
Obter uma certificação Top Data
Perguntas básicas sobre Python para entrevistas
Essas são algumas das perguntas que você pode encontrar durante uma entrevista inicial sobre Python.
1. O que é Python e liste algumas de suas principais características.
Python é uma linguagem de programação versátil e de alto nível, conhecida por sua sintaxe fácil de ler e amplas aplicações. Aqui estão algumas das principais características do Python:
- Sintaxe simples e fácil de entender: A sintaxe do Python é clara e direta, o que o torna acessível para quem está começando e eficiente para desenvolvedores experientes.
- Idioma interpretado: O Python executa o código linha por linha, o que ajuda na depuração e nos testes.
- Tipagem dinâmica: Python não precisa de declarações explícitas de tipos de dados, o que dá mais flexibilidade.
- Bibliotecas e estruturas extensas: Bibliotecas como NumPy, Pandas e Django aumentam as funcionalidades do Python para tarefas específicas em ciência de dados, desenvolvimento web e muito mais.
- Compatibilidade entre plataformas: Python pode rodar em diferentes sistemas operacionais, incluindo Windows, macOS e Linux.
2. O que são listas e tuplas em Python?
Listas e tuplas são estruturas de dados fundamentais do Python, com características e casos de uso distintos.
Lista:
- Mutável: Os elementos podem ser alterados depois de criados.
- Uso da memória: Consome mais memória.
- Desempenho: Iteração mais lenta em comparação com tuplas, mas melhor para operações de inserção e exclusão.
- Métodos: Oferece vários métodos integrados para manipulação.
Exemplo:
a_list = ["Data", "Camp", "Tutorial"]
a_list.append("Session")
print(a_list) # Output: ['Data', 'Camp', 'Tutorial', 'Session']Tupla:
- Imutável: Os elementos não podem ser alterados após a criação.
- Uso da memória: Consome menos memória.
- Desempenho: Iteração mais rápida em comparação com listas, mas sem a flexibilidade das listas.
- Métodos: Métodos integrados limitados.
Exemplo:
a_tuple = ("Data", "Camp", "Tutorial")
print(a_tuple) # Output: ('Data', 'Camp', 'Tutorial')Saiba mais no nosso tutorial sobre listas em Python.
3. O que é __init__() em Python?
O método ` __init__() ` é conhecido como construtor na linguagem de programação orientada a objetos (OOP). É usado para inicializar o estado de um objeto quando ele é criado. Esse método é chamado automaticamente quando uma nova instância de uma classe é instanciada.
Objetivo:
- Atribua valores às propriedades do objeto.
- Faça as operações de inicialização.
Exemplo:
Criamos uma classe book_shop e adicionamos o construtor e a função book(). O construtor vai guardar o nome do livro e a função ` book() ` vai imprimir o nome do livro.
Para testar nosso código, inicializamos o objeto b com “Sandman” e executamos a função book().
class book_shop:
# constructor
def __init__(self, title):
self.title = title
# Sample method
def book(self):
print('The tile of the book is', self.title)
b = book_shop('Sandman')
b.book()
# The tile of the book is Sandman4. Qual é a diferença entre um tipo de dados mutável e um tipo de dados imutável?
Tipos de dados mutáveis:
- Definição: Tipos de dados mutáveis são aqueles que podem ser modificados depois de criados.
- Exemplos: Lista, Dicionário, Conjunto.
- Características: Os elementos podem ser adicionados, removidos ou alterados.
- Caso de uso: Ótimo pra coleções de itens que precisam de atualizações frequentes.
Exemplo:
# List Example
a_list = [1, 2, 3]
a_list.append(4)
print(a_list) # Output: [1, 2, 3, 4]
# Dictionary Example
a_dict = {'a': 1, 'b': 2}
a_dict['c'] = 3
print(a_dict) # Output: {'a': 1, 'b': 2, 'c': 3}Tipos de dados imutáveis:
- Definição: Tipos de dados imutáveis são aqueles que não podem ser modificados depois de criados.
- Exemplos: Numérico (int, float), String, Tupla.
- Características: Os elementos não podem ser alterados depois de definidos; qualquer operação que pareça modificar um objeto imutável criará um novo objeto.
Exemplo:
# Numeric Example
a_num = 10
a_num = 20 # Creates a new integer object
print(a_num) # Output: 20
# String Example
a_str = "hello"
a_str = "world" # Creates a new string object
print(a_str) # Output: world
# Tuple Example
a_tuple = (1, 2, 3)
# a_tuple[0] = 4 # This will raise a TypeError
print(a_tuple) # Output: (1, 2, 3)5. Explique a compreensão de listas, dicionários e tuplas com um exemplo.
Lista
A compreensão de lista oferece uma sintaxe de uma linha para criar uma nova lista com base nos valores da lista existente. Você pode usar um loop “ for ” para fazer a mesma coisa, mas vai precisar escrever várias linhas e, às vezes, pode ficar complicado.
A compreensão de listas facilita a criação de listas com base em iteráveis existentes.
my_list = [i for i in range(1, 10)]
my_list
# [1, 2, 3, 4, 5, 6, 7, 8, 9]Dicionário
Parecido com uma compreensão de lista, você pode criar um dicionário com base em uma tabela já existente usando só uma linha de código. Você precisa colocar a operação entre chaves {}.
# Creating a dictionary using dictionary comprehension
my_dict = {i: i**2 for i in range(1, 10)}
# Output the dictionary
my_dict
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}Tupla
Diferente das listas e dicionários, não tem nenhuma “compreensão de tupla” especial.
Quando você usa parênteses com uma compreensão, o Python na verdade cria uma expressão geradora, não uma tupla. Para obter uma tupla, você precisa converter o gerador com tuple() ou definir uma tupla literal diretamente.
# Generator expression (not a tuple)
my_gen = (i for i in range(1, 10))
my_gen
# <generator object <genexpr> ...>
# Converting generator to tuple
my_tuple = tuple(i for i in range(1, 10))
my_tuple
# (1, 2, 3, 4, 5, 6, 7, 8, 9)
# Or simply define a tuple directly
literal_tuple = (1, 2, 3)
literal_tuple
# (1, 2, 3)
Você pode saber mais sobre isso no nosso tutorial sobre tuplas em Python.
6. O que é o Global Interpreter Lock (GIL) em Python e por que ele é importante?
O Global Interpreter Lock (GIL) é um mutex no CPython (a implementação de referência do Python) que garante que só um thread nativo execute o bytecode Python de cada vez. Isso simplifica o gerenciamento de memória, protegendo estruturas de dados internas, como contagens de referência, mas também limita o paralelismo real em tarefas dependentes da CPU, tornando o multithreading menos eficaz para cargas de trabalho computacionais. Mas funciona bem para tarefas ligadas a E/S, onde os threads ficam esperando por operações de rede, arquivo ou banco de dados.
Observação: O Python 3.13 trouxe uma versão experimental sem GIL (PEP 703), e o Python 3.14 adiciona suporte documentado para threads livres. Algumas extensões e bibliotecas C podem ainda não ser totalmente compatíveis.
Perguntas intermediárias sobre Python para entrevistas
Aqui estão algumas das perguntas que você pode encontrar durante uma entrevista de nível intermediário sobre Python.
7. Você podeexplicar os algoritmos comuns de pesquisa e percorrer grafos em Python?
Python tem vários algoritmos poderosos para pesquisa e percorrer grafos, e cada um lida com diferentes estruturas de dados e resolve diferentes problemas. Eu posso ouvi-los aqui:
- Pesquisa binária: Se você precisa encontrar rapidamente um item em uma lista ordenada, a pesquisa binária é a melhor opção. Funciona dividindo várias vezes a área de busca ao meio até encontrar o que procura.
- Árvore AVL: Uma árvore AVL mantém tudo equilibrado, o que é uma grande vantagem se você costuma inserir ou excluir itens em uma árvore. Essa estrutura de árvore binária de busca auto-balanceada mantém as buscas rápidas, garantindo que a árvore nunca fique muito desequilibrada.
- Busca em Largura (BFS): O BFS é basicamente explorar um gráfico nível por nível. É especialmente útil se você estiver tentando encontrar o caminho mais curto em um gráfico não ponderado, pois ele verifica todos os movimentos possíveis de cada nó antes de aprofundar.
- Pesquisa em profundidade (DFS): O DFS faz diferente, explorando o máximo possível cada ramificação antes de voltar atrás. É ótimo pra tarefas como resolver labirintos ou percorrer árvores.
- Algoritmo A*: O algoritmo A* é um pouco mais avançado e junta o melhor do BFS e do DFS usando heurística pra achar o caminho mais curto de forma eficiente. É muito usado pra encontrar caminhos em mapas e jogos.
8. O que é um KeyError em Python e como você pode lidar com ele?
Um erro “ KeyError ” em Python rola quando você tenta acessar uma chave que não existe em um dicionário. Esse erro aparece porque o Python espera que todas as chaves que você procura estejam no dicionário e, quando não estão, ele mostra um erro de “ KeyError ”.
Por exemplo, se você tiver um dicionário com as notas dos alunos e tentar acessar um aluno que não está no dicionário, você receberá uma exceção “ KeyError ”. Para resolver esse erro, você tem algumas opções:
-
Use o método .get(): Esse método retorna um erro de “
None” (ou um valor padrão especificado) em vez de lançar um erro se a chave não for encontrada. -
Use um bloco try-except: Envolver seu código em
try-exceptpermite capturar a exceçãoKeyErrore lidar com ela de maneira elegante. -
Procure a chave com: Você pode ver se uma chave tá no dicionário usando o método `
if key in dictionary` antes de tentar acessá-la.
Para saber mais, dá uma olhada no nosso tutorial completo: Exceções KeyError do Python e como corrigi-las.
9. Como o Python lida com o gerenciamento de memória e qual é o papel da coleta de lixo?
O Python cuida da alocação e desalocação de memória automaticamente usando uma pilha privada, onde todos os objetos e estruturas de dados ficam guardados. O gerenciamento de memória é feito pelo gerenciador de memória do Python, que otimiza o uso da memória, e pelo coletor de lixo, que cuida dos objetos que não estão sendo usados ou referenciados para liberar memória.
A coleta de lixo no Python usa contagem de referências e um coletor de lixo cíclico para detectar e coletar dados não usados. Quando um objeto não tem mais referências, ele pode ser eliminado pela coleta de lixo. O módulo ` gc ` em Python permite que você interaja diretamente com o coletor de lixo, oferecendo funções para ativar ou desativar a coleta de lixo, bem como para fazer a coleta manualmente.
10. Qual é a diferença entre cópia superficial e cópia profunda em Python, e quando você usaria cada uma delas?
Em Python, cópias superficiais e profundas são usadas para duplicar objetos, mas elas lidam com estruturas aninhadas de maneira diferente.
-
Cópia superficial: Uma cópia superficial cria um novo objeto, mas coloca referências aos objetos encontrados no original. Então, se o objeto original tiver outros objetos mutáveis (como listas dentro de listas), a cópia superficial vai referenciar os mesmos objetos internos. Isso pode causar mudanças inesperadas se você mexer em um desses objetos internos, seja na estrutura original ou na copiada. Você pode criar uma cópia superficial usando o método `
copy()` ou a função `copy()` do módulo `copy`. -
Cópia profunda: Uma cópia profunda cria um novo objeto e copia recursivamente todos os objetos encontrados no original. Isso quer dizer que até as estruturas aninhadas são duplicadas, então as mudanças em uma cópia não afetam a outra. Para criar uma cópia profunda, você pode usar a função `
deepcopy()` do módulo `copy`.
Exemplo de uso: Uma cópia superficial é legal quando o objeto só tem itens imutáveis ou quando você quer que as mudanças nas estruturas aninhadas apareçam nas duas cópias. Uma cópia profunda é ideal quando você está trabalhando com objetos complexos e aninhados, nos quais você quer uma duplicata totalmente independente. Dá uma olhada na nossa lista de exemplos em Python “ ”: O que você precisa saber tutorial para saber mais. Este tutorial tem uma seção inteira sobre a diferença entre cópia superficial e cópia profunda.
11. Como você pode usar o módulo collections do Python para simplificar tarefas comuns?
O módulo collections em Python oferece estruturas de dados específicas, como defaultdict, Counter, deque e OrderedDict, para facilitar várias tarefas. Por exemplo, Counter é ideal para contar elementos em um iterável, enquanto defaultdict pode inicializar valores de dicionário sem verificações explícitas.
Exemplo:
from collections import Counter
data = ['a', 'b', 'c', 'a', 'b', 'a']
count = Counter(data)
print(count) # Output: Counter({'a': 3, 'b': 2, 'c': 1})Perguntas avançadas sobre Python para entrevistas
Essas perguntas da entrevista são para profissionais mais experientes em Python.
12. O que é monkey patching em Python?
Monkey patching em Python é uma técnica dinâmica que pode mudar o comportamento do código durante a execução. Resumindo, você pode modificar uma classe ou módulo durante a execução.
Exemplo:
Vamos aprender monkey patching com um exemplo.
-
Criamos uma classe
monkeycom uma funçãopatch(). Também criamos uma funçãomonk_pfora da classe. -
Agora vamos trocar a função
patchpela funçãomonk_p, colocandomonkey.patchemmonk_p. -
No final, vamos testar a modificação criando o objeto usando a classe `
monkey` e executando a função `patch()`.
Em vez de mostrar patch() is being called, apareceu monk_p() is being called.
class monkey:
def patch(self):
print ("patch() is being called")
def monk_p(self):
print ("monk_p() is being called")
# replacing address of "patch" with "monk_p"
monkey.patch = monk_p
obj = monkey()
obj.patch()
# monk_p() is being calledCuidado: Use isso com moderação; o monkey patching pode tornar seu código mais difícil de ler e pode surpreender outras pessoas que trabalham com seu código ou testes.
13. Pra que serve a instrução “with” do Python?
A instrução ` with ` é usada para lidar com exceções, deixando o código mais limpo e simples. É geralmente usado para gerenciar recursos comuns, como criar, editar e salvar um arquivo.
Exemplo:
Em vez de escrever várias linhas de open, try, finally e close, você pode criar e escrever um arquivo de texto usando a instrução with. É simples.
# using with statement
with open('myfile.txt', 'w') as file:
file.write('DataCamp Black Friday Sale!!!')14. Por que usar else na construção try/except em Python?
try: except: são bem conhecidos por lidar super bem com Python, então onde else: pode ser útil? else: vai ser acionado quando nenhuma exceção for levantada.
Exemplo:
Vamos aprender mais sobre o else: com alguns exemplos.
-
Na primeira tentativa, colocamos
2como numerador edcomo denominador. Isso está errado, e foi acionado um erro de “Entrada inválida!” (except:). -
Na segunda tentativa, colocamos
2como numerador e1como denominador e obtivemos o resultado2. Nenhuma exceção foi levantada, então isso acionou oelse:, que mostrou a mensagem.Division is successful.
try:
num1 = int(input('Enter Numerator: '))
num2 = int(input('Enter Denominator: '))
division = num1/num2
print(f'Result is: {division}')
except:
print('Invalid input!')
else:
print('Division is successful.')
## Try 1 ##
# Enter Numerator: 2
# Enter Denominator: d
# Invalid input!
## Try 2 ##
# Enter Numerator: 2
# Enter Denominator: 1
# Result is: 2.0
# Division is successful.Faça o programa Python Fundamentals para aprender as habilidades básicas que você precisa para se tornar um programador Python.
15. O que são decoradores em Python?
Decoradores em Python são um padrão de design que permite adicionar novas funcionalidades a um objeto já existente sem mexer na sua estrutura. Eles são geralmente usados para ampliar o comportamento de funções ou métodos. Você pode ler mais sobre como usar decoradores Python em um guia separado.
Exemplo:
import functools
def my_decorator(func):
@functools.wraps(func) # preserves __name__, __doc__, etc.
def wrapper(*args, **kwargs):
print("Something is happening before the function is called.")
result = func(*args, **kwargs)
print("Something is happening after the function is called.")
return result
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
# Output:
# Something is happening before the function is called.
# Hello!
# Something is happening after the function is called.16. O que são gerenciadores de contexto em Python e como eles são implementados?
Os gerenciadores de contexto em Python são usados para gerenciar recursos, garantindo que eles sejam obtidos e liberados da maneira certa. O uso mais comum dos gerenciadores de contexto é a instrução ` with `.
Exemplo:
class FileManager:
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
self.file = open(self.filename, self.mode)
return self.file
def __exit__(self, exc_type, exc_value, traceback):
self.file.close()
with FileManager('test.txt', 'w') as f:
f.write('Hello, world!')Neste exemplo, a classe ` FileManager ` é um gerenciador de contexto que garante que o arquivo seja fechado corretamente depois de ser usado na instrução ` with `.
17. O que são metaclasses em Python e como elas diferem das classes normais?
Metaclasses são classes de classes. Elas definem como as classes se comportam e são criadas. Enquanto as classes normais criam objetos, as metaclasses criam classes. Usando metaclasses, você pode modificar definições de classe, aplicar regras ou adicionar funcionalidades durante a criação da classe.
Exemplo:
class Meta(type):
def __new__(cls, name, bases, dct):
print(f"Creating class {name}")
return super().__new__(cls, name, bases, dct)
class MyClass(metaclass=Meta):
pass
# Output: Creating class MyClassPerguntas para entrevistas sobre ciência de dados em Python
Pra quem tá mais ligado nas aplicações de ciência de dados do Python, aqui vão algumas perguntas que você pode encontrar.
18. Quais são as vantagens do NumPy em relação às listas Python normais?
O NumPy tem várias vantagens em relação às listas Python normais, como:
- Memória: As matrizes NumPy são mais eficientes em termos de memória do que as listas Python, porque armazenam elementos do mesmo tipo em blocos contíguos. (O uso exato da memória depende do tipo de elemento e do sistema, mas você pode conferir em
sys.getsizeofouarray.nbytes.) - Velocidade: O NumPy usa implementações C otimizadas, então as operações em grandes matrizes são bem mais rápidas do que com listas.
- Versatilidade: O NumPy suporta operações vetorizadas (por exemplo, adição, multiplicação) e oferece várias funções matemáticas integradas que as listas Python não suportam.
19. Qual é a diferença entre mesclar, unir e concatenar?
Mesclar
Junte dois DataFrames chamados objetos de série usando o identificador de coluna único.
É preciso dois DataFrame, uma coluna comum nos dois DataFrame e “como” você quer juntar eles. Você pode fazer uma junção esquerda, direita, externa, interna e cruzada entre dois DataFrame de dados. Por padrão, é uma junção interna.
pd.merge(df1, df2, how='outer', on='Id')Participe
Junte os DataFrames usando o índice exclusivo. É preciso um argumento opcional on, que pode ser o nome de uma coluna ou de várias colunas. Por padrão, a função join faz uma junção à esquerda.
df1.join(df2)Concatenar
Concatenar junta dois ou mais DataFrames ao longo de um eixo específico (linhas ou colunas). Não precisa de um argumento on.
pd.concat(df1,df2)- join(): junta dois DataFrame pelo índice.
- merge(): junta dois DataFrame pelas colunas que você escolher.
- concat(): junta dois ou mais DataFrames na vertical ou na horizontal.
20. Como você identifica e lida com valores ausentes?
Identificando valores ausentes
A gente pode identificar valores ausentes no DataFrame usando a função ` isnull() ` e, em seguida, aplicando ` sum()`. ` Isnull() ` retornará valores booleanos, e a soma fornecerá o número de valores ausentes em cada coluna.
No exemplo, criamos um dicionário de listas e o convertemos em um DataFrame do pandas. Depois disso, usamos isnull().sum() para obter o número de valores ausentes em cada coluna.
import pandas as pd
import numpy as np
# dictionary of lists
dict = {'id':[1, 4, np.nan, 9],
'Age': [30, 45, np.nan, np.nan],
'Score':[np.nan, 140, 180, 198]}
# creating a DataFrame
df = pd.DataFrame(dict)
df.isnull().sum()
# id 1
# Age 2
# Score 1Lidando com valores ausentes
Tem várias maneiras de lidar com valores ausentes no Python.
-
Se tiver valores faltando, dá um jeito de tirar a linha inteira ou as colunas usando o comando `
dropna()`. Esse jeito não é recomendado, porque você vai perder informações importantes. -
Preencha os valores que faltam com a constante, a média, o preenchimento para trás e o preenchimento para frente usando a função “
fillna()”. -
Substitua os valores ausentes por uma string, um inteiro ou um float constante usando a função `
replace()`. -
Preencha os valores que faltam usando um método de interpolação.
Observação: certifique-se de estar trabalhando com um conjunto de dados maior ao usar a função ` dropna() `.
# drop missing values
df.dropna(axis = 0, how ='any')
#fillna
df.fillna(method ='bfill')
#replace null values with -999
df.replace(to_replace = np.nan, value = -999)
# Interpolate
df.interpolate(method ='linear', limit_direction ='forward')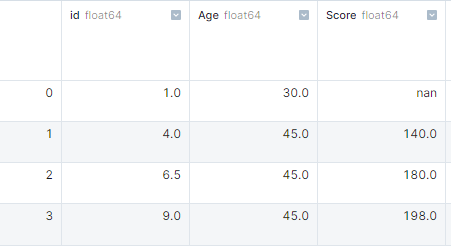
Torne-se um cientista de dados profissional fazendo o programa de carreira Cientista de Dados com Python. Inclui 25 cursos e seis projetos para ajudá-lo a aprender todos os fundamentos da ciência de dados com a ajuda das bibliotecas Python.
21. Quais bibliotecas Python você já usou pra visualização?
A visualização de dados é a parte mais importante da análise de dados. Você pode ver seus dados em ação, e isso ajuda a encontrar padrões escondidos.
As bibliotecas de visualização de dados Python mais populares são:
- Matplotlib
- Seaborn
- Plotly
- Bokeh
Em Python, geralmente usamos Matplotlib e seaborn para mostrar todos os tipos de visualização de dados. Com algumas linhas de código, você pode usá-lo para mostrar gráficos de dispersão, gráficos de linha, gráficos de caixa, gráficos de barras e muito mais.
Para aplicações interativas e mais complexas, usamos o Plotly. Você pode usá-lo para criar gráficos interativos coloridos com apenas algumas linhas de código. Você pode ampliar, aplicar animações e até adicionar funções de controle. O Plotly oferece mais de 40 tipos diferentes de gráficos, e a gente pode até usá-los para criar um aplicativo web ou painel de controle.
O Bokeh é usado para gráficos detalhados com um alto nível de interatividade em grandes conjuntos de dados.
22. Como você normalizaria ou padronizaria um conjunto de dados no Python?
A normalização ajusta os dados para um intervalo específico, geralmente [0, 1], enquanto a padronização os transforma para ter uma média de 0 e um desvio padrão de 1. As duas técnicas são essenciais pra preparar os dados pra machine learning.
Exemplo:
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import numpy as np
data = np.array([[1, 2], [3, 4], [5, 6]])
# Normalize
normalizer = MinMaxScaler()
normalized = normalizer.fit_transform(data)
print(normalized)
# Standardize
scaler = StandardScaler()
standardized = scaler.fit_transform(data)
print(standardized)Perguntas de entrevista sobre programação em Python
Se você tem uma entrevista de programação em Python chegando, preparar perguntas parecidas com essas pode te ajudar a impressionar o entrevistador.
23. Como substituir um espaço em uma string por um determinado caractere em Python?
É um desafio simples de manipulação de strings. Você precisa trocar o espaço por um caractere específico.
Exemplo 1: Um usuário forneceu a string l vey u e o caractere o, e o resultado será loveyou.
Exemplo 2: Um usuário forneceu a string D t C mpBl ckFrid yS le e o caractere a, e o resultado será DataCampBlackFridaySale.
A maneira mais fácil é usar o método embutido str.replace() para substituir diretamente os espaços pelo caractere fornecido.
def str_replace(text, ch):
return text.replace(" ", ch)
text = "D t C mpBl ckFrid yS le"
ch = "a"
str_replace(text, ch)
# 'DataCampBlackFridaySale'
24. Dado um número inteiro positivo num, escreva uma função que retorne True se num for um quadrado perfeito, caso contrário, retorne False.
Isso tem uma solução relativamente simples. Você pode ver se o número tem uma raiz quadrada perfeita assim:
- Usando
math.isqrt(num)para obter a raiz quadrada inteira exata. - Levantar ao quadrado e ver se dá o mesmo que o número original.
- Retornando o resultado como um booleano.
Teste 1
Nós fornecemos o número 10 para a valid_square() função:
- Calculando a raiz quadrada inteira do número, a gente consegue 3.
- Depois, pega o quadrado de 3 e dá 9.
- 9 não é igual ao número, então a função vai devolver False.
Teste 2
Nós fornecemos o número 36 para a valid_square() função:
- Calculando a raiz quadrada inteira do número, a gente chega a 6.
- Depois, multiplique 6 pelo 6 e você vai ter 36.
- 36 é igual ao número, então a função vai devolver Verdadeiro.
import math
def valid_square(num):
if num < 0:
return False
square = math.isqrt(num)
return square * square == num
valid_square(10)
# False
valid_square(36)
# True25. Dado um número inteiro n, devolva o número de zeros à direita em n fatorial n!
Para passar nesse desafio, você precisa primeiro calcular o fatorial de n (n!) e, em seguida, calcular o número de zeros de treinamento.
Encontrando o fatorial
Na primeira etapa, vamos usar um loop while para iterar sobre o fatorial de n e parar quando n for igual a 1.
Calculando zeros à direita
Na segunda etapa, vamos calcular o zero à direita, não o número total de zeros. Tem uma diferença enorme.
7! = 5040Os sete fatoriais têm um total de dois zeros e só um zero à direita, então nossa solução deve dar 1.
- Converta o número fatorial em uma string.
- Dá uma lida e aplica isso num loop.
- Se o número for 0, acrescente +1 ao resultado, caso contrário, interrompa o loop.
- Retorna o resultado.
A solução é elegante, mas precisa de atenção aos detalhes.
def factorial_trailing_zeros(n):
fact = n
while n > 1:
fact *= n - 1
n -= 1
result = 0
for i in str(fact)[::-1]:
if i == "0":
result += 1
else:
break
return result
factorial_trailing_zeros(10)
# 2
factorial_trailing_zeros(18)
# 3Faça o curso essencial de perguntas de entrevista sobre programação para se preparar para suas próximas entrevistas de programação em Python.
26. A sequência de caracteres pode ser dividida em palavras do dicionário?
Você recebe uma string grande e um dicionário com as palavras. Você precisa descobrir se a sequência de caracteres inserida pode ser dividida em palavras usando o dicionário ou não.
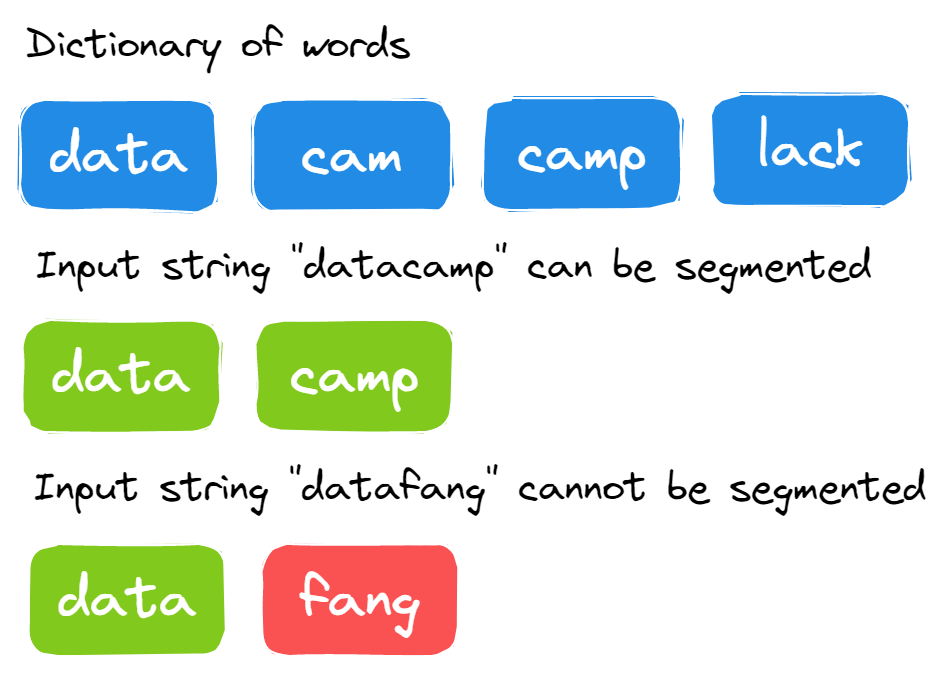
Imagem do autor
A solução é bem simples. Você precisa dividir uma string grande em cada ponto e ver se ela pode ser dividida nas palavras do dicionário.
- Execute o loop usando o comprimento da corda grande.
- Vamos criar duas subcadeias.
- A primeira substring vai checar cada ponto na string grande de
s[0:i]. - Se a primeira substring não estiver no dicionário, ele vai devolver False.
- Se a primeira substring estiver no dicionário, ele vai criar a segunda substring usando
s[i:]. - Se a segunda substring estiver no dicionário ou se a segunda substring tiver comprimento zero, retorne True. Chame recursivamente
can_segment_str()com a segunda substring e retorne True se ela puder ser segmentada. - Para tornar a solução eficiente para strings mais longas, adicionamos memoização para que as subcadeias não sejam recalculadas repetidamente.
def can_segment_str(s, dictionary, memo=None):
if memo is None:
memo = {}
if s in memo:
return memo[s]
if not s:
return True
for i in range(1, len(s) + 1):
first_str = s[0:i]
if first_str in dictionary:
second_str = s[i:]
if (
not second_str
or second_str in dictionary
or can_segment_str(second_str, dictionary, memo)
):
memo[s] = True
return True
memo[s] = False
return False
s = "datacamp"
dictionary = ["data", "camp", "cam", "lack"]
can_segment_str(s, dictionary)
# True27. Dá pra tirar as duplicatas de uma matriz ordenada?
Dado um array de inteiros ordenados em ordem crescente, remova as duplicatas para que cada elemento único apareça apenas uma vez. Como as listas Python não mudam de comprimento no local para esse problema, coloque os resultados nas primeiras k posições da mesma matriz e retorne k (o novo comprimento). Só os primeiros k elementos são válidos depois da chamada; os elementos além de k estão obsoletos.
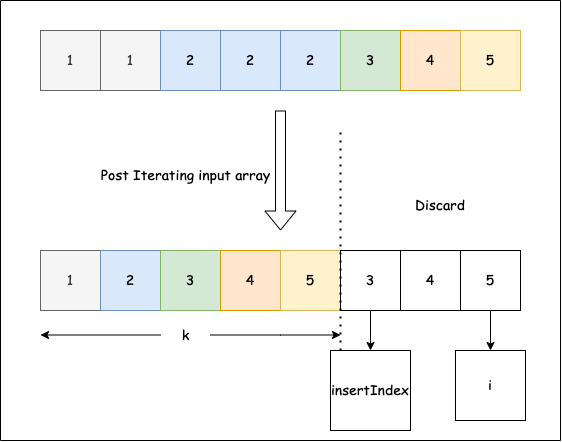
Imagem do LeetCode
Exemplo 1: a matriz de entrada é [1,1,2,2], a função deve retornar 2.
Exemplo 2: a matriz de entrada é [1,1,2,3,3], a função deve retornar 3.
Solução:
- Execute um loop do índice 1 até o final. Compare o elemento atual com o elemento único anterior; quando forem diferentes, escreva-o em
insertIndexe incrementeinsertIndex. DevolvainsertIndex. - Retorne
insertIndex, pois é o k.
Essa pergunta é bem simples quando você sabe como responder. Se você dedicar mais tempo para entender a afirmação, vai conseguir chegar facilmente a uma solução.
def removeDuplicates(array):
size = len(array)
if size == 0:
return 0
insertIndex = 1
for i in range(1, size):
if array[i - 1] != array[i]:
array[insertIndex] = array[i]
insertIndex += 1
return insertIndex
array_1 = [1, 2, 2, 3, 3, 4]
k1 = removeDuplicates(array_1)
# 4; array_1[:k1] -> [1, 2, 3, 4]
array_2 = [1, 1, 3, 4, 5, 6, 6]
k2 = removeDuplicates(array_2)
# 5; array_2[:k2] -> [1, 3, 4, 5, 6]
28. Você consegue achar o número que tá faltando na matriz?
Você recebeu a lista de números inteiros positivos de 1 a n. Todos os números de 1 a n estão lá, menos o x, e você precisa achar o x.
Exemplo:
|
4 |
5 |
3 |
2 |
8 |
1 |
6 |
- n = 8
- número que falta = 7
Essa pergunta é um problema matemático simples.
- Descubra a soma de todos os elementos da lista.
- Usando a fórmula da soma de séries aritméticas, vamos descobrir a soma esperada dos primeiros n números.
- Retorne a diferença entre a soma esperada e a soma dos elementos.
def find_missing(input_list):
sum_of_elements = sum(input_list)
# There is exactly 1 number missing
n = len(input_list) + 1
actual_sum = (n * ( n + 1 ) ) / 2
return int(actual_sum - sum_of_elements)
list_1 = [1,5,6,3,4]
find_missing(list_1)
# 229. Escreva uma função Python para ver se uma determinada string é um palíndromo.
Uma sequência é um palíndromo se for lida da mesma forma para frente e para trás.
Exemplo:
def is_palindrome(s):
s = ''.join(e for e in s if e.isalnum()).lower() # Remove non-alphanumeric and convert to lowercase
return s == s[::-1]
print(is_palindrome("A man, a plan, a canal: Panama")) # Output: True
print(is_palindrome("hello")) # Output: FalsePerguntas de entrevista sobre Python para o Facebook, Amazon, Apple, Netflix e Google
Abaixo, selecionamos algumas das perguntas que você pode esperar dos cargos mais procurados nos setores, como Meta, Amazon, Google e similares.
Perguntas da entrevista sobre Python no Facebook/Meta
As perguntas exatas que você vai encontrar na Meta dependem muito da função. Mas, você pode esperar algumas das seguintes coisas:
30. Você consegue descobrir o lucro máximo de uma única venda?
Você recebe uma lista com os preços das ações e precisa indicar o preço de compra e venda para obter o maior lucro possível.
Observação: Temos que tirar o máximo de lucro de uma única compra/venda e, se não conseguirmos lucrar, temos que reduzir nossas perdas.
Exemplo 1: preço_das_ações = [8, 4, 12, 9, 20, 1], compra = 4 e venda = 20. Maximizando o lucro.
Exemplo 2: preço_das_ações = [8, 6, 5, 4, 3, 2, 1], comprar = 6 e vender = 5. Minimizando a perda.
Solução:
- Vamos calcular o lucro global tirando a venda global (o primeiro elemento da lista) da compra atual (o segundo elemento da lista).
- Execute o loop para o intervalo de 1 até o comprimento da lista.
- Dentro do loop, calcule o lucro atual usando os elementos da lista e o valor de compra atual.
- Se o lucro atual for maior que o lucro global, troca o lucro global pelo lucro atual e vende globalmente para o elemento i da lista.
- Se a compra atual for maior do que o elemento atual da lista, troque a compra atual pelo elemento atual da lista.
- No final, vamos devolver o valor global de compra e venda. Para obter o valor global de compra, vamos subtrair o valor global de venda do lucro global.
A questão é um pouco complicada, e você pode criar seu próprio algoritmo para resolver os problemas.
def buy_sell_stock_prices(stock_prices):
current_buy = stock_prices[0]
global_sell = stock_prices[1]
global_profit = global_sell - current_buy
for i in range(1, len(stock_prices)):
current_profit = stock_prices[i] - current_buy
if current_profit > global_profit:
global_profit = current_profit
global_sell = stock_prices[i]
if current_buy > stock_prices[i]:
current_buy = stock_prices[i]
return global_sell - global_profit, global_sell
stock_prices_1 = [10,9,16,17,19,23]
buy_sell_stock_prices(stock_prices_1)
# (9, 23)
stock_prices_2 = [8, 6, 5, 4, 3, 2, 1]
buy_sell_stock_prices(stock_prices_2)
# (6, 5)Perguntas da entrevista sobre Python na Amazon
As perguntas da entrevista sobre Python na Amazon podem variar bastante, mas podem incluir:
31. Você consegue achar um triplo pitagórico em uma matriz?
Escreva uma função que retorne um True e se existir um triplo pitagórico que satisfaça a2 + b2 = c2.
Exemplo:
|
Entrada |
Saída |
|
[3, 1, 4, 6, 5] |
Verdadeiro |
|
[10, 4, 6, 12, 5] |
Falso |
Solução:
-
Eleve ao quadrado todos os elementos da matriz.
-
Organize a matriz em ordem crescente.
-
Faça duas voltas. O loop externo começa do último índice da matriz até 1, e o loop interno começa de (
outer_loop_index - 1) até o início. -
Crie um
set()o para guardar os elementos entre o índice do loop externo e o índice do loop interno. -
Dá uma olhada se tem algum número no conjunto que seja igual a
(array[outerLoopIndex] – array[innerLoopIndex]). Se sim, retorneTrue, caso contrário, retorneFalse.
def checkTriplet(array):
n = len(array)
for i in range(n):
array[i] = array[i]**2
array.sort()
for i in range(n - 1, 1, -1):
s = set()
for j in range(i - 1, -1, -1):
if (array[i] - array[j]) in s:
return True
s.add(array[j])
return False
arr = [3, 2, 4, 6, 5]
checkTriplet(arr)
# True32. De quantas maneiras você consegue dar troco com moedas e um valor total?
Precisamos criar uma função que pegue uma lista de denominações de moedas e um valor total e retorne o número de maneiras pelas quais podemos fazer o troco.
No exemplo, a gente forneceu denominações de moedas [1, 2, 5] e o valor total de 5. Em troca, temosquatro maneiras de fazer a mudança .
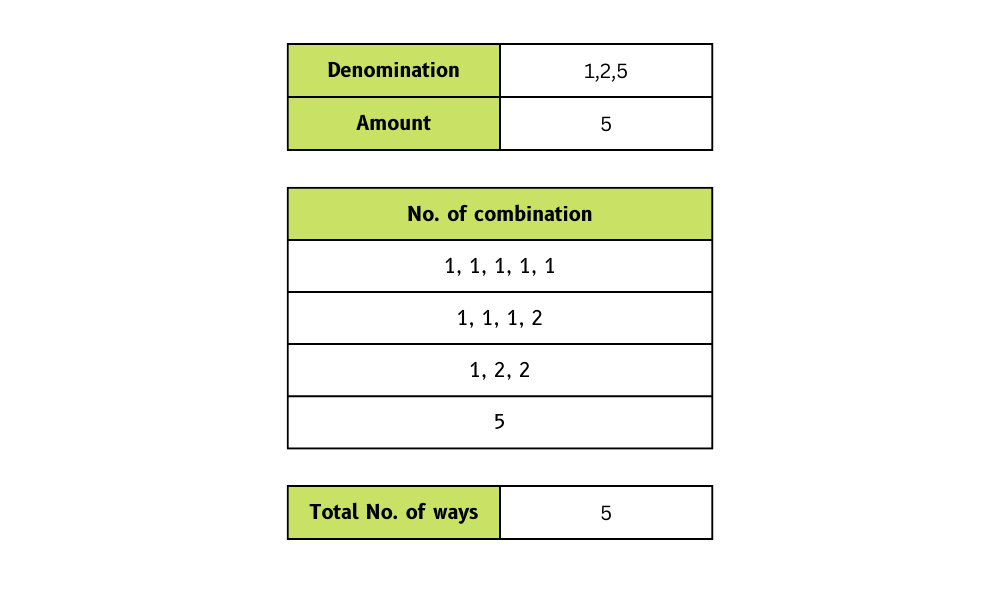
Imagem do autor
Solução:
- Vamos criar a lista de tamanho
amount + 1. Espaço extra é adicionado para guardar a solução por um valor zero. - Vamos começar uma lista de soluções com
solution[0] = 1. - Vamos fazer duas voltas. O loop externo faz uma iteração sobre as denominações, e o loop interno vai do valor atual da denominação até
amount + 1. - Os resultados das diferentes denominações são armazenados na matriz solução.
solution[i] = solution[i] + solution[i - den].
O processo vai ser repetido para todos os elementos da lista de denominações e, no último elemento da lista de soluções, teremos nosso número.
def solve_coin_change(denominations, amount):
solution = [0] * (amount + 1)
solution[0] = 1
for den in denominations:
for i in range(den, amount + 1):
solution[i] += solution[i - den]
return solution[amount]
denominations = [1, 2, 5]
amount = 5
solve_coin_change(denominations, amount)
# 4Perguntas da entrevista do Google Python
Assim como nas outras empresas mencionadas, as perguntas da entrevista Python do Google vão depender da função e do nível de experiência. Mas, algumas perguntas comuns são:
33. Defina uma função lambda, um iterador e um gerador em Python.
A função Lambda também é conhecida como função anônima. Você pode adicionar quantos parâmetros quiser, mas só com uma instrução.
Um iterador é um objeto que podemos usar para iterar sobre objetos iteráveis, como listas, dicionários, tuplas e conjuntos.
O gerador é uma função parecida com uma função normal, mas gera um valor usando a palavra-chave yield em vez de return. Se o corpo da função tiver yield, ela automaticamente vira um gerador.
Dá uma olhada no nosso tutorial completo pra saber mais sobre iteradores e geradores Python.
34. Dado um array arr[], ache o maior j – i que faça com que arr[j] > arr[i].
Essa pergunta é bem direta, mas precisa de atenção especial aos detalhes. Recebemos uma série de números inteiros positivos. Precisamos achar a diferença máxima entre j-i onde array[j] > array[i].
Exemplos:
- Entrada: [20, 70, 40, 50, 12, 38, 98], Saída: 6 (j = 6, i = 0)
- Entrada: [10, 3, 2, 4, 5, 6, 7, 8, 18, 0], Saída: 8 ( j = 8, i = 0)
Solução:
- Calcule o comprimento da matriz e comece a diferença máxima com -1.
- Faça duas voltas. O loop externo pega os elementos da esquerda, e o loop interno compara os elementos escolhidos com os elementos que começam do lado direito.
- Pare o loop interno quando o elemento for maior que o elemento escolhido e continue atualizando a diferença máxima usando j - I.
def max_index_diff(array):
n = len(array)
max_diff = -1
for i in range(0, n):
j = n - 1
while(j > i):
if array[j] > array[i] and max_diff < (j - i):
max_diff = j - i
j -= 1
return max_diff
array_1 = [20,70,40,50,12,38,98]
max_index_diff(array_1)
# 635. Como você usaria os operadores ternários em Python?
Os operadores ternários também são conhecidos como expressões condicionais. São operadores que avaliam expressões com base em condições verdadeiras e falsas.
Você pode escrever expressões condicionais em uma única linha, em vez de usar várias linhas de instruções if-else. Permite que você escreva um código limpo e compacto.
Por exemplo, podemos transformar instruções if-else aninhadas em uma única linha, como mostrado abaixo.
Instrução if-else
score = 75
if score < 70:
if score < 50:
print('Fail')
else:
print('Merit')
else:
print('Distinction')
# DistinctionOperador ternário aninhado
print('Fail' if score < 50 else 'Merit' if score < 70 else 'Distinction')
# Distinction36. Como você implementaria um cache LRU em Python?
Python tem um decorador embutido chamado ` functools.lru_cache ` pra implementar um cache LRU (Least Recently Used, ou menos usado recentemente). Ou, você pode criar um manualmente usando o OrderedDict de collections.
Exemplo usando functools:
from functools import lru_cache
@lru_cache(maxsize=3)
def add(a, b):
return a + b
print(add(1, 2)) # Calculates and caches result
print(add(1, 2)) # Retrieves result from cacheAprimorando as habilidades da sua equipe com Python
Embora a preparação para entrevistas em Python seja essencial para quem está procurando emprego e para os gerentes de contratação, é igualmente importante que as empresas invistam em treinamento contínuo em Python para suas equipes. Numa época em que automação, análise de dados e desenvolvimento de software são essenciais, garantir que seus funcionários tenham um bom domínio do Python pode ser um fator transformador para o sucesso da sua empresa.
Se você é um líder de equipe ou dono de empresa e quer garantir que toda a sua equipe seja boa em Python, o DataCamp for Business oferece programas de treinamento personalizados que podem ajudar seus funcionários a dominar as habilidades em Python, desde o básico até conceitos avançados. A gente pode oferecer:
- Trilhas de aprendizagem direcionadas: Personalizável de acordo com o nível de habilidade atual da sua equipe e as necessidades específicas da sua empresa.
- Prática prática: Projetos reais e exercícios de programação que ajudam a aprender e a lembrar melhor.
- Acompanhamento do progresso: Ferramentas para acompanhar e avaliar o progresso da sua equipe, garantindo que eles alcancem seus objetivos de aprendizagem.
Investir no aprimoramento das habilidades em Python por meio de plataformas como o DataCamp não só melhora as capacidades da sua equipe, mas também dá à sua empresa uma vantagem estratégica, permitindo que você inove, se mantenha competitivo e entregue resultados impactantes. Entre em contato com a nossa equipe e peça uma demonstração hoje mesmo.
Aumente a proficiência em Python da sua equipe
Treine sua equipe em Python com o DataCamp for Business. Treinamento abrangente, projetos práticos e métricas de desempenho detalhadas para sua empresa.



