
Erhalte eine Top Data Zertifizierung
Grundlegende Python-Interviewfragen
Hier sind ein paar Fragen, die dir bei einem Python-Vorstellungsgespräch für Einsteiger gestellt werden könnten.
1. Was ist Python und was sind seine wichtigsten Funktionen?
Python ist eine vielseitige, hochentwickelte Programmiersprache, die für ihre leicht verständliche Syntax und ihre vielfältigen Anwendungsmöglichkeiten bekannt ist. Hier sind ein paar der wichtigsten Features von Python:
- Einfache und verständliche Syntax: Die Syntax von Python ist klar und einfach, was sie für Anfänger leicht verständlich und für erfahrene Entwickler effizient macht.
- Übersetzte Sprache: Python macht den Code Zeile für Zeile, was beim Debuggen und Testen echt hilfreich ist.
- Dynamische Typisierung: Python braucht keine expliziten Datentypdeklarationen, was mehr Flexibilität ermöglicht.
- Umfangreiche Bibliotheken und Frameworks: Bibliotheken wie NumPy, Pandas und Django machen Python noch flexibler für spezielle Aufgaben in der Datenwissenschaft, Webentwicklung und so weiter.
- Plattformübergreifende Kompatibilität: Python läuft auf verschiedenen Betriebssystemen, wie Windows, macOS und Linux.
2. Was sind Python-Listen und -Tupel?
Listen und Tupel sind grundlegende Python-Datenstrukturen mit unterschiedlichen Eigenschaften und Anwendungsfällen.
Liste:
- Veränderlich: Elemente können nach dem Erstellen geändert werden.
- Speicherverbrauch: Benötigt mehr Speicherplatz.
- Leistung: Langsamer als bei Tupeln, aber besser für Einfüge- und Löschvorgänge.
- Methoden: Bietet verschiedene eingebaute Methoden zur Bearbeitung.
Beispiel:
a_list = ["Data", "Camp", "Tutorial"]
a_list.append("Session")
print(a_list) # Output: ['Data', 'Camp', 'Tutorial', 'Session']Tupel:
- Unveränderlich: Elemente können nach ihrer Erstellung nicht mehr geändert werden.
- Speicherverbrauch: Braucht weniger Speicherplatz.
- Leistung: Schnellere Iteration im Vergleich zu Listen, aber nicht so flexibel wie Listen.
- Methoden: Nur wenige eingebaute Methoden.
Beispiel:
a_tuple = ("Data", "Camp", "Tutorial")
print(a_tuple) # Output: ('Data', 'Camp', 'Tutorial')Mehr dazu erfährst du in unserem Tutorial zu Python-Listen.
3. Was ist __init__() in Python?
Die Methode „ __init__() “ wird in der objektorientierten Programmierung (OOP) als Konstruktor bezeichnet. Es wird benutzt, um den Zustand eines Objekts zu initialisieren, wenn es erstellt wird. Diese Methode wird automatisch aufgerufen, wenn eine neue Instanz einer Klasse erstellt wird.
Zweck:
- Weise den Objekteigenschaften Werte zu.
- Mach alle Initialisierungsvorgänge.
Beispiel:
Wir haben eine Klasse „ book_shop ” erstellt und den Konstruktor sowie die Funktion „ book() ” hinzugefügt. Der Konstruktor speichert den Namen des Buchtitels und die Funktion „ book() ” gibt den Namen des Buches aus.
Um unseren Code zu testen, haben wir das Objekt „ b “ mit „Sandman“ initialisiert und die Funktion „ book() “ ausgeführt.
class book_shop:
# constructor
def __init__(self, title):
self.title = title
# Sample method
def book(self):
print('The tile of the book is', self.title)
b = book_shop('Sandman')
b.book()
# The tile of the book is Sandman4. Was ist der Unterschied zwischen einem veränderbaren Datentyp und einem unveränderbaren Datentyp?
Veränderbare Datentypen:
- Definition: Veränderbare Datentypen sind solche, die nach ihrer Erstellung geändert werden können.
- Beispiele: Liste, Wörterbuch, Menge.
- Eigenschaften: Elemente können hinzugefügt, entfernt oder geändert werden.
- Anwendungsfall: Ideal für Sammlungen von Sachen, die oft aktualisiert werden müssen.
Beispiel:
# List Example
a_list = [1, 2, 3]
a_list.append(4)
print(a_list) # Output: [1, 2, 3, 4]
# Dictionary Example
a_dict = {'a': 1, 'b': 2}
a_dict['c'] = 3
print(a_dict) # Output: {'a': 1, 'b': 2, 'c': 3}Unveränderliche Datentypen:
- Definition: Unveränderliche Datentypen sind solche, die nach ihrer Erstellung nicht mehr geändert werden können.
- Beispiele: Numerisch (int, float), Zeichenfolge, Tupel.
- Eigenschaften: Elemente können nach ihrer Festlegung nicht mehr geändert werden. Jeder Vorgang, der ein unveränderliches Objekt zu modifizieren scheint, erstellt ein neues Objekt.
Beispiel:
# Numeric Example
a_num = 10
a_num = 20 # Creates a new integer object
print(a_num) # Output: 20
# String Example
a_str = "hello"
a_str = "world" # Creates a new string object
print(a_str) # Output: world
# Tuple Example
a_tuple = (1, 2, 3)
# a_tuple[0] = 4 # This will raise a TypeError
print(a_tuple) # Output: (1, 2, 3)5. Erkläre Listen-, Wörterbuch- und Tupel-Comprehension anhand eines Beispiels.
Liste
Die Listenkomprimierung bietet eine Einzeiler-Syntax, um eine neue Liste basierend auf den Werten der bestehenden Liste zu erstellen. Du kannst eine Schleife „ for “ verwenden, um dasselbe zu machen, aber dafür musst du mehrere Zeilen schreiben, und manchmal kann das ziemlich kompliziert werden.
Listenkomprimierung macht es einfacher, eine Liste aus einer vorhandenen iterierbaren Struktur zu erstellen.
my_list = [i for i in range(1, 10)]
my_list
# [1, 2, 3, 4, 5, 6, 7, 8, 9]Wörterbuch
Ähnlich wie bei einer Listenkomprimierung kannst du mit einer einzigen Codezeile ein Wörterbuch basierend auf einer vorhandenen Tabelle erstellen. Du musst die Operation in geschweifte Klammern setzen: {}.
# Creating a dictionary using dictionary comprehension
my_dict = {i: i**2 for i in range(1, 10)}
# Output the dictionary
my_dict
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}Tupel
Anders als bei Listen und Wörterbüchern gibt's keine spezielle „Tupel-Comprehension“.
Wenn du Klammern mit einer Comprehension verwendest, erstellt Python eigentlich einen Generatorausdruck und kein Tupel. Um ein Tupel zu bekommen, musst du entweder den Generator mit ` tuple() ` umwandeln oder direkt ein Tupel-Literal definieren.
# Generator expression (not a tuple)
my_gen = (i for i in range(1, 10))
my_gen
# <generator object <genexpr> ...>
# Converting generator to tuple
my_tuple = tuple(i for i in range(1, 10))
my_tuple
# (1, 2, 3, 4, 5, 6, 7, 8, 9)
# Or simply define a tuple directly
literal_tuple = (1, 2, 3)
literal_tuple
# (1, 2, 3)
Mehr dazu erfährst du in unserem Tutorial zu Python-Tupeln.
6. Was ist die Global Interpreter Lock (GIL) in Python und warum ist sie wichtig?
Die Global Interpreter Lock (GIL) ist ein Mutex in CPython (der Referenzimplementierung von Python), der dafür sorgt, dass immer nur ein nativer Thread Python-Bytecode ausführt. Es macht die Speicherverwaltung einfacher, indem es interne Datenstrukturen wie Referenzzahlen schützt, aber es schränkt auch echte Parallelität bei CPU-gebundenen Aufgaben ein, was Multithreading für Rechenaufgaben weniger effektiv macht. Es funktioniert aber super für Aufgaben, die viel mit Ein- und Ausgabe zu tun haben, wo Threads Zeit damit verbringen, auf Netzwerk-, Datei- oder Datenbankoperationen zu warten.
Anmerkung: Python 3.13 hat eine experimentelle Version ohne GIL eingeführt (PEP 703), und Python 3.14 hat eine dokumentierte Unterstützung für freie Threads hinzugefügt. Einige C-Erweiterungen und Bibliotheken sind vielleicht noch nicht ganz kompatibel.
Python-Interviewfragen für Fortgeschrittene
Hier sind ein paar Fragen, die dir in einem Python-Vorstellungsgespräch für Fortgeschrittene gestellt werden könnten.
7. Kannst du mirdie gängigen Such- und Graphdurchlaufalgorithmen in Python erklären?
Python hat eine Reihe von leistungsstarken Algorithmen für die Suche und Graphdurchquerung, und jeder davon arbeitet mit unterschiedlichen Datenstrukturen und löst verschiedene Probleme. Ich kann sie hier hören:
- Binäre Suche: Wenn du schnell einen Eintrag in einer sortierten Liste finden musst, ist die binäre Suche genau das Richtige für dich. Es funktioniert, indem der Suchbereich immer wieder halbiert wird, bis das Ziel gefunden ist.
- AVL-Baum: Ein AVL-Baum sorgt für Ausgewogenheit, was echt praktisch ist, wenn du oft Sachen in einen Baum einfügst oder daraus löschst. Diese selbstausgleichende binäre Suchbaumstruktur sorgt dafür, dass die Suche schnell bleibt, indem sie verhindert, dass der Baum zu schief wird.
- Breitensuche (BFS): Bei BFS geht's darum, einen Graphen Level für Level zu erkunden. Das ist besonders praktisch, wenn du den kürzesten Weg in einem ungewichteten Graphen suchst, weil es alle möglichen Schritte von jedem Knoten aus checkt, bevor es tiefer geht.
- Tiefensuche (DFS): DFS macht es anders, indem es jeden Zweig so weit wie möglich erkundet, bevor es zurückgeht. Das ist super für Sachen wie Labyrinth-Lösen oder Baumdurchquerung.
- Ein Algorithmus*: Der A*-Algorithmus ist ein bisschen fortgeschrittener und kombiniert das Beste von BFS und DFS, indem er Heuristiken nutzt, um den kürzesten Weg effizient zu finden. Es wird oft bei der Wegfindung für Karten und Spiele benutzt.
8. Was ist ein KeyError in Python und wie kannst du damit umgehen?
Ein „ KeyError “ in Python passiert, wenn du versuchst, auf einen Schlüssel zuzugreifen, der im Wörterbuch nicht da ist. Dieser Fehler passiert, weil Python erwartet, dass jeder Schlüssel, den du suchst, im Wörterbuch vorkommt. Wenn das nicht der Fall ist, kommt es zu einem „ KeyError “.
Wenn du zum Beispiel ein Wörterbuch mit Noten von Schülern hast und versuchst, auf einen Schüler zuzugreifen, der nicht im Wörterbuch steht, bekommst du eine „ KeyError “ (Nicht vorhandener Schlüssel). Um diesen Fehler zu beheben, hast du ein paar Möglichkeiten:
-
Benutze die Methode .get(): Diese Methode gibt „
None“ (oder einen bestimmten Standardwert) zurück, anstatt einen Fehler auszulösen, wenn der Schlüssel nicht gefunden wird. -
Benutz einen try-except-Block: Wenn du deinen Code in `
try-except` einbaust, kannst du den Fehler `KeyError` abfangen und elegant behandeln. -
Such nach dem Schlüssel mit in: Du kannst mit „
if key in dictionary“ checken, ob ein Schlüssel im Wörterbuch da ist, bevor du versuchst, drauf zuzugreifen.
Mehr Infos findest du in unserem kompletten Tutorial: Python KeyError-Ausnahmen und wie man sie behebt.
9. Wie geht Python mit der Speicherverwaltung um und welche Rolle spielt die Garbage Collection dabei?
Python kümmert sich automatisch um die Speicherzuweisung und -freigabe über einen privaten Heap, wo alle Objekte und Datenstrukturen gespeichert werden. Die Speicherverwaltung läuft über den Python-Speichermanager, der die Speichernutzung optimiert, und den Garbage Collector, der sich um nicht mehr genutzte oder nicht referenzierte Objekte kümmert, um Speicherplatz freizugeben.
Die Garbage Collection in Python nutzt Referenzzählung und einen zyklischen Garbage Collector, um nicht mehr brauchte Daten zu erkennen und zu sammeln. Wenn ein Objekt keine Referenzen mehr hat, kann es von der Garbage Collection gelöscht werden. Mit dem Modul „ gc ” in Python kannst du direkt mit dem Garbage Collector interagieren. Es hat Funktionen, um die Garbage Collection zu aktivieren oder zu deaktivieren und auch, um eine manuelle Sammlung durchzuführen.
10. Was ist der Unterschied zwischen einer flachen Kopie und einer tiefen Kopie in Python, und wann würdest du welche davon verwenden?
In Python werden flache und tiefe Kopien zum Duplizieren von Objekten verwendet, aber sie gehen mit verschachtelten Strukturen unterschiedlich um.
-
Flache Kopie: Bei einer flachen Kopie wird ein neues Objekt erstellt, aber es werden Verweise auf die Objekte eingefügt, die im Original vorkommen. Wenn das ursprüngliche Objekt also andere veränderbare Objekte enthält (wie Listen innerhalb von Listen), verweist die flache Kopie auf dieselben inneren Objekte. Das kann zu unerwarteten Änderungen führen, wenn du eines dieser inneren Objekte entweder in der Originalstruktur oder in der kopierten Struktur änderst. Du kannst eine flache Kopie mit der Methode „
copy()“ oder der Funktion „copy()“ aus dem Modul „copy“ erstellen. -
Tiefkopie: Eine tiefe Kopie macht ein neues Objekt und kopiert rekursiv alle Objekte, die im Original gefunden werden. Das heißt, dass sogar verschachtelte Strukturen dupliziert werden, sodass Änderungen in einer Kopie die andere nicht beeinflussen. Um eine tiefe Kopie zu erstellen, kannst du die Funktion „
deepcopy()“ aus dem Modul „copy“ benutzen.
Beispiel für die Verwendung: Eine flache Kopie ist super, wenn das Objekt nur unveränderliche Elemente hat oder wenn du willst, dass Änderungen in verschachtelten Strukturen in beiden Kopien angezeigt werden. Eine tiefe Kopie ist super, wenn du mit komplizierten, verschachtelten Objekten arbeitest und ein komplett unabhängiges Duplikat haben willst. Schau dir unsere Python-Kopierliste „ ” an: Was du wissen solltest Tutorial, um mehr zu erfahren. Dieses Tutorial hat einen ganzen Abschnitt über den Unterschied zwischen flacher Kopie und tiefer Kopie.
11. Wie kannst du das Collections-Modul von Python nutzen, um alltägliche Aufgaben einfacher zu machen?
Das Modul „ collections ” in Python hat spezielle Datenstrukturen wie „ defaultdict ”, „ Counter ”, „ deque ” und „ OrderedDict ”, die verschiedene Aufgaben einfacher machen. Zum Beispiel ist „ Counter “ super, um Elemente in einer iterierbaren Struktur zu zählen, während „ defaultdict “ Wörterbuchwerte ohne explizite Überprüfungen initialisieren kann.
Beispiel:
from collections import Counter
data = ['a', 'b', 'c', 'a', 'b', 'a']
count = Counter(data)
print(count) # Output: Counter({'a': 3, 'b': 2, 'c': 1})Fragen für Fortgeschrittene zum Thema Python
Diese Interviewfragen sind für Leute gedacht, die schon mehr Erfahrung mit Python haben.
12. Was ist Monkey Patching in Python?
Monkey Patching in Python ist eine dynamische Technik, mit der man das Verhalten des Codes während der Laufzeit ändern kann. Kurz gesagt, du kannst eine Klasse oder ein Modul zur Laufzeit ändern.
Beispiel:
Lass uns Monkey Patching anhand eines Beispiels lernen.
-
Wir haben eine Klasse „
monkey” mit einer Funktion „patch()” erstellt. Wir haben auch eine Funktion „monk_p“ außerhalb der Klasse erstellt. -
Wir werden jetzt die Funktion „
patch“ durch die Funktion „monk_p“ ersetzen, indem wir „monkey.patch“ der Variablen „monk_p“ zuweisen. -
Zum Schluss checken wir die Änderung, indem wir das Objekt mit der Klasse „
monkey“ erstellen und die Funktion „patch()“ ausführen.
Statt patch() is being called wurde monk_p() is being called angezeigt.
class monkey:
def patch(self):
print ("patch() is being called")
def monk_p(self):
print ("monk_p() is being called")
# replacing address of "patch" with "monk_p"
monkey.patch = monk_p
obj = monkey()
obj.patch()
# monk_p() is being calledAchtung: Benutz diese sparsam; Monkey Patching kann deinen Code schwerer lesbar machen und andere, die mit deinem Code oder deinen Tests arbeiten, überraschen.
13. Wofür ist die Python-Anweisung „with“ gedacht?
Die Anweisung „ with “ wird für die Ausnahmebehandlung verwendet, um den Code übersichtlicher und einfacher zu machen. Es wird meistens für die Verwaltung von allgemeinen Ressourcen wie das Erstellen, Bearbeiten und Speichern einer Datei benutzt.
Beispiel:
Anstatt mehrere Zeilen mit „open“, „try“, „finally“ und „close“ zu schreiben, kannst du mit der Anweisung „ with “ eine Textdatei erstellen und schreiben. Es ist ganz einfach.
# using with statement
with open('myfile.txt', 'w') as file:
file.write('DataCamp Black Friday Sale!!!')14. Warum benutzt man else in der try/except-Konstruktion in Python?
try: und „ except: “ sind allgemein für ihre außergewöhnliche Handhabung in Python bekannt. Wo kommt also „ else: “ zum Einsatz? „ else: “ wird ausgelöst, wenn keine Ausnahme ausgelöst wird.
Beispiel:
Lass uns mit ein paar Beispielen mehr über „ else: “ erfahren.
-
Beim ersten Versuch haben wir
2als Zähler unddals Nenner eingegeben. Das ist falsch, und „except:“ wurde mit „Ungültige Eingabe!“ ausgelöst. -
Beim zweiten Versuch haben wir
2als Zähler und1als Nenner eingegeben und das Ergebnis2bekommen. Es wurde keine Ausnahme ausgelöst, also hat das die Funktion „else:“ dazu gebracht, die Meldung zu drucken.Division is successful.
try:
num1 = int(input('Enter Numerator: '))
num2 = int(input('Enter Denominator: '))
division = num1/num2
print(f'Result is: {division}')
except:
print('Invalid input!')
else:
print('Division is successful.')
## Try 1 ##
# Enter Numerator: 2
# Enter Denominator: d
# Invalid input!
## Try 2 ##
# Enter Numerator: 2
# Enter Denominator: 1
# Result is: 2.0
# Division is successful.Mach den Python-Grundlagen -Lernpfad, um die grundlegenden Fähigkeiten zu lernen, die du brauchst, um Python-Programmierer zu werden.
15. Was sind Dekoratoren in Python?
Dekoratoren in Python sind ein Entwurfsmuster, mit dem du einem bestehenden Objekt neue Funktionen hinzufügen kannst, ohne seine Struktur zu ändern. Sie werden oft benutzt, um das Verhalten von Funktionen oder Methoden zu erweitern. Mehr über die Verwendung von Python-Dekoratoren erfährst du in einem separaten Leitfaden.
Beispiel:
import functools
def my_decorator(func):
@functools.wraps(func) # preserves __name__, __doc__, etc.
def wrapper(*args, **kwargs):
print("Something is happening before the function is called.")
result = func(*args, **kwargs)
print("Something is happening after the function is called.")
return result
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
# Output:
# Something is happening before the function is called.
# Hello!
# Something is happening after the function is called.16. Was sind Kontextmanager in Python und wie werden sie gemacht?
Kontextmanager in Python werden benutzt, um Ressourcen zu verwalten und sicherzustellen, dass sie richtig abgerufen und freigegeben werden. Die häufigste Verwendung von Kontextmanagern ist die Anweisung „ with “.
Beispiel:
class FileManager:
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
self.file = open(self.filename, self.mode)
return self.file
def __exit__(self, exc_type, exc_value, traceback):
self.file.close()
with FileManager('test.txt', 'w') as f:
f.write('Hello, world!')In diesem Beispiel ist die Klasse „ FileManager “ ein Kontextmanager, der dafür sorgt, dass die Datei nach ihrer Verwendung innerhalb der Anweisung „ with “ ordnungsgemäß geschlossen wird.
17. Was sind Metaklassen in Python und wie unterscheiden sie sich von normalen Klassen?
Metaklassen sind Klassen von Klassen. Sie legen fest, wie Klassen funktionieren und erstellt werden. Während normale Klassen Objekte erstellen, machen Metaklassen Klassen. Mit Metaklassen kannst du Klassendefinitionen ändern, Regeln durchsetzen oder bei der Klassenerstellung Funktionen hinzufügen.
Beispiel:
class Meta(type):
def __new__(cls, name, bases, dct):
print(f"Creating class {name}")
return super().__new__(cls, name, bases, dct)
class MyClass(metaclass=Meta):
pass
# Output: Creating class MyClassFragen zum Thema Python Data Science für Vorstellungsgespräche
Für alle, die sich mehr für die datenwissenschaftlichen Anwendungen von Python interessieren, sind hier ein paar Fragen, die vielleicht auftauchen könnten.
18. Was sind die Vorteile von NumPy gegenüber normalen Python-Listen?
NumPy hat gegenüber normalen Python-Listen ein paar Vorteile, zum Beispiel:
- Speicher: NumPy-Arrays sind speichereffizienter als Python-Listen, weil sie Elemente desselben Typs in zusammenhängenden Blöcken speichern. (Der genaue Speicherverbrauch hängt vom Elementtyp und vom System ab, aber du kannst das unter
sys.getsizeofoderarray.nbytesnachsehen.) - Geschwindigkeit: NumPy nutzt optimierte C-Implementierungen, sodass Operationen mit großen Arrays viel schneller sind als mit Listen.
- Vielseitigkeit: NumPy kann mit vektorisierten Operationen (wie Addition und Multiplikation) umgehen und hat viele eingebaute mathematische Funktionen, die Python-Listen nicht unterstützen.
19. Was ist der Unterschied zwischen „Merge“, „Join“ und „Concatenate“?
Zusammenführen
Füge zwei DataFrames namens „series objects“ mit der eindeutigen Spaltenkennung zusammen.
Man braucht zwei DataFrames, eine gemeinsame Spalte in beiden DataFrames und muss wissen, wie man sie verbinden will. Du kannst zwei DataFrames links, rechts, außen, innen und kreuzweise verbinden. Standardmäßig ist es ein innerer Join.
pd.merge(df1, df2, how='outer', on='Id')Mach mit
Verbinde die DataFrames mit dem eindeutigen Index. Es braucht ein optionales Argument „ on “, das ein Spaltenname oder mehrere Spaltennamen sein kann. Standardmäßig macht die Join-Funktion einen Left Join.
df1.join(df2)Verknüpfen
Mit „Concatenate“ kannst du zwei oder mehr DataFrames entlang einer bestimmten Achse (Zeilen oder Spalten) zusammenfügen. Es braucht kein Argument „ on “.
pd.concat(df1,df2)- join(): Verbindet zwei DataFrames über den Index.
- merge(): Fügt zwei DataFrames anhand der von dir angegebenen Spalte oder Spalten zusammen.
- concat(): Verbindet zwei oder mehr DataFrames vertikal oder horizontal.
20. Wie erkennst du fehlende Werte und wie gehst du damit um?
Fehlende Werte erkennen
Wir können fehlende Werte im DataFrame finden, indem wir die Funktion „ isnull() “ benutzen und dann „ sum() “ anwenden. „ Isnull() “ gibt boolesche Werte zurück, und die Summe zeigt dir die Anzahl der fehlenden Werte in jeder Spalte.
In diesem Beispiel haben wir ein Wörterbuch mit Listen erstellt und es in ein Pandas-DataFrame umgewandelt. Danach haben wir mit „ isnull().sum() “ die Anzahl der fehlenden Werte in jeder Spalte ermittelt.
import pandas as pd
import numpy as np
# dictionary of lists
dict = {'id':[1, 4, np.nan, 9],
'Age': [30, 45, np.nan, np.nan],
'Score':[np.nan, 140, 180, 198]}
# creating a DataFrame
df = pd.DataFrame(dict)
df.isnull().sum()
# id 1
# Age 2
# Score 1Umgang mit fehlenden Werten
In Python gibt's verschiedene Möglichkeiten, mit fehlenden Werten umzugehen.
-
Lass die ganze Zeile oder die Spalten weg, wenn sie fehlende Werte haben, indem du „
dropna()“ benutzt. Diese Methode ist nicht empfehlenswert, weil du wichtige Infos verlierst. -
Ersetz die fehlenden Werte mit der Konstante, dem Durchschnitt, der Rückwärtsfüllung und der Vorwärtsfüllung mithilfe der Funktion „
fillna()“. -
Ersetz fehlende Werte durch eine Konstante vom Typ String, Integer oder Float mit der Funktion „
replace()“. -
Ergänze die fehlenden Werte mit einer Interpolationsmethode.
Hey, pass auf: Wenn du die Funktion „ dropna() ” benutzt, solltest du mit einem größeren Datensatz arbeiten.
# drop missing values
df.dropna(axis = 0, how ='any')
#fillna
df.fillna(method ='bfill')
#replace null values with -999
df.replace(to_replace = np.nan, value = -999)
# Interpolate
df.interpolate(method ='linear', limit_direction ='forward')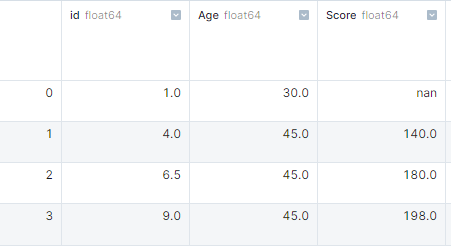
Werde ein echter Profi als Datenwissenschaftler, indem du den Lernpfad „Datenwissenschaftler mit Python“ einschlägst. Es umfasst 25 Kurse und sechs Projekte, mit denen du mithilfe von Python-Bibliotheken alle Grundlagen der Datenwissenschaft lernen kannst.
21. Welche Python-Bibliotheken hast du schon für die Visualisierung benutzt?
Die Datenvisualisierung ist der wichtigste Teil der Datenanalyse. Du kannst deine Daten in Aktion sehen, und das hilft dir, versteckte Muster zu entdecken.
Die beliebtesten Python-Bibliotheken für die Datenvisualisierung sind:
- Matplotlib
- Seaborn
- Plotly
- Bokeh
In Python benutzen wir meistens Matplotlib und seaborn, um alle Arten von Datenvisualisierungen anzuzeigen. Mit ein paar Zeilen Code kannst du damit Streudiagramme, Liniendiagramme, Boxplots, Balkendiagramme und vieles mehr anzeigen.
Für interaktive und komplexere Anwendungen nutzen wir Plotly. Du kannst damit mit ein paar Zeilen Code bunte interaktive Diagramme erstellen. Du kannst zoomen, Animationen hinzufügen und sogar Steuerungsfunktionen einbauen. Plotly hat über 40 verschiedene Diagrammtypen und man kann damit sogar Web-Apps oder Dashboards erstellen.
Bokeh ist super für detaillierte Grafiken mit viel Interaktivität bei großen Datensätzen.
22. Wie würdest du einen Datensatz in Python normalisieren oder standardisieren?
Bei der Normalisierung werden Daten auf einen bestimmten Bereich skaliert, meistens [0, 1], während sie bei der Standardisierung so umgewandelt werden, dass sie einen Mittelwert von 0 und eine Standardabweichung von 1 haben. Beide Techniken sind super wichtig, um Daten für Machine-Learning-Modelle vorzubereiten.
Beispiel:
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import numpy as np
data = np.array([[1, 2], [3, 4], [5, 6]])
# Normalize
normalizer = MinMaxScaler()
normalized = normalizer.fit_transform(data)
print(normalized)
# Standardize
scaler = StandardScaler()
standardized = scaler.fit_transform(data)
print(standardized)Fragen zum Thema Python-Programmierung für Vorstellungsgespräche
Wenn du bald ein Vorstellungsgespräch zum Thema Python-Programmierung hast, kannst du mit solchen Fragen beim Gesprächspartner punkten.
23. Wie kann man in Python einen String-Platzhalter durch ein bestimmtes Zeichen ersetzen?
Es ist eine einfache Aufgabe zum Bearbeiten von Zeichenfolgen. Du musst das Leerzeichen durch ein bestimmtes Zeichen ersetzen.
Beispiel 1: Ein Benutzer hat die Zeichenfolge „ l vey u “ und das Zeichen „ o “ eingegeben, und die Ausgabe lautet „ loveyou “.
Beispiel 2: Ein Benutzer hat die Zeichenfolge „ D t C mpBl ckFrid yS le “ und das Zeichen „ a “ eingegeben, und die Ausgabe lautet „ DataCampBlackFridaySale “.
Am einfachsten ist es, die eingebaute Methode zu nutzen str.replace() , um Leerzeichen direkt durch das angegebene Zeichen zu ersetzen.
def str_replace(text, ch):
return text.replace(" ", ch)
text = "D t C mpBl ckFrid yS le"
ch = "a"
str_replace(text, ch)
# 'DataCampBlackFridaySale'
24. Schreib eine Funktion, die True zurückgibt, wenn die positive ganze Zahl num ein perfektes Quadrat ist, sonst False.
Das hat eine ziemlich einfache Lösung. Du kannst überprüfen, ob die Zahl eine perfekte Quadratwurzel hat, indem du:
- Mit
math.isqrt(num), um die ganzzahlige Quadratwurzel genau zu berechnen. - Quadriere es und schau, ob es mit der ursprünglichen Zahl übereinstimmt.
- Das Ergebnis als booleschen Wert zurückgeben.
Test 1
Wir haben die Nummer 10 an die valid_square() Funktion gegeben:
- Wenn wir die ganzzahlige Quadratwurzel der Zahl ziehen, kriegen wir 3.
- Dann nimmst du die Quadratzahl von 3 und bekommst 9.
- 9 ist nicht gleich der Zahl, also gibt die Funktion „False“ zurück.
Test 2
Wir haben die Nummer 36 an die valid_square() Funktion gegeben:
- Wenn wir die ganzzahlige Quadratwurzel der Zahl nehmen, kriegen wir 6.
- Dann nimmst du die Quadratzahl von 6 und bekommst 36.
- 36 ist gleich der Zahl, also gibt die Funktion „True“ zurück.
import math
def valid_square(num):
if num < 0:
return False
square = math.isqrt(num)
return square * square == num
valid_square(10)
# False
valid_square(36)
# True25. Gib bei einer ganzen Zahl n die Anzahl der nachgestellten Nullen in n zurück.
Um diese Aufgabe zu lösen, musst du erst mal n-Fakultät (n!) berechnen und dann die Anzahl der Trainings-Nullen.
Fakultät finden
Als Erstes machen wir eine while-Schleife, um die n-Fakultät durchzugehen, und hören auf, wenn n gleich 1 ist.
Nullstellen berechnen
Im zweiten Schritt berechnen wir die nachgestellte Null, nicht die Gesamtzahl der Nullen. Es gibt einen riesigen Unterschied.
7! = 5040Die sieben Fakultäten haben insgesamt zwei Nullen und nur eine nachgestellte Null, also sollte unsere Lösung 1 ergeben.
- Mach die Fakultätszahl zu einer Zeichenfolge.
- Lies es nochmal durch und mach eine Schleife.
- Wenn die Zahl 0 ist, mach +1 zum Ergebnis, sonst beende die Schleife.
- Gibt das Ergebnis zurück.
Die Lösung ist echt elegant, aber man muss auf die Details achten.
def factorial_trailing_zeros(n):
fact = n
while n > 1:
fact *= n - 1
n -= 1
result = 0
for i in str(fact)[::-1]:
if i == "0":
result += 1
else:
break
return result
factorial_trailing_zeros(10)
# 2
factorial_trailing_zeros(18)
# 3Mach den Kurs „Essential Practicing Coding Interview Questions“, um dich auf deine nächsten Programmier-Vorstellungsgespräche in Python vorzubereiten.
26. Kann die Zeichenfolge in Wörter aus dem Wörterbuch aufgeteilt werden?
Du bekommst eine lange Zeichenfolge und ein Wörterbuch mit den Wörtern. Du musst herausfinden, ob die Eingabezeichenfolge mithilfe des Wörterbuchs in Wörter unterteilt werden kann oder nicht.
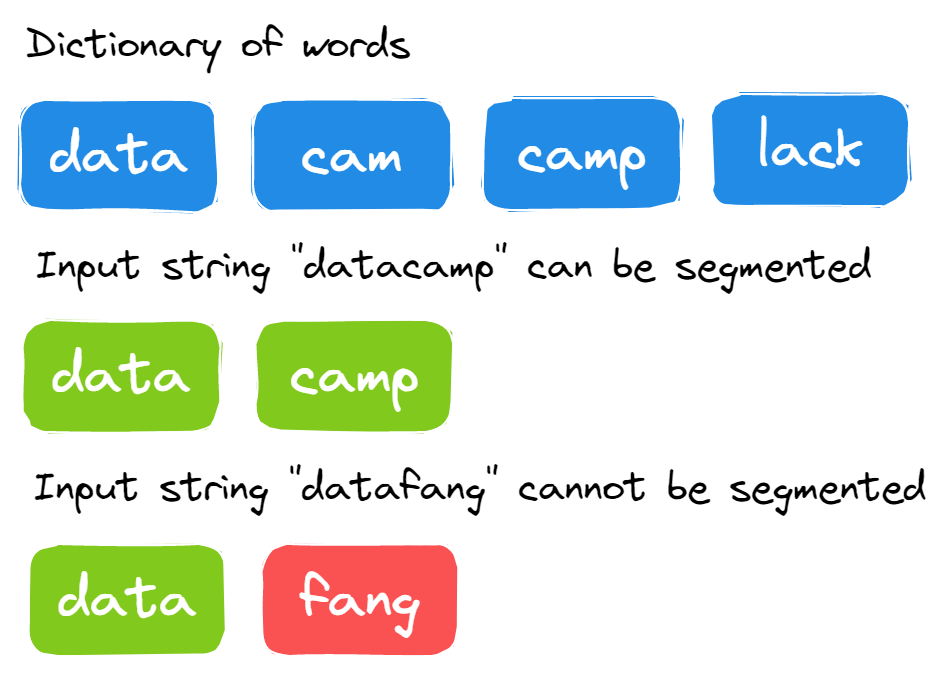
Bild vom Autor
Die Lösung ist ziemlich einfach. Du musst eine große Zeichenfolge an jedem Punkt segmentieren und prüfen, ob die Zeichenfolge in die Wörter des Wörterbuchs segmentiert werden kann.
- Mach die Schleife mit der Länge der großen Schnur.
- Wir machen zwei Teilstrings.
- Die erste Teilzeichenfolge checkt jeden Punkt in der großen Zeichenfolge von
s[0:i]. - Wenn die erste Teilzeichenfolge nicht im Wörterbuch ist, gibt es „False“ zurück.
- Wenn die erste Teilzeichenfolge im Wörterbuch ist, wird die zweite Teilzeichenfolge mit
s[i:]. - Wenn die zweite Teilzeichenfolge im Wörterbuch vorkommt oder null Zeichen lang ist, dann gib „True“ zurück. Ruf rekursiv „
can_segment_str()“ mit der zweiten Teilzeichenfolge auf und gib „True“ zurück, wenn sie segmentiert werden kann. - Damit die Lösung auch für längere Zeichenfolgen gut funktioniert, fügen wir Memoization hinzu, damit Teilzeichenfolgen nicht immer wieder neu berechnet werden müssen.
def can_segment_str(s, dictionary, memo=None):
if memo is None:
memo = {}
if s in memo:
return memo[s]
if not s:
return True
for i in range(1, len(s) + 1):
first_str = s[0:i]
if first_str in dictionary:
second_str = s[i:]
if (
not second_str
or second_str in dictionary
or can_segment_str(second_str, dictionary, memo)
):
memo[s] = True
return True
memo[s] = False
return False
s = "datacamp"
dictionary = ["data", "camp", "cam", "lack"]
can_segment_str(s, dictionary)
# True27. Kannst du Duplikate aus einem sortierten Array entfernen?
Nimm ein Array mit ganzen Zahlen, die in aufsteigender Reihenfolge sortiert sind, und entferne alle Duplikate, sodass jedes Element nur einmal vorkommt. Da Python-Listen bei diesem Problem ihre Länge nicht direkt ändern, pack die Ergebnisse einfach in die ersten k Positionen desselben Arrays und gib k (die neue Länge) zurück. Nur die ersten k Elemente sind nach dem Aufruf noch okay; die Elemente nach k sind veraltet.
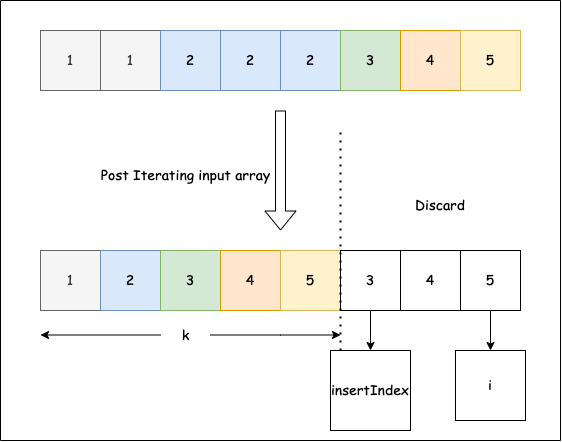
Bild von LeetCode
Beispiel 1: Das Eingabe-Array ist [1,1,2,2], die Funktion sollte 2 zurückgeben.
Beispiel 2: Das Eingabe-Array ist [1,1,2,3,3], die Funktion sollte 3 zurückgeben.
Lösung:
- Mach 'ne Schleife von Index 1 bis zum Ende. Vergleich das aktuelle Element mit dem vorherigen eindeutigen Element; wenn sie unterschiedlich sind, schreib es unter
insertIndexund erhöheinsertIndex. Rückgabe-insertIndex. - Gib „
insertIndex“ zurück, weil es das k ist.
Diese Frage ist ziemlich einfach, wenn man erst mal weiß, wie's geht. Wenn du dir mehr Zeit nimmst, um die Aussage zu verstehen, kannst du leicht eine Lösung finden.
def removeDuplicates(array):
size = len(array)
if size == 0:
return 0
insertIndex = 1
for i in range(1, size):
if array[i - 1] != array[i]:
array[insertIndex] = array[i]
insertIndex += 1
return insertIndex
array_1 = [1, 2, 2, 3, 3, 4]
k1 = removeDuplicates(array_1)
# 4; array_1[:k1] -> [1, 2, 3, 4]
array_2 = [1, 1, 3, 4, 5, 6, 6]
k2 = removeDuplicates(array_2)
# 5; array_2[:k2] -> [1, 3, 4, 5, 6]
28. Kannst du die fehlende Zahl im Array finden?
Du hast die Liste der positiven ganzen Zahlen von 1 bis n bekommen. Alle Zahlen von 1 bis n sind da, außer x, und du musst x finden.
Beispiel:
|
4 |
5 |
3 |
2 |
8 |
1 |
6 |
- n = 8
- fehlende Zahl = 7
Diese Frage ist echt einfach zu rechnen.
- Berechne die Summe aller Elemente in der Liste.
- Mit der Formel für die Summe einer arithmetischen Reihe berechnen wir die erwartete Summe der ersten n Zahlen.
- Gib die Differenz zwischen der erwarteten Summe und der Summe der Elemente zurück.
def find_missing(input_list):
sum_of_elements = sum(input_list)
# There is exactly 1 number missing
n = len(input_list) + 1
actual_sum = (n * ( n + 1 ) ) / 2
return int(actual_sum - sum_of_elements)
list_1 = [1,5,6,3,4]
find_missing(list_1)
# 229. Schreib eine Python-Funktion, die checkt, ob eine bestimmte Zeichenfolge ein Palindrom ist.
Eine Zeichenfolge ist ein Palindrom, wenn sie vorwärts und rückwärts gleich gelesen wird.
Beispiel:
def is_palindrome(s):
s = ''.join(e for e in s if e.isalnum()).lower() # Remove non-alphanumeric and convert to lowercase
return s == s[::-1]
print(is_palindrome("A man, a plan, a canal: Panama")) # Output: True
print(is_palindrome("hello")) # Output: FalsePython-Interviewfragen für Facebook, Amazon, Apple, Netflix und Google
Hier unten haben wir ein paar Fragen zusammengestellt, die du bei den angesagtesten Jobs in der Branche erwarten kannst, also bei Meta, Amazon, Google und so weiter.
Facebook/Meta Python-Interviewfragen
Die genauen Fragen, die dir bei Meta gestellt werden, hängen stark von der jeweiligen Position ab. Du kannst aber mit folgenden Dingen rechnen:
30. Kannst du den höchsten Einzelverkaufsgewinn herausfinden?
Du bekommst eine Liste mit Aktienkursen und musst den Kauf- und Verkaufspreis angeben, um den höchsten Gewinn zu erzielen.
Anmerkung: Wir müssen bei jedem Kauf/Verkauf so viel Gewinn wie möglich machen, und wenn das nicht klappt, müssen wir unsere Verluste so gering wie möglich halten.
Beispiel 1: Aktienkurs = [8, 4, 12, 9, 20, 1], Kauf = 4 und Verkauf = 20. Den Gewinn maximieren.
Beispiel 2: Aktienkurs = [8, 6, 5, 4, 3, 2, 1], Kauf = 6 und Verkauf = 5. Den Verlust so gering wie möglich halten.
Lösung:
- Wir berechnen den Gesamtgewinn, indem wir den Gesamtverkauf (das erste Element in der Liste) vom aktuellen Kauf (das zweite Element in der Liste) abziehen.
- Lass die Schleife für den Bereich von 1 bis zur Länge der Liste laufen.
- Berechne innerhalb der Schleife den aktuellen Gewinn mit den Listenelementen und dem aktuellen Kaufwert.
- Wenn der aktuelle Gewinn höher ist als der Gesamtgewinn, dann tausche den Gesamtgewinn mit dem aktuellen Gewinn aus und verkaufe das i-Element der Liste.
- Wenn der aktuelle Kaufwert größer ist als das aktuelle Element der Liste, dann tausche den aktuellen Kaufwert gegen das aktuelle Element der Liste aus.
- Am Ende geben wir den globalen Kauf- und Verkaufswert zurück. Um den globalen Kaufwert zu bekommen, ziehen wir den globalen Verkaufswert vom globalen Gewinn ab.
Die Frage ist ein bisschen knifflig, und du kannst dir deinen eigenen Algorithmus ausdenken, um die Probleme zu lösen.
def buy_sell_stock_prices(stock_prices):
current_buy = stock_prices[0]
global_sell = stock_prices[1]
global_profit = global_sell - current_buy
for i in range(1, len(stock_prices)):
current_profit = stock_prices[i] - current_buy
if current_profit > global_profit:
global_profit = current_profit
global_sell = stock_prices[i]
if current_buy > stock_prices[i]:
current_buy = stock_prices[i]
return global_sell - global_profit, global_sell
stock_prices_1 = [10,9,16,17,19,23]
buy_sell_stock_prices(stock_prices_1)
# (9, 23)
stock_prices_2 = [8, 6, 5, 4, 3, 2, 1]
buy_sell_stock_prices(stock_prices_2)
# (6, 5)Amazon Python-Interviewfragen
Die Fragen bei einem Vorstellungsgespräch bei Amazon Python können echt unterschiedlich sein, könnten aber zum Beispiel Folgendes umfassen:
31. Kannst du in einem Array ein pythagoreisches Tripel finden?
Schreib eine Funktion, die „ True “ zurückgibt, wenn es ein pythagoreisches Tripel gibt, das a² + b² = c² erfüllt.
Beispiel:
|
Eingabe |
Ausgabe |
|
[3, 1, 4, 6, 5] |
Richtig |
|
[10, 4, 6, 12, 5] |
Falsch |
Lösung:
-
Quadriere alle Elemente im Array.
-
Sortiere das Array in aufsteigender Reihenfolge.
-
Mach zwei Runden. Die äußere Schleife geht vom letzten Index des Arrays bis 1, und die innere Schleife fängt bei (
outer_loop_index - 1) an und geht bis zum Anfang. -
Erstell „
set()“, um die Elemente zwischen dem Index der äußeren Schleife und dem Index der inneren Schleife zu speichern. -
Schau mal, ob es in der Menge eine Zahl gibt, die gleich
(array[outerLoopIndex] – array[innerLoopIndex])ist. Wenn ja, gib „True“ zurück, sonst „False“.
def checkTriplet(array):
n = len(array)
for i in range(n):
array[i] = array[i]**2
array.sort()
for i in range(n - 1, 1, -1):
s = set()
for j in range(i - 1, -1, -1):
if (array[i] - array[j]) in s:
return True
s.add(array[j])
return False
arr = [3, 2, 4, 6, 5]
checkTriplet(arr)
# True32. Wie viele Möglichkeiten gibt's, mit Münzen und einem Gesamtbetrag Wechselgeld herauszugeben?
Wir müssen eine Funktion erstellen, die eine Liste mit Münzwerten und einen Gesamtbetrag nimmt und dann die Anzahl der Möglichkeiten zurückgibt, wie wir das Wechselgeld herausgeben können.
In diesem Beispiel haben wir Münzwerte von [1, 2, 5] und den Gesamtbetrag von 5angegeben. Im Gegenzug kriegen wir vier Möglichkeiten, um die Änderung vorzunehmen.
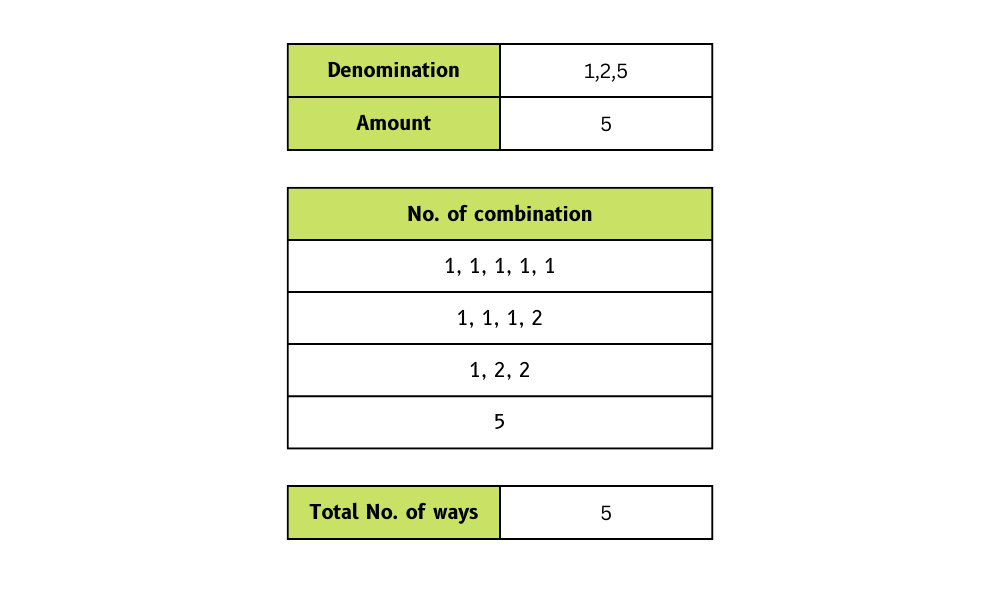
Bild vom Autor
Lösung:
- Wir machen die Liste mit der Größe „
amount + 1“. Es wird zusätzlicher Platz hinzugefügt, um die Lösung kostenlos zu speichern. - Wir fangen mit einer Liste von Lösungen an mit
solution[0] = 1. - Wir machen zwei Runden. Die äußere Schleife geht alle Nennwerte durch, und die innere Schleife läuft vom aktuellen Nennwert bis zum
amount + 1. - Die Ergebnisse der verschiedenen Konfessionen sind im Array gespeichert. Lösunggespeichert.
solution[i] = solution[i] + solution[i - den].
Der Vorgang wird für alle Elemente in der Nennungsliste wiederholt, und am Ende Element der Lösungsliste haben wir dann unsere Zahl.
def solve_coin_change(denominations, amount):
solution = [0] * (amount + 1)
solution[0] = 1
for den in denominations:
for i in range(den, amount + 1):
solution[i] += solution[i - den]
return solution[amount]
denominations = [1, 2, 5]
amount = 5
solve_coin_change(denominations, amount)
# 4Google Python-Interviewfragen
Wie bei den anderen erwähnten Unternehmen hängen die Python-Interviewfragen bei Google von der Position und der Erfahrung ab. Ein paar häufig gestellte Fragen sind:
33. Definiere eine Lambda-Funktion, einen Iterator und einen Generator in Python.
Die Lambda-Funktion wird auch als anonyme Funktion bezeichnet. Du kannst beliebig viele Parameter hinzufügen, aber nur mit einer einzigen Anweisung.
Ein Iterator ist ein Ding, mit dem wir über iterierbare Objekte wie Listen, Wörterbücher, Tupel und Mengen durchlaufen können.
Der Generator ist eine Funktion, die einer normalen Funktion ähnelt, aber er generiert einen Wert mit dem Schlüsselwort „yield“ statt mit „return“. Wenn der Funktionskörper yield enthält, wird er automatisch zu einem Generator.
Mehr über Python-Iteratoren und -Generatoren erfährst du in unserem kompletten Tutorial.
34. Such in dem Array arr[] den größten Wert j – i, sodass arr[j] größer als arr[i] ist.
Diese Frage ist ziemlich einfach, erfordert aber besondere Aufmerksamkeit für Details. Wir haben eine Reihe von positiven ganzen Zahlen. Wir müssen den größten Unterschied zwischen j und i finden, wo array[j] größer ist als array[i].
Beispiele:
- Eingabe: [20, 70, 40, 50, 12, 38, 98], Ausgabe: 6 (j = 6, i = 0)
- Eingabe: [10, 3, 2, 4, 5, 6, 7, 8, 18, 0], Ausgabe: 8 (j = 8, i = 0)
Lösung:
- Berechne die Länge des Arrays und starte die maximale Differenz mit -1.
- Mach zwei Runden. Die äußere Schleife holt sich Elemente von links, und die innere Schleife vergleicht die geholten Elemente mit Elementen, die von rechts kommen.
- Halt die innere Schleife an, wenn das Element größer als das ausgewählte Element ist, und aktualisier die maximale Differenz immer weiter mit j - I.
def max_index_diff(array):
n = len(array)
max_diff = -1
for i in range(0, n):
j = n - 1
while(j > i):
if array[j] > array[i] and max_diff < (j - i):
max_diff = j - i
j -= 1
return max_diff
array_1 = [20,70,40,50,12,38,98]
max_index_diff(array_1)
# 635. Wie würdest du die ternären Operatoren in Python nutzen?
Ternäre Operatoren werden auch als bedingte Ausdrücke bezeichnet. Das sind Operatoren, die Ausdrücke anhand der Bedingungen „wahr“ und „falsch“ auswerten.
Du kannst bedingte Ausdrücke in einer einzigen Zeile schreiben, anstatt mehrere Zeilen mit if-else-Anweisungen zu verwenden. Damit kannst du sauberen und kompakten Code schreiben.
Zum Beispiel können wir verschachtelte if-else-Anweisungen in eine einzige Zeile umwandeln, wie unten gezeigt.
If-else-Anweisung
score = 75
if score < 70:
if score < 50:
print('Fail')
else:
print('Merit')
else:
print('Distinction')
# DistinctionVerschachtelter ternärer Operator
print('Fail' if score < 50 else 'Merit' if score < 70 else 'Distinction')
# Distinction36. Wie würdest du einen LRU-Cache in Python machen?
Python hat einen eingebauten Dekorator namens „ functools.lru_cache “, mit dem man einen LRU-Cache (Least Recently Used) machen kann. Du kannst auch selbst eine erstellen, indem du die Datei „ OrderedDict ” von collections nimmst.
Beispiel mit „ functools “:
from functools import lru_cache
@lru_cache(maxsize=3)
def add(a, b):
return a + b
print(add(1, 2)) # Calculates and caches result
print(add(1, 2)) # Retrieves result from cacheVerbessere die Fähigkeiten deines Teams mit Python
Die Vorbereitung auf Python-Vorstellungsgespräche ist zwar für Jobsuchende und Personalverantwortliche wichtig, aber genauso wichtig ist es für Unternehmen, in die kontinuierliche Python-Weiterbildung ihrer Teams zu investieren. In einer Zeit, in der Automatisierung, Datenanalyse und Softwareentwicklung echt wichtig sind, kann es für den Erfolg deines Unternehmens entscheidend sein, dass deine Mitarbeiter gute Python-Kenntnisse haben.
Wenn du ein Teamleiter oder Unternehmer bist und sicherstellen willst, dass dein ganzes Team Python gut beherrscht, bietet DataCamp for Business maßgeschneiderte Schulungsprogramme, mit denen deine Mitarbeiter Python-Kenntnisse von den Grundlagen bis hin zu fortgeschrittenen Konzepten erlernen können. Wir können Folgendes anbieten:
- Gezielte Lernpfade: Du kannst es an das aktuelle Qualifikationsniveau deines Teams und die spezifischen Geschäftsanforderungen anpassen.
- Praktische Übungen: Praktische Projekte und Programmierübungen, die das Gelernte festigen und das Behalten verbessern.
- Fortschrittsverfolgung: Tools, um den Fortschritt deines Teams zu checken und zu bewerten, damit sie ihre Lernziele erreichen.
Wenn du über Plattformen wie DataCamp in Python-Weiterbildungen investierst, machst du nicht nur dein Team besser, sondern verschaffst deinem Unternehmen auch einen strategischen Vorteil. So kannst du innovativ sein, wettbewerbsfähig bleiben und beeindruckende Ergebnisse erzielen. Sprich mit unserem Team und frag noch heute nach einer Demo.
Steigere die Python-Kenntnisse deines Teams
Trainiere dein Team in Python mit DataCamp for Business. Umfassende Schulungen, praktische Projekte und detaillierte Leistungskennzahlen für dein Unternehmen.
