
Leerpad
SQL Server voor databasebeheerders
24 Hr
Bereid je je voor op een DBMS-sollicitatie? Je bent op de juiste plek.
Je kent databases uit je dagelijkse werk, maar sollicitaties testen je anders dan praktijksituaties. Interviewers willen niet alleen zien of je SQL-queries kunt schrijven - ze testen je begrip van normalisatie, ACID-eigenschappen en hoe je met databaseprestaties omgaat onder druk. Veel databaseprofessionals struikelen omdat ze concepten die ze dagelijks gebruiken niet kunnen uitleggen of moeite hebben met gedragsvragen die testen hoe ze met datateams werken.
Deze gids behandelt de meest gestelde DBMS-sollicitatievragen op alle niveaus. Je krijgt ook bewezen strategieën voor scenariovragen en tips om op te vallen tussen andere kandidaten.
Laten we beginnen met de basisvragen waarmee elk DBMS-interview start.
>Wil je je alleen op het codeergedeelte van het interview richten? Hier vind je 85 SQL-sollicitatievragen en -antwoorden voor 2026.
Verwacht deze vragen aan het begin van een technisch interview. Ze testen je basisbegrip van databasebeheersystemen.
Interviewers gebruiken deze vragen om te zien of je de kernconcepten van databases begrijpt voordat ze naar complexe scenario’s gaan. Ze zoeken heldere uitleg en praktische voorbeelden die laten zien dat je met databases hebt gewerkt, niet alleen definities hebt gememoriseerd.
Een DBMS is software die databases beheert - het regelt het opslaan, opvragen en organiseren van data en zorgt voor beveiliging en consistentie.
Zie het als de tussenlaag tussen je applicaties en de daadwerkelijke databestanden. Populaire voorbeelden zijn MySQL, PostgreSQL, Oracle en SQL Server. Het DBMS handelt taken af zoals gebruikersauthenticatie, databack-ups en zorgt ervoor dat meerdere gebruikers data kunnen benaderen zonder die te corrumperen.
Een database is de verzameling data zelf, terwijl een DBMS de software is die die data beheert.
De database bevat je tabellen, records en relaties. Het DBMS biedt de tools en interface om met die data te werken. Het is het verschil tussen een bibliotheek (database) en het bibliotheeksysteem (DBMS) dat je helpt boeken te vinden en uit te lenen.
ACID-principes zorgen ervoor dat transacties betrouwbaar zijn en dataintegriteit behouden blijft:
Een alledaags voorbeeld: Als je geld overboekt tussen rekeningen, moeten zowel de afschrijving als de bijschrijving samen plaatsvinden (atomicity), blijven de regels voor het totale saldo geldig (consistency), zien andere transacties geen tussenstanden (isolation) en blijft de wijziging bestaan, zelfs als het systeem crasht (durability).
Databasesleutels worden gebruikt om records uniek te identificeren en relaties vast te leggen. Dit zijn de typen die je moet kennen:
Een eenvoudig voorbeeld:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
department_id INT,
email VARCHAR(100) UNIQUE,
FOREIGN KEY (department_id) REFERENCES departments(id)
);Normalisatie elimineert dataduplicatie door data te organiseren in aparte, gerelateerde tabellen.
Het voorkomt inconsistenties en bespaart opslagruimte. Zo werken de belangrijkste normale vormen:
Eerste normale vorm (1NF): Elke kolom bevat atomaire (ondeelbare) waarden - geen lijstjes of meerdere waarden in één cel.
Slecht voorbeeld:

Afbeelding 1 - slecht voorbeeld 1NF
Goed voorbeeld:
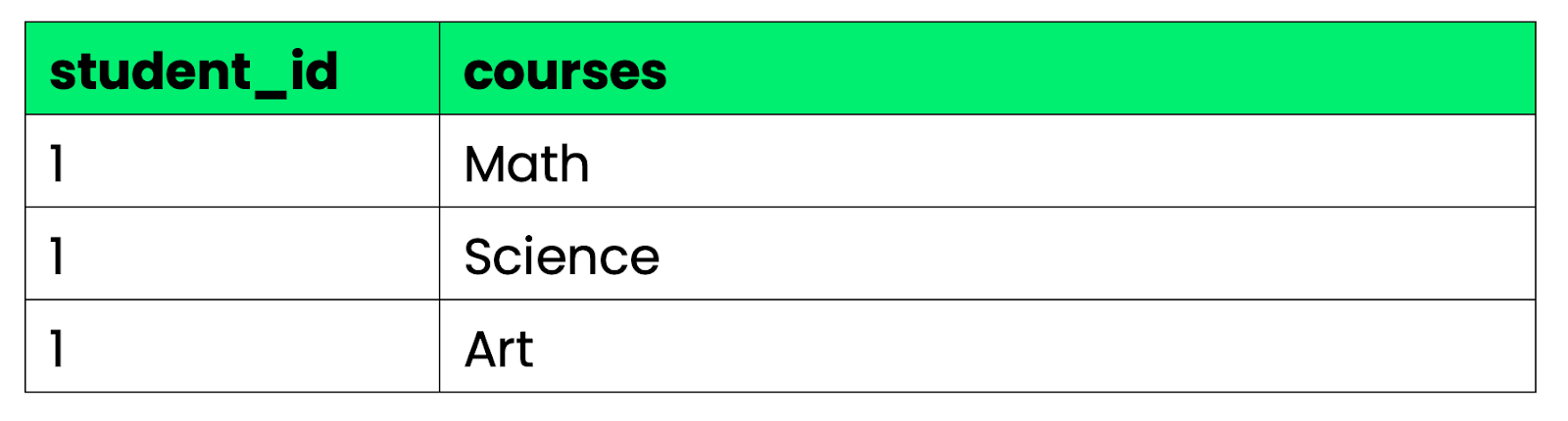
Afbeelding 2 - goed voorbeeld 1NF
Tweede normale vorm (2NF): Moet in 1NF zijn en partiële afhankelijkheden verwijderen—niet-sleutelkolommen moeten afhankelijk zijn van de volledige primaire sleutel, niet van een deel ervan.
Dit speelt wanneer je een samengestelde primaire sleutel hebt. Als je een tabel hebt met (student_id, course_id) als primaire sleutel, dan hoort student_name niet in deze tabel omdat die alleen afhangt van student_id, niet van beide sleutels.
Derde normale vorm (3NF): Moet in 2NF zijn en transitieve afhankelijkheden verwijderen. Niet-sleutelkolommen mogen niet afhangen van andere niet-sleutelkolommen.
Slecht voorbeeld:

Afbeelding 3 - slecht voorbeeld 3NF
Hier hangt advisor_office af van advisor_id, niet direct van student_id. Splits dit op in aparte tabellen.
Zonder normalisatie zou je klantgegevens bij elke bestelling opslaan, wat ruimte verspilt en updateproblemen veroorzaakt als klantgegevens wijzigen.
Deze opdrachten verwijderen data op verschillende manieren:
DELETE FROM employees WHERE department_id = 5;TRUNCATE TABLE employees;DROP TABLE employees;INNER JOIN retourneert alleen overeenkomende records uit beide tabellen:
SELECT e.name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.id;OUTER JOIN omvat ook niet-overeenkomende records:
>SQL-joins zijn op zich al een complex onderwerp - Hier zijn 20 sollicitatievragen alleen over joins
Een index is een datastructuur die het ophalen van data versnelt door snelkoppelingen naar tabelrijen te maken.
Zie het als de index van een boek - in plaats van elke pagina te lezen om een onderwerp te vinden, kijk je het op en ga je direct naar de juiste pagina. Indexen maken SELECT-queries sneller, maar vertragen INSERT-, UPDATE- en DELETE-bewerkingen omdat de index moet worden bijgewerkt.
CREATE INDEX idx_employee_email ON employees(email);Een view is een virtuele tabel die is gemaakt op basis van een SQL-query en zelf geen data opslaat.
Views vereenvoudigen complexe queries, bieden beveiliging door gevoelige kolommen te verbergen en presenteren data in verschillende formaten. Wanneer je een view bevraagt, voert de database de onderliggende SQL uit en geeft resultaten terug alsof het een echte tabel is.
CREATE VIEW active_employees AS
SELECT employee_id, name, email
FROM employees
WHERE status = 'active';
SELECT * FROM active_employees;Stored procedures zijn vooraf gecompileerde SQL-code die in de database is opgeslagen en die je bij naam kunt uitvoeren.
Ze verbeteren de prestaties omdat ze vooraf zijn gecompileerd, verminderen netwerkverkeer door meerdere statements in één call uit te voeren en bieden betere beveiliging via geparametriseerde queries. Ze centraliseren ook businesslogica in de database.
CREATE PROCEDURE GetEmployeesByDepartment(IN dept_id INT)
BEGIN
SELECT * FROM employees WHERE department_id = dept_id;
END;>Procedurele SQL kan een belangrijk interviewonderwerp zijn, afhankelijk van de rol. Deze 20 sollicitatievragen focussen op Oracle PL/SQL
Met deze basics uit de weg, gaan we door naar intermediate-vragen die je kennis testen.
Leer meer over DBMS met deze cursussen!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
