
programa
SQL Server para Administradores de Bases de Datos
24 h
¿Te estás preparando para una entrevista sobre DBMS? Estás en el lugar adecuado.
Conoces las bases de datos por tu trabajo diario, pero las entrevistas te ponen a prueba de forma diferente a las situaciones reales. Los entrevistadores no solo quieren ver si sabes escribir consultas SQL, sino que también pondrán a prueba tus conocimientos sobre normalización, propiedades ACID y cómo gestionarías los problemas de rendimiento de las bases de datos bajo presión. Muchos profesionales de bases de datos tropiezan porque no pueden explicar conceptos que usan a diario o tienen dificultades con preguntas de comportamiento que evalúan cómo trabajan con equipos de datos.
Esta guía recoge las preguntas más frecuentes en entrevistas sobre DBMS, con todos los niveles de dificultad. También obtendrás estrategias probadas para responder con éxito a preguntas basadas en situaciones hipotéticas y consejos que te ayudarán a destacar entre los demás candidatos.
Comencemos con las preguntas básicas con las que empieza toda entrevista sobre DBMS.
¿Quieres centrarte solo en la parte de programación de la entrevista? Aquí tienes 85 preguntas y respuestas para entrevistas sobre SQL para 2026.
Espera estas preguntas al comienzo de una entrevista técnica. Ponen a prueba tus conocimientos básicos sobre sistemas de gestión de bases de datos.
Los entrevistadores utilizan estas preguntas para comprobar si comprendes los conceptos básicos de las bases de datos antes de pasar a escenarios más complejos. Buscan explicaciones claras y ejemplos prácticos que demuestren que has trabajado con bases de datos, no solo que has memorizado definiciones.
Un DBMS es un software que gestiona bases de datos : se encarga de almacenar, recuperar y organizar datos, al tiempo que garantiza la seguridad y la coherencia.
Piensa en él como el intermediario entre tus aplicaciones y los archivos de datos reales. Algunos ejemplos populares son MySQL, PostgreSQL, Oracle y SQL Server. El DBMS se encarga de tareas como la autenticación de usuarios y la copia de seguridad de datos, y garantiza que varios usuarios puedan acceder a los datos sin corromperlos.
Una base de datos es la recopilación de datos en sí misma, mientras que un SBDB es el software que gestiona esos datos.
La base de datos contiene tus tablas, registros y relaciones. El DBMS proporciona las herramientas y la interfaz para interactuar con esos datos. Es como la diferencia entre una biblioteca (base de datos) y el sistema bibliotecario (DBMS) que te ayuda a encontrar y sacar libros.
Los principios ACID garantizan que las transacciones de la base de datos sean fiables y mantengan la integridad de los datos:
Aquí tienes un ejemplo cotidiano: Cuando transfieres dinero entre cuentas bancarias, tanto el débito como el crédito deben realizarse al mismo tiempo (atomicidad), las reglas de saldo total siguen siendo válidas (consistencia), otras transacciones no ven estados parciales (aislamiento) y el cambio persiste incluso si el sistema falla (durabilidad).
Las claves de base de datos se utilizan para identificar registros de forma única y establecer relaciones. Estos son los tipos que debes conocer:
Aquí tienes un ejemplo sencillo:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
department_id INT,
email VARCHAR(100) UNIQUE,
FOREIGN KEY (department_id) REFERENCES departments(id)
);La normalización elimina la redundancia de datos al organizar los datos en tablas separadas y relacionadas.
Evita inconsistencias en los datos y ahorra espacio de almacenamiento. Así es como funcionan las principales formas normales:
Primera forma normal (1NF): Cada columna contiene valores atómicos (indivisibles), sin listas ni valores múltiples en una sola celda.
Mal ejemplo:

Imagen 1: ejemplo incorrecto de 1NF
Buen ejemplo:
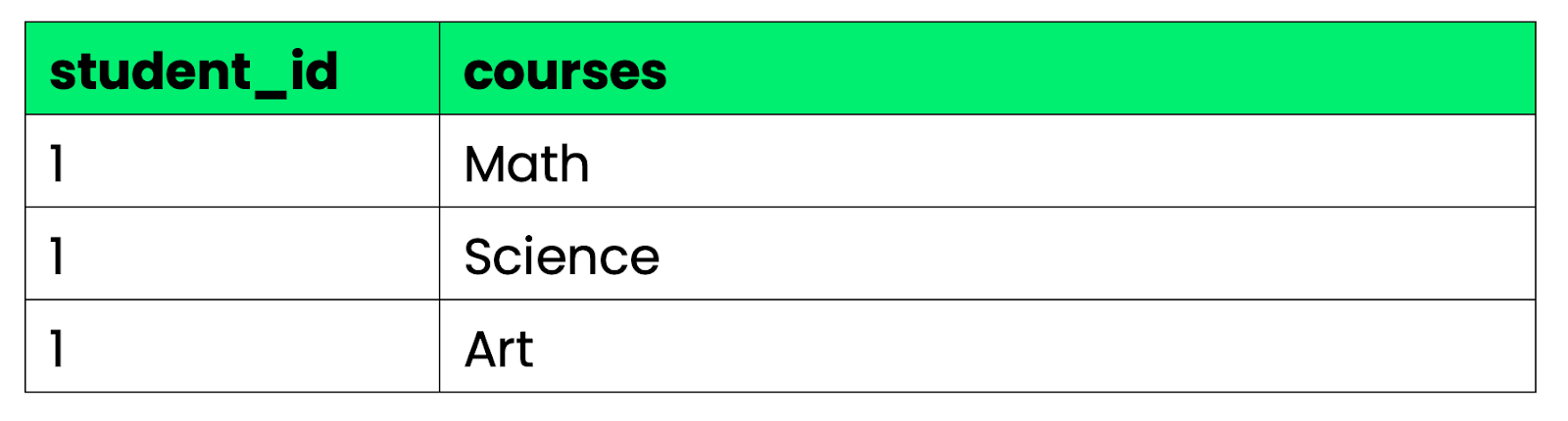
Imagen 2: buen ejemplo de 1NF
Segunda forma normal (2NF): Debe estar en 1NF y eliminar las dependencias parciales: las columnas que no son clave deben depender de toda la clave primaria, no solo de una parte de ella.
Esto se aplica cuando tienes una clave primaria compuesta. Si tienes una tabla con (student_id, course_id) como clave principal, entonces student_name no debería estar en esta tabla porque solo depende de student_id, no de ambas claves.
Tercera forma normal (3NF): Debe estar en 2NF y eliminar las dependencias transitivas. Las columnas que no son claves no deben depender de otras columnas que tampoco son claves.
Mal ejemplo:

Imagen 3: ejemplo incorrecto de 3NF
Aquí, advisor_office depende de advisor_id, no directamente de student_id. Divide esto en tablas separadas.
Sin normalización, almacenarías la información de los clientes con cada pedido, lo que desperdicia espacio y crea problemas de actualización cuando cambian los datos de los clientes.
Estos comandos eliminan datos de diferentes maneras:
DELETE FROM employees WHERE department_id = 5;TRUNCATE TABLE employees;DROP TABLE employees;INNER JOIN devuelve solo los registros coincidentes de ambas tablas:
SELECT e.name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.id;OUTER JOIN incluye registros que no coinciden:
Las uniones SQL son un tema complejo en sí mismo. Aquí tienes 20 preguntas de entrevista solo sobre uniones.
Un índice es una estructura de datos que acelera la recuperación de datos mediante la creación de accesos directos a las filas de la tabla.
Piensa en ello como en el índice de un libro: en lugar de leer todas las páginas para encontrar un tema, lo buscas y vas directamente a la página correcta. Los índices aceleran las consultas SELECT, pero ralentizan las operaciones INSERT, UPDATE y DELETE, ya que el índice necesita actualizarse.
CREATE INDEX idx_employee_email ON employees(email);Una vista es una tabla virtual creada a partir de una consulta SQL que no almacena datos por sí misma.
Las vistas simplifican las consultas complejas, proporcionan seguridad al ocultar columnas confidenciales y presentan los datos en diferentes formatos. Cuando consultás una vista, la base de datos ejecuta el SQL subyacente y devuelve los resultados como si se tratara de una tabla real.
CREATE VIEW active_employees AS
SELECT employee_id, name, email
FROM employees
WHERE status = 'active';
SELECT * FROM active_employees;Los procedimientos almacenados son código SQL precompilado almacenado en la base de datos que puedes ejecutar por su nombre.
Mejoran el rendimiento porque están precompiladas, reducen el tráfico de red al ejecutar múltiples instrucciones en una sola llamada y proporcionan mayor seguridad mediante consultas parametrizadas. También centralizan la lógica de negocio en la base de datos.
CREATE PROCEDURE GetEmployeesByDepartment(IN dept_id INT)
BEGIN
SELECT * FROM employees WHERE department_id = dept_id;
END;El SQL procedimental puede ser un tema importante en las entrevistas, dependiendo del puesto. Estas 20 preguntas de entrevista se centran en Oracle PL/SQL.
Una vez aclarado esto, pasemos a las preguntas intermedias que pondrán a prueba tus conocimientos.
¡Aprende más sobre DBMS con estos cursos!
programa
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Javier Canales Luna
15 min
blog
Josep Ferrer
15 min
blog
Abid Ali Awan
15 min


