
Kurs
Einführung in Git
2 Std.
79K
Du arbeitest gerade an einem Feature-Branch, als dich ein Teamkollege um ein Review für seinen Pull-Request bittet. Du könntest deine Änderungen stashen, den Branch wechseln und hoffen, dass du später wieder reinkommst. Oder du committest halbfertige Arbeit, nur um nichts zu verlieren. Dann noch der Notfall-Hotfix: Die Produktion steht, und du steckst mitten in einem Refactoring, das die halbe Codebase berührt. Jeder dieser Kontextwechsel kostet 10–15 Minuten Rüstzeit und reißt dich aus dem Fokus.
Git worktree löst das, indem du mehrere Branches gleichzeitig in separaten Verzeichnissen auschecken kannst. Statt zu stashen oder unfertige Commits zu machen, wechselst du einfach mit cd in ein anderes Verzeichnis, in dem bereits ein anderer Branch ausgecheckt ist. Arbeite am Hotfix, deploye ihn und wechsle dann mit cd zurück zu deinem Feature – exakt so, wie du es verlassen hast.
In diesem Tutorial zeige ich dir, wie du Worktrees erstellst und verwaltest, typische Stolperfallen vermeidest und sie in deinen Alltag integrierst. Du solltest Git-Branches, Commits und grundlegende Befehlszeilenkenntnisse bereits mitbringen. Wenn du die Git-Grundlagen auffrischen willst, empfehle ich DataCamps Tutorial „Introduction to Git“ für das Wichtigste vorab.
Git worktree ist ein integriertes Feature, das zusätzliche Arbeitsverzeichnisse erzeugt, die mit demselben Repository verknüpft sind. Dein Hauptarbeitsverzeichnis ist der primäre Worktree, und jeder zusätzliche Worktree erhält sein eigenes Verzeichnis mit einem eigenen ausgecheckten Branch. Alle diese Worktrees hängen am selben .git-Repository.
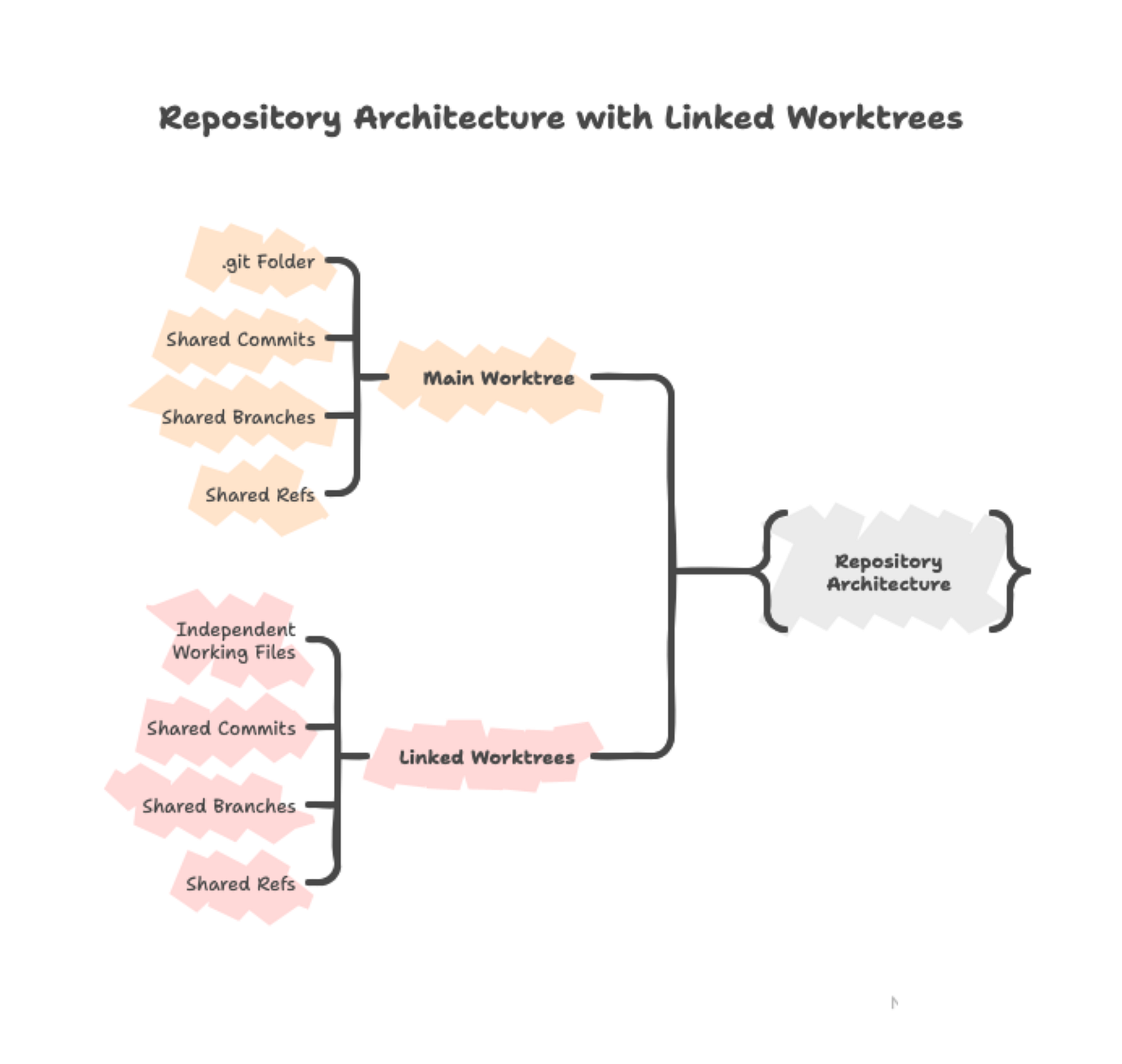
Diese geteilte Repository-Architektur bedeutet: Commits, die du in einem Worktree machst, erscheinen sofort in der gemeinsamen Git-Datenbank und sind in allen anderen Worktrees sichtbar. Die Dateien selbst bleiben unabhängig — wenn du train.py in einem Worktree bearbeitest, betrifft das nur dieses Verzeichnis, bis du die Änderungen committest.
Du kannst nicht in demselben Verzeichnis mehrere Terminals öffnen und gleichzeitig an verschiedenen Branches arbeiten. Git erlaubt pro Verzeichnis nur einen ausgecheckten Branch. Wenn du in einem Terminal git checkout feature-b ausführst, ändert das die Dateien für alle Terminals, die auf dieses Verzeichnis zeigen.
Git worktree löst das, indem jeder Branch sein eigenes Verzeichnis bekommt. Jedes Verzeichnis ist komplett unabhängig mit eigenen Dateien, laufenden Prozessen und Build-Artefakten. Der Wechsel zwischen Branches wird zu cd ../anderes-verzeichnis statt git checkout anderer-branch.
Bevor du git worktree nutzt, prüfe dein Setup:
git --version prüfen. Git worktree kam 2015 – die meisten Installationen haben es bereitsPrüfe, ob worktree verfügbar ist:
git worktree --helpWenn die Hilfeseite angezeigt wird, bist du startklar.
Git worktree ist ideal, wenn ein Branch-Wechsel deine aktuelle Arbeit stören würde:
Lass es bei kurzen Aufgaben unter 10 Minuten, bei denen git checkout einfacher ist, oder wenn du fokussiert an einem einzigen Thema ohne Unterbrechungen arbeitest.
Am besten verstehst du git worktree, wenn du einen erstellst und live ausprobierst. Wir gehen die Grundbefehle durch, schauen uns die von Git erzeugte Struktur an und beobachten, wie Änderungen zwischen Worktrees fließen.
Bevor wir in Worktrees einsteigen, brauchst du ein Git-Repository. Wenn du bereits ein Python-Projekt mit mehreren Branches hast, spring zum nächsten Abschnitt. Andernfalls richten wir schnell eine einfache ML-Pipeline ein:
mkdir ml-pipeline
cd ml-pipeline
git initErstelle eine README und ein Python-Skript:
echo "# ML Pipeline" > README.md
echo "def load_data():" > train.py
echo " print('Loading training data...')" >> train.pyPrüfe, ob die Dateien erstellt wurden:
ls
# Du solltest sehen: README.md train.pyDiese Dateien committen und einen Feature-Branch anlegen:
git add .
git commit -m "Initial commit"
git branch feature-preprocessingJetzt hast du ein Repository mit zwei Branches: main (dein aktueller Branch) und feature-preprocessing.
Einen Worktree für einen bestehenden Branch zu erstellen, braucht nur einen Befehl. Lass uns feature-preprocessing in einem separaten Verzeichnis auschecken:
git worktree add ../ml-pipeline-preprocessing feature-preprocessingDadurch entsteht ein neues Verzeichnis namens ml-pipeline-preprocessing eine Ebene über deinem aktuellen Ort, der Branch feature-preprocessing wird dort ausgecheckt und mit deinem bestehenden Repository verknüpft.
Git bestätigt die Erstellung:
Preparing worktree (checking out 'feature-preprocessing')
HEAD is now at 0a7f986 Initial commitFür komplett neue Arbeit erstellst du Branch und Worktree in einem Schritt:
git worktree add -b feature-visualization ../ml-pipeline-vizDer Schalter -b erzeugt einen neuen Branch namens feature-visualization und checkt ihn im neuen Worktree aus.
Mit dem angelegten Worktree hast du nun mehrere Verzeichnisse im Dateisystem. Um alle anzuzeigen:
git worktree list/Users/you/projects/ml-pipeline 0a7f986 [main]
/Users/you/projects/ml-pipeline-preprocessing 0a7f986 [feature-preprocessing]Die erste Zeile zeigt deinen Haupt-Worktree — das ursprüngliche Verzeichnis mit dem .git-Ordner. Die zweite Zeile zeigt den verknüpften Worktree. Beide zeigen den aktuellen Commit-Hash und den ausgecheckten Branch.
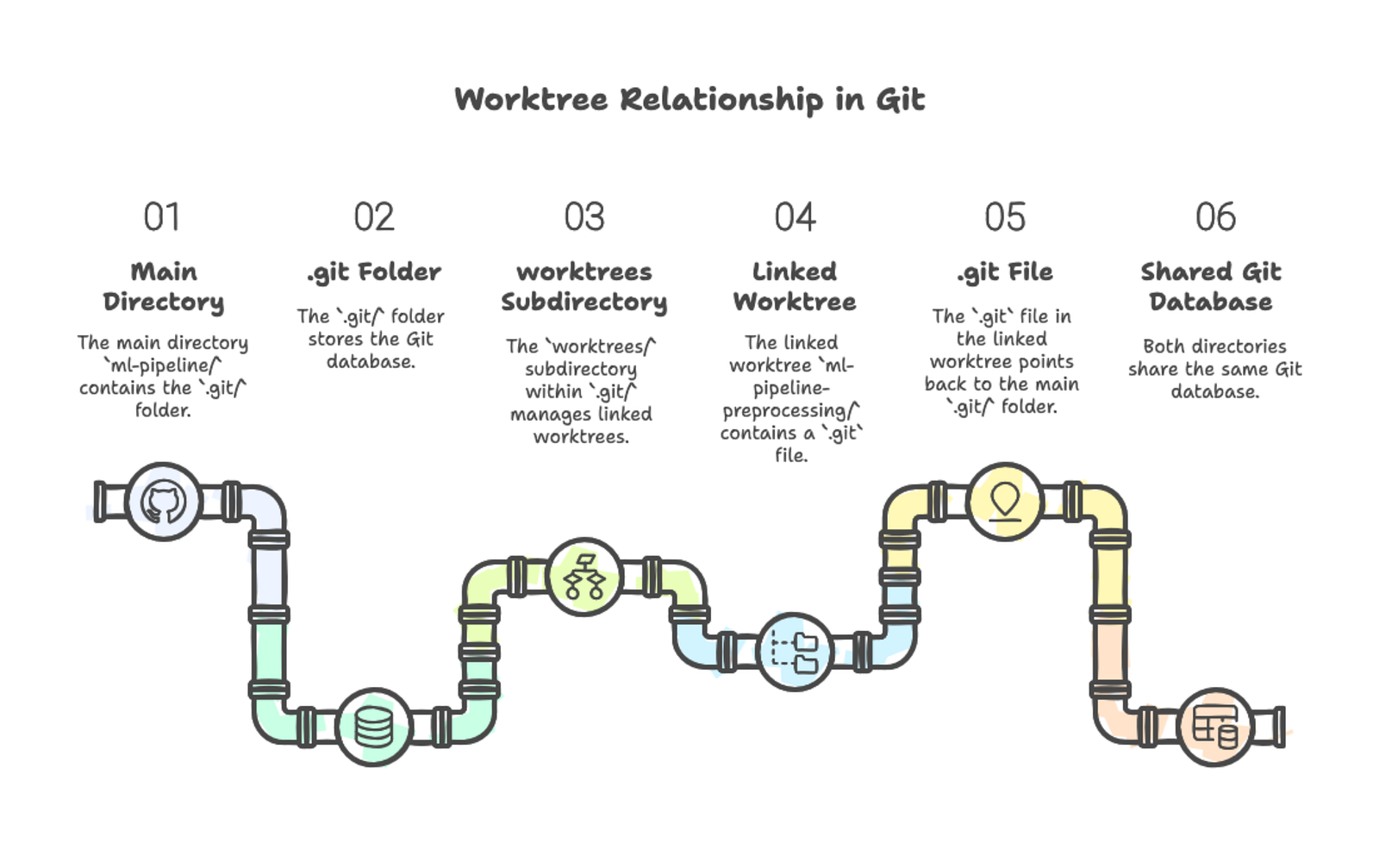
Jedes Worktree-Verzeichnis funktioniert wie ein vollständiges Git-Repository. Du kannst hinein navigieren, Dateien bearbeiten, git status ausführen und Commits machen. Verknüpfte Worktrees enthalten keinen vollständigen .git-Ordner — stattdessen gibt es eine .git-Datei, die auf das Haupt-Repository verweist. Im Haupt-.git-Verzeichnis speichert ein worktrees-Ordner Metadaten zu jedem verknüpften Worktree.
Wechsle zum Worktree feature-preprocessing und mach einen Commit:
cd ../ml-pipeline-preprocessing
cat >> train.py << 'EOF'
def preprocess_features(df):
"""Normalize numeric features."""
return (df - df.mean()) / df.std()
EOF
git add train.py
git commit -m "Add feature preprocessing function"Der Commit läuft ganz normal durch:
[feature-preprocessing 7c8d4e2] Add feature preprocessing function
1 file changed, 3 insertions(+)Geh zurück in deinen Haupt-Worktree und prüfe die Historie:
cd ../ml-pipeline
git log --oneline --allDein neuer Commit erscheint:
7c8d4e2 Add feature preprocessing function
0a7f986 Initial commitBeachte, dass der Commit sofort an beiden Orten sichtbar ist – ohne weitere Befehle.
Jetzt, da du weißt, wie du Worktrees erstellst und nutzt, schauen wir uns praxisnahe Szenarien an, in denen sie echte Probleme in der Entwicklung lösen.
Dein Teamkollege braucht Feedback zu seinem PR. Statt deine Änderungen zu stashen und den Branch zu wechseln, erstell ein separates Verzeichnis fürs Review:
git worktree add ../ml-pipeline-review pr/update-training
cd ../ml-pipeline-review
pip install -r requirements.txt
python train_model.py --config experiments/baseline.yamlTeste die Änderungen und gib dein Feedback. Wenn du fertig bist:
cd ../ml-pipeline
git worktree remove ../ml-pipeline-reviewDeine ursprüngliche Arbeit bleibt unberührt. Kein Stashing, kein Kontextwechsel nötig. Mehr Strategien für effektive Code-Reviews findest du im DataCamp-Guide zu Best Practices für Code-Reviews.
Ohne Worktrees:
Mit Worktrees:
git worktree add ../ml-pipeline-hotfix main
cd ../ml-pipeline-hotfixFixen und deployen:
git add src/data/validation.py
git commit -m "Fix schema validation for nullable timestamp fields"
git push origin main
cd ../ml-pipeline
git worktree remove ../ml-pipeline-hotfixDu bist in Sekunden zurück in deinem Refactoring – mit allen Dateien exakt wie zuvor.
Du implementierst Custom-Metriken und einen neuen Dataloader — zwei unabhängige Features. Richte für jedes einen Worktree ein:
git worktree add -b feature-custom-metrics ../ml-pipeline-metrics
git worktree add -b feature-streaming-loader ../ml-pipeline-loaderDein Dateisystem sieht jetzt so aus:
~/projects/
ml-pipeline/ [main] - deine übliche Arbeit
ml-pipeline-metrics/ [feature-custom-metrics]
ml-pipeline-loader/ [feature-streaming-loader]Lass beide Features parallel laufen — jeweils in einem eigenen Terminal:
# Terminal 1
cd ~/projects/ml-pipeline-metrics
python experiments/evaluate_custom_metrics.py
# Terminal 2
cd ~/projects/ml-pipeline-loader
pytest tests/test_data_loader.py -vBeide Prozesse laufen gleichzeitig ohne Konflikte. Wenn ein Feature fertig ist, merge es und entferne den Worktree:
cd ~/projects/ml-pipeline
git merge feature-custom-metrics
git worktree remove ../ml-pipeline-metrics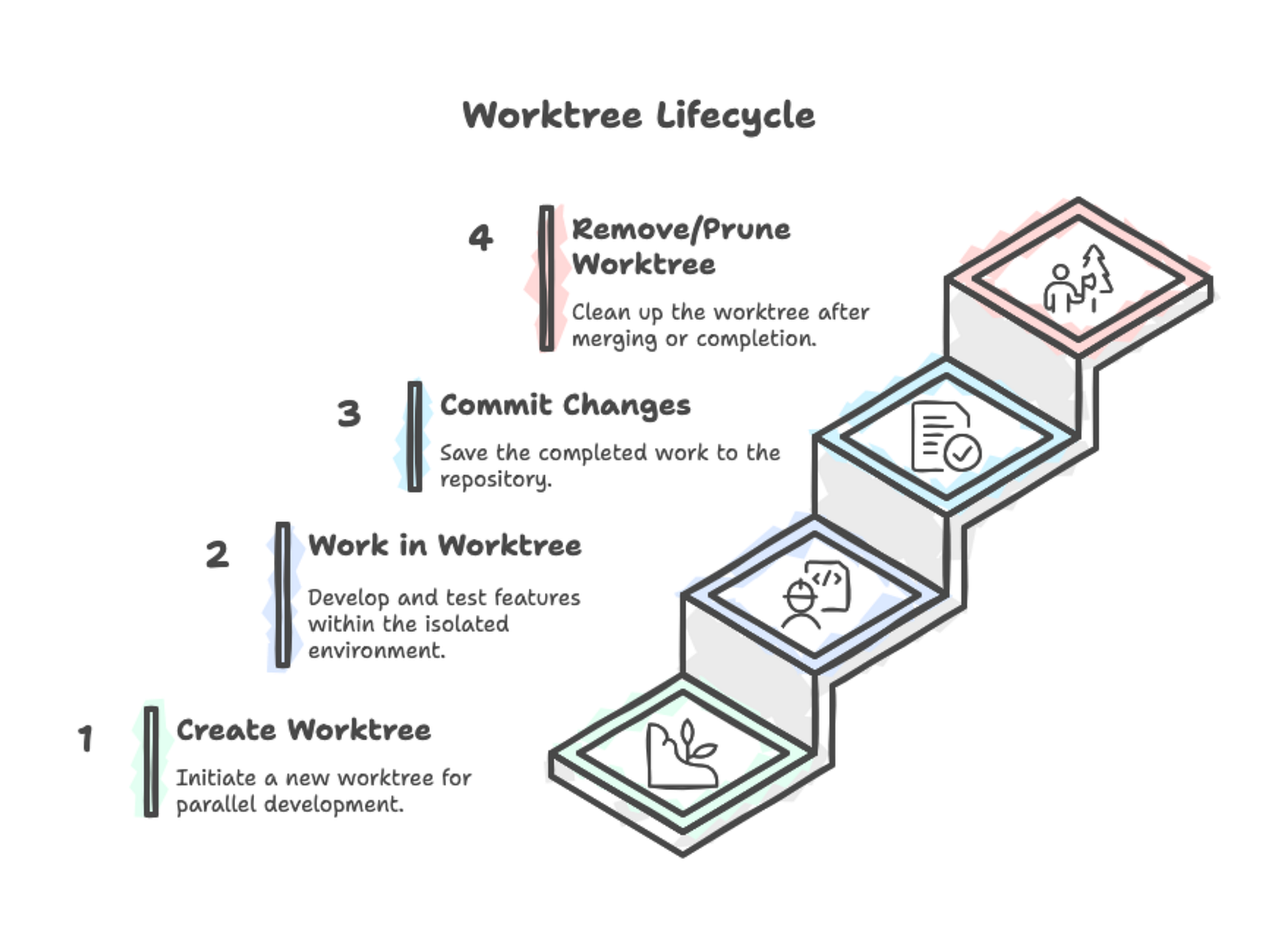
So siehst du alle Worktrees in einem Repository:
git worktree list/Users/you/projects/ml-pipeline a3f9c81 [main]
/Users/you/projects/ml-pipeline-review b7d4e92 [pr/data-validation]
/Users/you/projects/ml-pipeline-hotfix a3f9c81 [hotfix/schema-bug]Jede Zeile zeigt den Verzeichnispfad, den aktuellen Commit-Hash und den ausgecheckten Branch. Der erste Eintrag ist immer dein Haupt-Worktree (mit dem .git-Ordner), die restlichen sind verknüpfte Worktrees.
Für Skripte oder schnelles Navigieren kannst du nur die Pfade extrahieren:
git worktree list | awk '{print $1}'Wenn du in einem Worktree fertig bist, entferne ihn sauber:
cd ~/projects/ml-pipeline
git worktree remove ../ml-pipeline-reviewGit schützt vor Datenverlust. Wenn es uncommittete Änderungen gibt:
git worktree remove ../ml-pipeline-reviewfatal: '../ml-pipeline-review' contains modified or untracked files, use --force to delete itErzwinge das Entfernen, wenn du sicher bist:
git worktree remove --force ../ml-pipeline-reviewWenn ein Worktree gesperrt ist, nutze --force doppelt:
git worktree remove --force --force ../ml-pipeline-lockedWenn du ein Worktree-Verzeichnis manuell gelöscht hast (rm -rf oder Dateimanager), verfolgt Git es intern weiter. Räum veraltete Referenzen auf:
git worktree pruneZeige vorab, was entfernt würde:
git worktree prune --dry-runSchauen wir uns an, wie du das Maximum aus Worktrees herausholst und typische Fehler vermeidest.
Wo du Worktrees ablegst, ist wichtig. Die meisten legen sie als Geschwisterverzeichnisse zum Haupt-Repository an:
~/projects/
ml-pipeline/ # main worktree
ml-pipeline-feature-auth/ # linked worktree
ml-pipeline-hotfix-login/ # linked worktreeDiese Struktur hält alles beisammen und macht Pfade vorhersehbar. Das Muster projektname-branchname sagt dir genau, was im Verzeichnis steckt.
Manche bevorzugen einen eigenen Ordner:
~/projects/
ml-pipeline/ # main worktree
ml-pipeline-worktrees/
feature-auth/
hotfix-login/Wähle eine Variante und bleib konsistent. Aussagekräftige Namen wie ml-pipeline-user-authentication dokumentieren sich selbst, während generische wie ml-pipeline-temp oder ml-pipeline-2 dich zwingen, nachzusehen. Behandle Worktrees als temporär — erstelle sie für eine konkrete Aufgabe und entferne sie danach.
Git verhindert, dass derselbe Branch in zwei Worktrees ausgecheckt wird:
git worktree add ../ml-pipeline-duplicate mainfatal: 'main' is already used by worktree at '/Users/you/projects/ml-pipeline'Dieser Schutz existiert, weil du sonst widersprüchliche Commits erzeugen könntest. Wenn du denselben Code an zwei Orten brauchst, erstelle einen neuen Branch.
Jeder Worktree bleibt auf deinem Dateisystem, bis du ihn explizit entfernst. Alte Worktrees stapeln sich; Projekte sammeln schnell 15+ vergessene Worktrees und belegen Gigabytes.
Jeder Worktree enthält eine vollständige Kopie der Dateien deines Repositories. Ein 500-MB-Repository mit 5 Worktrees belegt 2,5 GB. Entferne Worktrees, wenn du fertig bist:
git worktree list
git worktree remove ../ml-pipeline-old-featureErstelle keinen Worktree innerhalb des Verzeichnisses eines anderen Worktrees. Git erlaubt es, aber es führt zu verwirrenden Strukturen und erschwert das Aufräumen.
Shell-Aliasse sparen Zeit, wenn du häufig Worktrees erstellst:
alias gwl='git worktree list'
alias gwa='git worktree add'
alias gwr='git worktree remove'Für komplexere Setups schreib eine Funktion, die in einem Schritt einen Worktree erstellt und deine Entwicklungsumgebung konfiguriert:
wt() {
git worktree add "../${PWD##*/}-$1" -b "$1"
cd "../${PWD##*/}-$1"
python -m venv .venv && source .venv/bin/activate && pip install -r requirements.txt
}Die Variable ${PWD##*/} extrahiert den Namen deines aktuellen Verzeichnisses. wt feature-logging aus ml-pipeline erzeugt ml-pipeline-feature-logging, wechselt hinein und setzt eine Python-Virtualenv samt Abhängigkeiten auf.
Einen Worktree zu erstellen, wird so zum Einzeiler:
wt feature-custom-metricsPasse das für deine Sprache an: Ersetze das Python-Setup durch bundle install für Ruby, cargo build für Rust oder npm install für Node.js.
Dein Editor oder deine IDE funktioniert ohne Spezialkonfiguration mit Worktrees. Jeder Worktree ist einfach ein Verzeichnis – also öffne ihn wie jeden anderen Projektordner. Moderne Editoren können mehrere Projektwurzeln gleichzeitig öffnen — du kannst drei Worktrees in einem Fenster geöffnet haben und in der Sidebar wechseln.
Wenn du KI-Coding-Assistenten nutzt, schalten Worktrees einen mächtigen Parallel-Workflow frei. Dieser Ansatz hat 2024–2025 bei Entwicklerinnen, Entwicklern und Teams an Fahrt aufgenommen.
Erstelle separate Worktrees für verschiedene Aufgaben:
git worktree add -b feature-add-logging ../ml-pipeline-logging
git worktree add -b feature-optimize-preprocessing ../ml-pipeline-optim
git worktree add -b bugfix-memory-leak ../ml-pipeline-bugfixÖffne für jeden Worktree ein Terminal-Panel und starte deinen KI-Assistenten:
# Pane 1
cd ~/projects/ml-pipeline-logging
claude
# Pane 2
cd ~/projects/ml-pipeline-optim
claude
# Pane 3
cd ~/projects/ml-pipeline-bugfix
claudeJede KI-Instanz arbeitet an einem anderen Feature, ohne sich in die Quere zu kommen. Teams berichten, dass Arbeit, die früher Tage dauerte, in Stunden erledigt wird. Zum Beispiel betreibt incident.io 4–5 Claude-Code-Agenten parallel mit diesem Muster. In einem Fall schätzte Claude eine UI-Verbesserung auf 2 Stunden – fertig in 10 Minuten.
Abzuwägen:
Das eignet sich für große, unabhängige Features (je 30+ Minuten), die nicht dieselben Dateien berühren und wenn genügend API-Kontingent vorhanden ist. Lass es bei schnellen Bugfixes, eng gekoppelten Features oder in der Nähe von API-Limits.
Erinnerst du dich an das Szenario vom Anfang — ein Teamkollege braucht ein PR-Review, während du mitten im Feature steckst. Jetzt kennst du die Lösung: git worktree add ../ml-pipeline-review pr/branch-name, dann cd und mit dem Review starten. Deine Feature-Arbeit bleibt unberührt. Kein Stashing, keine halbfertigen Commits, kein mentaler Overhead beim Wiedereinstieg. Zwei Verzeichnisse, zwei Branches, null Reibung.
Git worktree fügt deinem Workflow keine Komplexität hinzu — es nimmt sie weg. Jeder Worktree ist nur ein Verzeichnis mit einem ausgecheckten Branch. Doch diese Einfachheit schaltet etwas Mächtiges frei: Du kannst ohne kognitiven Ballast zwischen Aufgaben wechseln, statt zu stashen, zu checken und dein mentales Modell neu aufzubauen.
Wenn du Worktrees in teamweite Workflows wie Pull-Requests und Code-Reviews integrieren willst, DataCamps Skill Track „GitHub Foundations“ deckt die wichtigsten Praktiken für effektive Zusammenarbeit in verteilten Teams ab.
Top-Git-Kurse
Kurs
Kurs
Kurs
Tutorial
Satyabrata Pal
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Kurtis Pykes
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal