
Basis Python-sollicitatievragen
Dit zijn enkele vragen die je kunt tegenkomen tijdens een Python-sollicitatie op instapniveau.
1. Wat is Python, en noem enkele van de belangrijkste kenmerken.
Python is een veelzijdige, high-level programmeertaal, bekend om zijn leesbare syntax en brede toepassingsmogelijkheden. Enkele van Python’s belangrijkste kenmerken:
- Eenvoudige en leesbare syntax: De syntax van Python is duidelijk en overzichtelijk, wat het toegankelijk maakt voor beginners en efficiënt voor ervaren ontwikkelaars.
- Geïnterpreteerde taal: Python voert code regel voor regel uit, wat helpt bij debuggen en testen.
- Dynamische types: Python vereist geen expliciete declaraties van datatypen en biedt zo meer flexibiliteit.
- Uitgebreide bibliotheken en frameworks: Bibliotheken zoals NumPy, Pandas en Django breiden Python’s functionaliteit uit voor specialistische taken in data science, webontwikkeling en meer.
- Platformonafhankelijk: Python draait op verschillende besturingssystemen, waaronder Windows, macOS en Linux.
2. Wat zijn Python-lijsten (lists) en tuples?
Lijsten en tuples zijn fundamentele Python-datastructuren met verschillende eigenschappen en gebruiksscenario’s.
Lijst:
- Muteerbaar: Elementen kunnen na creatie worden gewijzigd.
- Geheugenverbruik: Gebruikt meer geheugen.
- Prestaties: Langzamere iteratie vergeleken met tuples, maar beter voor invoeg- en verwijderbewerkingen.
- Methoden: Biedt diverse ingebouwde methoden voor manipulatie.
Voorbeeld:
a_list = ["Data", "Camp", "Tutorial"]
a_list.append("Session")
print(a_list) # Output: ['Data', 'Camp', 'Tutorial', 'Session']Tuple:
- Immutable: Elementen kunnen na creatie niet worden gewijzigd.
- Geheugenverbruik: Gebruikt minder geheugen.
- Prestaties: Snellere iteratie dan lijsten, maar mist de flexibiliteit van lijsten.
- Methoden: Beperkte ingebouwde methoden.
Voorbeeld:
a_tuple = ("Data", "Camp", "Tutorial")
print(a_tuple) # Output: ('Data', 'Camp', 'Tutorial')Leer meer in onze Python Lists-tutorial.
3. Wat is __init__() in Python?
De methode __init__() staat in de terminologie van objectgeoriënteerd programmeren (OOP) bekend als een constructor. Deze wordt gebruikt om de status van een object te initialiseren zodra het wordt aangemaakt. Deze methode wordt automatisch aangeroepen wanneer een nieuwe instantie van een klasse wordt geïnstantieerd.
Doel:
- Waarden toewijzen aan objecteigenschappen.
- Eventuele initialisatiebewerkingen uitvoeren.
Voorbeeld:
We hebben een klasse book_shop gemaakt en de constructor en de functie book() toegevoegd. De constructor slaat de boektitel op en de functie book() print de boeknaam.
Om onze code te testen hebben we het object b geïnitialiseerd met “Sandman” en de functie book() uitgevoerd.
class book_shop:
# constructor
def __init__(self, title):
self.title = title
# Sample method
def book(self):
print('The title of the book is', self.title)
b = book_shop('Sandman')
b.book()
# The title of the book is Sandman4. Wat is het verschil tussen een muteerbaar datatype en een immuteerbaar datatype?
Muteerbare datatypen:
- Definitie: Muteerbare datatypen kunnen na hun creatie worden gewijzigd.
- Voorbeelden: List, Dictionary, Set.
- Kenmerken: Elementen kunnen worden toegevoegd, verwijderd of aangepast.
- Gebruik: Geschikt voor verzamelingen waarin je vaak updates moet doen.
Voorbeeld:
# List Example
a_list = [1, 2, 3]
a_list.append(4)
print(a_list) # Output: [1, 2, 3, 4]
# Dictionary Example
a_dict = {'a': 1, 'b': 2}
a_dict['c'] = 3
print(a_dict) # Output: {'a': 1, 'b': 2, 'c': 3}Immuteerbare datatypen:
- Definitie: Immuteerbare datatypen kunnen na hun creatie niet worden gewijzigd.
- Voorbeelden: Numeriek (int, float), String, Tuple.
- Kenmerken: Elementen kunnen niet worden aangepast zodra ze zijn gezet; elke bewerking die lijkt te wijzigen, creëert een nieuw object.
Voorbeeld:
# Numeric Example
a_num = 10
a_num = 20 # Creates a new integer object
print(a_num) # Output: 20
# String Example
a_str = "hello"
a_str = "world" # Creates a new string object
print(a_str) # Output: world
# Tuple Example
a_tuple = (1, 2, 3)
# a_tuple[0] = 4 # This will raise a TypeError
print(a_tuple) # Output: (1, 2, 3)5. Leg list-, dictionary- en tuple-comprehension uit met een voorbeeld.
Lijst
List comprehension biedt een éénregelige syntax om een nieuwe lijst te maken op basis van waarden uit een bestaande lijst. Je kunt hetzelfde repliceren met een for-lus, maar dat vereist meerdere regels en kan complex worden.
List comprehension vereenvoudigt het maken van lijsten op basis van een bestaande iterable.
my_list = [i for i in range(1, 10)]
my_list
# [1, 2, 3, 4, 5, 6, 7, 8, 9]Dictionary
Net als bij een list comprehension kun je met één regel code een dictionary maken op basis van een bestaande tabel. Je moet de operatie tussen accolades {} zetten.
# Creating a dictionary using dictionary comprehension
my_dict = {i: i**2 for i in range(1, 10)}
# Output the dictionary
my_dict
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}Tuple
In tegenstelling tot lijsten en dictionaries is er geen speciale “tuple comprehension”.
Wanneer je haakjes gebruikt met een comprehension, maakt Python eigenlijk een generator expressie, geen tuple. Om een tuple te krijgen, moet je ofwel de generator converteren met tuple() of direct een tuple-literal definiëren.
# Generator expression (not a tuple)
my_gen = (i for i in range(1, 10))
my_gen
# <generator object <genexpr> ...>
# Converting generator to tuple
my_tuple = tuple(i for i in range(1, 10))
my_tuple
# (1, 2, 3, 4, 5, 6, 7, 8, 9)
# Or simply define a tuple directly
literal_tuple = (1, 2, 3)
literal_tuple
# (1, 2, 3)
Je kunt er meer over leren in onze Python Tuples-tutorial.
6. Wat is de Global Interpreter Lock (GIL) in Python, en waarom is die belangrijk?
De Global Interpreter Lock (GIL) is een mutex in CPython (de referentie-implementatie van Python) die ervoor zorgt dat slechts één native thread tegelijk Python-bytecode uitvoert. Dit vereenvoudigt het geheugenbeheer door interne datastructuren zoals referentietellingen te beschermen, maar beperkt ook echte paralleliteit bij CPU-gebonden taken, waardoor multithreading minder effectief is voor computationele workloads. Voor I/O-gebonden taken werkt het echter goed, omdat threads tijd doorbrengen met wachten op netwerk-, bestand- of databasebewerkingen.
Let op: Python 3.13 introduceerde een experimentele no-GIL build (PEP 703), en Python 3.14 voegt gedocumenteerde free-threaded ondersteuning toe. Sommige C-extensies en bibliotheken zijn mogelijk nog niet volledig compatibel.
Intermediaire Python-sollicitatievragen
Hier zijn enkele vragen die je kunt tegenkomen tijdens een Python-sollicitatie op gemiddeld niveau.
7. Kun je veelvoorkomende zoek- en graafdoorloopalgoritmen in Python uitleggen?
Python biedt verschillende krachtige algoritmen voor zoeken en graafdoorloop, die elk met andere datastructuren werken en verschillende problemen oplossen. Ik leg ze hier uit:
- Binaire zoekopdracht: Als je snel een item in een gesorteerde lijst wilt vinden, is binaire zoekopdracht je go-to. Het werkt door herhaaldelijk het zoekbereik te halveren totdat het doel is gevonden.
- AVL-boom: Een AVL-boom houdt dingen in balans, wat een groot voordeel is als je vaak items invoegt of verwijdert in een boom. Deze zelf-balancerende binaire zoekboom zorgt ervoor dat zoekopdrachten snel blijven door te voorkomen dat de boom te scheef wordt.
- Breedte-eerst zoeken (BFS): BFS verkent een graaf niveau voor niveau. Het is vooral nuttig om het kortste pad in een ongewogen graaf te vinden, omdat het alle mogelijke zetten vanaf elke knoop bekijkt voordat het dieper gaat.
- Diepte-eerst zoeken (DFS): DFS gaat zo ver mogelijk een tak in voordat het terugspoort. Het is ideaal voor taken zoals doolhofoplossing of boomdoorloop.
- A*-algoritme: Het A*-algoritme is wat geavanceerder en combineert het beste van BFS en DFS met heuristieken om efficiënt het kortste pad te vinden. Het wordt vaak gebruikt voor padzoeken op kaarten en in games.
8. Wat is een KeyError in Python, en hoe kun je die afhandelen?
Een KeyError in Python treedt op wanneer je probeert een sleutel te benaderen die niet bestaat in een dictionary. Deze fout wordt opgegooid omdat Python verwacht dat elke opgezochte sleutel aanwezig is in de dictionary, en wanneer dat niet zo is, wordt een KeyError gegooid.
Als je bijvoorbeeld een dictionary met studentscores hebt en je probeert een student op te vragen die er niet in staat, krijg je een KeyError. Je kunt dit op een paar manieren afhandelen:
-
Gebruik de .get()-methode: Deze methode retourneert
None(of een opgegeven standaardwaarde) in plaats van een fout te gooien als de sleutel niet wordt gevonden. -
Gebruik een try-except-blok: Door je code in
try-exceptte wikkelen, kun je deKeyErroropvangen en netjes afhandelen. -
Controleer op de sleutel met in: Je kunt controleren of een sleutel bestaat met
if key in dictionaryvoordat je die benadert.
Lees voor meer details onze volledige tutorial: Python KeyError Exceptions and How to Fix Them.
9. Hoe gaat Python om met geheugenbeheer, en welke rol speelt garbage collection?
Python beheert geheugenallocatie en -vrijgave automatisch met een private heap, waar alle objecten en datastructuren worden opgeslagen. Het geheugenbeheer wordt afgehandeld door de memory manager van Python, die het geheugengebruik optimaliseert, en de garbage collector, die ongebruikte of ongerefereerde objecten opruimt om geheugen vrij te maken.
Garbage collection in Python gebruikt referentietelling en een cyclische garbage collector om ongebruikte data te detecteren en te verzamelen. Wanneer een object geen referenties meer heeft, komt het in aanmerking voor garbage collection. Met de gc-module in Python kun je direct met de garbage collector interageren en functies gebruiken om hem in of uit te schakelen en handmatig te collecteren.
10. Wat is het verschil tussen shallow copy en deep copy in Python, en wanneer gebruik je welke?
In Python worden shallow en deep copies gebruikt om objecten te dupliceren, maar ze behandelen geneste structuren verschillend.
-
Shallow copy: Een shallow copy maakt een nieuw object maar voegt referenties in naar de objecten in het origineel. Als het originele object andere muteerbare objecten bevat (zoals lijsten in lijsten), zal de shallow copy naar dezelfde binnenste objecten verwijzen. Dit kan tot onverwachte wijzigingen leiden als je zo’n binnenobject aanpast in het origineel of de kopie. Je kunt een shallow copy maken met de methode
copy()of de functiecopy()uit de modulecopy. -
Deep copy: Een deep copy maakt een nieuw object en kopieert recursief alle objecten binnen het origineel. Dit betekent dat zelfs geneste structuren worden gedupliceerd, zodat wijzigingen in de ene kopie de andere niet beïnvloeden. Gebruik hiervoor de functie
deepcopy()uit de modulecopy.
Voorbeeldgebruik: Een shallow copy is geschikt wanneer het object alleen immuteerbare items bevat of wanneer je wilt dat wijzigingen in geneste structuren in beide kopieën zichtbaar zijn. Een deep copy is ideaal bij complexe, geneste objecten waarbij je een volledig onafhankelijke duplicaat wil. Lees onze tutorial Python Copy List: What You Should Know voor meer informatie, inclusief een hele sectie over het verschil tussen shallow en deep copy.
11. Hoe kun je de collections-module van Python gebruiken om veelvoorkomende taken te vereenvoudigen?
De module collections in Python biedt gespecialiseerde datastructuren zoals defaultdict, Counter, deque en OrderedDict om uiteenlopende taken te vereenvoudigen. Zo is Counter ideaal om elementen in een iterable te tellen, terwijl defaultdict dictionary-waarden kan initialiseren zonder expliciete controles.
Voorbeeld:
from collections import Counter
data = ['a', 'b', 'c', 'a', 'b', 'a']
count = Counter(data)
print(count) # Output: Counter({'a': 3, 'b': 2, 'c': 1})Geavanceerde Python-sollicitatievragen
Deze sollicitatievragen zijn voor meer ervaren Python-gebruikers.
12. Wat is monkey patching in Python?
Monkey patching in Python is een dynamische techniek waarmee je het gedrag van code tijdens runtime kunt wijzigen. Kort gezegd kun je een klasse of module aanpassen tijdens runtime.
Voorbeeld:
Laten we monkey patching leren met een voorbeeld.
-
We hebben een klasse
monkeygemaakt met een functiepatch(). We hebben ook een functiemonk_pbuiten de klasse gemaakt. -
We vervangen nu
patchdoor de functiemonk_pdoormonkey.patchtoe te wijzen aanmonk_p. -
Tot slot testen we de wijziging door een object aan te maken met de klasse
monkeyen de functiepatch()uit te voeren.
In plaats van patch() is being called werd monk_p() is being called weergegeven.
class monkey:
def patch(self):
print ("patch() is being called")
def monk_p(self):
print ("monk_p() is being called")
# replacing address of "patch" with "monk_p"
monkey.patch = monk_p
obj = monkey()
obj.patch()
# monk_p() is being calledLet op: Gebruik dit spaarzaam; monkey patching kan je code moeilijker leesbaar maken en collega’s die met je code of tests werken, verrassen.
13. Waarvoor is de Python-“with”-instructie ontworpen?
De with-instructie wordt gebruikt voor exceptie-afhandeling om code schoner en eenvoudiger te maken. Deze wordt meestal gebruikt voor het beheren van veelgebruikte resources zoals het aanmaken, bewerken en opslaan van een bestand.
Voorbeeld:
In plaats van meerdere regels met open, try, finally en close te schrijven, kun je met de with-instructie eenvoudig een tekstbestand aanmaken en beschrijven.
# using with statement
with open('myfile.txt', 'w') as file:
file.write('DataCamp Black Friday Sale!!!')14. Waarom gebruik je else in een try/except-constructie in Python?
try: en except: zijn algemeen bekend voor exceptie-afhandeling in Python, dus waar is else: nuttig? else: wordt uitgevoerd wanneer er geen exceptie is opgetreden.
Voorbeeld:
Laten we else: beter leren kennen met een paar voorbeelden.
-
Bij de eerste poging gaven we
2op als teller endals noemer. Dat is onjuist, enexcept:werd uitgevoerd met “Invalid input!”. -
Bij de tweede poging gaven we
2op als teller en1als noemer en kregen resultaat2. Er werd geen exceptie opgegooid, duselse:werd uitgevoerd met het berichtDivision is successful.
try:
num1 = int(input('Enter Numerator: '))
num2 = int(input('Enter Denominator: '))
division = num1/num2
print(f'Result is: {division}')
except:
print('Invalid input!')
else:
print('Division is successful.')
## Try 1 ##
# Enter Numerator: 2
# Enter Denominator: d
# Invalid input!
## Try 2 ##
# Enter Numerator: 2
# Enter Denominator: 1
# Result is: 2.0
# Division is successful.Volg de skill track Python Fundamentals om de basisvaardigheden op te doen die je nodig hebt om Python-programmeur te worden.
15. Wat zijn decorators in Python?
Decorators in Python zijn een ontwerppatroon waarmee je nieuwe functionaliteit aan een bestaand object kunt toevoegen zonder de structuur ervan te wijzigen. Ze worden vaak gebruikt om het gedrag van functies of methoden uit te breiden. Je kunt meer lezen over hoe je Python-decorators gebruikt in een aparte gids.
Voorbeeld:
import functools
def my_decorator(func):
@functools.wraps(func) # preserves __name__, __doc__, etc.
def wrapper(*args, **kwargs):
print("Something is happening before the function is called.")
result = func(*args, **kwargs)
print("Something is happening after the function is called.")
return result
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
# Output:
# Something is happening before the function is called.
# Hello!
# Something is happening after the function is called.16. Wat zijn contextmanagers in Python, en hoe worden ze geïmplementeerd?
Contextmanagers in Python worden gebruikt om resources te beheren en te zorgen dat ze correct worden verkregen en vrijgegeven. Het meest gebruikelijke gebruik van contextmanagers is de with-instructie.
Voorbeeld:
class FileManager:
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
self.file = open(self.filename, self.mode)
return self.file
def __exit__(self, exc_type, exc_value, traceback):
self.file.close()
with FileManager('test.txt', 'w') as f:
f.write('Hello, world!')In dit voorbeeld is de klasse FileManager een contextmanager die ervoor zorgt dat het bestand correct wordt gesloten nadat het binnen de with-instructie is gebruikt.
17. Wat zijn metaklassen in Python, en hoe verschillen ze van gewone klassen?
Metaklassen zijn klassen van klassen. Ze bepalen hoe klassen zich gedragen en worden aangemaakt. Terwijl gewone klassen objecten creëren, creëren metaklassen klassen. Met metaklassen kun je tijdens het aanmaken van de klasse definities wijzigen, regels afdwingen of functionaliteit toevoegen.
Voorbeeld:
class Meta(type):
def __new__(cls, name, bases, dct):
print(f"Creating class {name}")
return super().__new__(cls, name, bases, dct)
class MyClass(metaclass=Meta):
pass
# Output: Creating class MyClassPython Data Science-sollicitatievragen
Voor wie zich meer richt op data science-toepassingen van Python zijn dit enkele vragen die je kunt tegenkomen.
18. Wat zijn de voordelen van NumPy ten opzichte van gewone Python-lijsten?
NumPy heeft verschillende voordelen ten opzichte van gewone Python-lijsten, zoals:
- Geheugen: NumPy-arrays zijn geheugen-efficiënter dan Python-lijsten omdat ze elementen van hetzelfde type in aaneengesloten blokken opslaan. (Exact geheugenverbruik hangt af van elementtype en systeem, maar je kunt het controleren met
sys.getsizeofofarray.nbytes.) - Snelheid: NumPy gebruikt geoptimaliseerde C-implementaties, dus bewerkingen op grote arrays zijn veel sneller dan met lijsten.
- Veelzijdigheid: NumPy ondersteunt gevectoriseerde operaties (zoals optellen, vermenigvuldigen) en biedt veel ingebouwde wiskundige functies die Python-lijsten niet hebben.
19. Wat is het verschil tussen merge, join en concatenate?
Merge
Voeg twee DataFrames of series-objecten samen met de unieke kolomidentifier.
Je hebt twee DataFrames nodig, een gemeenschappelijke kolom in beide DataFrames en hoe je ze wilt samenvoegen. Je kunt left, right, outer, inner en cross join uitvoeren op twee DataFrames. Standaard is het een inner join.
pd.merge(df1, df2, how='outer', on='Id')Join
Voeg de DataFrames samen met de unieke index. Het accepteert een optioneel argument on dat een kolom of meerdere kolomnamen kan zijn. Standaard voert de join-functie een left join uit.
df1.join(df2)Concatenate
Concatenate voegt twee of meerdere DataFrames samen langs een bepaalde as (rijen of kolommen). Het vereist geen on-argument.
pd.concat(df1,df2)- join(): combineert twee DataFrames op index.
- merge(): combineert twee DataFrames op de kolom(men) die je opgeeft.
- concat(): combineert twee of meer DataFrames verticaal of horizontaal.
20. Hoe identificeer en behandel je missende waarden?
Missende waarden identificeren
We kunnen missende waarden in een DataFrame identificeren met de functie isnull() en daar vervolgens sum() op toepassen. isnull() retourneert booleans, en de som geeft het aantal missende waarden per kolom.
In het voorbeeld hebben we een dictionary van lijsten gemaakt en die omgezet naar een pandas DataFrame. Daarna gebruikten we isnull().sum() om het aantal missende waarden per kolom te krijgen.
import pandas as pd
import numpy as np
# dictionary of lists
dict = {'id':[1, 4, np.nan, 9],
'Age': [30, 45, np.nan, np.nan],
'Score':[np.nan, 140, 180, 198]}
# creating a DataFrame
df = pd.DataFrame(dict)
df.isnull().sum()
# id 1
# Age 2
# Score 1Omgaan met missende waarden
Er zijn verschillende manieren om met missende waarden om te gaan in Python.
-
Verwijder de hele rij of kolommen als ze missende waarden bevatten met
dropna(). Deze methode wordt niet aanbevolen, omdat je belangrijke informatie verliest. -
Vul missende waarden met een constante, gemiddelde, backward fill of forward fill met de functie
fillna(). -
Vervang missende waarden door een constante string, integer of float met de functie
replace(). -
Vul missende waarden in met een interpolatiemethode.
Let op: zorg dat je met een grotere dataset werkt wanneer je dropna() gebruikt.
# drop missing values
df.dropna(axis = 0, how ='any')
#fillna
df.fillna(method ='bfill')
#replace null values with -999
df.replace(to_replace = np.nan, value = -999)
# Interpolate
df.interpolate(method ='linear', limit_direction ='forward')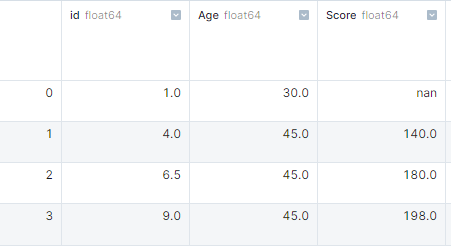
Word een professionele data scientist met de Associate Data Scientist in Python career track. Deze bevat 25 cursussen en zes projecten om je alle basisbeginselen van data science te leren met behulp van Python-bibliotheken.
21. Welke Python-bibliotheken heb je gebruikt voor visualisatie?
Datavisualisatie is het belangrijkste onderdeel van data-analyse. Je ziet je data in actie en het helpt verborgen patronen te vinden.
De populairste Python-datavisualisatiebibliotheken zijn:
- Matplotlib
- Seaborn
- Plotly
- Bokeh
In Python gebruiken we meestal Matplotlib en seaborn om allerlei visualisaties te tonen. Met een paar regels code maak je scatterplots, lijndiagrammen, boxplots, staafdiagrammen en meer.
Voor interactieve en complexere toepassingen gebruiken we Plotly. Daarmee maak je kleurrijke interactieve grafieken met een paar regels code. Je kunt zoomen, animatie toepassen en zelfs besturingsfuncties toevoegen. Plotly biedt meer dan 40 unieke soorten grafieken, en je kunt er ook een webapp of dashboard mee maken.
Bokeh wordt gebruikt voor gedetailleerde grafieken met een hoge mate van interactiviteit over grote datasets.
22. Hoe zou je een dataset normaliseren of standaardiseren in Python?
Normaliseren schaalt data naar een specifiek bereik, meestal [0, 1], terwijl standaardiseren de data transformeert naar een gemiddelde van 0 en een standaarddeviatie van 1. Beide technieken zijn essentieel om data voor te bereiden voor machine learning-modellen.
Voorbeeld:
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import numpy as np
data = np.array([[1, 2], [3, 4], [5, 6]])
# Normalize
normalizer = MinMaxScaler()
normalized = normalizer.fit_transform(data)
print(normalized)
# Standardize
scaler = StandardScaler()
standardized = scaler.fit_transform(data)
print(standardized)Python codeersollicitatievragen
Als je binnenkort een Python-codeerinterview hebt, helpt het om je voor te bereiden met soortgelijke vragen om indruk te maken op de interviewer.
23. Hoe kun je spaties in een string vervangen door een opgegeven teken in Python?
Dit is een eenvoudige uitdaging in stringmanipulatie. Je moet spaties vervangen door een specifiek teken.
Voorbeeld 1: Een gebruiker heeft de string l vey u en het teken o opgegeven, en de output is loveyou.
Voorbeeld 2: Een gebruiker heeft de string D t C mpBl ckFrid yS le en het teken a opgegeven, en de output is DataCampBlackFridaySale.
De eenvoudigste manier is om de ingebouwde methode str.replace() te gebruiken om spaties direct te vervangen door het opgegeven teken.
def str_replace(text, ch):
return text.replace(" ", ch)
text = "D t C mpBl ckFrid yS le"
ch = "a"
str_replace(text, ch)
# 'DataCampBlackFridaySale'
24. Gegeven een positief geheel getal num, schrijf een functie die True retourneert als num een volkomen kwadraat is, anders False.
Dit heeft een redelijk eenvoudige oplossing. Je kunt controleren of het getal een volkomen vierkantswortel heeft door:
- Gebruik te maken van
math.isqrt(num)om exact de gehele wortel te krijgen. - Deze te kwadrateren en te controleren of die gelijk is aan het originele getal.
- Het resultaat als boolean te retourneren.
Test 1
We geven het getal 10 aan de functie valid_square():
- Door de gehele vierkantswortel van het getal te nemen, krijgen we 3.
- Vervolgens kwadrateren we 3 en krijgen 9.
- 9 is niet gelijk aan het getal, dus retourneert de functie False.
Test 2
We geven het getal 36 aan de functie valid_square():
- Door de gehele vierkantswortel van het getal te nemen, krijgen we 6.
- Vervolgens kwadrateren we 6 en krijgen 36.
- 36 is gelijk aan het getal, dus retourneert de functie True.
import math
def valid_square(num):
if num < 0:
return False
square = math.isqrt(num)
return square * square == num
valid_square(10)
# False
valid_square(36)
# True25. Gegeven een geheel getal n, retourneer het aantal volgende nullen in n faculteit n!
Om deze uitdaging te halen, moet je eerst n faculteit (n!) berekenen en vervolgens het aantal volgende nullen berekenen.
Faculteit berekenen
In de eerste stap gebruiken we een while-lus om over n faculteit te itereren en te stoppen wanneer n gelijk is aan 1.
Volgende nullen berekenen
In de tweede stap berekenen we de volgende nullen, niet het totale aantal nullen. Dat is een groot verschil.
7! = 5040Zeven faculteit heeft in totaal twee nullen en slechts één volgende nul, dus onze oplossing moet 1 retourneren.
- Zet het faculteitsgetal om naar een string.
- Lees het terug en pas een lus toe.
- Als het cijfer 0 is, tel +1 op bij het resultaat, anders breek je de lus af.
- Retourneer het resultaat.
De oplossing is elegant maar vereist aandacht voor detail.
def factorial_trailing_zeros(n):
fact = n
while n > 1:
fact *= n - 1
n -= 1
result = 0
for i in str(fact)[::-1]:
if i == "0":
result += 1
else:
break
return result
factorial_trailing_zeros(10)
# 2
factorial_trailing_zeros(18)
# 3Volg de essentiële cursus practicing coding interview questions om je voor te bereiden op je volgende Python-codeerinterviews.
26. Kan de string worden opgesplitst in woorden uit de dictionary?
Je krijgt een grote string en een woordenlijst. Je moet bepalen of de invoerstring kan worden gesegmenteerd in woorden uit de dictionary of niet.
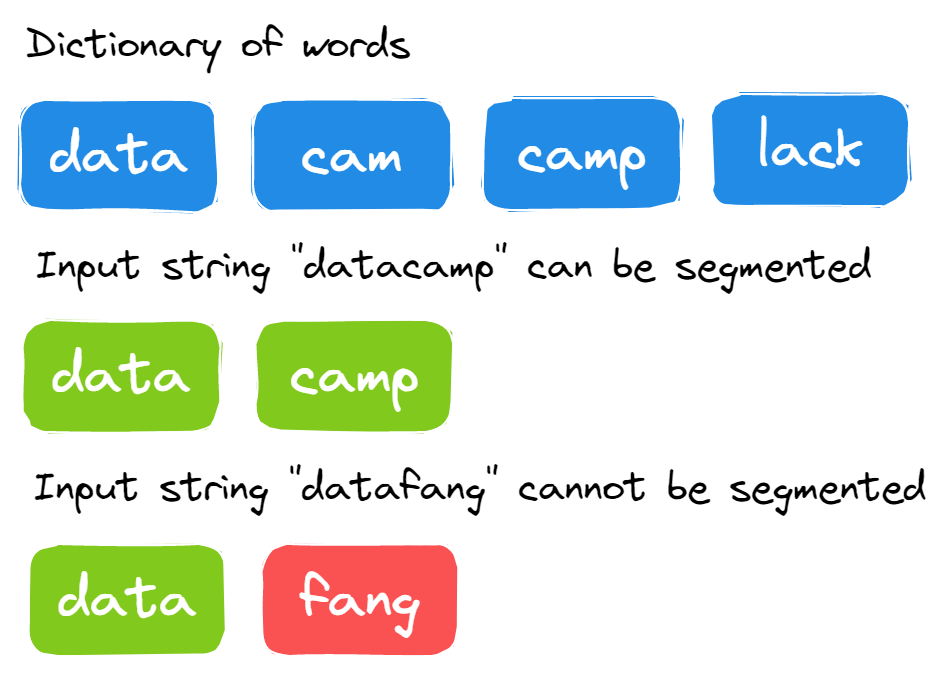
Afbeelding door de auteur
De oplossing is redelijk rechttoe rechtaan. Je segmenteert de grote string op elk punt en controleert of de string kan worden opgesplitst in woorden uit de dictionary.
- Voer een lus uit over de lengte van de grote string.
- We maken twee substrings.
- De eerste substring controleert elk punt in de grote string van
s[0:i]. - Als de eerste substring niet in de dictionary staat, retourneer je False.
- Als de eerste substring in de dictionary staat, maak je de tweede substring met
s[i:]. - Als de tweede substring in de dictionary staat of de tweede substring heeft lengte nul, retourneer dan True. Roep recursief
can_segment_str()aan met de tweede substring en retourneer True als die kan worden gesegmenteerd. - Om de oplossing efficiënt te maken voor langere strings, voegen we memoization toe zodat substrings niet telkens opnieuw worden berekend.
def can_segment_str(s, dictionary, memo=None):
if memo is None:
memo = {}
if s in memo:
return memo[s]
if not s:
return True
for i in range(1, len(s) + 1):
first_str = s[0:i]
if first_str in dictionary:
second_str = s[i:]
if (
not second_str
or second_str in dictionary
or can_segment_str(second_str, dictionary, memo)
):
memo[s] = True
return True
memo[s] = False
return False
s = "datacamp"
dictionary = ["data", "camp", "cam", "lack"]
can_segment_str(s, dictionary)
# True27. Kun je duplicaten verwijderen uit een gesorteerde array?
Gegeven een gesorteerde integer-array in oplopende volgorde, verwijder duplicaten zodat elk uniek element slechts één keer voorkomt. Omdat Python-lijsten in dit probleem niet in-place van lengte veranderen, plaats je de resultaten in de eerste k posities van dezelfde array en retourneer je k (de nieuwe lengte). Alleen de eerste k elementen zijn geldig na de aanroep; elementen voorbij k zijn verouderd.
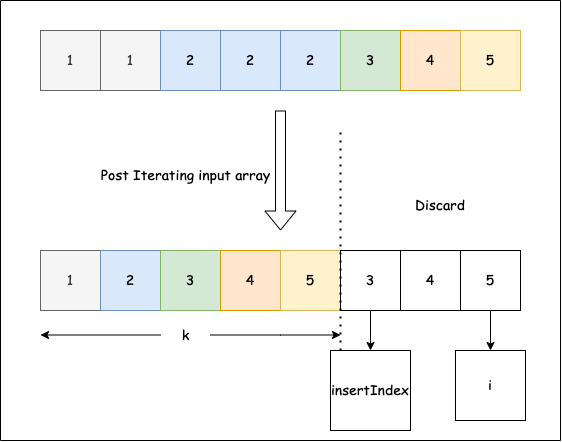
Afbeelding van LeetCode
Voorbeeld 1: inputarray is [1,1,2,2], de functie moet 2 retourneren.
Voorbeeld 2: inputarray is [1,1,2,3,3], de functie moet 3 retourneren.
Oplossing:
- Voer een lus uit van index 1 tot het einde. Vergelijk het huidige element met het vorige unieke element; wanneer verschillend, schrijf het op
insertIndexen verhooginsertIndex. RetourneerinsertIndex. - Retourneer
insertIndexaangezien dat k is.
Deze vraag is relatief eenvoudig zodra je weet hoe. Als je de tijd neemt om de vraag te begrijpen, kom je gemakkelijk met een oplossing.
def removeDuplicates(array):
size = len(array)
if size == 0:
return 0
insertIndex = 1
for i in range(1, size):
if array[i - 1] != array[i]:
array[insertIndex] = array[i]
insertIndex += 1
return insertIndex
array_1 = [1, 2, 2, 3, 3, 4]
k1 = removeDuplicates(array_1)
# 4; array_1[:k1] -> [1, 2, 3, 4]
array_2 = [1, 1, 3, 4, 5, 6, 6]
k2 = removeDuplicates(array_2)
# 5; array_2[:k2] -> [1, 3, 4, 5, 6]
28. Kun je het ontbrekende getal in de array vinden?
Je krijgt een lijst met positieve integers van 1 tot n. Alle getallen van 1 tot n zijn aanwezig behalve x, en jij moet x vinden.
Voorbeeld:
|
4 |
5 |
3 |
2 |
8 |
1 |
6 |
- n = 8
- ontbrekend getal = 7
Deze vraag is een eenvoudige wiskundesom.
- Bereken de som van alle elementen in de lijst.
- Gebruik de formule voor de som van een rekenkundige reeks om de verwachte som van de eerste n getallen te vinden.
- Retourneer het verschil tussen de verwachte som en de som van de elementen.
def find_missing(input_list):
sum_of_elements = sum(input_list)
# There is exactly 1 number missing
n = len(input_list) + 1
actual_sum = (n * ( n + 1 ) ) / 2
return int(actual_sum - sum_of_elements)
list_1 = [1,5,6,3,4]
find_missing(list_1)
# 229. Schrijf een Python-functie om te bepalen of een gegeven string een palindroom is.
Een string is een palindroom als deze voorwaarts en achterwaarts hetzelfde leest.
Voorbeeld:
def is_palindrome(s):
s = ''.join(e for e in s if e.isalnum()).lower() # Remove non-alphanumeric and convert to lowercase
return s == s[::-1]
print(is_palindrome("A man, a plan, a canal: Panama")) # Output: True
print(is_palindrome("hello")) # Output: FalsePython-sollicitatievragen voor Facebook, Amazon, Apple, Netflix en Google
Hieronder hebben we enkele vragen geselecteerd die je kunt verwachten bij de meest gewilde functies in de industrie, zoals bij Meta, Amazon, Google en consorten.
Facebook/Meta Python-sollicitatievragen
De exacte vragen die je bij Meta krijgt, hangen grotendeels af van de rol. Je kunt echter het volgende verwachten:
30. Kun je de maximale winst uit één verkoop vinden?
Je krijgt een lijst met aandelenkoersen en je moet de koop- en verkoopprijs teruggeven om de hoogste winst te behalen.
Let op: We moeten maximale winst halen uit één koop/verkoop, en als we geen winst kunnen maken, moeten we ons verlies beperken.
Voorbeeld 1: stock_price = [8, 4, 12, 9, 20, 1], koop = 4 en verkoop = 20. Winst maximaliseren.
Voorbeeld 2: stock_price = [8, 6, 5, 4, 3, 2, 1], koop = 6 en verkoop = 5. Verlies minimaliseren.
Oplossing:
- We berekenen de globale winst door de globale verkoop (het eerste element in de lijst) af te trekken van de huidige koop (het tweede element in de lijst).
- Voer de lus uit voor het bereik van 1 tot de lengte van de lijst.
- Bereken binnen de lus de huidige winst met de lijst-elementen en de huidige koopwaarde.
- Als de huidige winst groter is dan de globale winst, vervang de globale winst door de huidige winst en zet de globale verkoop op het i-de element van de lijst.
- Als de huidige koop groter is dan het huidige element van de lijst, vervang de huidige koop door dat element.
- Aan het eind retourneren we de globale koop- en verkoopwaarde. Om de globale koopwaarde te krijgen, trekken we de globale winst af van de globale verkoop.
De vraag is wat lastig, en je kunt met je eigen algoritme komen om het probleem op te lossen.
def buy_sell_stock_prices(stock_prices):
current_buy = stock_prices[0]
global_sell = stock_prices[1]
global_profit = global_sell - current_buy
for i in range(1, len(stock_prices)):
current_profit = stock_prices[i] - current_buy
if current_profit > global_profit:
global_profit = current_profit
global_sell = stock_prices[i]
if current_buy > stock_prices[i]:
current_buy = stock_prices[i]
return global_sell - global_profit, global_sell
stock_prices_1 = [10,9,16,17,19,23]
buy_sell_stock_prices(stock_prices_1)
# (9, 23)
stock_prices_2 = [8, 6, 5, 4, 3, 2, 1]
buy_sell_stock_prices(stock_prices_2)
# (6, 5)Amazon Python-sollicitatievragen
Amazon Python-sollicitatievragen kunnen sterk variëren, maar kunnen het volgende omvatten:
31. Kun je een Pythagorees drietal in een array vinden?
Schrijf een functie die True retourneert als er een Pythagorees drietal is dat voldoet aan a2+ b2 = c2.
Voorbeeld:
|
Input |
Output |
|
[3, 1, 4, 6, 5] |
True |
|
[10, 4, 6, 12, 5] |
False |
Oplossing:
-
Kwadrateer alle elementen in de array.
-
Sorteer de array in oplopende volgorde.
-
Voer twee lussen uit. De buitenste lus begint bij de laatste index van de array tot 1, en de binnenste lus begint van (
outer_loop_index - 1) naar het begin. -
Maak een
set()om de elementen tussen de index van de buitenste lus en die van de binnenste lus op te slaan. -
Controleer of er een getal in de set aanwezig is dat gelijk is aan
(array[outerLoopIndex] – array[innerLoopIndex]). Zo ja, retourneerTrue, andersFalse.
def checkTriplet(array):
n = len(array)
for i in range(n):
array[i] = array[i]**2
array.sort()
for i in range(n - 1, 1, -1):
s = set()
for j in range(i - 1, -1, -1):
if (array[i] - array[j]) in s:
return True
s.add(array[j])
return False
arr = [3, 2, 4, 6, 5]
checkTriplet(arr)
# True32. Op hoeveel manieren kun je wisselgeld maken met munten en een totaalbedrag?
We moeten een functie maken die een lijst met muntdenominaties en een totaalbedrag neemt en het aantal manieren retourneert waarop we wisselgeld kunnen maken.
In het voorbeeld hebben we de muntdenominaties [1, 2, 5] en het totaalbedrag 5 opgegeven. In ruil daarvoor krijgen we vier manieren om het wisselgeld te maken.
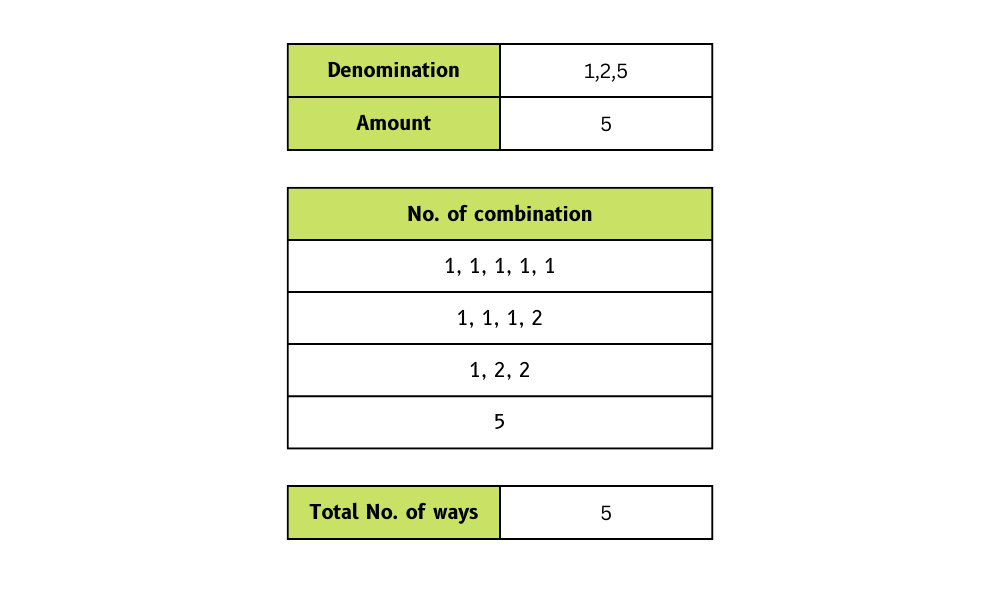
Afbeelding door de auteur
Oplossing:
- We maken de lijst met grootte
amount + 1. Extra ruimte wordt toegevoegd om de oplossing voor een nulbedrag op te slaan. - We initialiseren een oplossingenlijst met
solution[0] = 1. - We voeren twee lussen uit. De buitenste lus itereert over de denominaties en de binnenste lus loopt van de huidige denominatiewaarde tot
amount + 1. - De resultaten van verschillende denominaties worden opgeslagen in de array solution:
solution[i] = solution[i] + solution[i - den].
Dit proces wordt herhaald voor alle elementen in de denominatielijst, en in het laatste element van de oplossingslijst staat ons antwoord.
def solve_coin_change(denominations, amount):
solution = [0] * (amount + 1)
solution[0] = 1
for den in denominations:
for i in range(den, amount + 1):
solution[i] += solution[i - den]
return solution[amount]
denominations = [1, 2, 5]
amount = 5
solve_coin_change(denominations, amount)
# 4Google Python-sollicitatievragen
Net als bij de andere genoemde bedrijven hangen Google Python-sollicitatievragen af van de rol en ervaringsniveau. Enkele veelvoorkomende vragen zijn echter:
33. Definieer een lambda-functie, een iterator en een generator in Python.
Een Lambda-functie staat ook bekend als een anonieme functie. Je kunt er een onbeperkt aantal parameters aan meegeven, maar slechts één expressie gebruiken.
Een iterator is een object dat we kunnen gebruiken om over iterables zoals lijsten, dictionaries, tuples en sets te itereren.
Een generator is een functie vergelijkbaar met een normale functie, maar genereert een waarde met het sleutelwoord yield in plaats van return. Als de functiebody yield bevat, wordt het automatisch een generator.
Lees meer over Python-iterators en -generators in onze volledige tutorial.
34. Gegeven een array arr[], vind de maximale j – i zodanig dat arr[j] > arr[i]
Deze vraag is vrij eenvoudig maar vereist aandacht voor detail. We krijgen een array met positieve integers. We moeten het maximale verschil vinden tussen j-i waarbij array[j] > array[i].
Voorbeelden:
- Input: [20, 70, 40, 50, 12, 38, 98], Output: 6 (j = 6, i = 0)
- Input: [10, 3, 2, 4, 5, 6, 7, 8, 18, 0], Output: 8 ( j = 8, i = 0)
Oplossing:
- Bereken de lengte van de array en initialiseer max verschil met -1.
- Voer twee lussen uit. De buitenste lus kiest elementen vanaf links en de binnenste lus vergelijkt het gekozen element met elementen vanaf de rechterkant.
- Stop de binnenste lus wanneer het element groter is dan het gekozen element en blijf het maximale verschil updaten met j - i.
def max_index_diff(array):
n = len(array)
max_diff = -1
for i in range(0, n):
j = n - 1
while(j > i):
if array[j] > array[i] and max_diff < (j - i):
max_diff = j - i
j -= 1
return max_diff
array_1 = [20,70,40,50,12,38,98]
max_index_diff(array_1)
# 635. Hoe zou je de ternary operator in Python gebruiken?
Ternary operators staan ook bekend als conditionele expressies. Het zijn operatoren die een expressie evalueren op basis van voorwaarden die True of False zijn.
Je kunt conditionele expressies in één regel schrijven in plaats van met meerdere regels if-else. Dit zorgt voor schone en compacte code.
We kunnen bijvoorbeeld geneste if-else-statements omzetten naar één regel, zoals hieronder.
If-else-statement
score = 75
if score < 70:
if score < 50:
print('Fail')
else:
print('Merit')
else:
print('Distinction')
# DistinctionGeneste ternary operator
print('Fail' if score < 50 else 'Merit' if score < 70 else 'Distinction')
# Distinction36. Hoe zou je een LRU-cache in Python implementeren?
Python biedt een ingebouwde decorator functools.lru_cache om een LRU (Least Recently Used) cache te implementeren. Je kunt er ook zelf een maken met OrderedDict uit collections.
Voorbeeld met functools:
from functools import lru_cache
@lru_cache(maxsize=3)
def add(a, b):
return a + b
print(add(1, 2)) # Calculates and caches result
print(add(1, 2)) # Retrieves result from cachePython AI- en Machine Learning-sollicitatievragen
Met de snelle groei van AI en large language models (LLM’s) bevatten Python-interviews steeds vaker vragen over moderne AI/ML-concepten. Hier zijn kernvragen waarop je je in 2026 moet voorbereiden.
37. Wat is een Large Language Model (LLM), en hoe zou je er een gebruiken in Python?
Een Large Language Model (LLM) is een deep learning-model dat is getraind op enorme tekstdatasets om mensachtige tekst te begrijpen en te genereren. Populaire LLM’s zijn GPT-5, Claude, Llama en Gemini. In Python kun je met LLM’s communiceren via API’s of ze lokaal draaien.
Voorbeeld met de API van OpenAI:
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain Python decorators in simple terms."}
]
)
print(response.choices[0].message.content)Leer meer in onze tutorial How to Build LLM Applications with LangChain.
38. Wat is RAG (Retrieval-Augmented Generation), en waarom is het belangrijk?
RAG combineert zoeksystemen met generatieve AI om nauwkeurigere, beter onderbouwde antwoorden te geven. In plaats van uitsluitend te vertrouwen op de trainingsdata van de LLM, haalt RAG relevante documenten uit een kennisbank op en gebruikt die als context voor generatie.
Belangrijke componenten van een RAG-systeem:
- Document Store: Een vectordatabase (zoals Pinecone, Chroma of FAISS) met ge-embedde documenten
- Retriever: Vindt relevante documenten op basis van querysimilariteit
- Generator: Een LLM die antwoorden genereert met de opgehaalde context
Voorbeeld RAG-werkstroom:
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Create vector store from documents
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
# Create RAG chain
llm = ChatOpenAI(model="gpt-4")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever()
)
# Query the system
result = qa_chain.invoke("What are Python best practices?")
print(result)Lees onze gids How to Improve RAG Performance voor geavanceerde technieken.
39. Hoe ga je om met async/await in Python voor AI-toepassingen?
Asynchroon programmeren is essentieel voor AI-toepassingen die meerdere API-calls doen of gelijktijdige verzoeken afhandelen. De module asyncio van Python maakt niet-blokkerende I/O-bewerkingen mogelijk.
Voorbeeld: Gelijktijdige LLM API-calls:
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI()
async def get_completion(prompt: str) -> str:
response = await client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
async def process_multiple_prompts(prompts: list[str]) -> list[str]:
tasks = [get_completion(prompt) for prompt in prompts]
return await asyncio.gather(*tasks)
# Run concurrent requests
prompts = ["Explain Python lists", "Explain Python dicts", "Explain Python sets"]
results = asyncio.run(process_multiple_prompts(prompts))
for result in results:
print(result)Lees verder in onze Python Async Programming Guide.
40. Wat zijn embeddings, en hoe worden ze gebruikt in machine learning?
Embeddings zijn dichte vectorrepresentaties van data (tekst, afbeeldingen, enz.) die semantische betekenis vastleggen. Soortgelijke items hebben vergelijkbare embeddings, wat taken zoals semantisch zoeken, clusteren en aanbevelingssystemen mogelijk maakt.
Voorbeeld: Tekstembeddings maken:
from sentence_transformers import SentenceTransformer
import numpy as np
# Load embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Create embeddings
sentences = [
"Python is a programming language",
"JavaScript is used for web development",
"Python is great for data science"
]
embeddings = model.encode(sentences)
# Calculate similarity
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Python sentences are more similar to each other
print(f"Similarity 0-2: {cosine_similarity(embeddings[0], embeddings[2]):.3f}") # Higher
print(f"Similarity 0-1: {cosine_similarity(embeddings[0], embeddings[1]):.3f}") # Lower41. Hoe zou je een AI-agent bouwen in Python?
AI-agents zijn autonome systemen die hun omgeving waarnemen, beslissingen nemen en acties uitvoeren om doelen te bereiken. Moderne AI-agents combineren vaak LLM’s met tools en geheugen.
Belangrijke componenten van een AI-agent:
- LLM-kern: De redeneermotor die input verwerkt en acties bepaalt
- Tools: Functies die de agent kan aanroepen (websearch, code-uitvoering, API’s)
- Geheugen: Kortetermijn- (conversatie) en langetermijngeheugen (vector store)
- Planning: Complexe taken opsplitsen in subtaken
Voorbeeld met LangChain:
from langchain.agents import create_openai_functions_agent, AgentExecutor
from langchain.chat_models import ChatOpenAI
from langchain.tools import Tool
from langchain import hub
# Define tools
def search_database(query: str) -> str:
return f"Results for: {query}"
tools = [
Tool(
name="DatabaseSearch",
func=search_database,
description="Search the company database for information"
)
]
# Create agent
llm = ChatOpenAI(model="gpt-4")
prompt = hub.pull("hwchase17/openai-functions-agent")
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
# Run agent
result = agent_executor.invoke({"input": "Find sales data for Q4"})
print(result["output"])Leer meer in onze tutorial Building LangChain Agents.
Je team upskillen met Python
Hoewel het voorbereiden op Python-interviews essentieel is voor werkzoekenden en hiring managers, is het voor bedrijven net zo belangrijk om continu in Python-training voor hun teams te investeren. In een tijd waarin automatisering, data-analyse en softwareontwikkeling cruciaal zijn, kan ervoor zorgen dat je medewerkers sterke Python-vaardigheden hebben een doorslaggevende factor zijn voor het succes van je bedrijf.
Als je teamleider of ondernemer bent en wilt dat je hele team vaardig is in Python, biedt DataCamp for Business op maat gemaakte trainingsprogramma’s om je medewerkers Python-vaardigheden te laten beheersen, van de basis tot geavanceerde concepten. We kunnen bieden:
- Gerichte leerroutes: Aanpasbaar aan het huidige vaardigheidsniveau van je team en specifieke bedrijfsbehoeften.
- Hands-on oefening: Praktijkprojecten en codeeroefeningen die het leren versterken en de retentie verbeteren.
- Voortgangsmeting: Tools om de voortgang van je team te monitoren en te beoordelen, zodat ze hun leerdoelen behalen.
Investeren in Python-upskilling via platforms zoals DataCamp vergroot niet alleen de capaciteiten van je team, maar geeft je bedrijf ook een strategisch voordeel, waardoor je kunt innoveren, concurrerend blijft en impactvolle resultaten levert. Neem contact op met ons team en vraag vandaag nog een demo aan.
