
Corso
Concetti sui Large Language Models (LLM)
2 h
104.1K
La distillazione degli LLM è una tecnica che punta a replicare le prestazioni di un large language model riducendone al contempo dimensioni e requisiti computazionali.
Immagina un professore esperto che condivide la sua competenza con un nuovo studente. Il professore, che rappresenta il modello teacher, trasmette concetti e intuizioni complessi, mentre il modello student impara a imitarne gli insegnamenti in modo più semplice ed efficiente.
Questo processo non solo conserva le competenze chiave del teacher, ma ottimizza anche lo student per applicazioni più rapide e versatili.
L’aumento delle dimensioni e dei requisiti computazionali dei large language model ne ostacola l’adozione e il deployment su larga scala. Hardware ad alte prestazioni e consumi energetici in crescita limitano spesso l’accessibilità di questi modelli, soprattutto in contesti con risorse ridotte come i dispositivi mobili o le piattaforme di edge computing.
La distillazione degli LLM affronta queste sfide producendo modelli più piccoli e veloci, ideali per l’integrazione su un ventaglio più ampio di dispositivi e piattaforme.
Questa innovazione non solo democratizza l’accesso all’AI avanzata, ma supporta anche applicazioni in tempo reale, dove velocità ed efficienza sono fondamentali. Abilitando soluzioni di AI più accessibili e scalabili, la distillazione aiuta a far progredire l’implementazione pratica delle tecnologie di AI.
La distillazione degli LLM comprende diverse tecniche per fare in modo che il modello student mantenga le informazioni chiave operando in modo più efficiente. Di seguito esploriamo i meccanismi che rendono efficace questo trasferimento di conoscenza.
Il paradigma teacher-student è il cuore della distillazione degli LLM, un concetto fondamentale che guida il trasferimento della conoscenza. In questa impostazione, un modello più grande e avanzato trasferisce il suo sapere a un modello più piccolo e leggero.
Il modello teacher, spesso uno stato dell’arte addestrato con ampie risorse, funge da ricca fonte di informazioni. Lo student, invece, è progettato per apprendere dal teacher imitando il suo comportamento e interiorizzandone le conoscenze.
Il compito principale dello student è replicare gli output del teacher mantenendo dimensioni molto più contenute e requisiti computazionali ridotti. Questo comporta osservare e apprendere dalle previsioni, dagli aggiustamenti e dalle risposte del teacher a vari input.
Così facendo, lo student può raggiungere un livello di prestazioni e comprensione paragonabile, diventando adatto al deployment in ambienti con risorse limitate.
Per trasferire conoscenza dal teacher allo student si usano diverse tecniche. Questi metodi assicurano che lo student non solo impari in modo efficiente, ma conservi anche le conoscenze e le capacità essenziali del teacher. Ecco alcune tra le più diffuse nella distillazione degli LLM.
Una delle tecniche più note è la knowledge distillation (KD). In KD, il modello student viene addestrato usando le probabilità di output del teacher, dette soft target, insieme alle etichette di verità a terra, dette hard target.
I soft target offrono una visione sfumata delle previsioni del teacher, fornendo una distribuzione di probabilità sugli output possibili anziché una singola risposta corretta. Queste informazioni aggiuntive aiutano lo student a cogliere i pattern sottili e le conoscenze complesse racchiuse nelle risposte del teacher.
Usando i soft target, lo student può comprendere meglio il processo decisionale del teacher, ottenendo prestazioni più accurate e affidabili. Questo approccio preserva le conoscenze critiche del teacher e rende l’addestramento dello student più fluido ed efficace.
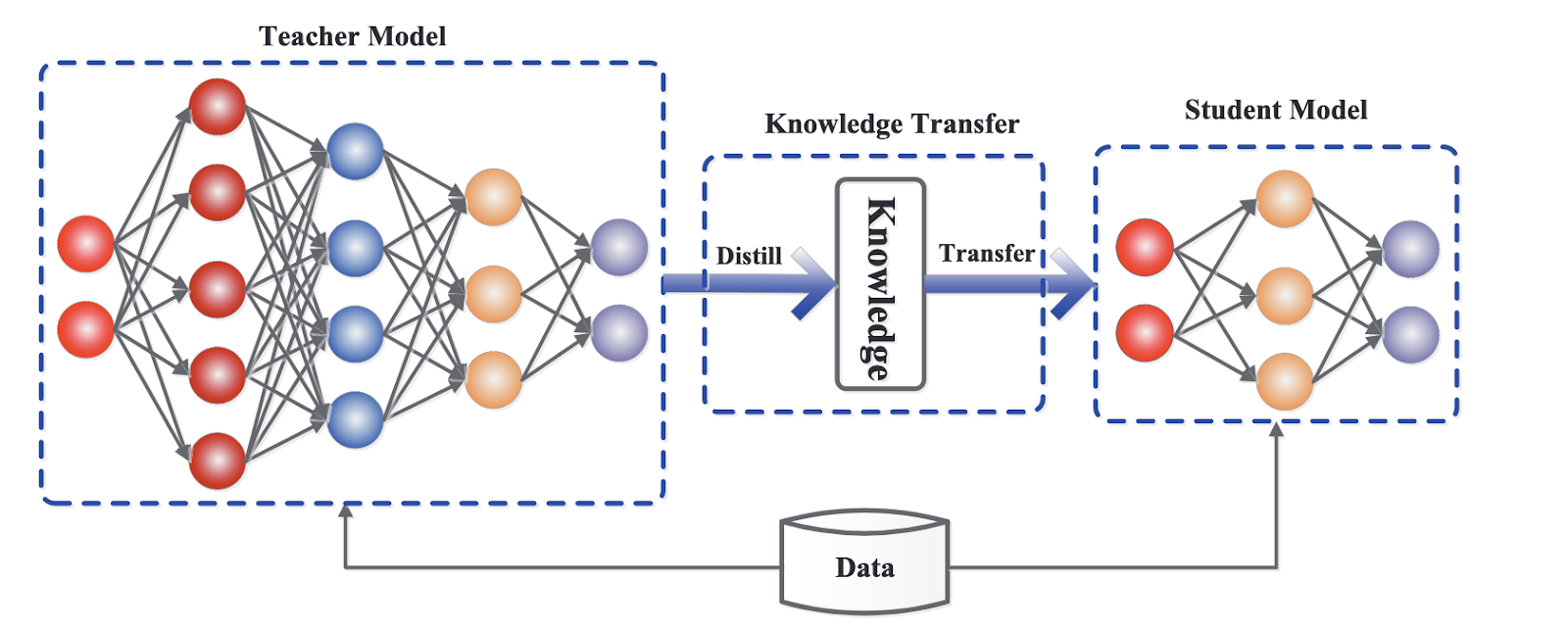
Framework generico per la knowledge distillation. Fonte
Oltre alla KD, diverse altre tecniche possono migliorare il processo:
La distillazione offre numerosi vantaggi che migliorano usabilità ed efficienza dei modelli linguistici, rendendoli più pratici per applicazioni diverse.
Ecco alcuni dei principali benefici.
Uno dei vantaggi principali è la creazione di modelli sensibilmente più piccoli. Trasferendo conoscenza da un teacher grande a uno student piccolo, il modello risultante conserva gran parte delle capacità del teacher pur avendo una frazione delle sue dimensioni.
La riduzione delle dimensioni porta a:
Le dimensioni ridotte dei modelli distillati si traducono direttamente in una velocità di inferenza superiore. È particolarmente importante per applicazioni che richiedono elaborazione in tempo reale e risposte rapide.
Ecco come si manifesta questo vantaggio:
Un altro vantaggio rilevante è la riduzione dei costi computazionali. I modelli più piccoli richiedono meno potenza per essere eseguiti, con risparmi in vari ambiti:
Gli LLM distillati sono più versatili e accessibili, consentendo il deployment su più piattaforme. Questa maggiore diffusione ha diverse implicazioni:
I vantaggi della distillazione vanno ben oltre l’efficienza e i risparmi. I modelli linguistici distillati si applicano a un’ampia gamma di attività di natural language processing (NLP) e casi d’uso specifici di settore, rendendo le soluzioni di AI accessibili in vari ambiti.
Gli LLM distillati eccellono in molti compiti di NLP. Le loro dimensioni ridotte e le prestazioni migliorate li rendono ideali per task che richiedono elaborazione in tempo reale e minore potenza computazionale.
Gli LLM distillati permettono di sviluppare chatbot più piccoli e veloci che gestiscono con fluidità assistenza e supporto. Questi chatbot comprendono e rispondono alle domande in tempo reale, offrendo un’esperienza senza attriti senza richiedere ingenti risorse.
Strumenti di sintesi basati su LLM distillati possono condensare articoli, documenti o feed social in riepiloghi concisi. Aiutano gli utenti a cogliere rapidamente i punti chiave senza leggere testi lunghi.
I modelli distillati rendono i servizi di traduzione più veloci e accessibili sui dispositivi. Possono essere distribuiti su telefoni, tablet e anche in app offline, fornendo traduzioni in tempo reale con minore latenza e overhead computazionale.
Gli LLM distillati non sono utili solo per i compiti comuni di NLP, ma brillano anche in ambiti specializzati che richiedono elaborazione rapida e risultati accurati.
Gli LLM distillati non si limitano ai classici task di NLP. Possono incidere su molti settori migliorando processi ed esperienze utente e stimolando l’innovazione.
Nel settore sanitario, gli LLM distillati possono elaborare cartelle cliniche e dati diagnostici in modo più efficiente, abilitando diagnosi più rapide e accurate. Possono essere integrati in dispositivi medici, supportando medici e operatori con analisi dati e decisioni in tempo reale.
Il settore finanziario beneficia di modelli distillati grazie a sistemi di rilevamento frodi potenziati e modelli per l’interazione con i clienti. Decifrando rapidamente pattern di transazioni e richieste, aiutano a prevenire attività fraudolente e a fornire consulenza e supporto personalizzati.
Nell’istruzione, gli LLM distillati facilitano la creazione di sistemi di apprendimento adattivi e piattaforme di tutoraggio personalizzate. Questi sistemi analizzano il rendimento e offrono contenuti su misura, migliorando gli esiti e rendendo l’istruzione più accessibile ed efficace.
Implementare la distillazione richiede una serie di passaggi e l’uso di framework e librerie specializzate pensate per agevolare il processo. Vediamo strumenti e fasi necessari per distillare un large language model.
Per semplificare la distillazione sono disponibili vari framework e librerie, ognuno con caratteristiche utili al processo.
La libreria Hugging Face Transformers è uno strumento molto diffuso per implementare la distillazione. Include una classe Distiller che semplifica il trasferimento di conoscenza da un teacher a uno student.
Usando la classe Distiller è possibile sfruttare modelli pre-addestrati, affinarli su dataset specifici e applicare tecniche di distillazione per risultati ottimali.
Oltre a Hugging Face Transformers, molte altre librerie supportano la distillazione degli LLM:
Distiller di PyTorch è pensato per comprimere modelli di deep learning, con supporto alla distillazione. Offre varie utility per gestire il processo e migliorare l’efficienza.Implementare la distillazione richiede pianificazione ed esecuzione attente. Ecco i passaggi chiave.
Il primo passo è predisporre un dataset adatto ad addestrare lo student. Il dataset dovrebbe rappresentare i compiti che il modello svolgerà, così che lo student impari a generalizzare bene.
Le tecniche di data augmentation possono arricchire il dataset, fornendo allo student una gamma più ampia di esempi da cui apprendere.
La scelta di un teacher adeguato è necessaria per una distillazione efficace. Dovrebbe essere un modello pre-addestrato ad alte prestazioni e con elevata accuratezza sui task target. La qualità e le caratteristiche del teacher influenzano direttamente le prestazioni dello student.
Il processo comprende i passaggi seguenti:
Valutare le prestazioni del modello distillato è essenziale per verificarne il rispetto dei criteri desiderati. Le metriche comuni includono:
Approfondisco la valutazione degli LLM in questo articolo su LLM Evaluation: Metriche, metodologie, best practice.
Sebbene offra numerosi benefici, la distillazione presenta anche diverse sfide da affrontare per garantire un’implementazione di successo.
Una delle difficoltà principali è il potenziale di perdita di conoscenza. Durante la distillazione, alcune informazioni e caratteristiche sottili del teacher potrebbero non essere pienamente catturate dallo student, con un calo di prestazioni. Il problema può essere marcato nei compiti che richiedono comprensione profonda o conoscenze specialistiche.
Ecco alcune strategie per mitigare la perdita di conoscenza:
Un’attenta messa a punto degli iperparametri è vitale. Parametri come temperatura e learning rate influenzano in modo significativo la capacità dello student di apprendere dal teacher:
Valutare l’efficacia del modello distillato è indispensabile per garantire che soddisfi i criteri di prestazione desiderati, soprattutto rispetto ai predecessori e alle alternative. Ciò implica confrontare lo student con il teacher e con altre baseline, per capire quanto la distillazione abbia preservato o migliorato la funzionalità.
Per valutare l’efficacia, è importante concentrarsi su queste metriche:
Seguire le best practice può aumentare l’efficacia della distillazione. Queste linee guida enfatizzano sperimentazione, valutazione continua e implementazione strategica.
Il campo della distillazione degli LLM evolve rapidamente. In questa sezione esploriamo trend, sfide di ricerca attuali e tecniche emergenti.
Le ricerche recenti si concentrano su nuove tecniche e architetture per aumentare efficienza ed efficacia della distillazione. Tra i progressi notevoli:
Nonostante i progressi, restano diverse sfide e questioni aperte:
Tecniche e innovazioni emergenti vengono sviluppate continuamente per affrontare queste sfide e far avanzare il campo. Alcuni approcci promettenti:
La distillazione degli LLM è una tecnica decisiva per rendere i large language model più pratici ed efficienti. Trasferendo conoscenze essenziali da un teacher complesso a uno student più piccolo, preserva le prestazioni riducendo dimensioni e requisiti computazionali.
Questo processo abilita applicazioni di AI più rapide e accessibili in vari settori, dai task NLP in tempo reale ai casi d’uso specializzati in sanità e finanza. Implementare la distillazione richiede pianificazione attenta e gli strumenti giusti, ma i benefici—come costi inferiori e deployment più ampio—sono notevoli.
Con il progresso della ricerca, la distillazione avrà un ruolo sempre più importante nella democratizzazione dell’AI, rendendo i modelli potenti più accessibili e usabili in contesti diversi.
Impara gli LLM con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

