
Lernpfad
SQL Server für Datenbankadministratoren
24 Std.
Machst du dich für ein DBMS-Vorstellungsgespräch bereit? Du bist hier genau richtig.
Du kennst Datenbanken aus deinem Arbeitsalltag, aber in Vorstellungsgesprächen wirst du anders getestet als in echten Situationen. Die Interviewer wollen nicht nur wissen, ob du SQL-Abfragen schreiben kannst – sie checken auch, ob du Normalisierung und ACID-Eigenschaften verstehst und wie du mit Datenbank-Performance-Problemen umgehst, wenn es stressig wird. Viele Datenbankprofis haben Probleme, weil sie Konzepte, die sie jeden Tag benutzen, nicht erklären können oder mit Fragen zu ihrem Verhalten im Umgang mit Datenteams nicht klarkommen.
Dieser Leitfaden deckt die häufigsten DBMS-Interviewfragen aller Schwierigkeitsgrade ab. Du bekommst auch bewährte Strategien, um szenariobasierte Fragen zu meistern, und Tipps, die dir helfen, dich von anderen Bewerbern abzuheben.
Fangen wir mit den grundlegenden Fragen an, mit denen jedes DBMS-Vorstellungsgespräch startet.
Willst du dich beim Vorstellungsgespräch nur auf den Teil zum Programmieren konzentrieren? Hier sind 85 SQL-Interviewfragen und Antworten für 2026.
Rechne damit, dass dir diese Fragen zu Beginn eines technischen Vorstellungsgesprächs gestellt werden. Sie prüfen dein grundlegendes Verständnis von Datenbankmanagementsystemen.
Die Interviewer nutzen diese Fragen, um zu sehen, ob du die wichtigsten Datenbankkonzepte verstehst, bevor sie zu komplexeren Szenarien übergehen. Die wollen klare Erklärungen und praktische Beispiele, die zeigen, dass du mit Datenbanken gearbeitet hast und nicht nur Definitionen auswendig gelernt hast.
Ein DBMS ist eine Software, die Datenbanken verwaltet – sie kümmert sich um das Speichern, Abrufen und Organisieren von Daten und sorgt dabei für Sicherheit und Konsistenz.
Stell dir das als Vermittler zwischen deinen Anwendungen und den eigentlichen Datendateien vor. Beliebte Beispiele sind MySQL, PostgreSQL, Oracle und SQL Server. Das DBMS kümmert sich um Sachen wie die Benutzerauthentifizierung und Datensicherung und sorgt dafür, dass mehrere Leute auf die Daten zugreifen können, ohne sie zu beschädigen.
Eine Datenbank ist die Sammlung von Daten an sich, während ein DBMS die Software ist, die diese Daten verwaltet.
Die Datenbank hat deine Tabellen, Datensätze und Beziehungen. Das DBMS hat die Tools und die Schnittstelle, um mit diesen Daten zu arbeiten. Es ist wie der Unterschied zwischen einer Bibliothek (Datenbank) und dem Bibliothekssystem (DBMS), das dir hilft, Bücher zu finden und auszuleihen.
Die ACID-Prinzipien sorgen dafür, dass Datenbanktransaktionen zuverlässig sind und die Datenintegrität erhalten bleibt:
Hier ist ein Beispiel aus dem Alltag: Wenn du Geld zwischen Bankkonten überweist, müssen sowohl die Belastung als auch die Gutschrift gleichzeitig passieren (Atomarität), die Regeln für den Gesamtsaldo bleiben gültig (Konsistenz), andere Transaktionen sehen keine Teilzustände (Isolation) und die Änderung bleibt auch bei einem Systemabsturz bestehen (Dauerhaftigkeit).
Datenbankschlüssel werden benutzt, um Datensätze eindeutig zu identifizieren und Beziehungen herzustellen. Hier sind die Typen, die du kennen solltest:
Hier ist ein einfaches Beispiel:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
department_id INT,
email VARCHAR(100) UNIQUE,
FOREIGN KEY (department_id) REFERENCES departments(id)
);Durch die Normalisierung wird Datenredundanz vermieden , indem sie die Daten in separate, miteinander verbundene Tabellen sortiert.
Es verhindert Dateninkonsistenzen und spart Speicherplatz. So funktionieren die wichtigsten Normalformen:
Erste Normalform (1NF): Jede Spalte hat einzelne Werte – keine Listen oder mehrere Werte in einer Zelle.
Schlechtes Beispiel:

Bild 1 – Schlechtes Beispiel für 1NF
Gutes Beispiel:
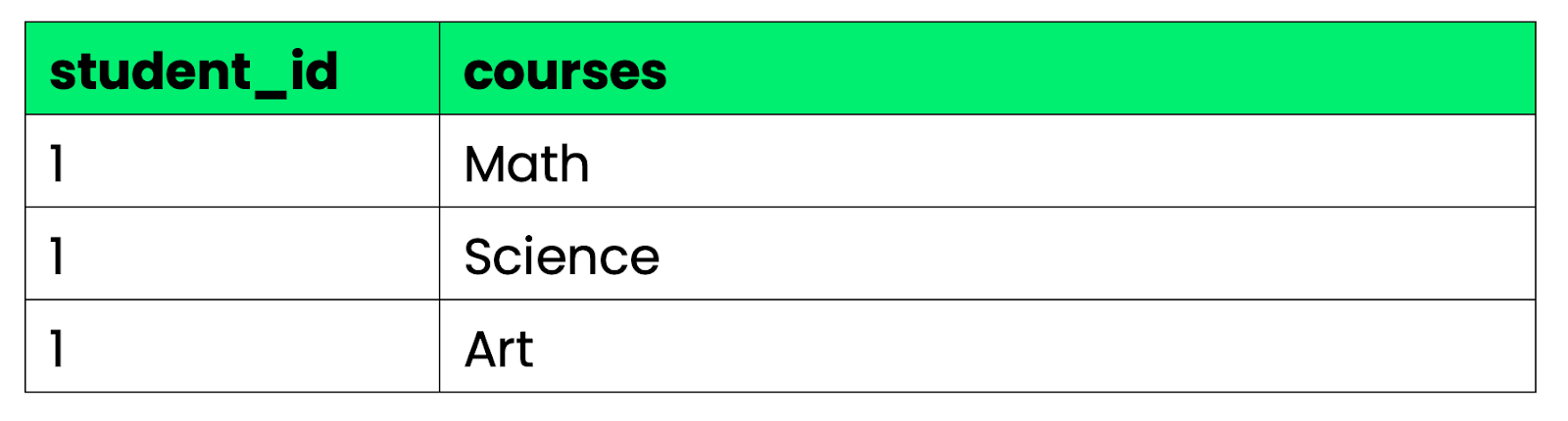
Bild 2 – Gutes Beispiel für 1NF
Zweite Normalform (2NF): Es muss in 1NF sein und teilweise Abhängigkeiten entfernen – Nicht-Schlüsselspalten müssen vom gesamten Primärschlüssel abhängen, nicht nur von einem Teil davon.
Das gilt, wenn du einen zusammengesetzten Primärschlüssel hast. Wenn du eine Tabelle mit (student_id, course_id) als Primärschlüssel hast, dann sollte student_name nicht in dieser Tabelle sein, weil es nur von student_id abhängt, nicht von beiden Schlüsseln.
Dritte Normalform (3NF): Es muss in 2NF sein und transitive Abhängigkeiten entfernen. Nicht-Schlüsselspalten sollten nicht von anderen Nicht-Schlüsselspalten abhängig sein.
Schlechtes Beispiel:

Bild 3 – Schlechtes Beispiel für 3NF
Hier hängt „ advisor_office “ von „ advisor_id “ ab, nicht direkt von „ student_id “. Teile das in separate Tabellen auf.
Ohne Normalisierung würdest du Kundendaten bei jeder Bestellung speichern, was Speicherplatz verschwendet und zu Problemen bei der Aktualisierung führt, wenn sich Kundendaten ändern.
Diese Befehle löschen Daten auf verschiedene Arten:
DELETE FROM employees WHERE department_id = 5;TRUNCATE TABLE employees;DROP TABLE employees;INNER JOIN gibt nur die übereinstimmenden Datensätze aus beiden Tabellen zurück:
SELECT e.name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.id;OUTER JOIN nimmt auch nicht übereinstimmende Datensätze mit rein:
SQL-Joins sind echt ein komplexes Thema – hier sind 20 Interviewfragen, die sich nur um Joins drehen.
Ein Index ist eine Art Datenstruktur, die das Finden von Daten schneller macht , indem er Abkürzungen zu Tabellenzeilen erstellt.
Stell dir das wie das Stichwortverzeichnis eines Buches vor – statt jede Seite durchzublättern, um ein Thema zu finden, schaust du einfach nach und springst direkt zur richtigen Seite. Indizes machen SELECT-Abfragen schneller, verlangsamen aber INSERT-, UPDATE- und DELETE-Operationen, weil der Index aktualisiert werden muss.
CREATE INDEX idx_employee_email ON employees(email);Eine Ansicht ist eine virtuelle Tabelle , die aus einer SQL-Abfrage erstellt wird und selbst keine Daten speichert.
Ansichten machen komplexe Abfragen einfacher, sorgen für Sicherheit, indem sie sensible Spalten verstecken, und zeigen Daten in verschiedenen Formaten an. Wenn du eine Ansicht abfragst, führt die Datenbank die zugrunde liegende SQL aus und gibt die Ergebnisse zurück, als wäre es eine echte Tabelle.
CREATE VIEW active_employees AS
SELECT employee_id, name, email
FROM employees
WHERE status = 'active';
SELECT * FROM active_employees;Gespeicherte Prozeduren sind vorab kompilierter SQL-Code in der Datenbank gespeichert und können nach ihrem Namen ausgeführt werden.
Sie machen die Leistung besser, weil sie schon fertig programmiert sind, den Netzwerkverkehr reduzieren, indem sie mehrere Anweisungen in einem Aufruf ausführen, und durch parametrisierte Abfragen für mehr Sicherheit sorgen. Außerdem bringen sie die Geschäftslogik in der Datenbank zusammen.
CREATE PROCEDURE GetEmployeesByDepartment(IN dept_id INT)
BEGIN
SELECT * FROM employees WHERE department_id = dept_id;
END;Prozedurales SQL kann je nach Job ein wichtiges Thema im Vorstellungsgespräch sein. Diese 20 Interviewfragen drehen sich um Oracle PL/SQL.
Nachdem wir das geklärt haben, lass uns zu den mittleren Fragen kommen, die dein Wissen auf die Probe stellen.
Lerne mit diesen Kursen mehr über DBMS!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.