
Programma
Fondamenti di SQL
26 h
Il pivot in SQL consiste nel trasformare i dati da un formato basato su righe a uno basato su colonne. Questa trasformazione è utile per report e analisi, perché consente una vista dei dati più strutturata e compatta. Convertire righe in colonne permette anche di analizzare e riassumere i dati in modo da mettere in evidenza gli insight chiave con maggiore chiarezza.
Considera il seguente esempio: ho una tabella con transazioni di vendita giornaliere, e ogni riga registra la data, il nome del prodotto e l’importo delle vendite.
| Data | Prodotto | Vendite |
|---|---|---|
| 2024-01-01 | Notebook | 100 |
| 2024-01-01 | Mouse | 200 |
| 2024-01-02 | Notebook | 150 |
| 2024-01-02 | Mouse | 250 |
Eseguendo il pivot di questa tabella, posso ristrutturarla per mostrare ogni prodotto come una colonna, con i dati di vendita per ciascuna data sotto la rispettiva colonna. Nota anche che avviene un’aggregazione.
| Data | Notebook | Mouse |
|---|---|---|
| 2024-01-01 | 100 | 200 |
| 2024-01-02 | 150 | 250 |
Tradizionalmente, le operazioni di pivot richiedevano query SQL complesse con aggregazione condizionale. Nel tempo, le implementazioni SQL si sono evolute e molti database moderni includono gli operatori PIVOT e UNPIVOT per trasformazioni più efficienti e dirette.
L’operazione di pivot in SQL trasforma i dati convertendo i valori di riga in colonne. Di seguito trovi la sintassi e la struttura di base del pivot in SQL, con le seguenti parti:
SELECT: L’istruzione SELECT fa riferimento alle colonne da restituire nella tabella pivot SQL.
Subquery: La sottoquery contiene l’origine dati o la tabella da includere nella tabella pivot SQL.
PIVOT: L’operatore PIVOT contiene le aggregazioni e i filtri da applicare nella tabella pivot.
-- Select static columns and pivoted columns
SELECT <static columns>, [pivoted columns]
FROM
(
-- Subquery defining source data for pivot
<subquery that defines data>
) AS source
PIVOT
(
-- Aggregate function applied to value column, creating new columns
<aggregation function>(<value column>)
FOR <column to pivot> IN ([list of pivoted columns])
) AS pivot_table;Vediamo ora un esempio passo passo per mostrare come convertire le righe in colonne in SQL. Considera la tabella SalesData qui sotto.
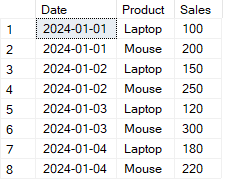
Esempio di tabella da trasformare usando l’operatore SQL PIVOT. Immagine dell’autore.
Voglio eseguire il pivot di questi dati per confrontare le vendite giornaliere di ciascun prodotto. Comincerò selezionando la sottoquery che alimenterà l’operatore PIVOT.
-- Subquery defining source data for pivot
SELECT Date, Product, Sales
FROM SalesData;Ora userò l’operatore PIVOT per convertire i valori di Product in colonne e aggregare Sales usando l’operatore SUM.
-- Select Date and pivoted columns for each product
SELECT Date, [Laptop], [Mouse]
FROM
(
-- Subquery to fetch Date, Product, and Sales columns
SELECT Date, Product, Sales FROM SalesData
) AS source
PIVOT
(
-- Aggregate Sales by Product, pivoting product values to columns
SUM(Sales)
FOR Product IN ([Laptop], [Mouse])
) AS pivot_table;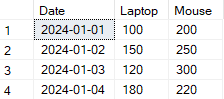
Esempio di trasformazione dell’output usando il pivot di righe in colonne in SQL. Immagine dell’autore.
Sebbene il pivot semplifichi il riepilogo dei dati, questa tecnica può presentare potenziali criticità. Di seguito trovi le possibili sfide con il pivot in SQL e come affrontarle.
Nomi di colonne dinamici: Quando i valori da convertire (ad esempio, i tipi di prodotto) sono sconosciuti, scrivere i nomi delle colonne in modo statico non funziona. Alcuni database, come SQL Server, supportano SQL dinamico con stored procedure per evitare questo problema; altri richiedono di gestirlo a livello di applicazione.
Gestione dei valori NULL: quando non ci sono dati per una specifica colonna pivotata, il risultato può includere NULL. Puoi usare COALESCE per sostituire i valori NULL con zero o un altro segnaposto.
Compatibilità tra database: non tutti i database supportano direttamente l’operatore PIVOT. Se il tuo dialetto SQL non lo supporta, puoi ottenere risultati simili con le istruzioni CASE e aggregazione condizionale.
Esistono diversi metodi per eseguire il pivot dei dati in SQL, a seconda del database utilizzato o di altri requisiti. Sebbene l’operatore PIVOT sia comunemente usato in SQL Server, altre tecniche come le istruzioni CASE permettono trasformazioni simili anche senza supporto diretto a PIVOT. Tratterò i due metodi più comuni per effettuare il pivot dei dati in SQL, con relativi pro e contro.
L’operatore PIVOT, disponibile in SQL Server, fornisce un modo diretto per convertire righe in colonne specificando una funzione di aggregazione e definendo le colonne da pivotare.
Considera la seguente tabella chiamata sales_data.
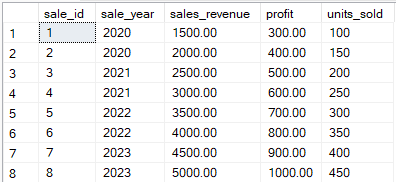
Esempio di tabella Orders da trasformare con l’operatore PIVOT. Immagine dell’autore.
Userò l’operatore PIVOT per aggregare i dati in modo che il totale di sales_revenue di ciascun anno venga mostrato in colonne.
-- Use PIVOT to aggregate sales revenue by year
SELECT *
FROM (
-- Select the relevant columns from the source table
SELECT sale_year, sales_revenue
FROM sales_data
) AS src
PIVOT (
-- Aggregate sales revenue for each year
SUM(sales_revenue)
-- Create columns for each year
FOR sale_year IN ([2020], [2021], [2022], [2023])
) AS piv;
Esempio di trasformazione dell’output usando SQL PIVOT. Immagine dell’autore.
L’uso dell’operatore PIVOT presenta i seguenti vantaggi e limitazioni:
Vantaggi: il metodo è efficiente quando le colonne sono indicizzate correttamente. Ha anche una sintassi semplice e leggibile.
Limitazioni: non tutti i database supportano l’operatore PIVOT. Richiede di specificare in anticipo le colonne e il pivot dinamico introduce ulteriore complessità.
Puoi anche usare le istruzioni CASE per eseguire il pivot manualmente in database che non supportano l’operatore PIVOT, come MySQL e PostgreSQL. Questo approccio utilizza l’aggregazione condizionale, valutando ogni riga e assegnando condizionalmente valori a nuove colonne in base a criteri specifici.
Ad esempio, possiamo eseguire manualmente il pivot dei dati nella stessa tabella sales_data con istruzioni CASE.
-- Aggregate sales revenue by year using CASE statements
SELECT
-- Calculate total sales revenue for each year
SUM(CASE WHEN sale_year = 2020 THEN sales_revenue ELSE 0 END) AS sales_2020,
SUM(CASE WHEN sale_year = 2021 THEN sales_revenue ELSE 0 END) AS sales_2021,
SUM(CASE WHEN sale_year = 2022 THEN sales_revenue ELSE 0 END) AS sales_2022,
SUM(CASE WHEN sale_year = 2023 THEN sales_revenue ELSE 0 END) AS sales_2023
FROM
sales_data;
Esempio di trasformazione dell’output usando l’istruzione SQL CASE. Immagine dell’autore.
Usare l’istruzione CASE per la trasformazione presenta i seguenti vantaggi e limitazioni:
Vantaggi: il metodo funziona su tutti i database SQL ed è flessibile per generare dinamicamente nuove colonne, anche quando i nomi dei prodotti sono sconosciuti o cambiano spesso.
Limitazioni: le query possono diventare complesse e lunghe se ci sono molte colonne da pivotare. A causa dei molteplici controlli condizionali, il metodo è leggermente più lento rispetto all’operatore PIVOT.
Convertire righe in colonne in SQL può avere implicazioni sulle performance, soprattutto con dataset di grandi dimensioni. Ecco alcuni consigli e best practice per scrivere query di pivot efficienti, ottimizzarne le prestazioni ed evitare errori comuni.
Di seguito trovi le best practice per ottimizzare le query e migliorare le performance.
Strategie di indicizzazione: un’indicizzazione corretta è fondamentale per ottimizzare le query di pivot, consentendo a SQL di recuperare ed elaborare i dati più rapidamente. Indicizza sempre le colonne usate frequentemente nella clausola WHERE o quelle su cui effettui il raggruppamento per ridurre i tempi di scansione.
Evita pivot annidati: impilare più operazioni di pivot in un’unica query può essere difficile da leggere e più lento da eseguire. Semplifica suddividendo la query in parti o usando una tabella temporanea.
Limita colonne e righe nel pivot: effettua il pivot solo delle colonne necessarie all’analisi, perché pivotare molte colonne è dispendioso in termini di risorse e può generare tabelle molto grandi.
Di seguito gli errori più comuni che potresti incontrare nelle query di pivot e come evitarli.
Scansioni complete non necessarie: le query di pivot possono innescare scansioni complete della tabella, soprattutto se mancano indici pertinenti. Evitale indicizzando le colonne chiave e filtrando i dati prima di applicare il pivot.
Uso di SQL dinamico per pivot frequenti: l’SQL dinamico può rallentare le performance a causa della ricompilazione delle query. Per evitarlo, fai caching o limita i pivot dinamici a scenari specifici e, quando possibile, gestisci le colonne dinamiche a livello applicativo.
Aggregazioni su grandi dataset senza pre-filtraggio: funzioni di aggregazione come SUM o COUNT su dataset ampi possono rallentare il database. Invece di pivotare l’intero dataset, filtra prima i dati con una clausola WHERE.
Valori NULL nelle colonne pivotate: le operazioni di pivot producono spesso valori NULL quando mancano dati per una specifica colonna. Questi possono rallentare le query e rendere i risultati meno chiari. Per evitarlo, usa funzioni come COALESCE per sostituire i NULL con un valore predefinito.
Test solo con dati di esempio: le query di pivot possono comportarsi in modo diverso con dataset grandi a causa di maggiori richieste di memoria ed elaborazione. Testale sempre su dati reali o campioni rappresentativi per valutare accuratamente l’impatto sulle performance.
Prova il nostro percorso di carriera SQL Server Developer, che copre tutto, dalle transazioni e la gestione degli errori al miglioramento delle performance delle query.
Le operazioni di pivot differiscono significativamente tra database come SQL Server, MySQL e Oracle. Ognuno ha sintassi e limitazioni specifiche. Vedremo esempi di pivot dei dati nei diversi database e le loro caratteristiche principali.
SQL Server fornisce un operatore PIVOT integrato, semplice da usare per convertire righe in colonne. L’operatore PIVOT è facile da utilizzare e si integra con le potenti funzioni di aggregazione di SQL Server. Le caratteristiche chiave del pivot in SQL includono:
Supporto diretto a PIVOT e UNPIVOT: l’operatore PIVOT di SQL Server consente una rapida trasformazione da righe a colonne. L’operatore UNPIVOT può anche invertire il processo.
Opzioni di aggregazione: l’operatore PIVOT consente varie funzioni di aggregazione, come SUM, COUNT e AVG.
La limitazione dell’operatore PIVOT in SQL Server è che richiede di conoscere in anticipo i valori di colonna da pivotare, risultando meno flessibile per dati che cambiano dinamicamente.
Nell’esempio seguente, l’operatore PIVOT converte i valori di Product in colonne e aggrega Sales usando l’operatore SUM.
-- Select Date and pivoted columns for each product
SELECT Date, [Laptop], [Mouse]
FROM
(
-- Subquery to fetch Date, Product, and Sales columns
SELECT Date, Product, Sales FROM SalesData
) AS source
PIVOT
(
-- Aggregate Sales by Product, pivoting product values to columns
SUM(Sales)
FOR Product IN ([Laptop], [Mouse])
) AS pivot_table;Ti consiglio il corso di DataCamp Introduction to SQL Server per padroneggiare le basi di SQL Server per l’analisi dei dati.
MySQL non offre un supporto nativo per l’operatore PIVOT. Tuttavia, puoi usare le istruzioni CASE per convertire manualmente righe in colonne e combinare altre funzioni di aggregazione come SUM, AVG e COUNT. Sebbene questo metodo sia flessibile, può diventare complesso se hai molte colonne da pivotare.
La query seguente ottiene lo stesso output dell’esempio con PIVOT in SQL Server, aggregando condizionalmente le vendite per ciascun prodotto tramite CASE.
-- Select Date and pivoted columns for each product
SELECT
Date,
-- Use CASE to create a column for Laptop and Mouse sales
SUM(CASE WHEN Product = 'Laptop' THEN Sales ELSE 0 END) AS Laptop,
SUM(CASE WHEN Product = 'Mouse' THEN Sales ELSE 0 END) AS Mouse
FROM SalesData
GROUP BY Date;Oracle supporta l’operatore PIVOT, che consente la trasformazione diretta delle righe in colonne. Proprio come in SQL Server, dovrai specificare esplicitamente le colonne da trasformare.
Nella query seguente, l’operatore PIVOT converte i valori di ProductName in colonne e aggrega SalesAmount usando l’operatore SUM.
SELECT *
FROM (
-- Source data selection
SELECT SaleDate, ProductName, SaleAmount FROM SalesData
)
PIVOT (
-- Aggregate Sales by Product, creating pivoted columns
SUM(SaleAmount)
FOR ProductName IN ('Laptop' AS Laptop, 'Mouse' AS Mouse)
);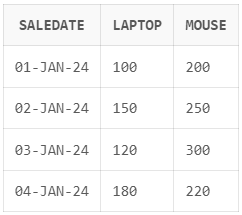
Esempio di trasformazione dell’output usando l’operatore SQL PIVOT in Oracle. Immagine dell’autore.
Le tecniche avanzate per trasformare righe in colonne sono utili quando serve flessibilità nella gestione di dati complessi. Tecniche dinamiche e gestione di più colonne simultanee permettono di trasformare i dati in scenari in cui il pivot statico è limitato. Esploriamo nel dettaglio questi due metodi.
I pivot dinamici consentono di creare query che si adattano automaticamente ai cambiamenti nei dati. Questa tecnica è particolarmente utile quando hai colonne che cambiano spesso, come nomi di prodotti o categorie, e vuoi che la tua query includa automaticamente le nuove voci senza doverla aggiornare manualmente.
Supponiamo di avere una tabella SalesData e di voler creare un pivot dinamico che si adatti all’aggiunta di nuovi prodotti. Nella query seguente, @columns costruisce dinamicamente l’elenco delle colonne pivotate e sp_executesql esegue l’SQL generato.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX);
-- Step 1: Generate a list of distinct products to pivot
SELECT @columns = STRING_AGG(QUOTENAME(Product), ', ')
FROM (SELECT DISTINCT Product FROM SalesData) AS products;
-- Step 2: Build the dynamic SQL query
SET @sql = N'
SELECT Date, ' + @columns + '
FROM
(SELECT Date, Product, Sales FROM SalesData) AS source
PIVOT
(
SUM(Sales)
FOR Product IN (' + @columns + ')
) AS pivot_table;';
-- Step 3: Execute the dynamic SQL
EXEC sp_executesql @sql;Quando devi pivotare più colonne contemporaneamente, userai l’operatore PIVOT e tecniche di aggregazione aggiuntive per creare più colonne nella stessa query.
Nell’esempio seguente ho eseguito il pivot delle colonne Sales e Quantity per Product.
-- Pivot Sales and Quantity for Laptop and Mouse by Date
SELECT
p1.Date,
p1.[Laptop] AS Laptop_Sales,
p2.[Laptop] AS Laptop_Quantity,
p1.[Mouse] AS Mouse_Sales,
p2.[Mouse] AS Mouse_Quantity
FROM
(
-- Pivot for Sales
SELECT Date, [Laptop], [Mouse]
FROM
(SELECT Date, Product, Sales FROM SalesData) AS source
PIVOT
(SUM(Sales) FOR Product IN ([Laptop], [Mouse])) AS pivot_sales
) p1
JOIN
(
-- Pivot for Quantity
SELECT Date, [Laptop], [Mouse]
FROM
(SELECT Date, Product, Quantity FROM SalesData) AS source
PIVOT
(SUM(Quantity) FOR Product IN ([Laptop], [Mouse])) AS pivot_quantity
) p2
ON p1.Date = p2.Date;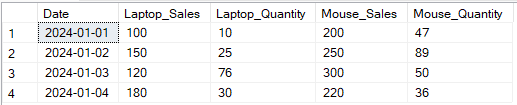
Esempio di trasformazione dell’output di più colonne usando l’operatore SQL PIVOT. Immagine dell’autore.
Pivotare più colonne consente report più dettagliati, perché permette di pivotare più attributi per elemento, ottenendo insight più ricchi. Tuttavia, la sintassi può essere complessa, soprattutto se le colonne sono molte. Potrebbe essere necessario specificarle in modo statico, a meno che non si combini con tecniche di pivot dinamico, aggiungendo ulteriore complessità.
Convertire righe in colonne è una tecnica SQL che vale la pena imparare. Ho visto tecniche di pivot in SQL usate per creare tabelle di retention per coorti, in cui si traccia la retention degli utenti nel tempo. Ho visto anche tecniche di pivot in SQL nell’analisi di dati da sondaggi, dove ogni riga rappresenta un rispondente e ogni domanda può essere convertita nella propria colonna.
I nostri corsi Reporting in SQL sono un’ottima opzione se vuoi imparare a riassumere e preparare i dati per presentazioni e/o dashboard. Anche i percorsi di carriera Associate Data Analyst in SQL e Associate Data Engineer in SQL sono un’ottima idea e danno valore a qualsiasi CV: iscriviti oggi stesso.
Impara SQL con DataCamp
Programma
Programma
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

