Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
99.8K
A destilação de LLM é uma técnica que busca replicar o desempenho de um modelo de linguagem grande e, ao mesmo tempo, reduzir seu tamanho e as demandas computacionais.
Imagine um professor experiente compartilhando seus conhecimentos com um novo aluno. O professor, representando o modelo do professor, transmite conceitos e percepções complexas, enquanto o modelo do aluno aprende a imitar esses ensinamentos de maneira mais simplificada e eficiente.
Esse processo não apenas retém as competências essenciais do professor, mas também otimiza o aluno para aplicações mais rápidas e versáteis.
O tamanho crescente e os requisitos computacionais dos grandes modelos de linguagem impedem sua ampla adoção e implementação. O hardware de alto desempenho e o aumento do consumo de energia geralmente limitam a acessibilidade desses modelos, principalmente em ambientes com recursos limitados, como dispositivos móveis ou plataformas de computação de ponta.
A destilação do LLM aborda esses desafios produzindo modelos menores e mais rápidos, o que os torna ideais para a integração em uma gama mais ampla de dispositivos e plataformas.
Essa inovação não apenas democratiza o acesso à IA avançada, mas também oferece suporte a aplicativos em tempo real em que a velocidade e a eficiência são altamente valorizadas. Ao possibilitar soluções de IA mais acessíveis e dimensionáveis, a destilação do LLM ajuda a promover a implementação prática das tecnologias de IA.
O processo de destilação do LLM envolve várias técnicas que garantem que o modelo do aluno retenha informações importantes e opere com mais eficiência. Aqui, exploramos os principais mecanismos que tornam essa transferência de conhecimento eficaz.
O paradigma professor-aluno está no centro da destilação do LLM, um conceito fundamental que impulsiona o processo de transferência de conhecimento. Nessa configuração, um modelo maior e mais avançado transmite seu conhecimento a um modelo menor e mais leve.
O modelo do professor, geralmente um modelo de linguagem de última geração com treinamento extensivo e recursos computacionais, serve como uma fonte rica de informações. Por outro lado, o aluno é projetado para aprender com o professor, imitando seu comportamento e internalizando seu conhecimento.
A principal tarefa do modelo do aluno é replicar os resultados do professor, mantendo um tamanho muito menor e requisitos computacionais reduzidos. Esse processo envolve a observação e o aprendizado do aluno com as previsões, os ajustes e as respostas do professor a várias informações.
Dessa forma, o aluno pode atingir um nível comparável de desempenho e compreensão, o que o torna adequado para implantação em ambientes com recursos limitados.
Várias técnicas de destilação são empregadas para transferir conhecimento do professor para o aluno. Esses métodos garantem que o modelo do aluno não apenas aprenda com eficiência, mas também retenha o conhecimento e os recursos essenciais do modelo do professor. Aqui estão algumas das técnicas mais importantes usadas na destilação de LLM.
Uma das técnicas mais importantes na destilação de LLM é a destilação de conhecimento (KD). No KD, o modelo do aluno é treinado usando as probabilidades de saída do modelo do professor, conhecidas como soft targets, juntamente com os rótulos da verdade terrestre, chamados de hard targets.
As metas flexíveis fornecem uma visão diferenciada das previsões do professor, oferecendo uma distribuição de probabilidade sobre possíveis resultados em vez de uma única resposta correta. Essas informações adicionais ajudam o modelo do aluno a captar os padrões sutis e o conhecimento complexo codificado nas respostas do professor.
Ao usar metas flexíveis, o modelo do aluno pode entender melhor o processo de tomada de decisão do professor, o que leva a um desempenho mais preciso e confiável. Essa abordagem não apenas preserva o conhecimento crítico do professor, mas também permite um processo de treinamento mais suave e eficaz para o aluno.
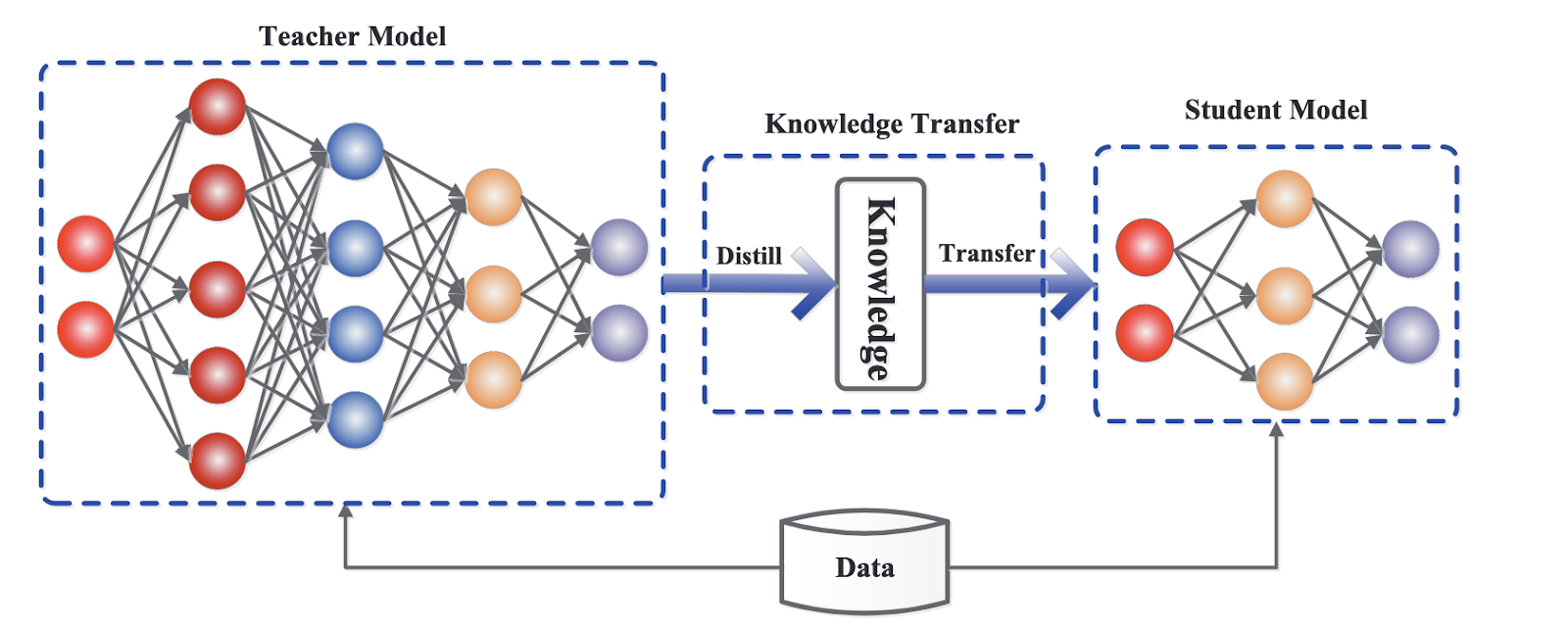
Estrutura genérica para destilação de conhecimento. Fonte
Além do KD, várias outras técnicas podem melhorar o processo de destilação do LLM:
A destilação de LLM oferece uma série de benefícios consideráveis que desenvolvem a usabilidade e a eficiência dos modelos de linguagem, tornando-os mais práticos para diversas aplicações.
Aqui, exploramos algumas das principais vantagens.
Um dos principais benefícios da destilação do LLM é a criação de modelos visivelmente menores. Ao transferir o conhecimento de um modelo de professor grande para um modelo de aluno menor, o aluno resultante retém grande parte dos recursos do professor, embora tenha uma fração do seu tamanho.
Essa redução no tamanho do modelo leva a:
O tamanho menor dos modelos destilados se traduz diretamente em maior velocidade de inferência. Isso é particularmente importante para aplicativos que exigem processamento em tempo real e respostas rápidas.
Veja como esse benefício se manifesta:
Outra vantagem notável da destilação LLM é a redução dos custos computacionais. Modelos menores exigem menos poder computacional para serem executados, o que resulta em economia de custos em várias áreas:
Os LLMs destilados são mais versáteis e acessíveis, permitindo a implementação em várias plataformas. Esse alcance ampliado tem várias implicações:
Os benefícios da destilação LLM vão muito além da eficiência do modelo e da economia de custos. Os modelos de linguagem destilados podem ser aplicados em uma ampla gama de processamento de linguagem natural (NLP) e casos de uso específicos do setor, tornando as soluções de IA acessíveis em vários campos.
Os LLMs destilados são excelentes em muitas tarefas de processamento de linguagem natural. Seu tamanho reduzido e desempenho aprimorado os tornam ideais para tarefas que exigem processamento em tempo real e menor potência computacional.
Os LLMs destilados permitem o desenvolvimento de chatbots menores e mais rápidos chatbots menores e mais rápidos que podem lidar facilmente com tarefas de atendimento e suporte ao cliente. Esses chatbots podem entender e responder às consultas dos usuários em tempo real, proporcionando uma experiência perfeita ao cliente sem a necessidade de computação extensiva.
As ferramentas de resumo alimentadas por LLMs destilados podem condensar artigos de notícias, documentos ou feeds de mídia social em resumos concisos. Isso ajuda os usuários a entender rapidamente os pontos principais sem precisar ler textos longos.
Os modelos destilados tornam os serviços de tradução mais rápidos e mais acessíveis em todos os dispositivos. Eles podem ser implantados em telefones celulares, tablets e até mesmo em aplicativos off-line, fornecendo tradução em tempo real com latência e sobrecarga computacional reduzidas.
Os LLMs destilados não são apenas valiosos para tarefas comuns de PNL, mas também se destacam em áreas especializadas que exigem processamento rápido e resultados precisos.
Os LLMs destilados não se limitam apenas a tarefas gerais de PNL. Eles também podem afetar muitos setores, melhorando os processos e as experiências dos usuários e impulsionando a inovação.
No setor setor de saúdeos LLMs destilados podem processar registros de pacientes e dados de diagnóstico com mais eficiência, permitindo diagnósticos mais rápidos e precisos. Esses modelos podem ser implantados em dispositivos médicos, dando suporte a médicos e profissionais de saúde com análise de dados em tempo real e tomada de decisões.
O setor setor financeiro se beneficia de modelos destilados por meio de sistemas de detecção de fraudes e modelos de interação com o cliente. Ao decifrar rapidamente os padrões de transações e as consultas dos clientes, os LLMs destilados ajudam a evitar atividades fraudulentas e fornecem consultoria e suporte financeiro personalizados.
Em educaçãoNa educação, os LLMs destilados facilitam a criação de sistemas de aprendizagem adaptáveis e plataformas de tutoria personalizadas. Esses sistemas podem analisar o desempenho dos alunos e oferecer conteúdo educacional personalizado, melhorando os resultados do aprendizado e tornando a educação mais acessível e impactante.
A implementação da destilação do LLM envolve uma série de etapas e o uso de estruturas e bibliotecas especializadas projetadas para facilitar o processo. Aqui, exploramos as ferramentas e as etapas necessárias para destilar um grande modelo de linguagem.
Para simplificar o processo de destilação, estão disponíveis algumas estruturas e bibliotecas, cada uma oferecendo recursos exclusivos para dar suporte à destilação do LLM.
A biblioteca de transformadores Biblioteca de transformadores Hugging Face é uma ferramenta popular para implementar a destilação LLM. Ele inclui uma classe Distiller que simplifica o processo de transferência de conhecimento de um modelo de professor para um modelo de aluno .
Usando a classe Distiller, os profissionais podem aproveitar modelos pré-treinados, ajustá-los em conjuntos de dados específicos e empregar técnicas de destilação para obter resultados ideais.
Além dos Hugging Face Transformers, muitas outras bibliotecas oferecem suporte à destilação LLM:
Distiller foi projetado para compactar modelos de aprendizagem profunda, incluindo suporte para técnicas de destilação. Ele oferece uma variedade de utilitários para gerenciar o processo de destilação e melhorar a eficiência do modelo.A implementação da destilação do LLM requer planejamento e execução cuidadosos. Aqui estão as principais etapas envolvidas no processo.
A primeira etapa do processo de destilação é preparar um conjunto de dados adequado para treinar o modelo do aluno. O conjunto de dados deve ser representativo das tarefas que o modelo executará, garantindo que o modelo do aluno aprenda a generalizar bem.
As técnicas de aumento de dados também podem aprimorar o conjunto de dados, fornecendo ao modelo do aluno uma gama mais ampla de exemplos para aprender.
Para que a destilação seja bem-sucedida, é necessário selecionar um modelo de professor adequado. O modelo do professor deve ser um modelo pré-treinado de bom desempenho, com um alto nível de precisão nas tarefas de destino. A qualidade e os atributos do modelo do professor influenciam diretamente o desempenho do modelo do aluno.
O processo de destilação envolve as seguintes etapas:
A avaliação do desempenho do modelo destilado é essencial para garantir que ele atenda aos critérios desejados. As métricas de avaliação comuns incluem:
Falo mais detalhadamente sobre a avaliação do LLM neste artigo em Avaliação do LLM: Métricas, metodologias, práticas recomendadas.
Embora a destilação do LLM ofereça inúmeros benefícios, ela também apresenta vários desafios que devem ser abordados para garantir uma implementação bem-sucedida.
Um dos principais obstáculos na destilação do LLM é a possibilidade de perda de conhecimento. Durante o processo de destilação, algumas das informações e recursos diferenciados do modelo do professor podem precisar ser totalmente capturados pelo modelo do aluno, o que leva a uma redução no desempenho. Esse problema pode ser particularmente acentuado em tarefas que exigem compreensão profunda ou conhecimento especializado.
Aqui estão algumas estratégias que podemos implementar para mitigar a perda de conhecimento:
O ajuste cuidadoso dos hiperparâmetros é essencial para o sucesso do processo de destilação. Os principais hiperparâmetros, como a temperatura e a taxa de aprendizado, influenciam significativamente a capacidade do modelo do aluno de aprender com o professor:
A avaliação da eficácia do modelo destilado é uma etapa indispensável para garantir que ele atenda aos critérios de desempenho desejados, especialmente em relação a seus predecessores e alternativas. Isso envolve a comparação do desempenho do aluno com o do professor e outras linhas de base para entender até que ponto o processo de destilação preservou ou avançou a funcionalidade do modelo.
Para avaliar a eficácia do modelo destilado, é importante que você se concentre nas seguintes métricas:
A adesão às práticas recomendadas pode aumentar a eficácia da destilação do LLM. Essas diretrizes enfatizam a experimentação, a avaliação contínua e a implementação estratégica.
O campo da destilação de LLM está evoluindo rapidamente. Esta seção explora as últimas tendências, os desafios atuais de pesquisa e as técnicas emergentes na destilação de LLM.
Pesquisas recentes em destilação LLM se concentraram no desenvolvimento de novas técnicas e arquiteturas para aumentar a eficiência e a eficácia do processo de destilação. Alguns avanços notáveis incluem:
Apesar do progresso significativo, vários desafios e questões de pesquisa em aberto permanecem no campo da destilação LLM:
Técnicas e inovações emergentes estão sendo desenvolvidas continuamente para enfrentar esses desafios e impulsionar o campo. Algumas abordagens promissoras são:
A destilação de LLM é uma técnica essencial para tornar modelos de linguagem grandes mais práticos e eficientes. Ao transferir o conhecimento essencial de um modelo de professor complexo para um modelo de aluno menor, a destilação preserva o desempenho e reduz o tamanho e as demandas computacionais.
Esse processo permite aplicativos de IA mais rápidos e acessíveis em vários setores, desde tarefas de PNL em tempo real até casos de uso especializado em saúde e finanças. A implementação da destilação do LLM envolve um planejamento cuidadoso e as ferramentas certas, mas os benefícios - como custos mais baixos e implantação mais ampla - são substanciais.
À medida que a pesquisa continua avançando, a destilação do LLM desempenhará um papel cada vez mais importante na democratização da IA, tornando os modelos avançados mais acessíveis e utilizáveis em diversos contextos.
Aprenda sobre LLMs com estes cursos!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Nisha Arya Ahmed
12 min
blog
Abid Ali Awan
9 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Moez Ali


