Corso
Acquisizione dati semplificata con pandas
4 h
63.2K
Streamlit è un framework gratuito e open source per creare e condividere rapidamente splendide web app di machine learning e data science.
È una libreria basata su Python pensata specificamente per gli ingegneri di machine learning. I data scientist o i machine learning engineer non sono sviluppatori web e non sono interessati a passare settimane a imparare a usare questi framework per creare web app. Preferiscono invece uno strumento più facile da imparare e usare, purché possa visualizzare i dati e raccogliere i parametri necessari per il modellamento.
Con Streamlit puoi creare un’app dall’aspetto impeccabile con poche righe di codice.

La cosa migliore di Streamlit è che non devi nemmeno conoscere le basi dello sviluppo web per iniziare o per creare la tua prima web app. Quindi, se ti occupi di data science e vuoi distribuire i tuoi modelli in modo semplice, rapido e con poche righe di codice, Streamlit fa per te.
Uno degli aspetti fondamentali per il successo di un’applicazione è offrirla con un’interfaccia utente efficace e intuitiva. Molte app moderne con grandi quantità di dati affrontano la sfida di costruire rapidamente un’interfaccia efficace, senza passaggi complicati. Streamlit è una promettente libreria Python open source che permette agli sviluppatori di creare interfacce utente accattivanti in pochissimo tempo.
Streamlit è il modo più semplice, soprattutto per chi non ha conoscenze di front-end, per portare il proprio codice in una web app:
La prima cosa è installarlo:
1. Installa Anaconda e crea il tuo ambiente
2. Apri il terminale
3. Digita questo comando nel terminale per installare Streamlit:
pip install streamlit4. Verifica se l'installazione è andata a buon fine:
streamlit hello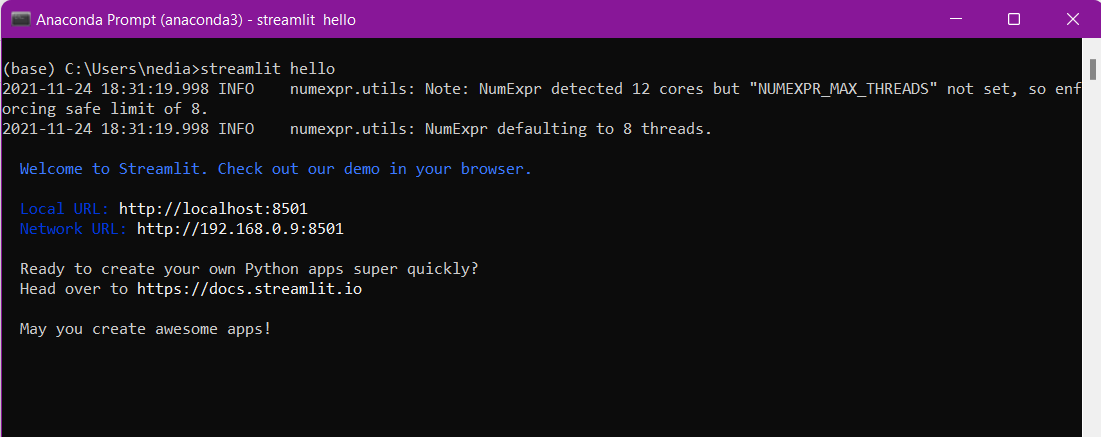
Quando esegui questo comando nel terminale, la pagina qui sotto dovrebbe aprirsi automaticamente:
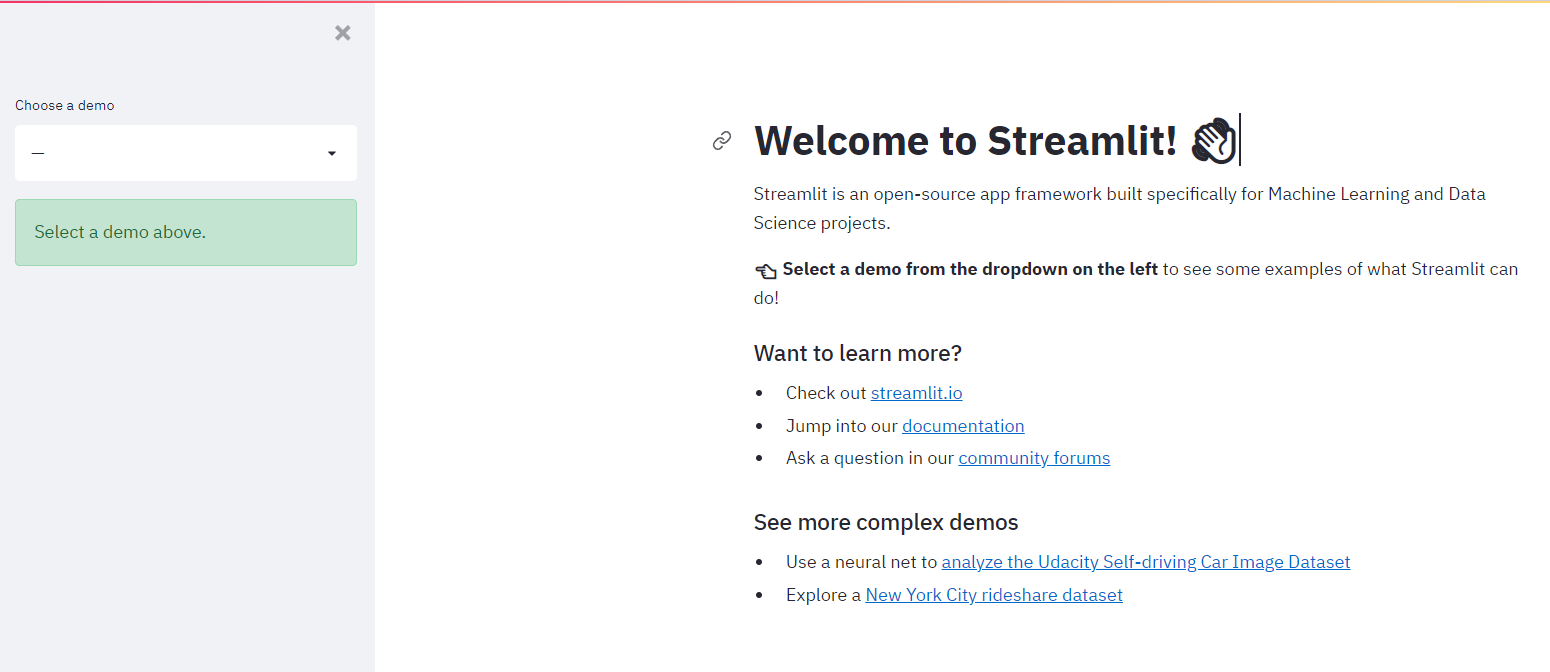
1. Installa pip:
python3 -m ensurepip --upgrade2. Installa pipenv:
pip3 install pipenv3. Crea il tuo ambiente. Apri la cartella del progetto:
cd project_folder_name4. Crea un ambiente pipenv:
pipenv shell5. Digita questo comando per installare Streamlit:
pip install streamlitVerifica se l'installazione è andata a buon fine:
streamlit hello1. Installa pip:
sudo apt-get install python3-pip2. Installa pipenv:
pip3 install pipenv3. Crea il tuo ambiente. Apri la cartella del progetto:
cd project_folder_name4. Crea un ambiente pipenv:
pipenv shell5. Digita questo comando per installare Streamlit
pip install streamlit6. Verifica se l'installazione è andata a buon fine:
streamlit hellostreamlit run file_name.py
I comandi di Streamlit sono facili da scrivere e da capire. Con un semplice comando puoi visualizzare testi, media, widget, grafici, ecc.
Qui ti mostro come aggiungere testo alla tua app Streamlit e i diversi comandi disponibili.
st.write(): questa funzione si usa per aggiungere qualsiasi cosa a una web app, da stringhe formattate a grafici in figure matplotlib, grafici Altair, figure plotly, data frame, modelli Keras e altro.
import streamlit as stst.write("Hello ,let's learn how to build a streamlit app together")
st.title(): questa funzione ti permette di aggiungere il titolo dell'app. st.header(): imposta l'intestazione di una sezione. st.markdown(): imposta una sezione in Markdown. st.subheader(): imposta la sottointestazione di una sezione. st.caption(): scrive una didascalia. st.code(): mostra del codice. st.latex(): mostra espressioni matematiche formattate in LaTeX.
import streamlit as stst.title("This is the app title")st.header("This is the header")st.markdown("This is the markdown")st.subheader("This is the subheader")st.caption("This is the caption")st.code("x = 2021")st.latex(r''' a+a r^1+a r^2+a r^3 ''')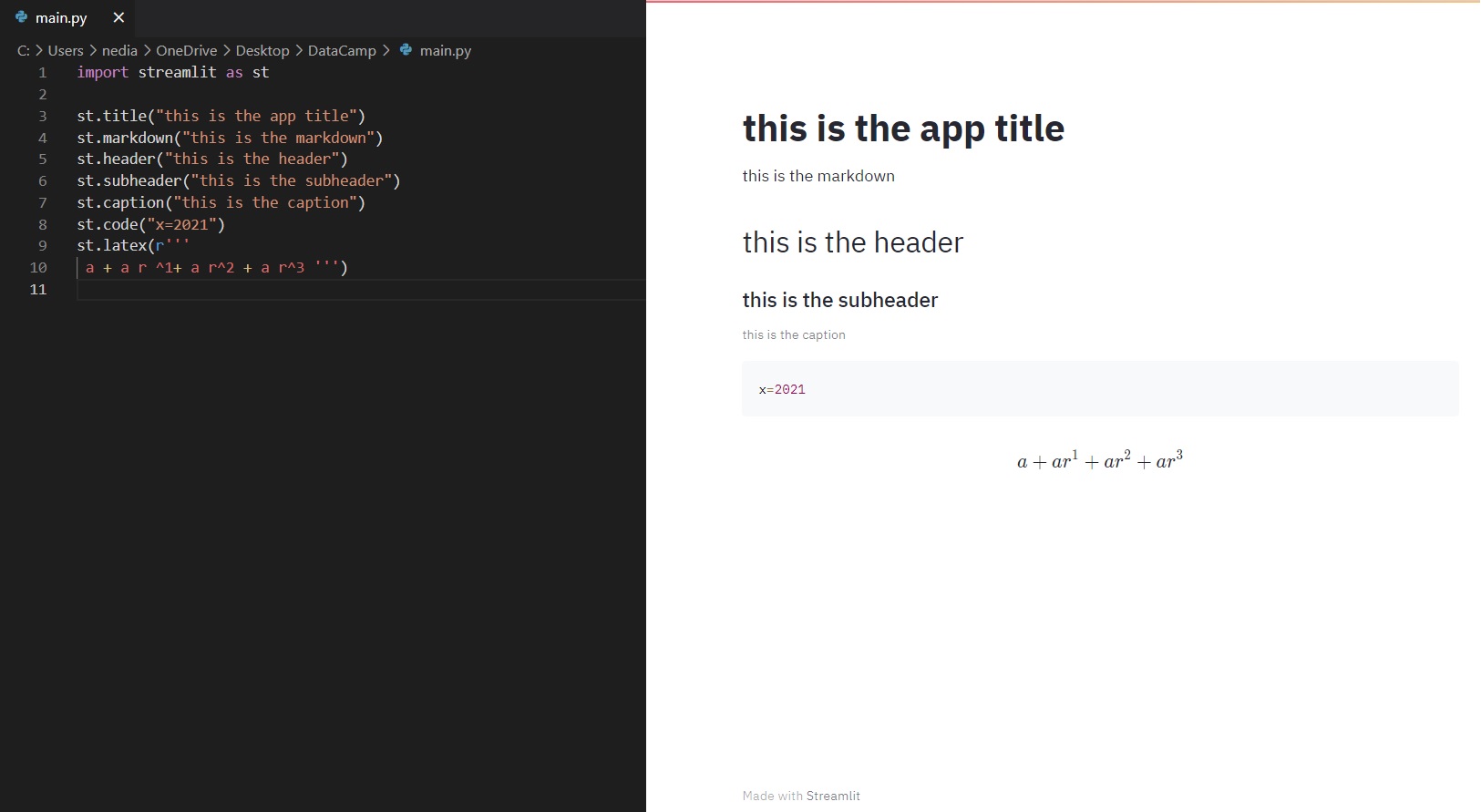
È difficile trovare funzioni facili come quelle di Streamlit per mostrare immagini, video e file audio. Vediamo come visualizzare i media con Streamlit!
st.image(): mostra un'immagine. st.audio(): mostra un audio. st.video(): mostra un video.
st.image("kid.jpg", caption="A kid playing")st.audio("audio.mp3")st.video("video.mp4")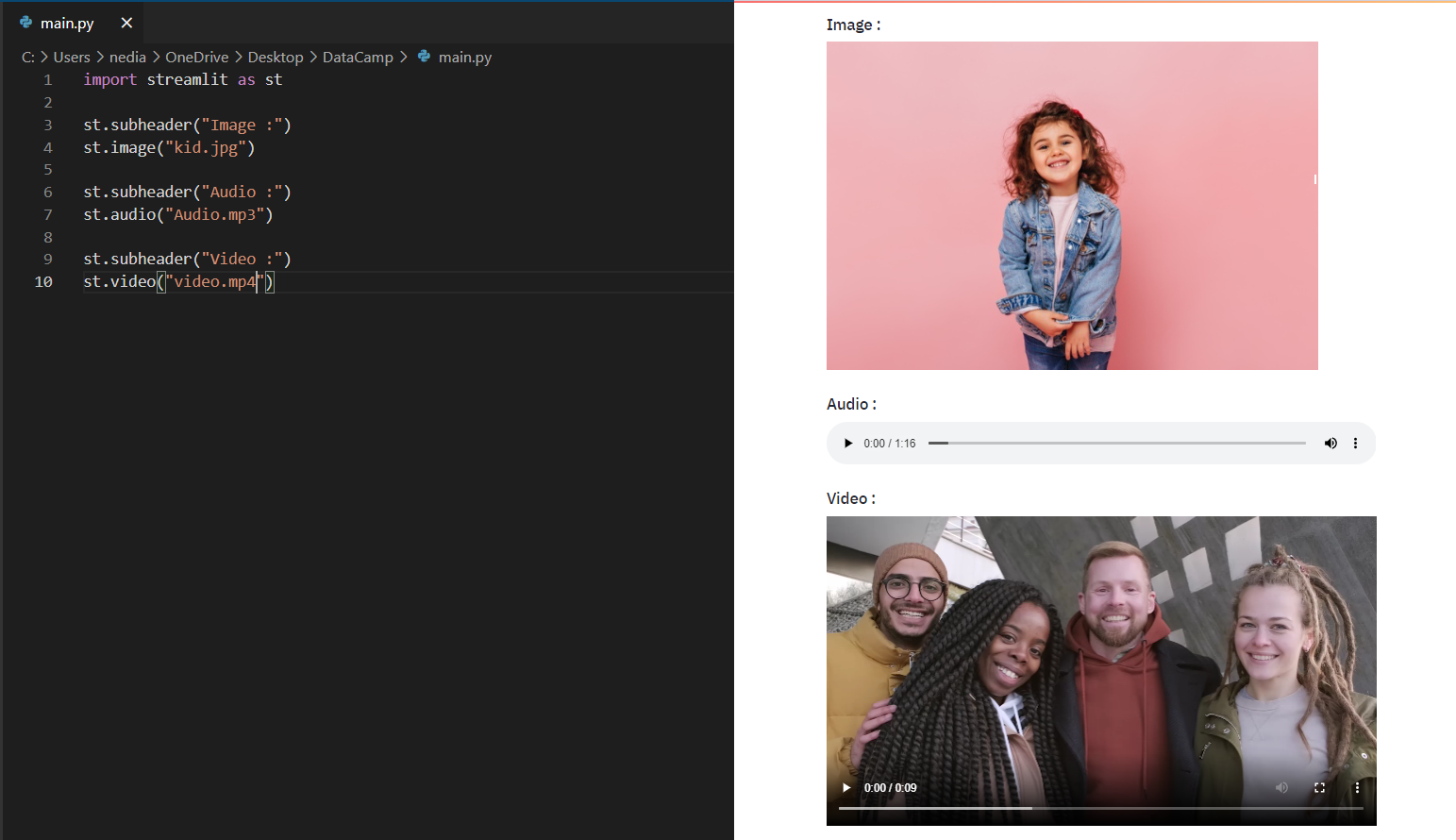
I widget sono i componenti più importanti dell'interfaccia utente. Streamlit ha vari widget che ti permettono di integrare l'interattività direttamente nelle tue app con pulsanti, slider, campi di testo e altro.
st.checkbox(): restituisce un valore booleano. Quando la casella è selezionata, restituisce True, altrimenti False. st.button(): mostra un pulsante. st.radio(): mostra un gruppo di radio button. st.selectbox(): mostra un menu a selezione singola. st.multiselect(): mostra un selettore multiplo. st.select_slider(): mostra uno slider a selezione. st.slider(): mostra uno slider.
st.checkbox('Yes')st.button('Click Me')st.radio('Pick your gender', ['Male', 'Female'])st.selectbox('Pick a fruit', ['Apple', 'Banana', 'Orange'])st.multiselect('Choose a planet', ['Jupiter', 'Mars', 'Neptune'])st.select_slider('Pick a mark', ['Bad', 'Good', 'Excellent'])st.slider('Pick a number', 0, 50)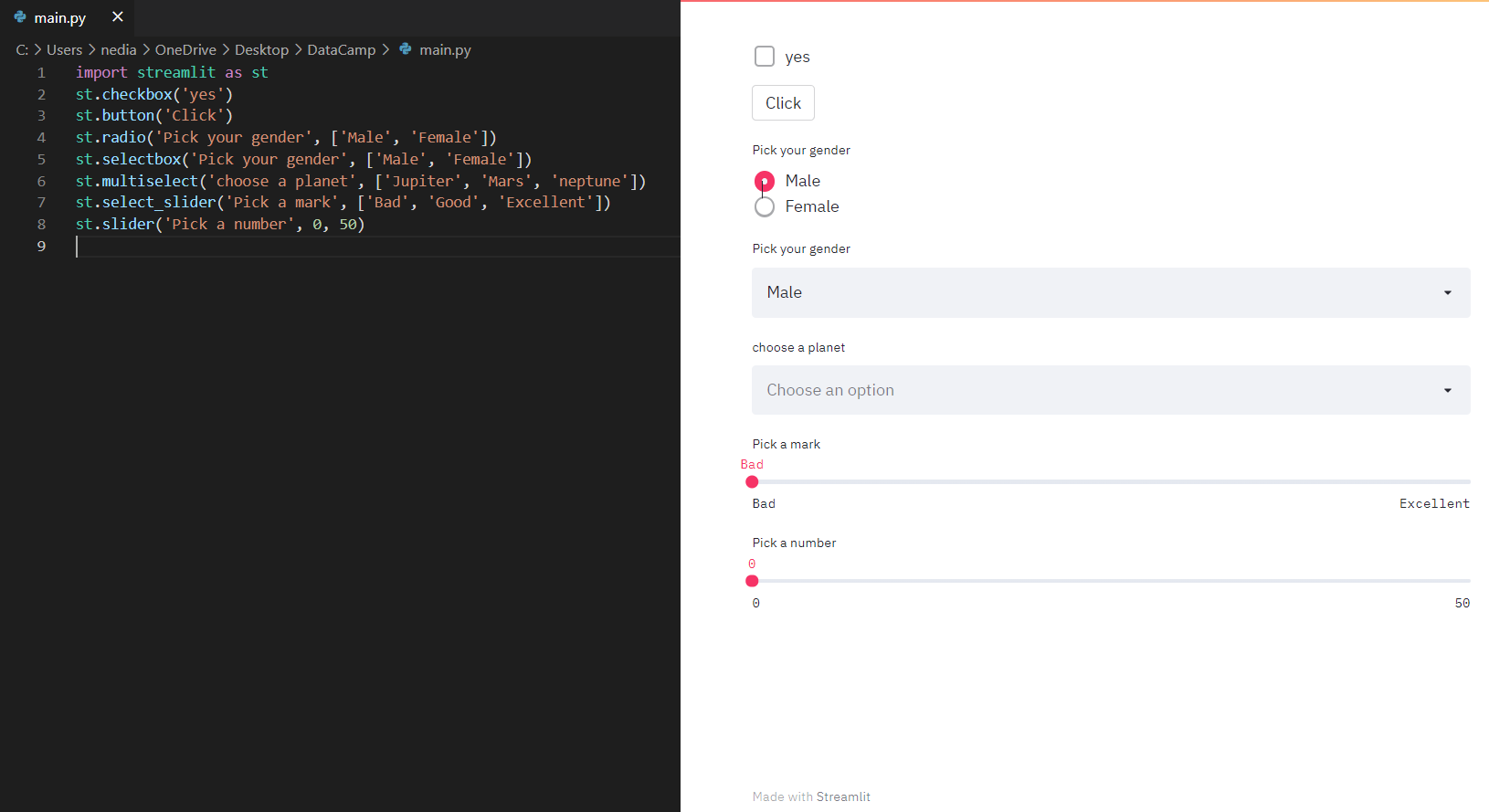
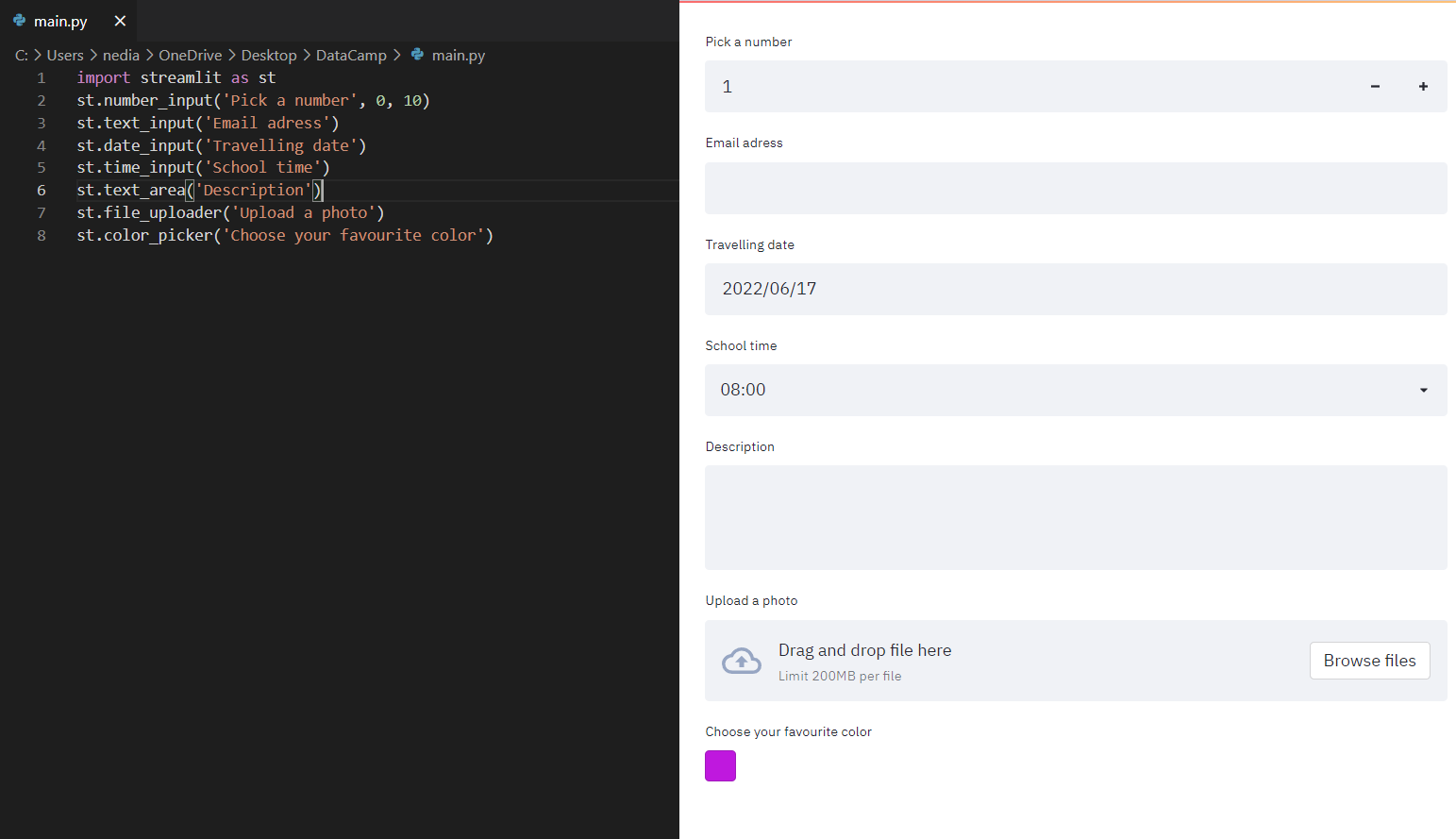
st.number_input(): mostra un input numerico. st.text_input(): mostra un input testuale. st.date_input(): mostra un selettore di data. st.time_input(): mostra un selettore di orario. st.text_area(): mostra un campo di testo multi-riga. st.file_uploader(): mostra un caricatore di file. st.color_picker(): mostra un selettore di colore.
st.number_input('Pick a number', 0, 10)st.text_input('Email address')st.date_input('Traveling date')st.time_input('School time')st.text_area('Description')st.file_uploader('Upload a photo')st.color_picker('Choose your favorite color')t
Ora vediamo come aggiungere una barra di avanzamento e messaggi di stato come errore e successo alla nostra app.
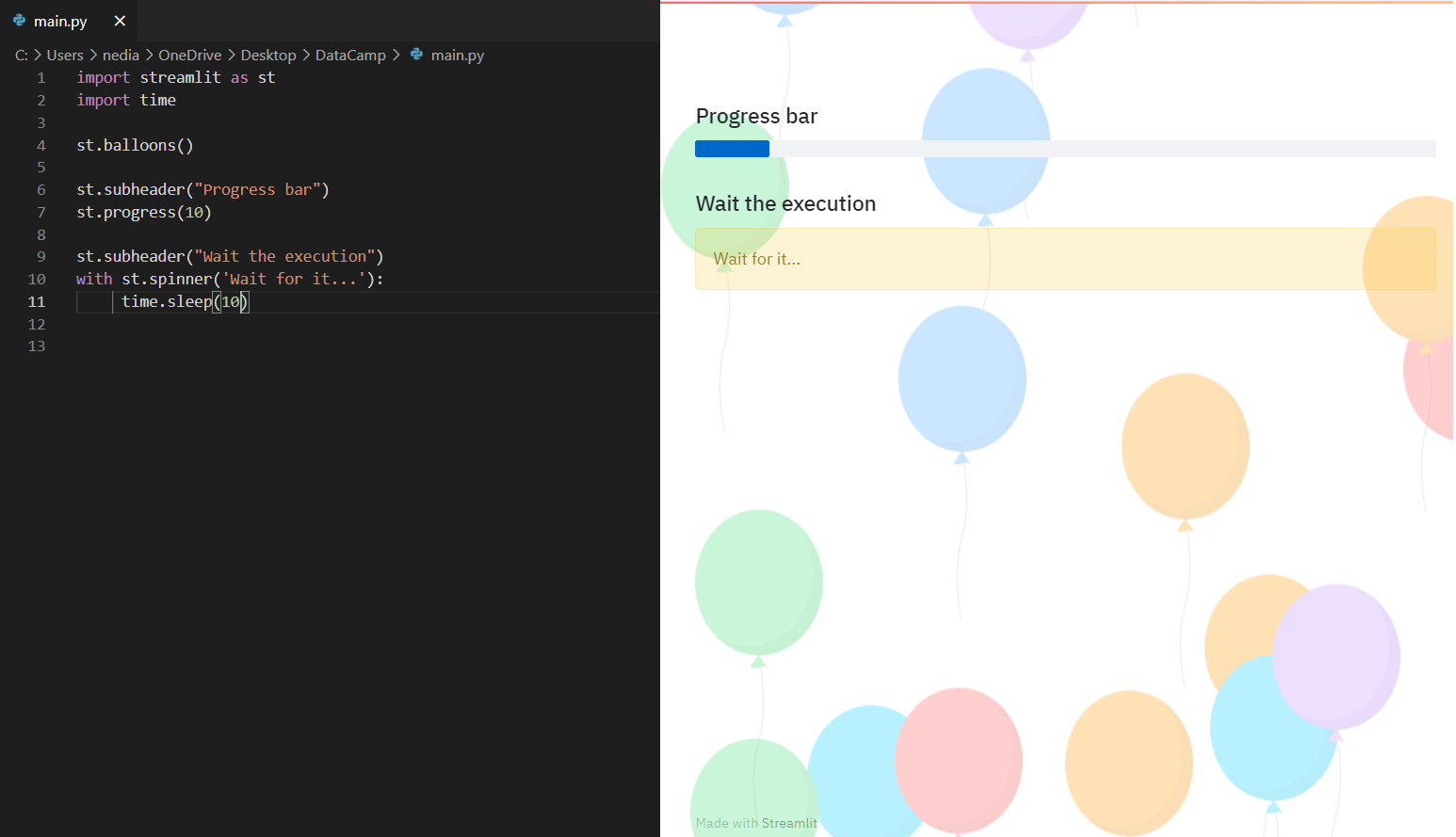
st.balloons(): visualizza palloncini per celebrare. st.progress(): visualizza una barra di avanzamento. st.spinner(): mostra un messaggio di attesa temporaneo durante l'esecuzione.
st.balloons() # Celebration balloonsst.progress(10) # Progress barwith st.spinner('Wait for it...'): time.sleep(10) # Simulating a process delayst.success(): mostra un messaggio di successo. st.error(): mostra un messaggio di errore. st.warning(): mostra un avviso. st.info(): mostra un messaggio informativo. st.exception(): mostra un'eccezione.
st.success("You did it!")st.error("Error occurred")st.warning("This is a warning")st.info("It's easy to build a Streamlit app")st.exception(RuntimeError("RuntimeError exception"))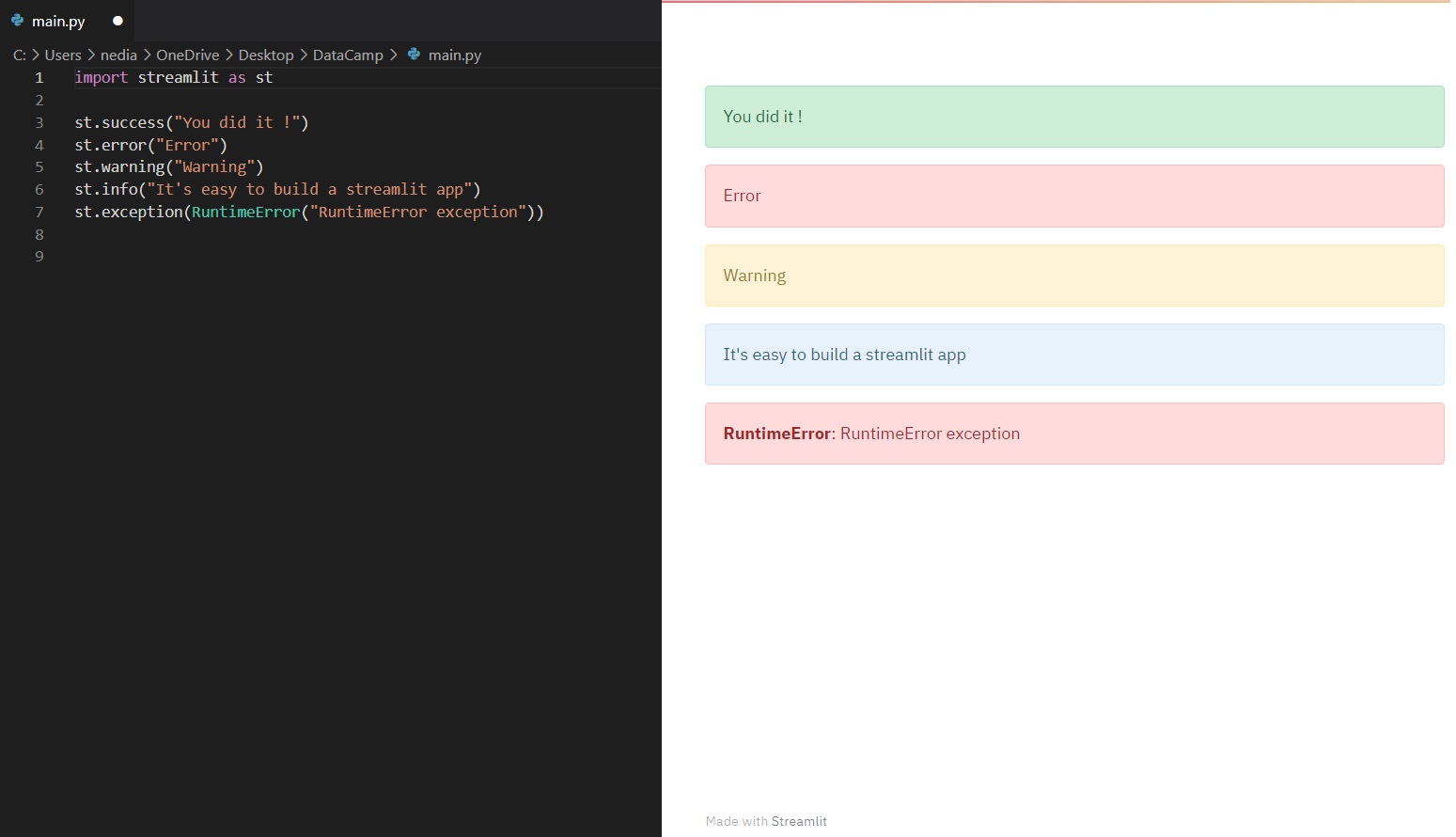
Puoi anche creare una barra laterale o un container nella tua pagina per organizzare l'app. La gerarchia e l'organizzazione delle pagine nella tua app possono avere un forte impatto sull'esperienza utente. Organizzando i contenuti, permetti ai visitatori di capire e navigare il sito, aiutandoli a trovare ciò che cercano e aumentando la probabilità che tornino in futuro.
Passare un elemento a st.sidebar() farà sì che l'elemento venga fissato a sinistra, consentendo agli utenti di concentrarsi sui contenuti della tua app.
Tuttavia, st.spinner() e st.echo() non sono supportati con st.sidebar.
Come vedi, puoi creare una barra laterale nell'interfaccia della tua app e inserirvi elementi che renderanno l'app più organizzata e facile da comprendere.
st.sidebar.title("Sidebar Title")st.sidebar.markdown("This is the sidebar content")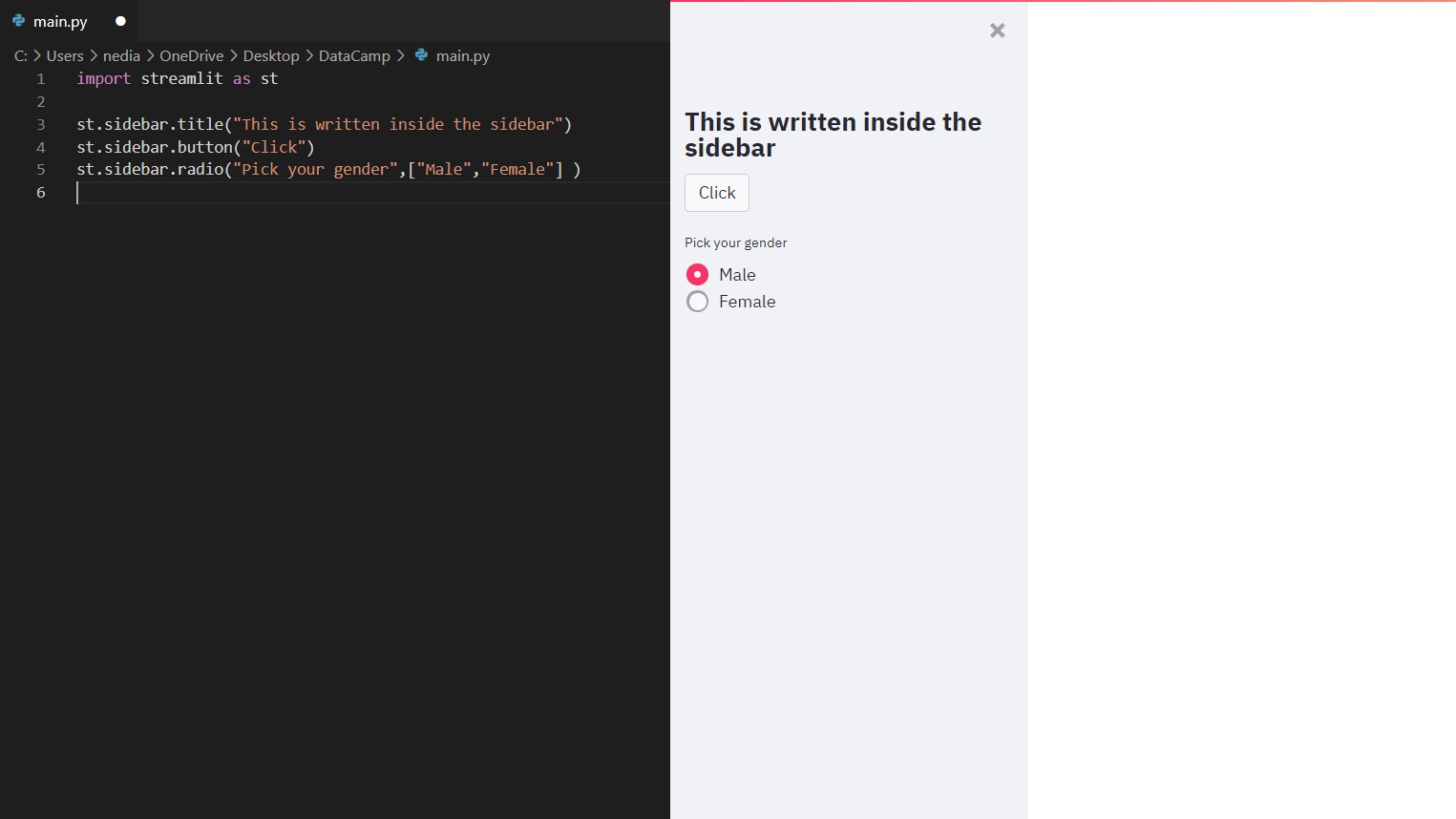
st.container() serve per creare un container invisibile in cui inserire elementi allo scopo di creare una disposizione e una gerarchia utili.
with st.container(): st.write("This is inside the container")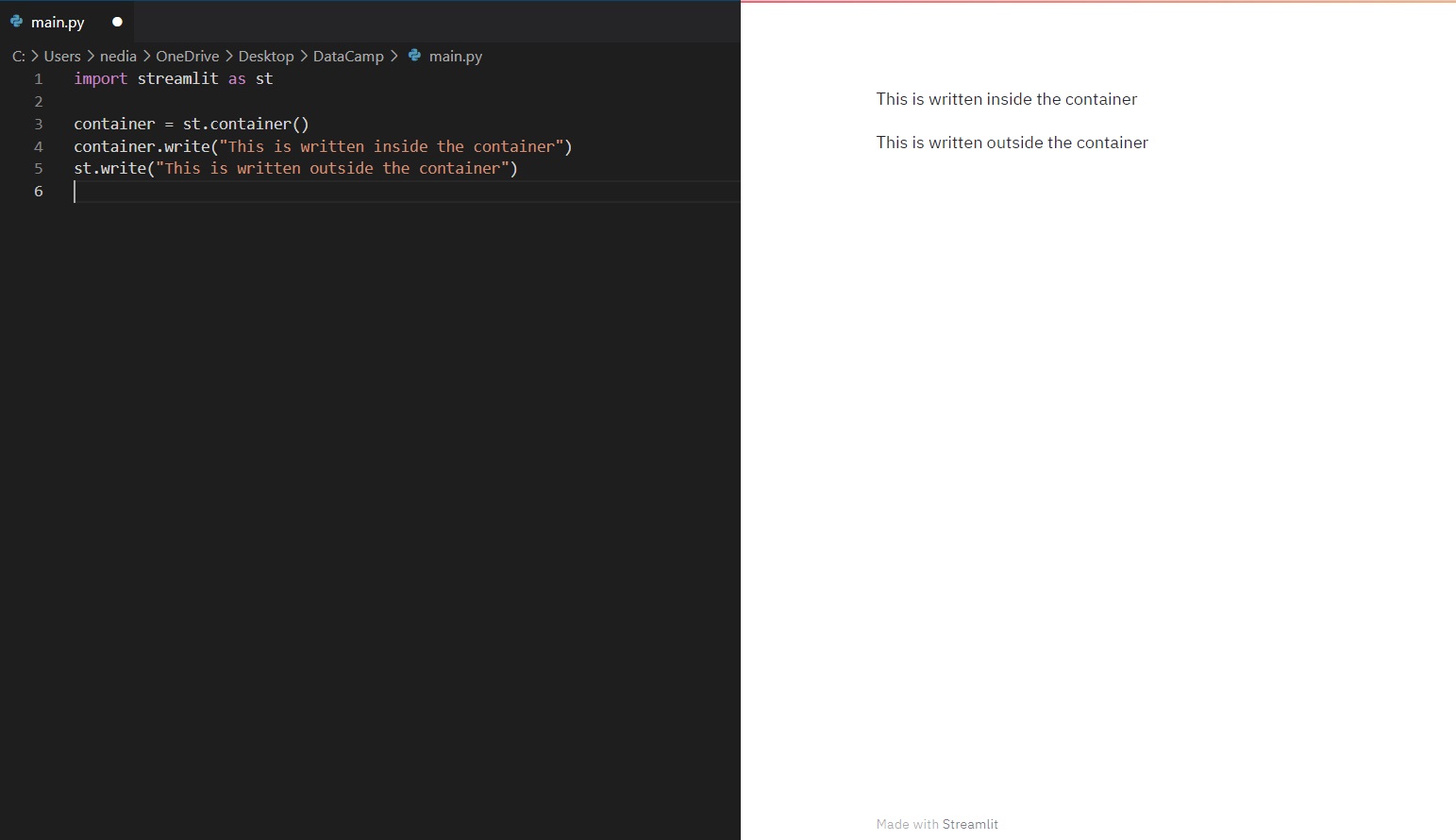
StreamlitStreamlit si integra con le principali librerie di visualizzazione Python. Ecco le funzioni di charting disponibili di default:
st.pyplot(): mostra una figura matplotlib.pyplot.
import streamlit as stimport matplotlib.pyplot as pltimport numpy as nprand = np.random.normal(1, 2, size=20)fig, ax = plt.subplots()ax.hist(rand, bins=15)st.pyplot(fig)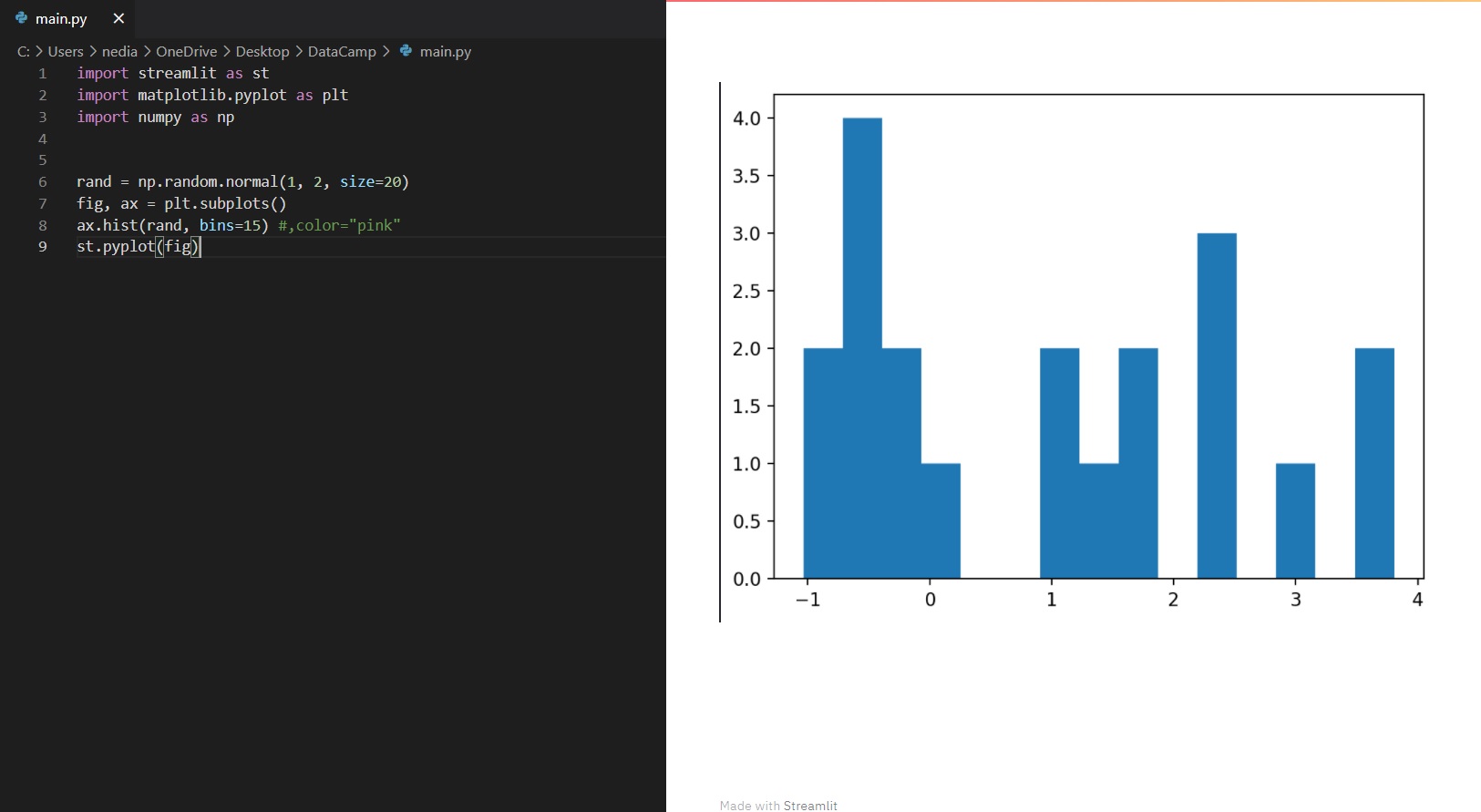
st.line_chart(): mostra un grafico a linee.
import streamlit as stimport pandas as pdimport numpy as npdf = pd.DataFrame(np.random.randn(10, 2), columns=['x', 'y'])st.line_chart(df)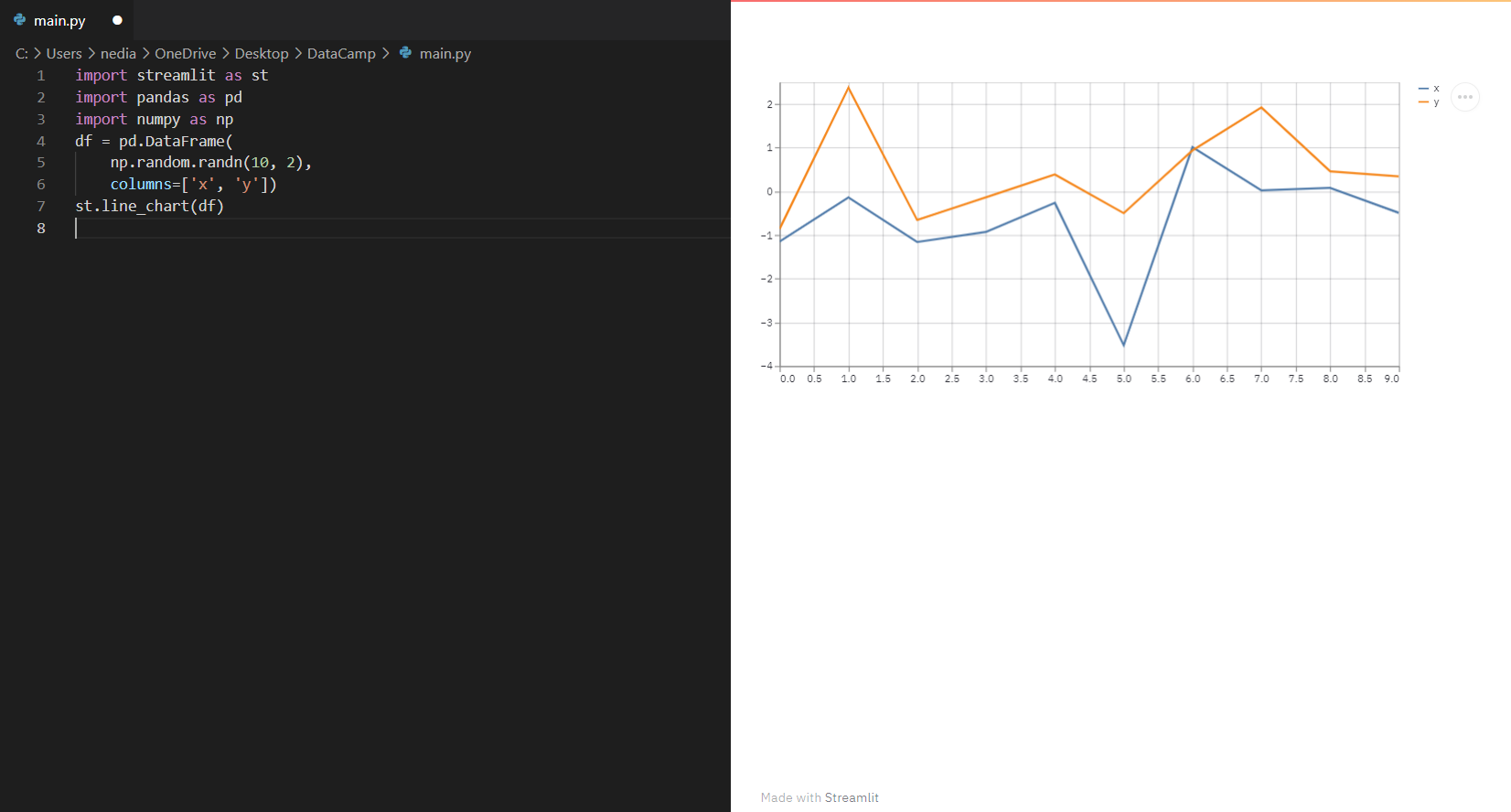
st.bar_chart(): mostra un grafico a barre.
import streamlit as stimport pandas as pdimport numpy as npdf = pd.DataFrame(np.random.randn(10, 2), columns=['x', 'y'])st.bar_chart(df)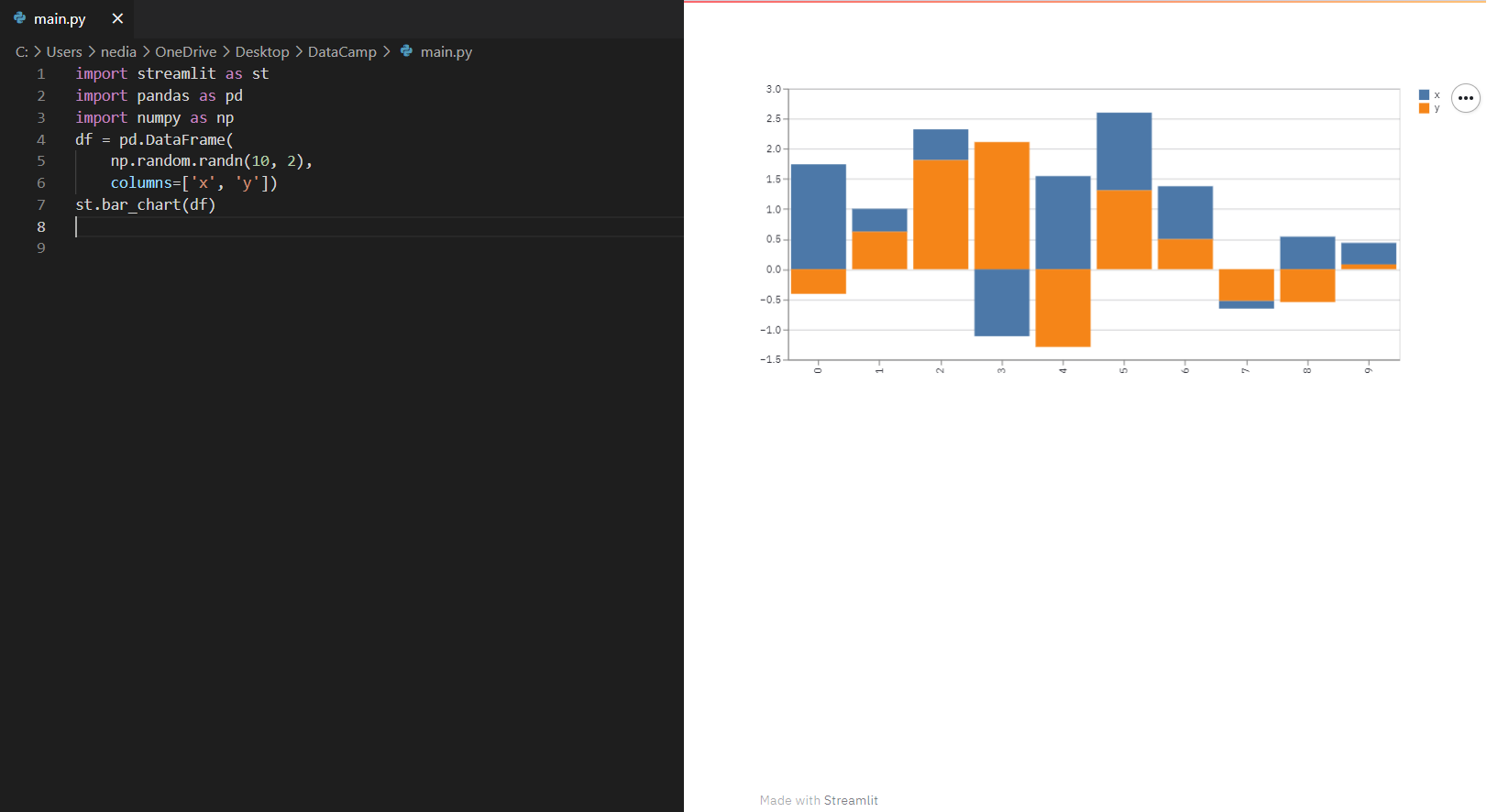
st.area_chart(): mostra un grafico ad area.
import streamlit as stimport pandas as pdimport numpy as npdf = pd.DataFrame(np.random.randn(10, 2), columns=['x', 'y'])st.area_chart(df)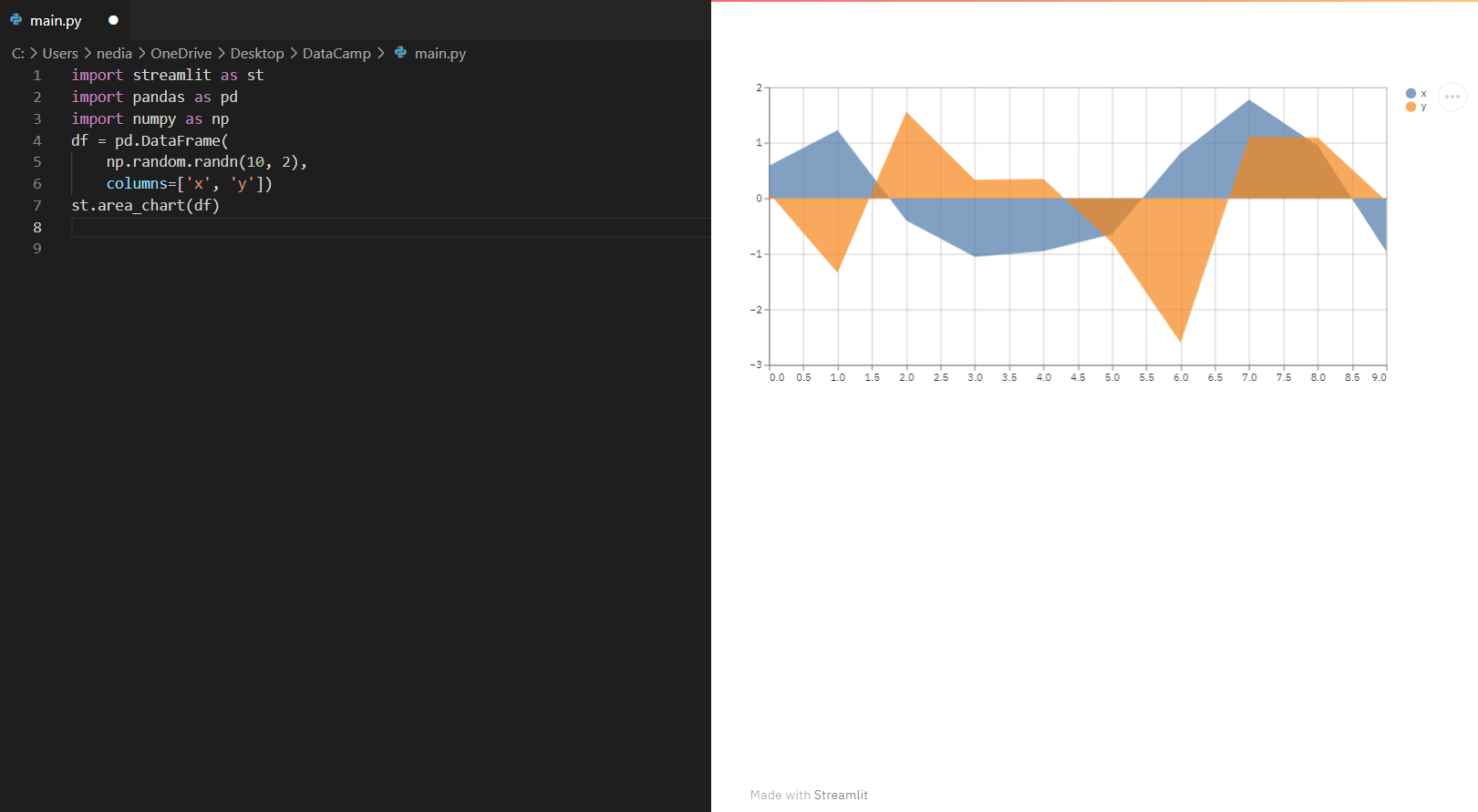
st.altair_chart(): mostra un grafico Altair.
import streamlit as stimport pandas as pdimport numpy as npimport altair as altdf = pd.DataFrame(np.random.randn(500, 3), columns=['x', 'y', 'z'])chart = alt.Chart(df).mark_circle().encode( x='x', y='y', size='z', color='z', tooltip=['x', 'y', 'z'])st.altair_chart(chart, use_container_width=True)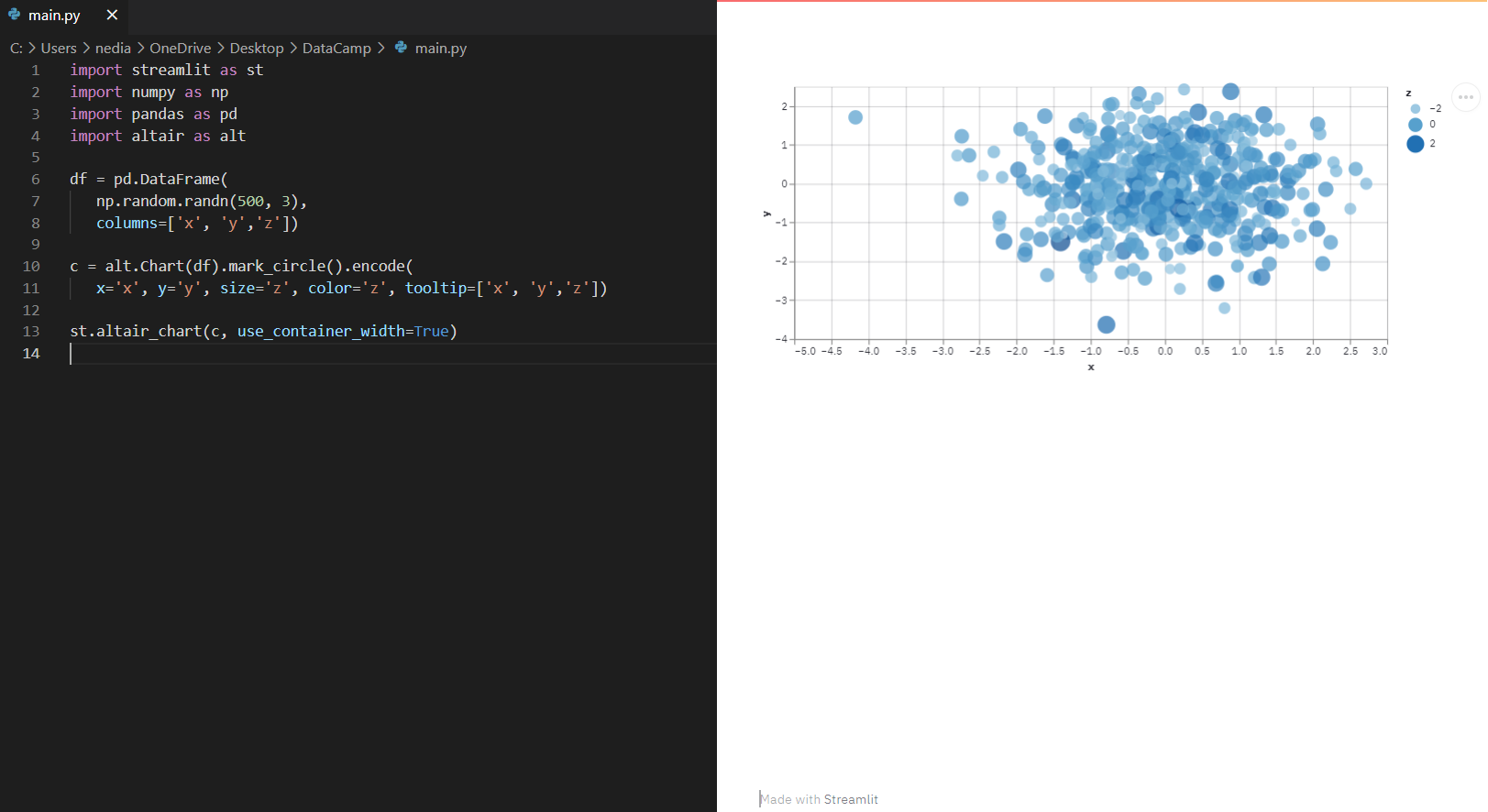
st.graphviz_chart(): mostra oggetti grafici, che possono essere composti con diversi nodi e archi.
import streamlit as stimport graphvizst.graphviz_chart(''' digraph { Big_shark -> Tuna Tuna -> Mackerel Mackerel -> Small_fishes Small_fishes -> Shrimp }''')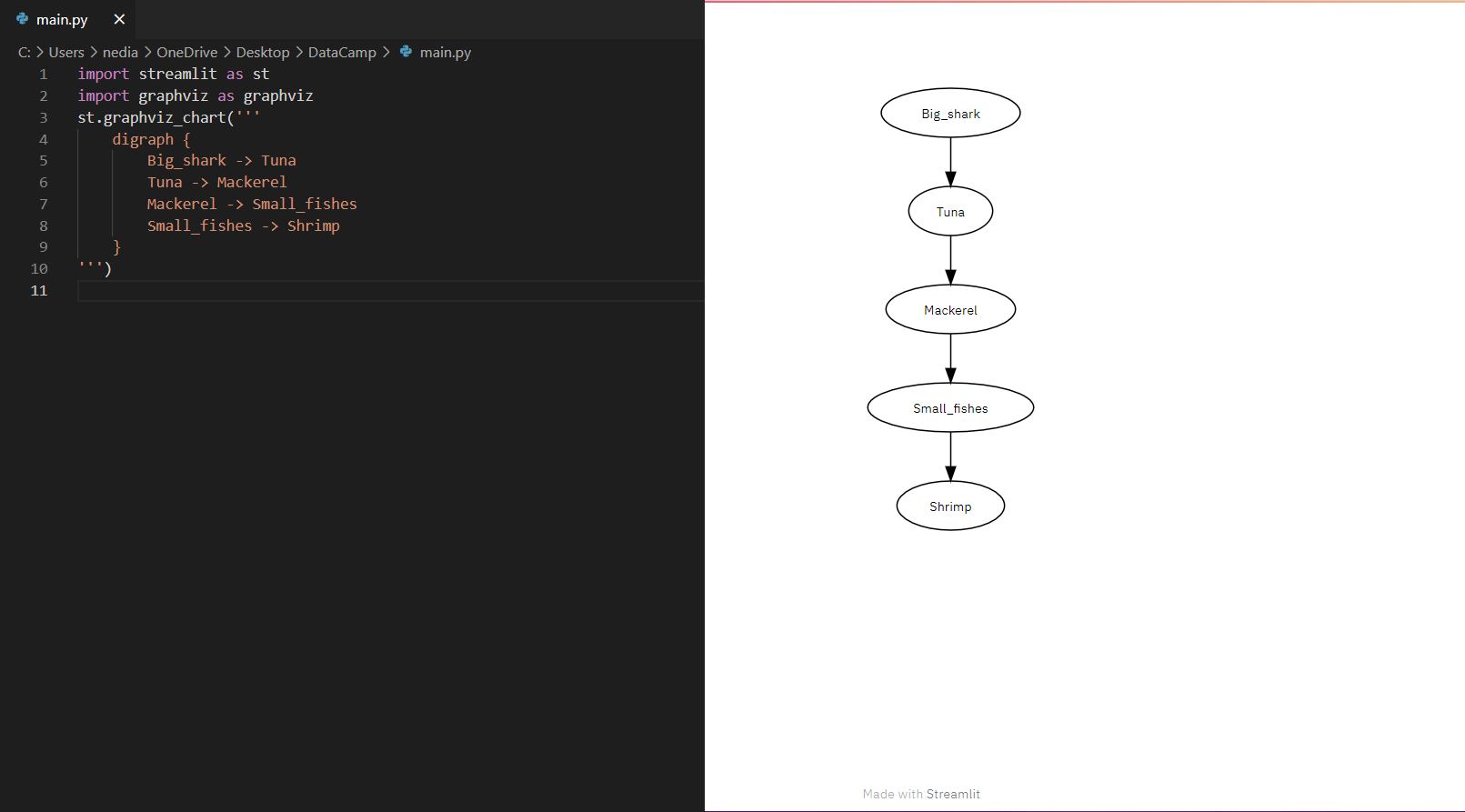
st.map(): mostra mappe nell'app. Richiede però i valori di latitudine e longitudine, che non devono essere nulli/NA.
import pandas as pdimport numpy as npimport streamlit as stdf = pd.DataFrame( np.random.randn(500, 2) / [50, 50] + [37.76, -122.4], columns=['lat', 'lon'])st.map(df)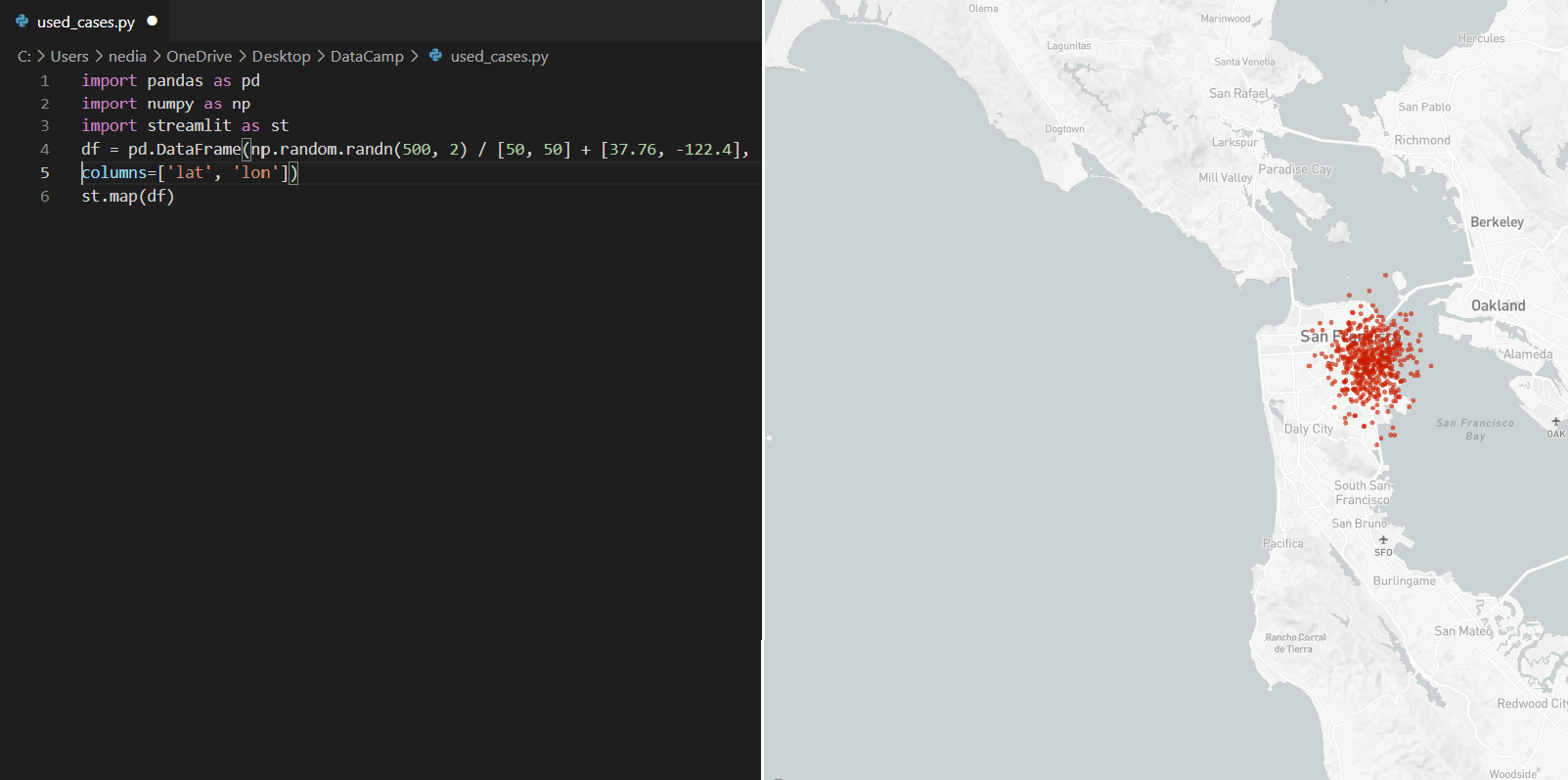
Puoi anche scegliere un tema che rispecchi il tuo stile. Segui i passaggi nella GIF qui sotto:

E se ti interessa approfondire lo stile e i temi, dai un'occhiata a Theming.
Ora è il momento di costruire insieme un'app!
In questa sezione ti guiderò in un progetto che ho realizzato sulla previsione dei prestiti.
Il principale profitto dei prestiti deriva direttamente dagli interessi. Le società di prestito concedono un prestito dopo un intenso processo di verifica e validazione. Tuttavia, non hanno comunque la certezza che il richiedente sia in grado di rimborsare il prestito senza difficoltà. In questo tutorial, costruiremo un modello predittivo (Random Forest Classifier) per prevedere lo stato del prestito di un richiedente. La nostra missione è preparare una web app per renderla disponibile in produzione.
Partiamo importando le librerie necessarie per la nostra app:
import streamlit as stimport pandas as pdimport numpy as npimport pickle # to load a saved modelimport base64 # to handle gif encodingIn questa app useremo più widget come slider: selectbox e radio nel menu laterale, per cui prepareremo alcune funzioni Python. L'esempio sarà una semplice demo con due pagine. Nella homepage mostrerà i dati che abbiamo selezionato, mentre la pagina Exploration ti permetterà di visualizzare variabili in grafici, e la pagina Prediction conterrà variabili con un pulsante chiamato Predict che ti permetterà di stimare lo stato del prestito. Il codice seguente ti fornisce una selectbox nella barra laterale che ti consente di selezionare una pagina. I dati sono messi in cache in modo da non dover essere ricaricati continuamente.
@st.cache_data è il decorator di caching consigliato (sostituisce il deprecato @st.cache) che mantiene performante la tua app quando carichi dati dal web, manipoli dataset di grandi dimensioni o esegui computazioni costose. Usa @st.cache_data per dati serializzabili come DataFrame e stringhe, e @st.cache_resource per risorse globali come connessioni a database o modelli ML.
@st.cache_datadef get_fvalue(val): feature_dict = {"No": 1, "Yes": 2} return feature_dict[val]def get_value(val, my_dict): return my_dict[val]
Nella pagina Home visualizzeremo: immagine di presentazione / il dataset / istogramma del reddito del richiedente e dell'importo del prestito.
Nota: useremo if/elif/else per passare da una pagina all'altra.
Caricheremo loan_dataset.csv nella variabile data che ci permetterà di mostrarne alcune righe nella pagina Home.
if app_mode == 'Home': st.title('Loan Prediction') st.image('loan_image.jpg') st.markdown('Dataset:') data = pd.read_csv('loan_dataset.csv') st.write(data.head()) st.bar_chart(data[['ApplicantIncome', 'LoanAmount']].head(20))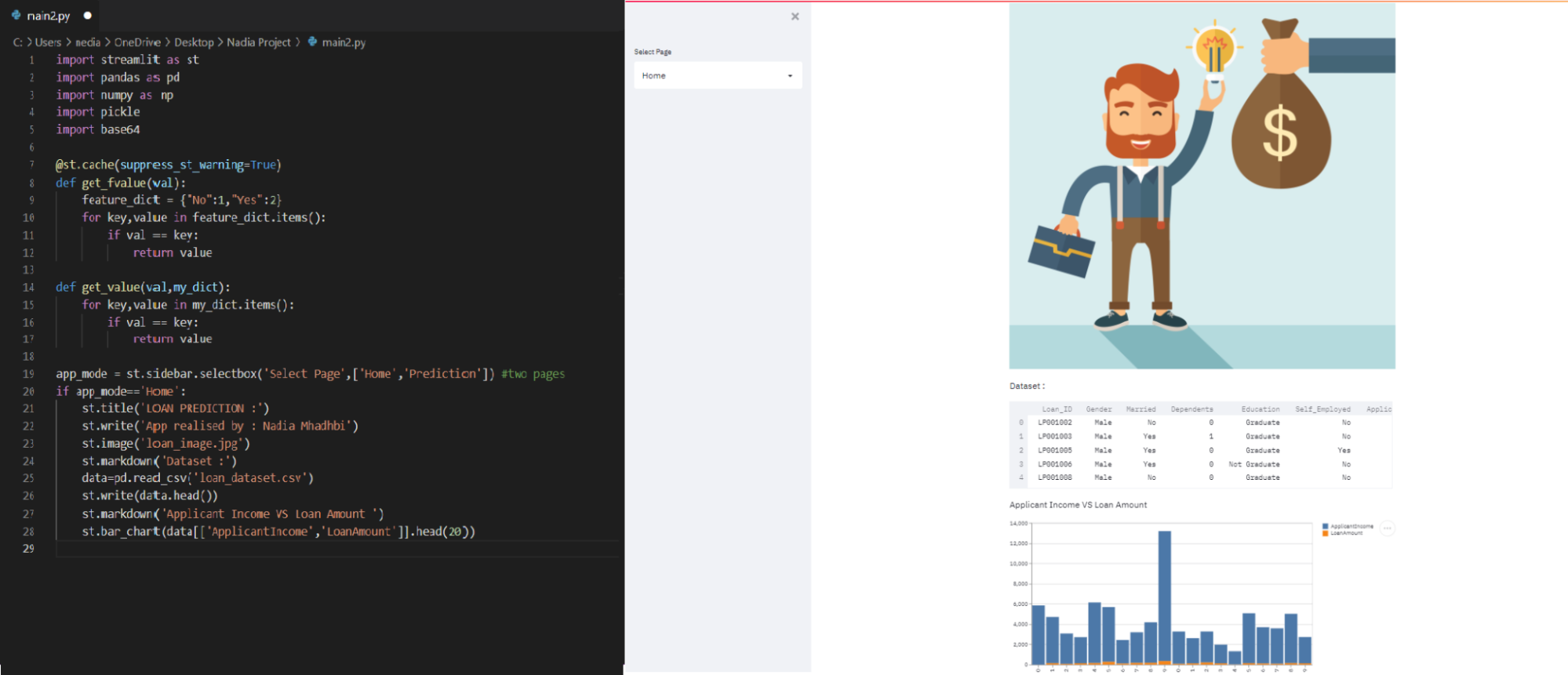
Poi nella pagina Prediction:
if app_mode == 'Prediction': ApplicantIncome = st.sidebar.slider('ApplicantIncome', 0, 10000, 0) LoanAmount = st.sidebar.slider('LoanAmount in K$', 9.0, 700.0, 200.0) # Assuming additional input features here... # Prediction Logic if st.button("Predict"): loaded_model = pickle.load(open('Random_Forest.sav', 'rb')) prediction = loaded_model.predict(np.array([ApplicantIncome, LoanAmount]).reshape(1, -1)) if prediction[0] == 0: st.error('According to our calculations, you will not get the loan.') else: st.success('Congratulations! You will get the loan.')Abbiamo scritto due funzioni get_value(val,my_dict) e get_fvalue(val) e dei dizionari come feature_dict per gestire st.sidebar.radio() con variabili non numeriche. È opzionale, puoi facilmente fare qualcosa di simile:

Vediamo perché lo abbiamo fatto.
Nota: gli algoritmi di machine learning non gestiscono le variabili categoriche. Nel dataset ho fatto del feature engineering. Per esempio, la colonna Married ha due valori “Yes” e “No” e ho fatto un Label Encoding (dai un'occhiata per capire meglio) quindi "NO" sarà uguale a 1 e "Yes" a 2. La funzione get_fvalue(val) restituirà facilmente il valore (1/2) a seconda di ciò che ha scelto l'utente. Stesso discorso per la funzione get_value(val,my_dict). La differenza tra le due funzioni è che la prima lavora su caratteristiche sì/no e la seconda è il caso generale quando abbiamo più variabili (esempio: Gender).
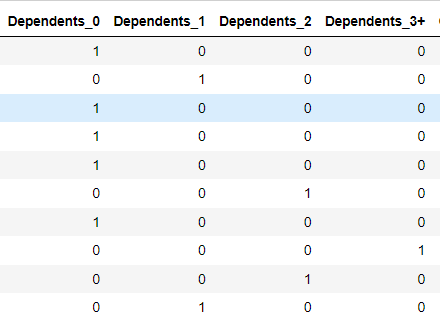
Come possiamo vedere, la variabile Dependents ha quattro categorie '0','1', '2' e '3+' e non possiamo convertire qualcosa del genere in una variabile numerica, e abbiamo '+3' che significa che Dependents può valere 3,4,5 ... Abbiamo fatto una One Hot Encoding (dai un'occhiata per capire meglio). Così abbiamo creato una radio nella sidebar contenente i quattro elementi e ognuno ha una variabile binaria: se l'utente sceglie '0' class_0 sarà uguale a 1 e le altre saranno uguali a 0.
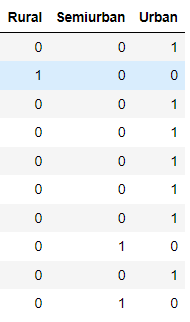
Abbiamo fatto anche la One Hot Encoding per Property_Area ed è per questo che abbiamo creato 3 variabili (Rural,Urban,Semiurban). Quando Rural vale 1, le altre saranno uguali a 0.
Quindi abbiamo visto entrambi i casi—quando facciamo label o one hot encoding delle nostre feature—e come gestirli per creare con successo un'app Streamlit funzionante.
data1={ 'Gender':Gender, 'Married':Married, 'Dependents':[class_0,class_1,class_2,class_3], 'Education':Education, 'ApplicantIncome':ApplicantIncome, 'CoapplicantIncome':CoapplicantIncome, 'Self Employed':Self_Employed, 'LoanAmount':LoanAmount, 'Loan_Amount_Term':Loan_Amount_Term, 'Credit_History':Credit_History, 'Property_Area':[Rural,Urban,Semiurban], } feature_list=[ApplicantIncome,CoapplicantIncome,LoanAmount,Loan_Amount_Term,Credit_History,get_value(Gender,gender_dict),get_fvalue(Married),data1['Dependents'][0],data1['Dependents'][1],data1['Dependents'][2],data1['Dependents'][3],get_value(Education,edu),get_fvalue(Self_Employed),data1['Property_Area'][0],data1['Property_Area'][1],data1['Property_Area'][2]] single_sample = np.array(feature_list).reshape(1,-1)Ora memorizzeremo le nostre variabili in un dizionario perché abbiamo scritto get_value(val,my_dict) e get_fvalue(val) per lavorare con i dizionari. Dopodiché, l'input—ciò che l'utente sceglierà come input nella nostra app Streamlit—sarà organizzato in una lista chiamata feature_list e poi in una variabile numpy chiamata single_sample.
Nota: gli input delle feature devono essere disposti nello stesso ordine delle colonne del dataset (ad es. Married non può prendere l'input di Gender).
if st.button("Predict"): file_ = open("6m-rain.gif", "rb") contents = file_.read() data_url = base64.b64encode(contents).decode("utf-8") file_.close() file = open("green-cola-no.gif", "rb") contents = file.read() data_url_no = base64.b64encode(contents).decode("utf-8") file.close() loaded_model = pickle.load(open('Random_Forest.sav', 'rb')) prediction = loaded_model.predict(single_sample) if prediction[0] == 0 : st.error( 'According to our Calculations, you will not get the loan from Bank' ) st.markdown( f'<img src="data:image/gif;base64,{data_url_no}" alt="cat gif">', unsafe_allow_html=True,) elif prediction[0] == 1 : st.success( 'Congratulations!! you will get the loan from Bank' ) st.markdown( f'<img src="data:image/gif;base64,{data_url}" alt="cat gif">', unsafe_allow_html=True, )Infine, caricheremo il nostro modello RandomForestClassifier salvato in loaded_model e la sua predizione, che è 0 o 1 (problema di classificazione), in prediction. I file .gif saranno memorizzati in file e file_. A seconda del valore di prediction, avremo due casi, "Success" o "Failed", per ottenere un prestito dalla banca.
Questa è la nostra pagina Prediction:
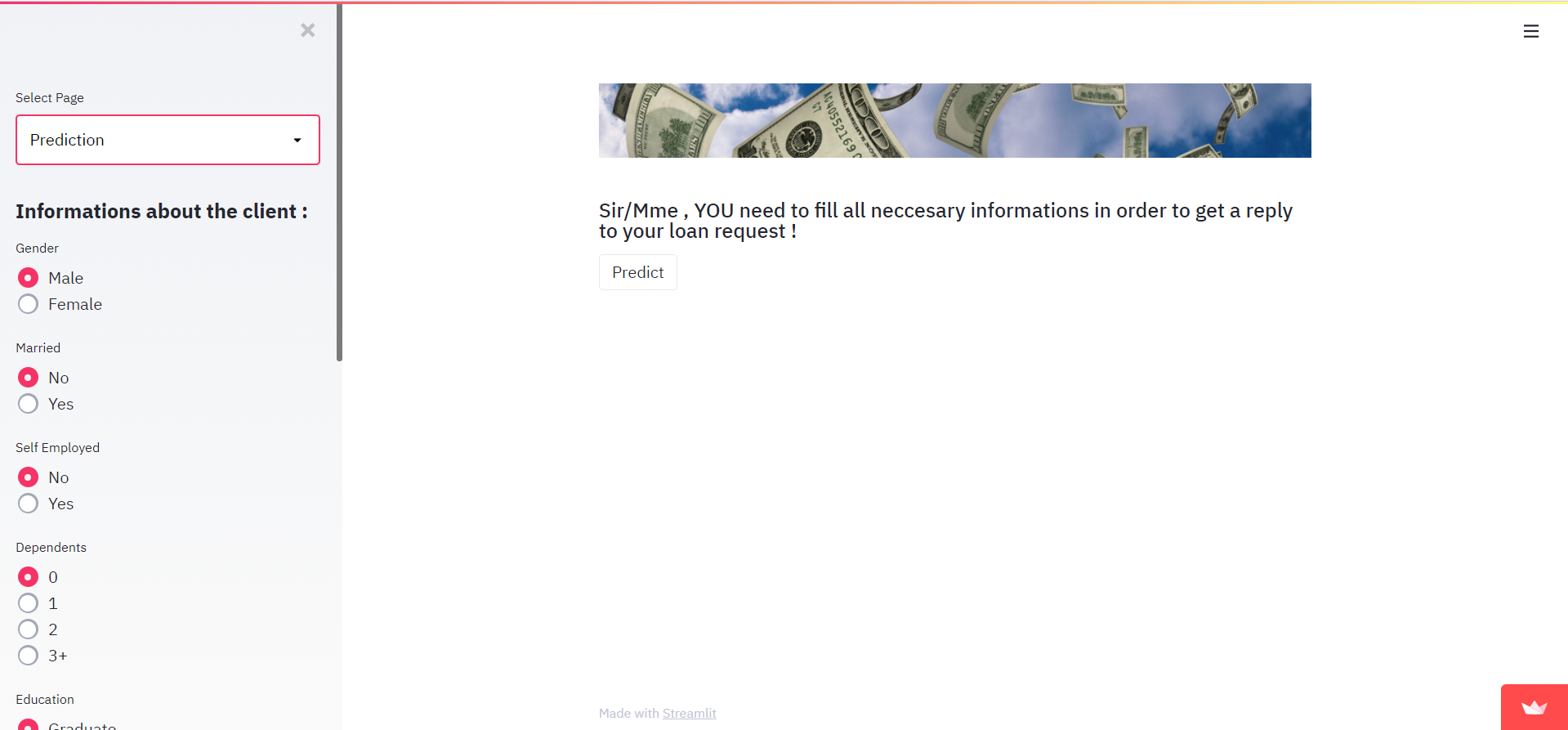
In caso di FALLIMENTO, l'output sarà così:
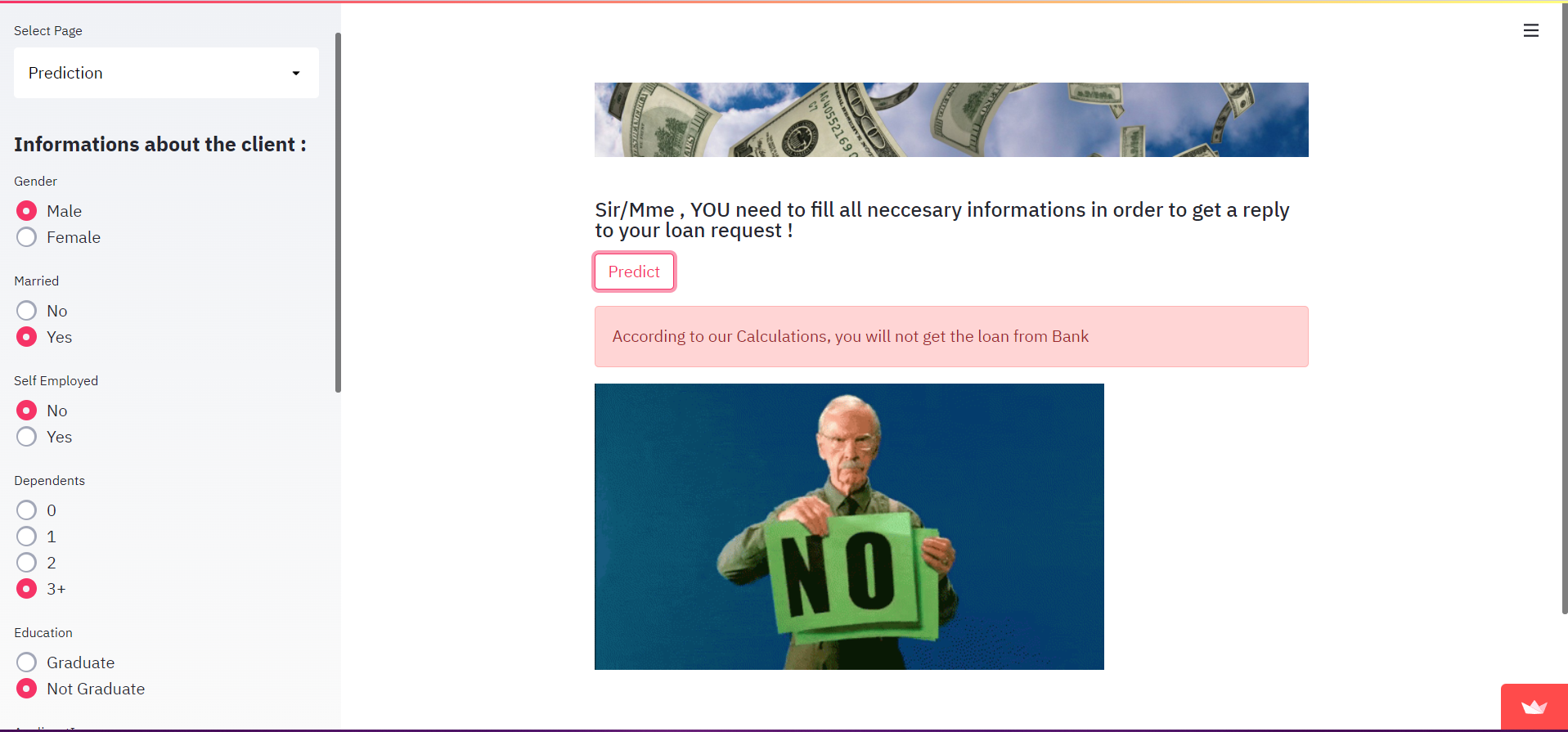
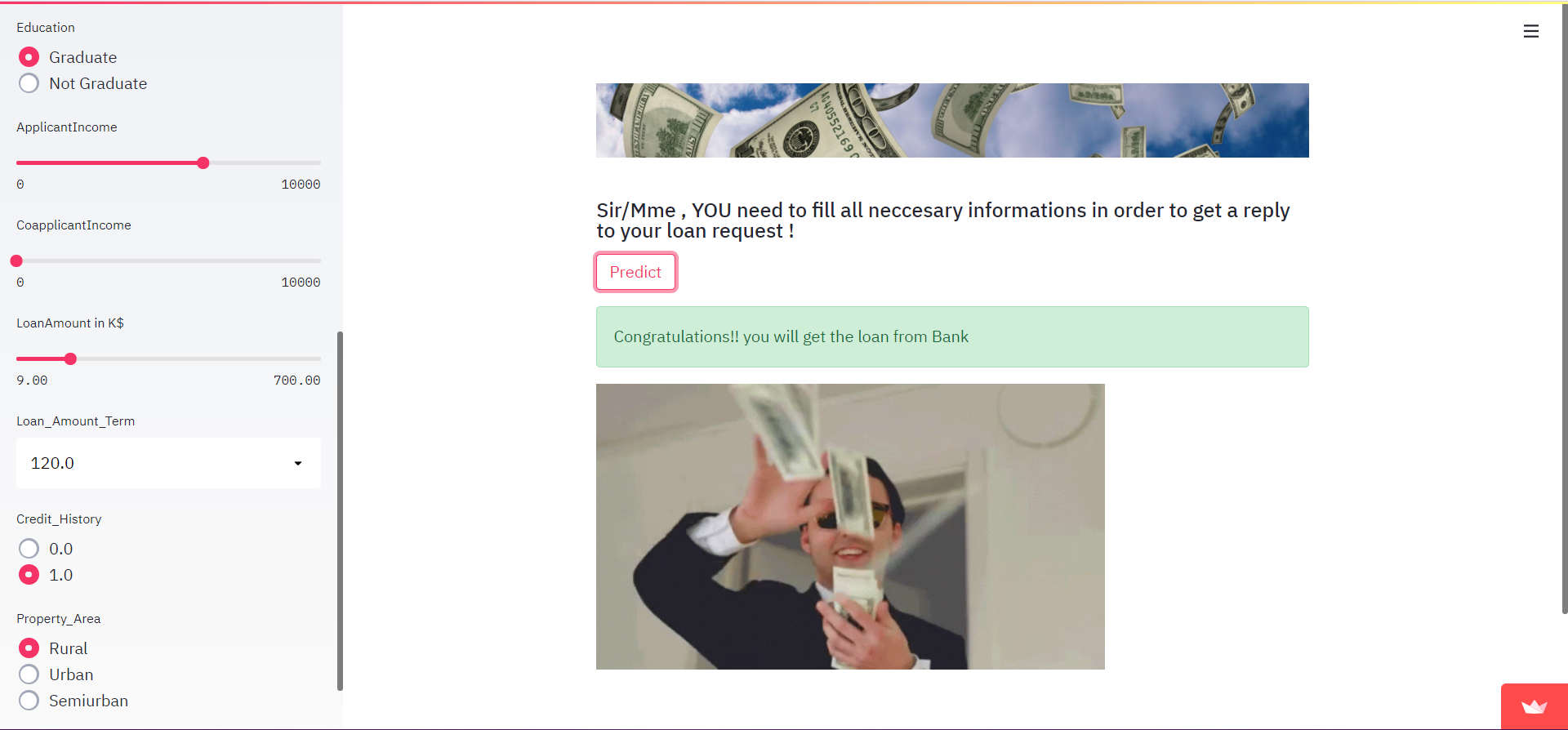
In caso di SUCCESSO, l'output sarà così:
La distribuzione è il meccanismo con cui le applicazioni vengono consegnate dagli sviluppatori agli utenti.
Distribuire un'applicazione è il processo di copia, configurazione e abilitazione di una specifica applicazione su uno specifico URL di base. Una volta terminato il processo di distribuzione, l'applicazione diventa pubblicamente accessibile all'URL di base. Il server esegue questo processo in due fasi: prima effettua lo staging dell'applicazione, poi la attiva dopo lo staging riuscito.
Impariamo come distribuire un'app Streamlit!
Prima di provare a distribuire la tua app, devi creare un nuovo repository su GitHub in cui inserire il codice della tua app e le dipendenze.
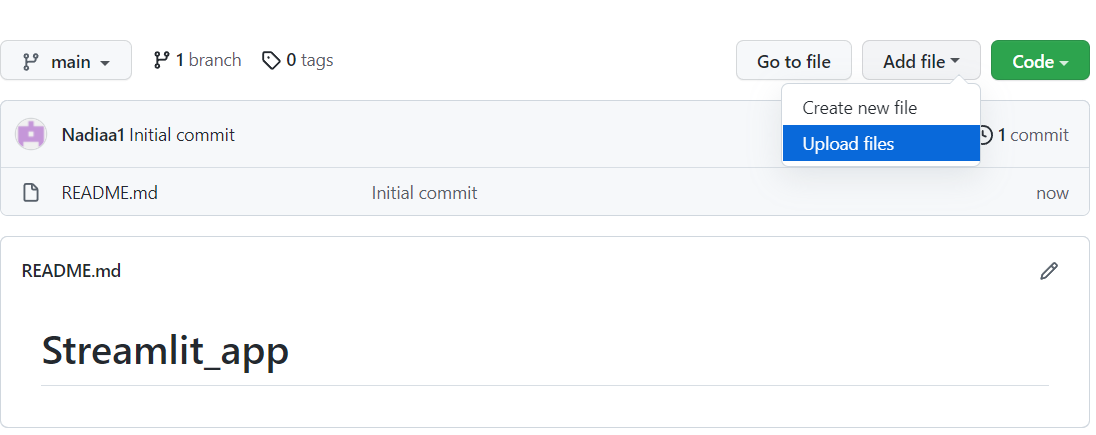
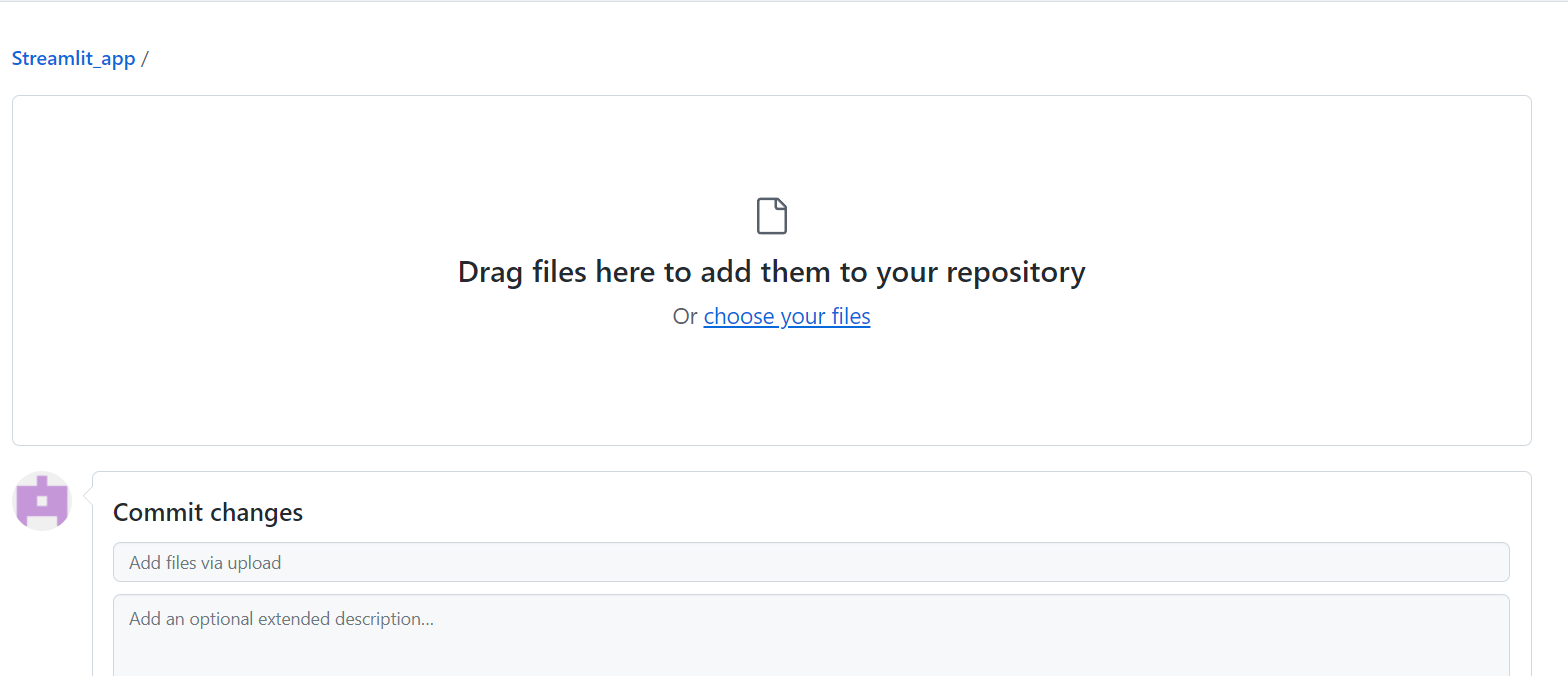
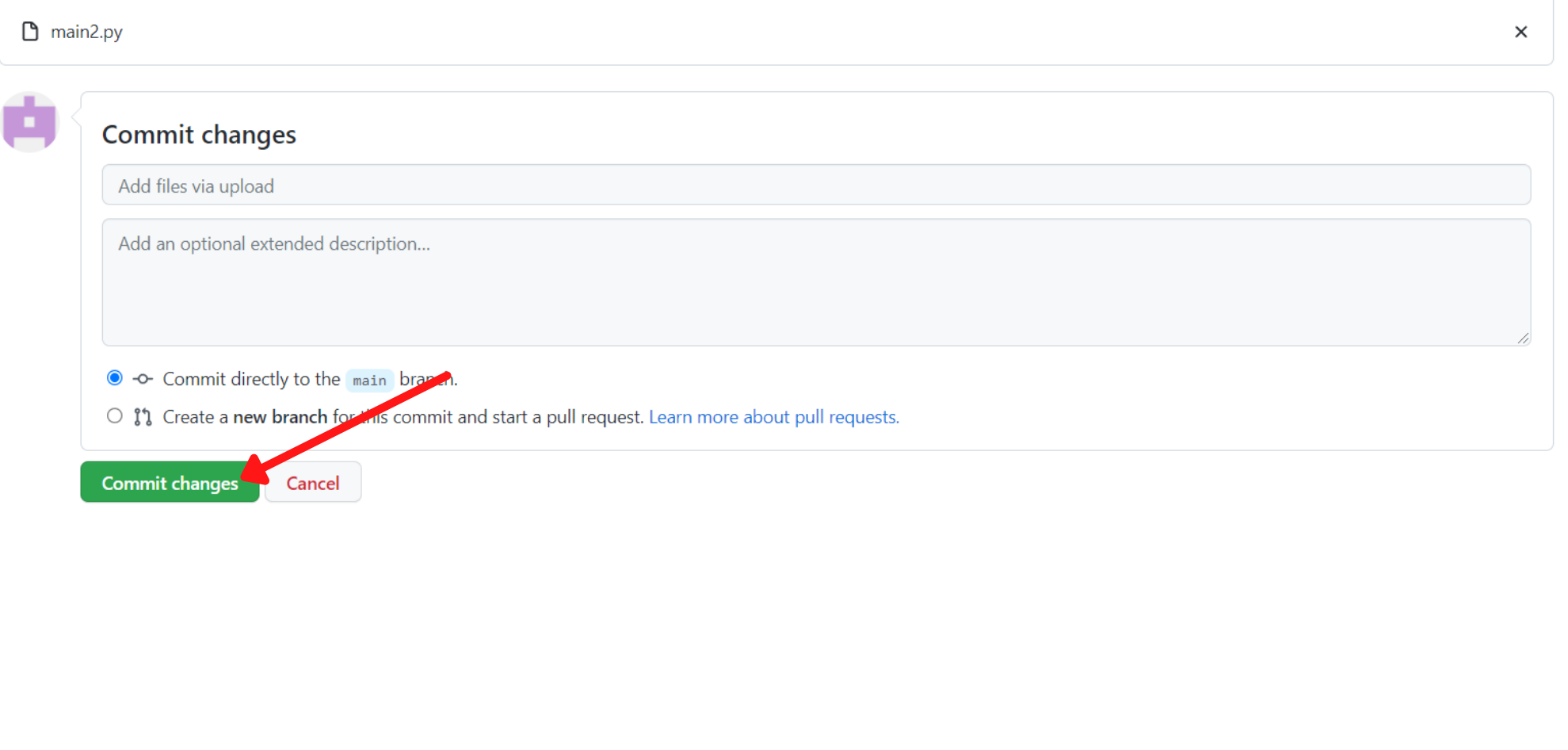
Poi clicca su commit changes per salvarle:
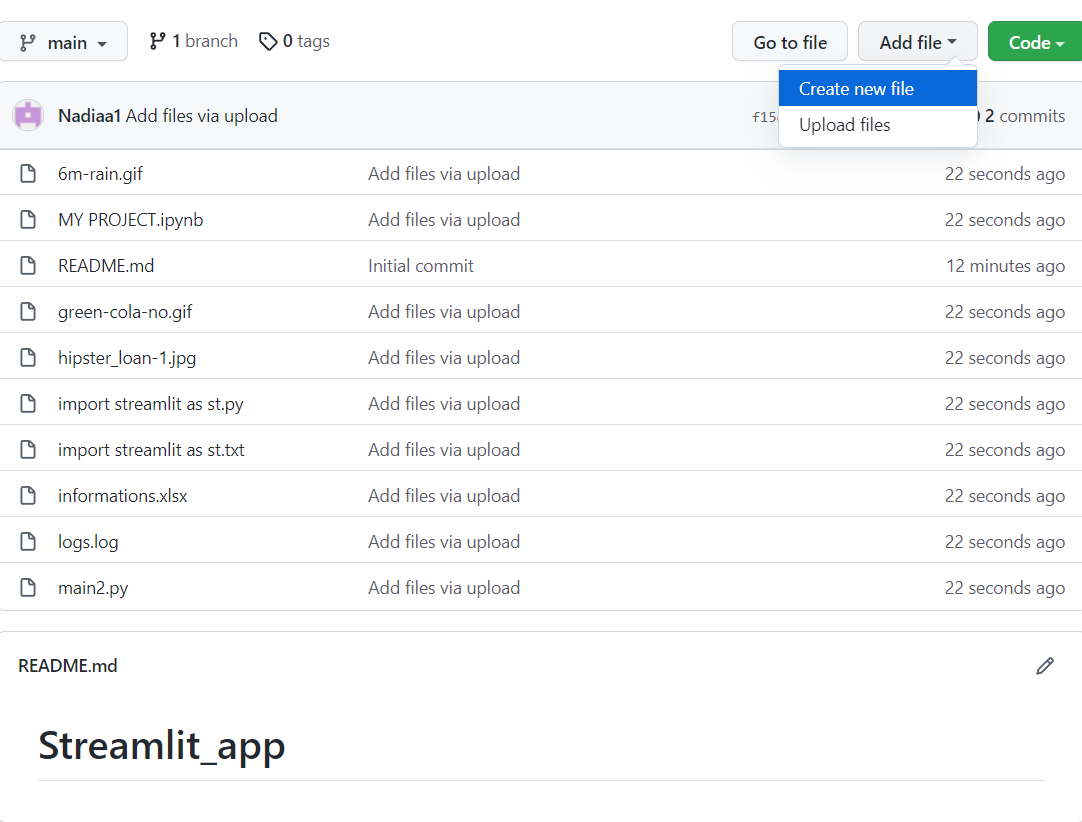
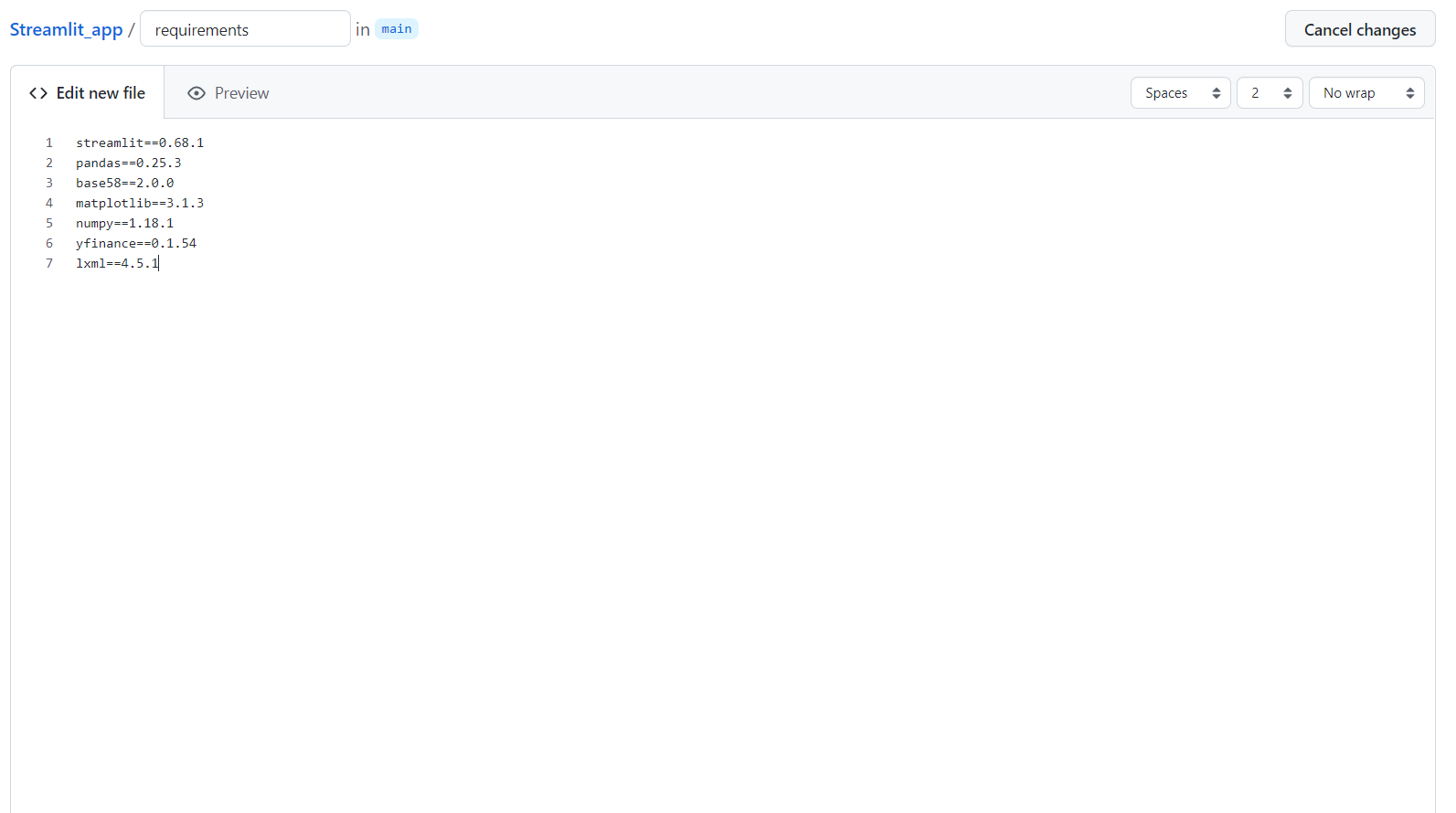
Dopo aver creato un repository e caricato i file, devi creare un nuovo file chiamato requirements in cui inserire le librerie che hai usato nella tua app.
Per prima cosa, clicca su create new file.
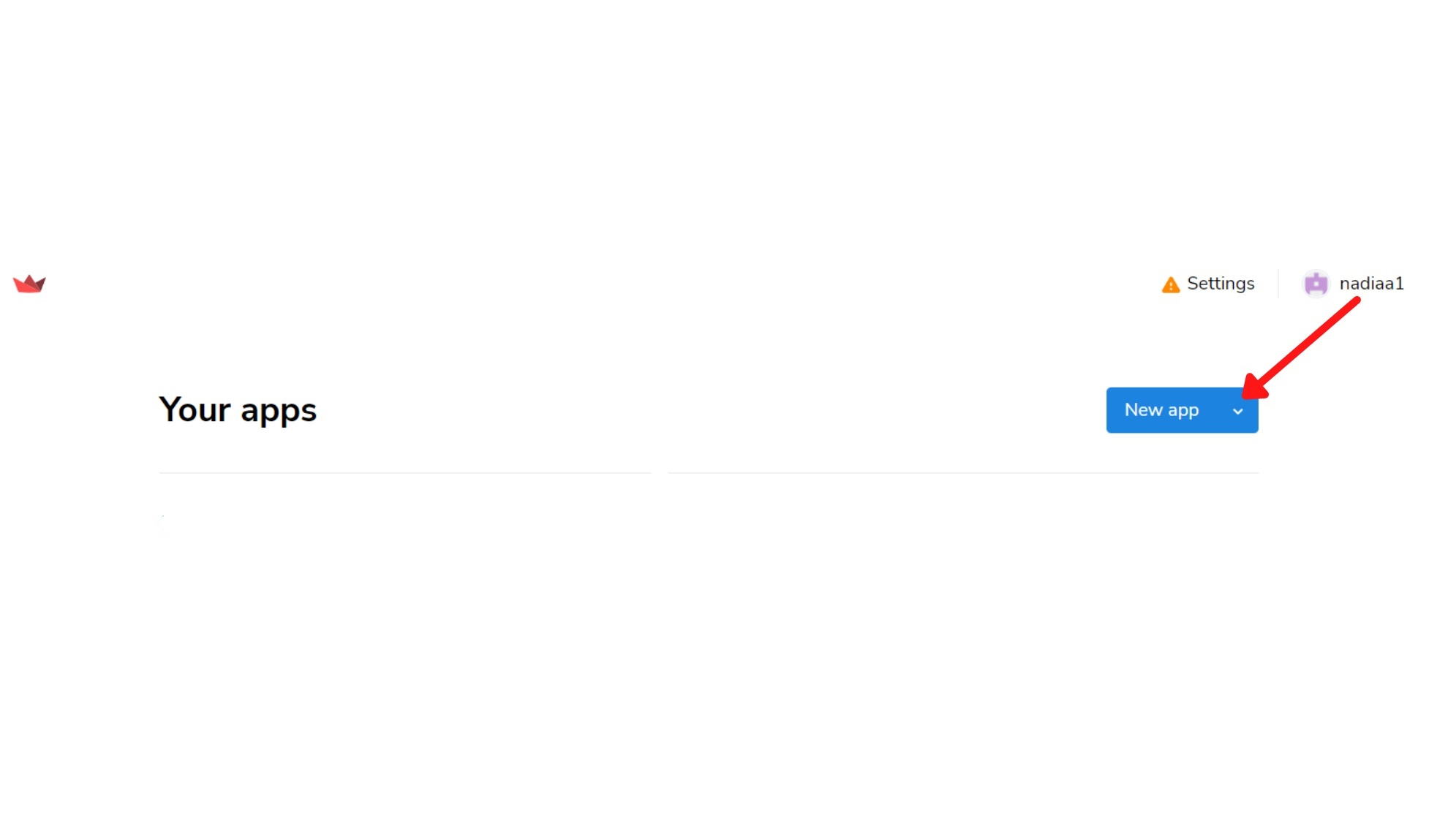
Ora sei vicino alla distribuzione della tua app, ti basta visitare questo link.
Quindi segui questi passaggi:
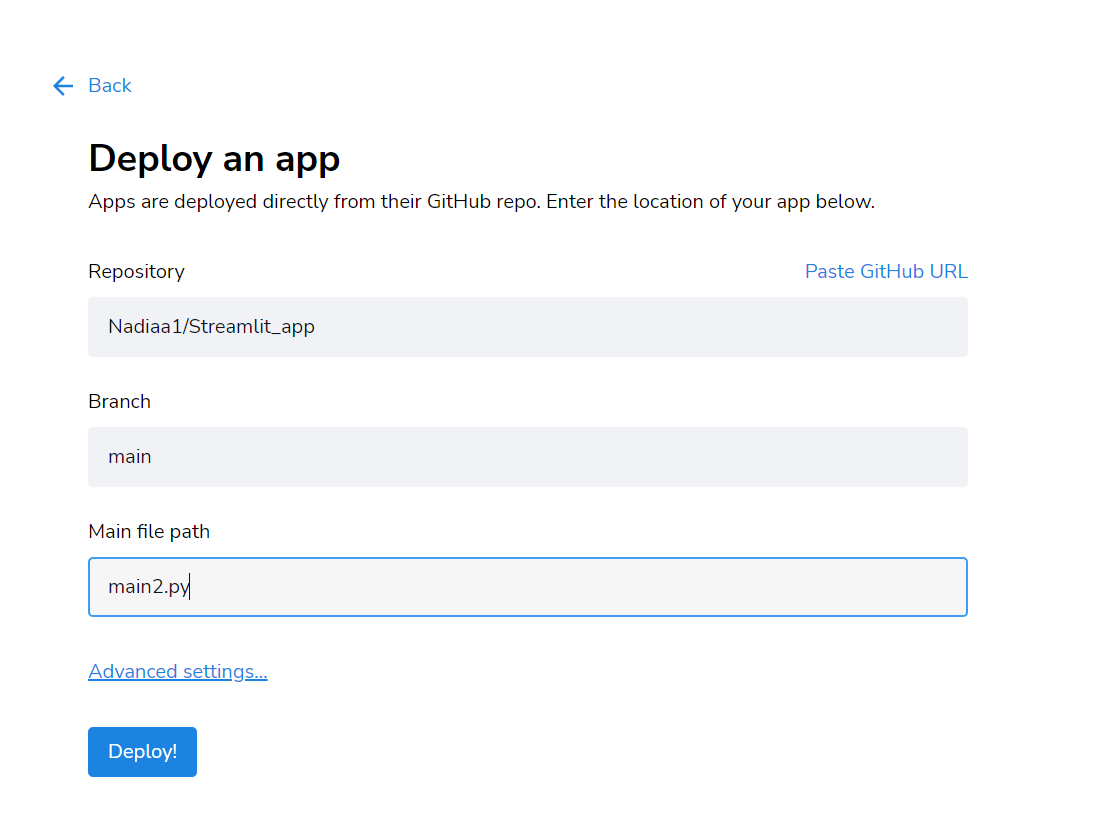
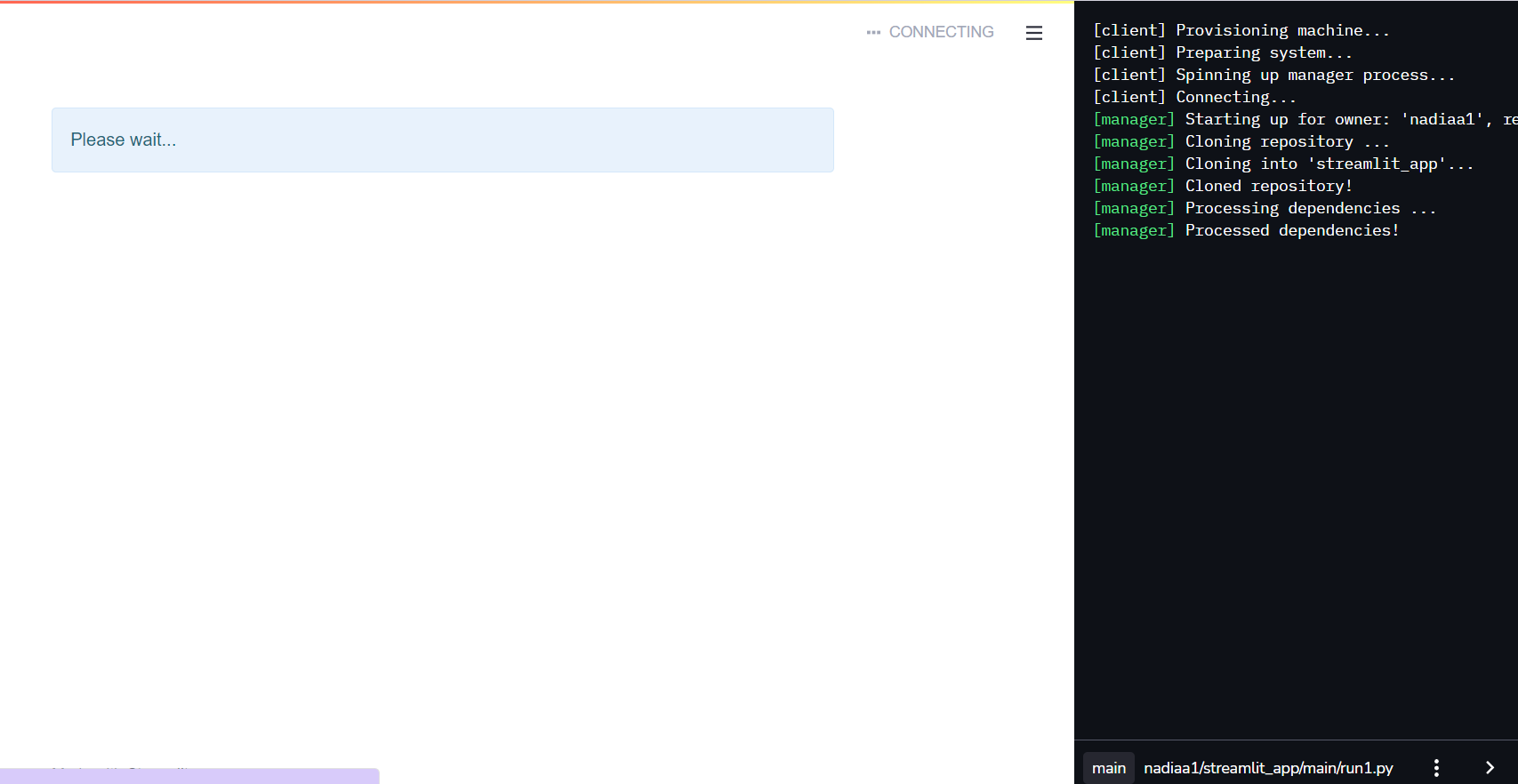
Clicca su Deploy e attendi qualche istante!
Si aprirà automaticamente una pagina nel tuo browser! Questa pagina è la tua app di progetto realizzata con Streamlit.
Congratulazioni, hai distribuito con successo la tua app! Clicca qui per vedere l'app distribuita.
Per maggiori informazioni, visita questo link: docs.streamlit.io
Impara con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

