
Kursus
Konsep Large Language Models (LLM)
2 Hr
104.3K
Distilasi LLM adalah teknik yang berupaya mereplikasi kinerja model bahasa besar sambil mengurangi ukuran dan kebutuhan komputasinya.
Bayangkan seorang profesor berpengalaman membagikan keahliannya kepada siswa baru. Profesor, yang merepresentasikan model guru, menyampaikan konsep dan wawasan yang kompleks, sementara model murid belajar meniru ajaran tersebut dengan cara yang lebih sederhana dan efisien.
Proses ini tidak hanya mempertahankan kompetensi inti dari sang guru, tetapi juga mengoptimalkan murid untuk aplikasi yang lebih cepat dan serbaguna.
Ukuran yang terus meningkat dan kebutuhan komputasi model bahasa besar menghambat adopsi dan penerapan secara luas. Perangkat keras berkinerja tinggi dan konsumsi energi yang meningkat sering kali membatasi aksesibilitas model-model ini, khususnya di lingkungan dengan sumber daya terbatas seperti perangkat seluler atau platform komputasi tepi.
Distilasi LLM mengatasi tantangan ini dengan menghasilkan model yang lebih kecil dan lebih cepat, sehingga ideal untuk diintegrasikan ke berbagai perangkat dan platform.
Inovasi ini tidak hanya mendemokratisasi akses ke AI tingkat lanjut, tetapi juga mendukung aplikasi waktu nyata di mana kecepatan dan efisiensi sangat dihargai. Dengan memungkinkan solusi AI yang lebih mudah diakses dan dapat diskalakan, distilasi LLM membantu memajukan implementasi praktis teknologi AI.
Proses distilasi LLM melibatkan beberapa teknik yang memastikan model murid mempertahankan informasi kunci sambil beroperasi lebih efisien. Di sini, kita bahas mekanisme utama yang membuat transfer pengetahuan ini efektif.
Paradigma guru-murid berada di jantung distilasi LLM, sebuah konsep dasar yang mendorong proses transfer pengetahuan. Dalam pengaturan ini, model yang lebih besar dan lebih canggih menurunkan pengetahuannya ke model yang lebih kecil dan ringan.
Model guru, sering kali merupakan model bahasa mutakhir dengan pelatihan dan sumber daya komputasi yang luas, berperan sebagai sumber informasi yang kaya. Di sisi lain, model murid dirancang untuk belajar dari guru dengan meniru perilakunya dan menginternalisasi pengetahuannya.
Tugas utama model murid adalah mereplikasi keluaran guru sambil tetap berukuran jauh lebih kecil dan membutuhkan komputasi yang lebih rendah. Proses ini melibatkan pengamatan dan pembelajaran dari prediksi, penyesuaian, dan respons guru terhadap berbagai masukan.
Dengan demikian, murid dapat mencapai tingkat kinerja dan pemahaman yang sebanding, sehingga cocok untuk diterapkan di lingkungan dengan keterbatasan sumber daya.
Berbagai teknik distilasi digunakan untuk mentransfer pengetahuan dari guru ke murid. Metode-metode ini memastikan model murid tidak hanya belajar secara efisien, tetapi juga mempertahankan pengetahuan dan kemampuan esensial dari model guru. Berikut beberapa teknik paling menonjol yang digunakan dalam distilasi LLM.
Salah satu teknik paling menonjol dalam distilasi LLM adalah knowledge distillation (KD). Dalam KD, model murid dilatih menggunakan probabilitas keluaran model guru, yang dikenal sebagai soft targets, bersamaan dengan label kebenaran dasar yang disebut hard targets.
Soft targets memberikan pandangan bernuansa tentang prediksi guru, menawarkan distribusi probabilitas atas kemungkinan keluaran alih-alih satu jawaban benar. Informasi tambahan ini membantu model murid menangkap pola halus dan pengetahuan rumit yang tersandi dalam respons guru.
Dengan menggunakan soft targets, model murid dapat lebih memahami proses pengambilan keputusan guru, sehingga menghasilkan kinerja yang lebih akurat dan andal. Pendekatan ini tidak hanya mempertahankan pengetahuan kritis dari guru, tetapi juga memungkinkan proses pelatihan yang lebih mulus dan efektif bagi murid.
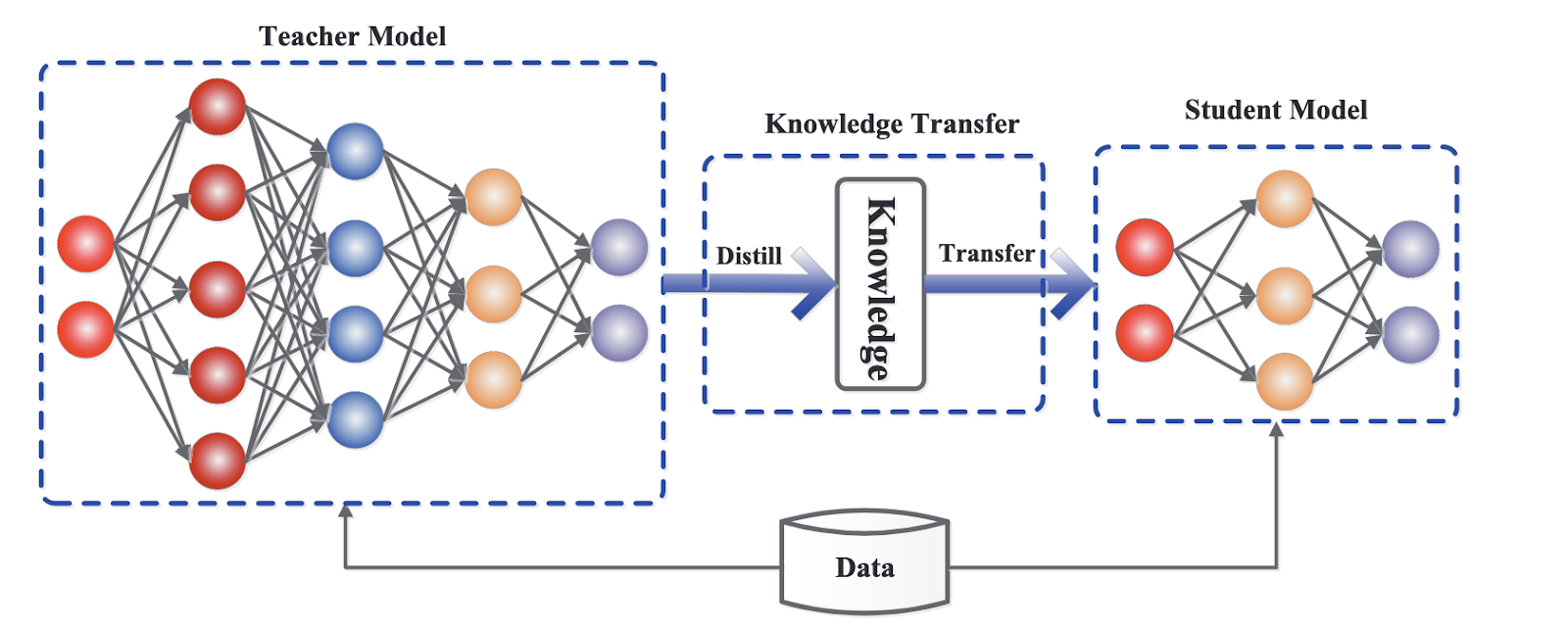
Kerangka umum untuk knowledge distillation. Sumber
Di luar KD, beberapa teknik lain dapat meningkatkan proses distilasi LLM:
Distilasi LLM menawarkan berbagai manfaat besar yang meningkatkan kegunaan dan efisiensi model bahasa, menjadikannya lebih praktis untuk beragam aplikasi.
Berikut beberapa keunggulan utamanya.
Salah satu manfaat utama distilasi LLM adalah terciptanya model yang jauh lebih kecil. Dengan mentransfer pengetahuan dari model guru yang besar ke model murid yang lebih kecil, murid mempertahankan banyak kemampuan guru meski ukurannya hanya sebagian kecil.
Pengurangan ukuran ini menghasilkan:
Ukuran model hasil distilasi yang lebih kecil berbanding lurus dengan peningkatan kecepatan inferensi. Ini sangat penting untuk aplikasi yang memerlukan pemrosesan waktu nyata dan respons cepat.
Berikut wujud manfaatnya:
Keuntungan lain yang patut dicatat dari distilasi LLM adalah pengurangan biaya komputasi. Model yang lebih kecil membutuhkan daya komputasi lebih sedikit untuk berjalan, yang menghasilkan penghematan biaya di beberapa area:
LLM terdistilasi lebih serbaguna dan mudah diakses, memungkinkan penerapan lintas platform. Jangkauan yang diperluas ini memiliki beberapa implikasi:
Manfaat distilasi LLM melampaui efisiensi model dan penghematan biaya. Model bahasa terdistilasi dapat diterapkan di berbagai tugas pemrosesan bahasa alami (NLP) dan use case spesifik industri, membuat solusi AI dapat diakses di berbagai bidang.
LLM terdistilasi unggul dalam banyak tugas pemrosesan bahasa alami. Ukurannya yang lebih kecil dan kinerja yang ditingkatkan membuatnya ideal untuk tugas yang memerlukan pemrosesan waktu nyata dan daya komputasi lebih rendah.
LLM terdistilasi memungkinkan pengembangan chatbot yang lebih kecil dan cepat yang dapat menangani tugas layanan dan dukungan pelanggan dengan lancar. Chatbot ini dapat memahami dan merespons pertanyaan pengguna secara waktu nyata, memberikan pengalaman pelanggan yang mulus tanpa memerlukan komputasi yang ekstensif.
Alat perangkuman berbasis LLM terdistilasi dapat memadatkan artikel berita, dokumen, atau linimasa media sosial menjadi ringkasan yang singkat. Ini membantu pengguna cepat memahami poin-poin utama tanpa harus membaca teks yang panjang.
Model terdistilasi membuat layanan penerjemahan lebih cepat dan mudah diakses di berbagai perangkat. Model ini dapat diterapkan pada ponsel, tablet, bahkan aplikasi offline, menghadirkan terjemahan waktu nyata dengan latensi dan beban komputasi yang lebih rendah.
LLM terdistilasi tidak hanya berharga untuk tugas NLP umum, tetapi juga unggul di area spesialis yang memerlukan pemrosesan cepat dan hasil akurat.
LLM terdistilasi tidak hanya terbatas pada tugas NLP umum. Model ini juga dapat berdampak pada banyak industri dengan memperbaiki proses, pengalaman pengguna, dan mendorong inovasi.
Di industri kesehatan, LLM terdistilasi dapat memproses rekam medis dan data diagnostik dengan lebih efisien, memungkinkan diagnosis yang lebih cepat dan akurat. Model ini dapat diterapkan dalam perangkat medis, mendukung dokter dan tenaga kesehatan dengan analisis data waktu nyata dan pengambilan keputusan.
Sektor keuangan diuntungkan dengan model terdistilasi melalui peningkatan sistem deteksi penipuan dan model interaksi pelanggan. Dengan cepat mengurai pola transaksi dan pertanyaan pelanggan, LLM terdistilasi membantu mencegah aktivitas penipuan dan memberikan saran serta dukungan finansial yang dipersonalisasi.
Di bidang pendidikan, LLM terdistilasi memfasilitasi pembuatan sistem pembelajaran adaptif dan platform tutor personal. Sistem ini dapat menganalisis kinerja siswa dan menawarkan konten pembelajaran yang disesuaikan, meningkatkan hasil belajar dan membuat pendidikan lebih mudah diakses serta berdampak.
Mengimplementasikan distilasi LLM melibatkan serangkaian langkah dan penggunaan kerangka kerja serta pustaka khusus yang dirancang untuk memfasilitasi proses. Di sini, kita bahas alat dan langkah yang diperlukan untuk mendistilasi model bahasa besar.
Untuk merampingkan proses distilasi, beberapa kerangka kerja dan pustaka tersedia, masing-masing menawarkan fitur unik untuk mendukung distilasi LLM.
Pustaka Hugging Face transformers adalah alat populer untuk mengimplementasikan distilasi LLM. Pustaka ini mencakup kelas Distiller yang menyederhanakan proses transfer pengetahuan dari model guru ke model murid.
Dengan menggunakan kelas Distiller, praktisi dapat memanfaatkan model pralatih, melakukan fine-tuning pada dataset tertentu, dan menerapkan teknik distilasi untuk mencapai hasil optimal.
Selain Hugging Face Transformers, banyak pustaka lain yang mendukung distilasi LLM:
Distiller dirancang untuk mengompresi model pembelajaran mendalam, termasuk dukungan untuk teknik distilasi. Pustaka ini menawarkan berbagai utilitas untuk mengelola proses distilasi dan meningkatkan efisiensi model.Mengimplementasikan distilasi LLM memerlukan perencanaan dan eksekusi yang cermat. Berikut langkah-langkah kunci yang terlibat dalam prosesnya.
Langkah pertama dalam proses distilasi adalah menyiapkan dataset yang sesuai untuk melatih model murid. Dataset harus representatif terhadap tugas yang akan dijalankan model, memastikan model murid belajar untuk mengeneralisasi dengan baik.
Teknik augmentasi data juga dapat meningkatkan dataset, memberikan model murid rentang contoh yang lebih luas untuk dipelajari.
Memilih model guru yang tepat diperlukan untuk distilasi yang berhasil. Model guru harus merupakan model pralatih berkinerja baik dengan tingkat akurasi tinggi pada tugas target. Kualitas dan atribut model guru secara langsung memengaruhi kinerja model murid.
Proses distilasi melibatkan langkah-langkah berikut:
Mengevaluasi kinerja model terdistilasi penting untuk memastikan ia memenuhi kriteria yang diinginkan. Metrik evaluasi umum meliputi:
Saya membahas evaluasi LLM lebih mendalam dalam artikel tentang Evaluasi LLM: Metrik, Metodologi, Praktik Terbaik.
Meski menawarkan banyak manfaat, distilasi LLM juga menghadirkan beberapa tantangan yang harus diatasi untuk memastikan implementasi yang sukses.
Salah satu hambatan utama dalam distilasi LLM adalah potensi kehilangan pengetahuan. Selama proses distilasi, sebagian informasi bernuansa dan fitur dari model guru mungkin tidak sepenuhnya tertangkap oleh model murid, yang menyebabkan penurunan kinerja. Masalah ini bisa sangat terasa pada tugas yang memerlukan pemahaman mendalam atau pengetahuan khusus.
Berikut beberapa strategi yang dapat kita terapkan untuk mengurangi kehilangan pengetahuan:
Penalaan hiperparameter yang cermat sangat penting untuk keberhasilan proses distilasi. Hiperparameter kunci, seperti temperatur dan laju pembelajaran, sangat memengaruhi kemampuan model murid untuk belajar dari guru:
Mengevaluasi efektivitas model terdistilasi adalah langkah yang tidak terelakkan untuk menjamin bahwa model memenuhi kriteria kinerja yang diinginkan, khususnya dibandingkan pendahulu dan alternatifnya. Ini melibatkan perbandingan kinerja murid dengan guru dan baseline lain untuk memahami seberapa baik proses distilasi mempertahankan atau meningkatkan fungsionalitas model.
Untuk menilai efektivitas model terdistilasi, penting berfokus pada metrik berikut:
Mematuhi praktik terbaik dapat meningkatkan efektivitas distilasi LLM. Pedoman ini menekankan eksperimen, evaluasi berkelanjutan, dan implementasi strategis.
Bidang distilasi LLM berkembang pesat. Bagian ini membahas tren terbaru, tantangan riset saat ini, dan teknik yang sedang muncul dalam distilasi LLM.
Riset terbaru dalam distilasi LLM berfokus pada pengembangan teknik dan arsitektur baru untuk meningkatkan efisiensi dan efektivitas proses distilasi. Beberapa kemajuan penting meliputi:
Meski kemajuan signifikan telah dicapai, sejumlah tantangan dan pertanyaan riset terbuka tetap ada dalam bidang distilasi LLM:
Teknik dan inovasi baru terus dikembangkan untuk mengatasi tantangan ini dan mendorong bidang ini maju. Beberapa pendekatan yang menjanjikan antara lain:
Distilasi LLM adalah teknik penting untuk membuat model bahasa besar menjadi lebih praktis dan efisien. Dengan mentransfer pengetahuan esensial dari model guru yang kompleks ke model murid yang lebih kecil, distilasi mempertahankan kinerja sambil mengurangi ukuran dan kebutuhan komputasi.
Proses ini memungkinkan aplikasi AI yang lebih cepat dan mudah diakses di berbagai industri, mulai dari tugas NLP waktu nyata hingga use case khusus di bidang kesehatan dan keuangan. Mengimplementasikan distilasi LLM memerlukan perencanaan yang cermat dan alat yang tepat, namun manfaatnya—seperti biaya lebih rendah dan penerapan yang lebih luas—sangat besar.
Seiring riset terus berkembang, distilasi LLM akan memainkan peran yang semakin penting dalam mendemokratisasi AI, membuat model yang kuat lebih mudah diakses dan digunakan dalam berbagai konteks.
Pelajari tentang LLM melalui kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
