
Cours
Concepts des grands modèles de langage (LLM)
2 h
99.8K
LLM distillation is a technique that seeks to replicate the performance of a large language model while reducing its size and computational demands.
Imagine a seasoned professor sharing their expertise with a new student. The professor, representing the teacher model, conveys complex concepts and insights, while the student model learns to mimic these teachings in a more simplified and efficient manner.
This process not only retains the core competencies of the teacher but also optimizes the student for faster and more versatile applications.
The increasing size and computational requirements of large language models prevent their widespread adoption and deployment. High-performance hardware and increasing energy consumption often limit the accessibility of these models, particularly in resource-constrained environments such as mobile devices or edge computing platforms.
LLM distillation addresses these challenges by producing smaller and faster models, making them ideal for integration across a broader range of devices and platforms.
This innovation not only democratizes access to advanced AI but also supports real-time applications where speed and efficiency are highly valued. By enabling more accessible and scalable AI solutions, LLM distillation helps advance the practical implementation of AI technologies.
The LLM distillation process involves several techniques that ensure the student model retains key information while operating more efficiently. Here, we explore the key mechanisms that make this knowledge transfer effective.
The teacher-student paradigm is at the heart of LLM distillation, a foundational concept that drives the knowledge transfer process. In this setup, a larger, more advanced model imparts its knowledge to a smaller, more lightweight model.
The teacher model, often a state-of-the-art language model with extensive training and computational resources, serves as a rich source of information. On the other hand, the student is designed to learn from the teacher by mimicking its behavior and internalizing its knowledge.
The student model's primary task is to replicate the teacher's outputs while maintaining a much smaller size and reduced computational requirements. This process involves the student observing and learning from the teacher's predictions, adjustments, and responses to various inputs.
By doing so, the student can achieve a comparable level of performance and understanding, making it suitable for deployment in resource-constrained environments.
Various distillation techniques are employed to transfer knowledge from the teacher to the student. These methods ensure that the student model not only learns efficiently but also retains the essential knowledge and capabilities of the teacher model. Here are some of the most prominent techniques used in LLM distillation.
One of the most distinguished techniques in LLM distillation is knowledge distillation (KD). In KD, the student model is trained using the teacher model's output probabilities, known as soft targets, alongside the ground truth labels, referred to as hard targets.
Soft targets provide a nuanced view of the teacher's predictions, offering a probability distribution over possible outputs rather than a single correct answer. This additional information helps the student model capture the subtle patterns and intricate knowledge encoded in the teacher's responses.
By using soft targets, the student model can better understand the teacher's decision-making process, leading to more accurate and reliable performance. This approach not only preserves the critical knowledge from the teacher but also enables a smoother and more effective training process for the student.
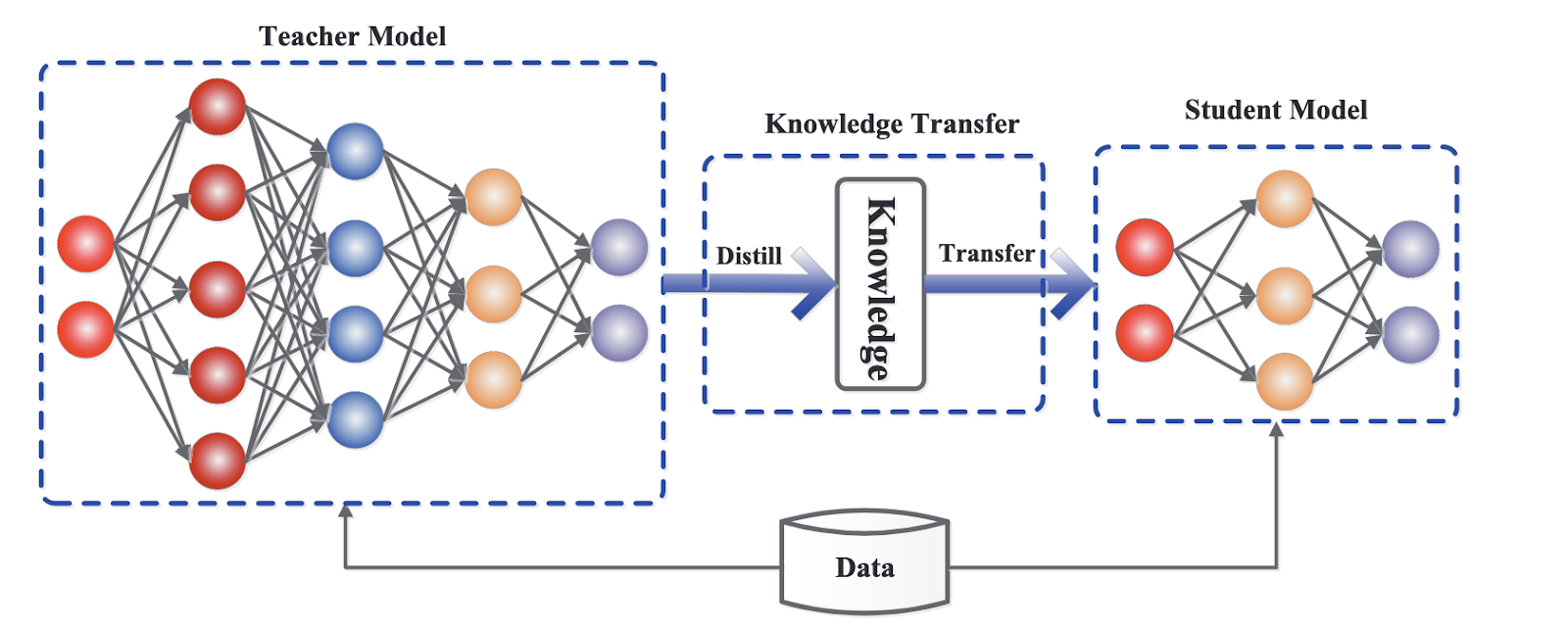
Generic framework for knowledge distillation. Source
Beyond KD, several other techniques can improve the LLM distillation process:
LLM distillation offers a range of considerable benefits that develop the usability and efficiency of language models, making them more practical for diverse applications.
Here, we explore some of the key advantages.
One of the primary benefits of LLM distillation is the creation of noticeably smaller models. By transferring knowledge from a large teacher model to a smaller student model, the resulting student retains much of the teacher's capabilities while being a fraction of its size.
This reduction in model size leads to:
The smaller size of distilled models translates directly to improved inference speed. This is particularly important for applications that require real-time processing and quick responses.
Here’s how this benefit manifests:
Another noteworthy advantage of LLM distillation is the reduction in computational costs. Smaller models require less computational power to run, which leads to cost savings in several areas:
Distilled LLMs are more versatile and accessible, allowing for deployment across platforms. This expanded reach has several implications:
The benefits of LLM distillation extend far beyond just model efficiency and cost savings. Distilled language models can be applied across a wide range of natural language processing (NLP) tasks and industry-specific use cases, making AI solutions accessible across various fields.
Distilled LLMs excel in many natural language processing tasks. Their reduced size and enhanced performance make them ideal for tasks that require real-time processing and lower computational power.
Distilled LLMs enable the development of smaller, faster chatbots that can smoothly handle customer service and support tasks. These chatbots can understand and respond to user queries in real time, providing a seamless customer experience without the need for extensive computing.
Summarization tools powered by distilled LLMs can condense news articles, documents, or social media feeds into concise summaries. This helps users quickly grasp the key points without reading through lengthy texts.
Distilled models make translation services faster and more accessible across devices. They can be deployed on mobile phones, tablets, and even offline applications, providing real-time translation with reduced latency and computational overhead.
Distilled LLMs are not only valuable for common NLP tasks but also excel in specialized areas that require quick processing and accurate outcomes.
Distilled LLMs are not just limited to general NLP tasks. They can also impact many industries by improving processes and user experiences, and driving innovation.
In the healthcare industry, distilled LLMs can process patient records and diagnostic data more efficiently, enabling faster and more accurate diagnoses. These models can be deployed in medical devices, supporting doctors and healthcare professionals with real-time data analysis and decision-making.
The finance sector benefits from distilled models through upgraded fraud detection systems and customer interaction models. By quickly deciphering transaction patterns and customer queries, distilled LLMs help prevent fraudulent activities and provide personalized financial advice and support.
In education, distilled LLMs facilitate the creation of adaptive learning systems and personalized tutoring platforms. These systems can analyze student performance and offer tailored educational content, enhancing learning outcomes and making education more accessible and impactful.
Implementing LLM distillation involves a series of steps and the use of specialized frameworks and libraries designed to facilitate the process. Here, we explore the tools and steps necessary to distill a large language model.
To streamline the distillation process, a few frameworks and libraries are available, each offering unique features to support LLM distillation.
The Hugging Face transformers library is a popular tool for implementing LLM distillation. It includes a Distiller class that simplifies the process of transferring knowledge from a teacher model to a student model.
Using the Distiller class, practitioners can leverage pre-trained models, fine-tune them on specific datasets, and employ distillation techniques to achieve optimal results.
Aside from Hugging Face Transformers, many other libraries support LLM distillation:
Distiller is designed to compress deep learning models, including support for distillation techniques. It offers a range of utilities to manage the distillation process and improve model efficiency.Implementing LLM distillation requires careful planning and execution. Here are the key steps involved in the process.
The first step in the distillation process is to prepare a suitable dataset for training the student model. The dataset should be representative of the tasks the model will perform, ensuring that the student model learns to generalize well.
Data augmentation techniques can also enhance the dataset, providing the student model with a broader range of examples to learn from.
Selecting an appropriate teacher model is necessary for successful distillation. The teacher model should be a well-performing, pre-trained model with a high level of accuracy on the target tasks. The quality and attributes of the teacher model directly influence the performance of the student model.
The distillation process involves the following steps:
Evaluating the performance of the distilled model is essential to ensure it meets the desired criteria. Common evaluation metrics include:
I cover LLM evaluation more in-depth in this article on LLM Evaluation: Metrics, Methodologies, Best Practices.
While LLM distillation offers numerous benefits, it also presents several challenges that must be addressed to ensure successful implementation.
One of the primary hurdles in LLM distillation is the potential for knowledge loss. During the distillation process, some of the nuanced information and features of the teacher model may need to be fully captured by the student model, leading to a decrease in performance. This issue can be particularly pronounced in tasks that require deep understanding or specialized knowledge.
Here are a few strategies we can implement to mitigate knowledge loss:
Careful hyperparameter tuning is vital for the success of the distillation process. Key hyperparameters, such as temperature and learning rate, significantly influence the student model's ability to learn from the teacher:
Evaluating the effectiveness of the distilled model is an indispensable step to guarantee that it meets the desired performance criteria, particularly with its predecessors and alternatives. This involves comparing the performance of the student to the teacher and other baselines to understand how well the distillation process has preserved or advanced model functionality.
To gauge the effectiveness of the distilled model, it’s important to focus on the following metrics:
Adhering to best practices can increase the effectiveness of LLM distillation. These guidelines emphasize experimentation, continuous evaluation, and strategic implementation.
The field of LLM distillation is rapidly evolving. This section explores the latest trends, current research challenges, and emerging techniques in LLM distillation.
Recent research in LLM distillation has focused on developing novel techniques and architectures to enhance the efficiency and effectiveness of the distillation process. Some notable advancements include:
Despite significant progress, several challenges and open research questions remain in the field of LLM distillation:
Emerging techniques and innovations are continually being developed to address these challenges and push the field forward. Some promising approaches are:
LLM distillation is a pivotal technique in making large language models more practical and efficient. By transferring essential knowledge from a complex teacher model to a smaller student model, distillation preserves performance while reducing size and computational demands.
This process enables faster, more accessible AI applications across various industries, from real-time NLP tasks to specialized use cases in healthcare and finance. Implementing LLM distillation involves careful planning and the right tools, but the benefits—such as lower costs and broader deployment—are substantial.
As research continues to advance, LLM distillation will play an increasingly important role in democratizing AI, making powerful models more accessible and usable in diverse contexts.
Learn about LLMs with these courses!
Cours
Cours
Cours
blog
Tim Lu
15 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Javier Canales Luna
12 min
Tutoriel
Hesam Sheikh Hassani
Tutoriel
Josep Ferrer
Tutoriel
Ryan Ong
