Cursus
Gestroomlijnde data-inname met pandas
4 Hr
63.2K
Streamlit is een gratis en open-source framework om razendsnel mooie machine learning- en data science-webapps te bouwen en te delen.
Het is een Python-bibliotheek die specifiek is ontworpen voor machine learning-engineers. Data scientists of machine learning-engineers zijn geen webontwikkelaars en hebben geen zin om weken te besteden aan het leren van deze frameworks om webapps te bouwen. In plaats daarvan willen ze een tool die makkelijker te leren en te gebruiken is, zolang die data kan tonen en benodigde parameters voor modellering kan verzamelen.
Met Streamlit maak je met slechts een paar regels code een verbluffend ogende applicatie.

Het mooiste aan Streamlit is dat je niet eens de basis van webontwikkeling hoeft te kennen om te starten of je eerste webapp te maken. Dus als je met data science bezig bent en je je modellen makkelijk en snel wilt uitrollen met slechts een paar regels code, dan is Streamlit een goede keuze.
Een van de belangrijke aspecten om een applicatie succesvol te maken, is het leveren van een effectieve en intuïtieve gebruikersinterface. Veel moderne data-intensieve apps staan voor de uitdaging om snel een effectieve interface te bouwen zonder ingewikkelde stappen. Streamlit is een veelbelovende open-source Python-bibliotheek waarmee ontwikkelaars in no-time aantrekkelijke interfaces kunnen bouwen.
Streamlit is de makkelijkste manier, vooral voor mensen zonder front-endkennis, om hun code in een webapp te plaatsen:
Het eerste wat je doet, is installeren:
1. Installeer Anaconda en maak je omgeving
2. Open de terminal
3. Typ dit commando in de terminal om Streamlit te installeren:
pip install streamlit4. Test of de installatie is gelukt:
streamlit hello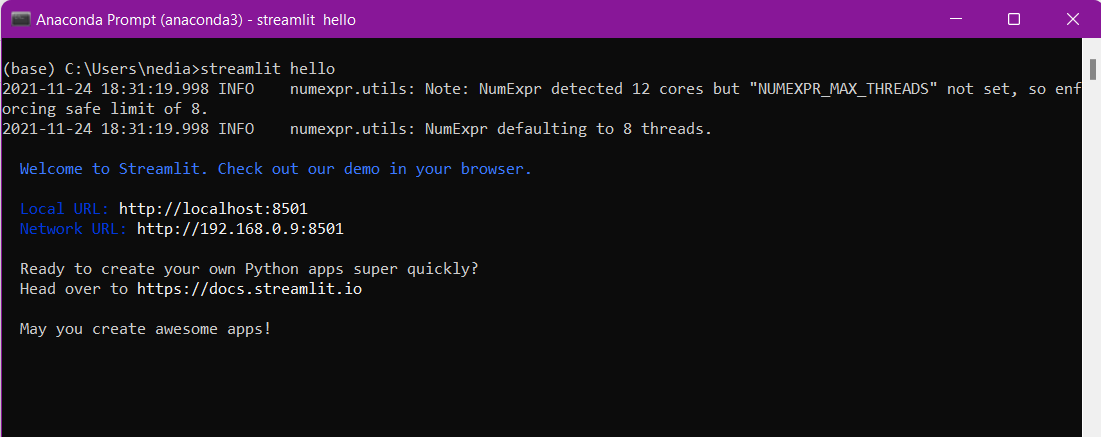
Als je dit commando in de terminal typt, zou de onderstaande pagina automatisch moeten openen:
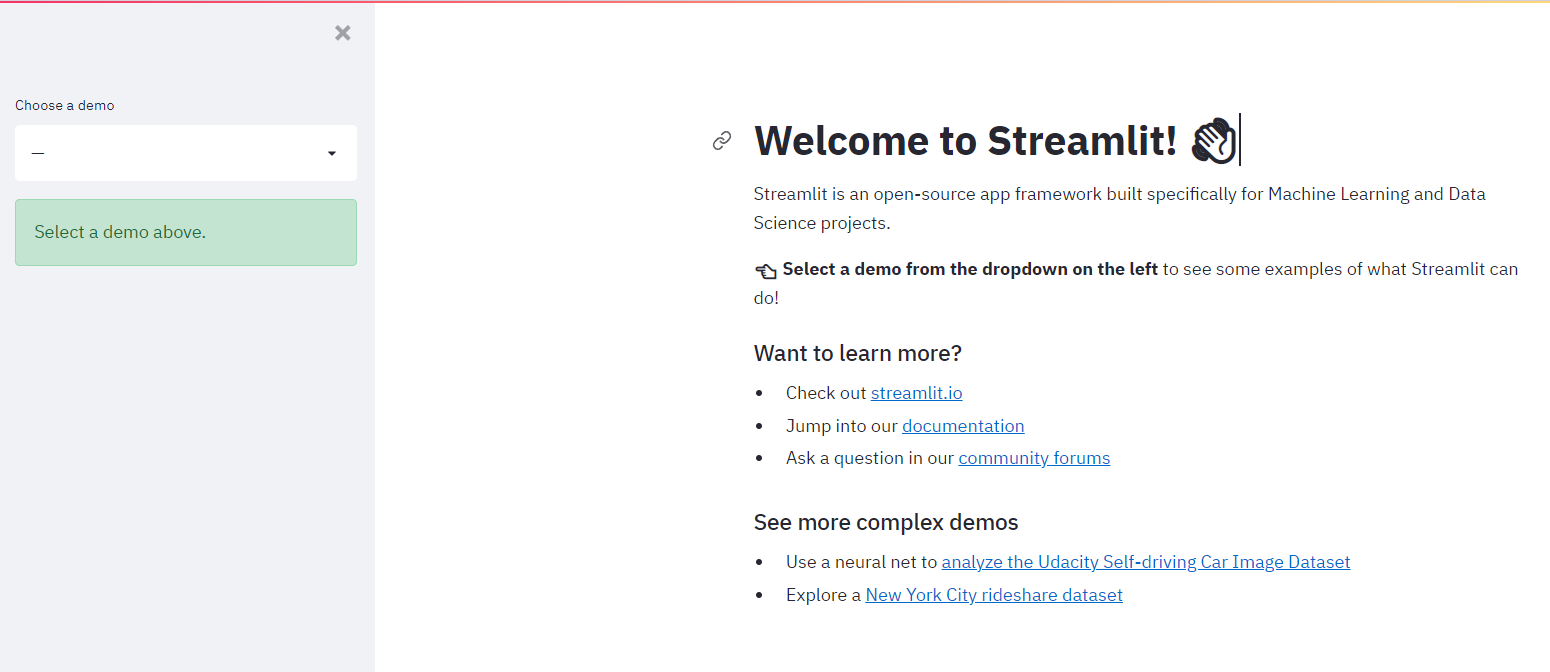
1. Installeer pip:
python3 -m ensurepip --upgrade2. Installeer pipenv:
pip3 install pipenv3. Maak je omgeving. Open je projectmap:
cd project_folder_name4. Maak een pipenv-omgeving:
pipenv shell5. Typ dit commando om Streamlit te installeren:
pip install streamlitTest of de installatie is gelukt:
streamlit hello1. Installeer pip:
sudo apt-get install python3-pip2. Installeer pipenv:
pip3 install pipenv3. Maak je omgeving. Open je projectmap:
cd project_folder_name4. Maak een pipenv-omgeving:
pipenv shell5. Typ dit commando om Streamlit te installeren
pip install streamlit6. Test of de installatie is gelukt:
streamlit hellostreamlit run file_name.py
Streamlit-commando's zijn eenvoudig te schrijven en te begrijpen. Met slechts een simpel commando kun je tekst, media, widgets, grafieken, enz. weergeven.
Hier laat ik je zien hoe je tekst toevoegt aan je Streamlit-app en welke verschillende commando's beschikbaar zijn.
st.write(): Deze functie wordt gebruikt om van alles aan een webapp toe te voegen, van een opgemaakte string tot grafieken in matplotlib-figuren, Altair-grafieken, plotly-figuren, dataframes, Keras-modellen, en meer.
import streamlit as stst.write("Hello ,let's learn how to build a streamlit app together")
st.title(): Hiermee voeg je de titel van de app toe. st.header(): Hiermee stel je de header van een sectie in. st.markdown(): Hiermee voeg je markdown toe aan een sectie. st.subheader(): Hiermee stel je de subheader van een sectie in. st.caption(): Hiermee schrijf je een bijschrift. st.code(): Hiermee toon je code. st.latex(): Hiermee geef je wiskundige expressies weer die in LaTeX zijn opgemaakt.
import streamlit as stst.title("This is the app title")st.header("This is the header")st.markdown("This is the markdown")st.subheader("This is the subheader")st.caption("This is the caption")st.code("x = 2021")st.latex(r''' a+a r^1+a r^2+a r^3 ''')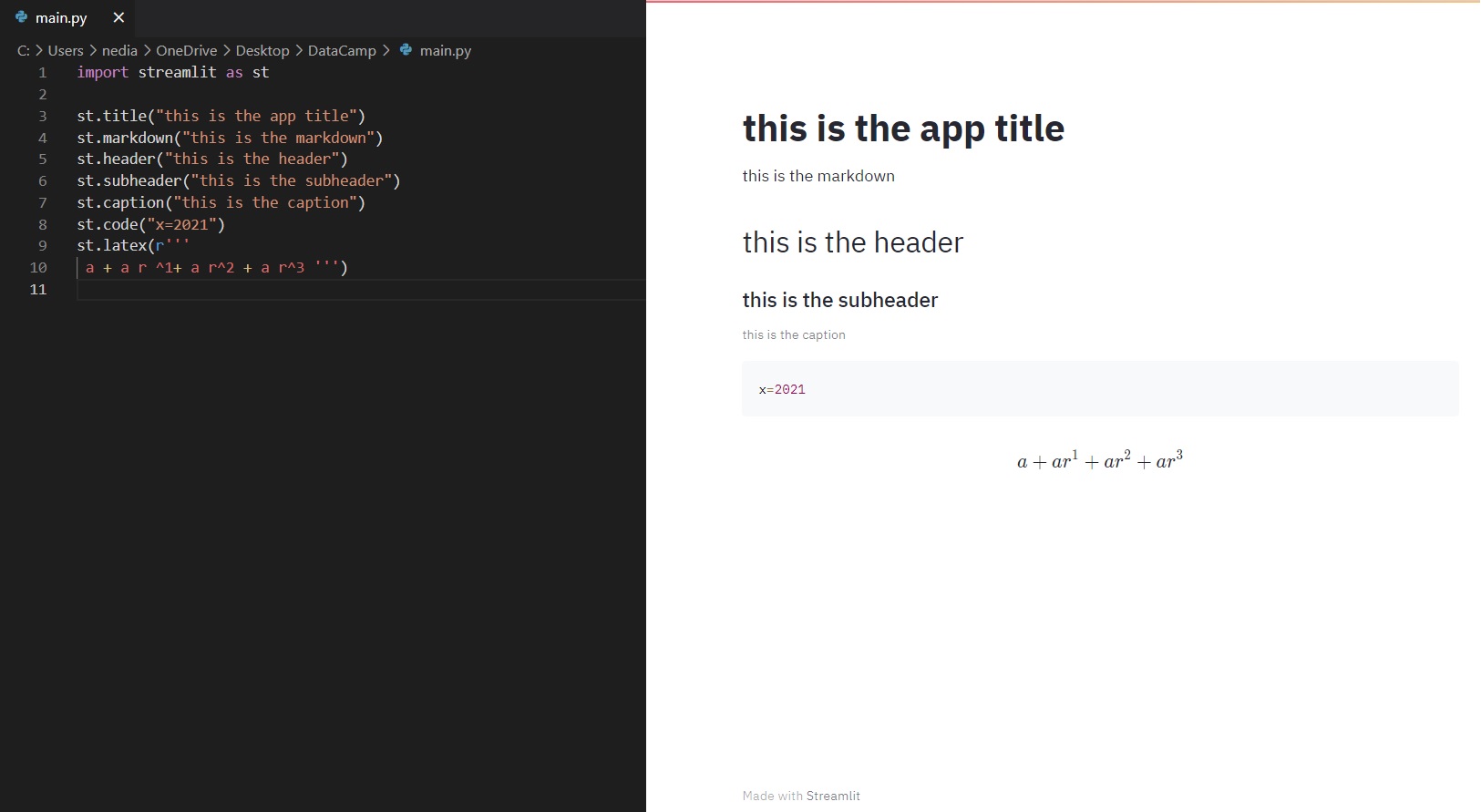
Je vindt nergens functies zo eenvoudig als die van Streamlit om afbeeldingen, video's en audiobestanden weer te geven. Laten we kijken hoe je media toont met Streamlit!
st.image(): Hiermee geef je een afbeelding weer. st.audio(): Hiermee geef je audio weer. st.video(): Hiermee geef je een video weer.
st.image("kid.jpg", caption="A kid playing")st.audio("audio.mp3")st.video("video.mp4")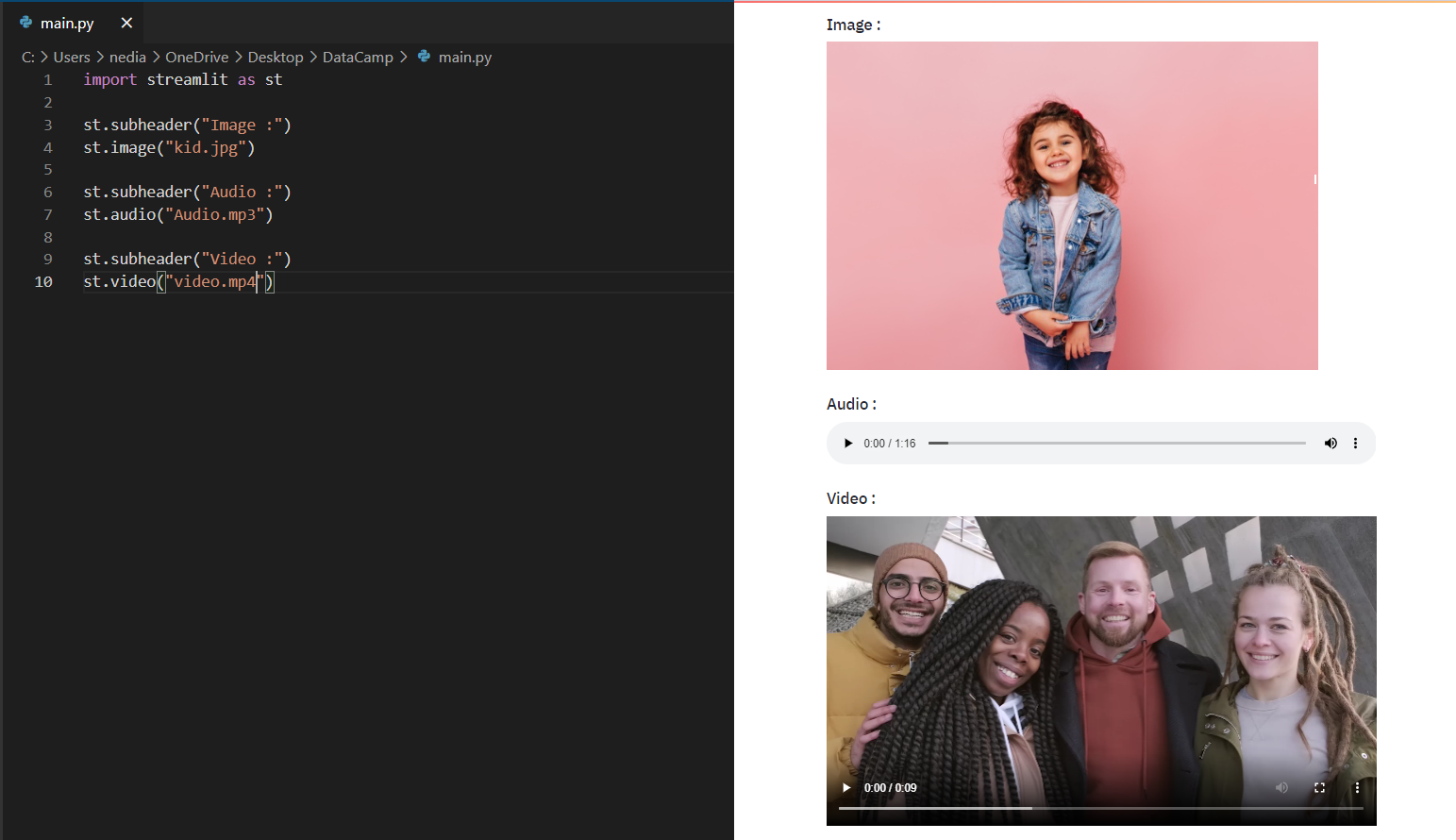
Widgets zijn de belangrijkste componenten van de gebruikersinterface. Streamlit heeft diverse widgets waarmee je met knoppen, sliders, tekstinvoer en meer direct interactiviteit in je apps kunt bouwen.
st.checkbox(): Deze functie retourneert een booleaanse waarde. Als het vakje is aangevinkt, retourneert het True, anders False. st.button(): Hiermee toon je een knopwidget. st.radio(): Hiermee toon je een radiobutton-widget. st.selectbox(): Hiermee toon je een selectiewidget. st.multiselect(): Hiermee toon je een multiselect-widget. st.select_slider(): Hiermee toon je een selectieslider. st.slider(): Hiermee toon je een slider-widget.
st.checkbox('Yes')st.button('Click Me')st.radio('Pick your gender', ['Male', 'Female'])st.selectbox('Pick a fruit', ['Apple', 'Banana', 'Orange'])st.multiselect('Choose a planet', ['Jupiter', 'Mars', 'Neptune'])st.select_slider('Pick a mark', ['Bad', 'Good', 'Excellent'])st.slider('Pick a number', 0, 50)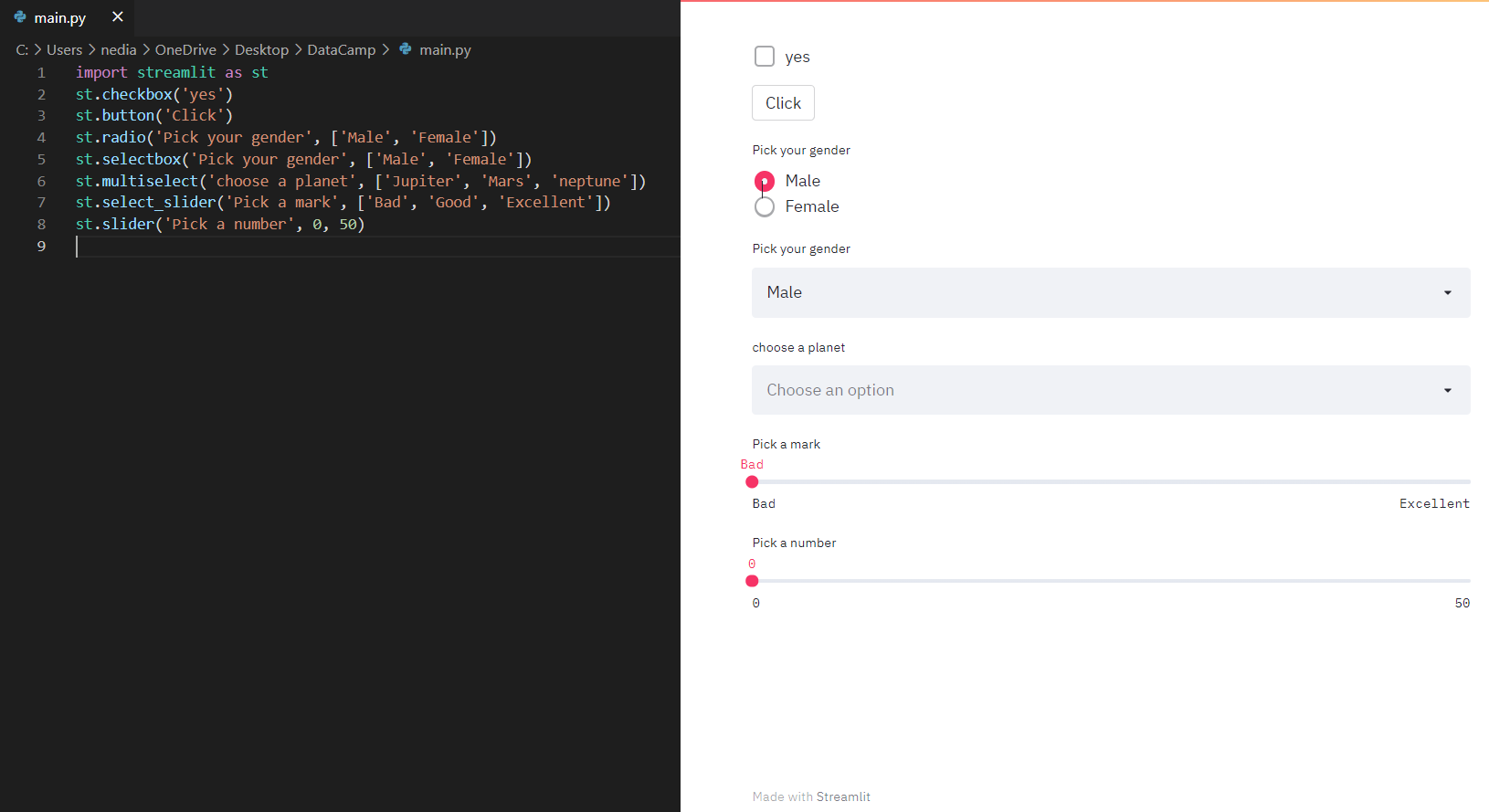
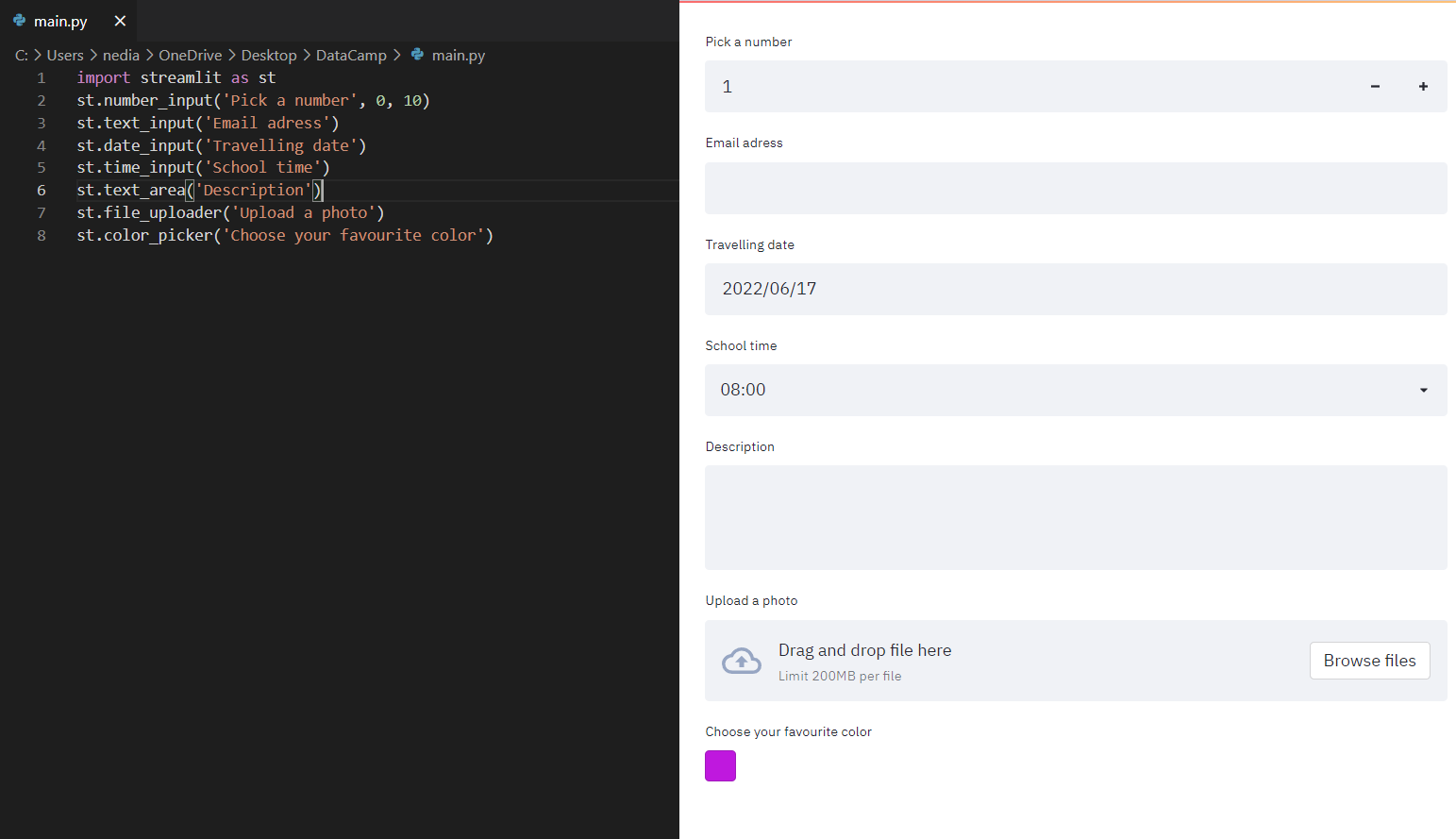
st.number_input(): Hiermee toon je een numerieke invoerwidget. st.text_input(): Hiermee toon je een tekstinvoerwidget. st.date_input(): Hiermee toon je een datumselectie-widget om een datum te kiezen. st.time_input(): Hiermee toon je een tijdselectie-widget om een tijd te kiezen. st.text_area(): Hiermee toon je een tekstinvoer met meer dan één regel. st.file_uploader(): Hiermee toon je een bestandsuploader. st.color_picker(): Hiermee toon je een kleurkiezer om een kleur te kiezen.
st.number_input('Pick a number', 0, 10)st.text_input('Email address')st.date_input('Traveling date')st.time_input('School time')st.text_area('Description')st.file_uploader('Upload a photo')st.color_picker('Choose your favorite color')t
Nu kijken we hoe we een voortgangsbalk en statusberichten zoals error en success kunnen toevoegen aan onze app.
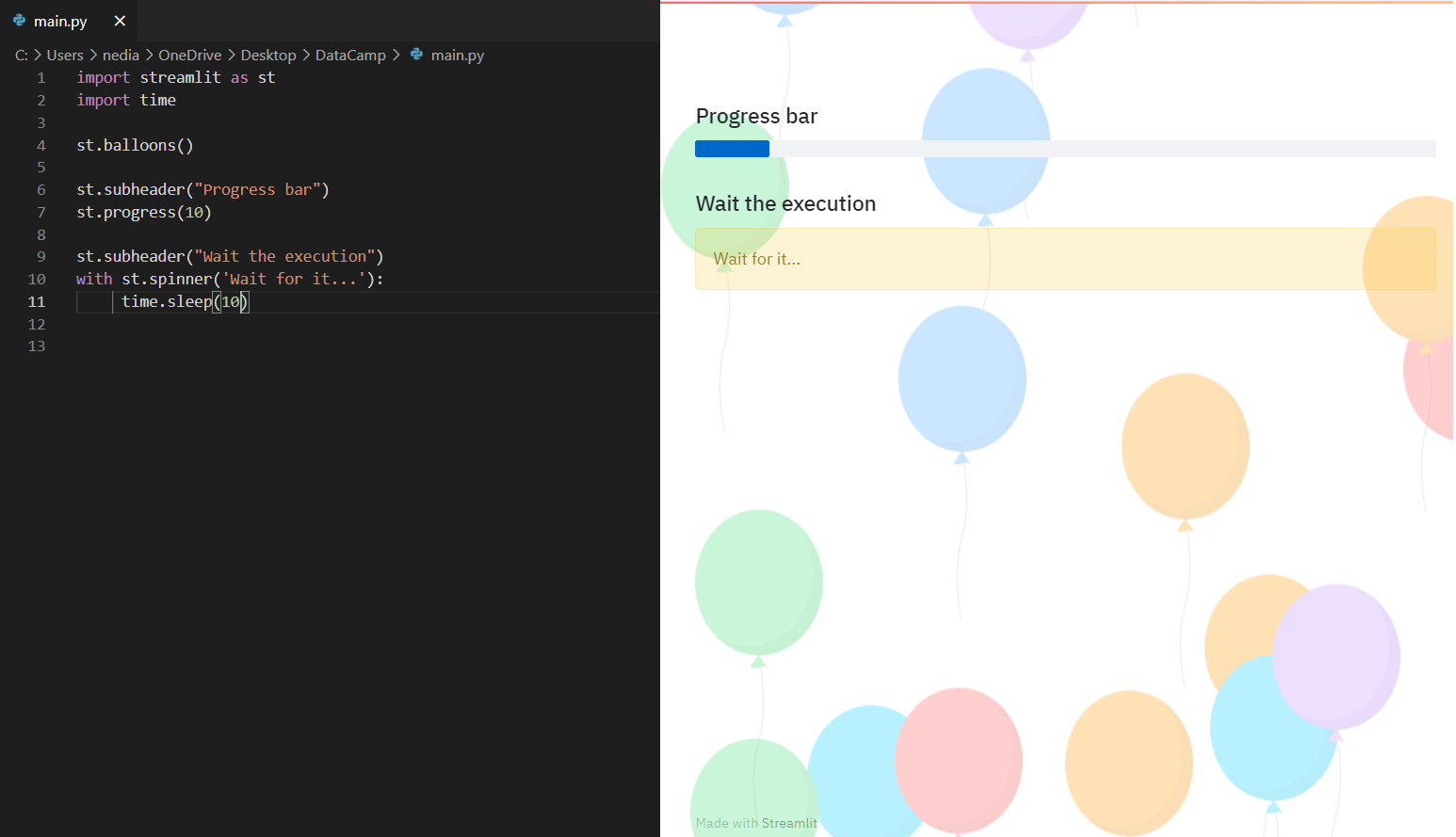
st.balloons(): Hiermee laat je ballonnen zien om iets te vieren. st.progress(): Hiermee toon je een voortgangsbalk. st.spinner(): Hiermee toon je tijdelijk een wachtbericht tijdens uitvoering.
st.balloons() # Celebration balloonsst.progress(10) # Progress barwith st.spinner('Wait for it...'): time.sleep(10) # Simulating a process delayst.success(): Hiermee toon je een succesbericht. st.error(): Hiermee toon je een foutmelding. st.warning(): Hiermee toon je een waarschuwing. st.info(): Hiermee toon je een informatief bericht. st.exception(): Hiermee toon je een uitzondering.
st.success("You did it!")st.error("Error occurred")st.warning("This is a warning")st.info("It's easy to build a Streamlit app")st.exception(RuntimeError("RuntimeError exception"))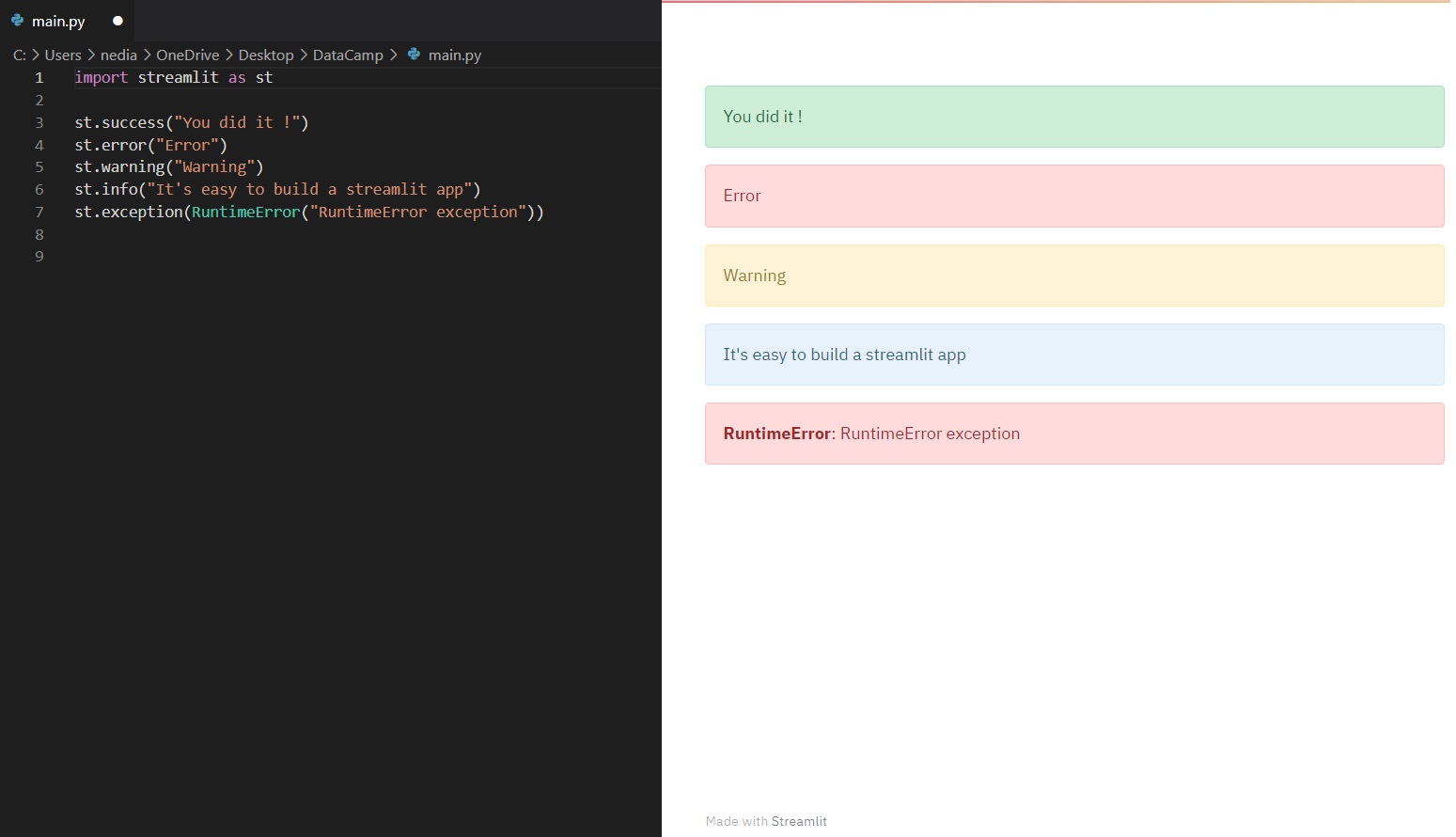
Je kunt ook een zijbalk of een container op je pagina maken om je app te organiseren. De hiërarchie en indeling van pagina's in je app hebben veel invloed op de gebruikerservaring. Door je content te structureren, help je bezoekers je site te begrijpen en te navigeren, waardoor ze sneller vinden wat ze zoeken en de kans groter is dat ze terugkeren.
Als je een element doorgeeft aan st.sidebar(), wordt dit element links vastgezet, zodat gebruikers zich kunnen focussen op de content in je app.
Maar st.spinner() en st.echo() worden niet ondersteund met st.sidebar.
Zoals je ziet kun je een zijbalk in je app-interface maken en daar elementen in plaatsen die je app overzichtelijker en begrijpelijker maken.
st.sidebar.title("Sidebar Title")st.sidebar.markdown("This is the sidebar content")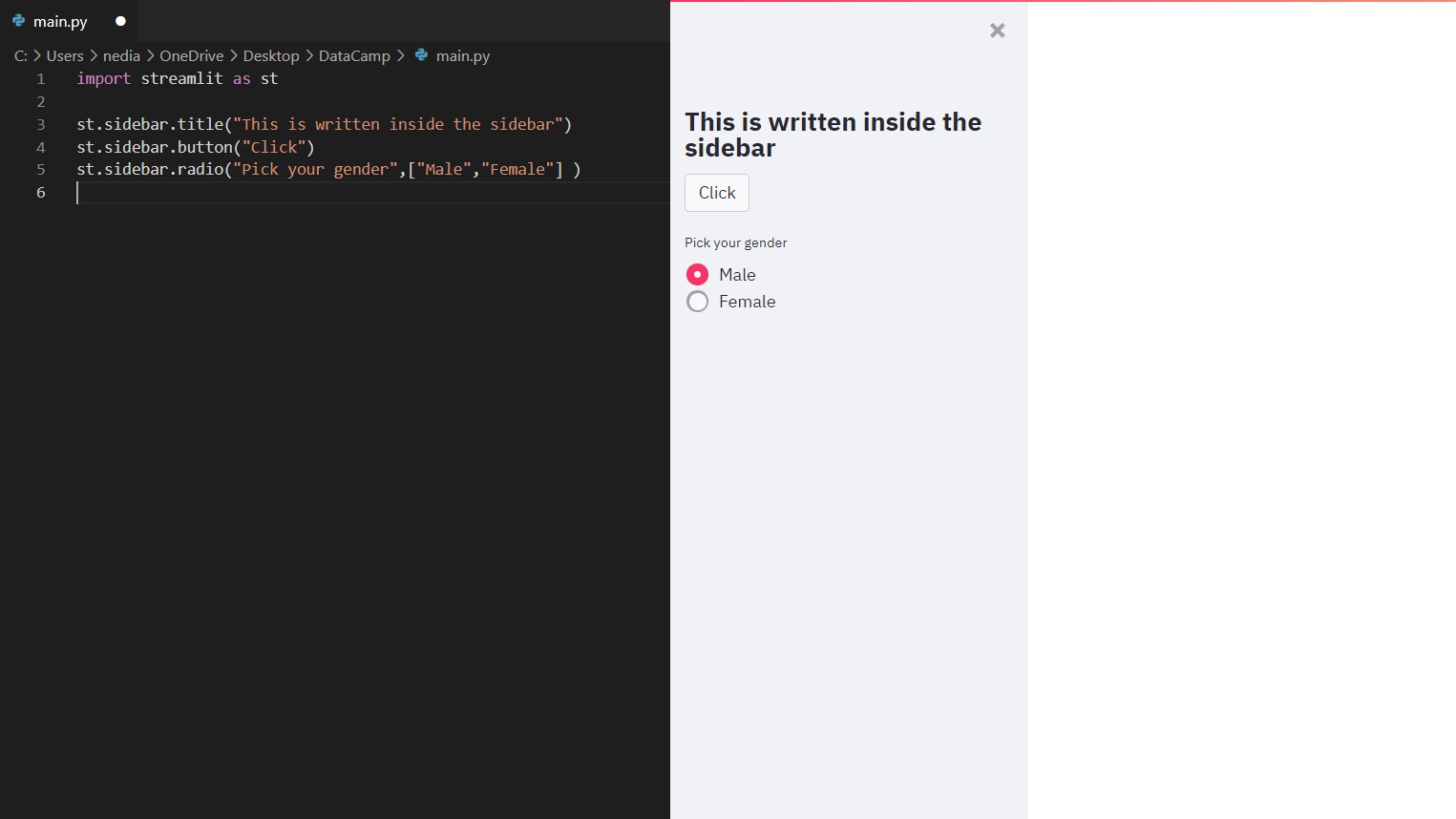
st.container() wordt gebruikt om een onzichtbare container te maken waarin je elementen kunt plaatsen om een handige indeling en hiërarchie te creëren.
with st.container(): st.write("This is inside the container")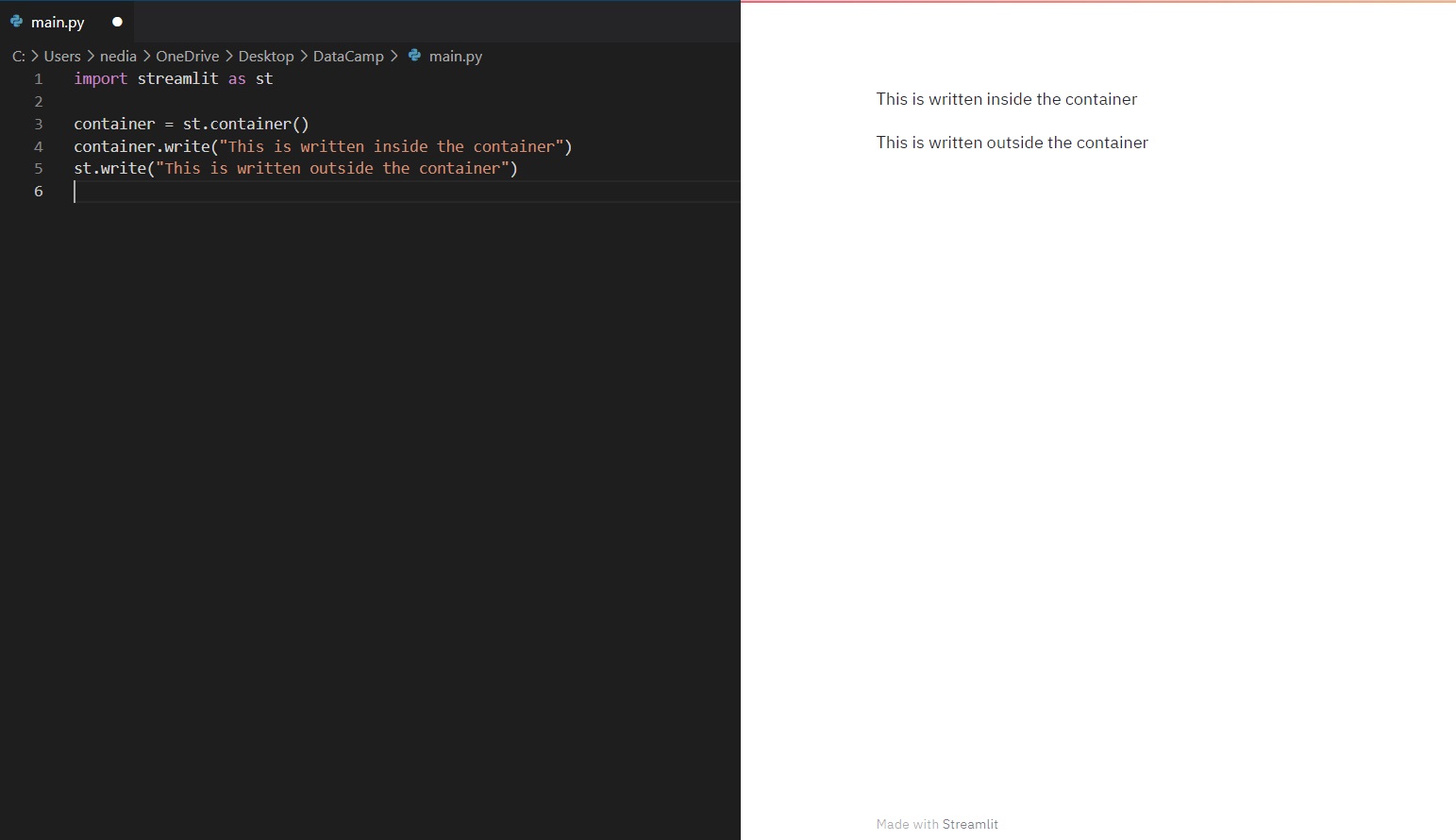
StreamlitStreamlit integreert met populaire Python-visualisatiebibliotheken. Dit zijn de grafiekfuncties die standaard beschikbaar zijn:
st.pyplot(): Hiermee geef je een matplotlib.pyplot-figuur weer.
import streamlit as stimport matplotlib.pyplot as pltimport numpy as nprand = np.random.normal(1, 2, size=20)fig, ax = plt.subplots()ax.hist(rand, bins=15)st.pyplot(fig)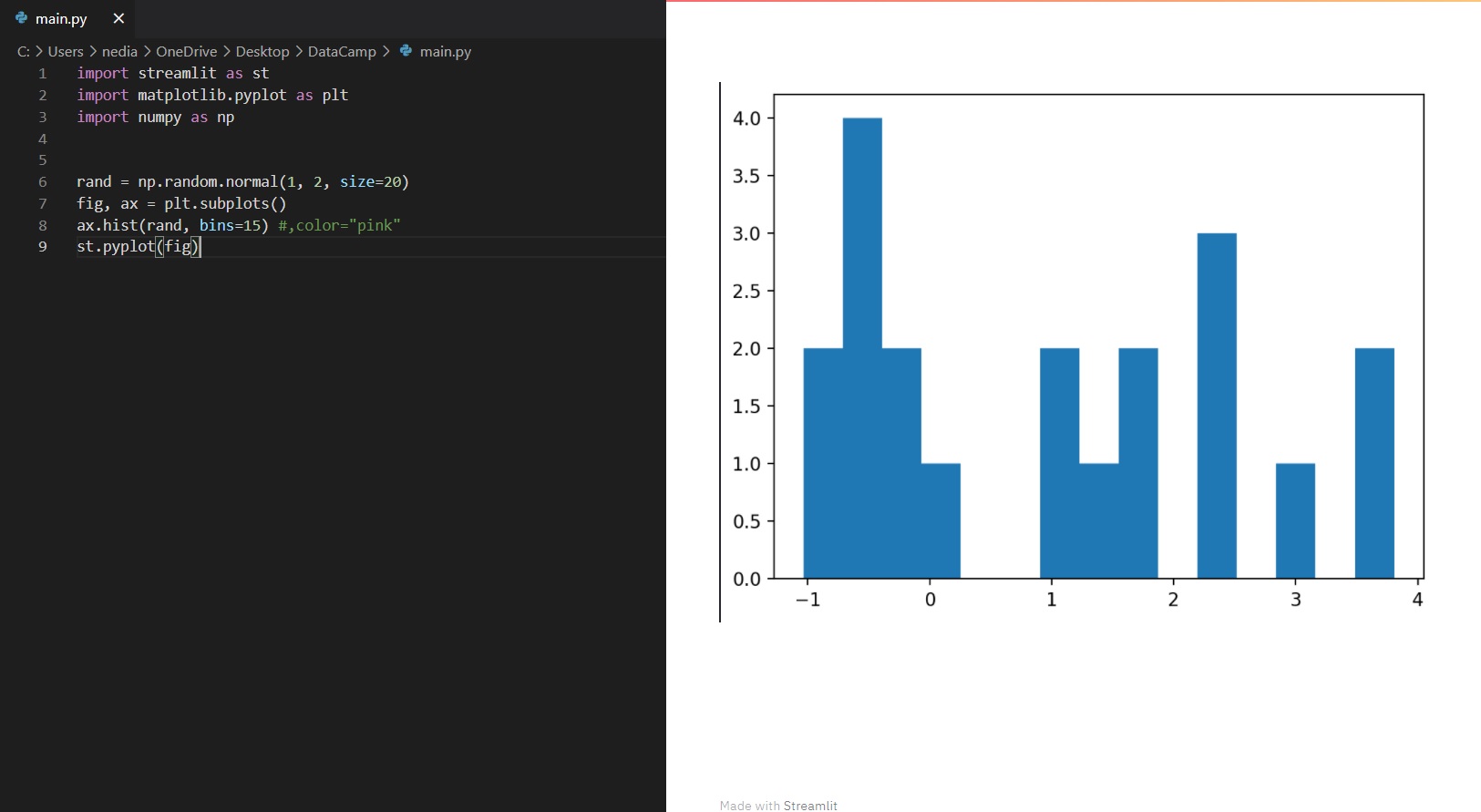
st.line_chart(): Deze functie wordt gebruikt om een lijngrafiek weer te geven.
import streamlit as stimport pandas as pdimport numpy as npdf = pd.DataFrame(np.random.randn(10, 2), columns=['x', 'y'])st.line_chart(df)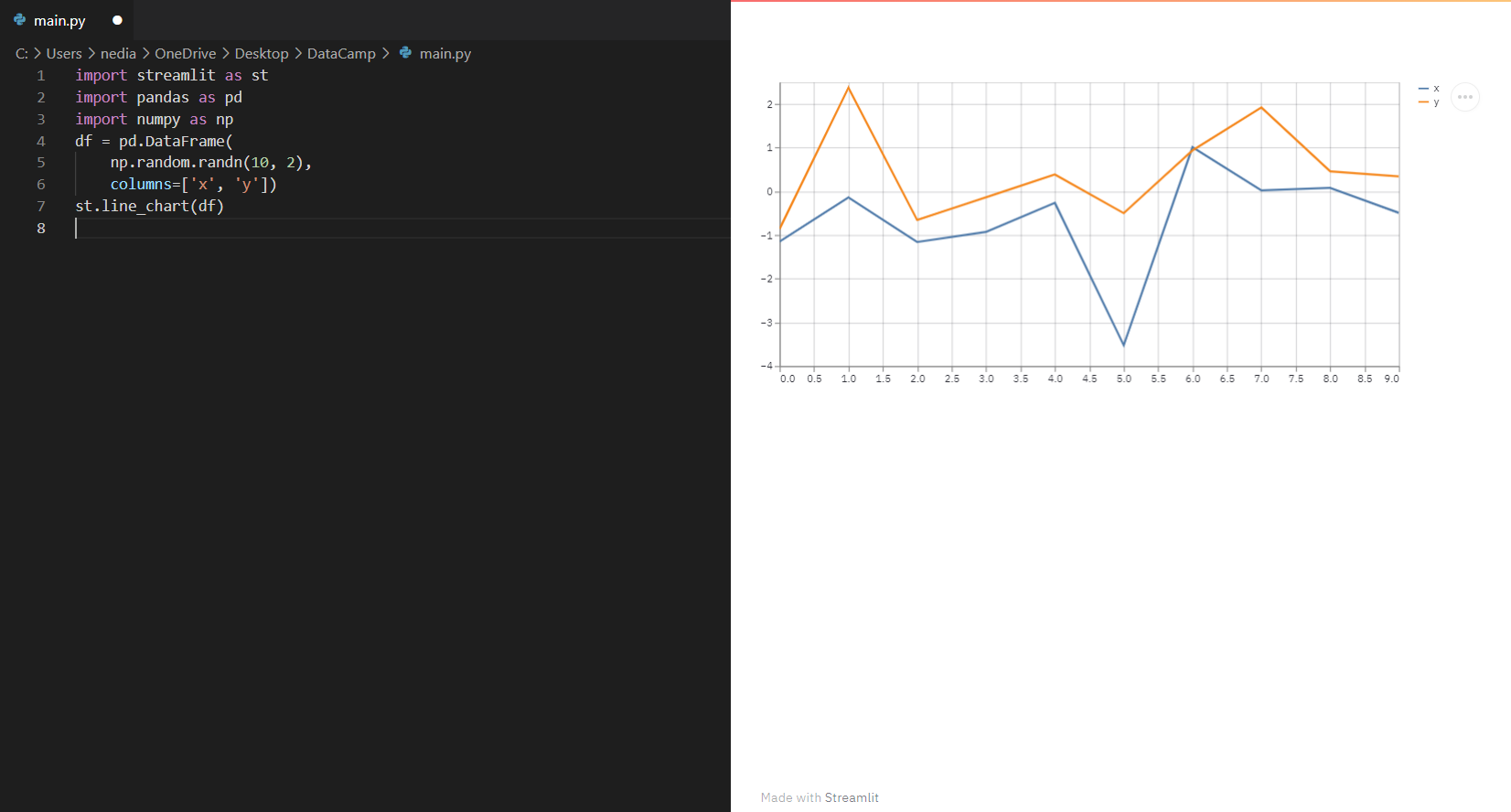
st.bar_chart(): Deze functie wordt gebruikt om een staafdiagram weer te geven.
import streamlit as stimport pandas as pdimport numpy as npdf = pd.DataFrame(np.random.randn(10, 2), columns=['x', 'y'])st.bar_chart(df)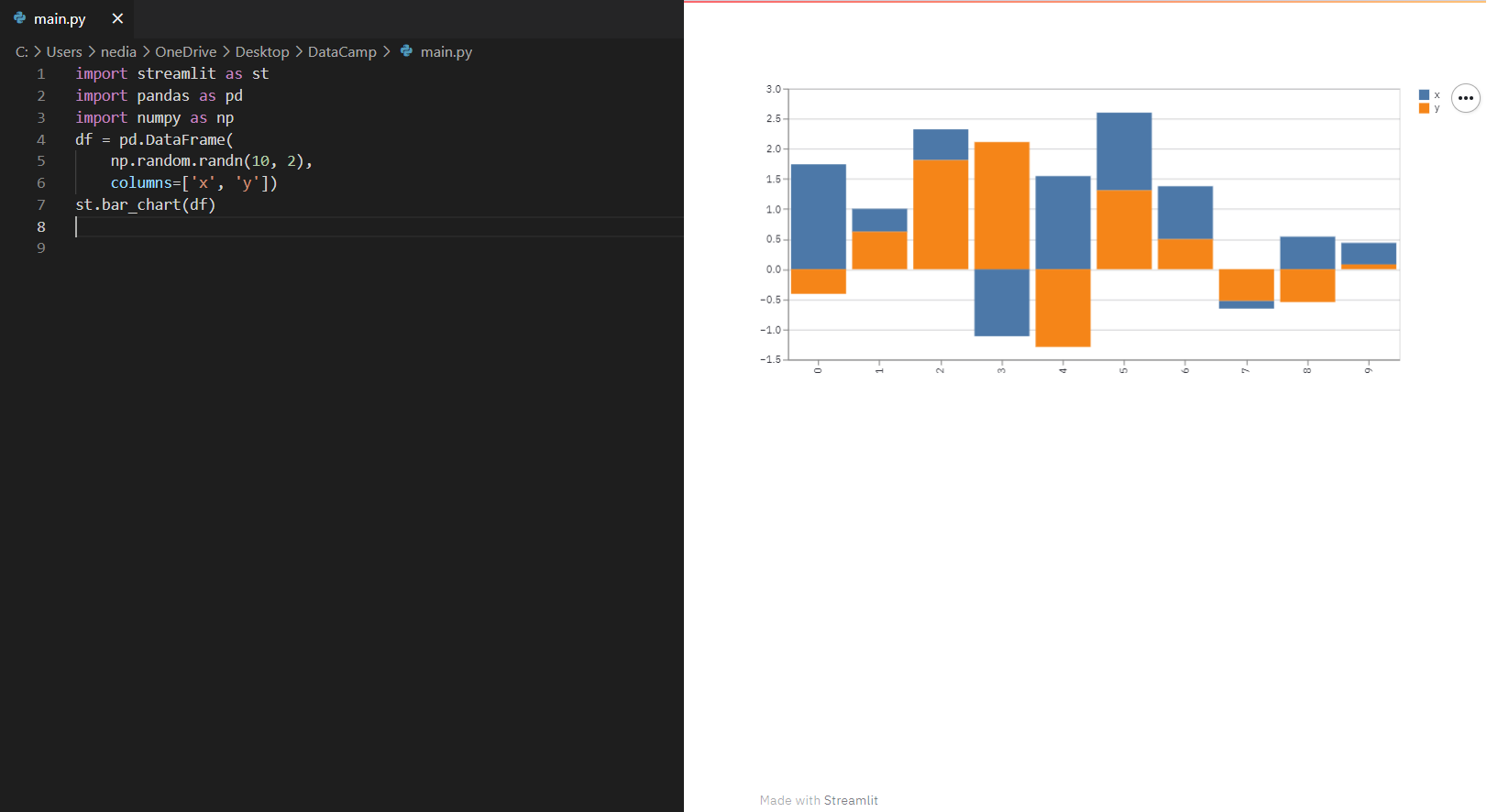
st.area_chart(): Deze functie wordt gebruikt om een gebiedsgrafiek weer te geven.
import streamlit as stimport pandas as pdimport numpy as npdf = pd.DataFrame(np.random.randn(10, 2), columns=['x', 'y'])st.area_chart(df)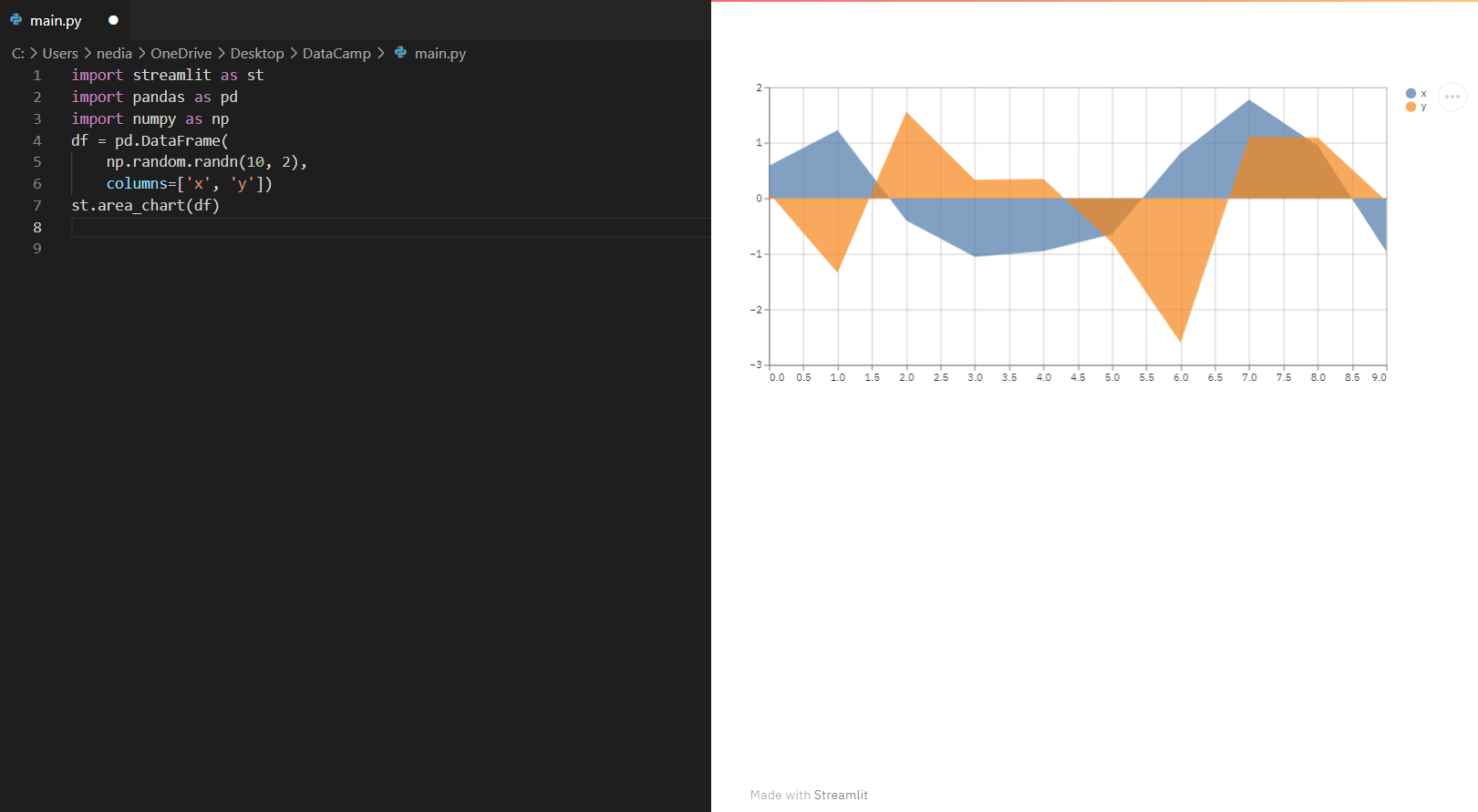
st.altair_chart(): Deze functie wordt gebruikt om een altair-grafiek weer te geven.
import streamlit as stimport pandas as pdimport numpy as npimport altair as altdf = pd.DataFrame(np.random.randn(500, 3), columns=['x', 'y', 'z'])chart = alt.Chart(df).mark_circle().encode( x='x', y='y', size='z', color='z', tooltip=['x', 'y', 'z'])st.altair_chart(chart, use_container_width=True)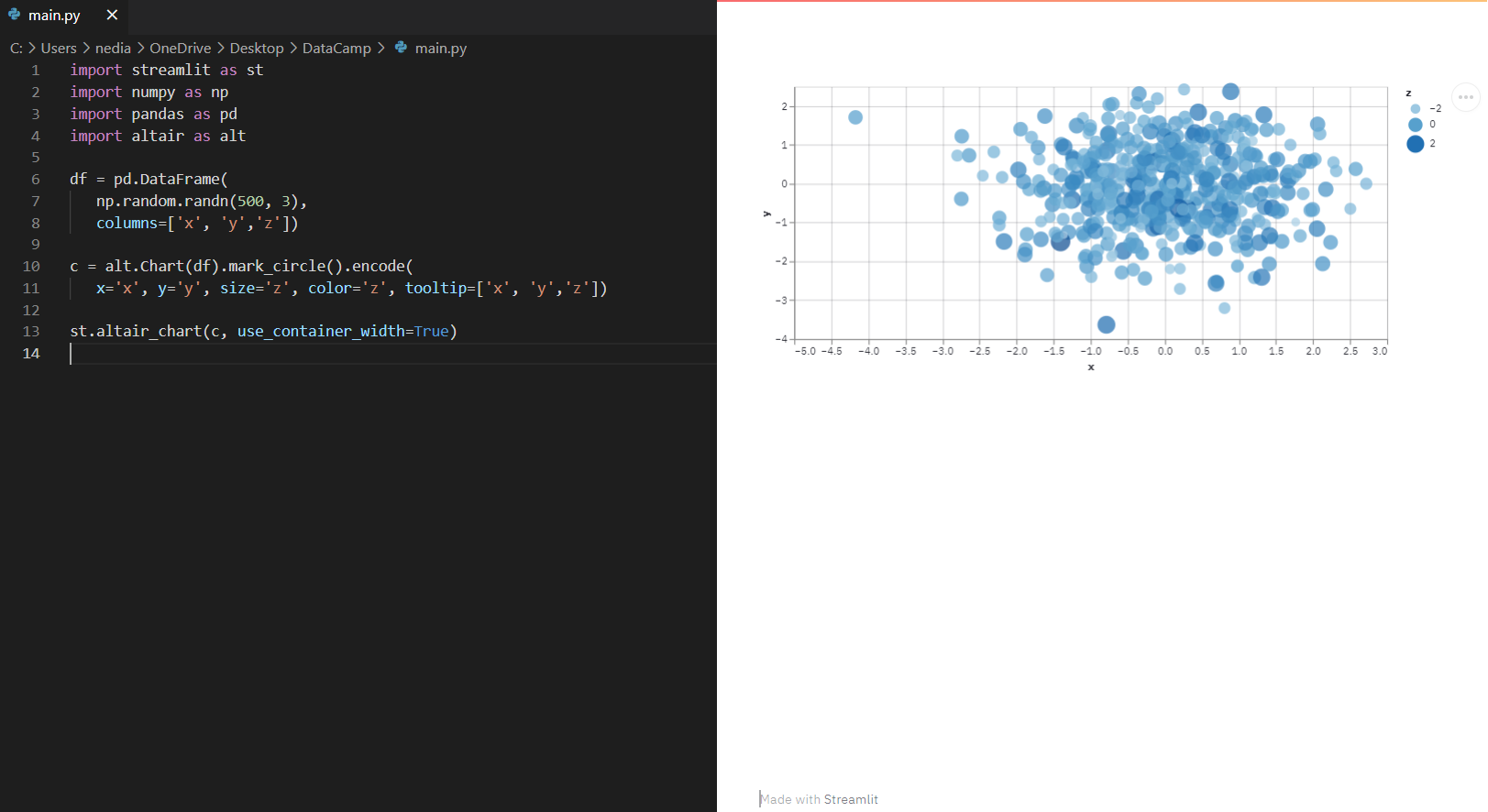
st.graphviz_chart(): Deze functie wordt gebruikt om graafobjecten weer te geven, die kunnen worden opgebouwd met verschillende knooppunten en randen.
import streamlit as stimport graphvizst.graphviz_chart(''' digraph { Big_shark -> Tuna Tuna -> Mackerel Mackerel -> Small_fishes Small_fishes -> Shrimp }''')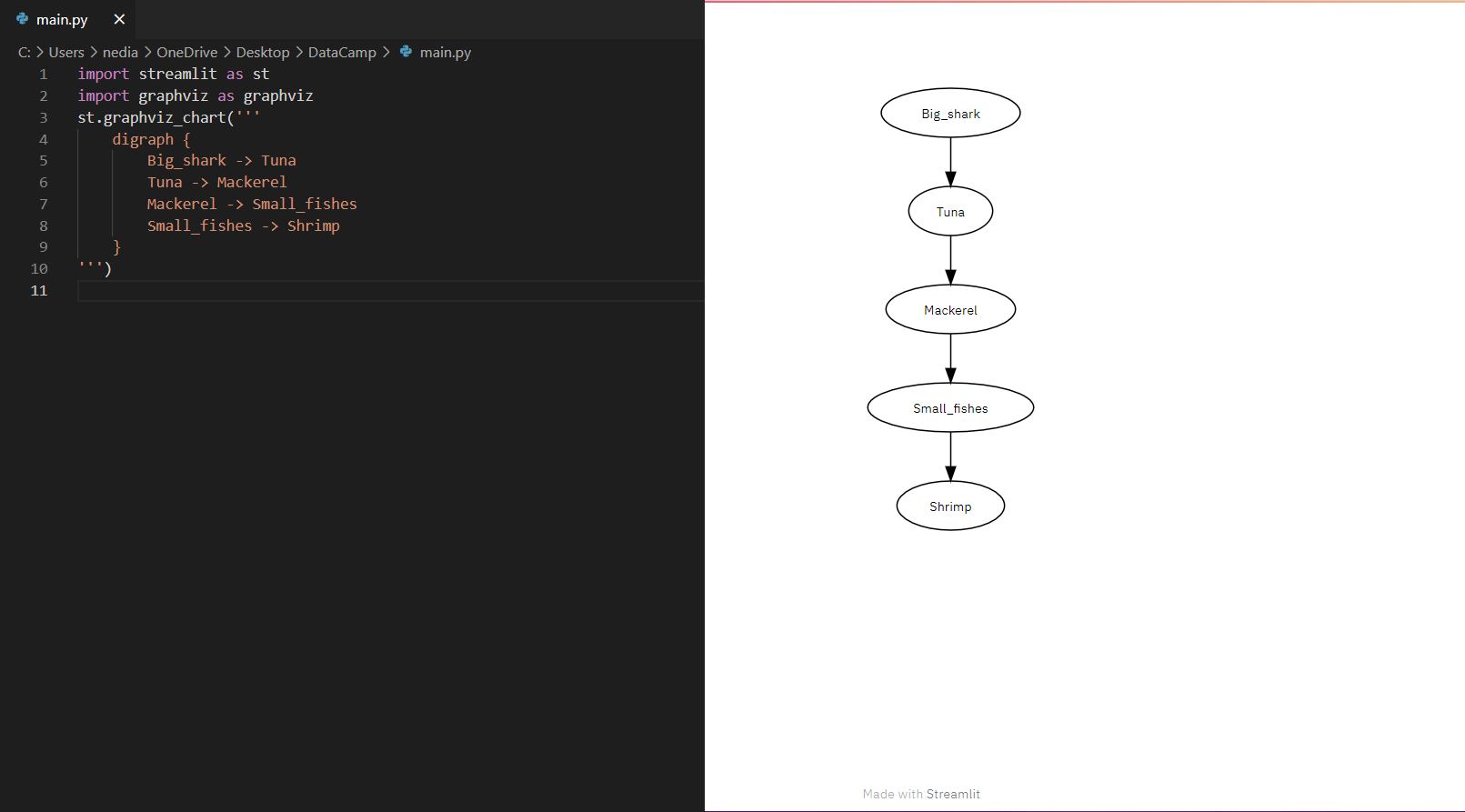
st.map(): Deze functie wordt gebruikt om kaarten in de app weer te geven. Hiervoor zijn echter de waarden van breedte- en lengtegraad vereist en deze waarden mogen niet null/NA zijn.
import pandas as pdimport numpy as npimport streamlit as stdf = pd.DataFrame( np.random.randn(500, 2) / [50, 50] + [37.76, -122.4], columns=['lat', 'lon'])st.map(df)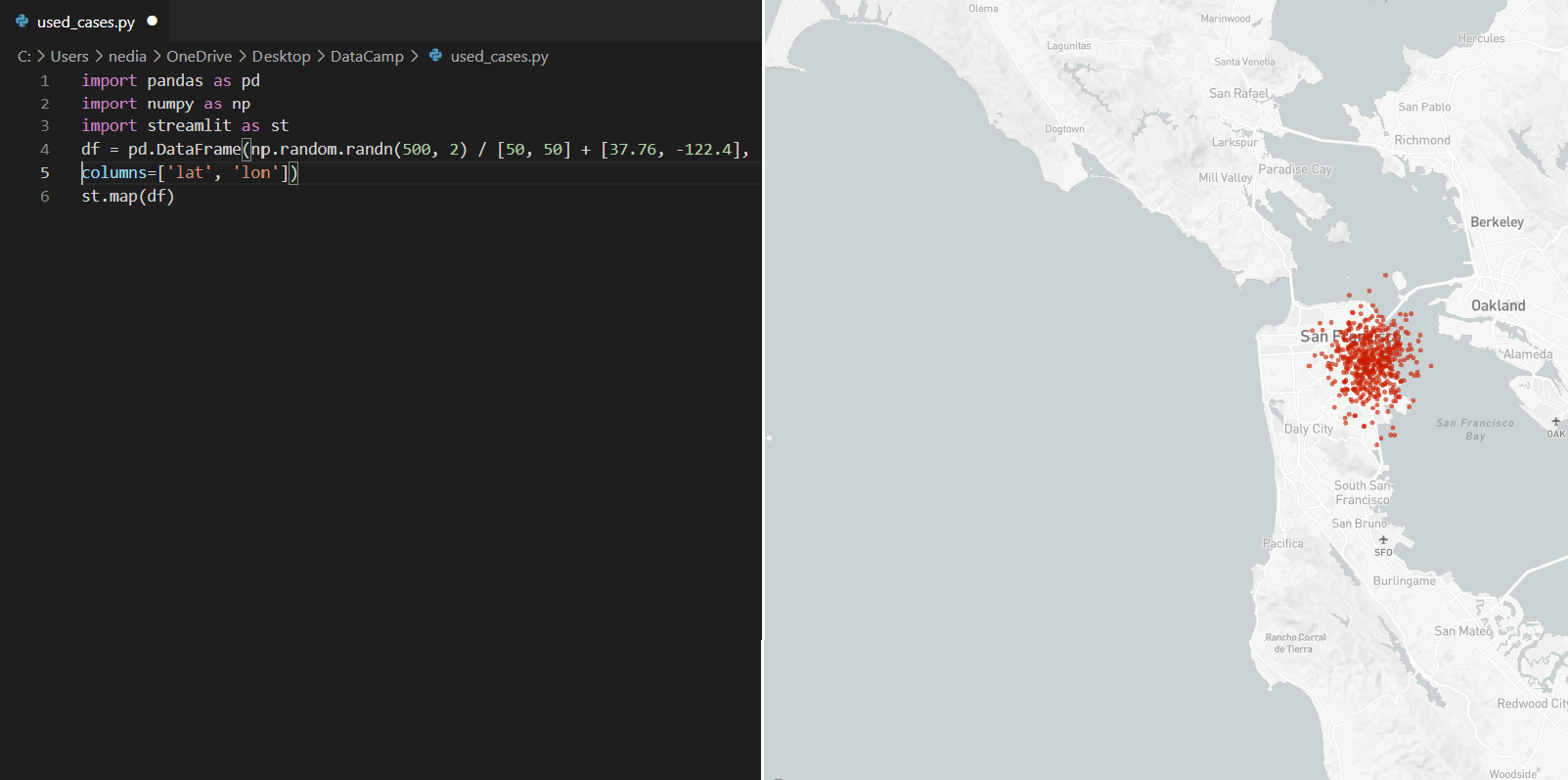
Je kunt ook een thema kiezen dat bij je stijl past. Volg de stappen in de GIF hieronder:

En als je meer wilt leren over styling en thema's, bekijk dan Theming.
Nu is het tijd om samen een app te bouwen!
In deze sectie neem ik je mee door een project dat ik maakte over kredietvoorspelling.
De belangrijkste winst uit leningen komt direct uit de rente. Leenbedrijven verstrekken een lening na een intensief verificatie- en validatieproces. Toch hebben ze nog geen zekerheid of de aanvrager de lening zonder problemen kan terugbetalen. In deze tutorial bouwen we een voorspellend model (Random Forest Classifier) om de leningstatus van een aanvrager te voorspellen. Onze missie is om een webapp te bouwen en deze in productie beschikbaar te maken.
We beginnen met het importeren van de benodigde bibliotheken voor onze app:
import streamlit as stimport pandas as pdimport numpy as npimport pickle # to load a saved modelimport base64 # to handle gif encodingIn deze app gebruiken we meerdere widgets zoals sliders: selectbox en radio in het zijbalkmenu, waarvoor we enkele Python-functies voorbereiden. Het voorbeeld is een eenvoudige demo met twee pagina's. Op de homepage tonen we de geselecteerde data, terwijl de pagina Exploration je variabelen laat visualiseren in grafieken, en de pagina Prediction variabelen bevat met een knop Predict waarmee je de leningstatus kunt inschatten. De onderstaande code geeft je een selectbox in de zijbalk waarmee je een pagina kunt kiezen. De data wordt gecachet zodat die niet steeds opnieuw geladen hoeft te worden.
@st.cache_data is de aanbevolen caching-decorator (ter vervanging van de verouderde @st.cache) die je app snel houdt bij het laden van data van het web, het manipuleren van grote datasets of het uitvoeren van kostbare berekeningen. Gebruik @st.cache_data voor serialiseerbare data zoals DataFrames en strings, en @st.cache_resource voor globale resources zoals databaseconnecties of ML-modellen.
@st.cache_datadef get_fvalue(val): feature_dict = {"No": 1, "Yes": 2} return feature_dict[val]def get_value(val, my_dict): return my_dict[val]
Op de Home-pagina visualiseren we: presentatie-afbeelding / de dataset / histogram van inkomen aanvrager en leenbedrag.
Let op: we gebruiken if/elif/else om tussen pagina's te schakelen.
We laden loan_dataset.csv in variabele data, zodat we er op de Home-pagina een paar regels van kunnen tonen.
if app_mode == 'Home': st.title('Loan Prediction') st.image('loan_image.jpg') st.markdown('Dataset:') data = pd.read_csv('loan_dataset.csv') st.write(data.head()) st.bar_chart(data[['ApplicantIncome', 'LoanAmount']].head(20))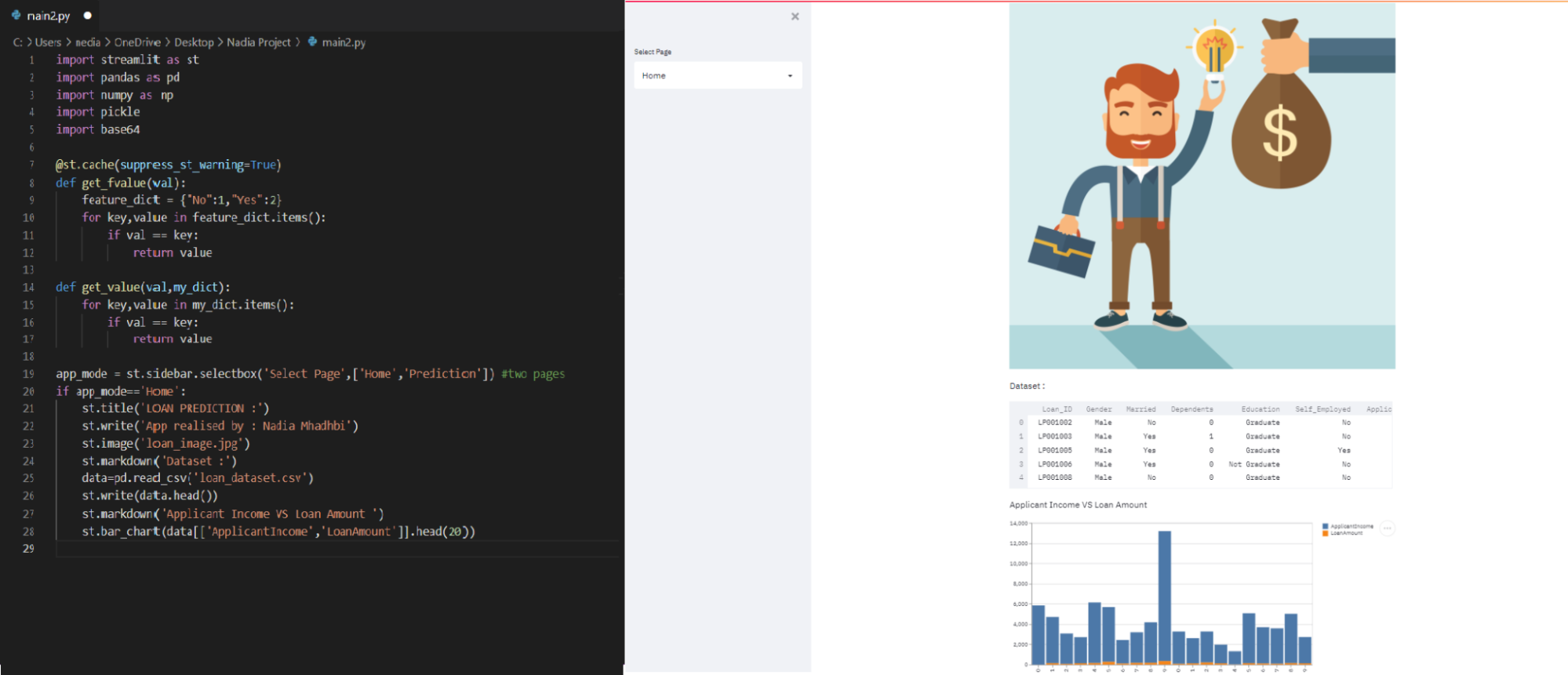
Vervolgens op de Prediction-pagina:
if app_mode == 'Prediction': ApplicantIncome = st.sidebar.slider('ApplicantIncome', 0, 10000, 0) LoanAmount = st.sidebar.slider('LoanAmount in K$', 9.0, 700.0, 200.0) # Assuming additional input features here... # Prediction Logic if st.button("Predict"): loaded_model = pickle.load(open('Random_Forest.sav', 'rb')) prediction = loaded_model.predict(np.array([ApplicantIncome, LoanAmount]).reshape(1, -1)) if prediction[0] == 0: st.error('According to our calculations, you will not get the loan.') else: st.success('Congratulations! You will get the loan.')We schreven twee functies get_value(val,my_dict) en get_fvalue(val) en woordenlijsten zoals feature_dict om st.sidebar.radio() met niet-numerieke variabelen te manipuleren. Het is optioneel; je kunt ook eenvoudig zoiets doen:

Laten we zien waarom we dat deden.
Let op: Machine learning-algoritmen kunnen niet overweg met categorische variabelen. In de dataset deed ik wat feature engineering. Bijvoorbeeld: de kolom Married heeft twee waarden 'Yes' en 'No' en ik deed Label Encoding (bekijk dit om het beter te begrijpen) zodat "NO" gelijk is aan 1 en "Yes" aan 2. De functie get_fvalue(val) retourneert eenvoudig de waarde (1/2), afhankelijk van wat de klant heeft gekozen. Hetzelfde voor de functie get_value(val,my_dict). Het verschil tussen de twee functies is dat de eerste werkt op ja/nee-kenmerken en de tweede in het algemene geval wanneer we meerdere categorieën hebben (bijvoorbeeld: Gender).
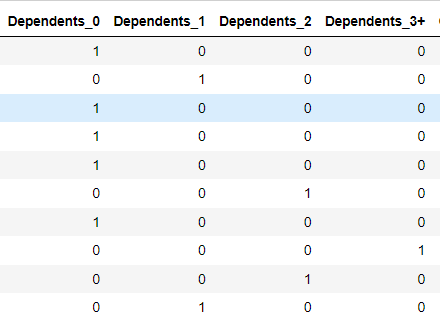
Zoals we zien heeft de variabele Dependents vier categorieën '0','1','2' en '3+' en we kunnen zoiets niet omzetten naar één numerieke variabele, en we hebben '+3' wat betekent dat Dependents 3,4,5 ... kan aannemen. We deden One-Hot Encoding (bekijk dit om het beter te begrijpen). Daarom maakten we een zijbalk-radio met de vier elementen en elk heeft een binaire variabele; als de klant '0' kiest, wordt class_0 gelijk aan 1 en de anderen gelijk aan 0.
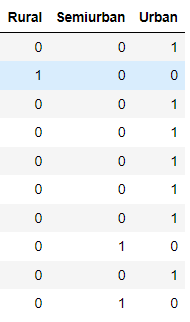
We deden ook One-Hot Encoding voor Property_Area, daarom maakten we 3 variabelen (Rural, Urban, Semiurban). Wanneer Rural 1 krijgt, zijn de anderen 0.
We hebben dus gezien wanneer we onze features label- of one-hot-encoden en hoe we daarmee omgaan om succesvol een werkende Streamlit-app te maken.
data1={ 'Gender':Gender, 'Married':Married, 'Dependents':[class_0,class_1,class_2,class_3], 'Education':Education, 'ApplicantIncome':ApplicantIncome, 'CoapplicantIncome':CoapplicantIncome, 'Self Employed':Self_Employed, 'LoanAmount':LoanAmount, 'Loan_Amount_Term':Loan_Amount_Term, 'Credit_History':Credit_History, 'Property_Area':[Rural,Urban,Semiurban], } feature_list=[ApplicantIncome,CoapplicantIncome,LoanAmount,Loan_Amount_Term,Credit_History,get_value(Gender,gender_dict),get_fvalue(Married),data1['Dependents'][0],data1['Dependents'][1],data1['Dependents'][2],data1['Dependents'][3],get_value(Education,edu),get_fvalue(Self_Employed),data1['Property_Area'][0],data1['Property_Area'][1],data1['Property_Area'][2]] single_sample = np.array(feature_list).reshape(1,-1)Nu slaan we onze variabelen op in een woordenboek, omdat we get_value(val,my_dict) en get_fvalue(val) schreven om met woordenboeken te werken. Daarna wordt de invoer—wat de klant kiest als input in onze Streamlit-app—geordend in een lijst feature_list en vervolgens in een numpy-variabele single_sample.
Let op: de inputs van features moeten in dezelfde volgorde staan als de kolommen in de dataset (bijv. Married kan niet de input van Gender krijgen).
if st.button("Predict"): file_ = open("6m-rain.gif", "rb") contents = file_.read() data_url = base64.b64encode(contents).decode("utf-8") file_.close() file = open("green-cola-no.gif", "rb") contents = file.read() data_url_no = base64.b64encode(contents).decode("utf-8") file.close() loaded_model = pickle.load(open('Random_Forest.sav', 'rb')) prediction = loaded_model.predict(single_sample) if prediction[0] == 0 : st.error( 'According to our Calculations, you will not get the loan from Bank' ) st.markdown( f'<img src="data:image/gif;base64,{data_url_no}" alt="cat gif">', unsafe_allow_html=True,) elif prediction[0] == 1 : st.success( 'Congratulations!! you will get the loan from Bank' ) st.markdown( f'<img src="data:image/gif;base64,{data_url}" alt="cat gif">', unsafe_allow_html=True, )Tot slot laden we ons opgeslagen RandomForestClassifier-model in loaded_model en de voorspelling, die 0 of 1 is (classificatieprobleem), in prediction. De .gif-bestanden worden opgeslagen in file en file_. Afhankelijk van de waarde van prediction hebben we twee gevallen, "Success" of "Failed", voor het krijgen van een lening van de bank.
Dit is onze Prediction-pagina:
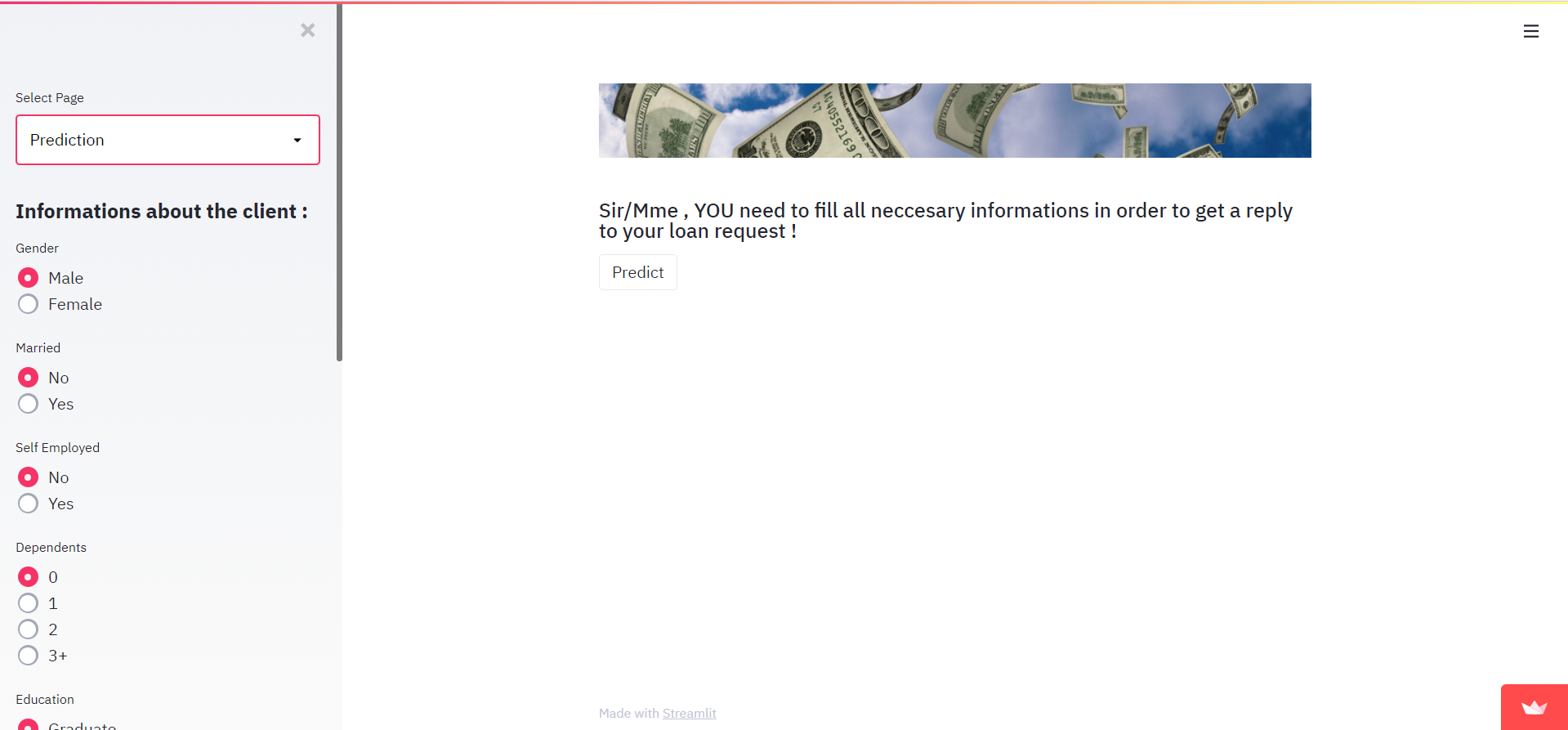
In het geval van FAILURE ziet de output er zo uit:
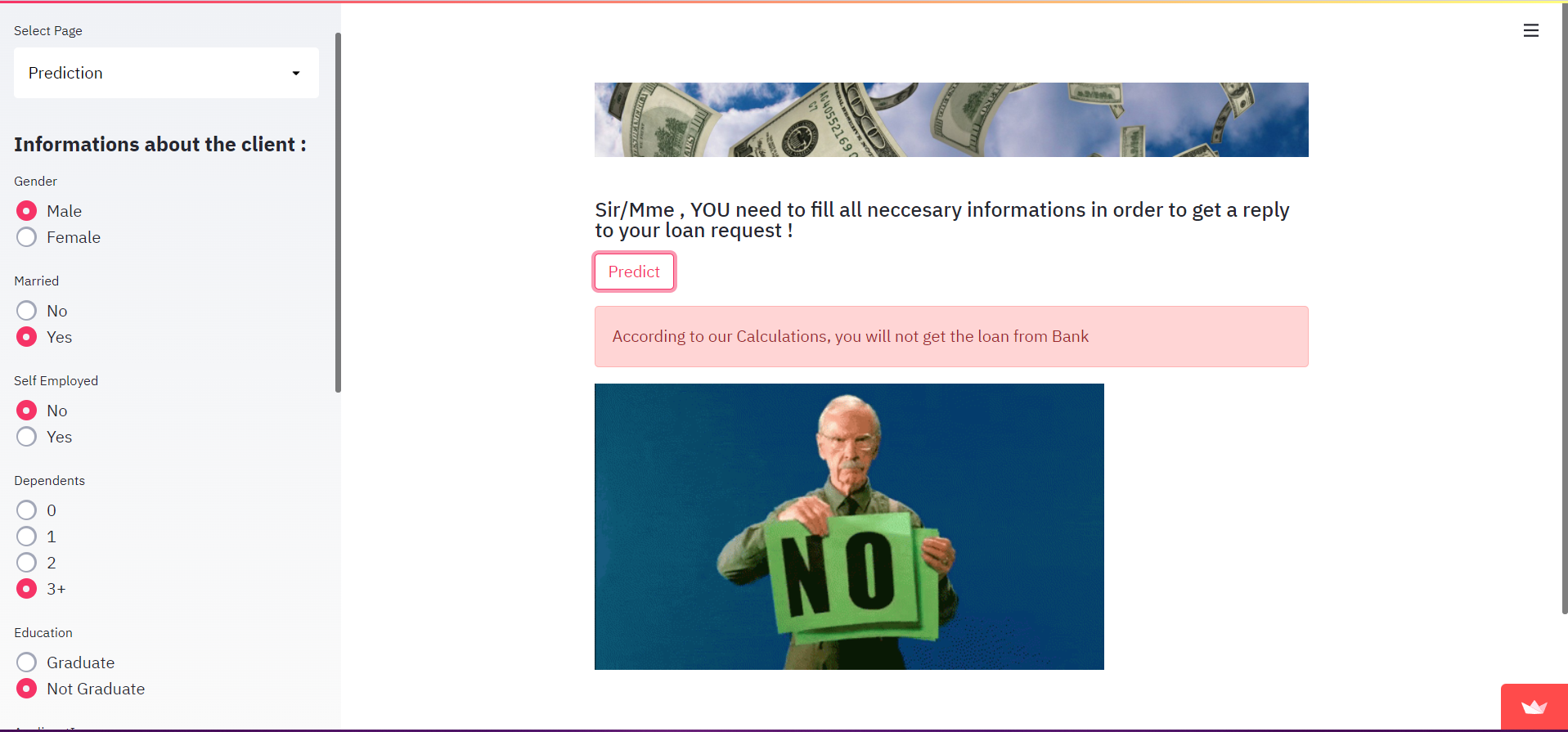
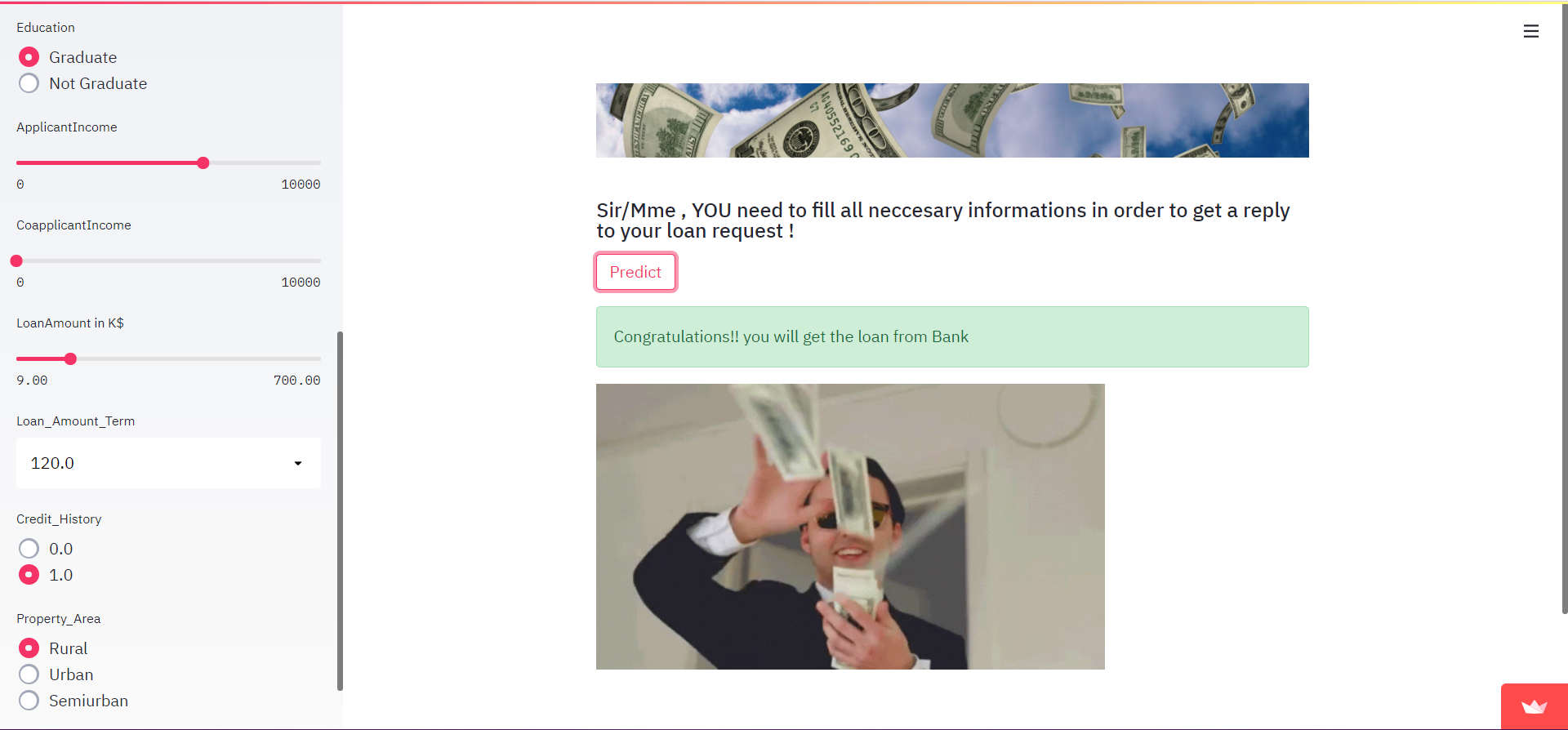
In het geval van SUCCESS ziet de output er zo uit:
Deployment is het mechanisme waarmee applicaties van ontwikkelaars naar gebruikers worden gebracht.
Het uitrollen van een applicatie is het proces van kopiëren, configureren en inschakelen van een specifieke applicatie op een specifieke basis-URL. Zodra het uitrolproces is voltooid, is de applicatie openbaar toegankelijk op de basis-URL. De server voert dit tweestappenproces uit door eerst de applicatie te stagen en deze daarna te activeren na succesvolle staging.
Laten we leren hoe je een Streamlit-app uitrolt!
Voordat je je app probeert uit te rollen, moet je een nieuwe repository op je GitHub maken waar je je app-code en dependencies plaatst.
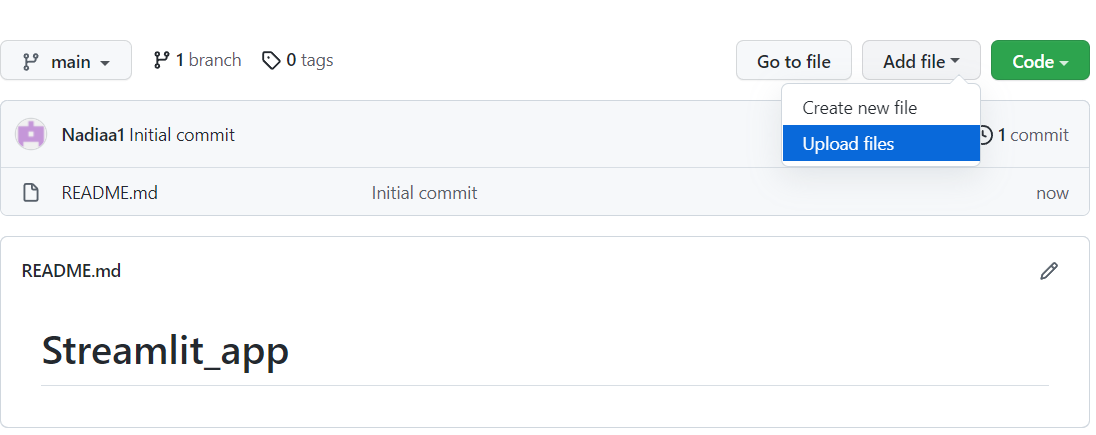
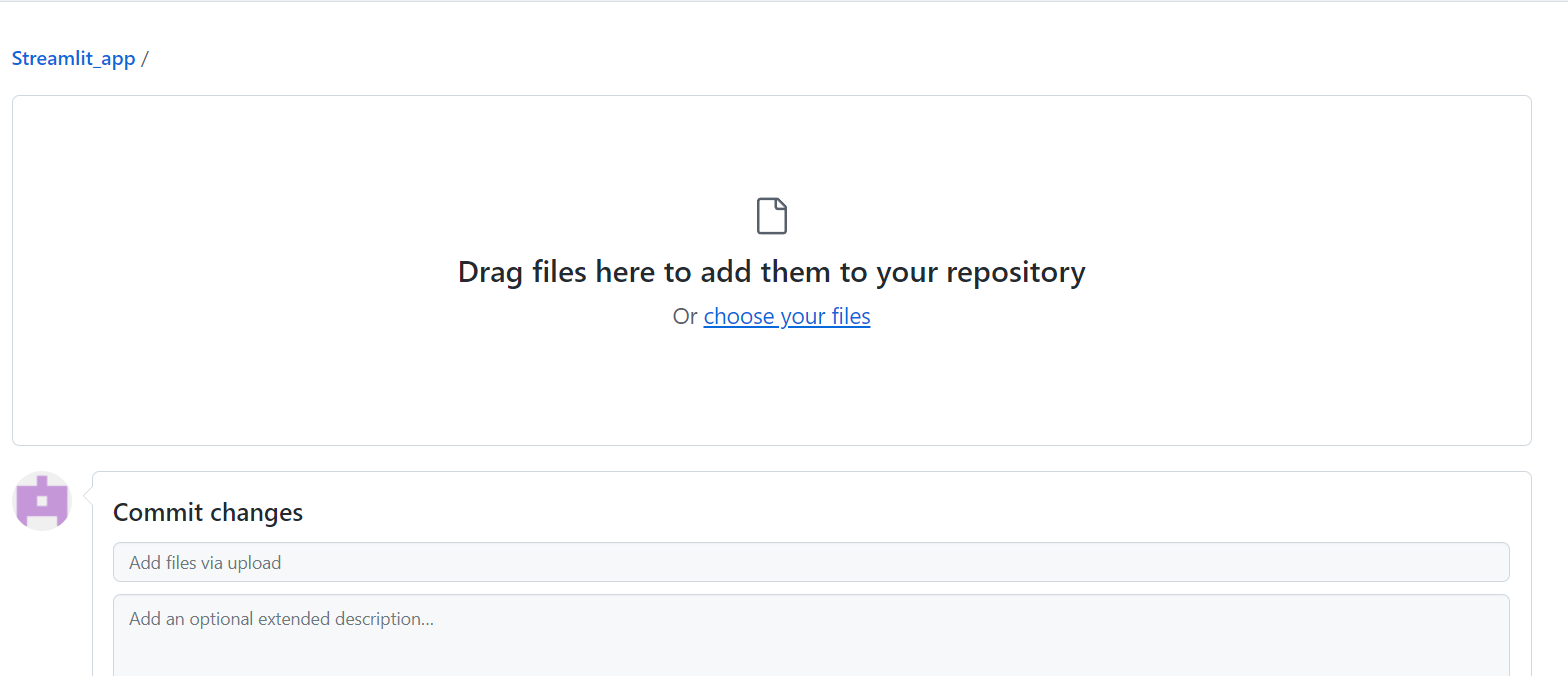
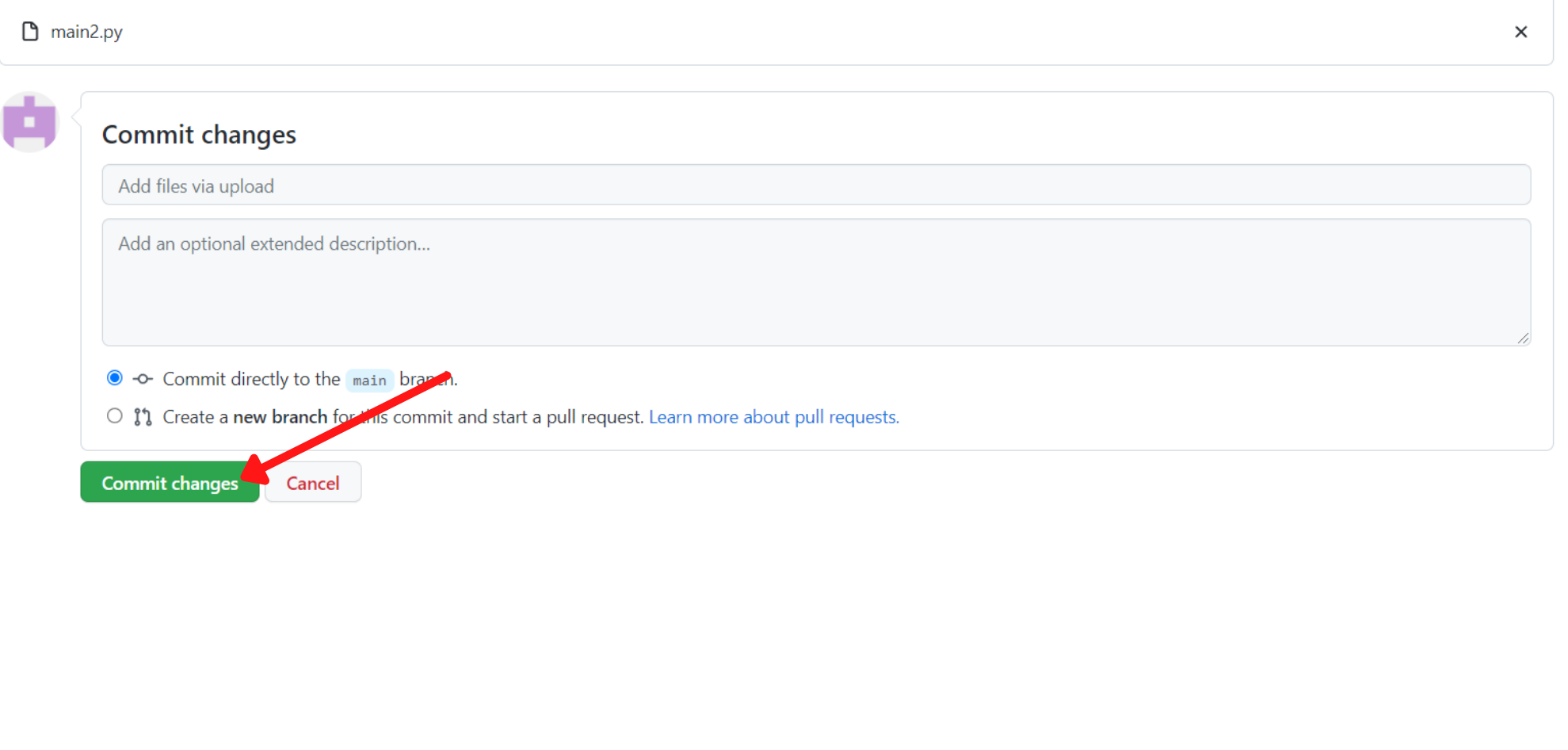
Klik daarna op commit changes om ze op te slaan:
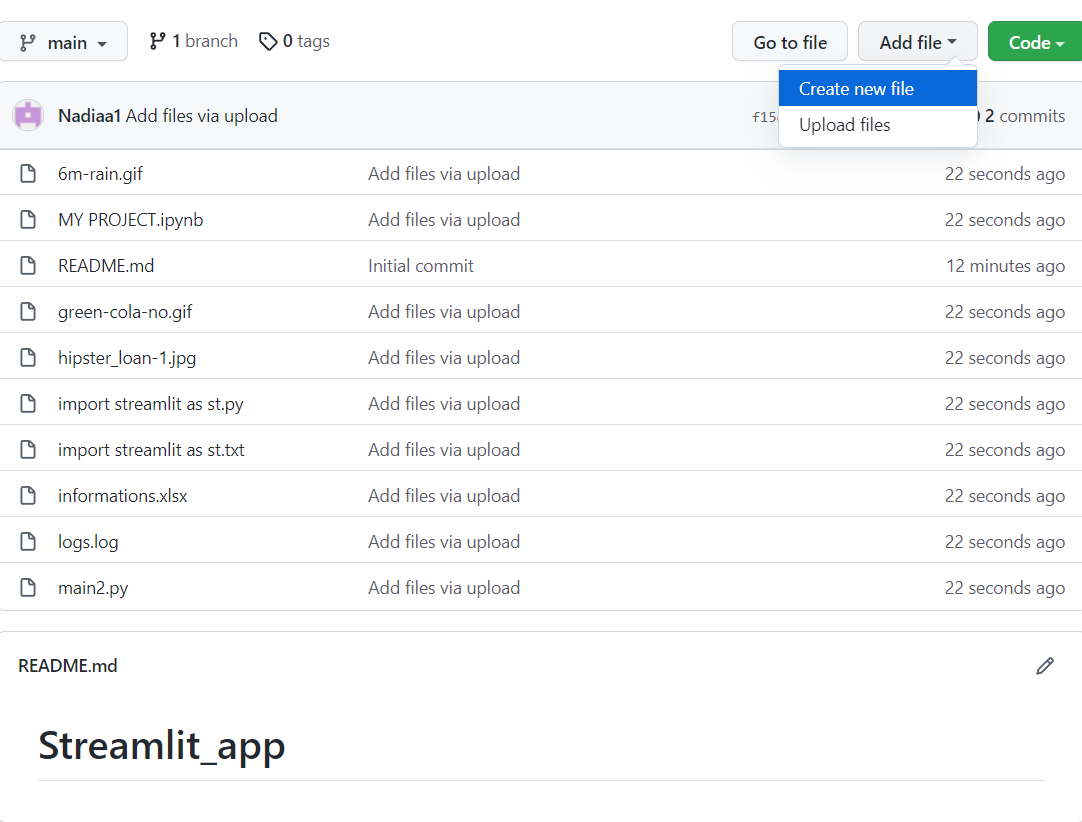
Nadat je een repository hebt gemaakt en bestanden hebt geüpload, moet je een nieuw bestand maken met de naam requirements waarin je de bibliotheken zet die je in je app gebruikt.
Klik eerst op create new file.
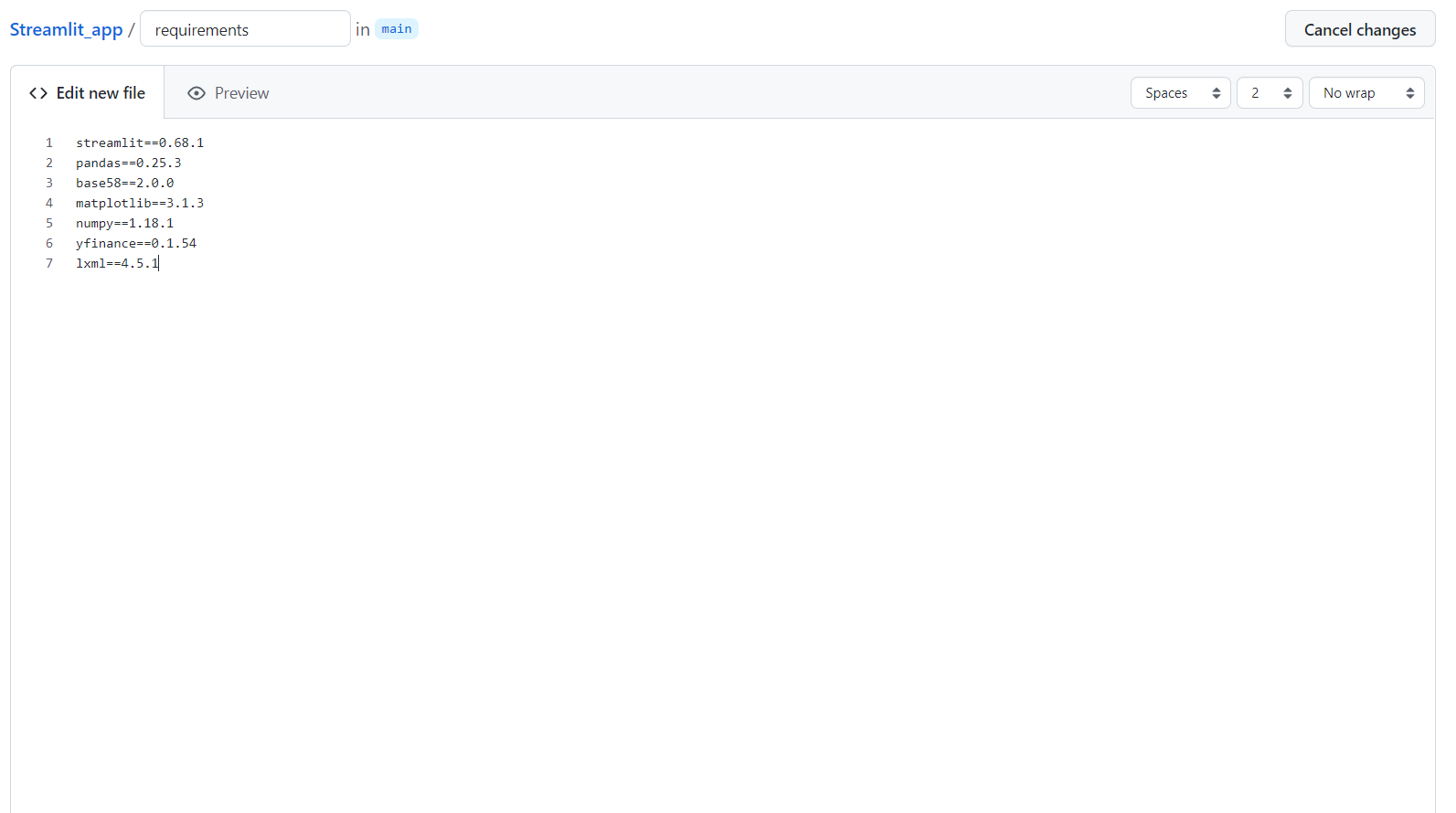
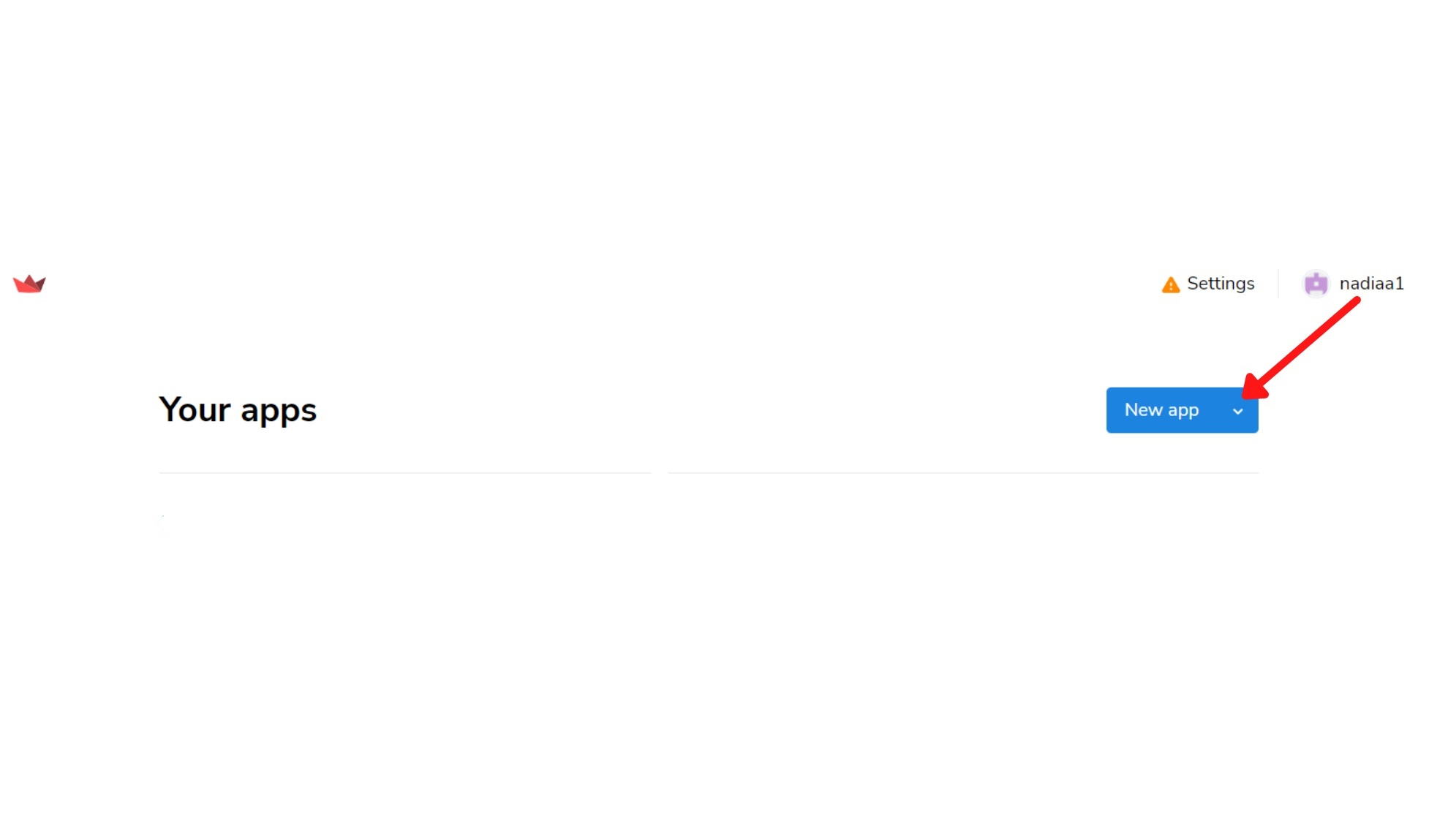
Nu ben je bijna klaar om je app uit te rollen; ga naar deze link.
Volg daarna deze stappen:
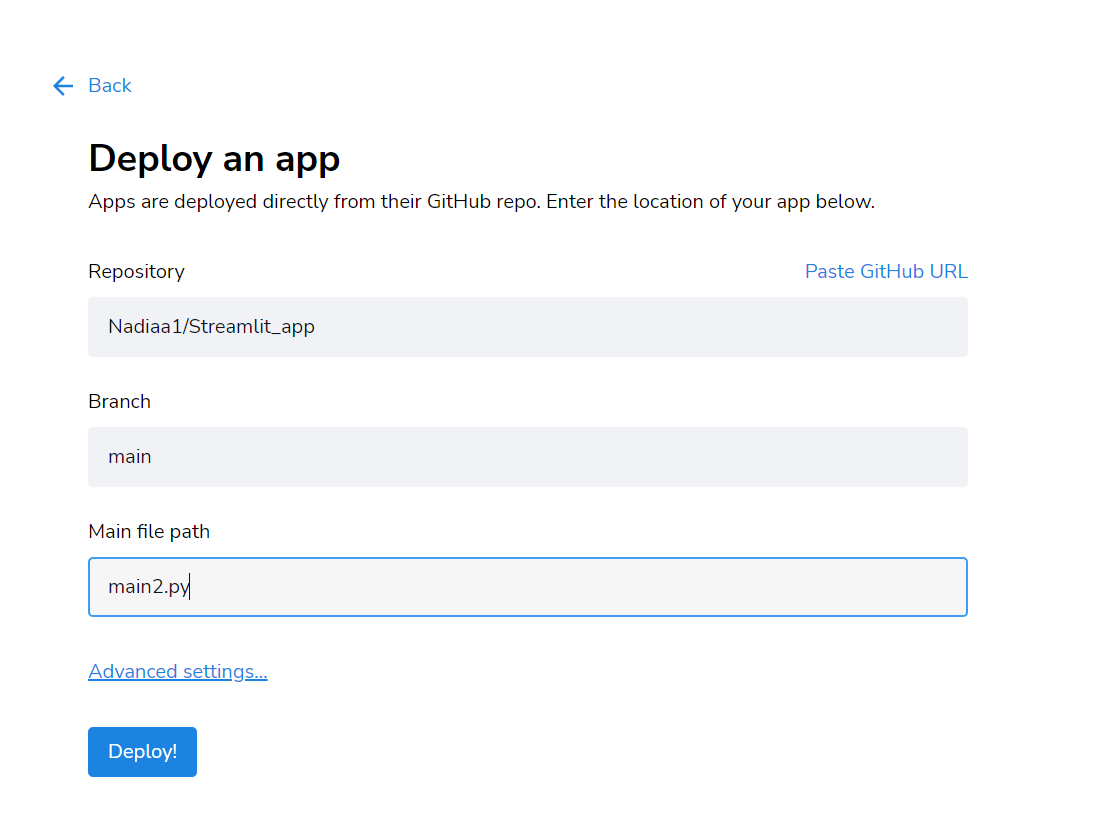
Klik op Deploy en wacht even!
Er opent automatisch een pagina in je browser! Deze pagina is je projectapp die met Streamlit is gerealiseerd.
Gefeliciteerd, je hebt je app succesvol uitgerold! Klik hier om de uitgerolde app te bekijken.
Voor meer documentatie, ga naar: docs.streamlit.io
Leren met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
