
Các câu hỏi phỏng vấn Python cơ bản
Đây là một số câu hỏi bạn có thể gặp trong một buổi phỏng vấn Python cấp độ đầu vào.
1. Python là gì, và liệt kê một số tính năng chính.
Python là một ngôn ngữ lập trình cấp cao, linh hoạt, nổi tiếng với cú pháp dễ đọc và phạm vi ứng dụng rộng. Dưới đây là một số tính năng chính của Python:
- Cú pháp đơn giản, dễ đọc: Cú pháp của Python rõ ràng và trực quan, giúp người mới dễ tiếp cận và người có kinh nghiệm làm việc hiệu quả.
- Ngôn ngữ thông dịch: Python thực thi mã từng dòng, hỗ trợ tốt cho gỡ lỗi và kiểm thử.
- Kiểu động: Python không yêu cầu khai báo kiểu dữ liệu tường minh, mang lại sự linh hoạt hơn.
- Thư viện và framework phong phú: Các thư viện như NumPy, Pandas và Django mở rộng chức năng của Python cho các tác vụ chuyên biệt trong khoa học dữ liệu, phát triển web, và hơn thế nữa.
- Tương thích đa nền tảng: Python có thể chạy trên nhiều hệ điều hành, gồm Windows, macOS và Linux.
2. Danh sách (list) và bộ (tuple) trong Python là gì?
List và tuple là các cấu trúc dữ liệu nền tảng trong Python với đặc điểm và trường hợp sử dụng khác nhau.
List:
- Có thể thay đổi (mutable): Phần tử có thể thay đổi sau khi tạo.
- Bộ nhớ: Tiêu tốn nhiều bộ nhớ hơn.
- Hiệu năng: Duyệt chậm hơn tuple nhưng tốt hơn cho thao tác chèn và xóa.
- Phương thức: Cung cấp nhiều phương thức dựng sẵn để thao tác.
Ví dụ:
a_list = ["Data", "Camp", "Tutorial"]
a_list.append("Session")
print(a_list) # Output: ['Data', 'Camp', 'Tutorial', 'Session']Tuple:
- Bất biến (immutable): Phần tử không thể thay đổi sau khi tạo.
- Bộ nhớ: Tiêu tốn ít bộ nhớ hơn.
- Hiệu năng: Duyệt nhanh hơn list nhưng thiếu linh hoạt như list.
- Phương thức: Ít phương thức dựng sẵn.
Ví dụ:
a_tuple = ("Data", "Camp", "Tutorial")
print(a_tuple) # Output: ('Data', 'Camp', 'Tutorial')Tìm hiểu thêm trong hướng dẫn Python Lists của chúng tôi.
3. __init__() trong Python là gì?
Phương thức __init__() được gọi là constructor trong thuật ngữ lập trình hướng đối tượng (OOP). Nó dùng để khởi tạo trạng thái của đối tượng khi được tạo. Phương thức này tự động được gọi khi một thể hiện mới của lớp được khởi tạo.
Mục đích:
- Gán giá trị cho các thuộc tính của đối tượng.
- Thực hiện các thao tác khởi tạo cần thiết.
Ví dụ:
Chúng ta tạo lớp book_shop và thêm constructor cùng hàm book(). Constructor sẽ lưu tiêu đề sách và hàm book() sẽ in tên sách.
Để kiểm thử, ta khởi tạo đối tượng b với “Sandman” và gọi hàm book().
class book_shop:
# constructor
def __init__(self, title):
self.title = title
# Sample method
def book(self):
print('The title of the book is', self.title)
b = book_shop('Sandman')
b.book()
# The title of the book is Sandman4. Sự khác biệt giữa kiểu dữ liệu mutable và immutable là gì?
Kiểu dữ liệu mutable:
- Định nghĩa: Có thể sửa đổi sau khi tạo.
- Ví dụ: List, Dictionary, Set.
- Đặc điểm: Có thể thêm, xóa, thay đổi phần tử.
- Trường hợp dùng: Phù hợp cho tập hợp cần cập nhật thường xuyên.
Ví dụ:
# List Example
a_list = [1, 2, 3]
a_list.append(4)
print(a_list) # Output: [1, 2, 3, 4]
# Dictionary Example
a_dict = {'a': 1, 'b': 2}
a_dict['c'] = 3
print(a_dict) # Output: {'a': 1, 'b': 2, 'c': 3}Kiểu dữ liệu immutable:
- Định nghĩa: Không thể sửa đổi sau khi tạo.
- Ví dụ: Numeric (int, float), String, Tuple.
- Đặc điểm: Phần tử không thể thay đổi; mọi thao tác “sửa” sẽ tạo đối tượng mới.
Ví dụ:
# Numeric Example
a_num = 10
a_num = 20 # Creates a new integer object
print(a_num) # Output: 20
# String Example
a_str = "hello"
a_str = "world" # Creates a new string object
print(a_str) # Output: world
# Tuple Example
a_tuple = (1, 2, 3)
# a_tuple[0] = 4 # This will raise a TypeError
print(a_tuple) # Output: (1, 2, 3)5. Giải thích list, dictionary và tuple comprehension kèm ví dụ.
List
List comprehension cung cấp cú pháp một dòng để tạo list mới dựa trên giá trị của list hiện có. Bạn có thể dùng vòng lặp for để làm tương tự, nhưng sẽ cần nhiều dòng và đôi khi trở nên phức tạp.
List comprehension giúp việc tạo list dựa trên iterable sẵn có trở nên dễ dàng.
my_list = [i for i in range(1, 10)]
my_list
# [1, 2, 3, 4, 5, 6, 7, 8, 9]Dictionary
Tương tự List comprehension, bạn có thể tạo dictionary dựa trên dữ liệu có sẵn chỉ với một dòng. Cần bao quanh phép tạo bằng dấu ngoặc nhọn {}.
# Creating a dictionary using dictionary comprehension
my_dict = {i: i**2 for i in range(1, 10)}
# Output the dictionary
my_dict
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}Tuple
Không giống list và dictionary, không có “tuple comprehension” riêng.
Khi bạn dùng dấu ngoặc đơn với comprehension, Python thực ra tạo biểu thức generator chứ không phải tuple. Để có tuple, bạn phải chuyển generator bằng tuple() hoặc định nghĩa tuple literal trực tiếp.
# Generator expression (not a tuple)
my_gen = (i for i in range(1, 10))
my_gen
# <generator object <genexpr> ...>
# Converting generator to tuple
my_tuple = tuple(i for i in range(1, 10))
my_tuple
# (1, 2, 3, 4, 5, 6, 7, 8, 9)
# Or simply define a tuple directly
literal_tuple = (1, 2, 3)
literal_tuple
# (1, 2, 3)
Bạn có thể tìm hiểu thêm trong hướng dẫn Python Tuples của chúng tôi.
6. Global Interpreter Lock (GIL) trong Python là gì và vì sao quan trọng?
Global Interpreter Lock (GIL) là một mutex trong CPython (bản triển khai tham chiếu của Python) đảm bảo chỉ một luồng gốc thực thi bytecode Python tại một thời điểm. Nó đơn giản hóa quản lý bộ nhớ bằng cách bảo vệ các cấu trúc dữ liệu nội bộ như bộ đếm tham chiếu, nhưng cũng hạn chế tính song song thực sự trong tác vụ nặng CPU, khiến multithreading kém hiệu quả cho tải tính toán. Tuy nhiên, nó hoạt động tốt với tác vụ I/O-bound, nơi luồng chờ mạng, tệp hoặc cơ sở dữ liệu.
Lưu ý: Python 3.13 giới thiệu bản dựng không GIL ở trạng thái thử nghiệm (PEP 703), và Python 3.14 bổ sung hỗ trợ free-threaded được tài liệu hóa. Một số extension C và thư viện có thể chưa tương thích đầy đủ.
Các câu hỏi phỏng vấn Python trung cấp
Dưới đây là một số câu hỏi bạn có thể gặp trong phỏng vấn Python cấp độ trung cấp.
7. Bạn có thể giải thích các thuật toán tìm kiếm và duyệt đồ thị phổ biến trong Python không?
Python có nhiều thuật toán mạnh mẽ cho tìm kiếm và duyệt đồ thị, mỗi loại xử lý cấu trúc dữ liệu và bài toán khác nhau. Dưới đây là giải thích:
- Tìm kiếm nhị phân (Binary Search): Nếu cần tìm nhanh một phần tử trong danh sách đã sắp xếp, tìm kiếm nhị phân là lựa chọn. Nó lặp lại việc chia đôi phạm vi tìm kiếm cho đến khi tìm thấy mục tiêu.
- Cây AVL: Cây AVL giữ cân bằng, rất có lợi nếu bạn thường xuyên chèn hoặc xóa phần tử trong cây. Cấu trúc cây tìm kiếm nhị phân tự cân bằng này đảm bảo tìm kiếm nhanh bằng cách ngăn cây bị lệch.
- Duyệt theo chiều rộng (BFS): BFS khám phá đồ thị theo từng lớp. Đặc biệt hữu ích để tìm đường đi ngắn nhất trong đồ thị không trọng số vì nó xét mọi khả năng từ mỗi nút trước khi đi sâu hơn.
- Duyệt theo chiều sâu (DFS): DFS đi theo một nhánh sâu nhất có thể trước khi quay lui. Tốt cho các tác vụ như giải mê cung hoặc duyệt cây.
- Thuật toán A*: A* nâng cao hơn, kết hợp ưu điểm của BFS và DFS bằng heuristic để tìm đường đi ngắn nhất hiệu quả. Thường dùng trong tìm đường trên bản đồ và trò chơi.
8. KeyError trong Python là gì và xử lý thế nào?
KeyError xảy ra khi bạn cố truy cập một khóa không tồn tại trong dictionary. Python kỳ vọng mọi khóa được tra cứu đều có trong dictionary, và khi không có, nó ném KeyError.
Ví dụ, nếu bạn có dictionary điểm của sinh viên và cố truy cập một sinh viên không có trong đó, bạn sẽ gặp KeyError. Để xử lý, bạn có vài cách:
-
Dùng phương thức .get(): Trả về
None(hoặc giá trị mặc định chỉ định) thay vì lỗi nếu khóa không tìm thấy. -
Dùng khối try-except: Bao mã trong
try-exceptđể bắtKeyErrorvà xử lý nhẹ nhàng. -
Kiểm tra khóa với in: Kiểm tra khóa có trong dictionary bằng
if key in dictionarytrước khi truy cập.
Để tìm hiểu thêm, đọc hướng dẫn đầy đủ: Ngoại lệ Python KeyError và cách khắc phục.
9. Python quản lý bộ nhớ như thế nào, và vai trò của garbage collection?
Python tự động cấp phát và giải phóng bộ nhớ bằng một heap riêng, nơi lưu mọi đối tượng và cấu trúc dữ liệu. Quá trình quản lý bộ nhớ do trình quản lý bộ nhớ của Python tối ưu hóa, còn garbage collector xử lý các đối tượng không dùng hoặc không được tham chiếu để giải phóng bộ nhớ.
Garbage collection trong Python dùng đếm tham chiếu và bộ gom vòng lặp (cyclic GC) để phát hiện và thu gom dữ liệu không dùng. Khi một đối tượng không còn tham chiếu, nó đủ điều kiện cho GC. Mô-đun gc cho phép tương tác trực tiếp với GC, cung cấp hàm bật/tắt và thu gom thủ công.
10. Sự khác biệt giữa shallow copy và deep copy trong Python, và khi nào dùng mỗi loại?
Trong Python, shallow và deep copy dùng để sao chép đối tượng, nhưng xử lý cấu trúc lồng nhau khác nhau.
-
Shallow Copy: Tạo đối tượng mới nhưng chèn tham chiếu tới các đối tượng bên trong của bản gốc. Nếu đối tượng gốc chứa đối tượng mutable (như list trong list), bản sao nông sẽ tham chiếu cùng đối tượng bên trong. Điều này có thể dẫn đến thay đổi ngoài ý muốn. Tạo bằng phương thức
copy()hoặccopy()của mô-đuncopy. -
Deep Copy: Tạo đối tượng mới và sao chép đệ quy mọi đối tượng bên trong. Cấu trúc lồng nhau cũng được nhân bản, nên thay đổi ở bản này không ảnh hưởng bản kia. Dùng
deepcopy()của mô-đuncopy.
Ví dụ sử dụng: Shallow copy phù hợp khi đối tượng chỉ chứa phần tử bất biến hoặc khi bạn muốn thay đổi trong cấu trúc lồng nhau phản ánh ở cả hai. Deep copy lý tưởng cho cấu trúc phức tạp, lồng nhau khi cần bản sao độc lập. Đọc Python Copy List: Những điều cần biết để biết thêm. Hướng dẫn có hẳn một phần về khác biệt shallow vs deep copy.
11. Bạn có thể dùng mô-đun collections của Python để đơn giản hóa các tác vụ phổ biến như thế nào?
Mô-đun collections cung cấp cấu trúc dữ liệu chuyên biệt như defaultdict, Counter, deque, và OrderedDict để đơn giản hóa nhiều tác vụ. Ví dụ, Counter lý tưởng để đếm phần tử trong iterable, còn defaultdict khởi tạo giá trị dictionary mà không cần kiểm tra tường minh.
Ví dụ:
from collections import Counter
data = ['a', 'b', 'c', 'a', 'b', 'a']
count = Counter(data)
print(count) # Output: Counter({'a': 3, 'b': 2, 'c': 1})Các câu hỏi phỏng vấn Python nâng cao
Những câu hỏi này dành cho người thực hành Python có kinh nghiệm hơn.
12. Monkey patching trong Python là gì?
Monkey patching trong Python là kỹ thuật động thay đổi hành vi của mã khi chạy. Nói ngắn gọn, bạn có thể sửa đổi một lớp hoặc mô-đun lúc runtime.
Ví dụ:
Hãy học monkey patching qua ví dụ.
-
Chúng ta tạo lớp
monkeyvới hàmpatch(). Cũng tạo hàmmonk_pbên ngoài lớp. -
Giờ ta thay
patchbằng hàmmonk_pbằng cách gánmonkey.patchchomonk_p. -
Cuối cùng, kiểm thử thay đổi bằng cách tạo đối tượng từ lớp
monkeyvà chạy hàmpatch().
Thay vì hiển thị patch() is being called, nó hiển thị monk_p() is being called.
class monkey:
def patch(self):
print ("patch() is being called")
def monk_p(self):
print ("monk_p() is being called")
# replacing address of "patch" with "monk_p"
monkey.patch = monk_p
obj = monkey()
obj.patch()
# monk_p() is being calledCẩn trọng: Chỉ dùng khi cần; monkey patching có thể làm mã khó đọc và gây bất ngờ cho người khác khi làm việc với mã hoặc bài kiểm thử của bạn.
13. Câu lệnh “with” trong Python được thiết kế cho mục đích gì?
Câu lệnh with dùng để xử lý ngoại lệ, giúp mã gọn gàng và đơn giản hơn. Thường được dùng để quản lý tài nguyên phổ biến như tạo, chỉnh sửa và lưu tệp.
Ví dụ:
Thay vì viết nhiều dòng open, try, finally và close, bạn có thể tạo và ghi tệp văn bản bằng with. Rất đơn giản.
# using with statement
with open('myfile.txt', 'w') as file:
file.write('DataCamp Black Friday Sale!!!')14. Tại sao dùng else trong cấu trúc try/except của Python?
try: và except: thường dùng để xử lý ngoại lệ, vậy else: hữu ích khi nào? else: sẽ được kích hoạt khi không có ngoại lệ xảy ra.
Ví dụ:
Tìm hiểu thêm về else: qua hai ví dụ.
-
Lần thử đầu, nhập
2là tử số vàdlà mẫu số. Sai nênexcept:được kích hoạt với “Invalid input!”. -
Lần thứ hai, nhập
2và1và nhận kết quả2. Không có ngoại lệ nênelse:in thông điệpDivision is successful.
try:
num1 = int(input('Enter Numerator: '))
num2 = int(input('Enter Denominator: '))
division = num1/num2
print(f'Result is: {division}')
except:
print('Invalid input!')
else:
print('Division is successful.')
## Try 1 ##
# Enter Numerator: 2
# Enter Denominator: d
# Invalid input!
## Try 2 ##
# Enter Numerator: 2
# Enter Denominator: 1
# Result is: 2.0
# Division is successful.Học lộ trình kỹ năng Python Fundamentals để có nền tảng trở thành lập trình viên Python.
15. Decorator trong Python là gì?
Decorators trong Python là mẫu thiết kế cho phép bạn bổ sung chức năng mới cho đối tượng hiện có mà không sửa cấu trúc của nó. Thường dùng để mở rộng hành vi của hàm hoặc phương thức. Bạn có thể đọc thêm về cách dùng decorators trong Python trong hướng dẫn riêng.
Ví dụ:
import functools
def my_decorator(func):
@functools.wraps(func) # preserves __name__, __doc__, etc.
def wrapper(*args, **kwargs):
print("Something is happening before the function is called.")
result = func(*args, **kwargs)
print("Something is happening after the function is called.")
return result
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
# Output:
# Something is happening before the function is called.
# Hello!
# Something is happening after the function is called.16. Context manager trong Python là gì và được triển khai như thế nào?
Context manager dùng để quản lý tài nguyên, đảm bảo được cấp phát và giải phóng đúng cách. Cách dùng phổ biến nhất là câu lệnh with.
Ví dụ:
class FileManager:
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
self.file = open(self.filename, self.mode)
return self.file
def __exit__(self, exc_type, exc_value, traceback):
self.file.close()
with FileManager('test.txt', 'w') as f:
f.write('Hello, world!')Trong ví dụ này, lớp FileManager là một context manager đảm bảo tệp được đóng đúng cách sau khi dùng trong khối with.
17. Metaclass trong Python là gì và khác gì lớp thông thường?
Metaclass là “lớp của các lớp”. Chúng định nghĩa cách các lớp hoạt động và được tạo ra. Trong khi lớp thông thường tạo đối tượng, metaclass tạo lớp. Bằng cách dùng metaclass, bạn có thể sửa định nghĩa lớp, áp quy tắc, hoặc thêm chức năng khi tạo lớp.
Ví dụ:
class Meta(type):
def __new__(cls, name, bases, dct):
print(f"Creating class {name}")
return super().__new__(cls, name, bases, dct)
class MyClass(metaclass=Meta):
pass
# Output: Creating class MyClassCác câu hỏi phỏng vấn Python cho Khoa học Dữ liệu
Dành cho những người tập trung nhiều hơn vào ứng dụng khoa học dữ liệu của Python, đây là một số câu hỏi bạn có thể gặp.
18. Ưu điểm của NumPy so với list Python thông thường là gì?
Có một số ưu điểm của NumPy so với list thông thường, như:
- Bộ nhớ: Mảng NumPy hiệu quả bộ nhớ hơn vì lưu phần tử cùng kiểu trong các khối liên tiếp. (Mức dùng bộ nhớ cụ thể phụ thuộc kiểu phần tử và hệ thống; bạn có thể kiểm tra bằng
sys.getsizeofhoặcarray.nbytes.) - Tốc độ: NumPy dùng hiện thực C tối ưu, nên thao tác trên mảng lớn nhanh hơn nhiều so với list.
- Đa dụng: NumPy hỗ trợ các phép vector hóa (ví dụ: cộng, nhân) và nhiều hàm toán học dựng sẵn mà list không có.
19. Sự khác nhau giữa merge, join và concatenate?
Merge
Gộp hai DataFrame (hoặc đối tượng series) bằng cột định danh duy nhất.
Cần hai DataFrame, một cột chung ở cả hai, và “cách” bạn muốn nối. Bạn có thể left, right, outer, inner, và cross join hai DataFrame. Mặc định là inner join.
pd.merge(df1, df2, how='outer', on='Id')Join
Join các DataFrame bằng chỉ mục (index) duy nhất. Nhận tham số tùy chọn on là tên cột hoặc nhiều cột. Mặc định, join thực hiện left join.
df1.join(df2)Concatenate
Concatenate nối hai hoặc nhiều DataFrame theo một trục (hàng hoặc cột). Không cần tham số on.
pd.concat(df1,df2)- join(): kết hợp hai DataFrame theo index.
- merge(): kết hợp hai DataFrame theo cột bạn chỉ định.
- concat(): kết hợp hai hoặc nhiều DataFrame theo chiều dọc hoặc ngang.
20. Bạn xác định và xử lý giá trị thiếu như thế nào?
Xác định giá trị thiếu
Có thể xác định giá trị thiếu trong DataFrame bằng hàm isnull() rồi áp dụng sum(). isnull() trả về giá trị boolean, và sum cho biết số lượng giá trị thiếu ở mỗi cột.
Trong ví dụ, chúng ta tạo dictionary các list và chuyển thành pandas DataFrame. Sau đó dùng isnull().sum() để lấy số lượng giá trị thiếu ở từng cột.
import pandas as pd
import numpy as np
# dictionary of lists
dict = {'id':[1, 4, np.nan, 9],
'Age': [30, 45, np.nan, np.nan],
'Score':[np.nan, 140, 180, 198]}
# creating a DataFrame
df = pd.DataFrame(dict)
df.isnull().sum()
# id 1
# Age 2
# Score 1Xử lý giá trị thiếu
Có nhiều cách xử lý giá trị thiếu trong Python.
-
Xóa toàn bộ hàng hoặc cột nếu chứa giá trị thiếu bằng
dropna(). Không khuyến nghị vì có thể mất dữ liệu quan trọng. -
Điền giá trị thiếu bằng hằng số, trung bình, bfill, ffill bằng hàm
fillna(). -
Thay giá trị thiếu bằng chuỗi, số nguyên, hoặc số thực bằng hàm
replace(). -
Điền giá trị thiếu bằng phương pháp nội suy (interpolation).
Lưu ý: hãy làm việc với tập dữ liệu lớn khi dùng dropna().
# drop missing values
df.dropna(axis = 0, how ='any')
#fillna
df.fillna(method ='bfill')
#replace null values with -999
df.replace(to_replace = np.nan, value = -999)
# Interpolate
df.interpolate(method ='linear', limit_direction ='forward')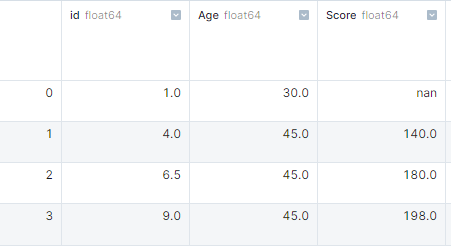
Trở thành nhà khoa học dữ liệu chuyên nghiệp với lộ trình nghề nghiệp Associate Data Scientist in Python. Bao gồm 25 khóa học và sáu dự án giúp bạn học vững nền tảng khoa học dữ liệu với các thư viện Python.
21. Bạn đã dùng những thư viện Python nào cho trực quan hóa?
Trực quan hóa dữ liệu là phần quan trọng nhất của phân tích dữ liệu. Bạn sẽ thấy dữ liệu vận hành và phát hiện mẫu ẩn.
Những thư viện trực quan hóa dữ liệu Python phổ biến nhất là:
- Matplotlib
- Seaborn
- Plotly
- Bokeh
Trong Python, chúng ta thường dùng Matplotlib và seaborn để hiển thị mọi loại biểu đồ. Chỉ với vài dòng mã, bạn có thể vẽ scatter, line, box, bar chart, và nhiều hơn.
Với ứng dụng tương tác và phức tạp hơn, ta dùng Plotly. Bạn có thể tạo đồ thị màu sắc, tương tác cao chỉ với vài dòng mã. Có thể phóng to, áp dụng animation, và thêm các điều khiển. Plotly cung cấp hơn 40 loại biểu đồ độc đáo và còn có thể dùng để tạo web app hay dashboard.
Bokeh dùng cho đồ họa chi tiết với mức tương tác cao trên tập dữ liệu lớn.
22. Bạn sẽ chuẩn hóa hoặc tiêu chuẩn hóa một tập dữ liệu trong Python như thế nào?
Chuẩn hóa (normalization) đưa dữ liệu về một khoảng cụ thể, thường [0, 1], còn tiêu chuẩn hóa (standardization) biến đổi dữ liệu có trung bình 0 và độ lệch chuẩn 1. Cả hai kỹ thuật đều thiết yếu để chuẩn bị dữ liệu cho mô hình học máy.
Ví dụ:
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import numpy as np
data = np.array([[1, 2], [3, 4], [5, 6]])
# Normalize
normalizer = MinMaxScaler()
normalized = normalizer.fit_transform(data)
print(normalized)
# Standardize
scaler = StandardScaler()
standardized = scaler.fit_transform(data)
print(standardized)Các câu hỏi mã hóa Python
Nếu bạn sắp có phỏng vấn mã hóa Python, chuẩn bị các câu hỏi tương tự dưới đây có thể giúp gây ấn tượng với người phỏng vấn.
23. Làm sao thay khoảng trắng trong chuỗi bằng một ký tự cho trước trong Python?
Đây là thử thách thao tác chuỗi đơn giản. Bạn cần thay khoảng trắng bằng ký tự chỉ định.
Ví dụ 1: Người dùng đưa chuỗi l vey u và ký tự o, đầu ra sẽ là loveyou.
Ví dụ 2: Người dùng đưa chuỗi D t C mpBl ckFrid yS le và ký tự a, đầu ra sẽ là DataCampBlackFridaySale.
Cách đơn giản nhất là dùng phương thức dựng sẵn str.replace() để thay trực tiếp khoảng trắng bằng ký tự cho trước.
def str_replace(text, ch):
return text.replace(" ", ch)
text = "D t C mpBl ckFrid yS le"
ch = "a"
str_replace(text, ch)
# 'DataCampBlackFridaySale'
24. Cho số nguyên dương num, viết hàm trả về True nếu num là số chính phương, ngược lại False.
Bài này có lời giải khá trực tiếp. Bạn có thể kiểm tra số có căn bậc hai nguyên hay không bằng cách:
- Dùng
math.isqrt(num)để lấy căn bậc hai nguyên chính xác. - Bình phương nó và kiểm tra bằng số ban đầu.
- Trả về kết quả dưới dạng boolean.
Kiểm thử 1
Ta đưa số 10 vào hàm valid_square():
- Lấy căn bậc hai nguyên của số, được 3.
- Bình phương 3, được 9.
- 9 không bằng số ban đầu, hàm trả về False.
Kiểm thử 2
Ta đưa số 36 vào hàm valid_square():
- Lấy căn bậc hai nguyên, được 6.
- Bình phương 6, được 36.
- 36 bằng số ban đầu, hàm trả về True.
import math
def valid_square(num):
if num < 0:
return False
square = math.isqrt(num)
return square * square == num
valid_square(10)
# False
valid_square(36)
# True25. Cho số nguyên n, trả về số lượng số 0 tận cùng trong n giai thừa n!
Để vượt qua thử thách, bạn phải tính giai thừa n (n!) rồi tính số lượng số 0 tận cùng.
Tính giai thừa
Bước đầu, dùng vòng lặp while để lặp qua n giai thừa và dừng khi n bằng 1.
Tính số 0 tận cùng
Bước hai, ta tính số 0 tận cùng, không phải tổng số số 0. Có sự khác biệt lớn.
7! = 5040Giai thừa bảy có tổng hai số 0 và chỉ một số 0 tận cùng, nên lời giải nên trả về 1.
- Chuyển số giai thừa thành chuỗi.
- Đọc ngược và áp dụng vòng lặp.
- Nếu ký tự là 0, cộng +1 vào kết quả, ngược lại thoát vòng lặp.
- Trả về kết quả.
Lời giải trang nhã nhưng cần chú ý chi tiết.
def factorial_trailing_zeros(n):
fact = n
while n > 1:
fact *= n - 1
n -= 1
result = 0
for i in str(fact)[::-1]:
if i == "0":
result += 1
else:
break
return result
factorial_trailing_zeros(10)
# 2
factorial_trailing_zeros(18)
# 3Học khóa luyện tập câu hỏi phỏng vấn mã hóa thiết yếu để chuẩn bị cho phỏng vấn mã hóa Python tiếp theo của bạn.
26. Chuỗi có thể được tách thành các từ trong từ điển không?
Bạn được cung cấp một chuỗi dài và một từ điển từ. Bạn cần xác định chuỗi đầu vào có thể được phân đoạn thành các từ dùng từ điển hay không.
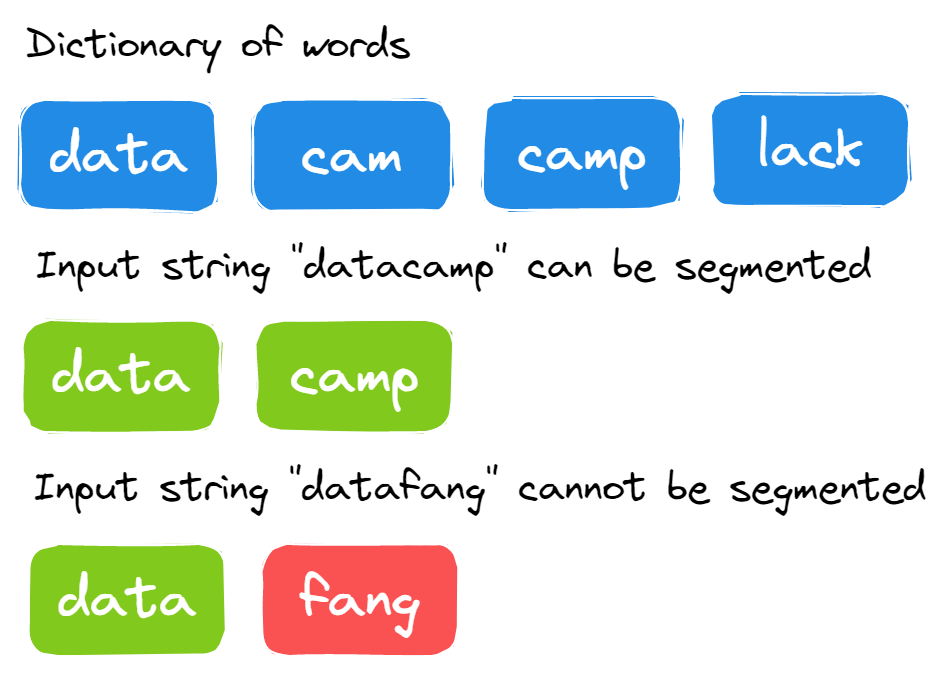
Hình minh họa của Tác giả
Lời giải khá trực tiếp. Bạn cần phân đoạn chuỗi lớn tại mỗi điểm và kiểm tra xem chuỗi có thể tách thành các từ trong từ điển không.
- Chạy vòng lặp theo độ dài chuỗi lớn.
- Tạo hai chuỗi con.
- Chuỗi con thứ nhất kiểm tra mỗi điểm từ
s[0:i]. - Nếu chuỗi con thứ nhất không có trong từ điển, trả về False.
- Nếu có, tạo chuỗi con thứ hai bằng
s[i:]. - Nếu chuỗi con thứ hai có trong từ điển hoặc có độ dài bằng 0, trả về True. Gọi đệ quy
can_segment_str()với chuỗi con thứ hai và trả về True nếu có thể phân đoạn. - Để hiệu quả với chuỗi dài, thêm memoization để không tính lại các chuỗi con nhiều lần.
def can_segment_str(s, dictionary, memo=None):
if memo is None:
memo = {}
if s in memo:
return memo[s]
if not s:
return True
for i in range(1, len(s) + 1):
first_str = s[0:i]
if first_str in dictionary:
second_str = s[i:]
if (
not second_str
or second_str in dictionary
or can_segment_str(second_str, dictionary, memo)
):
memo[s] = True
return True
memo[s] = False
return False
s = "datacamp"
dictionary = ["data", "camp", "cam", "lack"]
can_segment_str(s, dictionary)
# True27. Bạn có thể loại bỏ phần tử trùng lặp khỏi một mảng đã sắp xếp không?
Cho một mảng số nguyên đã sắp xếp tăng dần, loại bỏ phần tử trùng để mỗi phần tử duy nhất chỉ xuất hiện một lần. Do list Python không đổi độ dài tại chỗ cho bài này, hãy đặt kết quả vào k vị trí đầu của cùng mảng và trả về k (độ dài mới). Chỉ k phần tử đầu hợp lệ sau lời gọi; phần tử sau k là cũ.
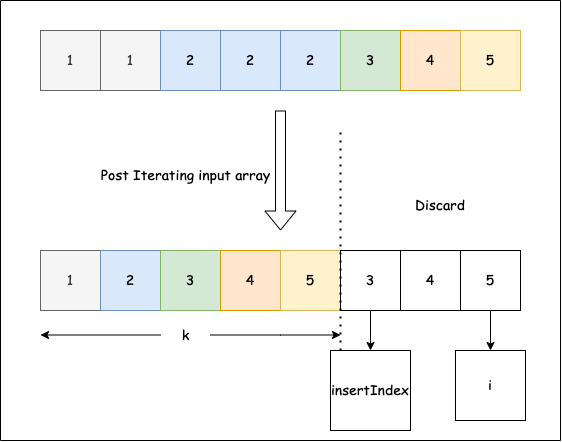
Hình từ LeetCode
Ví dụ 1: mảng đầu vào [1,1,2,2], hàm nên trả về 2.
Ví dụ 2: mảng đầu vào [1,1,2,3,3], hàm nên trả về 3.
Lời giải:
- Chạy vòng lặp từ chỉ số 1 đến hết. So sánh phần tử hiện tại với phần tử duy nhất trước đó; khi khác nhau, ghi vào vị trí
insertIndexvà tănginsertIndex. Trả vềinsertIndex. - Trả về
insertIndexvì đó là k.
Câu hỏi khá trực tiếp khi bạn hiểu đề. Dành thời gian hiểu kỹ, bạn sẽ dễ dàng đưa ra lời giải.
def removeDuplicates(array):
size = len(array)
if size == 0:
return 0
insertIndex = 1
for i in range(1, size):
if array[i - 1] != array[i]:
array[insertIndex] = array[i]
insertIndex += 1
return insertIndex
array_1 = [1, 2, 2, 3, 3, 4]
k1 = removeDuplicates(array_1)
# 4; array_1[:k1] -> [1, 2, 3, 4]
array_2 = [1, 1, 3, 4, 5, 6, 6]
k2 = removeDuplicates(array_2)
# 5; array_2[:k2] -> [1, 3, 4, 5, 6]
28. Bạn có thể tìm số còn thiếu trong mảng không?
Bạn được cung cấp danh sách số nguyên dương từ 1 đến n. Tất cả số từ 1 đến n đều có trừ x, và bạn phải tìm x.
Ví dụ:
|
4 |
5 |
3 |
2 |
8 |
1 |
6 |
- n = 8
- số còn thiếu = 7
Câu hỏi này là một bài toán toán học đơn giản.
- Tính tổng tất cả phần tử trong danh sách.
- Dùng công thức tổng cấp số cộng, ta tìm tổng kỳ vọng của n số đầu.
- Trả về hiệu giữa tổng kỳ vọng và tổng phần tử.
def find_missing(input_list):
sum_of_elements = sum(input_list)
# There is exactly 1 number missing
n = len(input_list) + 1
actual_sum = (n * ( n + 1 ) ) / 2
return int(actual_sum - sum_of_elements)
list_1 = [1,5,6,3,4]
find_missing(list_1)
# 229. Viết hàm Python xác định một chuỗi có phải palindrome hay không.
Một chuỗi là palindrome nếu đọc xuôi và ngược như nhau.
Ví dụ:
def is_palindrome(s):
s = ''.join(e for e in s if e.isalnum()).lower() # Remove non-alphanumeric and convert to lowercase
return s == s[::-1]
print(is_palindrome("A man, a plan, a canal: Panama")) # Output: True
print(is_palindrome("hello")) # Output: FalseCác câu hỏi phỏng vấn Python cho Facebook, Amazon, Apple, Netflix và Google
Bên dưới, chúng tôi chọn ra một số câu hỏi bạn có thể gặp ở các vị trí được săn đón nhất trong ngành, như tại Meta, Amazon, Google, v.v.
Câu hỏi phỏng vấn Python tại Facebook/Meta
Các câu hỏi bạn gặp tại Meta phụ thuộc nhiều vào vai trò. Tuy vậy, bạn có thể kỳ vọng một số câu sau:
30. Bạn có thể tìm lợi nhuận bán một lần tối đa không?
Bạn được cung cấp danh sách giá cổ phiếu và cần trả về giá mua và bán để có lợi nhuận cao nhất.
Lưu ý: Ta phải tối đa hóa lợi nhuận từ một lần mua/bán, và nếu không thể có lợi, ta cần giảm lỗ.
Ví dụ 1: stock_price = [8, 4, 12, 9, 20, 1], buy = 4, sell = 20. Tối đa hóa lợi nhuận.
Ví dụ 2: stock_price = [8, 6, 5, 4, 3, 2, 1], buy = 6, sell = 5. Giảm thiểu lỗ.
Lời giải:
- Tính lợi nhuận toàn cục bằng cách lấy global sell (phần tử đầu) trừ current buy (phần tử thứ hai).
- Chạy vòng lặp từ 1 đến độ dài danh sách.
- Trong vòng lặp, tính lợi nhuận hiện tại từ phần tử danh sách và current buy.
- Nếu lợi nhuận hiện tại lớn hơn toàn cục, cập nhật lợi nhuận toàn cục và global sell bằng phần tử thứ i.
- Nếu current buy lớn hơn phần tử hiện tại, cập nhật current buy bằng phần tử hiện tại.
- Cuối cùng trả về giá mua và bán toàn cục. Để có giá mua, lấy global sell trừ global profit.
Câu hỏi hơi đánh đố, và bạn có thể nghĩ ra thuật toán riêng để giải.
def buy_sell_stock_prices(stock_prices):
current_buy = stock_prices[0]
global_sell = stock_prices[1]
global_profit = global_sell - current_buy
for i in range(1, len(stock_prices)):
current_profit = stock_prices[i] - current_buy
if current_profit > global_profit:
global_profit = current_profit
global_sell = stock_prices[i]
if current_buy > stock_prices[i]:
current_buy = stock_prices[i]
return global_sell - global_profit, global_sell
stock_prices_1 = [10,9,16,17,19,23]
buy_sell_stock_prices(stock_prices_1)
# (9, 23)
stock_prices_2 = [8, 6, 5, 4, 3, 2, 1]
buy_sell_stock_prices(stock_prices_2)
# (6, 5)Câu hỏi phỏng vấn Python tại Amazon
Câu hỏi tại Amazon rất đa dạng nhưng có thể gồm:
31. Bạn có thể tìm bộ ba Pythagoras trong một mảng không?
Viết hàm trả về True nếu tồn tại bộ ba Pythagoras thỏa mãn a2 + b2 = c2.
Ví dụ:
|
Input |
Output |
|
[3, 1, 4, 6, 5] |
True |
|
[10, 4, 6, 12, 5] |
False |
Lời giải:
-
Bình phương tất cả phần tử trong mảng.
-
Sắp xếp mảng tăng dần.
-
Chạy hai vòng lặp. Vòng ngoài từ chỉ số cuối về 1, vòng trong từ (
outer_loop_index - 1) về đầu. -
Tạo
set()để lưu phần tử giữa chỉ số vòng ngoài và vòng trong. -
Kiểm tra có số nào trong set bằng
(array[outerLoopIndex] – array[innerLoopIndex])không. Nếu có, trả vềTrue, ngược lạiFalse.
def checkTriplet(array):
n = len(array)
for i in range(n):
array[i] = array[i]**2
array.sort()
for i in range(n - 1, 1, -1):
s = set()
for j in range(i - 1, -1, -1):
if (array[i] - array[j]) in s:
return True
s.add(array[j])
return False
arr = [3, 2, 4, 6, 5]
checkTriplet(arr)
# True32. Có bao nhiêu cách để đổi tiền với các đồng xu và tổng tiền cho trước?
Ta cần tạo hàm nhận danh sách mệnh giá xu và tổng tiền, rồi trả về số cách có thể đổi tiền.
Trong ví dụ, chúng ta có mệnh giá [1, 2, 5] và tổng tiền 5. Kết quả là bốn cách đổi.
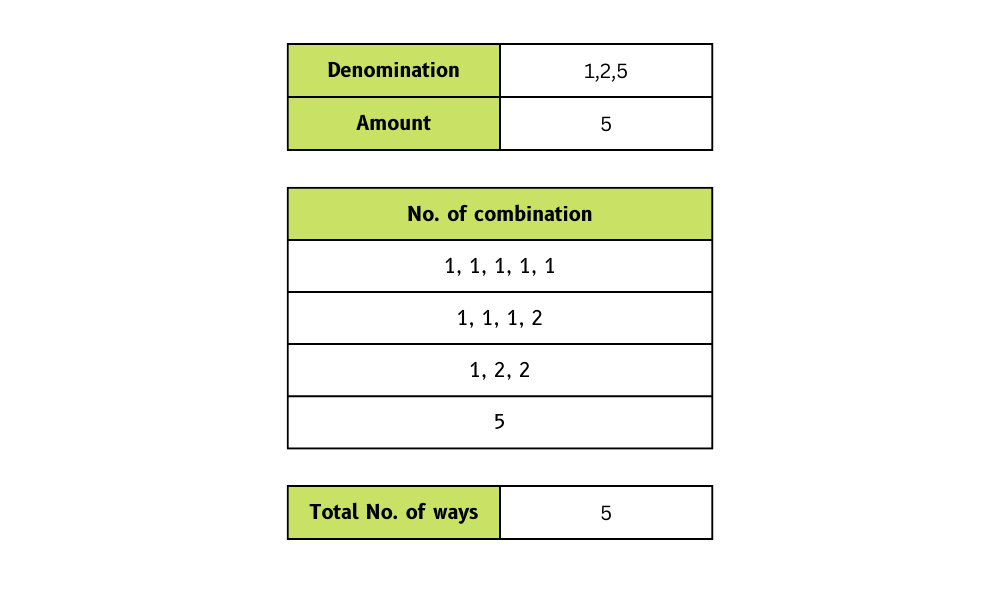
Hình minh họa của Tác giả
Lời giải:
- Tạo list kích thước
amount + 1. Thêm một phần tử để lưu lời giải cho tổng bằng 0. - Khởi tạo danh sách lời giải với
solution[0] = 1. - Chạy hai vòng lặp. Vòng ngoài lặp qua mệnh giá, vòng trong chạy từ giá trị mệnh giá hiện tại đến
amount + 1. - Kết quả của các mệnh giá khác nhau được lưu trong mảng solution:
solution[i] = solution[i] + solution[i - den].
Quy trình lặp lại cho mọi mệnh giá; ở phần tử cuối của danh sách solution, chúng ta có kết quả.
def solve_coin_change(denominations, amount):
solution = [0] * (amount + 1)
solution[0] = 1
for den in denominations:
for i in range(den, amount + 1):
solution[i] += solution[i - den]
return solution[amount]
denominations = [1, 2, 5]
amount = 5
solve_coin_change(denominations, amount)
# 4Câu hỏi phỏng vấn Python tại Google
Giống các công ty khác, câu hỏi Python tại Google phụ thuộc vai trò và kinh nghiệm. Tuy nhiên, một số câu thường gặp gồm:
33. Định nghĩa hàm lambda, iterator và generator trong Python.
Hàm Lambda còn gọi là hàm ẩn danh. Bạn có thể thêm bất kỳ số lượng tham số, nhưng chỉ có một biểu thức.
Iterator là đối tượng dùng để lặp qua các đối tượng có thể lặp như list, dictionary, tuple và set.
Generator là hàm tương tự hàm bình thường, nhưng tạo giá trị bằng từ khóa yield thay vì return. Nếu thân hàm có yield, nó tự động trở thành generator.
Đọc thêm về iterator và generator trong Python trong hướng dẫn đầy đủ.
34. Cho mảng arr[], tìm giá trị lớn nhất của j – i sao cho arr[j] > arr[i]
Câu hỏi khá trực tiếp nhưng cần chú ý chi tiết. Ta có mảng số nguyên dương, cần tìm chênh lệch lớn nhất j - i với điều kiện array[j] > array[i].
Ví dụ:
- Input: [20, 70, 40, 50, 12, 38, 98], Output: 6 (j = 6, i = 0)
- Input: [10, 3, 2, 4, 5, 6, 7, 8, 18, 0], Output: 8 ( j = 8, i = 0)
Lời giải:
- Tính độ dài mảng và khởi tạo chênh lệch max = -1.
- Chạy hai vòng lặp. Vòng ngoài chọn phần tử từ trái, vòng trong so sánh phần tử chọn với các phần tử từ phải.
- Dừng vòng trong khi phần tử bên phải lớn hơn phần tử chọn và liên tục cập nhật chênh lệch lớn nhất bằng j - i.
def max_index_diff(array):
n = len(array)
max_diff = -1
for i in range(0, n):
j = n - 1
while(j > i):
if array[j] > array[i] and max_diff < (j - i):
max_diff = j - i
j -= 1
return max_diff
array_1 = [20,70,40,50,12,38,98]
max_index_diff(array_1)
# 635. Bạn sẽ dùng toán tử ba ngôi (ternary) trong Python như thế nào?
Toán tử ba ngôi còn gọi là biểu thức điều kiện. Chúng đánh giá biểu thức dựa trên điều kiện Đúng/Sai.
Bạn có thể viết biểu thức điều kiện trong một dòng thay vì nhiều dòng if-else, giúp mã gọn và sạch.
Ví dụ, ta có thể chuyển if-else lồng nhau thành một dòng như sau.
Câu lệnh If-else
score = 75
if score < 70:
if score < 50:
print('Fail')
else:
print('Merit')
else:
print('Distinction')
# DistinctionToán tử ba ngôi lồng nhau
print('Fail' if score < 50 else 'Merit' if score < 70 else 'Distinction')
# Distinction36. Bạn sẽ triển khai LRU Cache trong Python như thế nào?
Python cung cấp decorator functools.lru_cache tích hợp để triển khai LRU (Least Recently Used) cache. Hoặc bạn có thể tự tạo bằng OrderedDict trong collections.
Ví dụ dùng functools:
from functools import lru_cache
@lru_cache(maxsize=3)
def add(a, b):
return a + b
print(add(1, 2)) # Calculates and caches result
print(add(1, 2)) # Retrieves result from cacheCác câu hỏi phỏng vấn Python về AI và Machine Learning
Với sự phát triển nhanh của AI và các mô hình ngôn ngữ lớn (LLM), phỏng vấn Python ngày càng bao gồm các câu hỏi về AI/ML hiện đại. Dưới đây là các câu hỏi bạn nên chuẩn bị cho năm 2026.
37. Mô hình ngôn ngữ lớn (LLM) là gì và bạn sẽ dùng thế nào trong Python?
LLM là mô hình học sâu được huấn luyện trên tập dữ liệu văn bản khổng lồ để hiểu và sinh văn bản giống con người. Các LLM phổ biến gồm GPT-5, Claude, Llama và Gemini. Trong Python, bạn có thể tương tác với LLM qua API hoặc chạy cục bộ.
Ví dụ dùng API của OpenAI:
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain Python decorators in simple terms."}
]
)
print(response.choices[0].message.content)Tìm hiểu thêm trong hướng dẫn Cách xây dựng ứng dụng LLM với LangChain.
38. RAG (Retrieval-Augmented Generation) là gì và tại sao quan trọng?
RAG kết hợp hệ thống truy xuất với AI sinh để tạo câu trả lời chính xác và có căn cứ hơn. Thay vì chỉ dựa vào dữ liệu huấn luyện của LLM, RAG truy xuất tài liệu liên quan từ kho tri thức và dùng làm ngữ cảnh cho việc sinh.
Thành phần chính của hệ thống RAG:
- Kho tài liệu: Cơ sở dữ liệu vector (như Pinecone, Chroma, hoặc FAISS) lưu trữ tài liệu đã embedding
- Retriever: Tìm tài liệu liên quan dựa trên độ tương đồng truy vấn
- Generator: LLM tạo phản hồi sử dụng ngữ cảnh đã truy xuất
Ví dụ quy trình RAG:
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Create vector store from documents
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
# Create RAG chain
llm = ChatOpenAI(model="gpt-4")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever()
)
# Query the system
result = qa_chain.invoke("What are Python best practices?")
print(result)Đọc hướng dẫn Cách cải thiện hiệu suất RAG để biết kỹ thuật nâng cao.
39. Bạn xử lý async/await trong Python cho ứng dụng AI như thế nào?
Lập trình bất đồng bộ rất quan trọng cho ứng dụng AI thực hiện nhiều cuộc gọi API hoặc xử lý yêu cầu đồng thời. Mô-đun asyncio của Python cho phép I/O không chặn.
Ví dụ: Gọi API LLM đồng thời:
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI()
async def get_completion(prompt: str) -> str:
response = await client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
async def process_multiple_prompts(prompts: list[str]) -> list[str]:
tasks = [get_completion(prompt) for prompt in prompts]
return await asyncio.gather(*tasks)
# Run concurrent requests
prompts = ["Explain Python lists", "Explain Python dicts", "Explain Python sets"]
results = asyncio.run(process_multiple_prompts(prompts))
for result in results:
print(result)Tìm hiểu sâu hơn với Hướng dẫn lập trình bất đồng bộ Python.
40. Embedding là gì và được dùng thế nào trong máy học?
Embedding là các vector đặc trưng dày đặc biểu diễn dữ liệu (văn bản, hình ảnh, v.v.) và nắm bắt ý nghĩa ngữ nghĩa. Mục tương tự có embedding tương tự, cho phép thực hiện tìm kiếm ngữ nghĩa, phân cụm và hệ gợi ý.
Ví dụ: Tạo text embeddings:
from sentence_transformers import SentenceTransformer
import numpy as np
# Load embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Create embeddings
sentences = [
"Python is a programming language",
"JavaScript is used for web development",
"Python is great for data science"
]
embeddings = model.encode(sentences)
# Calculate similarity
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Python sentences are more similar to each other
print(f"Similarity 0-2: {cosine_similarity(embeddings[0], embeddings[2]):.3f}") # Higher
print(f"Similarity 0-1: {cosine_similarity(embeddings[0], embeddings[1]):.3f}") # Lower41. Bạn sẽ xây dựng một agent AI trong Python như thế nào?
Agent AI là hệ thống tự động có thể cảm nhận môi trường, ra quyết định và hành động để đạt mục tiêu. Agent hiện đại thường kết hợp LLM với công cụ và bộ nhớ.
Thành phần chính của agent AI:
- LLM Core: Động cơ lập luận xử lý đầu vào và quyết định hành động
- Tools: Các hàm mà agent có thể gọi (tìm kiếm web, thực thi mã, API)
- Memory: Bộ nhớ ngắn hạn (hội thoại) và dài hạn (vector store)
- Planning: Phân rã nhiệm vụ phức tạp thành các tiểu nhiệm vụ
Ví dụ dùng LangChain:
from langchain.agents import create_openai_functions_agent, AgentExecutor
from langchain.chat_models import ChatOpenAI
from langchain.tools import Tool
from langchain import hub
# Define tools
def search_database(query: str) -> str:
return f"Results for: {query}"
tools = [
Tool(
name="DatabaseSearch",
func=search_database,
description="Search the company database for information"
)
]
# Create agent
llm = ChatOpenAI(model="gpt-4")
prompt = hub.pull("hwchase17/openai-functions-agent")
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
# Run agent
result = agent_executor.invoke({"input": "Find sales data for Q4"})
print(result["output"])Tìm hiểu thêm trong hướng dẫn Xây dựng LangChain Agents để tự động hóa tác vụ trong Python.
Nâng cao kỹ năng Python cho đội ngũ của bạn
Trong khi chuẩn bị phỏng vấn Python là điều thiết yếu với ứng viên và nhà tuyển dụng, các doanh nghiệp cũng cần đầu tư vào đào tạo Python liên tục cho đội ngũ. Trong kỷ nguyên mà tự động hóa, phân tích dữ liệu và phát triển phần mềm là trụ cột, đảm bảo nhân viên có kỹ năng Python vững vàng có thể tạo ra khác biệt cho thành công của công ty bạn.
Nếu bạn là lãnh đạo nhóm hoặc chủ doanh nghiệp muốn đảm bảo cả đội thông thạo Python, DataCamp for Business cung cấp các chương trình đào tạo phù hợp giúp nhân viên làm chủ kỹ năng Python, từ cơ bản đến nâng cao. Chúng tôi có thể cung cấp:
- Lộ trình học tập mục tiêu: Tùy biến theo trình độ hiện tại và nhu cầu kinh doanh cụ thể của đội bạn.
- Thực hành trực tiếp: Dự án thực tế và bài tập mã hóa củng cố kiến thức và tăng khả năng ghi nhớ.
- Theo dõi tiến độ: Công cụ giám sát và đánh giá tiến trình của đội, đảm bảo đạt mục tiêu học tập.
Đầu tư nâng cao kỹ năng Python qua các nền tảng như DataCamp không chỉ tăng năng lực cho đội ngũ mà còn mang lại lợi thế chiến lược cho doanh nghiệp, giúp bạn đổi mới, cạnh tranh và tạo ra kết quả hiệu quả. Kết nối với đội ngũ chúng tôi và yêu cầu bản demo ngay hôm nay.