
Obtén una Certificación Top Data
Preguntas básicas sobre Python para entrevistas de trabajo
Estas son algunas de las preguntas que te pueden hacer en una entrevista de trabajo para principiantes en Python.
1. ¿Qué es Python? Enumera algunas de sus características principales.
Python es un lenguaje de programación versátil y de alto nivel conocido por su sintaxis fácil de leer y sus amplias aplicaciones. Estas son algunas de las características principales de Python:
- Sintaxis sencilla y legible: La sintaxis de Python es clara y sencilla, lo que lo hace accesible para principiantes y eficiente para programadores experimentados.
- Idioma interpretado: Python ejecuta el código línea por línea, lo que facilita la depuración y las pruebas.
- Tipado dinámico: Python no requiere declaraciones explícitas de tipos de datos, lo que permite una mayor flexibilidad.
- Amplias bibliotecas y marcos: Bibliotecas como NumPy, Pandas y Django amplían la funcionalidad de Python para tareas especializadas en ciencia de datos, desarrollo web y mucho más.
- Compatibilidad entre plataformas: Python puede ejecutarse en diferentes sistemas operativos, incluidos Windows, macOS y Linux.
2. ¿Qué son las listas y tuplas de Python?
Las listas y las tuplas son estructuras de datos fundamentales de Python con características y casos de uso distintos.
Lista:
- Mutable: Los elementos se pueden modificar después de su creación.
- Uso de memoria: Consume más memoria.
- Rendimiento: Iteración más lenta en comparación con las tuplas, pero mejor para operaciones de inserción y eliminación.
- Métodos: Ofrece varios métodos integrados para la manipulación.
Ejemplo:
a_list = ["Data", "Camp", "Tutorial"]
a_list.append("Session")
print(a_list) # Output: ['Data', 'Camp', 'Tutorial', 'Session']Tupla:
- Inmutable: Los elementos no se pueden modificar después de su creación.
- Uso de memoria: Consume menos memoria.
- Rendimiento: Iteración más rápida en comparación con las listas, pero carece de la flexibilidad de estas.
- Métodos: Métodos integrados limitados.
Ejemplo:
a_tuple = ("Data", "Camp", "Tutorial")
print(a_tuple) # Output: ('Data', 'Camp', 'Tutorial')Más información en nuestro tutorial sobre listas de Python.
3. ¿Qué es __init__() en Python?
El método __init__() se conoce como constructor en la terminología de la programación orientada a objetos (OOP). Se utiliza para inicializar el estado de un objeto cuando se crea. Este método se invoca automáticamente cuando se instancia una nueva instancia de una clase.
Objetivo:
- Asigna valores a las propiedades de los objetos.
- Realiza las operaciones de inicialización.
Ejemplo:
Hemos creado una clase book_shop y hemos añadido el constructor y la función book(). El constructor almacenará el nombre del título del libro y la función book() imprimirá el nombre del libro.
Para probar nuestro código, hemos inicializado el objeto b con «Sandman» y hemos ejecutado la función book().
class book_shop:
# constructor
def __init__(self, title):
self.title = title
# Sample method
def book(self):
print('The tile of the book is', self.title)
b = book_shop('Sandman')
b.book()
# The tile of the book is Sandman4. ¿Cuál es la diferencia entre un tipo de datos mutable y un tipo de datos inmutable?
Tipos de datos mutables:
- Definición: Los tipos de datos mutables son aquellos que pueden modificarse después de su creación.
- Ejemplos: Lista, diccionario, conjunto.
- Características: Se pueden añadir, eliminar o modificar elementos.
- Caso de uso: Adecuado para colecciones de artículos que requieren actualizaciones frecuentes.
Ejemplo:
# List Example
a_list = [1, 2, 3]
a_list.append(4)
print(a_list) # Output: [1, 2, 3, 4]
# Dictionary Example
a_dict = {'a': 1, 'b': 2}
a_dict['c'] = 3
print(a_dict) # Output: {'a': 1, 'b': 2, 'c': 3}Tipos de datos inmutables:
- Definición: Los tipos de datos inmutables son aquellos que no pueden modificarse después de su creación.
- Ejemplos: Numérico (int, float), cadena, tupla.
- Características: Los elementos no se pueden cambiar una vez establecidos; cualquier operación que parezca modificar un objeto inmutable creará un nuevo objeto.
Ejemplo:
# Numeric Example
a_num = 10
a_num = 20 # Creates a new integer object
print(a_num) # Output: 20
# String Example
a_str = "hello"
a_str = "world" # Creates a new string object
print(a_str) # Output: world
# Tuple Example
a_tuple = (1, 2, 3)
# a_tuple[0] = 4 # This will raise a TypeError
print(a_tuple) # Output: (1, 2, 3)5. Explica la comprensión de listas, diccionarios y tuplas con un ejemplo.
Lista
La comprensión de listas ofrece una sintaxis de una sola línea para crear una nueva lista basada en los valores de la lista existente. Puedes utilizar un bucle « for » para replicar lo mismo, pero tendrás que escribir varias líneas y, en ocasiones, puede resultar complejo.
La comprensión de listas facilita la creación de listas basadas en iterables existentes.
my_list = [i for i in range(1, 10)]
my_list
# [1, 2, 3, 4, 5, 6, 7, 8, 9]Diccionario
De forma similar a una comprensión de lista, puedes crear un diccionario basado en una tabla existente con una sola línea de código. Debes encerrar la operación entre llaves {}.
# Creating a dictionary using dictionary comprehension
my_dict = {i: i**2 for i in range(1, 10)}
# Output the dictionary
my_dict
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}Tupla
A diferencia de las listas y los diccionarios, no existe una «comprensión de tuplas» especial.
Cuando utilizas paréntesis con una comprensión, Python crea en realidad una expresión generadora, no una tupla. Para obtener una tupla, debes convertir el generador con tuple() o definir directamente una tupla literal.
# Generator expression (not a tuple)
my_gen = (i for i in range(1, 10))
my_gen
# <generator object <genexpr> ...>
# Converting generator to tuple
my_tuple = tuple(i for i in range(1, 10))
my_tuple
# (1, 2, 3, 4, 5, 6, 7, 8, 9)
# Or simply define a tuple directly
literal_tuple = (1, 2, 3)
literal_tuple
# (1, 2, 3)
Puedes obtener más información al respecto en nuestro tutorial sobre tuplas de Python.
6. ¿Qué es el bloqueo global del intérprete (GIL) en Python y por qué es importante?
El bloqueo global del intérprete (GIL) es un mutex en CPython (la implementación de referencia de Python) que garantiza que solo un subproceso nativo ejecute el código byte de Python a la vez. Simplifica la gestión de la memoria al proteger estructuras de datos internas como los recuentos de referencias, pero también restringe el paralelismo real en tareas dependientes de la CPU, lo que hace que el multithreading sea menos eficaz para las cargas de trabajo computacionales. Sin embargo, funciona bien para tareas vinculadas a E/S, en las que los subprocesos dedican tiempo a esperar operaciones de red, archivos o bases de datos.
Nota: Python 3.13 introdujo una compilación experimental sin GIL (PEP 703), y Python 3.14 añade compatibilidad documentada con subprocesos libres. Es posible que algunas extensiones y bibliotecas C aún no sean totalmente compatibles.
Preguntas de entrevista sobre Python para nivel intermedio
Estas son algunas de las preguntas que te pueden plantear durante una entrevista de nivel intermedio sobre Python.
7. ¿Puedesexplicar los algoritmos comunes de búsqueda y recorrido de grafos en Python?
Python cuenta con varios algoritmos potentes para la búsqueda y el recorrido de grafos, y cada uno de ellos maneja diferentes estructuras de datos y resuelve diferentes problemas. Puedo oírlos aquí:
- Búsqueda binaria: Si necesitas encontrar rápidamente un elemento en una lista ordenada, la búsqueda binaria es la mejor opción. Funciona dividiendo repetidamente el rango de búsqueda por la mitad hasta que se encuentra el objetivo.
- Árbol AVL: Un árbol AVL mantiene el equilibrio, lo que supone una gran ventaja si se insertan o eliminan elementos con frecuencia en un árbol. Esta estructura de árbol binario de búsqueda autoequilibrado mantiene la rapidez de las búsquedas al garantizar que el árbol nunca se desequilibre demasiado.
- Búsqueda en anchura (BFS): BFS consiste en explorar un gráfico nivel por nivel. Es especialmente útil si estás tratando de encontrar el camino más corto en un gráfico no ponderado, ya que comprueba todos los movimientos posibles desde cada nodo antes de profundizar más.
- Búsqueda en profundidad (DFS): DFS adopta un enfoque diferente, explorando todo lo posible cada rama antes de retroceder. Es ideal para tareas como resolver laberintos o recorrer árboles.
- Algoritmo A*: El algoritmo A* es un poco más avanzado y combina lo mejor de BFS y DFS utilizando heurística para encontrar la ruta más corta de manera eficiente. Se utiliza habitualmente en la búsqueda de rutas para mapas y juegos.
8. ¿Qué es un KeyError en Python y cómo puedes gestionarlo?
En Python, se produce un error « KeyError » cuando intentas acceder a una clave que no existe en un diccionario. Este error se produce porque Python espera que todas las claves que buscas estén presentes en el diccionario y, cuando no es así, lanza un error « KeyError » (No se encuentra la clave).
Por ejemplo, si tienes un diccionario con las calificaciones de los alumnos e intentas acceder a un alumno que no está en el diccionario, obtendrás un error « KeyError » (No existe el objeto « »). Para solucionar este error, tienes varias opciones:
-
Utiliza el método .get(): Este método devuelve un valor de tipo `
None` (o un valor predeterminado especificado) en lugar de generar un error si no se encuentra la clave. -
Utiliza un bloque try-except: Al envolver tu código en
try-except, puedes detectar el errorKeyErrory gestionarlo correctamente. -
Busca la clave con: Puedes comprobar si una clave existe en el diccionario utilizando «
if key in dictionary» antes de intentar acceder a ella.
Para obtener más información, lee nuestro tutorial completo: Excepciones KeyError de Python y cómo solucionarlas.
9. ¿Cómo gestiona Python la memoria y qué papel desempeña la recolección de basura?
Python gestiona la asignación y desasignación de memoria automáticamente utilizando un montón privado, donde se almacenan todos los objetos y estructuras de datos. El proceso de gestión de la memoria lo lleva a cabo el gestor de memoria de Python, que optimiza el uso de la memoria, y el recolector de basura, que se encarga de los objetos no utilizados o sin referencias para liberar memoria.
La recolección de basura en Python utiliza el recuento de referencias, así como un recolector de basura cíclico para detectar y recolectar datos no utilizados. Cuando un objeto ya no tiene referencias, pasa a ser susceptible de ser eliminado por el recolector de basura. El módulo gc de Python te permite interactuar directamente con el recolector de basura, proporcionando funciones para habilitar o deshabilitar la recolección de basura, así como para realizar la recolección manual.
10. ¿Cuál es la diferencia entre una copia superficial y una copia profunda en Python, y cuándo se utiliza cada una?
En Python, las copias superficiales y profundas se utilizan para duplicar objetos, pero manejan las estructuras anidadas de manera diferente.
-
Copia superficial: Una copia superficial crea un nuevo objeto, pero inserta referencias a los objetos que se encuentran en el original. Por lo tanto, si el objeto original contiene otros objetos mutables (como listas dentro de listas), la copia superficial hará referencia a los mismos objetos internos. Esto puede provocar cambios inesperados si modificas uno de esos objetos internos, ya sea en la estructura original o en la copiada. Puedes crear una copia superficial utilizando el método `
copy()` o la función `copy()` del módulo `copy`. -
Copia profunda: Una copia profunda crea un nuevo objeto y copia recursivamente todos los objetos que se encuentran dentro del original. Esto significa que incluso las estructuras anidadas se duplican, por lo que los cambios en una copia no afectan a la otra. Para crear una copia profunda, puedes utilizar la función `
deepcopy()` del módulo `copy`.
Ejemplo de uso: Una copia superficial es adecuada cuando el objeto solo contiene elementos inmutables o cuando deseas que los cambios en las estructuras anidadas se reflejen en ambas copias. Una copia profunda es ideal cuando se trabaja con objetos complejos y anidados en los que se desea obtener un duplicado completamente independiente. Lee nuestra lista de copias de Python « »: Lo que debes saber Tutorial de para obtener más información. Este tutorial incluye una sección completa sobre la diferencia entre copia superficial y copia profunda.
11. ¿Cómo puedes utilizar el módulo collections de Python para simplificar tareas comunes?
El módulo collections de Python proporciona estructuras de datos especializadas como defaultdict, Counter, deque y OrderedDict para simplificar diversas tareas. Por ejemplo, Counter es ideal para contar elementos en un iterable, mientras que defaultdict puede inicializar valores de diccionario sin comprobaciones explícitas.
Ejemplo:
from collections import Counter
data = ['a', 'b', 'c', 'a', 'b', 'a']
count = Counter(data)
print(count) # Output: Counter({'a': 3, 'b': 2, 'c': 1})Preguntas avanzadas sobre Python para entrevistas de trabajo
Estas preguntas de entrevista están dirigidas a profesionales con más experiencia en Python.
12. ¿Qué es el monkey patching en Python?
El monkey patching en Python es una técnica dinámica que puede cambiar el comportamiento del código en tiempo de ejecución. En resumen, puedes modificar una clase o un módulo en tiempo de ejecución.
Ejemplo:
Aprendamos el monkey patching con un ejemplo.
-
Hemos creado una clase
monkeycon una funciónpatch(). También hemos creado una funciónmonk_pfuera de la clase. -
Ahora reemplazaremos la función
patchpor la funciónmonk_pasignandomonkey.patchamonk_p. -
Al final, probaremos la modificación creando el objeto con la clase
monkeyy ejecutando la funciónpatch().
En lugar de mostrar patch() is being called, ha mostrado monk_p() is being called.
class monkey:
def patch(self):
print ("patch() is being called")
def monk_p(self):
print ("monk_p() is being called")
# replacing address of "patch" with "monk_p"
monkey.patch = monk_p
obj = monkey()
obj.patch()
# monk_p() is being calledPrecaución: Úsalos con moderación; el monkey patching puede dificultar la lectura de tu código y sorprender a otras personas que trabajen con tu código o tus pruebas.
13. ¿Para qué está diseñada la instrucción «with» de Python?
La instrucción « with » se utiliza para gestionar excepciones y hacer que el código sea más limpio y sencillo. Se utiliza generalmente para la gestión de recursos comunes, como crear, editar y guardar un archivo.
Ejemplo:
En lugar de escribir varias líneas de open, try, finally y close, puedes crear y escribir un archivo de texto utilizando la instrucción with. Es muy sencillo.
# using with statement
with open('myfile.txt', 'w') as file:
file.write('DataCamp Black Friday Sale!!!')14. ¿Por qué utilizar «else» en la construcción «try/except» en Python?
try: except: y son conocidos por su excepcional manejo en Python, entonces, ¿dónde resulta útil else:? else: se activará cuando no se genere ninguna excepción.
Ejemplo:
Aprendamos más sobre else: con un par de ejemplos.
-
En el primer intento, introdujimos
2como numerador ydcomo denominador. Lo cual es incorrecto, y se ha activado un error «except:» con el mensaje «¡Entrada no válida!». -
En el segundo intento, introdujimos
2como numerador y1como denominador, y obtuvimos el resultado2. No se planteó ninguna excepción, por lo que se activó el controlador de eventos de sistema (else:) y se imprimió el mensaje.Division is successful.
try:
num1 = int(input('Enter Numerator: '))
num2 = int(input('Enter Denominator: '))
division = num1/num2
print(f'Result is: {division}')
except:
print('Invalid input!')
else:
print('Division is successful.')
## Try 1 ##
# Enter Numerator: 2
# Enter Denominator: d
# Invalid input!
## Try 2 ##
# Enter Numerator: 2
# Enter Denominator: 1
# Result is: 2.0
# Division is successful.Realiza el programa de habilidades fundamentales de Python para adquirir los conocimientos básicos que necesitas para convertirte en programador de Python.
15. ¿Qué son los decoradores en Python?
Los decoradores en Python son un patrón de diseño que te permite añadir nuevas funcionalidades a un objeto existente sin modificar su estructura. Se utilizan habitualmente para ampliar el comportamiento de funciones o métodos. Puedes leer más sobre cómo usar los decoradores de Python en una guía aparte.
Ejemplo:
import functools
def my_decorator(func):
@functools.wraps(func) # preserves __name__, __doc__, etc.
def wrapper(*args, **kwargs):
print("Something is happening before the function is called.")
result = func(*args, **kwargs)
print("Something is happening after the function is called.")
return result
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
# Output:
# Something is happening before the function is called.
# Hello!
# Something is happening after the function is called.16. ¿Qué son los gestores de contexto en Python y cómo se implementan?
Los gestores de contexto en Python se utilizan para gestionar recursos, asegurando que se adquieren y liberan correctamente. El uso más común de los gestores de contexto es la instrucción « with ».
Ejemplo:
class FileManager:
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
self.file = open(self.filename, self.mode)
return self.file
def __exit__(self, exc_type, exc_value, traceback):
self.file.close()
with FileManager('test.txt', 'w') as f:
f.write('Hello, world!')En este ejemplo, la clase ` FileManager ` es un gestor de contexto que garantiza que el archivo se cierre correctamente después de utilizarlo dentro de la instrucción ` with `.
17. ¿Qué son las metaclases en Python y en qué se diferencian de las clases normales?
Las metaclases son clases de clases. Definen cómo se comportan y se crean las clases. Mientras que las clases normales crean objetos, las metaclases crean clases. Mediante el uso de metaclases, puedes modificar definiciones de clases, aplicar reglas o añadir funcionalidades durante la creación de clases.
Ejemplo:
class Meta(type):
def __new__(cls, name, bases, dct):
print(f"Creating class {name}")
return super().__new__(cls, name, bases, dct)
class MyClass(metaclass=Meta):
pass
# Output: Creating class MyClassPreguntas para entrevistas sobre ciencia de datos con Python
Para aquellos que se centran más en las aplicaciones de Python en la ciencia de datos, estas son algunas preguntas que pueden surgir.
18. ¿Cuáles son las ventajas de NumPy con respecto a las listas normales de Python?
NumPy presenta varias ventajas con respecto a las listas normales de Python, tales como:
- Memoria: Los arreglos NumPy son más eficientes en cuanto a memoria que las listas de Python, ya que almacenan elementos del mismo tipo en bloques contiguos. (El uso exacto de la memoria depende del tipo de elemento y del sistema, pero puedes consultarlo en
sys.getsizeofoarray.nbytes.) - Velocidad: NumPy utiliza implementaciones optimizadas en C, por lo que las operaciones con arreglos grandes son mucho más rápidas que con listas.
- Versatilidad: NumPy admite operaciones vectorizadas (por ejemplo, suma, multiplicación) y proporciona muchas funciones matemáticas integradas que las listas de Python no admiten.
19. ¿Cuál es la diferencia entre fusionar, unir y concatenar?
Combinar
Combina dos DataFrames denominados objetos de serie utilizando el identificador de columna único.
Se necesitan dos DataFrame, una columna común en ambos DataFrame y «cómo» deseas unirlos. Puedes unir dos DataFrames mediante uniones izquierda, derecha, externa, interna y cruzada. Por defecto, es una unión interna.
pd.merge(df1, df2, how='outer', on='Id')Únete
Une los DataFrames utilizando el índice único. Requiere un argumento opcional on que puede ser un nombre de columna o varios nombres de columna. Por defecto, la función join realiza una unión izquierda.
df1.join(df2)Concatenar
Concatenate une dos o más DataFrames a lo largo de un eje concreto (filas o columnas). No hace falta entrar en un debate sobre el « on ».
pd.concat(df1,df2)- join(): combina dois DataFrame por índice.
- merge(): combina dos DataFrames por la columna o columnas que especifiques.
- concat(): combina dos o más DataFrames vertical u horizontalmente.
20. ¿Cómo identificas y gestionas los valores perdidos?
Identificación de valores perdidos
Podemos identificar los valores que faltan en el DataFrame utilizando la función « isnull() » y, a continuación, aplicando « sum() ». « Isnull() » devolverá valores booleanos y la suma te dará el número de valores que faltan en cada columna.
En el ejemplo, hemos creado un diccionario de listas y lo hemos convertido en un DataFrame de pandas. Después, utilizamos isnull().sum() para obtener el número de valores perdidos en cada columna.
import pandas as pd
import numpy as np
# dictionary of lists
dict = {'id':[1, 4, np.nan, 9],
'Age': [30, 45, np.nan, np.nan],
'Score':[np.nan, 140, 180, 198]}
# creating a DataFrame
df = pd.DataFrame(dict)
df.isnull().sum()
# id 1
# Age 2
# Score 1Tratamiento de valores perdidos
Hay varias formas de tratar los valores perdidos en Python.
-
Elimina toda la fila o las columnas si contienen valores perdidos utilizando
dropna(). No se recomienda este método, ya que perderás información importante. -
Rellena los valores que faltan con la constante, la media, el relleno hacia atrás y el relleno hacia adelante utilizando la función «
fillna()». -
Reemplaza los valores que faltan por una cadena, un entero o un flotante constantes utilizando la función «
replace()». -
Rellena los valores que faltan utilizando un método de interpolación.
Nota: asegúrate de que estás trabajando con un conjunto de datos más grande cuando utilices la función dropna().
# drop missing values
df.dropna(axis = 0, how ='any')
#fillna
df.fillna(method ='bfill')
#replace null values with -999
df.replace(to_replace = np.nan, value = -999)
# Interpolate
df.interpolate(method ='linear', limit_direction ='forward')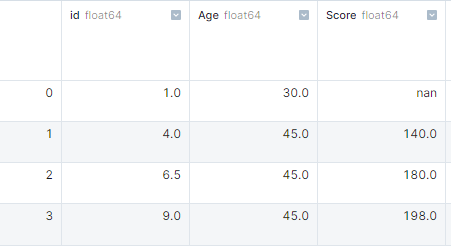
Conviértete en un científico de datos profesional siguiendo el programa de Científico de datos con Python. Incluye 25 cursos y seis proyectos para ayudarte a aprender todos los fundamentos de la ciencia de datos con la ayuda de bibliotecas de Python.
21. ¿Qué bibliotecas de Python has utilizado para la visualización?
La visualización de datos es la parte más importante del análisis de datos. Puedes ver tus datos en acción, lo que te ayuda a encontrar patrones ocultos.
Las bibliotecas de visualización de datos más populares de Python son:
- Matplotlib
- Seaborn
- Plotly
- Bokeh
En Python, generalmente usamos Matplotlib y seaborn para mostrar todo tipo de visualizaciones de datos. Con unas pocas líneas de código, puedes utilizarlo para mostrar diagramas de dispersión, diagramas de líneas, diagramas de caja, gráficos de barras y mucho más.
Para aplicaciones interactivas y más complejas, utilizamos Plotly. Puedes utilizarlo para crear gráficos interactivos a todo color con unas pocas líneas de código. Puedes ampliar, aplicar animaciones e incluso añadir funciones de control. Plotly ofrece más de 40 tipos de gráficos únicos, y incluso podemos utilizarlos para crear una aplicación web o un panel de control.
Bokeh se utiliza para gráficos detallados con un alto nivel de interactividad en grandes conjuntos de datos.
22. ¿Cómo normalizarías o estandarizarías un conjunto de datos en Python?
La normalización escala los datos a un rango específico, normalmente [0, 1], mientras que la estandarización los transforma para que tengan una media de 0 y una desviación estándar de 1. Ambas técnicas son esenciales para preparar datos para modelos de machine learning.
Ejemplo:
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import numpy as np
data = np.array([[1, 2], [3, 4], [5, 6]])
# Normalize
normalizer = MinMaxScaler()
normalized = normalizer.fit_transform(data)
print(normalized)
# Standardize
scaler = StandardScaler()
standardized = scaler.fit_transform(data)
print(standardized)Preguntas de entrevista sobre programación en Python
Si tienes una entrevista de programación en Python próximamente, preparar preguntas similares a estas puede ayudarte a causar una buena impresión al entrevistador.
23. ¿Cómo se puede sustituir un espacio de cadena por un carácter determinado en Python?
Es un sencillo reto de manipulación de cadenas. Debes sustituir el espacio por un carácter específico.
Ejemplo 1: Un usuario ha proporcionado la cadena « l vey u » y el carácter « o », y el resultado será « loveyou ».
Ejemplo 2: Un usuario ha proporcionado la cadena « D t C mpBl ckFrid yS le » y el carácter « a », y el resultado será « DataCampBlackFridaySale ».
La forma más sencilla es utilizar el método integrado str.replace() para reemplazar directamente los espacios por el carácter dado.
def str_replace(text, ch):
return text.replace(" ", ch)
text = "D t C mpBl ckFrid yS le"
ch = "a"
str_replace(text, ch)
# 'DataCampBlackFridaySale'
24. Dado un número entero positivo num, escribe una función que devuelva True si num es un cuadrado perfecto, y False en caso contrario.
Esto tiene una solución relativamente sencilla. Puedes comprobar si el número tiene una raíz cuadrada perfecta de la siguiente manera:
- Usando
math.isqrt(num)para obtener la raíz cuadrada entera exacta. - Elevarlo al cuadrado y comprobar si es igual al número original.
- Devuelve el resultado como un valor booleano.
Prueba 1
Hemos asignado el número 10 a la valid_square() función:
- Al calcular la raíz cuadrada entera del número, obtenemos 3.
- Luego, eleva al cuadrado el número 3 y obtienes 9.
- 9 no es igual al número, por lo que la función devolverá False.
Prueba 2
Hemos asignado el número 36 a la valid_square() función:
- Al calcular la raíz cuadrada entera del número, obtenemos 6.
- Luego, eleva al cuadrado el número 6 y obtienes 36.
- 36 es igual al número, por lo que la función devolverá True.
import math
def valid_square(num):
if num < 0:
return False
square = math.isqrt(num)
return square * square == num
valid_square(10)
# False
valid_square(36)
# True25. Dado un número entero n, devuelve el número de ceros finales en n factorial n!
Para superar este reto, primero debes calcular el factorial de n (n!) y, a continuación, calcular el número de ceros de entrenamiento.
Hallar el factorial
En el primer paso, utilizaremos un bucle while para iterar sobre el factorial de n y detenerte cuando n sea igual a 1.
Cálculo de ceros finales
En el segundo paso, calcularemos los ceros finales, no el número total de ceros. Hay una gran diferencia.
7! = 5040Los siete factoriales tienen un total de dos ceros y solo un cero final, por lo que nuestra solución debería devolver 1.
- Convierte el número factorial en una cadena.
- Vuelve a leerlo y aplícalo en bucle.
- Si el número es 0, añade +1 al resultado; de lo contrario, rompe el bucle.
- Devuelve el resultado.
La solución es elegante, pero requiere prestar atención a los detalles.
def factorial_trailing_zeros(n):
fact = n
while n > 1:
fact *= n - 1
n -= 1
result = 0
for i in str(fact)[::-1]:
if i == "0":
result += 1
else:
break
return result
factorial_trailing_zeros(10)
# 2
factorial_trailing_zeros(18)
# 3Realiza el curso esencial de preguntas de entrevista sobre programación para prepararte para tus próximas entrevistas de programación en Python.
26. ¿Se puede dividir la cadena en palabras del diccionario?
Se te proporciona una cadena larga y un diccionario con las palabras. Tienes que averiguar si la cadena de entrada se puede segmentar en palabras utilizando el diccionario o no.
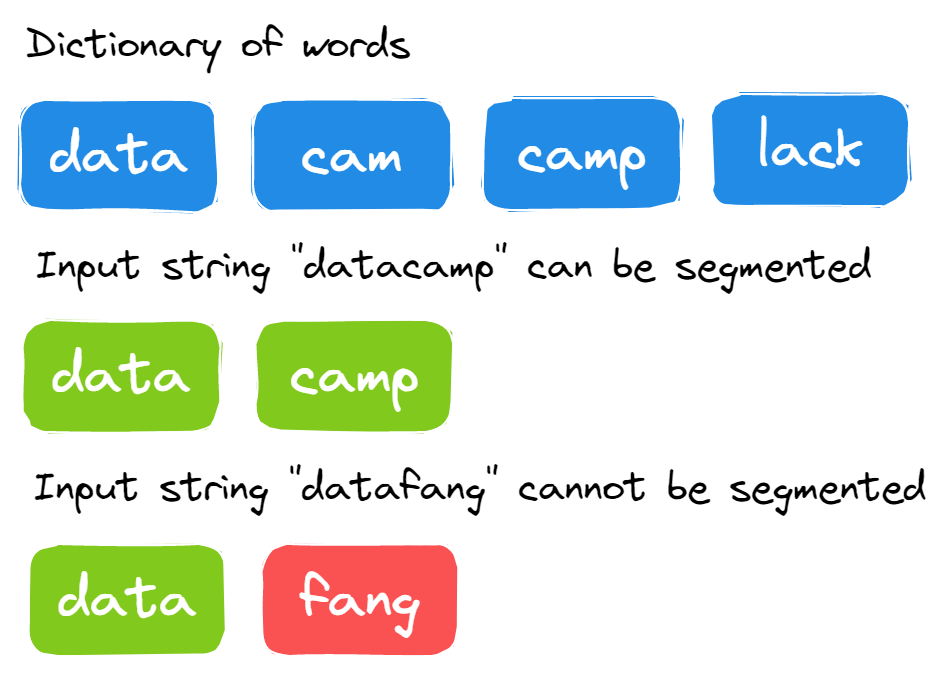
Imagen del autor
La solución es bastante sencilla. Tienes que segmentar una cadena grande en cada punto y comprobar si la cadena se puede segmentar en las palabras del diccionario.
- Ejecuta el bucle utilizando la longitud de la cadena grande.
- Crearemos dos subcadenas.
- La primera subcadena comprobará cada punto de la cadena grande desde
s[0:i]. - Si la primera subcadena no está en el diccionario, devolverá False.
- Si la primera subcadena está en el diccionario, creará la segunda subcadena utilizando
s[i:]. - Si la segunda subcadena está en el diccionario o tiene longitud cero, devuelve True. Llama recursivamente a
can_segment_str()con la segunda subcadena y devuelve True si se puede segmentar. - Para que la solución sea eficaz con cadenas más largas, añadimos memorización para que las subcadenas no se vuelvan a calcular una y otra vez.
def can_segment_str(s, dictionary, memo=None):
if memo is None:
memo = {}
if s in memo:
return memo[s]
if not s:
return True
for i in range(1, len(s) + 1):
first_str = s[0:i]
if first_str in dictionary:
second_str = s[i:]
if (
not second_str
or second_str in dictionary
or can_segment_str(second_str, dictionary, memo)
):
memo[s] = True
return True
memo[s] = False
return False
s = "datacamp"
dictionary = ["data", "camp", "cam", "lack"]
can_segment_str(s, dictionary)
# True27. ¿Puedes eliminar los duplicados de un arreglo ordenado?
Dada un arreglo de números enteros ordenado en orden ascendente, elimina los duplicados para que cada elemento único aparezca solo una vez. Dado que las listas de Python no cambian de longitud in situ para este problema, coloca los resultados en las primeras k posiciones del mismo arreglo y devuelve k (la nueva longitud). Solo los primeros k elementos son válidos después de la llamada; los elementos más allá de k están obsoletos.
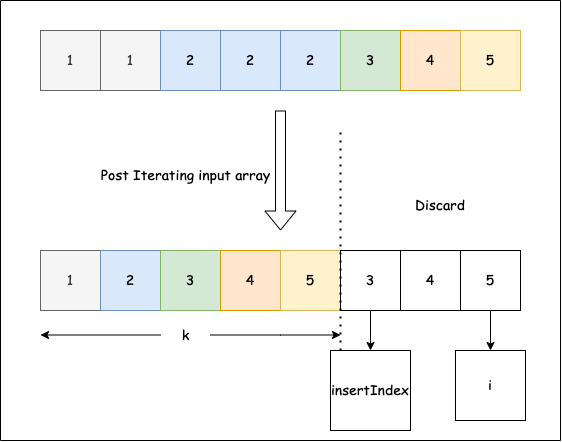
Imagen de LeetCode
Ejemplo 1El arreglo de entrada es [1,1,2,2], la función debería devolver 2.
Ejemplo 2El arreglo de entrada es [1,1,2,3,3], la función debería devolver 3.
Solución:
- Ejecuta un bucle desde el índice 1 hasta el final. Compara el elemento actual con el elemento único anterior; si son diferentes, escríbelo en
insertIndexe incrementainsertIndex. DevuelveinsertIndex. - Devuelve
insertIndex, ya que es la k.
Esta pregunta es relativamente sencilla una vez que sabes cómo responderla. Si dedicas más tiempo a comprender la afirmación, podrás encontrar fácilmente una solución.
def removeDuplicates(array):
size = len(array)
if size == 0:
return 0
insertIndex = 1
for i in range(1, size):
if array[i - 1] != array[i]:
array[insertIndex] = array[i]
insertIndex += 1
return insertIndex
array_1 = [1, 2, 2, 3, 3, 4]
k1 = removeDuplicates(array_1)
# 4; array_1[:k1] -> [1, 2, 3, 4]
array_2 = [1, 1, 3, 4, 5, 6, 6]
k2 = removeDuplicates(array_2)
# 5; array_2[:k2] -> [1, 3, 4, 5, 6]
28. ¿Puedes encontrar el número que falta en el arreglo?
Se te ha proporcionado la lista de números enteros positivos del 1 al n. Todos los números del 1 al n están presentes excepto x, y debes encontrar x.
Ejemplo:
|
4 |
5 |
3 |
2 |
8 |
1 |
6 |
- n = 8
- número que falta = 7
Esta pregunta es un simple problema matemático.
- Halla la suma de todos los elementos de la lista.
- Utilizando la fórmula de la suma de una serie aritmética, hallaremos la suma esperada de los primeros n números.
- Devuelve la diferencia entre la suma esperada y la suma de los elementos.
def find_missing(input_list):
sum_of_elements = sum(input_list)
# There is exactly 1 number missing
n = len(input_list) + 1
actual_sum = (n * ( n + 1 ) ) / 2
return int(actual_sum - sum_of_elements)
list_1 = [1,5,6,3,4]
find_missing(list_1)
# 229. Escribe una función Python para determinar si una cadena dada es un palíndromo.
Una cadena es un palíndromo si se lee igual hacia adelante y hacia atrás.
Ejemplo:
def is_palindrome(s):
s = ''.join(e for e in s if e.isalnum()).lower() # Remove non-alphanumeric and convert to lowercase
return s == s[::-1]
print(is_palindrome("A man, a plan, a canal: Panama")) # Output: True
print(is_palindrome("hello")) # Output: FalsePreguntas de entrevista sobre Python para Facebook, Amazon, Apple, Netflix y Google
A continuación, hemos seleccionado algunas de las preguntas que puedes esperar en los puestos más codiciados de los sectores, como Meta, Amazon, Google y similares.
Preguntas de la entrevista de Facebook/Meta Python
Las preguntas exactas que te harán en Meta dependen en gran medida del puesto. Sin embargo, es posible que te encuentres con algunas de las siguientes situaciones:
30. ¿Puedes encontrar el beneficio máximo por venta individual?
Se te proporciona la lista de precios de las acciones y debes devolver el precio de compra y venta para obtener el mayor beneficio.
Nota: Tenemos que obtener el máximo beneficio de cada compra/venta, y si no podemos obtener beneficios, tenemos que reducir nuestras pérdidas.
Ejemplo 1: stock_price = [8, 4, 12, 9, 20, 1], buy = 4 y sell = 20. Maximizar los beneficios.
Ejemplo 2: stock_price = [8, 6, 5, 4, 3, 2, 1], buy = 6 y sell = 5. Minimizar la pérdida.
Solución:
- Calcularemos el beneficio global restando la venta global (el primer elemento de la lista) de la compra actual (el segundo elemento de la lista).
- Ejecuta el bucle para el rango de 1 a la longitud de la lista.
- Dentro del bucle, calcula el beneficio actual utilizando los elementos de la lista y el valor de compra actual.
- Si el beneficio actual es mayor que el beneficio global, cambia el beneficio global por el beneficio actual y vende globalmente al elemento i de la lista.
- Si la compra actual es mayor que el elemento actual de la lista, cambia la compra actual por el elemento actual de la lista.
- Al final, devolveremos el valor global de compra y venta. Para obtener el valor global de compra, restaremos las ventas globales de los beneficios globales.
La pregunta es un poco complicada, y puedes crear tu propio algoritmo para resolver los problemas.
def buy_sell_stock_prices(stock_prices):
current_buy = stock_prices[0]
global_sell = stock_prices[1]
global_profit = global_sell - current_buy
for i in range(1, len(stock_prices)):
current_profit = stock_prices[i] - current_buy
if current_profit > global_profit:
global_profit = current_profit
global_sell = stock_prices[i]
if current_buy > stock_prices[i]:
current_buy = stock_prices[i]
return global_sell - global_profit, global_sell
stock_prices_1 = [10,9,16,17,19,23]
buy_sell_stock_prices(stock_prices_1)
# (9, 23)
stock_prices_2 = [8, 6, 5, 4, 3, 2, 1]
buy_sell_stock_prices(stock_prices_2)
# (6, 5)Preguntas de la entrevista de Amazon Python
Las preguntas de las entrevistas de Amazon Python pueden variar mucho, pero podrían incluir:
31. ¿Puedes encontrar un triplete pitagórico en un arreglo?
Escribe una función que devuelva un valor booleano ( True ) si existe un triplete pitagórico que satisfaga la ecuación a2+ b2 = c2.
Ejemplo:
|
Entrada |
Salida |
|
[3, 1, 4, 6, 5] |
Verdadero |
|
[10, 4, 6, 12, 5] |
Falso |
Solución:
-
Elevad al cuadrado todos los elementos del arreglo.
-
Ordena el arreglo en orden ascendente.
-
Corre dos vueltas. El bucle externo comienza desde el último índice del arreglo hasta 1, y el bucle interno comienza desde (
outer_loop_index - 1) hasta el inicio. -
Crea un
set()o para almacenar los elementos entre el índice del bucle externo y el índice del bucle interno. -
Comprueba si hay algún número en el conjunto que sea igual a
(array[outerLoopIndex] – array[innerLoopIndex]). Si es así, devuelveTrue, si no,False.
def checkTriplet(array):
n = len(array)
for i in range(n):
array[i] = array[i]**2
array.sort()
for i in range(n - 1, 1, -1):
s = set()
for j in range(i - 1, -1, -1):
if (array[i] - array[j]) in s:
return True
s.add(array[j])
return False
arr = [3, 2, 4, 6, 5]
checkTriplet(arr)
# True32. ¿De cuántas maneras puedes dar cambio con monedas y una cantidad total?
Necesitamos crear una función que tome una lista de denominaciones de monedas y un importe total y devuelva el número de formas en que podemos dar el cambio.
En el ejemplo, hemos proporcionado denominaciones de monedas [1, 2, 5] y el importe total de 5. A cambio, obtenemos cuatro formas de realizar el cambio.
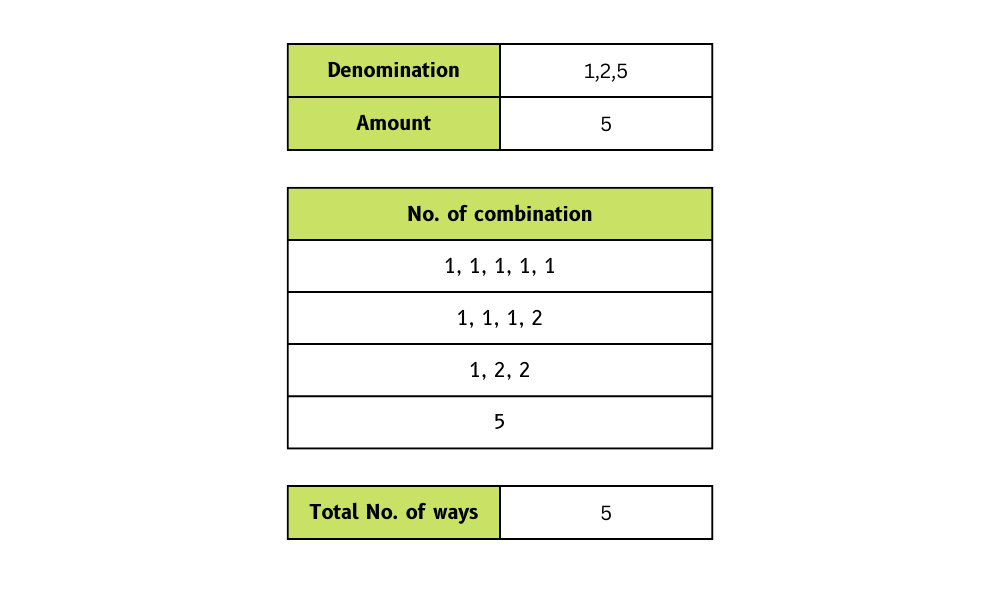
Imagen del autor
Solución:
- Crearemos la lista de tamaño
amount + 1. Se añade espacio adicional para almacenar la solución sin coste alguno. - Iniciaremos una lista de soluciones con
solution[0] = 1. - Correremos dos vueltas. El bucle externo itera sobre las denominaciones, y el bucle interno se ejecuta desde el valor de denominación actual hasta
amount + 1. - Los resultados de las diferentes denominaciones se almacenan en el arreglo solución.
solution[i] = solution[i] + solution[i - den].
El proceso se repetirá para todos los elementos de la lista de denominaciones y, en el último elemento de la lista de soluciones, tendremos nuestro número.
def solve_coin_change(denominations, amount):
solution = [0] * (amount + 1)
solution[0] = 1
for den in denominations:
for i in range(den, amount + 1):
solution[i] += solution[i - den]
return solution[amount]
denominations = [1, 2, 5]
amount = 5
solve_coin_change(denominations, amount)
# 4Preguntas de la entrevista de Google sobre Python
Al igual que en las otras empresas mencionadas, las preguntas de la entrevista de Google Python dependerán del puesto y del nivel de experiencia. Sin embargo, algunas preguntas frecuentes son:
33. Define una función lambda, un iterador y un generador en Python.
La función Lambda también se conoce como función anónima. Puedes añadir tantos parámetros como quieras, pero solo con una instrucción.
Un iterador es un objeto que podemos utilizar para iterar sobre objetos iterables como listas, diccionarios, tuplas y conjuntos.
El generador es una función similar a una función normal, pero genera un valor utilizando la palabra clave yield en lugar de return. Si el cuerpo de la función contiene yield, automáticamente se convierte en un generador.
Lee más sobre los iteradores y generadores de Python en nuestro tutorial completo.
34. Dada un arreglo arr[], encuentra el máximo j – i tal que arr[j] > arr[i].
Esta pregunta es bastante sencilla, pero requiere prestar especial atención a los detalles. Se os proporciona un arreglo de números enteros positivos. Tenemos que encontrar la diferencia máxima entre j-i donde arreglo[j] > arreglo[i].
Ejemplos:
- Entrada: [20, 70, 40, 50, 12, 38, 98], Salida: 6 (j = 6, i = 0)
- Entrada: [10, 3, 2, 4, 5, 6, 7, 8, 18, 0], Salida: 8 (j = 8, i = 0)
Solución:
- Calcula la longitud del arreglo e inicia la diferencia máxima con -1.
- Corre dos vueltas. El bucle externo selecciona elementos de la izquierda, y el bucle interno compara los elementos seleccionados con los elementos que comienzan por la derecha.
- Detén el bucle interno cuando el elemento sea mayor que el elemento seleccionado y sigue actualizando la diferencia máxima utilizando j - I.
def max_index_diff(array):
n = len(array)
max_diff = -1
for i in range(0, n):
j = n - 1
while(j > i):
if array[j] > array[i] and max_diff < (j - i):
max_diff = j - i
j -= 1
return max_diff
array_1 = [20,70,40,50,12,38,98]
max_index_diff(array_1)
# 635. ¿Cómo usarías los operadores ternarios en Python?
Los operadores ternarios también se conocen como expresiones condicionales. Son operadores que evalúan expresiones basándose en condiciones verdaderas y falsas.
Puedes escribir expresiones condicionales en una sola línea en lugar de escribir varias líneas de sentencias if-else. Te permite escribir código limpio y compacto.
Por ejemplo, podemos convertir las sentencias if-else anidadas en una sola línea, como se muestra a continuación.
Sentencia if-else
score = 75
if score < 70:
if score < 50:
print('Fail')
else:
print('Merit')
else:
print('Distinction')
# DistinctionOperador ternario anidado
print('Fail' if score < 50 else 'Merit' if score < 70 else 'Distinction')
# Distinction36. ¿Cómo implementarías una caché LRU en Python?
Python proporciona un decorador integrado functools.lru_cache para implementar una caché LRU (Least Recently Used, menos utilizada recientemente). También puedes crear uno manualmente utilizando el generador de claves de cifrado de texto ( OrderedDict ) de collections.
Ejemplo utilizando functools:
from functools import lru_cache
@lru_cache(maxsize=3)
def add(a, b):
return a + b
print(add(1, 2)) # Calculates and caches result
print(add(1, 2)) # Retrieves result from cacheMejora las habilidades de tu equipo con Python
Si bien la preparación para las entrevistas de Python es esencial para los solicitantes de empleo y los responsables de contratación, es igualmente importante que las empresas inviertan en la formación continua en Python de sus equipos. En una era en la que la automatización, el análisis de datos y el desarrollo de software son fundamentales, garantizar que tus empleados tengan sólidos conocimientos de Python puede ser un factor transformador para el éxito de tu empresa.
Si eres jefe de equipo o propietario de una empresa y quieres asegurarte de que todo tu equipo domine Python, DataCamp for Business ofrece programas de formación personalizados que pueden ayudar a tus empleados a dominar las habilidades de Python, desde los conceptos básicos hasta los más avanzados. Podemos ofrecer:
- Itinerarios de aprendizaje específicos: Personalizable según el nivel de habilidad actual de tu equipo y las necesidades específicas de tu empresa.
- Práctica práctica: Proyectos del mundo real y ejercicios de programación que refuerzan el aprendizaje y mejoran la retención.
- Seguimiento del progreso: Herramientas para supervisar y evaluar el progreso de tu equipo, asegurándote de que alcancen sus objetivos de aprendizaje.
Invertir en la mejora de las habilidades en Python a través de plataformas como DataCamp no solo mejora las capacidades de tu equipo, sino que también proporciona a tu empresa una ventaja estratégica, permitiéndote innovar, mantener tu competitividad y obtener resultados impactantes. Ponte en contacto con nuestro equipo y solicita una demostración hoy mismo.
Aumenta el dominio de Python de tu equipo
Forma a tu equipo en Python con DataCamp para empresas. Formación completa, proyectos prácticos y métricas de rendimiento detalladas para tu empresa.


