
Cursus
Concepten van Large Language Models (LLMs)
2 Hr
104.1K
LLM-distillatie is een techniek die het doel heeft de prestaties van een groot taalmodel te benaderen, terwijl de omvang en rekenvereisten worden verkleind.
Stel je een ervaren professor voor die zijn expertise deelt met een nieuwe student. De professor, die het teacher-model vertegenwoordigt, draagt complexe concepten en inzichten over, terwijl het student-model leert deze lessen op een eenvoudigere en efficiëntere manier na te bootsen.
Dit proces behoudt niet alleen de kerncompetenties van de teacher, maar optimaliseert de student ook voor snellere en flexibelere toepassingen.
De toenemende omvang en rekenvereisten van grote taalmodellen belemmeren brede adoptie en uitrol. Hoogwaardige hardware en stijgend energieverbruik beperken vaak de toegankelijkheid, zeker in omgevingen met beperkte middelen zoals mobiele apparaten of edge computing-platforms.
LLM-distillatie pakt deze uitdagingen aan door kleinere en snellere modellen te produceren, ideaal voor integratie op een breder scala aan apparaten en platforms.
Deze innovatie democratiseert niet alleen de toegang tot geavanceerde AI, maar ondersteunt ook realtime-toepassingen waar snelheid en efficiëntie cruciaal zijn. Door toegankelijkere en schaalbare AI-oplossingen mogelijk te maken, versnelt LLM-distillatie de praktische inzet van AI-technologieën.
Het LLM-distillatieproces omvat verschillende technieken die ervoor zorgen dat het student-model kerninformatie behoudt en tegelijk efficiënter werkt. Hier bespreken we de belangrijkste mechanismen achter effectieve kennisoverdracht.
Het teacher-studentparadigma vormt de kern van LLM-distillatie en drijft de kennisoverdracht. In deze opzet draagt een groter, geavanceerder model zijn kennis over aan een kleiner, lichter model.
Het teacher-model, vaak een state-of-the-art taalmodel met uitgebreide training en rekenkracht, fungeert als rijke informatiebron. De student is ontworpen om van de teacher te leren door diens gedrag na te bootsen en kennis te internaliseren.
De primaire taak van het student-model is de output van de teacher te reproduceren, met een veel kleinere omvang en lagere rekenvereisten. Dit houdt in dat de student leert van de voorspellingen, aanpassingen en reacties van de teacher op uiteenlopende input.
Zo kan de student een vergelijkbaar prestatieniveau en begrip bereiken, waardoor het geschikt is voor inzet in omgevingen met beperkte middelen.
Er worden diverse distillatietechnieken gebruikt om kennis van de teacher naar de student over te dragen. Deze zorgen ervoor dat de student niet alleen efficiënt leert, maar ook de essentiële kennis en capaciteiten van de teacher behoudt. Enkele prominente technieken in LLM-distillatie:
Een van de bekendste technieken is knowledge distillation (KD). Bij KD wordt de student getraind met de outputkansen van de teacher, de zogeheten soft targets, naast de grondwaarheidslabels, de hard targets.
Soft targets geven een genuanceerd beeld van de voorspellingen van de teacher, met een kansverdeling over mogelijke uitkomsten in plaats van één juist antwoord. Deze extra informatie helpt de student subtiele patronen en complexe kennis in de reacties van de teacher te vangen.
Door soft targets te gebruiken, leert de student het beslisproces van de teacher beter begrijpen, wat tot nauwkeurigere en betrouwbaardere prestaties leidt. Deze aanpak bewaart cruciale kennis en maakt de training van de student vloeiender en effectiever.
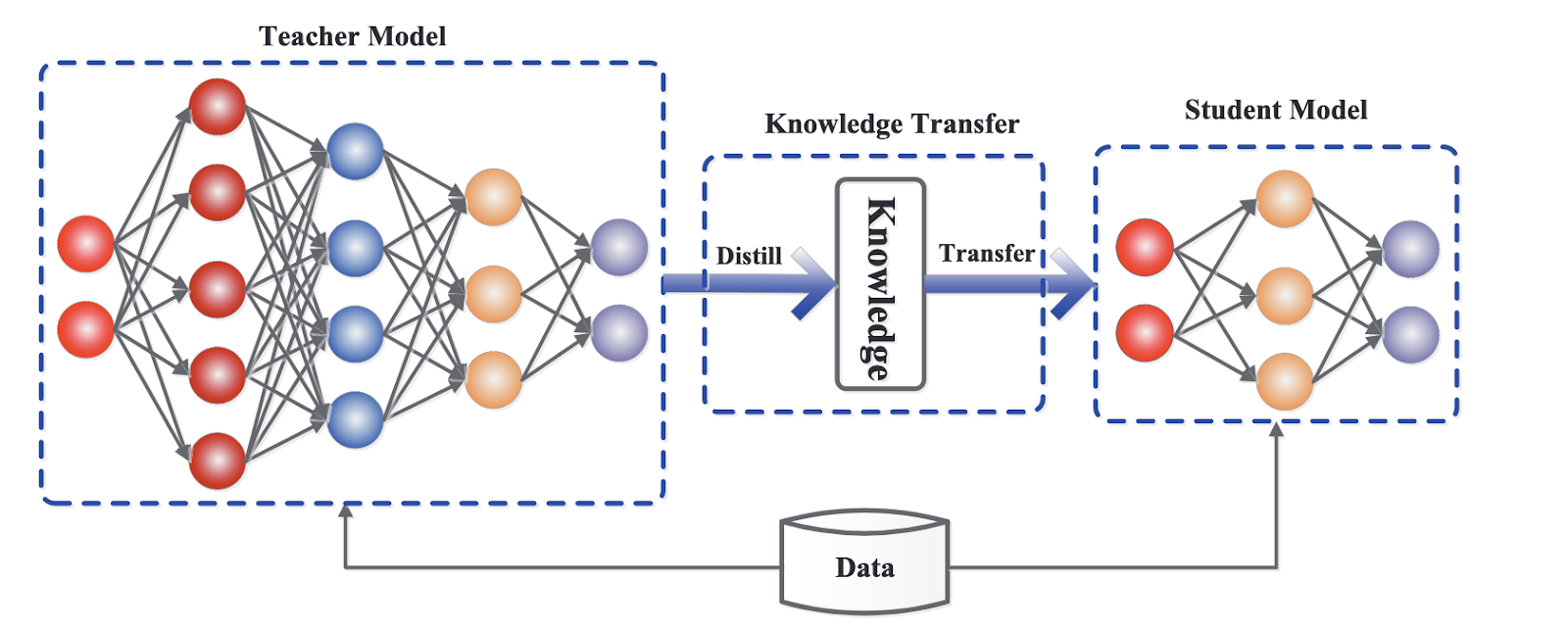
Algemeen framework voor knowledge distillation. Bron
Naast KD zijn er meerdere technieken die het distillatieproces kunnen verbeteren:
LLM-distillatie biedt tal van voordelen die de bruikbaarheid en efficiëntie van taalmodellen vergroten, waardoor ze praktischer worden voor uiteenlopende toepassingen.
Hier bespreken we een paar kernvoordelen.
Een van de belangrijkste voordelen is dat modellen merkbaar kleiner worden. Door kennis van een grote teacher naar een kleine student over te brengen, behoudt de student veel van de capaciteiten, maar dan in fractie van de omvang.
Dit levert op:
De kleinere omvang vertaalt zich direct in snellere inferentie. Dit is vooral belangrijk voor toepassingen die realtime verwerking en snelle reacties vereisen.
Zo komt dit tot uiting:
Een ander voordeel is lagere rekenkosten. Kleinere modellen vragen minder rekenkracht, wat kostenbesparingen oplevert:
Gedistilleerde LLM’s zijn veelzijdiger en toegankelijker, waardoor uitrol over platforms mogelijk is. Dit heeft meerdere implicaties:
De voordelen van LLM-distillatie gaan verder dan efficiëntie en kosten. Gedistilleerde taalmodellen zijn inzetbaar voor uiteenlopende natural language processing (NLP)-taken en sectorspecifieke use-cases, waardoor AI-oplossingen breed toegankelijk worden.
Gedistilleerde LLM’s blinken uit in veel NLP-taken. Door hun kleinere omvang en goede prestaties zijn ze ideaal voor realtime verwerking met minder rekenkracht.
Gedistilleerde LLM’s maken kleinere, snellere chatbots mogelijk die klantenservice soepel afhandelen. Ze begrijpen en beantwoorden vragen in realtime, zonder zware rekenkracht.
Samenvattingstools op basis van gedistilleerde LLM’s kunnen nieuwsartikelen, documenten of socialmediastromen tot bondige kernpunten terugbrengen, zodat gebruikers snel de essentie zien.
Gedistilleerde modellen versnellen en verbreden vertaalservices op apparaten. Ze draaien op telefoons, tablets en zelfs offline, met realtimevertaling en lagere latency en rekenlast.
Naast gangbare NLP-taken presteren gedistilleerde LLM’s ook goed in specialistische gebieden die snelle verwerking en nauwkeurigheid vragen.
Gedistilleerde LLM’s beperken zich niet tot algemene NLP-taken. Ze kunnen ook sectoren veranderen door processen en gebruikerservaringen te verbeteren en innovatie te stimuleren.
In de zorgsector verwerken gedistilleerde LLM’s patiëntendossiers en diagnostische data efficiënter, wat snellere en nauwkeurigere diagnoses ondersteunt. Ze kunnen in medische apparaten worden ingezet voor realtime data-analyse en besluitvorming.
De financiële sector profiteert via betere fraudedetectiesystemen en klantinteractiemodellen. Door snel transacties en vragen te doorgronden, helpen LLM’s fraude voorkomen en gepersonaliseerd advies te bieden.
In het onderwijs faciliteren gedistilleerde LLM’s adaptieve leersystemen en gepersonaliseerde tutoring. Ze analyseren prestaties en bieden maatwerkcontent, wat leerresultaten verbetert en onderwijs toegankelijker maakt.
Het implementeren van LLM-distillatie vraagt om meerdere stappen en gespecialiseerde frameworks en libraries. Hier bespreken we de tools en stappen om een groot taalmodel te distilleren.
Er zijn diverse frameworks en libraries die het distillatieproces stroomlijnen, elk met eigen functies voor LLM-distillatie.
De Hugging Face Transformers-library is een populaire tool voor LLM-distillatie. Het bevat een Distiller-klasse die de kennisoverdracht van teacher naar student vereenvoudigt.
Met de Distiller-klasse kun je voorgetrainde modellen inzetten, ze finetunen op specifieke datasets en distillatietechnieken toepassen voor optimale resultaten.
Naast Hugging Face Transformers ondersteunen ook andere libraries LLM-distillatie:
Distiller is bedoeld om deep learning-modellen te comprimeren, met ondersteuning voor distillatie en handige utilities voor efficiëntiebeheer.Het implementeren van LLM-distillatie vraagt zorgvuldige planning en uitvoering. Dit zijn de belangrijkste stappen.
Begin met een geschikt trainingsdataset voor de student. Het dataset moet representatief zijn voor de taken, zodat de student goed generaliseert.
Data-augmentatie kan het dataset verder verrijken en de student blootstellen aan meer voorbeelden.
Een passend teacher-model kiezen is cruciaal. Het moet een goed presterend, voorgetraind model zijn met hoge nauwkeurigheid op de doeltaken. De kwaliteit en eigenschappen van de teacher bepalen direct de prestaties van de student.
Het distillatieproces omvat:
De prestaties van het gedistilleerde model evalueren is essentieel. Veelgebruikte metriek zijn:
Ik ga dieper in op LLM-evaluatie in dit artikel over LLM-evaluatie: metriek, methodologieën, best practices.
Hoewel LLM-distillatie veel voordelen biedt, zijn er ook uitdagingen die je moet adresseren voor een succesvolle implementatie.
Een van de grootste hobbels is mogelijk kennisverlies. Tijdens distillatie wordt niet altijd alle nuance en detail van de teacher volledig door de student vastgelegd, met prestatieverlies als gevolg. Dit speelt vooral bij taken die diepe of specialistische kennis vragen.
Strategieën om kennisverlies te beperken:
Zorgvuldige tuning is cruciaal. Belangrijke hyperparameters, zoals temperatuur en learning rate, beïnvloeden sterk hoe goed de student leert van de teacher:
Het beoordelen van de effectiviteit is onmisbaar om te garanderen dat het model aan de gewenste criteria voldoet, zeker vergeleken met voorgangers en alternatieven. Vergelijk de student met de teacher en andere baselines om te zien in hoeverre functionaliteit is behouden of verbeterd.
Richt je op de volgende metriek:
Door best practices te volgen, vergroot je de effectiviteit van LLM-distillatie. De nadruk ligt op experimenteren, continu evalueren en strategisch implementeren.
Het veld van LLM-distillatie ontwikkelt zich razendsnel. In deze sectie: trends, huidige onderzoeksuitdagingen en opkomende technieken.
Recent onderzoek richt zich op nieuwe technieken en architecturen om de efficiëntie en effectiviteit van distillatie te vergroten. Enkele opvallende ontwikkelingen:
Ondanks de vooruitgang blijven er uitdagingen en open vragen:
Nieuwe technieken worden continu ontwikkeld om deze uitdagingen aan te pakken en het veld vooruit te helpen. Veelbelovende benaderingen zijn:
LLM-distillatie is een cruciale techniek om grote taalmodellen praktischer en efficiënter te maken. Door essentiële kennis van een complexe teacher naar een kleinere student over te dragen, blijft de prestatie behouden terwijl omvang en rekenlast afnemen.
Dit maakt snellere, toegankelijkere AI-toepassingen mogelijk in uiteenlopende sectoren, van realtime NLP-taken tot specialistische use-cases in zorg en finance. De implementatie vraagt zorgvuldige planning en de juiste tools, maar de baten—zoals lagere kosten en bredere uitrol—zijn aanzienlijk.
Naarmate onderzoek vordert, zal LLM-distillatie een steeds grotere rol spelen in het democratiseren van AI, zodat krachtige modellen toegankelijker en bruikbaarder worden in diverse contexten.
Leer over LLM’s met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
