
Domande base di Python
Queste sono alcune domande che potresti incontrare durante un colloquio Python per profili junior.
1. Che cos'è Python? Elenca alcune delle sue caratteristiche principali.
Python è un linguaggio di programmazione ad alto livello e versatile, noto per la sua sintassi leggibile e per gli ampi ambiti di applicazione. Ecco alcune caratteristiche chiave di Python:
- Sintassi semplice e leggibile: la sintassi di Python è chiara e lineare, accessibile ai principianti ed efficiente per gli sviluppatori esperti.
- Linguaggio interpretato: Python esegue il codice riga per riga, facilitando debug e test.
- Tipizzazione dinamica: non richiede dichiarazioni esplicite dei tipi di dato, offrendo maggiore flessibilità.
- Librerie e framework estesi: librerie come NumPy, Pandas e Django ampliano le funzionalità di Python per attività specialistiche in data science, sviluppo web e altro.
- Compatibilità multipiattaforma: Python gira su diversi sistemi operativi, tra cui Windows, macOS e Linux.
2. Cosa sono le liste e le tuple in Python?
Liste e tuple sono strutture dati fondamentali in Python con caratteristiche e casi d'uso distinti.
List (lista):
- Mutabile: gli elementi possono essere modificati dopo la creazione.
- Uso di memoria: consuma più memoria.
- Prestazioni: iterazione più lenta rispetto alle tuple ma migliore per operazioni di inserimento e cancellazione.
- Metodi: offre vari metodi built-in per la manipolazione.
Esempio:
a_list = ["Data", "Camp", "Tutorial"]
a_list.append("Session")
print(a_list) # Output: ['Data', 'Camp', 'Tutorial', 'Session']Tuple (tupla):
- Immutabile: gli elementi non possono essere modificati dopo la creazione.
- Uso di memoria: consuma meno memoria.
- Prestazioni: iterazione più veloce rispetto alle liste ma con minore flessibilità.
- Metodi: metodi built-in limitati.
Esempio:
a_tuple = ("Data", "Camp", "Tutorial")
print(a_tuple) # Output: ('Data', 'Camp', 'Tutorial')Scopri di più nel nostro tutorial sulle liste in Python.
3. Che cos'è __init__() in Python?
Il metodo __init__() è noto come costruttore nella terminologia della programmazione orientata agli oggetti (OOP). Viene utilizzato per inizializzare lo stato di un oggetto al momento della creazione. Questo metodo viene chiamato automaticamente quando viene istanziata una nuova istanza di una classe.
Scopo:
- Assegnare valori alle proprietà dell'oggetto.
- Eseguire eventuali operazioni di inizializzazione.
Esempio:
Abbiamo creato una classe book_shop e aggiunto il costruttore e la funzione book(). Il costruttore memorizzerà il titolo del libro e la funzione book() stamperà il nome del libro.
Per testare il codice abbiamo inizializzato l'oggetto b con “Sandman” ed eseguito la funzione book().
class book_shop:
# constructor
def __init__(self, title):
self.title = title
# Sample method
def book(self):
print('The title of the book is', self.title)
b = book_shop('Sandman')
b.book()
# The title of the book is Sandman4. Qual è la differenza tra un tipo di dato mutabile e uno immutabile?
Tipi di dato mutabili:
- Definizione: possono essere modificati dopo la creazione.
- Esempi: List, Dictionary, Set.
- Caratteristiche: è possibile aggiungere, rimuovere o cambiare elementi.
- Caso d'uso: adatti a collezioni di elementi che richiedono aggiornamenti frequenti.
Esempio:
# List Example
a_list = [1, 2, 3]
a_list.append(4)
print(a_list) # Output: [1, 2, 3, 4]
# Dictionary Example
a_dict = {'a': 1, 'b': 2}
a_dict['c'] = 3
print(a_dict) # Output: {'a': 1, 'b': 2, 'c': 3}Tipi di dato immutabili:
- Definizione: non possono essere modificati dopo la creazione.
- Esempi: Numerici (int, float), String, Tuple.
- Caratteristiche: gli elementi non possono essere cambiati una volta impostati; qualsiasi operazione che sembri modificare un oggetto immutabile crea in realtà un nuovo oggetto.
Esempio:
# Numeric Example
a_num = 10
a_num = 20 # Creates a new integer object
print(a_num) # Output: 20
# String Example
a_str = "hello"
a_str = "world" # Creates a new string object
print(a_str) # Output: world
# Tuple Example
a_tuple = (1, 2, 3)
# a_tuple[0] = 4 # This will raise a TypeError
print(a_tuple) # Output: (1, 2, 3)5. Spiega le comprehension di list, dictionary e tuple con un esempio.
List
La list comprehension offre una sintassi in una riga per creare una nuova lista a partire dai valori di una lista esistente. Puoi ottenere lo stesso risultato con un ciclo for, ma richiederà più righe e talvolta può essere più complesso.
La list comprehension semplifica la creazione di una lista basata su un iterabile esistente.
my_list = [i for i in range(1, 10)]
my_list
# [1, 2, 3, 4, 5, 6, 7, 8, 9]Dictionary
In modo analogo a una list comprehension, puoi creare un dizionario a partire da una struttura esistente con una sola riga di codice. Devi racchiudere l'operazione tra parentesi graffe {}.
# Creating a dictionary using dictionary comprehension
my_dict = {i: i**2 for i in range(1, 10)}
# Output the dictionary
my_dict
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}Tuple
A differenza di liste e dizionari, non esiste una vera e propria “tuple comprehension”.
Quando usi le parentesi tonde con una comprehension, Python crea in realtà una generator expression, non una tupla. Per ottenere una tupla, devi convertire il generatore con tuple() o definire direttamente un letterale di tupla.
# Generator expression (not a tuple)
my_gen = (i for i in range(1, 10))
my_gen
# <generator object <genexpr> ...>
# Converting generator to tuple
my_tuple = tuple(i for i in range(1, 10))
my_tuple
# (1, 2, 3, 4, 5, 6, 7, 8, 9)
# Or simply define a tuple directly
literal_tuple = (1, 2, 3)
literal_tuple
# (1, 2, 3)
Puoi approfondire nel nostro tutorial sulle tuple in Python.
6. Che cos'è il Global Interpreter Lock (GIL) in Python e perché è importante?
Il Global Interpreter Lock (GIL) è un mutex in CPython (l'implementazione di riferimento) che assicura che un solo thread nativo esegua il bytecode Python alla volta. Semplifica la gestione della memoria proteggendo strutture dati interne come i reference count, ma limita il vero parallelismo nei task CPU-bound, rendendo il multithreading meno efficace per carichi computazionali. Funziona invece bene per task I/O-bound, in cui i thread attendono operazioni di rete, file o database.
Nota: Python 3.13 ha introdotto una build sperimentale senza GIL (PEP 703) e Python 3.14 aggiunge un supporto free-threaded documentato. Alcune estensioni C e librerie potrebbero non essere ancora pienamente compatibili.
Domande intermedie di Python
Ecco alcune domande che potresti incontrare durante un colloquio Python di livello intermedio.
7. Puoi esplicare gli algoritmi comuni di ricerca e attraversamento di grafi in Python?
Python offre diversi potenti algoritmi per la ricerca e l'attraversamento di grafi, ognuno dei quali lavora con strutture dati diverse e risolve problemi differenti. Ecco una spiegazione:
- Binary Search: se devi trovare rapidamente un elemento in una lista ordinata, la ricerca binaria è la soluzione. Divide ripetutamente l'intervallo di ricerca a metà finché non trova il target.
- AVL Tree: un albero AVL mantiene l'equilibrio, un grande vantaggio se inserisci o elimini elementi frequentemente. Questo albero binario di ricerca autobilanciante mantiene le ricerche veloci evitando che l'albero si sbilanci troppo.
- Breadth-First Search (BFS): la BFS esplora un grafo livello per livello. È particolarmente utile per trovare il percorso più breve in un grafo non pesato, perché controlla tutte le mosse possibili da ciascun nodo prima di andare più in profondità.
- Depth-First Search (DFS): la DFS esplora il più possibile lungo ogni ramo prima di tornare indietro. È ottima per compiti come la risoluzione di labirinti o l'attraversamento di alberi.
- Algoritmo A*: l'algoritmo A* è più avanzato e combina i punti di forza di BFS e DFS usando euristiche per trovare in modo efficiente il percorso più breve. È comunemente usato nel pathfinding per mappe e giochi.
8. Che cos'è un KeyError in Python e come si gestisce?
Un KeyError in Python si verifica quando provi ad accedere a una chiave che non esiste in un dizionario. Questo errore viene sollevato perché Python si aspetta che ogni chiave ricercata sia presente nel dizionario e, quando non lo è, lancia un KeyError.
Ad esempio, se hai un dizionario di voti degli studenti e provi ad accedere a uno studente non presente, otterrai un KeyError. Puoi gestire l'errore in vari modi:
-
Usa il metodo .get(): restituisce
None(o un valore di default specificato) invece di sollevare un errore se la chiave non viene trovata. -
Usa un blocco try-except: racchiudere il codice in
try-exceptti consente di intercettare ilKeyErrore gestirlo con grazia. -
Controlla la chiave con in: puoi verificare se una chiave esiste nel dizionario usando
if key in dictionaryprima di accedervi.
Per approfondire, leggi il nostro tutorial completo: Eccezioni Python KeyError e come risolverle.
9. Come gestisce Python la memoria e quale ruolo ha il garbage collection?
Python gestisce automaticamente l'allocazione e la deallocazione della memoria usando uno heap privato, dove sono memorizzati tutti gli oggetti e le strutture dati. La gestione della memoria è affidata al memory manager di Python, che ottimizza l'uso della memoria, e al garbage collector, che si occupa degli oggetti inutilizzati o non referenziati per liberare memoria.
Il garbage collector in Python usa il conteggio dei riferimenti e un collector ciclico per rilevare e raccogliere i dati inutilizzati. Quando un oggetto non ha più riferimenti, diventa idoneo alla garbage collection. Il modulo gc in Python permette di interagire direttamente con il garbage collector, fornendo funzioni per abilitarlo o disabilitarlo e per effettuare raccolte manuali.
10. Qual è la differenza tra shallow copy e deep copy in Python e quando useresti l'una o l'altra?
In Python, le copie shallow e deep si usano per duplicare oggetti, ma trattano in modo diverso le strutture annidate.
-
Shallow Copy: crea un nuovo oggetto ma inserisce riferimenti agli oggetti contenuti nell'originale. Se l'oggetto originale contiene altri oggetti mutabili (come liste dentro liste), la shallow copy farà riferimento agli stessi oggetti interni. Questo può portare a modifiche inattese se modifichi uno di quegli oggetti sia nell'originale che nella copia. Puoi creare una shallow copy usando il metodo
copy()o la funzionecopy()del modulocopy. -
Deep Copy: crea un nuovo oggetto e copia ricorsivamente tutti gli oggetti contenuti nell'originale. Questo significa che persino le strutture annidate vengono duplicate, quindi le modifiche in una copia non influiscono sull'altra. Per creare una deep copy puoi usare la funzione
deepcopy()del modulocopy.
Esempio d'uso: una shallow copy è adatta quando l'oggetto contiene solo elementi immutabili o quando vuoi che i cambiamenti nelle strutture annidate si riflettano in entrambe le copie. Una deep copy è ideale quando lavori con oggetti complessi e annidati e vuoi un duplicato completamente indipendente. Leggi il nostro tutorial Python Copy List: cosa dovresti sapere per saperne di più. Include un'intera sezione sulla differenza tra shallow e deep copy.
11. Come puoi usare il modulo collections di Python per semplificare compiti comuni?
Il modulo collections in Python fornisce strutture dati specializzate come defaultdict, Counter, deque e OrderedDict per semplificare vari compiti. Ad esempio, Counter è ideale per contare elementi in un iterabile, mentre defaultdict può inizializzare i valori del dizionario senza controlli espliciti.
Esempio:
from collections import Counter
data = ['a', 'b', 'c', 'a', 'b', 'a']
count = Counter(data)
print(count) # Output: Counter({'a': 3, 'b': 2, 'c': 1})Domande avanzate di Python
Queste domande sono per professionisti Python con maggiore esperienza.
12. Che cos'è il monkey patching in Python?
Il monkey patching in Python è una tecnica dinamica che può cambiare il comportamento del codice a runtime. In breve, puoi modificare una classe o un modulo in esecuzione.
Esempio:
Vediamo il monkey patching con un esempio.
-
Abbiamo creato una classe
monkeycon una funzionepatch(). Abbiamo anche creato una funzionemonk_pfuori dalla classe. -
Ora sostituiremo
patchcon la funzionemonk_passegnandomonkey.patchamonk_p. -
Infine, testeremo la modifica creando l'oggetto usando la classe
monkeyed eseguendo la funzionepatch().
Invece di visualizzare patch() is being called, viene mostrato monk_p() is being called.
class monkey:
def patch(self):
print ("patch() is being called")
def monk_p(self):
print ("monk_p() is being called")
# replacing address of "patch" with "monk_p"
monkey.patch = monk_p
obj = monkey()
obj.patch()
# monk_p() is being calledAttenzione: Usalo con parsimonia; il monkey patching può rendere il codice più difficile da leggere e sorprendere chi lavora con il tuo codice o i tuoi test.
13. A cosa serve l'istruzione “with” in Python?
L'istruzione with viene usata per la gestione delle eccezioni e per rendere il codice più pulito e semplice. In genere si usa per la gestione di risorse comuni come creare, modificare e salvare un file.
Esempio:
Invece di scrivere più righe con open, try, finally e close, puoi creare e scrivere un file di testo usando l'istruzione with. È semplice.
# using with statement
with open('myfile.txt', 'w') as file:
file.write('DataCamp Black Friday Sale!!!')14. Perché usare else nella struttura try/except in Python?
try: ed except: sono comunemente associati alla gestione delle eccezioni in Python, quindi a cosa serve else:? else: viene eseguito quando non viene sollevata alcuna eccezione.
Esempio:
Vediamo else: con un paio di esempi.
-
Al primo tentativo abbiamo inserito
2come numeratore edcome denominatore. È errato eexcept:è stato eseguito con “Invalid input!”. -
Al secondo tentativo abbiamo inserito
2come numeratore e1come denominatore ottenendo il risultato2. Non è stata sollevata alcuna eccezione, quindi è stato eseguitoelse:che ha stampato il messaggioDivision is successful.
try:
num1 = int(input('Enter Numerator: '))
num2 = int(input('Enter Denominator: '))
division = num1/num2
print(f'Result is: {division}')
except:
print('Invalid input!')
else:
print('Division is successful.')
## Try 1 ##
# Enter Numerator: 2
# Enter Denominator: d
# Invalid input!
## Try 2 ##
# Enter Numerator: 2
# Enter Denominator: 1
# Result is: 2.0
# Division is successful.Segui lo skill track Python Fundamentals per acquisire le competenze fondamentali necessarie per diventare un programmatore Python.
15. Cosa sono i decorator in Python?
I decorator in Python sono un pattern che consente di aggiungere nuove funzionalità a un oggetto esistente senza modificarne la struttura. Sono comunemente usati per estendere il comportamento di funzioni o metodi. Puoi leggere di più su come usare i decorator in Python in una guida dedicata.
Esempio:
import functools
def my_decorator(func):
@functools.wraps(func) # preserves __name__, __doc__, etc.
def wrapper(*args, **kwargs):
print("Something is happening before the function is called.")
result = func(*args, **kwargs)
print("Something is happening after the function is called.")
return result
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
# Output:
# Something is happening before the function is called.
# Hello!
# Something is happening after the function is called.16. Cosa sono i context manager in Python e come si implementano?
I context manager in Python servono a gestire risorse, assicurando che vengano acquisite e rilasciate correttamente. Il caso d'uso più comune dei context manager è l'istruzione with.
Esempio:
class FileManager:
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
self.file = open(self.filename, self.mode)
return self.file
def __exit__(self, exc_type, exc_value, traceback):
self.file.close()
with FileManager('test.txt', 'w') as f:
f.write('Hello, world!')In questo esempio, la classe FileManager è un context manager che assicura che il file venga chiuso correttamente dopo l'uso all'interno dell'istruzione with.
17. Cosa sono le metaclassi in Python e in cosa differiscono dalle classi normali?
Le metaclassi sono classi di classi. Definiscono come le classi si comportano e vengono create. Mentre le classi normali creano oggetti, le metaclassi creano classi. Usando le metaclassi, puoi modificare le definizioni di classe, imporre regole o aggiungere funzionalità durante la creazione della classe.
Esempio:
class Meta(type):
def __new__(cls, name, bases, dct):
print(f"Creating class {name}")
return super().__new__(cls, name, bases, dct)
class MyClass(metaclass=Meta):
pass
# Output: Creating class MyClassDomande Python per Data Science
Per chi è più orientato alle applicazioni di data science in Python, ecco alcune domande che potresti incontrare.
18. Quali sono i vantaggi di NumPy rispetto alle normali liste Python?
Ci sono diversi vantaggi di NumPy rispetto alle normali liste Python, tra cui:
- Memoria: gli array NumPy sono più efficienti in memoria perché memorizzano elementi dello stesso tipo in blocchi contigui. (L'uso effettivo dipende dal tipo di elemento e dal sistema, ma puoi verificarlo con
sys.getsizeofoarray.nbytes.) - Velocità: NumPy usa implementazioni C ottimizzate, quindi le operazioni su grandi array sono molto più veloci che con le liste.
- Versatilità: NumPy supporta operazioni vettorializzate (ad es. addizione, moltiplicazione) e fornisce molte funzioni matematiche integrate che le liste Python non supportano.
19. Qual è la differenza tra merge, join e concatenate?
Merge
Esegue il merge di due DataFrame o oggetti series usando una colonna identificativa univoca.
Richiede due DataFrame, una colonna in comune in entrambi e il “come” vuoi unirli. Puoi effettuare left, right, outer, inner e cross join tra due DataFrame. Per default è un inner join.
pd.merge(df1, df2, how='outer', on='Id')Join
Unisci i DataFrame usando l'indice univoco. Accetta un argomento opzionale on che può essere una colonna o più nomi di colonne. Per default, la funzione join esegue un left join.
df1.join(df2)Concatenate
Concatenate unisce due o più DataFrame lungo un asse specifico (righe o colonne). Non richiede un argomento on.
pd.concat(df1,df2)- join(): combina due DataFrame per indice.
- merge(): combina due DataFrame per le colonne specificate.
- concat(): combina due o più DataFrame in verticale o orizzontale.
20. Come identifichi e gestisci i valori mancanti?
Identificare i valori mancanti
Possiamo identificare i valori mancanti in un DataFrame usando la funzione isnull() e poi applicando sum(). isnull() restituirà valori booleani e la somma ti darà il numero di valori mancanti in ogni colonna.
Nell'esempio, abbiamo creato un dizionario di liste e lo abbiamo convertito in un DataFrame pandas. Successivamente, abbiamo usato isnull().sum() per ottenere il numero di valori mancanti in ogni colonna.
import pandas as pd
import numpy as np
# dictionary of lists
dict = {'id':[1, 4, np.nan, 9],
'Age': [30, 45, np.nan, np.nan],
'Score':[np.nan, 140, 180, 198]}
# creating a DataFrame
df = pd.DataFrame(dict)
df.isnull().sum()
# id 1
# Age 2
# Score 1Gestire i valori mancanti
Esistono vari modi per gestire i valori mancanti in Python.
-
Eliminare l'intera riga o colonna se contiene valori mancanti usando
dropna(). Questo metodo non è raccomandato perché potresti perdere informazioni importanti. -
Riempire i valori mancanti con una costante, media, backward fill o forward fill usando la funzione
fillna(). -
Sostituire i valori mancanti con una costante String, Integer o Float usando la funzione
replace(). -
Compilare i valori mancanti usando un metodo di interpolazione.
Nota: assicurati di lavorare con un dataset ampio quando usi la funzione dropna().
# drop missing values
df.dropna(axis = 0, how ='any')
#fillna
df.fillna(method ='bfill')
#replace null values with -999
df.replace(to_replace = np.nan, value = -999)
# Interpolate
df.interpolate(method ='linear', limit_direction ='forward')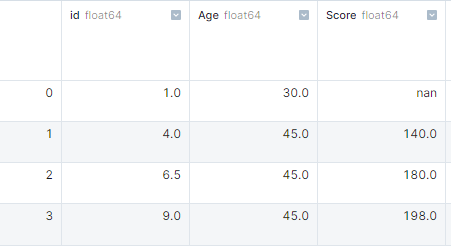
Diventa un data scientist professionista seguendo il career track Associate Data Scientist in Python. Include 25 corsi e sei progetti per imparare tutti i fondamenti della data science con le librerie Python.
21. Quali librerie Python hai usato per la visualizzazione?
La visualizzazione dei dati è la parte più importante dell'analisi. Ti permette di vedere i dati in azione e aiuta a scoprire pattern nascosti.
Le librerie Python più popolari per la visualizzazione sono:
- Matplotlib
- Seaborn
- Plotly
- Bokeh
In Python, in genere usiamo Matplotlib e Seaborn per mostrare tutti i tipi di visualizzazioni. Con poche righe di codice puoi creare scatter plot, line plot, box plot, bar chart e molto altro.
Per applicazioni interattive e più complesse usiamo Plotly. Puoi creare grafici interattivi e colorati con poche righe di codice. Puoi zoomare, applicare animazioni e persino aggiungere controlli. Plotly offre più di 40 tipi di grafici unici e possiamo usarlo anche per creare applicazioni web o dashboard.
Bokeh si usa per grafica dettagliata con un alto livello di interattività su grandi dataset.
22. Come normalizzeresti o standardizzeresti un dataset in Python?
La normalizzazione scala i dati in un intervallo specifico, di solito [0, 1], mentre la standardizzazione li trasforma in modo che abbiano media 0 e deviazione standard 1. Entrambe le tecniche sono essenziali per preparare i dati ai modelli di machine learning.
Esempio:
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import numpy as np
data = np.array([[1, 2], [3, 4], [5, 6]])
# Normalize
normalizer = MinMaxScaler()
normalized = normalizer.fit_transform(data)
print(normalized)
# Standardize
scaler = StandardScaler()
standardized = scaler.fit_transform(data)
print(standardized)Domande di coding in Python
Se hai un colloquio di coding in Python in arrivo, prepararti con domande simili a queste può aiutarti a fare colpo sull'intervistatore.
23. Come puoi sostituire gli spazi in una stringa con un carattere dato in Python?
È una semplice sfida di manipolazione di stringhe. Devi sostituire gli spazi con un carattere specifico.
Esempio 1: l'utente ha fornito la stringa l vey u e il carattere o, l'output sarà loveyou.
Esempio 2: l'utente ha fornito la stringa D t C mpBl ckFrid yS le e il carattere a, l'output sarà DataCampBlackFridaySale.
Il modo più semplice è usare il metodo integrato str.replace() per sostituire direttamente gli spazi con il carattere indicato.
def str_replace(text, ch):
return text.replace(" ", ch)
text = "D t C mpBl ckFrid yS le"
ch = "a"
str_replace(text, ch)
# 'DataCampBlackFridaySale'
24. Dato un intero positivo num, scrivi una funzione che restituisca True se num è un quadrato perfetto altrimenti False.
La soluzione è relativamente diretta. Puoi verificare se il numero ha una radice quadrata perfetta:
- Usando
math.isqrt(num)per ottenere esattamente la radice quadrata intera. - Elevandola al quadrato e verificando se è uguale al numero originale.
- Restituendo il risultato come booleano.
Test 1
Abbiamo fornito il numero 10 alla funzione valid_square():
- Prendendo la radice quadrata intera del numero, otteniamo 3.
- Poi eleviamo 3 al quadrato e otteniamo 9.
- 9 non è uguale al numero, quindi la funzione restituirà False.
Test 2
Abbiamo fornito il numero 36 alla funzione valid_square():
- Prendendo la radice quadrata intera del numero, otteniamo 6.
- Poi eleviamo 6 al quadrato e otteniamo 36.
- 36 è uguale al numero, quindi la funzione restituirà True.
import math
def valid_square(num):
if num < 0:
return False
square = math.isqrt(num)
return square * square == num
valid_square(10)
# False
valid_square(36)
# True25. Dato un intero n, restituisci il numero di zeri finali in n fattoriale n!
Per superare questa sfida, devi prima calcolare n fattoriale (n!) e poi calcolare il numero di zeri finali.
Calcolare il fattoriale
Nella prima fase useremo un ciclo while per iterare fino a n fattoriale e fermarci quando n è uguale a 1.
Calcolare gli zeri finali
Nella seconda fase calcoleremo gli zeri finali, non il numero totale di zeri. C'è una grande differenza.
7! = 5040Il fattoriale di sette ha in totale due zeri e solo uno zero finale, quindi la nostra soluzione dovrebbe restituire 1.
- Converti il numero fattoriale in stringa.
- Leggilo all'indietro e applica un ciclo.
- Se il numero è 0, aggiungi +1 al risultato, altrimenti interrompi il ciclo.
- Restituisci il risultato.
La soluzione è elegante ma richiede attenzione ai dettagli.
def factorial_trailing_zeros(n):
fact = n
while n > 1:
fact *= n - 1
n -= 1
result = 0
for i in str(fact)[::-1]:
if i == "0":
result += 1
else:
break
return result
factorial_trailing_zeros(10)
# 2
factorial_trailing_zeros(18)
# 3Segui il corso essenziale sulle domande di coding da colloquio per prepararti ai prossimi colloqui in Python.
26. La stringa può essere suddivisa in parole di un dizionario?
Ti viene fornita una lunga stringa e un dizionario di parole. Devi verificare se la stringa di input può essere segmentata in parole usando il dizionario oppure no.
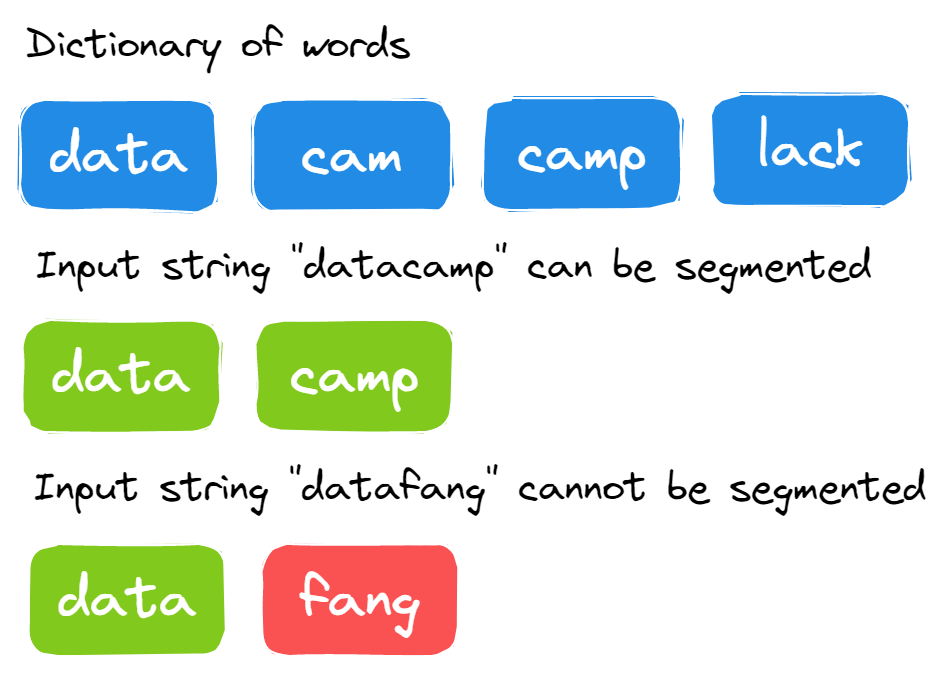
Immagine dell'autore
La soluzione è abbastanza diretta. Devi segmentare una lunga stringa in ciascun punto e verificare se può essere divisa nelle parole del dizionario.
- Esegui il ciclo usando la lunghezza della stringa grande.
- Creeremo due sotto-stringhe.
- La prima sotto-stringa verificherà ogni punto della stringa grande da
s[0:i]. - Se la prima sotto-stringa non è nel dizionario, restituirà False.
- Se la prima sotto-stringa è nel dizionario, verrà creata la seconda sotto-stringa usando
s[i:]. - Se la seconda sotto-stringa è nel dizionario o se ha lunghezza zero, allora restituisci True. Chiama ricorsivamente
can_segment_str()con la seconda sotto-stringa e restituisci True se può essere segmentata. - Per rendere la soluzione efficiente su stringhe lunghe, aggiungiamo la memoizzazione così da non ricalcolare più volte le stesse sotto-stringhe.
def can_segment_str(s, dictionary, memo=None):
if memo is None:
memo = {}
if s in memo:
return memo[s]
if not s:
return True
for i in range(1, len(s) + 1):
first_str = s[0:i]
if first_str in dictionary:
second_str = s[i:]
if (
not second_str
or second_str in dictionary
or can_segment_str(second_str, dictionary, memo)
):
memo[s] = True
return True
memo[s] = False
return False
s = "datacamp"
dictionary = ["data", "camp", "cam", "lack"]
can_segment_str(s, dictionary)
# True27. Sai rimuovere i duplicati da un array ordinato?
Dato un array di interi ordinato in ordine crescente, rimuovi i duplicati in modo che ogni elemento unico compaia una sola volta. Poiché le liste Python non cambiano lunghezza in-place per questo problema, inserisci i risultati nelle prime k posizioni dello stesso array e restituisci k (la nuova lunghezza). Solo i primi k elementi sono validi dopo la chiamata; oltre k sono obsoleti.
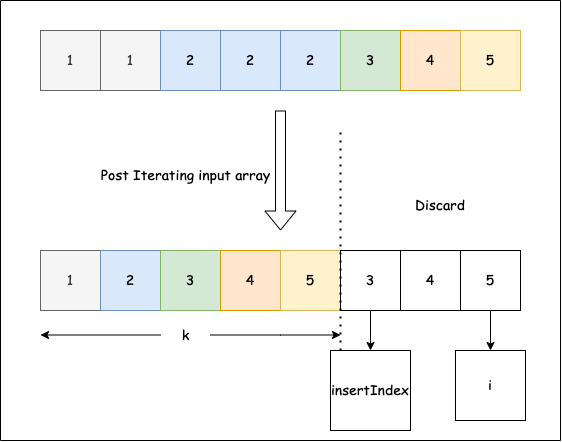
Immagine da LeetCode
Esempio 1: array di input [1,1,2,2], la funzione dovrebbe restituire 2.
Esempio 2: array di input [1,1,2,3,3], la funzione dovrebbe restituire 3.
Soluzione:
- Esegui un ciclo dall'indice 1 alla fine. Confronta l'elemento corrente con il precedente elemento unico; quando è diverso, scrivilo a
insertIndexe incrementainsertIndex. RestituisciinsertIndex. - Restituisci
insertIndexpoiché è il valore k.
Questa domanda è relativamente semplice una volta capita. Se dedichi tempo a comprendere bene il testo, puoi arrivare facilmente a una soluzione.
def removeDuplicates(array):
size = len(array)
if size == 0:
return 0
insertIndex = 1
for i in range(1, size):
if array[i - 1] != array[i]:
array[insertIndex] = array[i]
insertIndex += 1
return insertIndex
array_1 = [1, 2, 2, 3, 3, 4]
k1 = removeDuplicates(array_1)
# 4; array_1[:k1] -> [1, 2, 3, 4]
array_2 = [1, 1, 3, 4, 5, 6, 6]
k2 = removeDuplicates(array_2)
# 5; array_2[:k2] -> [1, 3, 4, 5, 6]
28. Sai trovare il numero mancante nell'array?
Ti è stato fornito l'elenco di interi positivi da 1 a n. Sono presenti tutti i numeri da 1 a n tranne x, e devi trovare x.
Esempio:
|
4 |
5 |
3 |
2 |
8 |
1 |
6 |
- n = 8
- numero mancante = 7
Questa domanda è un semplice problema di matematica.
- Trova la somma di tutti gli elementi nella lista.
- Usando la formula della somma di una progressione aritmetica, troviamo la somma attesa dei primi n numeri.
- Restituisci la differenza tra la somma attesa e la somma degli elementi.
def find_missing(input_list):
sum_of_elements = sum(input_list)
# There is exactly 1 number missing
n = len(input_list) + 1
actual_sum = (n * ( n + 1 ) ) / 2
return int(actual_sum - sum_of_elements)
list_1 = [1,5,6,3,4]
find_missing(list_1)
# 229. Scrivi una funzione Python per determinare se una stringa è un palindromo.
Una stringa è un palindromo se si legge allo stesso modo in avanti e all'indietro.
Esempio:
def is_palindrome(s):
s = ''.join(e for e in s if e.isalnum()).lower() # Remove non-alphanumeric and convert to lowercase
return s == s[::-1]
print(is_palindrome("A man, a plan, a canal: Panama")) # Output: True
print(is_palindrome("hello")) # Output: FalseDomande Python per Facebook, Amazon, Apple, Netflix e Google
Di seguito abbiamo selezionato alcune domande che potresti aspettarti per i ruoli più ambiti del settore, come quelli in Meta, Amazon, Google e simili.
Domande da colloquio Python per Facebook/Meta
Le domande esatte che incontrerai in Meta dipendono in gran parte dal ruolo. Tuttavia, potresti aspettarti alcune delle seguenti:
30. Sai trovare il massimo profitto da una singola vendita?
Ti viene fornita la lista dei prezzi di un'azione, e devi restituire il prezzo di acquisto e di vendita per ottenere il profitto più alto.
Nota: dobbiamo ottenere il massimo profitto da un singolo acquisto/vendita e, se non possiamo fare profitto, dobbiamo ridurre le perdite.
Esempio 1: stock_price = [8, 4, 12, 9, 20, 1], buy = 4 e sell = 20. Massimizzare il profitto.
Esempio 2: stock_price = [8, 6, 5, 4, 3, 2, 1], buy = 6 e sell = 5. Minimizzare la perdita.
Soluzione:
- Calcoleremo il profitto globale sottraendo il global sell (il primo elemento della lista) dal current buy (il secondo elemento della lista).
- Esegui il ciclo da 1 alla lunghezza della lista.
- All'interno del ciclo, calcola il profitto corrente usando gli elementi della lista e il current buy.
- Se il profitto corrente è maggiore del profitto globale, aggiorna il profitto globale e imposta global sell all'elemento i della lista.
- Se il current buy è maggiore dell'elemento corrente della lista, imposta current buy a quell'elemento.
- Alla fine, restituisci i valori global buy e sell. Per ottenere global buy, sottrai il global profit dal global sell.
La domanda è un po' insidiosa e puoi proporre un algoritmo tuo per risolvere il problema.
def buy_sell_stock_prices(stock_prices):
current_buy = stock_prices[0]
global_sell = stock_prices[1]
global_profit = global_sell - current_buy
for i in range(1, len(stock_prices)):
current_profit = stock_prices[i] - current_buy
if current_profit > global_profit:
global_profit = current_profit
global_sell = stock_prices[i]
if current_buy > stock_prices[i]:
current_buy = stock_prices[i]
return global_sell - global_profit, global_sell
stock_prices_1 = [10,9,16,17,19,23]
buy_sell_stock_prices(stock_prices_1)
# (9, 23)
stock_prices_2 = [8, 6, 5, 4, 3, 2, 1]
buy_sell_stock_prices(stock_prices_2)
# (6, 5)Domande da colloquio Python per Amazon
Le domande in Amazon possono variare molto ma potrebbero includere:
31. Sai trovare una terna pitagorica in un array?
Scrivi una funzione che restituisca True se esiste una terna pitagorica che soddisfa a2 + b2 = c2.
Esempio:
|
Input |
Output |
|
[3, 1, 4, 6, 5] |
True |
|
[10, 4, 6, 12, 5] |
False |
Soluzione:
-
Eleva al quadrato tutti gli elementi dell'array.
-
Ordina l'array in ordine crescente.
-
Esegui due cicli. Il ciclo esterno parte dall'ultimo indice dell'array fino a 1, quello interno parte da (
outer_loop_index - 1) fino all'inizio. -
Crea un
set()per memorizzare gli elementi tra l'indice del ciclo esterno e quello del ciclo interno. -
Controlla se è presente un numero nel set uguale a
(array[outerLoopIndex] – array[innerLoopIndex]). Se sì, restituisciTrue, altrimentiFalse.
def checkTriplet(array):
n = len(array)
for i in range(n):
array[i] = array[i]**2
array.sort()
for i in range(n - 1, 1, -1):
s = set()
for j in range(i - 1, -1, -1):
if (array[i] - array[j]) in s:
return True
s.add(array[j])
return False
arr = [3, 2, 4, 6, 5]
checkTriplet(arr)
# True32. In quanti modi puoi fare il resto con monete e un importo totale?
Dobbiamo creare una funzione che prenda una lista di tagli di monete e un importo totale e restituisca il numero di modi in cui possiamo fare il resto.
Nell'esempio abbiamo fornito i tagli [1, 2, 5] e l'importo totale 5. In risposta otteniamo quattro modi per fare il resto.
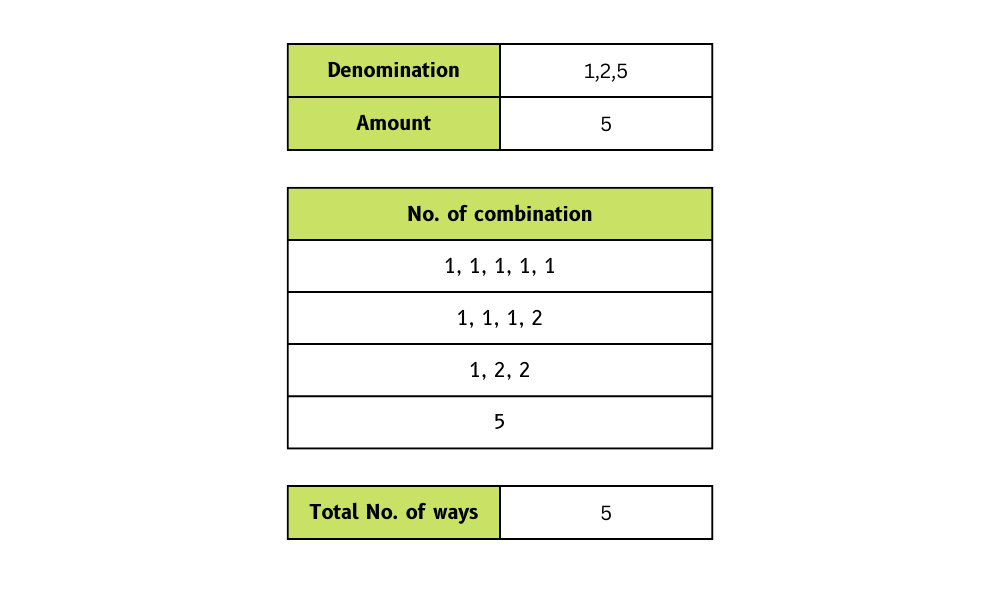
Immagine dell'autore
Soluzione:
- Creeremo una lista di dimensione
amount + 1. Lo spazio aggiuntivo serve per memorizzare la soluzione per importo zero. - Inizializziamo la lista delle soluzioni con
solution[0] = 1. - Eseguiamo due cicli. L'esterno itera sui tagli, l'interno va dal valore del taglio corrente fino a
amount + 1. - I risultati dei diversi tagli sono memorizzati nell'array solution.
solution[i] = solution[i] + solution[i - den].
Il processo viene ripetuto per tutti gli elementi nella lista dei tagli e all'ultimo elemento della lista solution avremo il nostro numero.
def solve_coin_change(denominations, amount):
solution = [0] * (amount + 1)
solution[0] = 1
for den in denominations:
for i in range(den, amount + 1):
solution[i] += solution[i - den]
return solution[amount]
denominations = [1, 2, 5]
amount = 5
solve_coin_change(denominations, amount)
# 4Domande da colloquio Python per Google
Come per le altre aziende citate, le domande in Google dipendono dal ruolo e dall'esperienza. Tuttavia, alcune domande comuni includono:
33. Definisci una funzione lambda, un iteratore e un generatore in Python.
La funzione lambda è anche nota come funzione anonima. Puoi aggiungere un qualsiasi numero di parametri ma con un'unica espressione.
Un iteratore è un oggetto che possiamo usare per iterare su oggetti iterabili come liste, dizionari, tuple e set.
Un generatore è una funzione simile a una funzione normale, ma genera valori usando la keyword yield invece di return. Se il corpo della funzione contiene yield, diventa automaticamente un generatore.
Leggi di più su iteratori e generatori in Python nel nostro tutorial completo.
34. Dato un array arr[], trova il massimo j – i tale che arr[j] > arr[i]
Questa domanda è piuttosto semplice ma richiede attenzione ai dettagli. Ci viene fornito un array di interi positivi. Dobbiamo trovare la differenza massima tra j - i dove array[j] > array[i].
Esempi:
- Input: [20, 70, 40, 50, 12, 38, 98], Output: 6 (j = 6, i = 0)
- Input: [10, 3, 2, 4, 5, 6, 7, 8, 18, 0], Output: 8 ( j = 8, i = 0)
Soluzione:
- Calcola la lunghezza dell'array e inizializza la differenza massima a -1.
- Esegui due cicli. Quello esterno seleziona elementi da sinistra, quello interno confronta gli elementi selezionati con quelli a partire da destra.
- Ferma il ciclo interno quando l'elemento è maggiore di quello selezionato e aggiorna la differenza massima con j - i.
def max_index_diff(array):
n = len(array)
max_diff = -1
for i in range(0, n):
j = n - 1
while(j > i):
if array[j] > array[i] and max_diff < (j - i):
max_diff = j - i
j -= 1
return max_diff
array_1 = [20,70,40,50,12,38,98]
max_index_diff(array_1)
# 635. Come useresti gli operatori ternari in Python?
Gli operatori ternari sono noti anche come espressioni condizionali. Sono operatori che valutano un'espressione in base a condizioni True e False.
Puoi scrivere espressioni condizionali in una sola riga invece di usare più righe di if-else. Ti permettono di scrivere codice pulito e compatto.
Ad esempio, possiamo convertire if-else annidati in una riga, come mostrato sotto.
Istruzione if-else
score = 75
if score < 70:
if score < 50:
print('Fail')
else:
print('Merit')
else:
print('Distinction')
# DistinctionOperatore ternario annidato
print('Fail' if score < 50 else 'Merit' if score < 70 else 'Distinction')
# Distinction36. Come implementeresti una LRU Cache in Python?
Python fornisce un decorator integrato functools.lru_cache per implementare una cache LRU (Least Recently Used). In alternativa, puoi crearne una manualmente usando OrderedDict di collections.
Esempio usando functools:
from functools import lru_cache
@lru_cache(maxsize=3)
def add(a, b):
return a + b
print(add(1, 2)) # Calculates and caches result
print(add(1, 2)) # Retrieves result from cacheDomande su AI e Machine Learning in Python
Con la rapida crescita dell'AI e dei large language model (LLM), i colloqui Python includono sempre più domande su concetti AI/ML moderni. Ecco le domande chiave su cui dovresti prepararti nel 2026.
37. Che cos'è un Large Language Model (LLM) e come lo useresti in Python?
Un Large Language Model (LLM) è un modello di deep learning addestrato su enormi dataset testuali per comprendere e generare testo simile a quello umano. LLM popolari includono GPT-5, Claude, Llama e Gemini. In Python puoi interagire con gli LLM tramite API o eseguirli in locale.
Esempio usando l'API di OpenAI:
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain Python decorators in simple terms."}
]
)
print(response.choices[0].message.content)Scopri di più nel nostro tutorial Come creare applicazioni LLM con LangChain.
38. Che cos'è il RAG (Retrieval-Augmented Generation) e perché è importante?
Il RAG combina sistemi di recupero con AI generativa per produrre risposte più accurate e fondate. Invece di affidarsi solo ai dati di training dell'LLM, RAG recupera documenti rilevanti da una base di conoscenza e li usa come contesto per la generazione.
Componenti chiave di un sistema RAG:
- Document Store: un database vettoriale (come Pinecone, Chroma o FAISS) che memorizza documenti embedded
- Retriever: trova documenti rilevanti in base alla similarità di query
- Generator: un LLM che produce risposte usando il contesto recuperato
Esempio di workflow RAG:
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Create vector store from documents
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
# Create RAG chain
llm = ChatOpenAI(model="gpt-4")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever()
)
# Query the system
result = qa_chain.invoke("What are Python best practices?")
print(result)Leggi la nostra guida su Come migliorare le prestazioni del RAG per tecniche avanzate.
39. Come gestisci async/await in Python per applicazioni AI?
La programmazione asincrona è essenziale per applicazioni AI che effettuano più chiamate API o gestiscono richieste concorrenti. Il modulo asyncio di Python abilita operazioni I/O non bloccanti.
Esempio: chiamate API LLM concorrenti:
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI()
async def get_completion(prompt: str) -> str:
response = await client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
async def process_multiple_prompts(prompts: list[str]) -> list[str]:
tasks = [get_completion(prompt) for prompt in prompts]
return await asyncio.gather(*tasks)
# Run concurrent requests
prompts = ["Explain Python lists", "Explain Python dicts", "Explain Python sets"]
results = asyncio.run(process_multiple_prompts(prompts))
for result in results:
print(result)Approfondisci con la nostra Guida alla programmazione asincrona in Python.
40. Cosa sono gli embedding e come vengono usati nel machine learning?
Gli embedding sono rappresentazioni vettoriali dense di dati (testo, immagini, ecc.) che catturano il significato semantico. Elementi simili hanno embedding simili, abilitando compiti come ricerca semantica, clustering e sistemi di raccomandazione.
Esempio: creare embedding di testo:
from sentence_transformers import SentenceTransformer
import numpy as np
# Load embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Create embeddings
sentences = [
"Python is a programming language",
"JavaScript is used for web development",
"Python is great for data science"
]
embeddings = model.encode(sentences)
# Calculate similarity
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Python sentences are more similar to each other
print(f"Similarity 0-2: {cosine_similarity(embeddings[0], embeddings[2]):.3f}") # Higher
print(f"Similarity 0-1: {cosine_similarity(embeddings[0], embeddings[1]):.3f}") # Lower41. Come costruiresti un agente AI in Python?
Gli agenti AI sono sistemi autonomi che possono percepire l'ambiente, prendere decisioni e agire per raggiungere obiettivi. Gli agenti moderni spesso combinano LLM con strumenti e memoria.
Componenti chiave di un agente AI:
- LLM Core: il motore di ragionamento che elabora input e decide le azioni
- Strumenti: funzioni che l'agente può chiamare (ricerca web, esecuzione di codice, API)
- Memoria: memoria a breve termine (conversazione) e a lungo termine (vector store)
- Pianificazione: suddivisione di compiti complessi in sotto-attività
Esempio con LangChain:
from langchain.agents import create_openai_functions_agent, AgentExecutor
from langchain.chat_models import ChatOpenAI
from langchain.tools import Tool
from langchain import hub
# Define tools
def search_database(query: str) -> str:
return f"Results for: {query}"
tools = [
Tool(
name="DatabaseSearch",
func=search_database,
description="Search the company database for information"
)
]
# Create agent
llm = ChatOpenAI(model="gpt-4")
prompt = hub.pull("hwchase17/openai-functions-agent")
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
# Run agent
result = agent_executor.invoke({"input": "Find sales data for Q4"})
print(result["output"])Scopri di più nel nostro tutorial Creare agenti LangChain per automatizzare compiti in Python.
Potenziare il tuo team con Python
Mentre la preparazione ai colloqui Python è essenziale per candidati e hiring manager, è altrettanto importante che le aziende investano in una formazione continua in Python per i propri team. In un'epoca in cui automazione, analisi dei dati e sviluppo software sono centrali, garantire che i tuoi dipendenti abbiano solide competenze in Python può essere un fattore trasformativo per il successo della tua azienda.
Se sei un team leader o un imprenditore e vuoi assicurarti che l'intero team sia competente in Python, DataCamp for Business offre programmi di formazione su misura che possono aiutare i tuoi dipendenti a padroneggiare le competenze Python, dalle basi ai concetti avanzati. Possiamo fornire:
- Percorsi di apprendimento mirati: personalizzabili in base al livello attuale del tuo team e alle esigenze specifiche del business.
- Pratica hands-on: progetti reali ed esercizi di coding che rafforzano l'apprendimento e migliorano la memorizzazione.
- Monitoraggio dei progressi: strumenti per monitorare e valutare i progressi del team, assicurando il raggiungimento degli obiettivi formativi.
Investire nel potenziamento delle competenze Python tramite piattaforme come DataCamp non solo migliora le capacità del tuo team, ma dà anche alla tua azienda un vantaggio strategico, permettendoti di innovare, restare competitivo e ottenere risultati concreti. Mettiti in contatto con il nostro team e richiedi una demo oggi.

