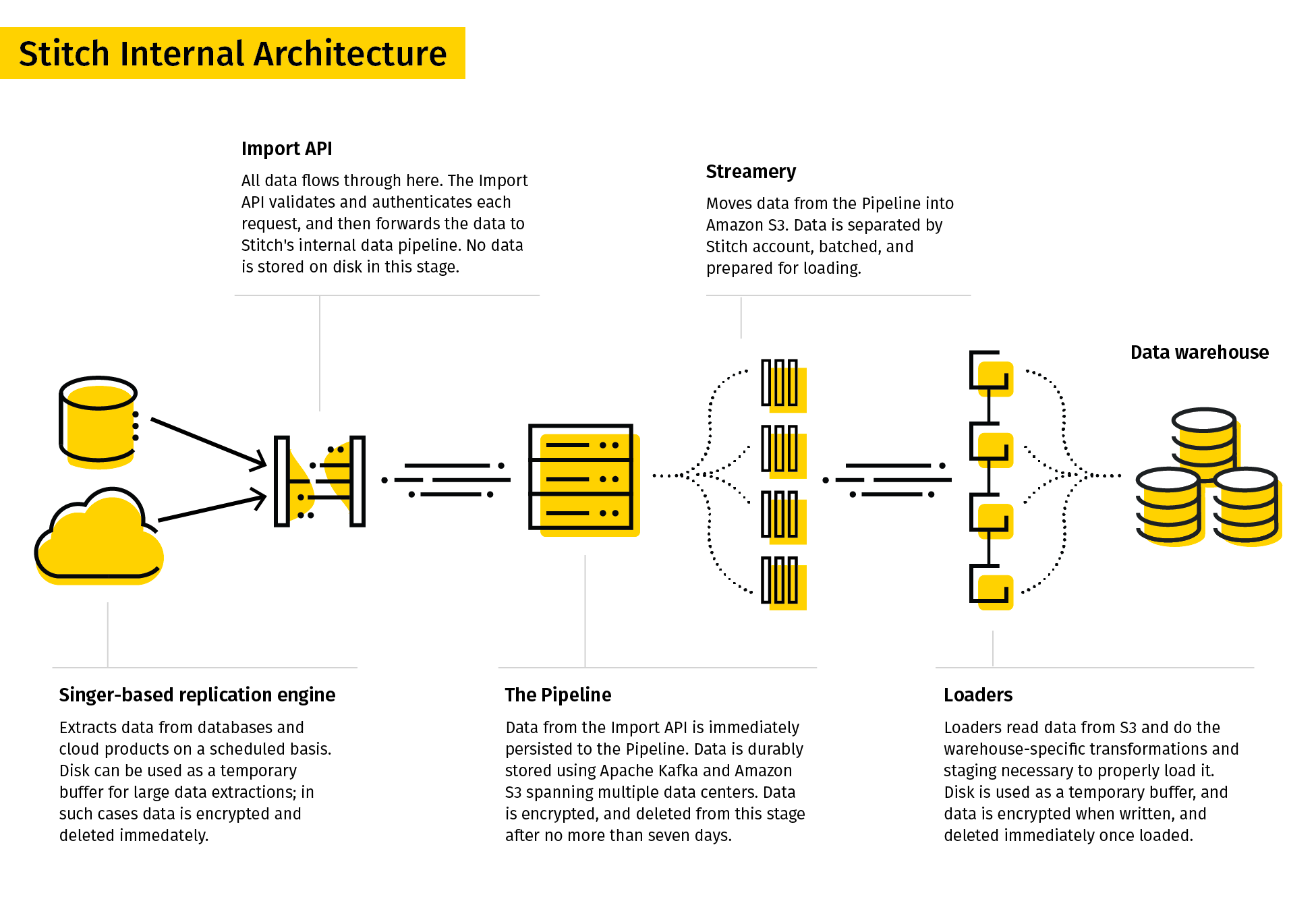
13. Stitch
Stitch se décrit comme un outil ETL simple et extensible conçu pour les équipes chargées des données.
Le processus de réplication de Stitch extrait les données de diverses sources, les transforme dans un format brut utile et les charge dans la destination. Ses connecteurs de données comprenaient des bases de données et des applications SaaS. Les destinations peuvent être des lacs de données, des entrepôts de donnéeset des plateformes de stockage.
Compte tenu de sa simplicité, Stitch ne prend en charge que les transformations simples et non les transformations définies par l'utilisateur.
14. SAP BusinessObjects Data Services
SAP BusinessObjects Data Services est un outil ETL d'entreprise qui permet aux utilisateurs d'extraire des données de plusieurs systèmes, de les transformer et de les charger dans des entrepôts de données.
Le concepteur de services de données fournit une interface utilisateur graphique pour définir les pipelines de données et spécifier les transformations de données. Les règles et les métadonnées sont stockées dans un référentiel, et un serveur de tâches exécute le travail par lots ou en temps réel.
Cependant, les services de données SAP peuvent être coûteux, car le coût de l'outil, du serveur, du matériel et de l'équipe d'ingénieurs peut rapidement s'accumuler.
SAP Data Services convient parfaitement aux entreprises qui utilisent SAP comme système de planification des ressources de l'entreprise (ERP), car il s'intègre de manière transparente à SAP Data Services.
15. Hevo
Hevo est une plateforme d'intégration de données pour l'ETL et l'ELT qui comprend plus de 150 connecteurs pour l'extraction de données à partir de sources multiples. Il s'agit d'un outil à code bas, qui permet aux utilisateurs de concevoir facilement des pipelines de données sans avoir besoin d'une expérience approfondie en matière de codage.
Hevo offre une série de fonctionnalités et d'avantages, notamment l'intégration de données en temps réel, la détection automatique des schémas et la capacité à gérer de grands volumes de données. La plateforme est également dotée d'une interface conviviale et d'un service d'assistance à la clientèle disponible 24 heures sur 24 et 7 jours sur 7.
16. Qlik Compose
Qlik Compose est une solution d'entreposage de données qui conçoit automatiquement des entrepôts de données et génère du code ETL. Cet outil automatise le développement et la maintenance de l'ETL, qui sont fastidieux et sources d'erreurs. Cela permet de raccourcir le délai d'exécution des projets d'entreposage de données.
Pour ce faire, Qlik Compose exécute le code généré automatiquement, qui charge les données à partir des sources et les transfère dans leurs entrepôts de données. Ces flux de travail peuvent être conçus et planifiés à l'aide du concepteur et du planificateur de flux de travail.
Qlik Compose permet également de valider les données et d'en assurer la qualité. Les praticiens qui ont besoin de données en temps réel peuvent également intégrer Compose à Qlik Replicate.
17. Integrate.io
Integrate.io, anciennement connu sous le nom de Xplenty, occupe une place bien méritée dans notre liste des meilleurs outils ETL. Son interface conviviale et intuitive ouvre la voie à une gestion complète des données, même pour les membres de l'équipe ayant moins de connaissances techniques. En tant que plateforme basée sur le cloud, Integrate.io élimine le besoin d'installations matérielles ou logicielles encombrantes et fournit une solution hautement évolutive qui s'adapte aux besoins de votre entreprise.
Sa capacité à se connecter à une grande variété de sources de données, des bases de données aux systèmes de gestion de la relation client, en fait un choix polyvalent pour répondre à diverses exigences en matière d'intégration de données. Accordant la priorité à la sécurité des données, il offre des fonctionnalités telles que le cryptage au niveau du champ et est conforme à des normes clés telles que GDPR et HIPAA. Grâce à de puissantes capacités de transformation des données, les utilisateurs peuvent facilement nettoyer, formater et enrichir leurs données dans le cadre du processus ETL.
18. Airbyte
Airbyte est l'une des principales plates-formes de FLE à code source ouvert. Airbyte propose le plus grand catalogue de connecteurs de données - 350 et plus - et 40 000 ingénieurs de données l'utiliseront en juin 2023.
Airbyte s'intègre à dbt pour la transformation des données et à Airflow / Prefect / Dagster pour l'orchestration. Il possède une interface utilisateur facile à utiliser et dispose d'une API et d'un fournisseur Terraform.
Airbyte se différencie par son ouverture ; il faut 20 minutes pour créer un nouveau connecteur avec leur constructeur de connecteurs sans code, et vous pouvez modifier n'importe quel connecteur standard, à condition d'avoir accès à leur code. En plus de sa version open-source, Airbyte propose une version hébergée dans le nuage (Airbyte Cloud) et une version auto-hébergée payante (Airbyte Enterprise) pour les cas où vous souhaitez produire vos pipelines.
19. Astera Centerprise
Astera Centerprise est un outil ETL/ELT de niveau entreprise, 100% sans code. En tant qu'élément de la pile de données Astera, Centerprise dispose d'une interface intuitive et conviviale qui s'accompagne d'une courbe d'apprentissage courte et permet aux utilisateurs de tous les niveaux techniques de créer des pipelines de données en quelques minutes.
L'outil d'intégration de données automatisé offre une gamme de fonctionnalités, telles que la connectivité prête à l'emploi à plusieurs sources et destinations de données, l'extraction de données alimentée par l'IA, le mappage automatique par l'IA, les transformations avancées intégrées et les fonctions de qualité des données. Les utilisateurs peuvent facilement extraire des données non structurées et structurées, les transformer et les charger dans la destination de leur choix à l'aide de flux de données. Ces flux de données peuvent être automatisés pour être exécutés à des intervalles spécifiques, dans des conditions particulières ou en cas d'abandon de fichiers, à l'aide du planificateur de tâches intégré.
20. Informatica PowerCenter
Informatica PowerCenter est l'un des meilleurs outils ETL du marché. Il dispose d'une large gamme de connecteurs pour les entrepôts de données et les lacs en nuage, y compris AWS, Azure, Google Cloud et SalesForce. Ses outils à code faible ou nul sont conçus pour faire gagner du temps et simplifier les flux de travail.
Informatica PowerCenter comprend plusieurs services qui permettent aux utilisateurs de concevoir, de déployer et de surveiller les pipelines de données. Par exemple, le gestionnaire de référentiel facilite la gestion des utilisateurs, le concepteur permet aux utilisateurs de spécifier le flux de données de la source à la cible, et le gestionnaire de flux de travail définit la séquence des tâches.
Améliorer l'expertise de votre équipe en matière d'ETL
Les données devenant essentielles aux activités de l'entreprise, il est crucial de mettre en place des processus ETL efficaces. Pour rester compétitif, il est essentiel d'améliorer en permanence les compétences de votre équipe en matière d'ingénierie et de gestion des données. DataCamp for Business propose des solutions sur mesure pour aider les organisations à améliorer les compétences de leurs employés, en veillant à ce qu'ils soient bien équipés pour gérer les complexités de l'analyse de données moderne. Avec DataCamp for business, votre équipe peut accéder :
- Des parcours d'apprentissage ciblés : Offrez à votre équipe une formation ciblée sur les outils ETL tels qu'Apache Airflow, AWS, etc. afin d'améliorer leur capacité à concevoir et à gérer des pipelines de données efficaces.
- Expérience pratique : Encouragez les projets pratiques qui reflètent les défis de votre organisation en matière de données, en aidant votre équipe à acquérir la confiance et l'expertise nécessaires pour gérer des tâches complexes liées aux données.
- Des solutions de formation évolutives : Choisissez des plateformes de formation évolutives qui offrent une gamme de ressources en ETL et en gestion de données, afin que votre équipe puisse s'adapter à la croissance de votre organisation.
- Suivi des progrès : Utilisez des outils pour suivre le développement de votre équipe, en fournissant un retour d'information régulier afin d'assurer une amélioration continue.
Investir dans les compétences de votre équipe de données permet non seulement d'améliorer l'efficacité de l'ETL, mais aussi de mettre en place de meilleures stratégies de données, contribuant ainsi au succès de votre organisation. Demandez une démonstration dès aujourd'hui pour en savoir plus.
Ressources complémentaires
En conclusion, il existe de nombreux outils d'ETL et d'intégration de données, chacun ayant ses propres caractéristiques et capacités. Parmi les options les plus courantes, citons SSIS, Talend Open Studio, Pentaho Data Integration, Hadoop, Airflow, AWS Data Pipeline, Google Dataflow, SAP BusinessObjects Data Services et Hevo. Les entreprises qui envisagent d'utiliser ces outils doivent évaluer soigneusement leurs besoins spécifiques et leur budget afin de choisir la solution la mieux adaptée à leurs besoins ( ). Pour plus de ressources sur les outils ETL et autres, consultez les liens suivants :
Obtenez une certification pour le poste de Data Engineer de vos rêves
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.


