
Obtenez une certification Top Data
Questions d'entretien de base sur Python
Voici quelques-unes des questions qui pourraient vous être posées lors d'un entretien d'embauche pour un poste débutant en Python.
1. Qu'est-ce que Python, et veuillez énumérer certaines de ses principales caractéristiques.
Python est un langage de programmation polyvalent et de haut niveau, réputé pour sa syntaxe facile à lire et ses nombreuses applications. Voici quelques-unes des principales fonctionnalités de Python :
- Syntaxe simple et lisible: La syntaxe de Python est claire et simple, ce qui la rend accessible aux débutants et efficace pour les développeurs expérimentés.
- Langue interprétée: Python exécute le code ligne par ligne, ce qui facilite le débogage et les tests.
- Typage dynamique: Python ne nécessite pas de déclarations explicites des types de données, ce qui offre une plus grande flexibilité.
- Bibliothèques et frameworks complets: Les bibliothèques telles que NumPy, Pandas et Django élargissent les fonctionnalités de Python pour des tâches spécialisées dans les domaines de la science des données, du développement web et bien d'autres encore.
- Compatibilité multiplateforme: Python peut fonctionner sur différents systèmes d'exploitation, notamment Windows, macOS et Linux.
2. Que sont les listes et les tuples en Python ?
Les listes et les tuples sont des structures de données fondamentales de Python présentant des caractéristiques et des cas d'utilisation distincts.
Liste :
- Mutable : Les éléments peuvent être modifiés après leur création.
- Utilisation de la mémoire : Consomme davantage de mémoire.
- Performance : Itération plus lente par rapport aux tuples, mais plus performante pour les opérations d'insertion et de suppression.
- Méthodes : Propose diverses méthodes intégrées pour la manipulation.
Exemple :
a_list = ["Data", "Camp", "Tutorial"]
a_list.append("Session")
print(a_list) # Output: ['Data', 'Camp', 'Tutorial', 'Session']Tuple :
- Immuable : Les éléments ne peuvent pas être modifiés après leur création.
- Utilisation de la mémoire : Consomme moins de mémoire.
- Performance : Itération plus rapide par rapport aux listes, mais manque de la flexibilité des listes.
- Méthodes : Méthodes intégrées limitées.
Exemple :
a_tuple = ("Data", "Camp", "Tutorial")
print(a_tuple) # Output: ('Data', 'Camp', 'Tutorial')Pour en savoir plus, veuillez consulter notre tutoriel sur les listes Python.
3. Que représente __init__() en Python ?
La méthode d'__init__() est connue sous le nom de constructeur dans la terminologie de la programmation orientée objet (POO). Il est utilisé pour initialiser l'état d'un objet lors de sa création. Cette méthode est automatiquement appelée lorsqu'une nouvelle instance d'une classe est instanciée.
Objectif :
- Attribuez des valeurs aux propriétés des objets.
- Effectuez toutes les opérations d'initialisation.
Exemple:
Nous avons créé une classe book_shop et ajouté le constructeur et la fonction book(). Le constructeur enregistrera le titre du livre et la fonction d'book() ation affichera le nom du livre.
Pour tester notre code, nous avons initialisé l'objet b avec « Sandman » et exécuté la fonction book().
class book_shop:
# constructor
def __init__(self, title):
self.title = title
# Sample method
def book(self):
print('The tile of the book is', self.title)
b = book_shop('Sandman')
b.book()
# The tile of the book is Sandman4. Quelle est la différence entre un type de données modifiable et un type de données non modifiable ?
Types de données modifiables :
- Définition : Les types de données mutables sont ceux qui peuvent être modifiés après leur création.
- Exemples : Liste, Dictionnaire, Ensemble.
- Caractéristiques : Il est possible d'ajouter, de supprimer ou de modifier des éléments.
- Cas d'utilisation : Convient aux collections d'articles nécessitant des mises à jour fréquentes.
Exemple :
# List Example
a_list = [1, 2, 3]
a_list.append(4)
print(a_list) # Output: [1, 2, 3, 4]
# Dictionary Example
a_dict = {'a': 1, 'b': 2}
a_dict['c'] = 3
print(a_dict) # Output: {'a': 1, 'b': 2, 'c': 3}Types de données immuables :
- Définition : Les types de données immuables sont ceux qui ne peuvent pas être modifiés après leur création.
- Exemples : Numérique (entier, flottant), chaîne de caractères, tuple.
- Caractéristiques : Les éléments ne peuvent pas être modifiés une fois définis ; toute opération qui semble modifier un objet immuable créera un nouvel objet.
Exemple :
# Numeric Example
a_num = 10
a_num = 20 # Creates a new integer object
print(a_num) # Output: 20
# String Example
a_str = "hello"
a_str = "world" # Creates a new string object
print(a_str) # Output: world
# Tuple Example
a_tuple = (1, 2, 3)
# a_tuple[0] = 4 # This will raise a TypeError
print(a_tuple) # Output: (1, 2, 3)5. Veuillez expliquer la compréhension des listes, des dictionnaires et des tuples à l'aide d'un exemple.
Liste
La compréhension de liste offre une syntaxe en une seule ligne pour créer une nouvelle liste basée sur les valeurs de la liste existante. Vous pouvez utiliser une boucle « for » pour reproduire la même chose, mais cela vous obligera à écrire plusieurs lignes, ce qui peut parfois s'avérer complexe.
La compréhension de liste facilite la création d'une liste à partir d'un itérable existant.
my_list = [i for i in range(1, 10)]
my_list
# [1, 2, 3, 4, 5, 6, 7, 8, 9]Dictionnaire
À l'instar d'une compréhension de liste, il est possible de créer un dictionnaire à partir d'un tableau existant à l'aide d'une seule ligne de code. Il est nécessaire d'encadrer l'opération entre des accolades {}.
# Creating a dictionary using dictionary comprehension
my_dict = {i: i**2 for i in range(1, 10)}
# Output the dictionary
my_dict
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}Tuple
Contrairement aux listes et aux dictionnaires, il n'existe pas de « compréhension de tuples » spécifique.
Lorsque vous utilisez des parenthèses avec une compréhension, Python crée en réalité une expression génératrice, et non un tuple. Pour obtenir un tuple, il est nécessaire soit de convertir le générateur à l'aide de ` tuple() `, soit de définir directement un littéral de tuple.
# Generator expression (not a tuple)
my_gen = (i for i in range(1, 10))
my_gen
# <generator object <genexpr> ...>
# Converting generator to tuple
my_tuple = tuple(i for i in range(1, 10))
my_tuple
# (1, 2, 3, 4, 5, 6, 7, 8, 9)
# Or simply define a tuple directly
literal_tuple = (1, 2, 3)
literal_tuple
# (1, 2, 3)
Vous pouvez en apprendre davantage à ce sujet dans notre tutoriel sur les tuples Python.
6. Qu'est-ce que le Global Interpreter Lock (GIL) en Python et pourquoi est-il important ?
Le Global Interpreter Lock (GIL) est un mutex dans CPython (l'implémentation Python de référence) qui garantit qu'un seul thread natif exécute le bytecode Python à la fois. Il simplifie la gestion de la mémoire en protégeant les structures de données internes telles que les comptes de référence, mais il limite également le véritable parallélisme dans les tâches liées au processeur, rendant le multithreading moins efficace pour les charges de travail informatiques. Cependant, cela fonctionne bien pour les tâches liées aux E/S, où les threads passent du temps à attendre des opérations réseau, fichier ou base de données.
Remarque: Python 3.13 a introduit une version expérimentale sans GIL (PEP 703), et Python 3.14 ajoute une prise en charge documentée des threads libres. Certaines extensions et bibliothèques C peuvent ne pas être encore entièrement compatibles.
Questions d'entretien Python de niveau intermédiaire
Voici quelques-unes des questions qui pourraient vous être posées lors d'un entretien de niveau intermédiaire sur Python.
7. Pourriez-vousexpliquer les algorithmes courants de recherche et de parcours de graphes en Python ?
Python dispose de plusieurs algorithmes puissants pour la recherche et le parcours de graphes, chacun traitant différentes structures de données et résolvant différents problèmes. Je peux les entendre ici :
- Recherche binaire: Si vous avez besoin de trouver rapidement un élément dans une liste triée, la recherche binaire est la solution idéale. Il fonctionne en divisant à plusieurs reprises la zone de recherche en deux jusqu'à ce que la cible soit localisée.
- Arbre AVL: Un arbre AVL assure l'équilibre, ce qui constitue un avantage considérable si vous insérez ou supprimez fréquemment des éléments dans un arbre. Cette structure d'arbre de recherche binaire auto-équilibrée garantit la rapidité des recherches en veillant à ce que l'arbre ne soit jamais trop asymétrique.
- Recherche en largeur (BFS): BFS consiste à explorer un graphe niveau par niveau. Cette méthode est particulièrement utile si vous cherchez le chemin le plus court dans un graphe non pondéré, car elle examine tous les déplacements possibles à partir de chaque nœud avant d'approfondir la recherche.
- Recherche en profondeur (DFS): DFS adopte une approche différente en explorant autant que possible chaque branche avant de revenir en arrière. Il est particulièrement adapté à des tâches telles que la résolution de labyrinthes ou le parcours d'arbres.
- Algorithme A*: L'algorithme A* est un peu plus avancé et combine le meilleur des algorithmes BFS et DFS en utilisant des heuristiques pour trouver efficacement le chemin le plus court. Il est couramment utilisé dans la recherche d'itinéraires pour les cartes et les jeux.
8. Qu'est-ce qu'une erreur KeyError en Python et comment la gérer ?
Une erreur « A KeyError » (Erreur de clé inexistante) en Python se produit lorsque vous essayez d'accéder à une clé qui n'existe pas dans un dictionnaire. Cette erreur est générée car Python s'attend à ce que chaque clé que vous recherchez soit présente dans le dictionnaire, et lorsqu'elle ne l'est pas, il génère une exception « KeyError ».
Par exemple, si vous disposez d'un dictionnaire contenant les notes des élèves et que vous essayez d'accéder à un élève qui ne figure pas dans le dictionnaire, vous obtiendrez une erreur d'accès non autorisé ( KeyError). Pour résoudre cette erreur, plusieurs options s'offrent à vous :
-
Veuillez utiliser la méthode .get(): Cette méthode renvoie
None(ou une valeur par défaut spécifiée) au lieu de générer une erreur si la clé n'est pas trouvée. -
Veuillez utiliser un bloc try-except: En encapsulant votre code dans
try-except, vous pouvez détecter l'exceptionKeyErroret la gérer de manière appropriée. -
Veuillez vérifier la clé avec : Vous pouvez vérifier si une clé existe dans le dictionnaire à l'aide de la fonction `
if key in dictionary` avant de tenter d'y accéder.
Pour en savoir plus, veuillez consulter notre tutoriel complet : Exceptions KeyError en Python et comment les résoudre.
9. Comment Python gère-t-il la gestion de la mémoire, et quel rôle joue le ramasse-miettes ?
Python gère automatiquement l'allocation et la désallocation de la mémoire à l'aide d'un tas privé, où tous les objets et toutes les structures de données sont stockés. Le processus de gestion de la mémoire est géré par le gestionnaire de mémoire de Python, qui optimise l'utilisation de la mémoire, et par le ramasse-miettes, qui traite les objets inutilisés ou non référencés afin de libérer de la mémoire.
Le ramasse-miettes en Python utilise le comptage de références ainsi qu'un ramasse-miettes cyclique pour détecter et collecter les données inutilisées. Lorsqu'un objet n'a plus aucune référence, il peut être supprimé par le ramasse-miettes. Le module gc de Python permet d'interagir directement avec le ramasse-miettes, en fournissant des fonctions permettant d'activer ou de désactiver le ramasse-miettes, ainsi que d'effectuer un ramassage manuel.
10. Quelle est la différence entre une copie superficielle et une copie profonde en Python, et dans quels cas les utiliseriez-vous respectivement ?
En Python, les copies superficielles et profondes sont utilisées pour dupliquer des objets, mais elles gèrent différemment les structures imbriquées.
-
Copie superficielle: Une copie superficielle crée un nouvel objet, mais insère des références aux objets présents dans l'original. Ainsi, si l'objet d'origine contient d'autres objets modifiables (tels que des listes dans des listes), la copie superficielle fera référence aux mêmes objets internes. Cela peut entraîner des modifications imprévues si vous modifiez l'un de ces objets internes dans la structure d'origine ou dans la structure copiée. Vous pouvez créer une copie superficielle à l'aide de la méthode `
copy()` ou de la fonction `copy()` du module `copy`. -
Copie profonde: Une copie profonde crée un nouvel objet et copie de manière récursive tous les objets trouvés dans l'original. Cela signifie que même les structures imbriquées sont dupliquées, de sorte que les modifications apportées à une copie n'affectent pas l'autre. Pour créer une copie profonde, vous pouvez utiliser la fonction `
deepcopy()` du module `copy`.
Exemple d'utilisation: Une copie superficielle est appropriée lorsque l'objet ne contient que des éléments immuables ou lorsque vous souhaitez que les modifications apportées aux structures imbriquées soient répercutées dans les deux copies. Une copie profonde est idéale lorsque vous travaillez avec des objets complexes et imbriqués pour lesquels vous souhaitez obtenir une copie entièrement indépendante. Veuillez consulter notre liste de copie Python d': Ce qu'il est important de savoir : Tutoriel pour en savoir plus. Ce tutoriel comprend une section complète sur la différence entre la copie superficielle et la copie profonde.
11. Comment pouvez-vous utiliser le module collections de Python pour simplifier les tâches courantes ?
Le module Python collections fournit des structures de données spécialisées telles que defaultdict, Counter, deque et OrderedDict afin de simplifier diverses tâches. Par exemple, Counter est idéal pour compter les éléments d'un itérable, tandis que defaultdict permet d'initialiser les valeurs d'un dictionnaire sans vérifications explicites.
Exemple :
from collections import Counter
data = ['a', 'b', 'c', 'a', 'b', 'a']
count = Counter(data)
print(count) # Output: Counter({'a': 3, 'b': 2, 'c': 1})Questions d'entretien avancées sur Python
Ces questions d'entretien s'adressent aux praticiens Python plus expérimentés.
12. Qu'est-ce que le monkey patching en Python ?
Le monkey patching en Python est une technique dynamique qui permet de modifier le comportement du code lors de son exécution. En résumé, il est possible de modifier une classe ou un module pendant l'exécution.
Exemple:
Apprenons le monkey patching à l'aide d'un exemple.
-
Nous avons créé une classe
monkeyavec une fonctionpatch(). Nous avons également créé une fonction d'monk_pe en dehors de la classe. -
Nous allons maintenant remplacer la fonction
patchpar la fonctionmonk_pen assignantmonkey.patchàmonk_p. -
Enfin, nous testerons la modification en créant l'objet à l'aide de la classe
monkeyet en exécutant la fonctionpatch().
Au lieu d'afficher patch() is being called, le site a affiché monk_p() is being called.
class monkey:
def patch(self):
print ("patch() is being called")
def monk_p(self):
print ("monk_p() is being called")
# replacing address of "patch" with "monk_p"
monkey.patch = monk_p
obj = monkey()
obj.patch()
# monk_p() is being calledVeuillez noter: Veuillez les utiliser avec parcimonie ; le monkey patching peut rendre votre code plus difficile à lire et surprendre les personnes qui travaillent avec votre code ou vos tests.
13. À quoi sert l'instruction « with » en Python ?
L'instruction « with » est utilisée pour la gestion des exceptions afin de rendre le code plus clair et plus simple. Il est généralement utilisé pour la gestion des ressources communes telles que la création, la modification et l'enregistrement d'un fichier.
Exemple:
Au lieu d'écrire plusieurs lignes d'ouverture, d'essai, de clôture et de fermeture, vous pouvez créer et écrire un fichier texte à l'aide de l'instruction « with ». C'est simple.
# using with statement
with open('myfile.txt', 'w') as file:
file.write('DataCamp Black Friday Sale!!!')14. Pourquoi utiliser else dans la construction try/except en Python ?
try: except: sont généralement connus pour leur gestion exceptionnelle en Python, alors dans quel cas else: s'avère-t-il utile ? else: sera déclenché lorsqu'aucune exception n'est levée.
Exemple:
Veuillez approfondir vos connaissances sur else: à l'aide de quelques exemples.
-
Lors de notre première tentative, nous avons saisi
2comme numérateur etdcomme dénominateur. Ceci est incorrect, et l'exception «except:» a été déclenchée avec le message « Invalid input! ». -
Lors de notre deuxième tentative, nous avons saisi
2comme numérateur et1comme dénominateur, ce qui a donné le résultat2. Aucune exception n'a été soulevée, ce qui a déclenché l'impression du message par l'else:.Division is successful.
try:
num1 = int(input('Enter Numerator: '))
num2 = int(input('Enter Denominator: '))
division = num1/num2
print(f'Result is: {division}')
except:
print('Invalid input!')
else:
print('Division is successful.')
## Try 1 ##
# Enter Numerator: 2
# Enter Denominator: d
# Invalid input!
## Try 2 ##
# Enter Numerator: 2
# Enter Denominator: 1
# Result is: 2.0
# Division is successful.Suivez le cursus Python Fundamentals pour acquérir les compétences fondamentales nécessaires pour devenir programmeur Python.
15. Que sont les décorateurs en Python ?
Les décorateurs en Python constituent un modèle de conception qui permet d'ajouter de nouvelles fonctionnalités à un objet existant sans en modifier la structure. Ils sont couramment utilisés pour étendre le comportement des fonctions ou des méthodes. Vous pouvez en savoir plus sur l'utilisation des décorateurs Python dans un guide séparé.
Exemple :
import functools
def my_decorator(func):
@functools.wraps(func) # preserves __name__, __doc__, etc.
def wrapper(*args, **kwargs):
print("Something is happening before the function is called.")
result = func(*args, **kwargs)
print("Something is happening after the function is called.")
return result
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
# Output:
# Something is happening before the function is called.
# Hello!
# Something is happening after the function is called.16. Que sont les gestionnaires de contexte en Python et comment sont-ils mis en œuvre ?
Les gestionnaires de contexte en Python sont utilisés pour gérer les ressources, en veillant à ce qu'elles soient correctement acquises et libérées. L'utilisation la plus courante des gestionnaires de contexte est l'instruction ` with `.
Exemple :
class FileManager:
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
self.file = open(self.filename, self.mode)
return self.file
def __exit__(self, exc_type, exc_value, traceback):
self.file.close()
with FileManager('test.txt', 'w') as f:
f.write('Hello, world!')Dans cet exemple, la classe ` FileManager ` est un gestionnaire de contexte qui garantit que le fichier est correctement fermé après avoir été utilisé dans l'instruction ` with `.
17. Que sont les métaclasses en Python et en quoi diffèrent-elles des classes classiques ?
Les métaclasses sont des classes de classes. Ils définissent comment les classes se comportent et sont créées. Alors que les classes régulières créent des objets, les métaclasses créent des classes. En utilisant des métaclasses, il est possible de modifier les définitions de classes, d'appliquer des règles ou d'ajouter des fonctionnalités lors de la création de classes.
Exemple :
class Meta(type):
def __new__(cls, name, bases, dct):
print(f"Creating class {name}")
return super().__new__(cls, name, bases, dct)
class MyClass(metaclass=Meta):
pass
# Output: Creating class MyClassQuestions d'entretien sur la science des données avec Python
Pour ceux qui s'intéressent davantage aux applications de Python dans le domaine de la science des données, voici quelques questions que vous pourriez vous poser.
18. Quels sont les avantages de NumPy par rapport aux listes Python classiques ?
NumPy présente plusieurs avantages par rapport aux listes Python classiques, notamment :
- Mémoire: Les tableaux NumPy sont plus efficaces en termes de mémoire que les listes Python, car ils stockent les éléments du même type dans des blocs contigus. (L'utilisation exacte de la mémoire dépend du type d'élément et du système, mais vous pouvez vérifier sur
sys.getsizeofouarray.nbytes.) - Vitesse: NumPy utilise des implémentations C optimisées, ce qui rend les opérations sur les grands tableaux beaucoup plus rapides qu'avec les listes.
- Polyvalence: NumPy prend en charge les opérations vectorisées (par exemple, l'addition, la multiplication) et fournit de nombreuses fonctions mathématiques intégrées que les listes Python ne prennent pas en charge.
19. Quelle est la différence entre fusionner, joindre et concaténer ?
Fusionner
Fusionner deux DataFrames nommés objets de série en utilisant l'identifiant de colonne unique.
Il est nécessaire de disposer de deux DataFrame, d'une colonne commune aux deux DataFrame et de déterminer la manière dont vous souhaitez les joindre. Vous pouvez effectuer une jointure gauche, droite, externe, interne et croisée entre deux DataFrames de données. Par défaut, il s'agit d'une jointure interne.
pd.merge(df1, df2, how='outer', on='Id')Veuillez vous joindre à nous.
Veuillez joindre les DataFrames en utilisant l'index unique. Il nécessite un argument facultatif on qui peut être un nom de colonne ou plusieurs noms de colonnes. Par défaut, la fonction join effectue une jointure gauche.
df1.join(df2)Concaténer
La fonction Concatenate permet de joindre deux ou plusieurs DataFrames selon un axe particulier (lignes ou colonnes). Il n'est pas nécessaire d'utiliser l'argument « on ».
pd.concat(df1,df2)- join(): combine deux DataFrames par index.
- merge(): combine deux DataFrames en fonction de la ou des colonnes que vous spécifiez.
- concat(): combine deux ou plusieurs DataFrames verticalement ou horizontalement.
20. Comment identifiez-vous et gérez-vous les valeurs manquantes ?
Identification des valeurs manquantes
Nous pouvons identifier les valeurs manquantes dans le DataFrame en utilisant la fonction ` isnull() `, puis en appliquant ` sum()`. ` Isnull() ` renverra des valeurs booléennes, et la somme vous donnera le nombre de valeurs manquantes dans chaque colonne.
Dans cet exemple, nous avons créé un dictionnaire de listes et l'avons converti en un DataFrame pandas. Par la suite, nous avons utilisé isnull().sum() pour obtenir le nombre de valeurs manquantes dans chaque colonne.
import pandas as pd
import numpy as np
# dictionary of lists
dict = {'id':[1, 4, np.nan, 9],
'Age': [30, 45, np.nan, np.nan],
'Score':[np.nan, 140, 180, 198]}
# creating a DataFrame
df = pd.DataFrame(dict)
df.isnull().sum()
# id 1
# Age 2
# Score 1Gestion des valeurs manquantes
Il existe plusieurs méthodes pour traiter les valeurs manquantes en Python.
-
Supprimez la ligne entière ou les colonnes si elles contiennent des valeurs manquantes à l'aide de la fonction `
dropna()`. Cette méthode n'est pas recommandée, car vous risquez de perdre des informations importantes. -
Veuillez compléter les valeurs manquantes à l'aide de la constante, de la moyenne, du remplissage vers l'arrière et du remplissage vers l'avant en utilisant la fonction
fillna(). -
Remplacez les valeurs manquantes par une chaîne, un entier ou un nombre flottant constant à l'aide de la fonction
replace(). -
Veuillez compléter les valeurs manquantes à l'aide d'une méthode d'interpolation.
Remarque: veuillez vous assurer que vous travaillez avec un ensemble de données plus volumineux lorsque vous utilisez la fonction dropna().
# drop missing values
df.dropna(axis = 0, how ='any')
#fillna
df.fillna(method ='bfill')
#replace null values with -999
df.replace(to_replace = np.nan, value = -999)
# Interpolate
df.interpolate(method ='linear', limit_direction ='forward')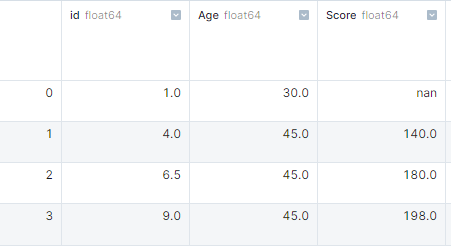
Devenez un professionnel des données en suivant le cursus professionnel Data Scientist avec Python. Il comprend 25 cours et six projets pour vous aider à acquérir toutes les bases de la science des données à l'aide des bibliothèques Python.
21. Quelles bibliothèques Python avez-vous utilisées pour la visualisation ?
La visualisation des données est l'élément le plus important de l'analyse des données. Vous pouvez observer vos données en action, ce qui vous aide à identifier des tendances cachées.
Les bibliothèques Python les plus utilisées pour la visualisation de données sont les suivantes :
- Matplotlib
- Seaborn
- Plotly
- Bokeh
En Python, nous utilisons généralement Matplotlib et seaborn pour afficher tous les types de visualisation de données. Avec quelques lignes de code, vous pouvez l'utiliser pour afficher des nuages de points, des graphiques linéaires, des boîtes à moustaches, des histogrammes et bien d'autres encore.
Pour les applications interactives et plus complexes, nous utilisons Plotly. Vous pouvez l'utiliser pour créer des graphiques interactifs colorés à l'aide de quelques lignes de code. Vous pouvez effectuer un zoom, appliquer des animations et même ajouter des fonctions de contrôle. Plotly propose plus de 40 types de graphiques uniques, et nous pouvons même les utiliser pour créer une application web ou un tableau de bord.
Bokeh est utilisé pour les graphiques détaillés avec un haut niveau d'interactivité sur de grands ensembles de données.
22. Comment normaliseriez-vous ou standardiseriez-vous un ensemble de données en Python ?
La normalisation met les données à l'échelle d'une plage spécifique, généralement [0, 1], tandis que la standardisation les transforme pour obtenir une moyenne de 0 et un écart type de 1. Ces deux techniques sont indispensables pour préparer les données destinées aux modèles d'apprentissage automatique.
Exemple :
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import numpy as np
data = np.array([[1, 2], [3, 4], [5, 6]])
# Normalize
normalizer = MinMaxScaler()
normalized = normalizer.fit_transform(data)
print(normalized)
# Standardize
scaler = StandardScaler()
standardized = scaler.fit_transform(data)
print(standardized)Questions d'entretien sur le codage Python
Si vous avez un entretien d'embauche sur le codage Python, préparer des questions similaires à celles-ci peut vous aider à impressionner le recruteur.
23. Comment remplacer un espace dans une chaîne de caractères par un caractère donné en Python ?
Il s'agit d'un défi simple de manipulation de chaînes de caractères. Il est nécessaire de remplacer l'espace par un caractère spécifique.
Exemple 1: Un utilisateur a fourni la chaîne l vey u et le caractère o, et le résultat sera loveyou.
Exemple 2: Un utilisateur a fourni la chaîne D t C mpBl ckFrid yS le et le caractère a, et le résultat sera DataCampBlackFridaySale.
La méthode la plus simple consiste à utiliser la méthode intégrée str.replace() pour remplacer directement les espaces par le caractère spécifié.
def str_replace(text, ch):
return text.replace(" ", ch)
text = "D t C mpBl ckFrid yS le"
ch = "a"
str_replace(text, ch)
# 'DataCampBlackFridaySale'
24. Étant donné un nombre entier positif num, veuillez créer une fonction qui renvoie True si num est un carré parfait, et False dans le cas contraire.
Il existe une solution relativement simple à ce problème. Vous pouvez vérifier si le nombre possède une racine carrée parfaite en procédant comme suit :
- Utilisation de
math.isqrt(num)pour obtenir la racine carrée entière exacte. - Élever au carré et vérifier si le résultat correspond au nombre initial.
- Renvoyer le résultat sous forme de valeur booléenne.
Test 1
Nous avons attribué le numéro 10 à la valid_square() fonction :
- En calculant la racine carrée entière du nombre, nous obtenons 3.
- Ensuite, veuillez calculer le carré de 3, ce qui donne 9.
- 9 n'est pas égal au nombre, donc la fonction renverra « False ».
Test 2
Nous avons attribué le numéro 36 à la valid_square() fonction :
- En calculant la racine carrée entière du nombre, nous obtenons 6.
- Ensuite, calculez le carré de 6 et obtenez 36.
- 36 correspond au nombre, donc la fonction renverra True.
import math
def valid_square(num):
if num < 0:
return False
square = math.isqrt(num)
return square * square == num
valid_square(10)
# False
valid_square(36)
# True25. Étant donné un nombre entier n, veuillez indiquer le nombre de zéros à la fin de n factoriel n!
Pour réussir ce défi, vous devez d'abord calculer n factoriel (n !), puis calculer le nombre de zéros d'entraînement.
Déterminer la factorielle
Dans un premier temps, nous utiliserons une boucle while pour itérer sur le factoriel de n et nous nous arrêterons lorsque n sera égal à 1.
Calcul des zéros à la fin
Dans la deuxième étape, nous calculerons le nombre de zéros à la fin, et non le nombre total de zéros. Il existe une différence considérable.
7! = 5040Les sept factoriels ont un total de deux zéros et un seul zéro à la fin, donc notre solution devrait renvoyer 1.
- Convertissez le nombre factoriel en chaîne de caractères.
- Veuillez relire et postuler pour une boucle.
- Si le nombre est égal à 0, veuillez ajouter +1 au résultat, sinon, veuillez interrompre la boucle.
- Renvoie le résultat.
La solution est élégante, mais nécessite une attention particulière aux détails.
def factorial_trailing_zeros(n):
fact = n
while n > 1:
fact *= n - 1
n -= 1
result = 0
for i in str(fact)[::-1]:
if i == "0":
result += 1
else:
break
return result
factorial_trailing_zeros(10)
# 2
factorial_trailing_zeros(18)
# 3Suivez le cours essentiel sur les questions d'entretien relatives au codage afin de vous préparer à vos prochains entretiens d'embauche en Python.
26. La chaîne peut-elle être divisée en mots du dictionnaire ?
On vous fournit une chaîne de caractères de grande taille et un dictionnaire contenant les mots. Vous devez déterminer si la chaîne de caractères saisie peut être segmentée en mots à l'aide du dictionnaire.
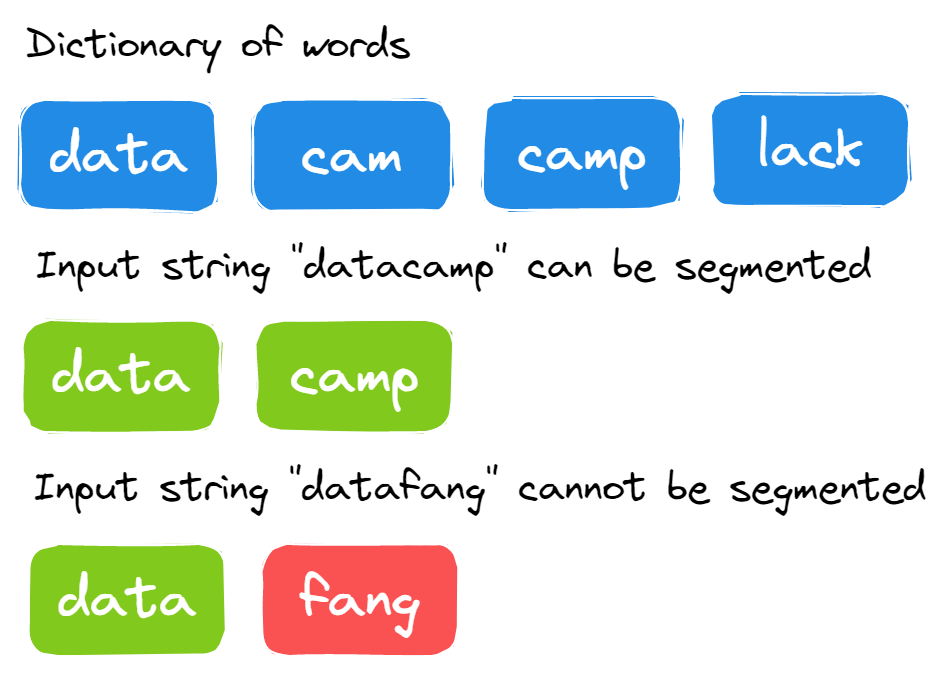
Image par l'auteur
La solution est relativement simple. Il est nécessaire de segmenter une chaîne de caractères longue à chaque point et de vérifier si la chaîne peut être segmentée en mots figurant dans le dictionnaire.
- Exécutez la boucle en utilisant la longueur de la grande chaîne.
- Nous allons créer deux sous-chaînes.
- La première sous-chaîne vérifiera chaque point de la grande chaîne à partir de
s[0:i]. - Si la première sous-chaîne n'est pas présente dans le dictionnaire, la fonction renverra la valeur « False ».
- Si la première sous-chaîne se trouve dans le dictionnaire, la deuxième sous-chaîne sera créée à l'aide de
s[i:]. - Si la deuxième sous-chaîne figure dans le dictionnaire ou si la deuxième sous-chaîne a une longueur nulle, renvoyer True. Appelez récursivement
can_segment_str()avec la deuxième sous-chaîne et renvoyez True si elle peut être segmentée. - Afin de rendre la solution plus efficace pour les chaînes plus longues, nous ajoutons la mémorisation. mémorisation afin que les sous-chaînes ne soient pas recalculées à plusieurs reprises.
def can_segment_str(s, dictionary, memo=None):
if memo is None:
memo = {}
if s in memo:
return memo[s]
if not s:
return True
for i in range(1, len(s) + 1):
first_str = s[0:i]
if first_str in dictionary:
second_str = s[i:]
if (
not second_str
or second_str in dictionary
or can_segment_str(second_str, dictionary, memo)
):
memo[s] = True
return True
memo[s] = False
return False
s = "datacamp"
dictionary = ["data", "camp", "cam", "lack"]
can_segment_str(s, dictionary)
# True27. Est-il possible de supprimer les doublons d'un tableau trié ?
Étant donné un tableau d'entiers triés par ordre croissant, veuillez supprimer les doublons afin que chaque élément unique n'apparaisse qu'une seule fois. Étant donné que les listes Python ne modifient pas leur longueur sur place pour ce problème, veuillez placer les résultats dans les k premières positions du même tableau et renvoyer k (la nouvelle longueur). Seuls les k premiers éléments sont valides après l'appel ; les éléments au-delà de k sont périmés.
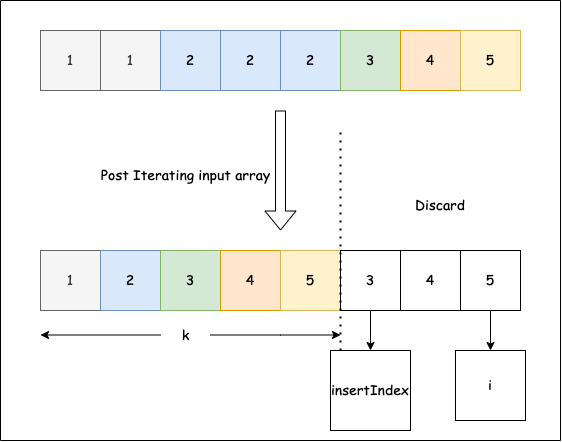
Image provenant de LeetCode
Exemple 1: le tableau d'entrée est [1,1,2,2], la fonction doit renvoyer 2.
Exemple 2: le tableau d'entrée est [1,1,2,3,3], la fonction doit renvoyer 3.
Solution:
- Exécutez une boucle de l'index 1 à la fin. Veuillez comparer l'élément actuel avec l'élément unique précédent ; s'ils sont différents, veuillez l'inscrire à l'adresse
insertIndexet incrémenterinsertIndex. Veuillez nous contacter à l'adresse suivante :insertIndex. - Renvoyer
insertIndexcar il s'agit de k.
Cette question est relativement simple une fois que l'on sait comment procéder. Si vous consacrez davantage de temps à la compréhension de la déclaration, vous pouvez facilement trouver une solution.
def removeDuplicates(array):
size = len(array)
if size == 0:
return 0
insertIndex = 1
for i in range(1, size):
if array[i - 1] != array[i]:
array[insertIndex] = array[i]
insertIndex += 1
return insertIndex
array_1 = [1, 2, 2, 3, 3, 4]
k1 = removeDuplicates(array_1)
# 4; array_1[:k1] -> [1, 2, 3, 4]
array_2 = [1, 1, 3, 4, 5, 6, 6]
k2 = removeDuplicates(array_2)
# 5; array_2[:k2] -> [1, 3, 4, 5, 6]
28. Pourriez-vous identifier le nombre manquant dans le tableau ?
On vous a fourni la liste des nombres entiers positifs compris entre 1 et n. Tous les nombres de 1 à n sont présents, à l'exception de x, et il est nécessaire de déterminer x.
Exemple:
|
4 |
5 |
3 |
2 |
8 |
1 |
6 |
- n = 8
- nombre manquant = 7
Cette question est un simple problème mathématique.
- Veuillez calculer la somme de tous les éléments de la liste.
- En utilisant la formule de la somme d'une série arithmétique, nous déterminerons la somme attendue des n premiers nombres.
- Renvoie la différence entre la somme attendue et la somme des éléments.
def find_missing(input_list):
sum_of_elements = sum(input_list)
# There is exactly 1 number missing
n = len(input_list) + 1
actual_sum = (n * ( n + 1 ) ) / 2
return int(actual_sum - sum_of_elements)
list_1 = [1,5,6,3,4]
find_missing(list_1)
# 229. Écrivez une fonction Python pour déterminer si une chaîne donnée est un palindrome.
Une chaîne est un palindrome si elle se lit de la même manière dans les deux sens.
Exemple :
def is_palindrome(s):
s = ''.join(e for e in s if e.isalnum()).lower() # Remove non-alphanumeric and convert to lowercase
return s == s[::-1]
print(is_palindrome("A man, a plan, a canal: Panama")) # Output: True
print(is_palindrome("hello")) # Output: FalseQuestions d'entretien Python pour Facebook, Amazon, Apple, Netflix et Google
Ci-dessous, nous avons sélectionné quelques-unes des questions auxquelles vous pourriez être confronté pour les postes les plus recherchés dans les secteurs d'activité, notamment chez Meta, Amazon, Google et autres.
Questions d'entretien Python chez Facebook/Meta
Les questions précises qui vous seront posées chez Meta dépendent en grande partie du poste. Cependant, vous pouvez vous attendre à certaines des situations suivantes :
30. Pourriez-vous déterminer le bénéfice maximal sur une seule vente ?
On vous fournit la liste des cours boursiers, et vous devez indiquer le prix d'achat et de vente afin de réaliser le profit le plus élevé.
Remarque: Nous devons maximiser les bénéfices de chaque transaction d'achat/vente, et si nous ne pouvons pas réaliser de bénéfices, nous devons minimiser nos pertes.
Exemple 1: cours_action = [8, 4, 12, 9, 20, 1], achat = 4 et vente = 20. Optimisation des bénéfices.
Exemple 2: cours_action = [8, 6, 5, 4, 3, 2, 1], achat = 6 et vente = 5. Réduire au minimum les pertes.
Solution:
- Nous calculerons le bénéfice global en soustrayant la vente globale (premier élément de la liste) de l'achat actuel (deuxième élément de la liste).
- Exécutez la boucle pour la plage comprise entre 1 et la longueur de la liste.
- Dans la boucle, veuillez calculer le bénéfice actuel en utilisant les éléments de la liste et la valeur d'achat actuelle.
- Si le bénéfice actuel est supérieur au bénéfice global, veuillez remplacer le bénéfice global par le bénéfice actuel et vendre globalement l'élément i de la liste.
- Si l'achat actuel est supérieur à l'élément actuel de la liste, veuillez remplacer l'achat actuel par l'élément actuel de la liste.
- Enfin, nous fournirons la valeur globale d'achat et de vente. Pour obtenir la valeur d'achat globale, nous soustrayons la valeur de vente globale du bénéfice global.
La question est quelque peu délicate, et vous pouvez concevoir votre propre algorithme pour résoudre les problèmes.
def buy_sell_stock_prices(stock_prices):
current_buy = stock_prices[0]
global_sell = stock_prices[1]
global_profit = global_sell - current_buy
for i in range(1, len(stock_prices)):
current_profit = stock_prices[i] - current_buy
if current_profit > global_profit:
global_profit = current_profit
global_sell = stock_prices[i]
if current_buy > stock_prices[i]:
current_buy = stock_prices[i]
return global_sell - global_profit, global_sell
stock_prices_1 = [10,9,16,17,19,23]
buy_sell_stock_prices(stock_prices_1)
# (9, 23)
stock_prices_2 = [8, 6, 5, 4, 3, 2, 1]
buy_sell_stock_prices(stock_prices_2)
# (6, 5)Questions d'entretien Python chez Amazon
Les questions d'entretien Python chez Amazon peuvent varier considérablement, mais peuvent inclure :
31. Pourriez-vous identifier un triplet pythagoricien dans un tableau ?
Écrivez une fonction qui renvoie « True » s'il existe un triplet pythagoricien qui satisfait a² + b² = c².
Exemple:
|
Entrée |
Sortie |
|
[3, 1, 4, 6, 5] |
Vrai |
|
[10, 4, 6, 12, 5] |
Faux |
Solution:
-
Élevez tous les éléments du tableau au carré.
-
Veuillez trier le tableau par ordre croissant.
-
Veuillez effectuer deux boucles. La boucle externe commence à partir du dernier index du tableau jusqu'à 1, et la boucle interne commence à partir de (
outer_loop_index - 1) jusqu'au début. -
Veuillez créer un
set()pour stocker les éléments entre l'index de la boucle externe et l'index de la boucle interne. -
Veuillez vérifier s'il existe un nombre dans l'ensemble qui est égal à
(array[outerLoopIndex] – array[innerLoopIndex]). Si oui, veuillez renvoyerTrue, sinonFalse.
def checkTriplet(array):
n = len(array)
for i in range(n):
array[i] = array[i]**2
array.sort()
for i in range(n - 1, 1, -1):
s = set()
for j in range(i - 1, -1, -1):
if (array[i] - array[j]) in s:
return True
s.add(array[j])
return False
arr = [3, 2, 4, 6, 5]
checkTriplet(arr)
# True32. De combien de façons différentes pouvez-vous rendre la monnaie avec des pièces et un montant total ?
Nous devons créer une fonction qui prend en entrée une liste de valeurs de pièces et un montant total, et qui renvoie le nombre de façons possibles de rendre la monnaie.
Dans l'exemple, nous avons fourni des coupures de pièces de [1, 2, 5] et le montant total de 5. En retour, nous recevons quatre méthodes pour effectuer le changement.
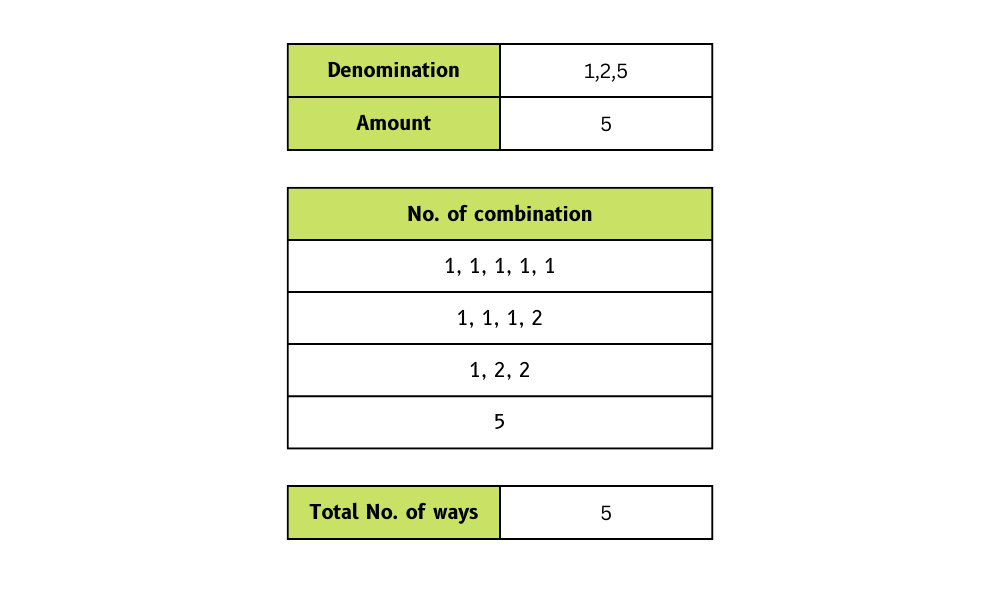
Image par l'auteur
Solution:
- Nous allons créer la liste de tailles
amount + 1. Un espace supplémentaire est ajouté pour stocker la solution sans frais supplémentaires. - Nous allons établir une liste de solutions avec
solution[0] = 1. - Nous effectuerons deux boucles. La boucle externe parcourt les dénominations, tandis que la boucle interne s'exécute à partir de la valeur de dénomination actuelle jusqu'à
amount + 1. - Les résultats des différentes dénominations sont stockés dans le tableau solution.
solution[i] = solution[i] + solution[i - den].
Le processus sera répété pour tous les éléments de la liste des dénominations, et au dernier élément de la liste des solutions, nous obtiendrons notre nombre.
def solve_coin_change(denominations, amount):
solution = [0] * (amount + 1)
solution[0] = 1
for den in denominations:
for i in range(den, amount + 1):
solution[i] += solution[i - den]
return solution[amount]
denominations = [1, 2, 5]
amount = 5
solve_coin_change(denominations, amount)
# 4Questions d'entretien Python chez Google
Comme pour les autres entreprises mentionnées, les questions posées lors des entretiens chez Google Python dépendront du poste et du niveau d'expérience. Cependant, voici quelques questions fréquentes :
33. Définissez une fonction lambda, un itérateur et un générateur en Python.
La fonction Lambda est également connue sous le nom de fonction anonyme. Vous pouvez ajouter autant de paramètres que nécessaire, mais avec une seule instruction.
Un itérateur est un objet que nous pouvons utiliser pour parcourir des objets itérables tels que des listes, des dictionnaires, des tuples et des ensembles.
Le générateur est une fonction similaire à une fonction normale, mais il génère une valeur en utilisant le mot-clé yield au lieu de return. Si le corps de la fonction contient yield, il devient automatiquement un générateur.
Pour en savoir plus sur les itérateurs et les générateurs Python, veuillez consulter notre tutoriel complet.
34. Étant donné un tableau arr[], déterminez la valeur maximale j – i telle que arr[j] > arr[i].
Cette question est assez simple, mais nécessite une attention particulière aux détails. Nous disposons d'un ensemble d'entiers positifs. Nous devons déterminer la différence maximale entre j et i lorsque tableau[j] est supérieur à tableau[i].
Exemples:
- Entrée : [20, 70, 40, 50, 12, 38, 98], Sortie : 6 (j = 6, i = 0)
- Entrée : [10, 3, 2, 4, 5, 6, 7, 8, 18, 0], Sortie : 8 (j = 8, i = 0)
Solution:
- Veuillez calculer la longueur du tableau et initialiser la différence maximale avec -1.
- Veuillez effectuer deux boucles. La boucle externe sélectionne les éléments à partir de la gauche, et la boucle interne compare les éléments sélectionnés avec les éléments à partir de la droite.
- Veuillez interrompre la boucle interne lorsque l'élément est supérieur à l'élément sélectionné et continuer à mettre à jour la différence maximale en utilisant j - I.
def max_index_diff(array):
n = len(array)
max_diff = -1
for i in range(0, n):
j = n - 1
while(j > i):
if array[j] > array[i] and max_diff < (j - i):
max_diff = j - i
j -= 1
return max_diff
array_1 = [20,70,40,50,12,38,98]
max_index_diff(array_1)
# 635. Comment utiliseriez-vous les opérateurs ternaires en Python ?
Les opérateurs ternaires sont également appelés expressions conditionnelles. Ce sont des opérateurs qui évaluent une expression en fonction de conditions vraies ou fausses.
Vous pouvez écrire des expressions conditionnelles sur une seule ligne au lieu d'utiliser plusieurs lignes d'instructions if-else. Il vous permet d'écrire un code clair et concis.
Par exemple, nous pouvons convertir les instructions if-else imbriquées en une seule ligne, comme illustré ci-dessous.
Instruction if-else
score = 75
if score < 70:
if score < 50:
print('Fail')
else:
print('Merit')
else:
print('Distinction')
# DistinctionOpérateur ternaire imbriqué
print('Fail' if score < 50 else 'Merit' if score < 70 else 'Distinction')
# Distinction36. Comment implémenteriez-vous un cache LRU en Python ?
Python fournit un décorateur intégré functools.lru_cache pour implémenter un cache LRU (Least Recently Used, moins récemment utilisé). Vous pouvez également en créer un manuellement à l'aide de l'outil de création de fichiers de configuration ( OrderedDict ) disponible à l'adresse collections.
Exemple utilisant functools:
from functools import lru_cache
@lru_cache(maxsize=3)
def add(a, b):
return a + b
print(add(1, 2)) # Calculates and caches result
print(add(1, 2)) # Retrieves result from cacheAméliorer les compétences de votre équipe grâce à Python
Si la préparation aux entretiens Python est essentielle pour les candidats et les responsables du recrutement, il est tout aussi important pour les entreprises d'investir dans la formation continue de leurs équipes à Python. À une époque où l'automatisation, l'analyse de données et le développement de logiciels sont essentiels, veiller à ce que vos employés possèdent de solides compétences en Python peut constituer un facteur déterminant pour la réussite de votre entreprise.
Si vous êtes chef d'équipe ou chef d'entreprise et que vous souhaitez vous assurer que l'ensemble de votre équipe maîtrise Python, DataCamp for Business propose des programmes de formation sur mesure qui peuvent aider vos employés à acquérir des compétences en Python, des notions de base aux concepts avancés. Nous sommes en mesure de fournir :
- Parcours d'apprentissage ciblés: Adaptable au niveau de compétence actuel de votre équipe et aux besoins spécifiques de votre entreprise.
- Pratique pratique: Projets concrets et exercices de codage qui renforcent l'apprentissage et améliorent la mémorisation.
- Suivi des progrès: Outils permettant de suivre et d'évaluer les progrès de votre équipe, en veillant à ce qu'elle atteigne ses objectifs d'apprentissage.
Investir dans le perfectionnement des compétences en Python via des plateformes telles que DataCamp permet non seulement d'améliorer les capacités de votre équipe, mais également de donner à votre entreprise un avantage stratégique, vous permettant d'innover, de rester compétitif et d'obtenir des résultats significatifs. Veuillez contacter notre équipe et demander une démonstration dès aujourd'hui.
Améliorez les compétences de votre équipe en Python
Formez votre équipe à Python avec DataCamp for Business. Une formation complète, des projets pratiques et des indicateurs de performance détaillés pour votre entreprise.
