
Cursus
Introductie tot Git
2 Hr
85K
Je werkt aan een featurebranch wanneer een teamgenoot je vraagt hun pull request te reviewen. Je zou je wijzigingen kunnen stashen, van branch wisselen en hopen dat je onthoudt waar je was gebleven. Of je commit half-af werk om te voorkomen dat je het kwijtraakt. Dan is er nog de spoed-hotfix: productie ligt plat, en jij zit midden in een refactor die de helft van de codebase raakt. Elke contextswitch als deze kost 10–15 minuten aan opstarttijd en breekt je focus.
Git worktree lost dit op door je toe te staan meerdere branches tegelijk uit te checken in aparte mappen. In plaats van onvoltooid werk te stashen of te committen, cd je simpelweg naar een andere map waar al een andere branch is uitgecheckt. Werk aan de hotfix, deploy ’m, en cd vervolgens terug naar je featurewerk, precies zoals je het had achtergelaten.
In deze tutorial laat ik je zien hoe je worktrees maakt en beheert, veelvoorkomende valkuilen vermijdt en ze integreert in je dagelijkse workflow. Je zou Git branches, commits en basiscommandolijnhandelingen al moeten begrijpen. Als je eerst je Git-basis wilt opfrissen, raad ik DataCamp’s Introduction to Git-tutorial aan om de essentials te behandelen.
Git worktree is een ingebouwde functie die extra werkmappen maakt die aan dezelfde repository zijn gekoppeld. Je hoofdwerkmap is de primaire worktree, en elke extra worktree die je maakt krijgt een eigen map met een eigen uitgecheckte branch. Al deze worktrees verbinden met dezelfde .git-repository.
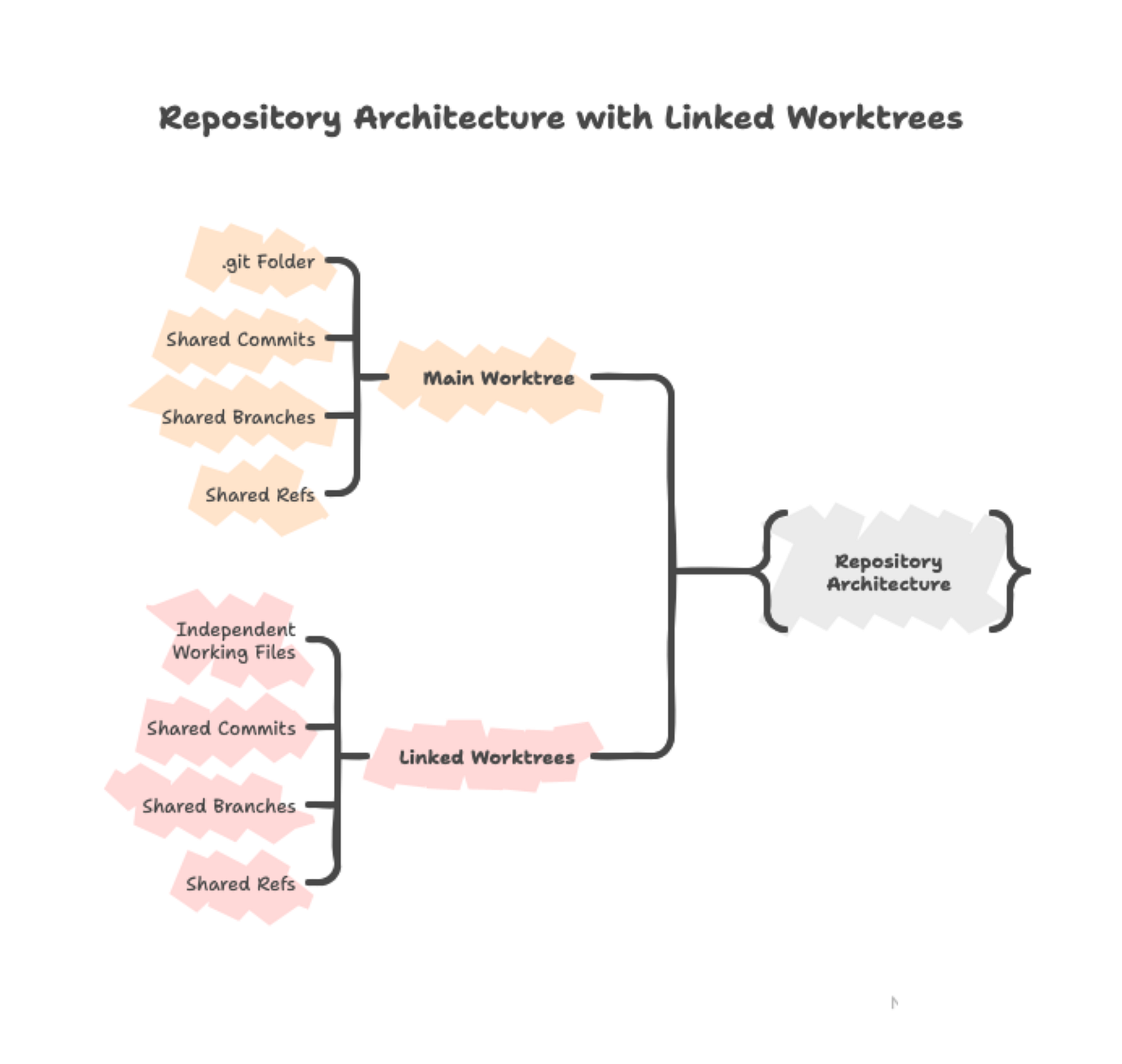
Deze gedeelde repository-architectuur betekent dat commits die je in een worktree maakt onmiddellijk verschijnen in de gedeelde Git-database, bereikbaar vanuit alle andere worktrees. De bestanden zelf blijven onafhankelijk — het bewerken van train.py in één worktree raakt alleen die map tot je de wijzigingen commit.
Je kunt niet meerdere terminals in dezelfde map openen en tegelijk aan verschillende branches werken. Git staat per map maar één uitgecheckte branch toe. Als je git checkout feature-b in één terminal draait, verandert dat de bestanden voor elke terminal die naar die map wijst.
Git worktree lost dit op door elke branch een eigen map te geven. Elke map is volledig onafhankelijk met eigen bestanden, draaiende processen en build-artifacts. Tussen branches wisselen wordt cd ../different-directory in plaats van git checkout different-branch.
Controleer vóór gebruik van git worktree je setup:
git --version om te controleren. Git worktree verscheen in 2015, dus de meeste installaties hebben hetControleer of worktree beschikbaar is:
git worktree --helpAls dit de helppagina toont, ben je klaar.
Git worktree werkt goed wanneer branches wisselen je huidige werk zou onderbreken:
Sla het over voor snelle taken onder 10 minuten waar git checkout eenvoudiger is, of wanneer je gefocust bent op één taak zonder onderbrekingen te verwachten.
De beste manier om git worktree te begrijpen is er één te maken en het in actie te zien. We lopen door de basiscommando’s, verkennen de structuur die Git maakt en bekijken hoe wijzigingen tussen worktrees stromen.
Voordat we in worktrees duiken, heb je een Git-repository nodig om mee te werken. Als je al een Pythonproject met meerdere branches hebt, ga dan door naar de volgende sectie. Anders zetten we snel een simpele ML-pipeline op:
mkdir ml-pipeline
cd ml-pipeline
git initMaak een README en een Pythonscript aan:
echo "# ML Pipeline" > README.md
echo "def load_data():" > train.py
echo " print('Loading training data...')" >> train.pyControleer of de bestanden zijn aangemaakt:
ls
# You should see: README.md train.pyCommit deze bestanden en maak een featurebranch:
git add .
git commit -m "Initial commit"
git branch feature-preprocessingNu heb je een repository met twee branches: main (je huidige branch) en feature-preprocessing.
Een worktree voor een bestaande branch maken vergt maar één commando. Laten we feature-preprocessing uitchecken in een aparte map:
git worktree add ../ml-pipeline-preprocessing feature-preprocessingDit maakt een nieuwe map genaamd ml-pipeline-preprocessing één niveau boven je huidige locatie, checkt daar de branch feature-preprocessing uit en koppelt deze aan je bestaande repository.
Git bevestigt de aanmaak:
Preparing worktree (checking out 'feature-preprocessing')
HEAD is now at 0a7f986 Initial commitVoor gloednieuw werk maak je tegelijk een branch en een worktree aan:
git worktree add -b feature-visualization ../ml-pipeline-vizDe -b-vlag maakt een nieuwe branch genaamd feature-visualization en checkt deze uit in de nieuwe worktree.
Met je worktree gemaakt heb je nu meerdere mappen op je bestandssysteem. Om ze allemaal te zien:
git worktree list/Users/you/projects/ml-pipeline 0a7f986 [main]
/Users/you/projects/ml-pipeline-preprocessing 0a7f986 [feature-preprocessing]De eerste regel toont je hoofdworktree — de originele map met de .git-map. De tweede regel toont je gekoppelde worktree. Beide tonen de huidige commit-hash en de uitgecheckte branch.
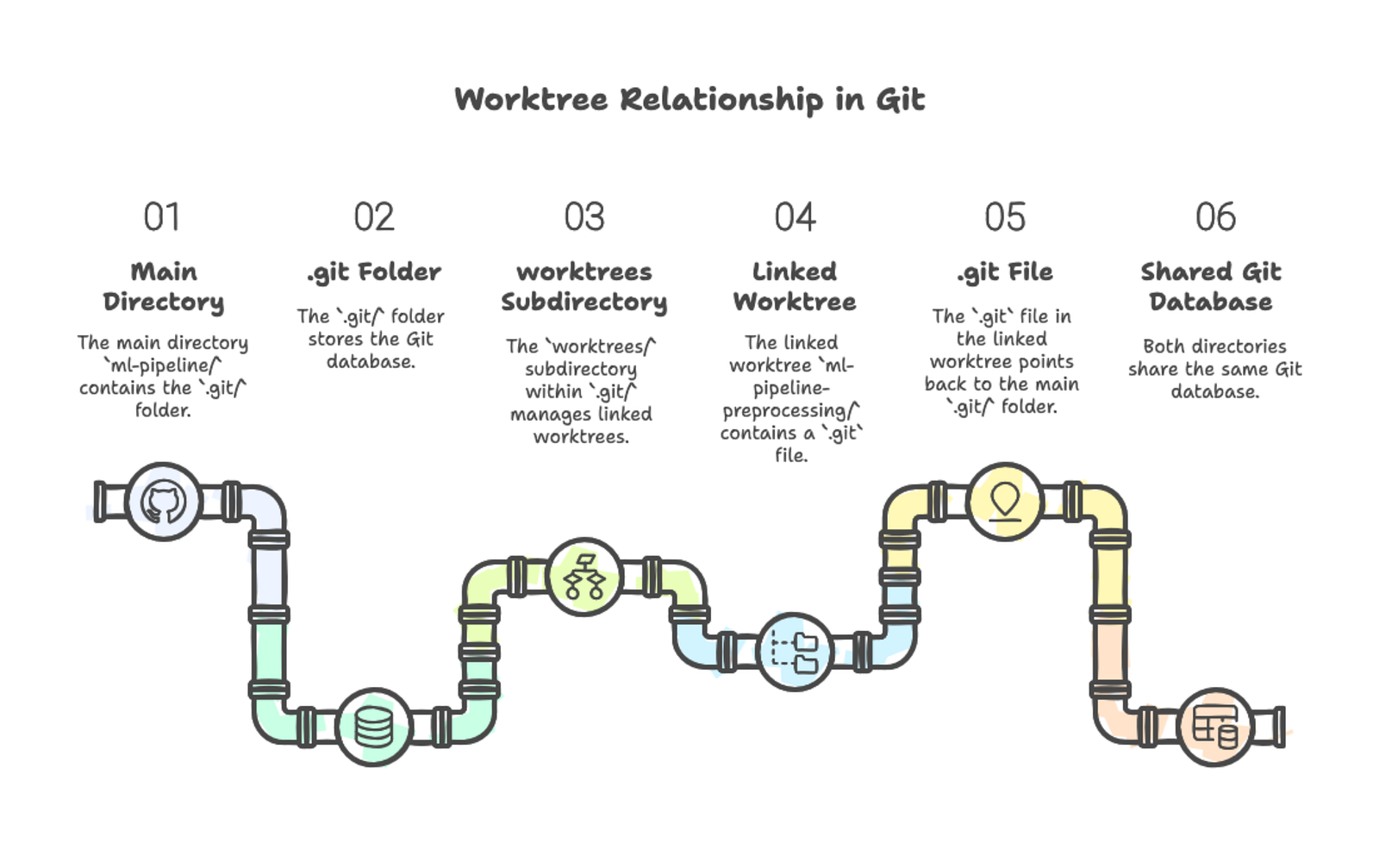
Elke worktree-map functioneert als een volledige Git-repository. Je kunt ernaartoe navigeren, bestanden bewerken, git status draaien en commits maken. Gekoppelde worktrees bevatten geen volledige .git-map — in plaats daarvan hebben ze een .git-bestand dat terugwijst naar de hoofdrepository. In de hoofd-.git-map slaat een worktrees-map metadata op over elke gekoppelde worktree.
Navigeer naar de feature-preprocessing-worktree en maak een commit:
cd ../ml-pipeline-preprocessing
cat >> train.py << 'EOF'
def preprocess_features(df):
"""Normalize numeric features."""
return (df - df.mean()) / df.std()
EOF
git add train.py
git commit -m "Add feature preprocessing function"De commit gaat normaal door:
[feature-preprocessing 7c8d4e2] Add feature preprocessing function
1 file changed, 3 insertions(+)Ga terug naar je hoofdworktree en bekijk de commitgeschiedenis:
cd ../ml-pipeline
git log --oneline --allJe nieuwe commit verschijnt:
7c8d4e2 Add feature preprocessing function
0a7f986 Initial commitLet op hoe de commit direct op beide locaties verschijnt zonder extra commando’s.
Nu je weet hoe je worktrees maakt en erin werkt, kijken we naar praktische scenario’s waarin ze echte ontwikkelproblemen oplossen.
Je teamgenoot heeft feedback nodig op hun PR. In plaats van je wijzigingen te stashen en van branch te wisselen, maak je een aparte map voor de review:
git worktree add ../ml-pipeline-review pr/update-training
cd ../ml-pipeline-review
pip install -r requirements.txt
python train_model.py --config experiments/baseline.yamlTest de wijzigingen en laat je feedback achter. Klaar?
cd ../ml-pipeline
git worktree remove ../ml-pipeline-reviewJe oorspronkelijke werk blijft onaangeroerd. Geen stashing of contextswitch nodig. Voor meer strategieën over effectieve code reviews, bekijk DataCamp’s gids met best practices voor code reviews.
Zonder worktrees:
Met worktrees:
git worktree add ../ml-pipeline-hotfix main
cd ../ml-pipeline-hotfixFix en deploy:
git add src/data/validation.py
git commit -m "Fix schema validation for nullable timestamp fields"
git push origin main
cd ../ml-pipeline
git worktree remove ../ml-pipeline-hotfixJe bent in seconden terug in je refactorwerk, met alle bestanden precies zoals je ze had achtergelaten.
Je implementeert custom metrics en een nieuwe dataloader — twee onafhankelijke features. Zet voor elk een worktree op:
git worktree add -b feature-custom-metrics ../ml-pipeline-metrics
git worktree add -b feature-streaming-loader ../ml-pipeline-loaderJe bestandssysteem ziet er nu zo uit:
~/projects/
ml-pipeline/ [main] - je gebruikelijke werk
ml-pipeline-metrics/ [feature-custom-metrics]
ml-pipeline-loader/ [feature-streaming-loader]Draai beide features parallel — elk in z’n eigen terminal:
# Terminal 1
cd ~/projects/ml-pipeline-metrics
python experiments/evaluate_custom_metrics.py
# Terminal 2
cd ~/projects/ml-pipeline-loader
pytest tests/test_data_loader.py -vBeide processen draaien gelijktijdig zonder conflicten. Als een feature klaar is, merge je ’m en verwijder je de worktree:
cd ~/projects/ml-pipeline
git merge feature-custom-metrics
git worktree remove ../ml-pipeline-metrics
Om alle worktrees in een repository te zien:
git worktree list/Users/you/projects/ml-pipeline a3f9c81 [main]
/Users/you/projects/ml-pipeline-review b7d4e92 [pr/data-validation]
/Users/you/projects/ml-pipeline-hotfix a3f9c81 [hotfix/schema-bug]Elke regel toont het pad naar de map, de huidige commit-hash en de uitgecheckte branch. De eerste vermelding is altijd je hoofdworktree (met de .git-map), en de rest zijn gekoppelde worktrees.
Voor scripting of snelle navigatie, haal alleen de paden eruit:
git worktree list | awk '{print $1}'Als je klaar bent met werk in een worktree, verwijder ’m dan netjes:
cd ~/projects/ml-pipeline
git worktree remove ../ml-pipeline-reviewGit beschermt tegen dataverlies. Als je ongecommitte wijzigingen hebt:
git worktree remove ../ml-pipeline-reviewfatal: '../ml-pipeline-review' contains modified or untracked files, use --force to delete itForceer verwijdering als je zeker bent:
git worktree remove --force ../ml-pipeline-reviewAls een worktree vergrendeld is, gebruik --force twee keer:
git worktree remove --force --force ../ml-pipeline-lockedAls je een worktree-map handmatig hebt verwijderd (rm -rf of bestandsbeheerder), volgt Git ’m intern nog steeds. Ruim verouderde referenties op:
git worktree pruneBekijk een preview van wat gepruned zou worden:
git worktree prune --dry-runLaten we kijken naar manieren om het meeste uit worktrees te halen en hoe je een paar veelgemaakte fouten voorkomt.
Waar je worktrees neerzet, maakt uit. De meeste developers plaatsen ze als zuster-mappen naast de hoofdrepository:
~/projects/
ml-pipeline/ # hoofdworktree
ml-pipeline-feature-auth/ # gekoppelde worktree
ml-pipeline-hotfix-login/ # gekoppelde worktreeDeze structuur houdt alles bij elkaar en maakt paden voorspelbaar. Het patroon projectnaam-branchenaam vertelt je precies wat elke map bevat.
Sommige developers kiezen een speciale map:
~/projects/
ml-pipeline/ # hoofdworktree
ml-pipeline-worktrees/
feature-auth/
hotfix-login/Kies een aanpak en gebruik die consequent. Beschrijvende namen zoals ml-pipeline-user-authentication maken mappen zelfverklarend, terwijl generieke namen als ml-pipeline-temp of ml-pipeline-2 je dwingen te checken wat erin zit. Behandel worktrees als tijdelijk — maak ze voor een specifieke taak en verwijder ze als je klaar bent.
Git voorkomt dat je dezelfde branch in twee worktrees uitcheckt:
git worktree add ../ml-pipeline-duplicate mainfatal: 'main' is already used by worktree at '/Users/you/projects/ml-pipeline'Deze bescherming bestaat omdat je conflicterende commits zou kunnen maken. Als je dezelfde code op twee plekken nodig hebt, maak dan een nieuwe branch.
Elke worktree blijft op je bestandssysteem staan totdat je ’m expliciet verwijdert. Oude worktrees stapelen zich op; projecten kunnen 15+ vergeten worktrees verzamelen die gigabytes opslokken.
Elke worktree bevat een volledige kopie van de bestanden van je repository. Een repository van 500 MB met 5 worktrees gebruikt 2,5 GB. Verwijder worktrees als je klaar bent:
git worktree list
git worktree remove ../ml-pipeline-old-featureMaak geen worktree binnen de map van een andere worktree. Git staat dit toe, maar het zorgt voor verwarrende mappenstructuren en maakt opruimen foutgevoelig.
Shell-aliases besparen tijd als je vaak worktrees maakt:
alias gwl='git worktree list'
alias gwa='git worktree add'
alias gwr='git worktree remove'Voor complexere setup schrijf je een functie die in één stap een worktree maakt en je ontwikkelomgeving configureert:
wt() {
git worktree add "../${PWD##*/}-$1" -b "$1"
cd "../${PWD##*/}-$1"
python -m venv .venv && source .venv/bin/activate && pip install -r requirements.txt
}De ${PWD##*/} haalt je huidige mapnaam op. wt feature-logging draaien vanuit ml-pipeline maakt ml-pipeline-feature-logging aan, navigeert ernaartoe en zet een Python-virtualenv met dependencies op.
Een worktree maken wordt zo één commando:
wt feature-custom-metricsPas dit aan voor je taal: vervang de Python-setup door bundle install voor Ruby, cargo build voor Rust of npm install voor Node.js.
Je editor of IDE werkt met worktrees zonder speciale configuratie. Elke worktree is gewoon een map, dus open hem zoals elke andere projectmap. De meeste moderne editors ondersteunen het openen van meerdere projectroots tegelijk — je kunt drie worktrees in één venster open hebben en ertussen schakelen in de zijbalk.
Als je AI-coding assistants gebruikt, ontgrendelen worktrees een krachtige parallelle workflow. Deze aanpak wint aan populariteit onder developers en teams in 2024–2025.
Maak aparte worktrees voor verschillende taken:
git worktree add -b feature-add-logging ../ml-pipeline-logging
git worktree add -b feature-optimize-preprocessing ../ml-pipeline-optim
git worktree add -b bugfix-memory-leak ../ml-pipeline-bugfixOpen een terminalpane voor elke worktree en start je AI-assistent:
# Pane 1
cd ~/projects/ml-pipeline-logging
claude
# Pane 2
cd ~/projects/ml-pipeline-optim
claude
# Pane 3
cd ~/projects/ml-pipeline-bugfix
claudeElke AI-instance werkt aan een andere feature zonder elkaar te storen. Teams rapporteren werk in uren te voltooien dat eerder dagen kostte. Zo draait incident.io 4–5 Claude Code-agents parallel met dit patroon. In één geval schatte Claude dat een UI-verbetering 2 uur zou kosten maar was hij in 10 minuten klaar.
Afwegingen om te overwegen:
Dit werkt goed voor grote, onafhankelijke features (30+ minuten elk) waarbij werk niet dezelfde bestanden raakt en je voldoende API-quota hebt. Sla het over voor snelle bugfixes, strak gekoppelde features of wanneer je dicht bij API-rate limits zit.
Weet je dat scenario van het begin nog — een teamgenoot heeft een PR-review nodig terwijl jij midden in een feature zit? Je kent nu de oplossing: git worktree add ../ml-pipeline-review pr/branch-name, dan cd om te beginnen met reviewen. Je featurewerk blijft onaangeroerd. Geen stashing, geen half-af code committen, geen mentale overhead om je context opnieuw op te bouwen als je terugkeert. Twee mappen, twee branches, nul frictie.
Git worktree voegt geen complexiteit toe aan je workflow — het haalt die juist weg. Elke worktree is gewoon een map met een uitgecheckte branch. Maar die eenvoud ontgrendelt iets krachtigs: de mogelijkheid om direct tussen taken te schakelen zonder de cognitieve belasting van stashen, uitchecken en je mentale model opnieuw opbouwen.
Als je worktrees wilt integreren met teamworkflows zoals pull requests en code reviews, DataCamp’s GitHub Foundations skill track behandelt de essentiële praktijken om effectief te werken met gedistribueerde teams.
Topcursussen voor Git
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
