Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
100.3K
La destilación de LLM es una técnica que pretende replicar el rendimiento de un modelo lingüístico de gran tamaño, reduciendo al mismo tiempo su tamaño y sus exigencias computacionales.
Imagina a un profesor experimentado compartiendo su experiencia con un nuevo alumno. El profesor, que representa el modelo de maestro, transmite conceptos y conocimientos complejos, mientras que el modelo de alumno aprende a imitar estas enseñanzas de forma más simplificada y eficaz.
Este proceso no sólo conserva las competencias básicas del profesor, sino que también optimiza al alumno para aplicaciones más rápidas y versátiles.
El creciente tamaño y requisitos informáticos de los grandes modelos lingüísticos impiden su adopción y despliegue generalizados. El hardware de alto rendimiento y el creciente consumo de energía a menudo limitan la accesibilidad de estos modelos, sobre todo en entornos con recursos limitados, como los dispositivos móviles o las plataformas informáticas periféricas.
La destilación LLM aborda estos retos produciendo modelos más pequeños y rápidos, lo que los hace ideales para su integración en una gama más amplia de dispositivos y plataformas.
Esta innovación no sólo democratiza el acceso a la IA avanzada, sino que también es compatible con aplicaciones en tiempo real en las que se valoran mucho la velocidad y la eficacia. Al permitir soluciones de IA más accesibles y escalables, la destilación LLM ayuda a avanzar en la aplicación práctica de las tecnologías de IA.
El proceso de destilación del LLM implica varias técnicas que garantizan que el modelo del alumno retenga la información clave a la vez que funciona con mayor eficacia. Aquí exploramos los mecanismos clave que hacen que esta transferencia de conocimientos sea eficaz.
El paradigma profesor-alumno está en el centro de la destilación del LLM, un concepto fundacional que impulsa el proceso de transferencia de conocimientos. En esta configuración, un modelo más grande y avanzado imparte sus conocimientos a un modelo más pequeño y ligero.
El modelo del profesor, a menudo un modelo lingüístico de última generación con un amplio entrenamiento y recursos computacionales, sirve como una rica fuente de información. Por otra parte, el alumno está diseñado para aprender del profesor imitando su comportamiento e interiorizando sus conocimientos.
La tarea principal del modelo del alumno es replicar los resultados del profesor manteniendo un tamaño mucho menor y unos requisitos computacionales reducidos. Este proceso implica que el alumno observe y aprenda de las predicciones, ajustes y respuestas del profesor a diversas entradas.
De este modo, el alumno puede alcanzar un nivel comparable de rendimiento y comprensión, lo que lo hace adecuado para su despliegue en entornos con recursos limitados.
Se emplean diversas técnicas de destilación para transferir conocimientos del profesor al alumno. Estos métodos garantizan que el modelo de alumno no sólo aprenda eficazmente, sino que también retenga los conocimientos y capacidades esenciales del modelo de profesor. He aquí algunas de las técnicas más destacadas utilizadas en la destilación LLM.
Una de las técnicas más destacadas en la destilación de LLM es la destilación de conocimientos (DC). En KD, el modelo del alumno se entrena utilizando las probabilidades de salida del modelo del profesor, conocidas comoobjetivos blandos , junto con las etiquetas de la verdad sobre el terreno, denominadas objetivos duros.
Los objetivos blandos proporcionan una visión matizada de las predicciones del profesor, ofreciendo una distribución de probabilidades sobre los posibles resultados en lugar de una única respuesta correcta. Esta información adicional ayuda al alumno modelo a captar los sutiles patrones y los intrincados conocimientos codificados en las respuestas del profesor.
Al utilizar objetivos blandos, el modelo de alumno puede comprender mejor el proceso de toma de decisiones del profesor, lo que conduce a un rendimiento más preciso y fiable. Este enfoque no sólo conserva los conocimientos críticos del profesor, sino que también permite un proceso de formación más fluido y eficaz para el alumno.
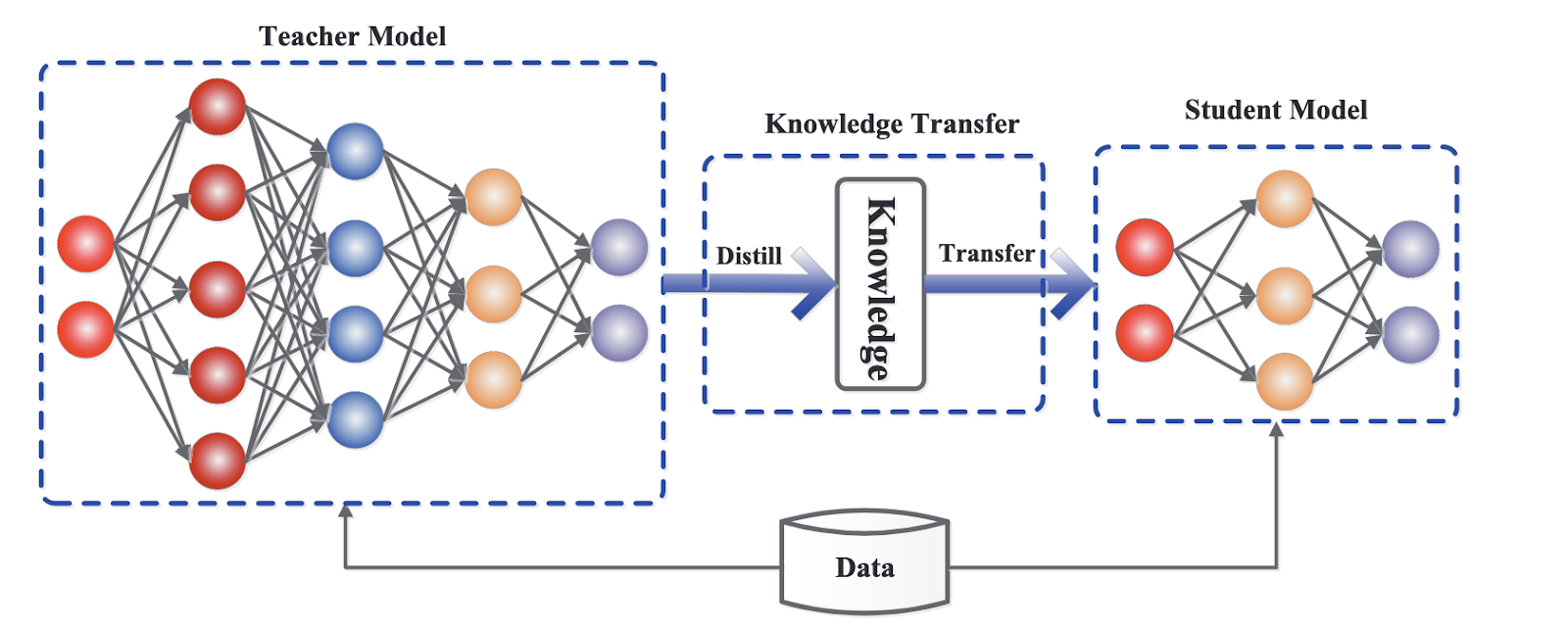
Marco genérico para la destilación de conocimientos. Fuente
Además de la KD, hay otras técnicas que pueden mejorar el proceso de destilación LLM:
La destilación de LLM ofrece una serie de ventajas considerables que desarrollan la usabilidad y eficacia de los modelos lingüísticos, haciéndolos más prácticos para diversas aplicaciones.
Aquí exploramos algunas de sus principales ventajas.
Una de las principales ventajas de la destilación LLM es la creación de modelos notablemente más pequeños. Al transferir conocimientos de un modelo de profesor grande a un modelo de alumno más pequeño, el alumno resultante conserva gran parte de las capacidades del profesor siendo una fracción de su tamaño.
Esta reducción del tamaño del modelo conduce a:
El menor tamaño de los modelos destilados se traduce directamente en una mayor velocidad de inferencia. Esto es especialmente importante para las aplicaciones que requieren procesamiento en tiempo real y respuestas rápidas.
He aquí cómo se manifiesta este beneficio:
Otra ventaja destacable de la destilación LLM es la reducción de los costes computacionales. Los modelos más pequeños requieren menos potencia de cálculo para funcionar, lo que supone un ahorro de costes en varias áreas:
Los LLM destilados son más versátiles y accesibles, lo que permite su despliegue en distintas plataformas. Este alcance ampliado tiene varias implicaciones:
Las ventajas de la destilación LLM van mucho más allá de la eficiencia del modelo y el ahorro de costes. Los modelos lingüísticos destilados pueden aplicarse a una amplia gama de procesamiento del lenguaje natural (PLN) y casos de uso específicos de la industria, haciendo que las soluciones de IA sean accesibles en diversos campos.
Los LLM destilados destacan en muchas tareas de procesamiento del lenguaje natural. Su tamaño reducido y su mayor rendimiento los hacen ideales para tareas que requieren procesamiento en tiempo real y menor potencia de cálculo.
Los LLM destilados permiten desarrollar chatbots más pequeños y rápidos chatbots que pueden gestionar sin problemas las tareas de atención al cliente y soporte. Estos chatbots pueden entender y responder a las consultas de los usuarios en tiempo real, proporcionando una experiencia de cliente sin fisuras y sin necesidad de una gran informática.
Las herramientas de resumen basadas en LLM destilados pueden condensar artículos de noticias, documentos o fuentes de redes sociales en resúmenes concisos. Esto ayuda a los usuarios a captar rápidamente los puntos clave sin tener que leer largos textos.
Los modelos destilados hacen que los servicios de traducción sean más rápidos y accesibles en todos los dispositivos. Pueden desplegarse en teléfonos móviles, tabletas e incluso aplicaciones offline, proporcionando traducción en tiempo real con una latencia y una sobrecarga computacional reducidas.
Los LLM destilados no sólo son valiosos para las tareas habituales de la PNL, sino que también destacan en áreas especializadas que requieren un procesamiento rápido y resultados precisos.
Los LLM destilados no se limitan a tareas generales de PNL. También pueden influir en muchas industrias mejorando los procesos y las experiencias de los usuarios, e impulsando la innovación.
En el industria sanitarialos LLM destilados pueden procesar los historiales de los pacientes y los datos de diagnóstico con mayor eficacia, lo que permite diagnósticos más rápidos y precisos. Estos modelos pueden implantarse en dispositivos médicos, ayudando a los médicos y profesionales sanitarios con el análisis de datos en tiempo real y la toma de decisiones.
La página sector financiero se beneficia de modelos destilados a través de sistemas de detección del fraude y modelos de interacción con el cliente. Al descifrar rápidamente los patrones de las transacciones y las consultas de los clientes, los LLM destilados ayudan a prevenir las actividades fraudulentas y proporcionan asesoramiento y apoyo financiero personalizados.
En educaciónlos LLM destilados facilitan la creación de sistemas de aprendizaje adaptativo y plataformas de tutoría personalizada. Estos sistemas pueden analizar el rendimiento de los alumnos y ofrecer contenidos educativos a medida, mejorando los resultados del aprendizaje y haciendo que la educación sea más accesible e impactante.
Implementar la destilación LLM implica una serie de pasos y el uso de marcos y bibliotecas especializados diseñados para facilitar el proceso. Aquí exploramos las herramientas y los pasos necesarios para destilar un gran modelo lingüístico.
Para agilizar el proceso de destilación, existen algunos marcos y bibliotecas, cada uno de los cuales ofrece características únicas para apoyar la destilación LLM.
La Biblioteca de transformadores Cara Abrazada es una herramienta popular para aplicar la destilación LLM. Incluye una clase Distiller que simplifica el proceso de transferencia de conocimientos de un modelo de profesor a un modelo de alumno .
Utilizando la clase Distiller, los profesionales pueden aprovechar modelos preentrenados, afinarlos en conjuntos de datos específicos y emplear técnicas de destilación para lograr resultados óptimos.
Aparte de los Transformadores de Cara Abrazada, muchas otras bibliotecas admiten la destilación LLM:
Distiller está diseñado para comprimir modelos de aprendizaje profundo, incluyendo soporte para técnicas de destilación. Ofrece una serie de utilidades para gestionar el proceso de destilación y mejorar la eficacia del modelo.Poner en práctica la destilación LLM requiere una planificación y ejecución cuidadosas. He aquí los pasos clave del proceso.
El primer paso en el proceso de destilación es preparar un conjunto de datos adecuado para entrenar el modelo del alumno. El conjunto de datos debe ser representativo de las tareas que realizará el modelo, para garantizar que el modelo del alumno aprenda a generalizar bien.
Las técnicas de aumento de datos también pueden mejorar el conjunto de datos, proporcionando al modelo del alumno una gama más amplia de ejemplos de los que aprender.
Seleccionar un modelo de profesor adecuado es necesario para que la destilación tenga éxito. El modelo maestro debe ser un modelo preentrenado de buen rendimiento con un alto nivel de precisión en las tareas objetivo. La calidad y los atributos del modelo del profesor influyen directamente en el rendimiento del modelo del alumno.
El proceso de destilación implica los siguientes pasos:
Evaluar el rendimiento del modelo destilado es esencial para garantizar que cumple los criterios deseados. Las métricas de evaluación habituales incluyen:
Cubro la evaluación LLM más a fondo en este artículo sobre LLM Evaluation: Métricas, metodologías, buenas prácticas.
Aunque la destilación LLM ofrece numerosas ventajas, también presenta varios retos que deben abordarse para garantizar el éxito de su aplicación.
Uno de los principales obstáculos en la destilación del LLM es la posible pérdida de conocimientos. Durante el proceso de destilación, es posible que parte de la información matizada y de las características del modelo del profesor deban ser captadas en su totalidad por el modelo del alumno, lo que provocaría una disminución del rendimiento. Este problema puede ser especialmente pronunciado en tareas que requieren una comprensión profunda o conocimientos especializados.
He aquí algunas estrategias que podemos aplicar para mitigar la pérdida de conocimientos:
El ajuste cuidadoso de los hiperparámetros es vital para el éxito del proceso de destilación. Los hiperparámetros clave, como la temperatura y la velocidad de aprendizaje, influyen significativamente en la capacidad del modelo alumno para aprender del maestro:
Evaluar la eficacia del modelo destilado es un paso indispensable para garantizar que cumple los criterios de rendimiento deseados, sobre todo con sus predecesores y alternativas. Esto implica comparar el rendimiento del alumno con el del profesor y otras líneas de base para comprender hasta qué punto el proceso de destilación ha conservado o avanzado la funcionalidad del modelo.
Para medir la eficacia del modelo destilado, es importante centrarse en las siguientes métricas:
Seguir las mejores prácticas puede aumentar la eficacia de la destilación LLM. Estas directrices hacen hincapié en la experimentación, la evaluación continua y la aplicación estratégica.
El campo de la destilación LLM está evolucionando rápidamente. Esta sección explora las últimas tendencias, los retos actuales de la investigación y las técnicas emergentes en la destilación LLM.
La investigación reciente en destilación LLM se ha centrado en el desarrollo de técnicas y arquitecturas novedosas para mejorar la eficiencia y eficacia del proceso de destilación. Algunos avances notables son:
A pesar de los importantes avances, aún quedan varios retos y cuestiones de investigación abiertas en el campo de la destilación LLM:
Se están desarrollando continuamente nuevas técnicas e innovaciones para afrontar estos retos e impulsar este campo. Algunos enfoques prometedores son:
La destilación LLM es una técnica fundamental para hacer más prácticos y eficaces los modelos lingüísticos de gran tamaño. Al transferir los conocimientos esenciales de un modelo de profesor complejo a un modelo de alumno más pequeño, la destilación conserva el rendimiento al tiempo que reduce el tamaño y las exigencias computacionales.
Este proceso permite aplicaciones de IA más rápidas y accesibles en diversos sectores, desde tareas de PNL en tiempo real hasta casos de uso especializado en sanidad y finanzas. Poner en práctica la destilación LLM requiere una planificación cuidadosa y las herramientas adecuadas, pero las ventajas -como la reducción de costes y un despliegue más amplio- son sustanciales.
A medida que la investigación siga avanzando, la destilación LLM desempeñará un papel cada vez más importante en la democratización de la IA, haciendo que los modelos potentes sean más accesibles y utilizables en diversos contextos.
Infórmate sobre los LLM con estos cursos
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Bhavishya Pandit
8 min
blog
Abid Ali Awan
9 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Moez Ali

