
Cursus
SQL Server pour les administrateurs de bases de données
24 h
Vous vous préparez pour un entretien concernant les SGBD ? Vous êtes au bon endroit.
Vous êtes familier avec les bases de données dans le cadre de votre travail quotidien, mais les entretiens vous évaluent différemment des situations réelles. Les recruteurs ne souhaitent pas seulement évaluer votre capacité à rédiger des requêtes SQL ; ils évalueront également votre compréhension de la normalisation, des propriétés ACID et votre approche face aux problèmes de performance des bases de données dans des situations de pression. De nombreux professionnels des bases de données rencontrent des difficultés car ils ne parviennent pas à expliquer les concepts qu'ils utilisent quotidiennement ou éprouvent des difficultés avec les questions comportementales qui évaluent leur capacité à collaborer avec les équipes chargées des données.
Ce guide couvre les questions les plus fréquemment posées lors d'entretiens d'embauche dans le domaine des SGBD, tous niveaux de difficulté confondus. Vous obtiendrez également des stratégies éprouvées pour réussir les questions basées sur des scénarios et des conseils qui vous aideront à vous démarquer des autres candidats.
Commençons par les questions fondamentales qui sont posées lors de chaque entretien d'embauche pour un poste dans le domaine des SGBD.
Souhaitez-vous vous concentrer uniquement sur la partie codage de l'entretien? Voici 85 questions et réponses d'entretien SQL pour 2026.
Veuillez vous attendre à ce type de questions au début d'un entretien technique. Ils évaluent votre compréhension fondamentale des systèmes de gestion de bases de données.
Les examinateurs utilisent ces questions pour évaluer si vous comprenez les concepts fondamentaux des bases de données avant de passer à des scénarios plus complexes. Ils recherchent des explications claires et des exemples concrets qui démontrent que vous avez travaillé avec des bases de données, et non pas simplement mémorisé des définitions.
Un SGBD est un logiciel qui gère les bases de données : il gère le stockage, la récupération et l'organisation des données tout en garantissant la sécurité et la cohérence.
Considérez-le comme l'intermédiaire entre vos applications et les fichiers de données réels. Parmi les exemples les plus courants, on peut citer MySQL, PostgreSQL, Oracle et SQL Server. Le SGBD gère des tâches telles que l'authentification des utilisateurs, la sauvegarde des données et veille à ce que plusieurs utilisateurs puissent accéder aux données sans les corrompre.
Une base de données est l'ensemble des données elles-mêmes, tandis qu'un SGBD est le logiciel qui gère ces données.
La base de données contient vos tables, vos enregistrements et vos relations. Le SGBD fournit les outils et l'interface permettant d'interagir avec ces données. C'est comme la différence entre une bibliothèque (base de données) et le système de gestion de bibliothèque (SGBD) qui vous aide à trouver et à emprunter des livres.
Les principes ACID garantissent la fiabilité des transactions de base de données et préservent l'intégrité des données :
Voici un exemple concret : Lorsque vous effectuez un transfert d'argent entre des comptes bancaires, le débit et le crédit doivent être effectués simultanément (atomicité), les règles relatives au solde total restent valables (cohérence), les autres transactions ne voient pas les états partiels (isolement) et la modification persiste même en cas de panne du système (durabilité).
Les clés de base de données sont utilisées pour identifier de manière unique les enregistrements et établir des relations. Voici les types que vous devez connaître :
Voici un exemple simple :
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
department_id INT,
email VARCHAR(100) UNIQUE,
FOREIGN KEY (department_id) REFERENCES departments(id)
);La normalisation élimine la redondance des données en organisant les données dans des tableaux distinctes et liées entre elles.
Cela permet d'éviter les incohérences dans les données et d'économiser de l'espace de stockage. Voici comment fonctionnent les principales formes normales :
Première forme normale (1NF) : Chaque colonne contient des valeurs atomiques (indivisibles) - aucune liste ni valeur multiple dans une même cellule.
Exemple à éviter :

Image 1 - Exemple incorrect de 1NF
Exemple pertinent :
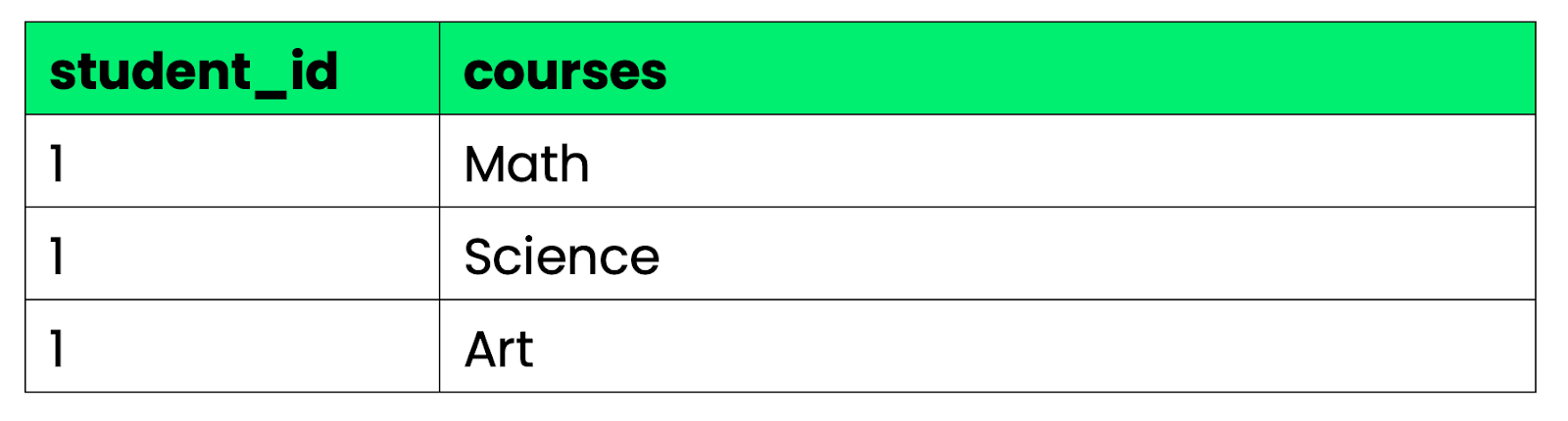
Image 2 - Bon exemple de 1NF
Deuxième forme normale (2NF) : Il doit être en 1NF et supprimer les dépendances partielles : les colonnes non clés doivent dépendre de la clé primaire dans son intégralité, et non seulement d'une partie de celle-ci.
Ceci s'applique lorsque vous disposez d'une clé primaire composite. Si vous avez un tableau avec (student_id, course_id) comme clé primaire, alors student_name ne devrait pas figurer dans ce tableau, car elle dépend uniquement de student_id, et non des deux clés.
Troisième forme normale (3NF) : Il est nécessaire que la base de données soit en 2NF et que les dépendances transitives soient supprimées. Les colonnes non clés ne devraient pas dépendre d'autres colonnes non clés.
Exemple à éviter :

Image 3 - Exemple incorrect de 3NF
Ici, advisor_office dépend de advisor_id, et non directement de student_id. Veuillez répartir ces informations dans des tableaux distincts.
Sans normalisation, vous stockeriez les informations client avec chaque commande, ce qui entraînerait un gaspillage d'espace et poserait des problèmes de mise à jour lorsque les coordonnées du client changent.
Ces commandes suppriment les données de différentes manières :
DELETE FROM employees WHERE department_id = 5;TRUNCATE TABLE employees;DROP TABLE employees;INNER JOIN Renvoie uniquement les enregistrements correspondants des deux tableaux :
SELECT e.name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.id;OUTER JOIN inclut les enregistrements non correspondants :
Les jointures SQL constituent un sujet complexe en soi. Voici 20 questions d'entretien portant uniquement sur les jointures.
Un index est une structure de données qui accélère la récupération des données en créant des raccourcis vers les lignes d'un tableau.
Considérez cela comme l'index d'un livre : au lieu de lire chaque page pour trouver un sujet, vous le recherchez et accédez directement à la page correspondante. Les index accélèrent les requêtes SELECT, mais ralentissent les opérations INSERT, UPDATE et DELETE, car l'index doit être mis à jour.
CREATE INDEX idx_employee_email ON employees(email);Une vue est une table virtuelle créée à partir d'une requête SQL qui ne stocke pas de données elle-même.
Les vues simplifient les requêtes complexes, renforcent la sécurité en masquant les colonnes sensibles et présentent les données sous différents formats. Lorsque vous interrogez une vue, la base de données exécute le code SQL sous-jacent et renvoie les résultats comme s'il s'agissait d'un tableau réel.
CREATE VIEW active_employees AS
SELECT employee_id, name, email
FROM employees
WHERE status = 'active';
SELECT * FROM active_employees;Les procédures stockées sont des codes SQL précompilés stocké dans la base de données que vous pouvez exécuter par son nom.
Ils améliorent les performances car ils sont précompilés, réduisent le trafic réseau en exécutant plusieurs instructions en un seul appel et offrent une meilleure sécurité grâce à des requêtes paramétrées. Ils centralisent également la logique métier dans la base de données.
CREATE PROCEDURE GetEmployeesByDepartment(IN dept_id INT)
BEGIN
SELECT * FROM employees WHERE department_id = dept_id;
END;Le SQL procédural peut constituer un sujet d'entretien important, selon le poste. Ces 20 questions d'entretien sont axées sur Oracle PL/SQL.
Maintenant que ces questions sont abordées, passons aux questions de niveau intermédiaire qui évalueront vos connaissances.
Veuillez approfondir vos connaissances sur les SGBD grâce à ces cours.
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Lynn Heidmann
