
Programa
SQL Server para administradores de banco de dados
24 h
Preparando-se para uma entrevista sobre DBMS? Você está no lugar certo.
Você conhece bancos de dados do seu trabalho diário, mas as entrevistas testam você de maneira diferente dos cenários do mundo real. Os entrevistadores não querem só ver se você sabe escrever consultas SQL — eles vão testar o seu entendimento sobre normalização, propriedades ACID e como você lidaria com problemas de desempenho do banco de dados sob pressão. Muitos profissionais de banco de dados tropeçam porque não conseguem explicar conceitos que usam todos os dias ou têm dificuldade com perguntas comportamentais que testam como eles trabalham com equipes de dados.
Este guia aborda as perguntas mais frequentes em entrevistas sobre DBMS em todos os níveis de dificuldade. Você também vai ter estratégias comprovadas para arrasar nas perguntas baseadas em cenários e dicas que vão te ajudar a se destacar dos outros candidatos.
Vamos começar com as perguntas básicas que toda entrevista sobre DBMS começa.
Quer focar só na parte de programação da entrevista? Aqui estão 85 perguntas e respostas de entrevista sobre SQL para 2026.
Espere essas perguntas no começo de uma entrevista técnica. Eles testam o seu conhecimento básico sobre sistemas de gerenciamento de bancos de dados.
Os entrevistadores usam essas perguntas para ver se você entende os conceitos básicos de banco de dados antes de passar para cenários mais complexos. Eles querem explicações claras e exemplos práticos que mostrem que você já trabalhou com bancos de dados, não só decorou definições.
Um DBMS é um software que gerencia bancos de dados — ele lida com o armazenamento, a recuperação e a organização de dados, garantindo segurança e consistência.
Pense nisso como o intermediário entre seus aplicativos e os arquivos de dados reais. Exemplos populares incluem MySQL, PostgreSQL, Oracle e SQL Server. O DBMS cuida de tarefas como autenticação de usuários, backup de dados e garante que vários usuários possam acessar os dados sem estragar nada.
Um banco de dados é a coleção de dados em si, enquanto um DBMS é o software que gerencia esses dados.
O banco de dados tem suas tabelas, registros e relações. O DBMS oferece as ferramentas e a interface para interagir com esses dados. É tipo a diferença entre uma biblioteca (banco de dados) e o sistema bibliotecário (DBMS) que te ajuda a encontrar e pegar livros emprestados.
Os princípios ACID garantem que as transações do banco de dados sejam confiáveis e mantenham a integridade dos dados:
Aqui vai um exemplo do dia a dia: Quando você transfere dinheiro entre contas bancárias, tanto o débito quanto o crédito precisam acontecer juntos (atomicidade), as regras de saldo total continuam válidas (consistência), outras transações não veem estados parciais (isolamento) e a mudança continua mesmo se o sistema travar (durabilidade).
As chaves do banco de dados são usadas para identificar registros de forma única e estabelecer relações. Aqui estão os tipos que você precisa saber:
Aqui vai um exemplo simples:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
department_id INT,
email VARCHAR(100) UNIQUE,
FOREIGN KEY (department_id) REFERENCES departments(id)
);A normalização elimina a redundância de dados organizando os dados em tabelas separadas e relacionadas.
Isso evita inconsistências nos dados e economiza espaço de armazenamento. Veja como funcionam as principais formas normais:
Primeira Forma Normal (1NF): Cada coluna tem valores atômicos (indivisíveis) — sem listas ou vários valores em uma única célula.
Exemplo ruim:

Imagem 1 - Exemplo ruim de 1NF
Um bom exemplo:
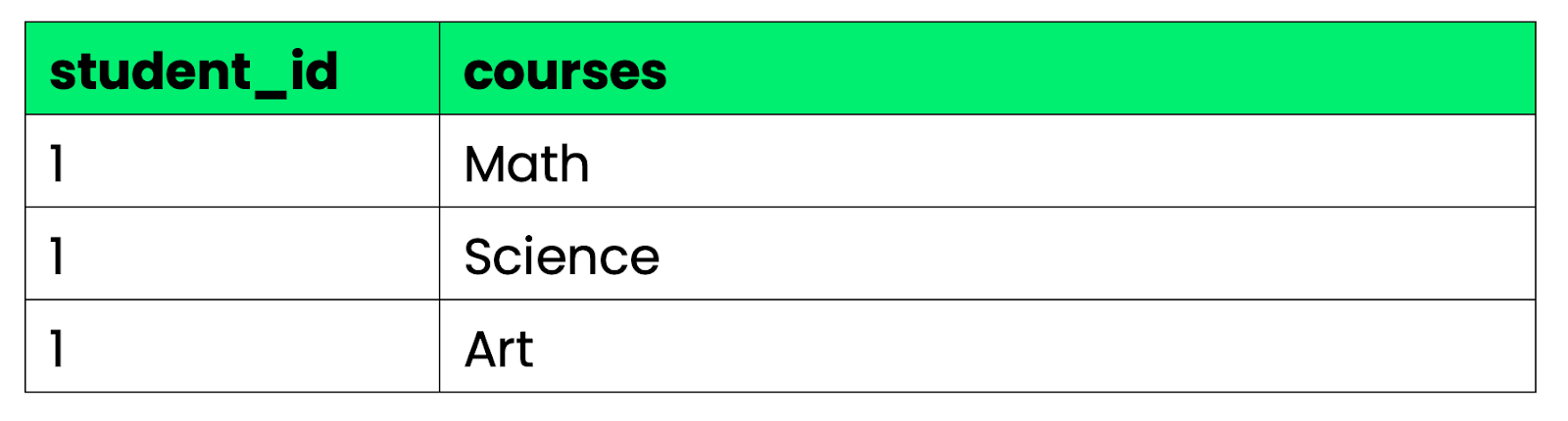
Imagem 2 - Um bom exemplo de 1NF
Segunda Forma Normal (2NF): Tem que estar em 1NF e tirar dependências parciais — as colunas que não são chaves têm que depender da chave primária inteira, não só de uma parte dela.
Isso vale quando você tem uma chave primária composta. Se você tem uma tabela com (student_id, course_id) como chave primária, então student_name não deveria estar nessa tabela, porque depende apenas de student_id, e não das duas chaves.
Terceira Forma Normal (3NF): Tem que estar em 2NF e tirar as dependências transitivas. As colunas que não são chaves não devem depender de outras colunas que também não são chaves.
Exemplo ruim:

Imagem 3 - Exemplo ruim de 3NF
Aqui, advisor_office depende de advisor_id, e não diretamente de student_id. Divida isso em tabelas separadas.
Sem a normalização, você armazenaria as informações do cliente em cada pedido, o que desperdiçaria espaço e criaria problemas de atualização quando os detalhes do cliente fossem alterados.
Esses comandos apagam dados de maneiras diferentes:
DELETE FROM employees WHERE department_id = 5;TRUNCATE TABLE employees;DROP TABLE employees;INNER JOIN retorna só os registros que batem nas duas tabelas:
SELECT e.name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.id;OUTER JOIN inclui registros que não combinam:
As junções SQL são um assunto bem complexo- Aqui estão 20 perguntas de entrevista só sobre junções
Um índice é uma estrutura de dados que agiliza a recuperação de dados criando atalhos para as linhas da tabela.
Pense nisso como o índice de um livro — em vez de ler todas as páginas para encontrar um tópico, você procura e vai direto para a página certa. Os índices tornam as consultas SELECT mais rápidas, mas diminuem a velocidade das operações INSERT, UPDATE e DELETE, porque o índice precisa ser atualizado.
CREATE INDEX idx_employee_email ON employees(email);Uma visualização é uma tabela virtual criada a partir de uma consulta SQL que não armazena dados propriamente ditos.
As visualizações simplificam consultas complexas, oferecem segurança ao ocultar colunas confidenciais e apresentam os dados em diferentes formatos. Quando você consulta uma visualização, o banco de dados executa o SQL subjacente e retorna os resultados como se fosse uma tabela real.
CREATE VIEW active_employees AS
SELECT employee_id, name, email
FROM employees
WHERE status = 'active';
SELECT * FROM active_employees;Os procedimentos armazenados são códigos SQL pré-compilados guardados no banco de dados que você pode executar pelo nome.
Elas melhoram o desempenho porque são pré-compiladas, reduzem o tráfego de rede ao executar várias instruções em uma única chamada e oferecem mais segurança por meio de consultas parametrizadas. Eles também centralizam a lógica de negócios no banco de dados.
CREATE PROCEDURE GetEmployeesByDepartment(IN dept_id INT)
BEGIN
SELECT * FROM employees WHERE department_id = dept_id;
END;O SQL procedural pode ser um tema importante na entrevista, dependendo da função. Essas 20 perguntas de entrevista são sobre Oracle PL/SQL.
Com isso resolvido, vamos mergulhar nas perguntas intermediárias que vão testar seus conhecimentos.
Aprenda mais sobre DBMS com esses cursos!
Programa
Curso
Curso
blog
Javier Canales Luna
15 min
blog
Javier Canales Luna
15 min
blog
Austin Chia
15 min
blog
Chloe Lubin
15 min

