
Leerpad
SQL-basisprincipes
26 Hr
Pivoteren in SQL betekent data transformeren van een rij-gebaseerd formaat naar een kolom-gebaseerd formaat. Deze transformatie is nuttig voor rapportage en data-analyse en maakt een meer gestructureerde en compacte dataview mogelijk. Rijen naar kolommen pivoteren laat gebruikers ook data analyseren en samenvatten op een manier die belangrijke inzichten duidelijker uitlicht.
Neem het volgende voorbeeld: ik heb een tabel met dagelijkse verkooptransacties, en elke rij bevat de datum, productnaam en verkoopbedrag.
| Datum | Product | Verkoop |
|---|---|---|
| 2024-01-01 | Laptop | 100 |
| 2024-01-01 | Muis | 200 |
| 2024-01-02 | Laptop | 150 |
| 2024-01-02 | Muis | 250 |
Door deze tabel te pivoteren kan ik haar herstructureren zodat elk product een kolom is, met de verkoopgegevens per datum onder de betreffende kolom. Let ook op dat er een aggregatie plaatsvindt.
| Datum | Laptop | Muis |
|---|---|---|
| 2024-01-01 | 100 | 200 |
| 2024-01-02 | 150 | 250 |
Traditioneel vereisten pivotbewerkingen complexe SQL-queries met conditionele aggregatie. In de loop der tijd zijn SQL-implementaties geëvolueerd, en veel moderne databases bevatten nu PIVOT- en UNPIVOT-operators om efficiëntere en eenvoudigere transformaties mogelijk te maken.
De SQL-pivotbewerking transformeert data door rijwaarden in kolommen te veranderen. Hieronder staat de basis-syntaxis en -structuur van SQL-pivot met de volgende onderdelen:
SELECT: De SELECT-instructie verwijst naar de kolommen die in de SQL-pivottabel moeten worden geretourneerd.
Subquery: De subquery bevat de gegevensbron of tabel die in de SQL-pivottabel moet worden opgenomen.
PIVOT: De PIVOT-operator bevat de aggregaties en filter die op de pivottabel moeten worden toegepast.
-- Select static columns and pivoted columns
SELECT <static columns>, [pivoted columns]
FROM
(
-- Subquery defining source data for pivot
<subquery that defines data>
) AS source
PIVOT
(
-- Aggregate function applied to value column, creating new columns
<aggregation function>(<value column>)
FOR <column to pivot> IN ([list of pivoted columns])
) AS pivot_table;Laten we het volgende stapsgewijze voorbeeld bekijken om te laten zien hoe je rijen naar kolommen pivot in SQL. Neem de onderstaande SalesData-tabel.
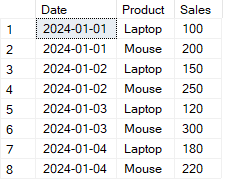
Voorbeeld van een tabel die wordt getransformeerd met de SQL PIVOT-operator. Afbeelding door de auteur.
Ik wil deze data pivoteren om de dagelijkse verkoop per product te vergelijken. Ik begin met het selecteren van de subquery die de PIVOT-operator zal structureren.
-- Subquery defining source data for pivot
SELECT Date, Product, Sales
FROM SalesData;Nu gebruik ik de PIVOT-operator om Product-waarden in kolommen om te zetten en Sales te aggregeren met de SUM-operator.
-- Select Date and pivoted columns for each product
SELECT Date, [Laptop], [Mouse]
FROM
(
-- Subquery to fetch Date, Product, and Sales columns
SELECT Date, Product, Sales FROM SalesData
) AS source
PIVOT
(
-- Aggregate Sales by Product, pivoting product values to columns
SUM(Sales)
FOR Product IN ([Laptop], [Mouse])
) AS pivot_table;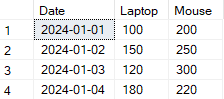
Voorbeeld van outputtransformatie met SQL rijen naar kolommen pivoteren. Afbeelding door de auteur.
Hoewel het pivoteren van data het samenvatten vereenvoudigt, kent deze techniek mogelijke issues. Hieronder staan de potentiële uitdagingen bij SQL-pivot en hoe je die aanpakt.
Dynamische kolomnamen: Als de te pivoteren waarden (bijv. producttypen) onbekend zijn, werkt hardcoden van kolomnamen niet. Sommige databases, zoals SQL Server, ondersteunen dynamische SQL met stored procedures om dit te voorkomen, terwijl andere vereisen dat je dit in de applicatielaag afhandelt.
Omgaan met NULL-waarden: Wanneer er geen data is voor een specifieke gepivote kolom, kan het resultaat NULL bevatten. Je kunt COALESCE gebruiken om NULL-waarden te vervangen door nul of een andere placeholder.
Compatibiliteit tussen databases: Niet alle databases ondersteunen de PIVOT-operator direct. Je kunt vergelijkbare resultaten bereiken met CASE-statements en conditionele aggregatie als je SQL-dialect dat niet doet.
Er bestaan verschillende methoden om data in SQL te pivoteren, afhankelijk van de gebruikte database of andere vereisten. Terwijl de PIVOT-operator vaak in SQL Server wordt gebruikt, maken andere technieken, zoals CASE-statements, vergelijkbare transformaties mogelijk zonder directe PIVOT-ondersteuning. Ik behandel de twee gangbare methoden om data te pivoteren in SQL en bespreek de voor- en nadelen.
De PIVOT-operator, beschikbaar in SQL Server, biedt een eenvoudige manier om rijen naar kolommen te pivoteren door een aggregatiefunctie op te geven en de te pivoteren kolommen te definiëren.
Bekijk de volgende tabel met de naam sales_data.
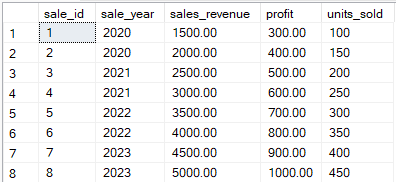
Voorbeeld van een Orders-tabel die wordt getransformeerd met de PIVOT-operator. Afbeelding door de auteur.
Ik gebruik de PIVOT-operator om de data te aggregeren zodat per jaar de totale sales_revenue in kolommen wordt getoond.
-- Use PIVOT to aggregate sales revenue by year
SELECT *
FROM (
-- Select the relevant columns from the source table
SELECT sale_year, sales_revenue
FROM sales_data
) AS src
PIVOT (
-- Aggregate sales revenue for each year
SUM(sales_revenue)
-- Create columns for each year
FOR sale_year IN ([2020], [2021], [2022], [2023])
) AS piv;
Voorbeeld van outputtransformatie met SQL PIVOT. Afbeelding door de auteur.
Het gebruik van de PIVOT-operator heeft de volgende voordelen en beperkingen:
Voordelen: De methode is efficiënt wanneer kolommen goed zijn geïndexeerd. De syntaxis is ook eenvoudig en beter leesbaar.
Beperkingen: Niet alle databases ondersteunen de PIVOT-operator. Je moet de kolommen vooraf opgeven, en dynamisch pivoteren vereist extra complexiteit.
Je kunt ook CASE-statements gebruiken om data handmatig te pivoteren in databases die geen PIVOT-operators ondersteunen, zoals MySQL en PostgreSQL. Deze aanpak gebruikt conditionele aggregatie door elke rij te evalueren en waarden voor nieuwe kolommen toe te kennen op basis van specifieke criteria.
We kunnen bijvoorbeeld data handmatig pivoteren in dezelfde sales_data-tabel met CASE-statements.
-- Aggregate sales revenue by year using CASE statements
SELECT
-- Calculate total sales revenue for each year
SUM(CASE WHEN sale_year = 2020 THEN sales_revenue ELSE 0 END) AS sales_2020,
SUM(CASE WHEN sale_year = 2021 THEN sales_revenue ELSE 0 END) AS sales_2021,
SUM(CASE WHEN sale_year = 2022 THEN sales_revenue ELSE 0 END) AS sales_2022,
SUM(CASE WHEN sale_year = 2023 THEN sales_revenue ELSE 0 END) AS sales_2023
FROM
sales_data;
Voorbeeld van outputtransformatie met een SQL CASE-statement. Afbeelding door de auteur.
Het gebruik van CASE voor transformatie heeft de volgende voordelen en beperkingen:
Voordelen: De methode werkt in alle SQL-databases en is flexibel om dynamisch nieuwe kolommen te genereren, zelfs wanneer productnamen onbekend zijn of vaak veranderen.
Beperkingen: Queries kunnen complex en lang worden als er veel kolommen te pivoteren zijn. Door de meerdere conditionele checks presteert de methode iets trager dan de PIVOT-operator.
Rijen naar kolommen pivoteren in SQL kan prestatiegevolgen hebben, vooral bij grote datasets. Hier zijn enkele tips en best practices om efficiënte pivotqueries te schrijven, hun prestaties te optimaliseren en veelvoorkomende valkuilen te vermijden.
De volgende best practices helpen je queries te optimaliseren en de prestaties te verbeteren.
Indexeringsstrategieën: Juiste indexering is cruciaal om pivotqueries te optimaliseren, zodat SQL data sneller kan ophalen en verwerken. Indexeer altijd de kolommen die vaak in de WHERE-clausule worden gebruikt of de kolommen waarop je groepeert om scantijden te verkorten.
Vermijd geneste pivots: Meerdere pivotbewerkingen stapelen in één query kan lastig leesbaar zijn en trager uitvoeren. Maak het eenvoudiger door de query op te splitsen of een tijdelijke tabel te gebruiken.
Beperk kolommen en rijen in de pivot: Pivot alleen kolommen die nodig zijn voor de analyse, want veel kolommen pivoteren is resource-intensief en kan grote tabellen opleveren.
Dit zijn de veelgemaakte fouten die je kunt tegenkomen in pivotqueries en hoe je ze voorkomt.
Onnodige full table scans: Pivotqueries kunnen full table scans triggeren, vooral als er geen relevante indexen zijn. Vermijd full scans door sleutelkolommen te indexeren en te filteren voordat je de pivot toepast.
Dynamische SQL gebruiken voor frequente pivots: Dynamische SQL kan prestaties vertragen door query-hercompilatie. Cache of beperk dynamische pivots tot specifieke scenario’s en overweeg dynamische kolommen waar mogelijk in de applicatielaag af te handelen.
Aggregatie op grote datasets zonder vooraf te filteren: Aggregatiefuncties zoals SUM of COUNT op grote datasets kunnen de database vertragen. Filter in plaats daarvan eerst de data met een WHERE-clausule voordat je pivot.
NULL-waarden in gepivote kolommen: Pivotbewerkingen leveren vaak NULL-waarden op als er geen data is voor een specifieke kolom. Dit kan queries vertragen en resultaten moeilijker interpreteerbaar maken. Gebruik functies zoals COALESCE om NULL-waarden te vervangen door een standaardwaarde.
Alleen met sampledata testen: Pivotqueries kunnen zich anders gedragen bij grote datasets door hogere geheugen- en verwerkingsbehoeften. Test pivotqueries altijd op echte of representatieve datasamples om prestatie-impact goed in te schatten.
Probeer onze SQL Server Developer-carrièretrack, die alles behandelt van transacties en foutafhandeling tot het verbeteren van queryprestaties.
Pivotbewerkingen verschillen aanzienlijk tussen databases zoals SQL Server, MySQL en Oracle. Elke database heeft specifieke syntaxis en beperkingen. Ik behandel voorbeelden van data pivoteren in de verschillende databases en hun belangrijkste kenmerken.
SQL Server biedt een ingebouwde PIVOT-operator, die het pivoteren van rijen naar kolommen eenvoudig maakt. De PIVOT-operator is makkelijk te gebruiken en integreert met de krachtige aggregatiefuncties van SQL Server. De belangrijkste kenmerken van pivoteren in SQL zijn onder andere:
Directe ondersteuning voor PIVOT en UNPIVOT: Met de PIVOT-operator van SQL Server kun je snel rijen naar kolommen transformeren. De UNPIVOT-operator kan dit proces ook omkeren.
Aggregatie-opties: De PIVOT-operator ondersteunt diverse aggregatiefuncties, zoals SUM, COUNT en AVG.
De beperking van de PIVOT-operator in SQL Server is dat de te pivoteren kolomwaarden vooraf bekend moeten zijn, wat minder flexibel is bij dynamisch veranderende data.
In het onderstaande voorbeeld zet de PIVOT-operator Product-waarden om in kolommen en aggregeert Sales met de SUM-operator.
-- Select Date and pivoted columns for each product
SELECT Date, [Laptop], [Mouse]
FROM
(
-- Subquery to fetch Date, Product, and Sales columns
SELECT Date, Product, Sales FROM SalesData
) AS source
PIVOT
(
-- Aggregate Sales by Product, pivoting product values to columns
SUM(Sales)
FOR Product IN ([Laptop], [Mouse])
) AS pivot_table;Ik raad DataCamp's Introduction to SQL Server-cursus aan om de basis van SQL Server voor data-analyse onder de knie te krijgen.
MySQL heeft geen native ondersteuning voor de PIVOT-operator. Je kunt echter het CASE-statement gebruiken om rijen handmatig naar kolommen te pivoteren en dit combineren met andere aggregatiefuncties zoals SUM, AVG en COUNT. Hoewel deze methode flexibel is, kan ze complex worden als je veel kolommen moet pivoteren.
De onderstaande query bereikt dezelfde output als het SQL Server-PIVOT-voorbeeld door verkoop per product conditioneel te aggregeren met het CASE-statement.
-- Select Date and pivoted columns for each product
SELECT
Date,
-- Use CASE to create a column for Laptop and Mouse sales
SUM(CASE WHEN Product = 'Laptop' THEN Sales ELSE 0 END) AS Laptop,
SUM(CASE WHEN Product = 'Mouse' THEN Sales ELSE 0 END) AS Mouse
FROM SalesData
GROUP BY Date;Oracle ondersteunt de PIVOT-operator, die een eenvoudige transformatie van rijen naar kolommen mogelijk maakt. Net als in SQL Server moet je de kolommen voor de transformatie expliciet opgeven.
In de onderstaande query zet de PIVOT-operator ProductName-waarden om in kolommen en aggregeert SalesAmount met de SUM-operator.
SELECT *
FROM (
-- Source data selection
SELECT SaleDate, ProductName, SaleAmount FROM SalesData
)
PIVOT (
-- Aggregate Sales by Product, creating pivoted columns
SUM(SaleAmount)
FOR ProductName IN ('Laptop' AS Laptop, 'Mouse' AS Mouse)
);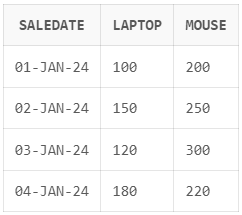
Voorbeeld van outputtransformatie met de SQL PIVOT-operator in Oracle. Afbeelding door de auteur.
Geavanceerde technieken voor het pivoteren van rijen naar kolommen zijn nuttig wanneer je flexibiliteit nodig hebt bij het omgaan met complexe data. Dynamische technieken en het gelijktijdig verwerken van meerdere kolommen stellen je in staat data te transformeren in scenario’s waar statisch pivoteren beperkt is. Laten we deze twee methoden in detail verkennen.
Dynamische pivots laten je pivotqueries maken die automatisch inspelen op veranderingen in de data. Deze techniek is vooral handig wanneer je kolommen hebt die vaak veranderen, zoals productnamen of categorieën, en je wilt dat je query automatisch nieuwe items opneemt zonder handmatig bij te werken.
Stel, we hebben een SalesData-tabel en we kunnen een dynamische pivot maken die zich aanpast als er nieuwe producten worden toegevoegd. In de onderstaande query bouwt @columns dynamisch de lijst met gepivote kolommen op, en sp_executesql voert de gegenereerde SQL uit.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX);
-- Step 1: Generate a list of distinct products to pivot
SELECT @columns = STRING_AGG(QUOTENAME(Product), ', ')
FROM (SELECT DISTINCT Product FROM SalesData) AS products;
-- Step 2: Build the dynamic SQL query
SET @sql = N'
SELECT Date, ' + @columns + '
FROM
(SELECT Date, Product, Sales FROM SalesData) AS source
PIVOT
(
SUM(Sales)
FOR Product IN (' + @columns + ')
) AS pivot_table;';
-- Step 3: Execute the dynamic SQL
EXEC sp_executesql @sql;In situaties waarin je meerdere kolommen tegelijk moet pivoteren, gebruik je de PIVOT-operator en extra aggregatietechnieken om meerdere kolommen in dezelfde query te creëren.
In het onderstaande voorbeeld heb ik de kolommen Sales en Quantity per Product gepivote.
-- Pivot Sales and Quantity for Laptop and Mouse by Date
SELECT
p1.Date,
p1.[Laptop] AS Laptop_Sales,
p2.[Laptop] AS Laptop_Quantity,
p1.[Mouse] AS Mouse_Sales,
p2.[Mouse] AS Mouse_Quantity
FROM
(
-- Pivot for Sales
SELECT Date, [Laptop], [Mouse]
FROM
(SELECT Date, Product, Sales FROM SalesData) AS source
PIVOT
(SUM(Sales) FOR Product IN ([Laptop], [Mouse])) AS pivot_sales
) p1
JOIN
(
-- Pivot for Quantity
SELECT Date, [Laptop], [Mouse]
FROM
(SELECT Date, Product, Quantity FROM SalesData) AS source
PIVOT
(SUM(Quantity) FOR Product IN ([Laptop], [Mouse])) AS pivot_quantity
) p2
ON p1.Date = p2.Date;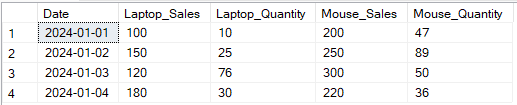
Voorbeeld van outputtransformatie van meerdere kolommen met de SQL PIVOT-operator. Afbeelding door de auteur.
Meerdere kolommen pivoteren maakt meer gedetailleerde rapporten mogelijk door meerdere attributen per item te pivoteren, wat rijkere inzichten oplevert. De syntaxis kan echter complex zijn, vooral als er veel kolommen zijn. Hardcoden kan nodig zijn tenzij je dit combineert met dynamische pivottechnieken, wat extra complexiteit toevoegt.
Rijen naar kolommen pivoteren is een SQL-techniek die het waard is om te leren. Ik heb SQL-pivottechnieken gezien voor het maken van een cohort-retentietabel, waarin je gebruikersretentie in de tijd bijhoudt. Ik heb SQL-pivottechnieken ook gezien bij het analyseren van enquêtegegevens, waarbij elke rij een respondent vertegenwoordigt en elke vraag naar een eigen kolom kan worden gepivot.
Onze cursus Reporting in SQL is een geweldige optie als je meer wilt leren over het samenvatten en voorbereiden van data voor presentatie en/of het bouwen van dashboards. Onze carrièretracks Associate Data Analyst in SQL en Associate Data Engineer in SQL zijn ook een goed idee en voegen veel toe aan elk cv, dus schrijf je vandaag nog in.
Leer SQL met DataCamp
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
