Curso
Entendendo a computação em nuvem
2 h
234.6K
O armazenamento eficaz de dados é um componente essencial para o sucesso operacional de qualquer empresa em todos os setores. Quanto mais dados são coletados, mais crucial é a necessidade de soluções de armazenamento dimensionáveis, confiáveis e econômicas.
A escolha do armazenamento de dados correto pode ser um desafio devido ao grande número de opções, seja na nuvem ou no local, cada uma com suas vantagens e limitações.
Este artigo não pretende cobrir todas as opções possíveis, mas se concentra em serviços dimensionáveis, confiáveis e econômicos: Amazon Simple Storage Service (Amazon S3) e Amazon Elastic File System (EFS).
Começaremos explicando por que as empresas devem adotar serviços de armazenamento e continuaremos abordando os fundamentos dos serviços de armazenamento. Em seguida, ofereceremos orientações sobre a integração de serviços de armazenamento em um processo operacional. A última seção é um mergulho profundo nos conceitos avançados, com foco específico nas otimizações de desempenho e custo.
Se você está procurando um recurso introdutório abrangente sobre o Amazon Web Services (AWS), confira este curso de Introdução ao AWS.
Com todas as opções de armazenamento disponíveis, é importante fornecer os motivos pelos quais uma empresa deve usar o AWS para armazenamento de arquivos, e esse é o objetivo desta seção.
Ele começa realizando uma análise comparativa entre os serviços de armazenamento da AWS e os tradicionais, juntamente com breves exemplos de aplicativos do mundo real. Esperamos que isso reforce a relevância do AWS S3 e do EFS em vários cenários.
Os serviços de armazenamento tradicionais e os serviços de armazenamento da AWS oferecem diferentes conjuntos de recursos e benefícios. Fazemos uma análise comparativa na tabela abaixo:
|
Recursos |
Armazenamento tradicional |
AWS S3 E EFS |
|
Custo |
O gasto de capital com hardware e os custos contínuos de manutenção podem ser imprevisíveis ao longo do tempo. |
O modelo de preço de pagamento conforme o uso reduz os custos iniciais e ajuda a melhorar o gerenciamento de custos com base no uso. |
|
Conformidade |
Alcançado por meio de controles e auditorias internas e pode exigir recursos adicionais para manter os padrões. |
A AWS está em conformidade com uma grande variedade de padrões do setor, como HIPAA e GDPR, simplificando a conformidade do usuário. |
|
Acessibilidade de dados |
Principalmente acessível a partir de locais ou redes específicas. O acesso remoto pode ser menos seguro e complexo. |
Acessível globalmente pela Internet, com alta disponibilidade e redundância de dados. |
|
Durabilidade dos dados |
Pronta para danos físicos, roubo ou desastres naturais. |
Ofereça durabilidade de 99,99999999999% (11 noves) ao replicar automaticamente os dados em várias zonas de disponibilidade. |
|
Gerenciamento e manutenção |
Requer uma equipe dedicada para manutenção de hardware, atualizações de software e solução de problemas. |
Tratada pela AWS. Isso reduz a carga administrativa sobre os usuários. |
|
Desempenho |
Depende do hardware e da infraestrutura de rede específicos. Além disso, as atualizações podem ser caras. |
Fornecer opções de desempenho personalizáveis. O S3 fornece classes de armazenamento e recursos de aceleração, enquanto o EFS oferece suporte a cargas de trabalho de explosão e modelos de taxa de transferência. |
|
Escalabilidade |
Limitado pela infraestrutura física e requer intervenções manuais para ser dimensionado. |
Altamente escalável, permitindo fácil ajuste ao armazenamento sem provisionamento inicial. |
|
Segurança |
Depende das medidas de segurança locais. Isso exige um esforço significativo para garantir a segurança e a conformidade dos dados. |
Ofereça controles de segurança abrangentes, incluindo criptografia de dados (em repouso e em trânsito), gerenciamento de acesso e certificações de conformidade. |
Tanto o S3 quanto o EFS têm um amplo espectro de aplicações em todos os setores. Abaixo estão alguns exemplos de casos de uso reais para ambos os serviços, destacando sua relevância e utilidade em diferentes cenários.
Primeiro, vamos considerar os casos de uso do Amazon Simple Storage Service (S3):
Vamos agora considerar os casos de uso do Amazon Elastic File System (EFS):
Com todos esses insights sobre os serviços de armazenamento S3 e EFS, é essencial saber quando usar cada serviço, e esse é o objetivo desta seção. Primeiro, apresentaremos o armazenamento de blocos, arquivos e objetos e, em seguida, abordaremos o aspecto comparativo do S3 e do EFS.
O armazenamento em bloco, o armazenamento em arquivo e o armazenamento em objeto são três tipos fundamentais de sistemas de armazenamento de dados. Cada um deles serve a propósitos diferentes na computação em nuvem e no gerenciamento de dados.
O armazenamento em bloco segmenta os dados em blocos, cada um com um identificador exclusivo, permitindo um gerenciamento de dados flexível e eficiente. O Amazon Elastic Block Store (EBS) e o Instance Store Volumes são exemplos de armazenamento em bloco no ecossistema do AWS.
O Instance Store oferece armazenamento efêmero diretamente conectado a um computador host, ideal para dados temporários. Por outro lado, o EBS oferece armazenamento persistente em nível de bloco, o que o torna adequado para bancos de dados, aplicativos e sistemas de arquivos que exigem durabilidade e backups incrementais por meio de instantâneos.
O armazenamento de arquivos organiza os dados em uma estrutura hierárquica de arquivos e pastas, semelhante a um sistema de arquivos tradicional em um computador. Esse método intuitivo simplifica o acesso e o gerenciamento de dados em vários aplicativos e serviços.
O Amazon Elastic File System (EFS) é um exemplo de armazenamento de arquivos na nuvem. Ele fornece um sistema de arquivos compartilhado que é dimensionado automaticamente e oferece suporte ao acesso simultâneo de várias instâncias.
O EFS é particularmente vantajoso para aplicativos que exigem acesso compartilhado a arquivos ou para servir conteúdo que vários usuários ou sistemas precisam acessar e editar.
O armazenamento de objetos, como o Amazon S3, foi projetado para armazenar grandes quantidades de dados não estruturados. Ao contrário do armazenamento em bloco e em arquivo, o armazenamento em objeto gerencia os dados como objetos dentro de compartimentos.
Cada objeto inclui os dados, os metadados e um identificador exclusivo, permitindo a recuperação e o gerenciamento eficientes dos dados em qualquer escala. O S3 é versátil e oferece suporte a uma ampla gama de casos de uso, desde a hospedagem de sites estáticos até o arquivamento de dados com suas várias classes de armazenamento, incluindo Standard, Standard-Infrequent Access (IA), Glacier Flexible Retrieval e Glacier Deep Archive.
A escolha entre o Amazon S3 e o Amazon Elastic File System (EFS) depende dos requisitos específicos do seu aplicativo ou carga de trabalho. Vamos dar uma olhada nas diferenças entre cada um deles:
|
Recurso |
Amazon S3 |
Amazon EFS |
|
Tipo de dados |
Dados não estruturados, como imagens, vídeos, registros e backups. |
Arquivos compartilhados que precisam ser acessados por várias instâncias do EC2 simultaneamente. |
|
Escala de armazenamento |
Projetado para grandes quantidades de dados, escalável até exabytes. |
Dimensiona-se automaticamente de acordo com suas necessidades de armazenamento, sem intervenção manual. |
|
Padrão de acesso |
Ideal para dados com padrões de acesso variados, desde os acessados com frequência até os arquivados. |
Adequado para dados que exigem acesso consistente e simultâneo por vários aplicativos. |
|
Integração |
Integra-se aos serviços do AWS para processamento de dados, análise e fornecimento de conteúdo. |
Oferece suporte a aplicativos que exigem uma interface tradicional de sistema de arquivos. |
|
Classes de armazenamento |
Várias classes de armazenamento. |
Não aplicável. |
|
Considerações sobre custos |
Os custos de armazenamento variam de acordo com a classe, com opções de acesso pouco frequente para reduzir os custos. |
Custo baseado na capacidade de armazenamento utilizada, sem custo inicial e com escalonamento automático. |
|
Escalabilidade e flexibilidade |
Altamente escalável, tanto em termos de capacidade de armazenamento quanto de desempenho. |
Flexibilidade no dimensionamento sem a necessidade de provisionar armazenamento, lidando facilmente com cargas de pico. |
Agora que temos uma melhor compreensão do conceito de armazenamento de arquivos, é hora de colocar a mão na massa com algumas implementações técnicas.
Esta seção aborda o processo de gerenciamento de dados com o Amazon S3. Especificamente, aprenderemos a criar um bucket para armazenamento, organizar dados em pastas, fazer upload de arquivos, ajustar permissões para acesso público quando necessário, aplicar metadados para gerenciamento e, por fim, excluir o bucket e seu conteúdo para limpar recursos e evitar custos adicionais.
O principal pré-requisito para concluir esta seção com êxito é ter uma conta da AWS, que pode ser criada no site da AWS.
O ponto de partida desta seção é o Amazon Web Services Management Console, conforme mostrado abaixo:
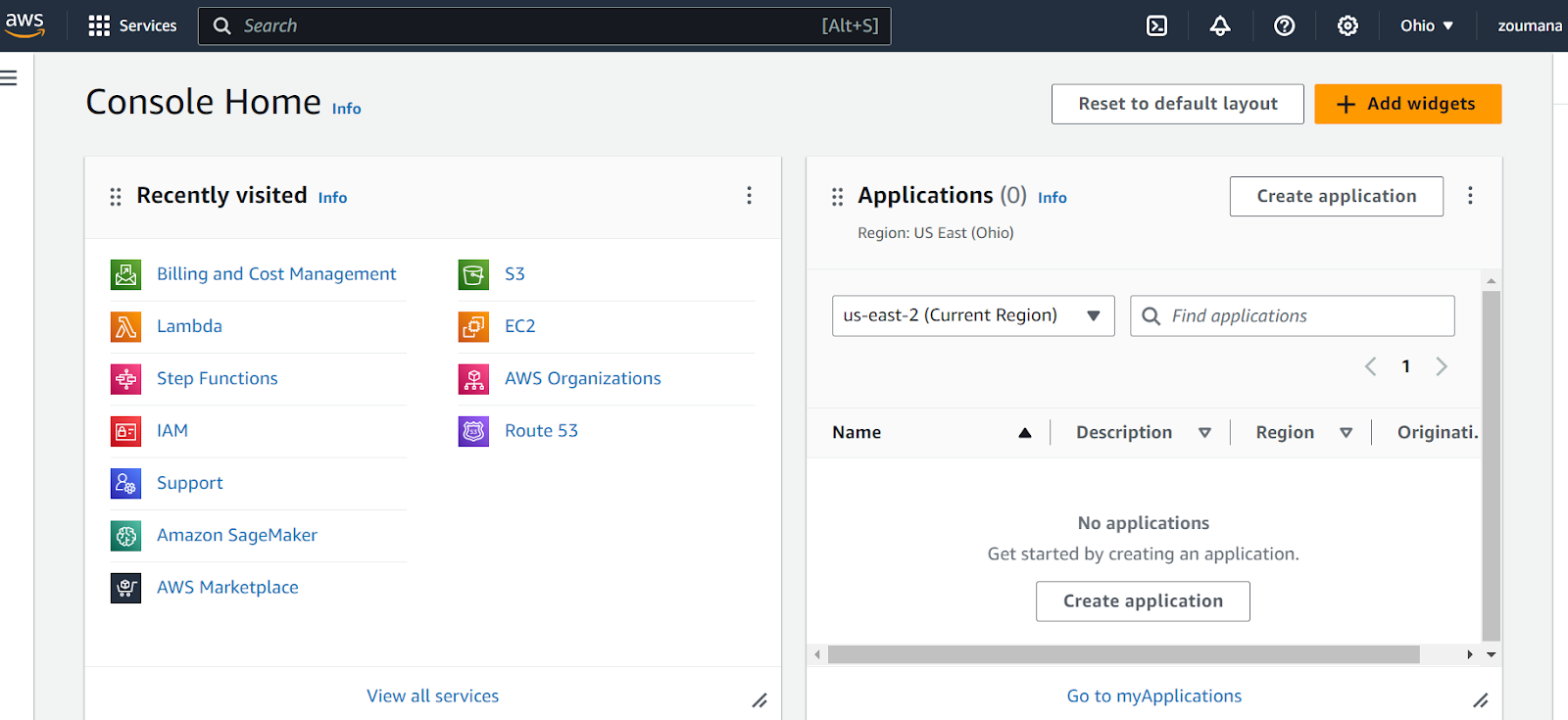
Esse console ajuda a gerenciar todos os recursos do AWS, desde instâncias de computação, como o EC2, até serviços de enfileiramento de mensagens, como o SQS, incluindo o gerenciamento de segurança.
Uma vez no console, a primeira etapa é criar uma instância S3. Isso pode ser feito usando as etapas a seguir (você pode seguir os números na imagem abaixo):
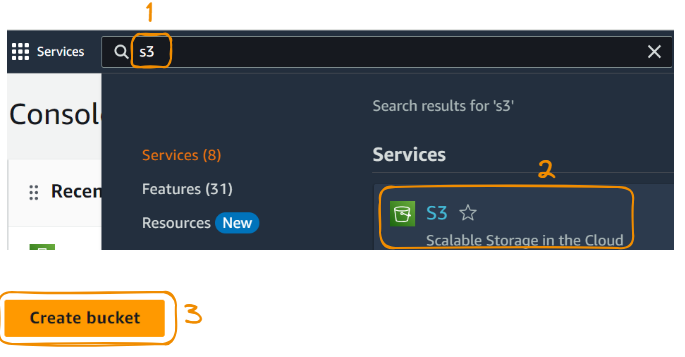
Agora, continuaremos com mais algumas etapas:
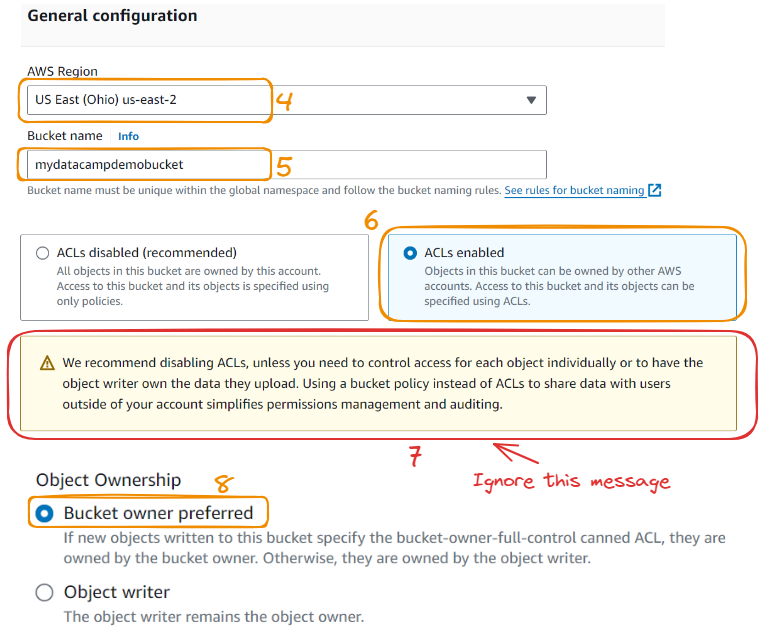
Vamos acrescentar algumas observações a algumas das etapas que abordamos:
Vamos criar o balde seguindo mais três etapas:

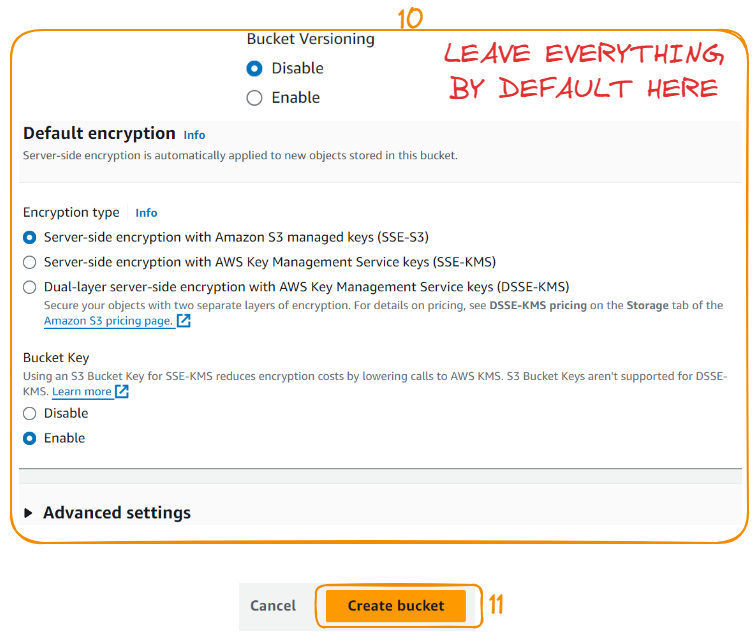
Depois de criar o bucket, você verá os detalhes abaixo. Um balde é um contêiner que pode conter recursos. O upload de recursos começa com a criação de uma pasta. Vamos começar com essas duas etapas:
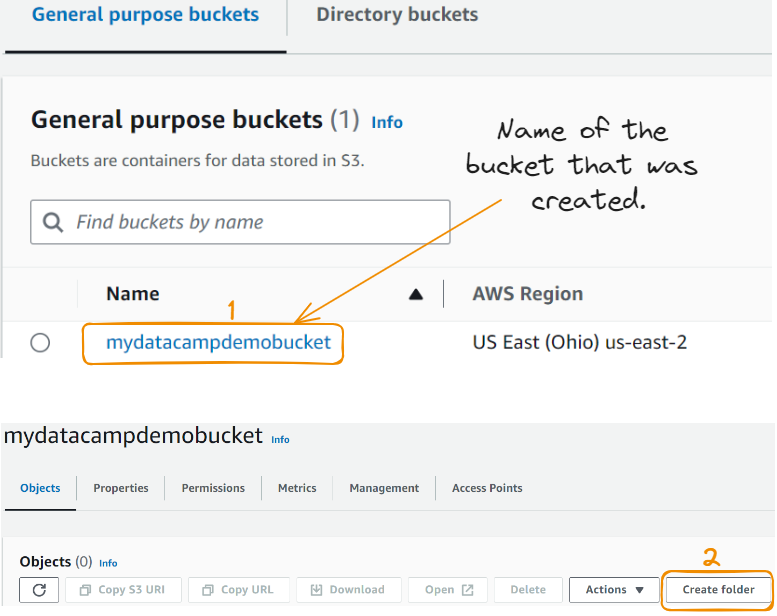
Agora, vamos criar a pasta:
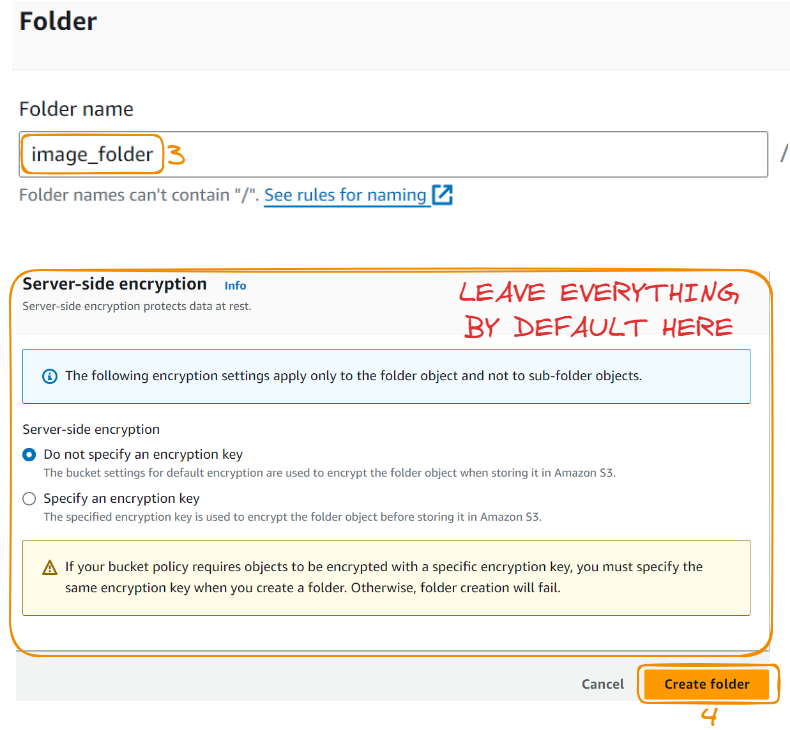
Observe que a pasta foi criada!

Agora é hora de carregar os dados na pasta. Vamos tentar fazer o upload de uma imagem:
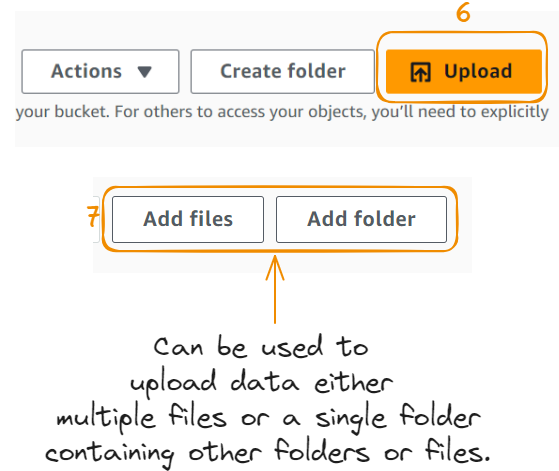
Fizemos o upload da imagem com sucesso!
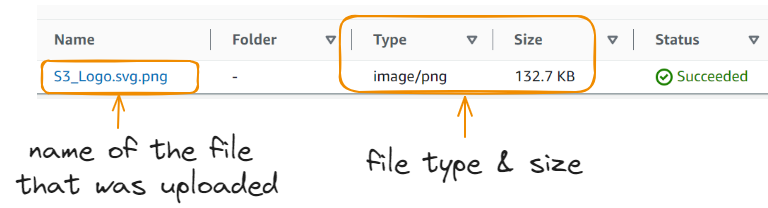
Por padrão, todos os arquivos carregados no bucket são privados e de propriedade do criador, e somente o proprietário pode visualizá-los, editá-los ou baixá-los. No entanto, talvez seja necessário configurar o bucket para que qualquer pessoa possa acessar o arquivo - isso pode ser útil quando todos precisam visualizar as fotos em um site.
Podemos fazer essa configuração permitindo que todos os públicos acessem a imagem. Isso deveria nos permitir acessar o URL do objeto com acesso público, mas, infelizmente, recebemos uma mensagem de acesso negado.
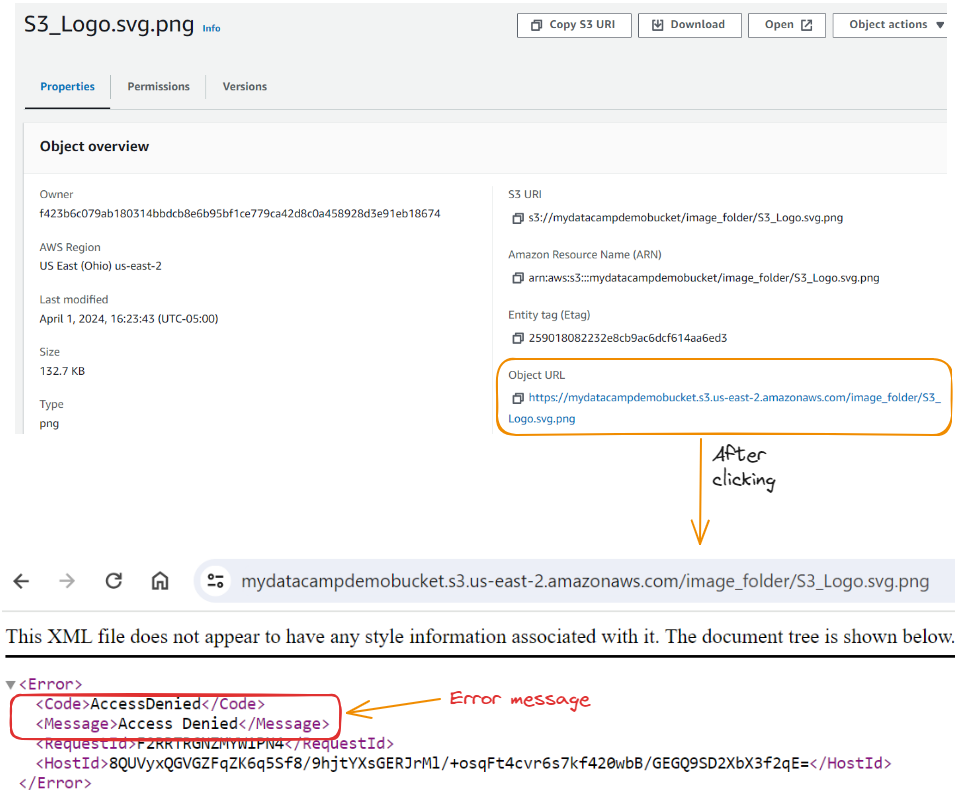
Para corrigir isso, precisamos navegar até a guia Permissões no nível dos buckets e editar a Política de Bucket: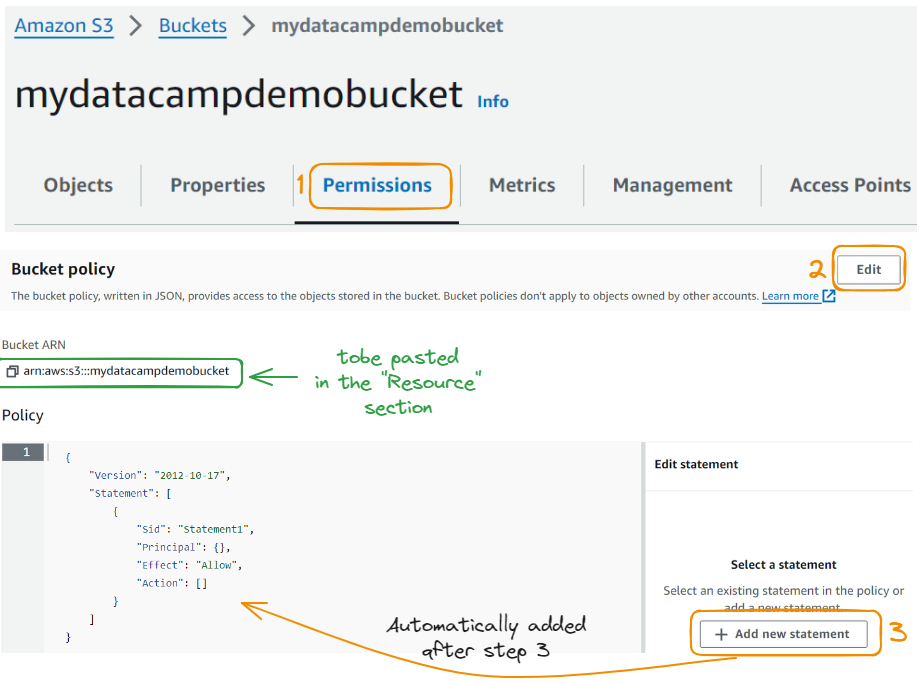
Agora vamos editar a declaração:
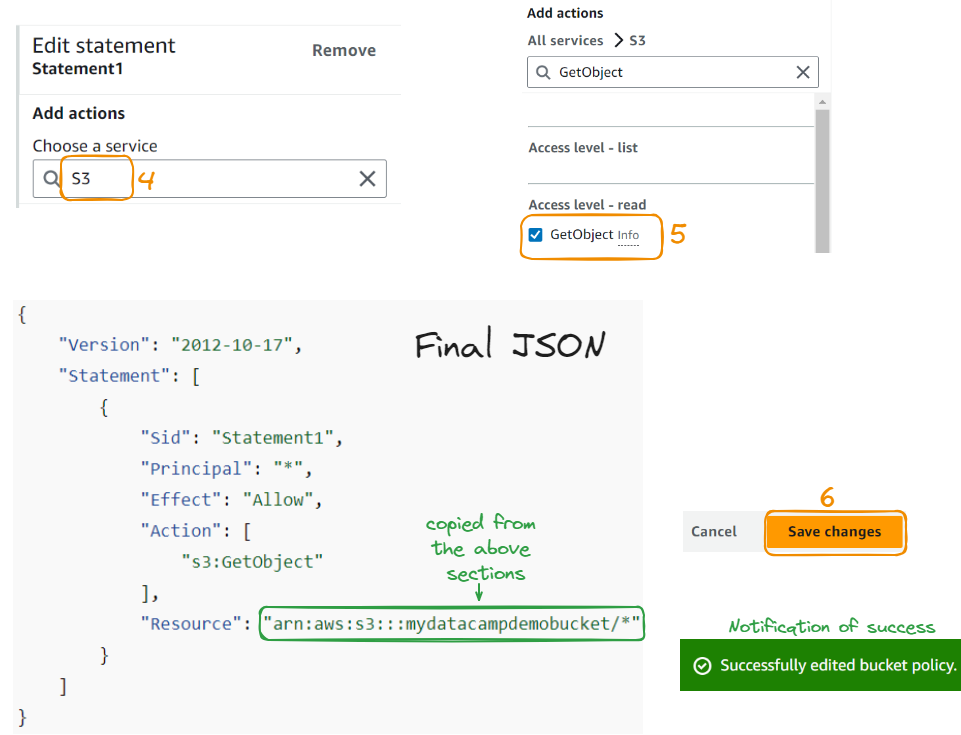 que fizemos essas alterações, a imagem finalmente será exibida!
que fizemos essas alterações, a imagem finalmente será exibida!

Logotipo da AWS após a configuração do controle de acesso
Esta seção aborda a criação de um sistema de arquivos EFS, enfatizando as configurações de desempenho e segurança.
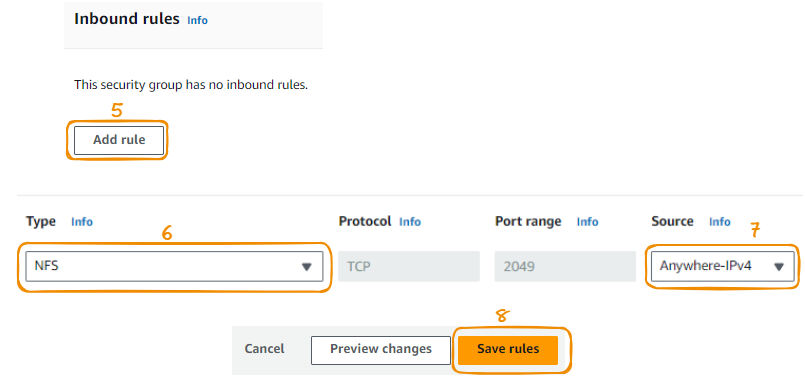
Primeiro, criamos um grupo de segurança escolhendo a opção "Security Groups" (Grupos de segurança) na guia Security (Segurança ) no banner esquerdo.

Então, nós:
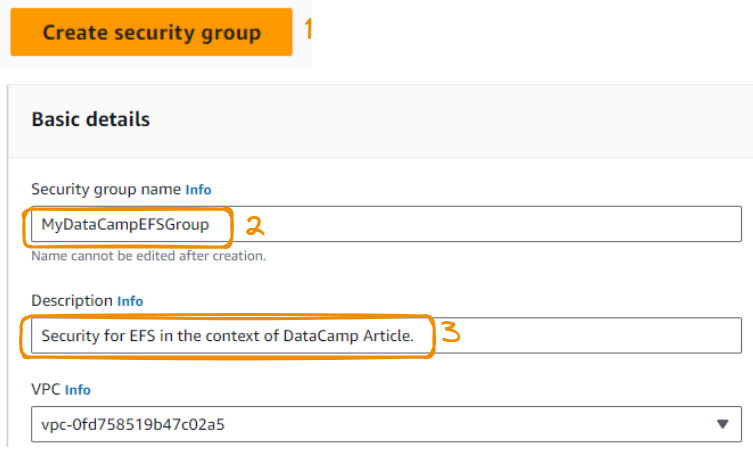
Não adicionamos nenhuma regra de entrada:
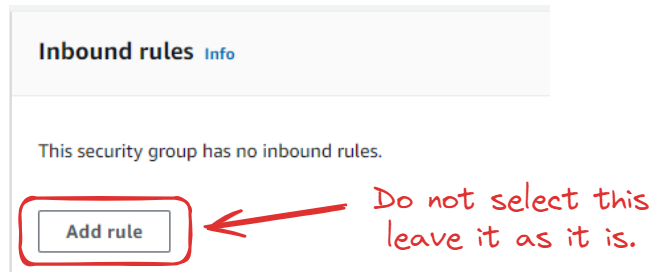
O tipo de regra de saída 1 deve ser Todo o tráfego:
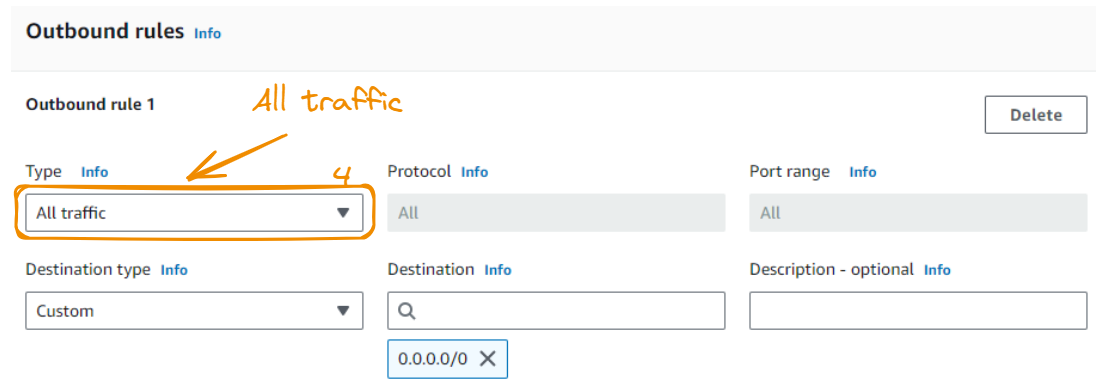
Agora que terminamos nossa configuração, podemos clicar no botão Criar grupo de segurança.
O grupo de segurança recém-criado é exibido na seção Grupos de segurança.
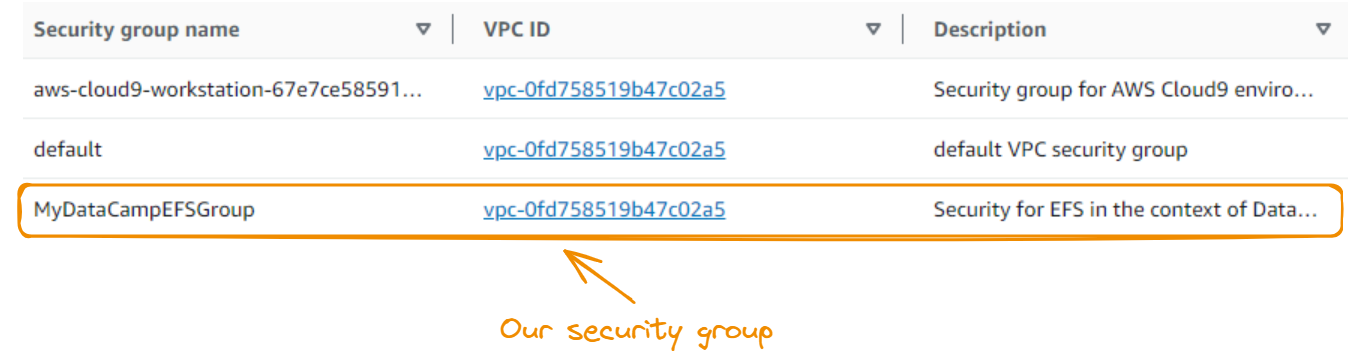
Em seguida, criamos um sistema de arquivos EFS. Começamos pesquisando e selecionando o EFS:
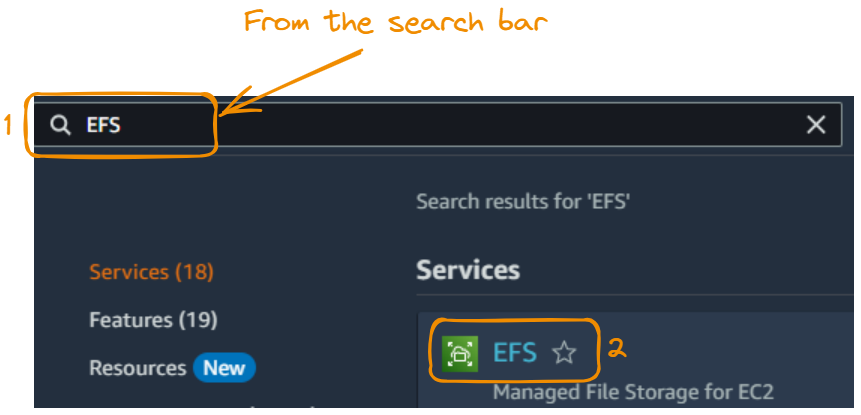
Agora clicamos em Criar sistema de arquivos.
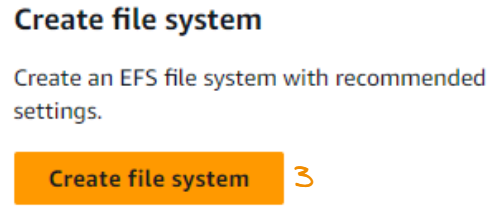
Usamos um nome significativo, deixamos a seção VPC como está e, em seguida, clicamos em Customize (Personalizar).
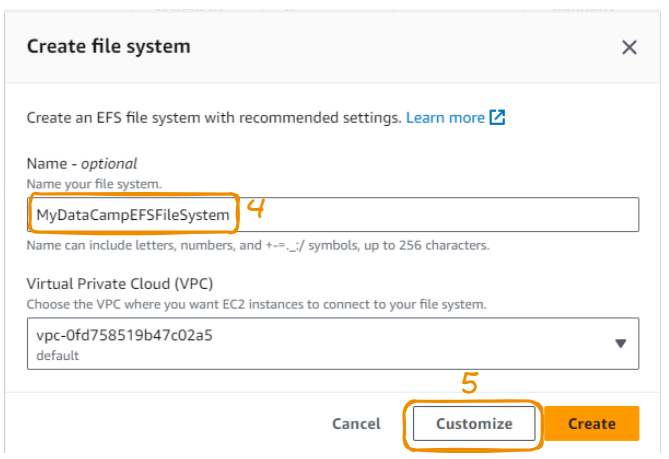
Para acessar a página de configuração de rede, clique em Next.

Agora, preenchemos as seções de grupos de segurança de cada zona de disponibilidade com MyDataCampEFSGroup.
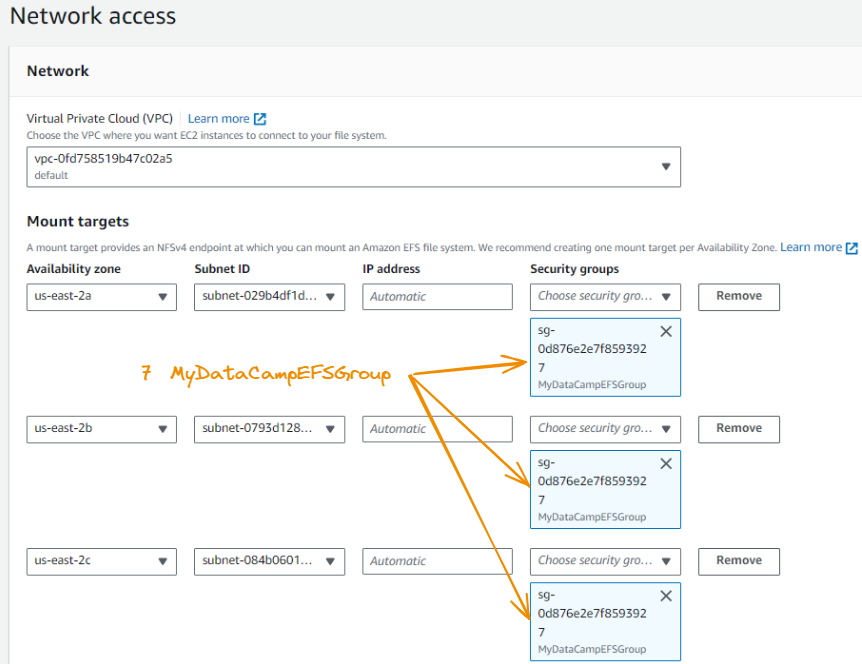
Quando terminarmos, clicaremos em Next novamente.

A etapa final nos permite revisar toda a configuração. Quando estivermos satisfeitos com tudo, clicamos em Create.
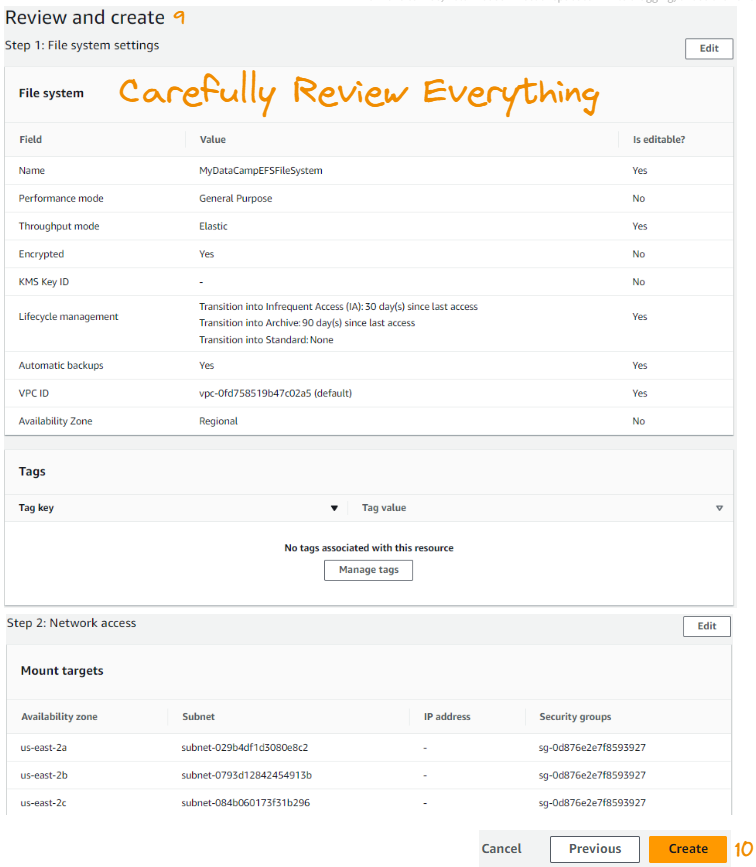
Quando tudo for executado com êxito, você verá o sistema de arquivos EFS recém-criado na guia File systems (Sistemas de arquivos ).
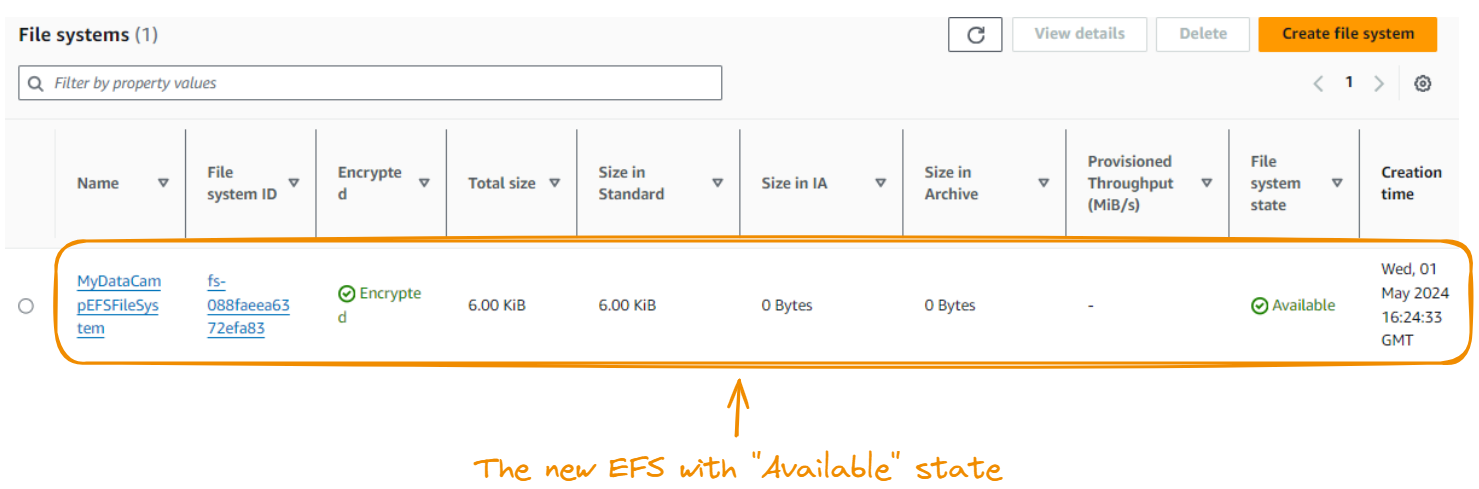
A próxima etapa é criar uma instância do EC2, que fornece ao EFS o ambiente de computação necessário e acessa simultaneamente os mesmos dados.
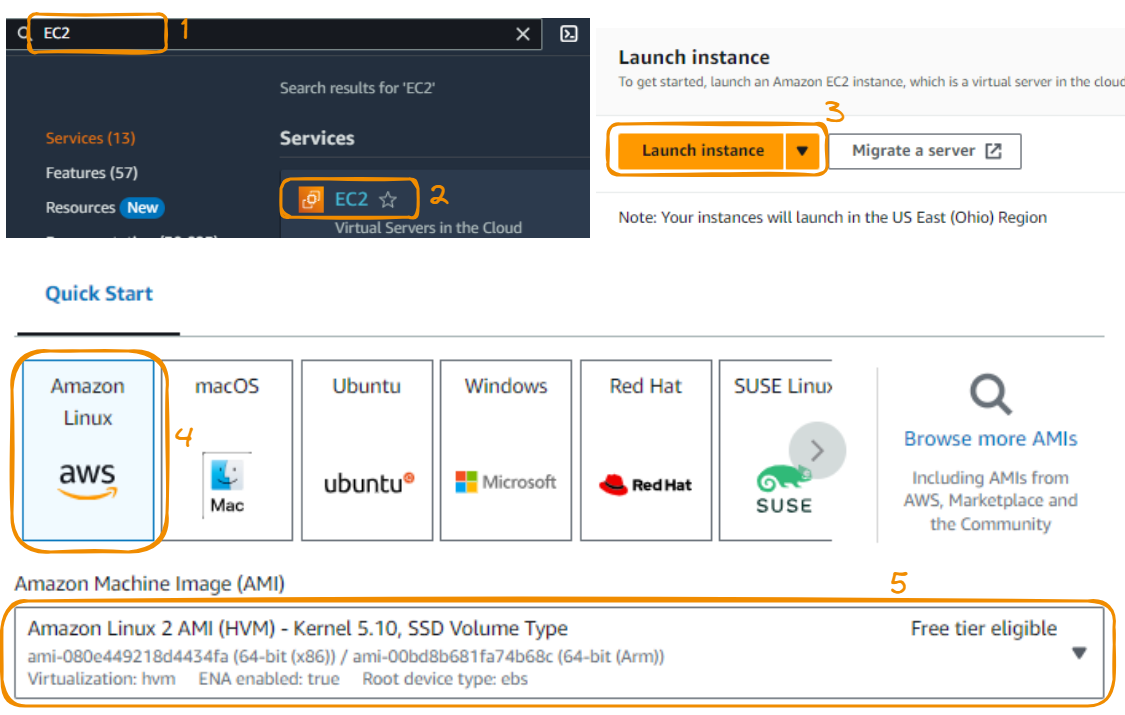
Vamos fazer tudo passo a passo! Começamos selecionando uma instância do EC2 para o console. Em seguida, clicamos em Launch instance ( Iniciar instância). Escolheremos o Amazon Linux 2, que vem qualificado para uma camada gratuita.
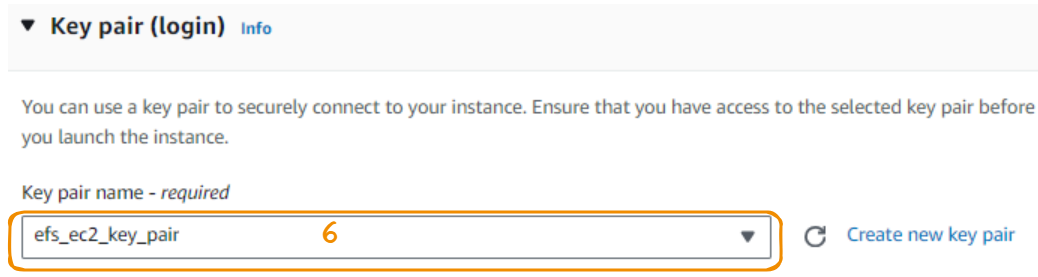
Agora, criamos um par de chaves para você se conectar com segurança à instância. O que criamos nesta seção tem uma extensão .pem com o nome efs_ec2_key_pair. Esse arquivo é então baixado e salvo localmente para uso posterior.
A capacidade de armazenamento padrão é de 8 GiB, o que é suficiente para o nosso cenário, e o número de instâncias é aumentado para 3. A etapa final é iniciar a instância clicando no botão Launch instance (Iniciar instância ), e o resultado final mostra as instâncias recém-criadas.
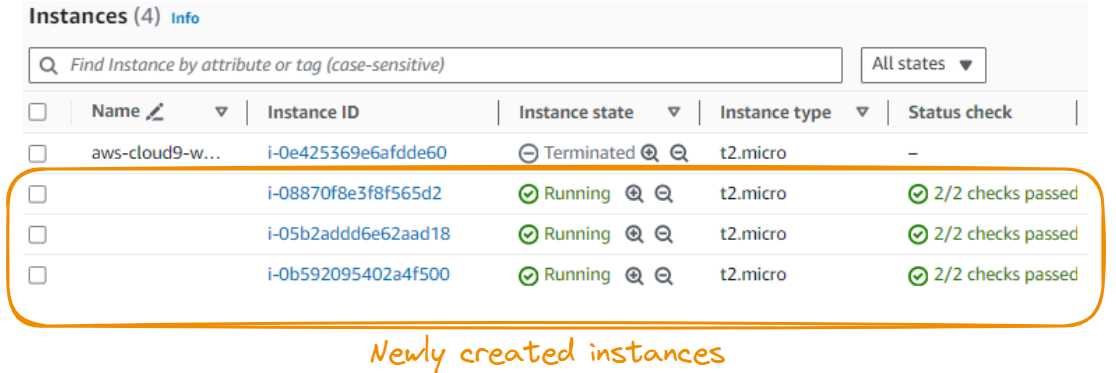
Antes de prosseguir, vamos nos certificar de que a conexão com as instâncias é possível. Usaremos o seguinte comando SSH (Secure Shell):
ssh -i [path_to_the_key] ec2-user@[Public IPv4 address]Vamos detalhar esse comando passo a passo:
ssh: Esse é o comando que inicia a conexão SSH.-i [path_to_the_key]: Essa opção especifica o caminho para o nosso arquivo de chave SSH privado, que é necessário para a autenticação no servidor remoto.ec2-user: Esse é o nome de usuário padrão para instâncias do EC2 Linux. Você pode usar um nome de usuário diferente, se estiver configurado.@: Esse símbolo separa o nome de usuário do endereço do servidor.[Public IPv4 address]: Esse é o endereço IP público da nossa instância do EC2. Você pode encontrar esse endereço no console de gerenciamento do AWS.Vamos ver os resultados da conexão com cada instância por meio do SSH.
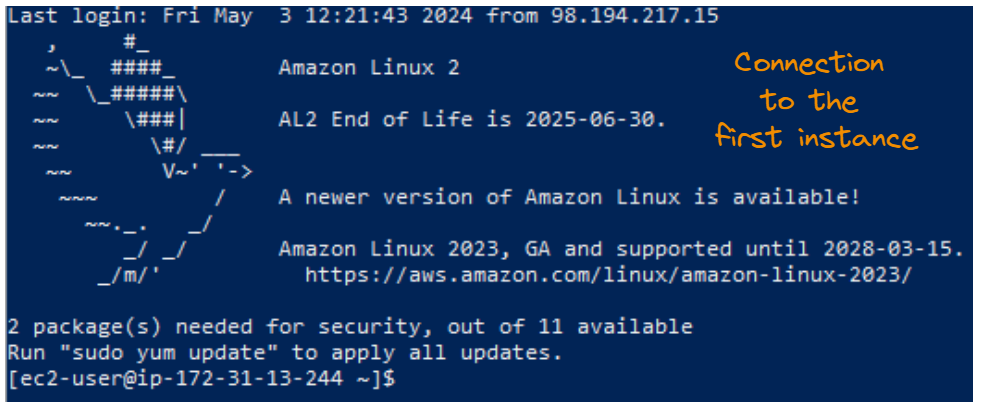 Resultado da conexão SSH para a primeira instância.
Resultado da conexão SSH para a primeira instância.
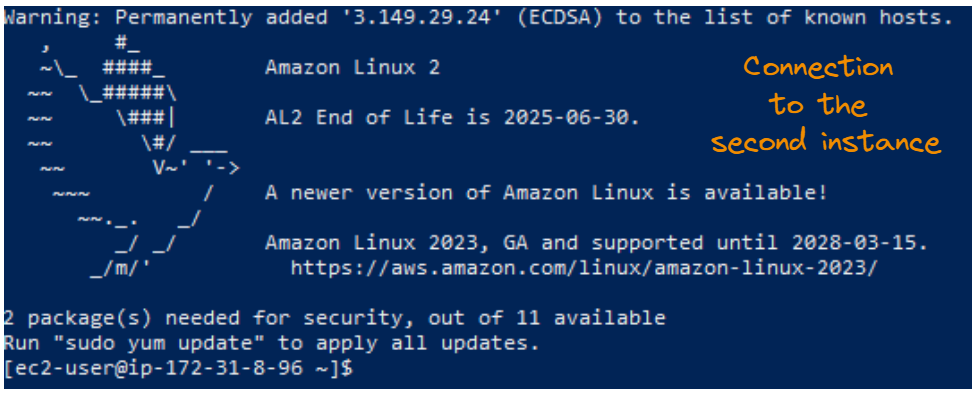
Resultado da conexão SSH para a segunda instância.
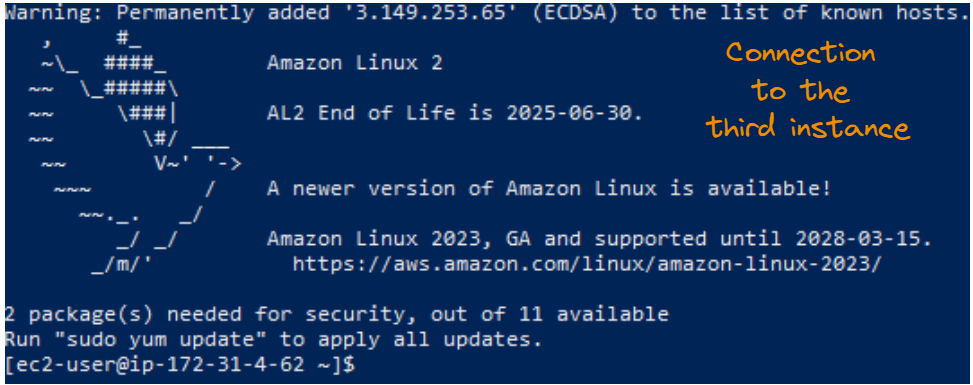
Resultado da conexão SSH para a terceira instância.
Essa etapa final permite a montagem das instâncias do EC2 criadas acima. Você pode fazer isso na interface geral do EFS.
Para simplificar, o processo de montagem é mostrado para apenas uma instância, mas a mesma abordagem se aplica às instâncias restantes.
Começamos instalando o auxiliar de montagem EFS para cada instância usando o seguinte comando:
sudo yum install -y amazon-efs-utils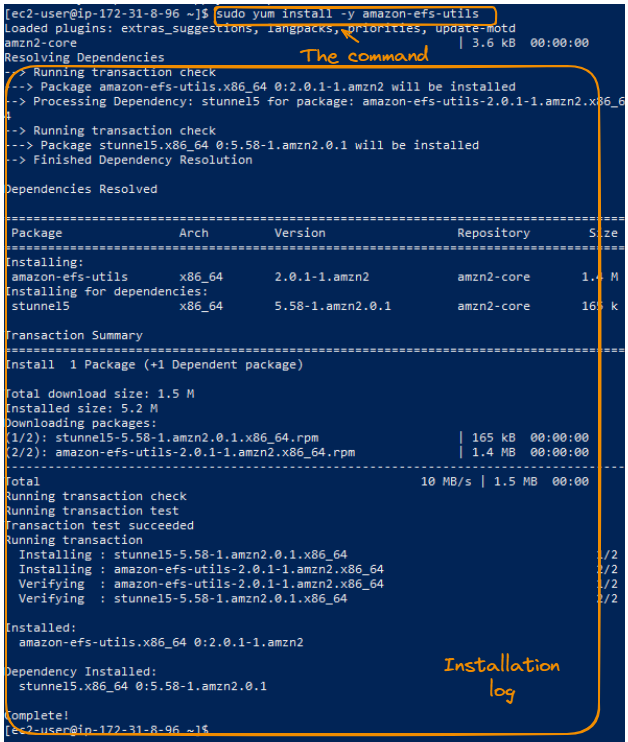
Instalação do log de rastreamento de utilitários do Amazon EFS.
Em seguida, criamos uma pasta efs em nossas instâncias na raiz usando sudo, certificando-nos de usar a mesma pasta em todas as instâncias.
sudo mkdir /efs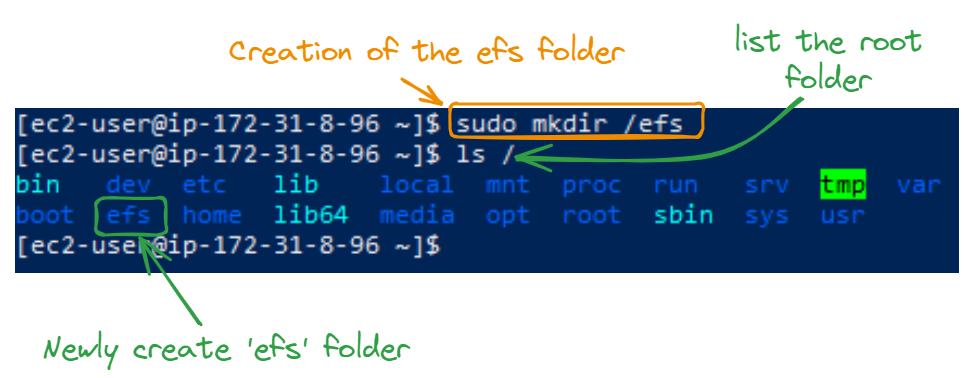
Depois de criar a pasta com êxito, a próxima etapa é montá-la. O ID do sistema de arquivos é o ID do EFS que criamos na seção EFS e o usamos no comando sudo mount -t efs [file system ID]:/ /efs:
sudo mount -t efs fs-088faeea6372efa83:/ /efs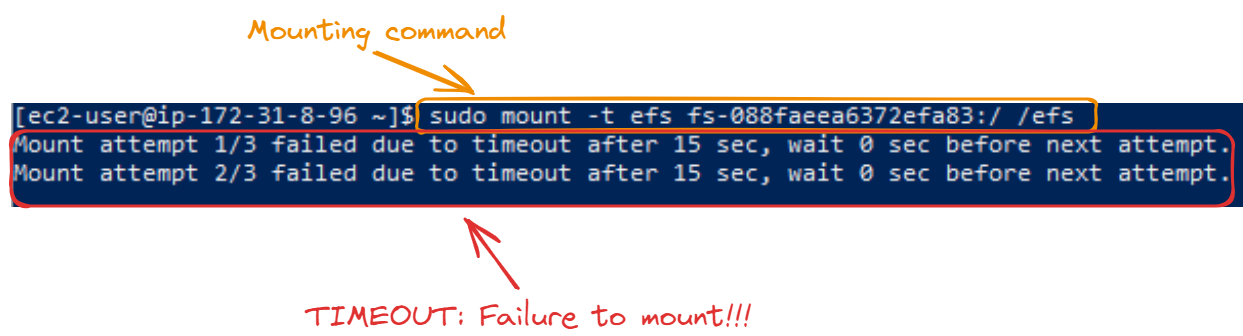
Esse tempo limite ocorre porque o grupo de segurança anexado ao sistema EFS que criamos não permite nenhum tráfego de entrada de nossas instâncias do EC2. Podemos corrigir isso habilitando o grupo de segurança para aceitar essas conexões de entrada:
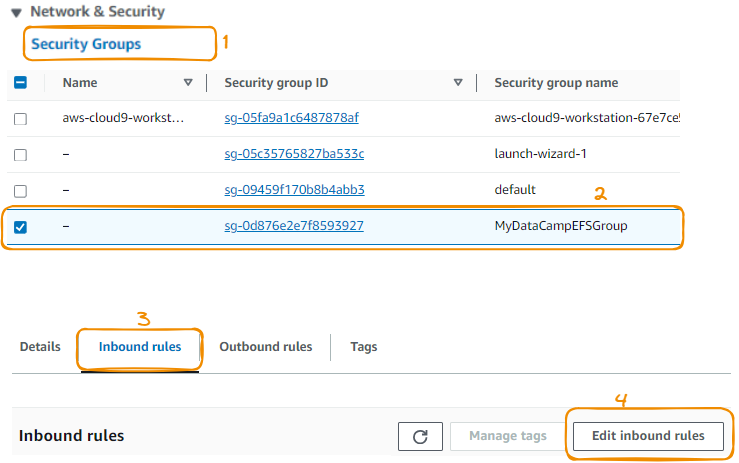
Agora, criamos uma nova regra de entrada:
Uma opção mais segura é criar um grupo de segurança separado para as instâncias do EC2 e permitir a conexão somente a partir desse grupo de segurança. Essa configuração está fora do escopo deste artigo.
Depois de concluir com êxito esse processo em cada instância do EC2, o sistema EFS poderá aceitar conexões de qualquer lugar (incluindo nossas instâncias do EC2). Desta vez, você não terá nenhum tempo limite:

Para garantir que o processo de montagem foi bem-sucedido, devemos ser capazes de:
A ilustração abaixo mostra como a pasta my_DataCamp_data é criada a partir da primeira instância do EC2, juntamente com um arquivo README.txt. O mesmo arquivo README pode ser visto nas instâncias restantes do EC2.

Compartilhamento de arquivos EFS.
Graças ao poder da configuração do sistema EFS, um arquivo criado por uma instância pode ser acessado pelas instâncias restantes.
Para obter uma visão geral mais ampla do ecossistema da AWS, confira este curso sobre a tecnologia e os serviços de nuvem da AWS.
Estratégias de armazenamento eficazes são essenciais para o gerenciamento eficiente dos dados. Dois aspectos fundamentais dessas estratégias são a otimização do desempenho e a otimização dos custos.
Essas estratégias são particularmente relevantes para o Simple Storage Service (S3) e o Elastic File System (EFS) da Amazon.
A otimização do desempenho no S3 e no EFS envolve a seleção de classes de armazenamento e modos de throughput adequados para aumentar a velocidade e a eficiência.
A otimização de custos envolve o uso de diferentes níveis de armazenamento com base na frequência de acesso aos dados e a utilização de ferramentas de monitoramento da AWS para o gerenciamento de custos. Essas estratégias ajudam no gerenciamento eficiente de dados e na redução de custos no armazenamento em nuvem.
Parabéns por você ter chegado até aqui! Esperamos que este mergulho profundo prepare você para começar a usar o armazenamento da AWS.
Uma maneira eficiente de dominar os serviços da AWS é aplicá-los a cenários do mundo real - não apenas de forma autônoma, mas também combinando vários serviços. Se esse tipo de exercício parece interessante para você, confira este curso sobre Streaming de dados com o AWS Kinesis e o Lambda.
Se você pretende conseguir um emprego no espaço da AWS, não deixe de conferir as certificações relevantes da AWS em 2024. Além disso, pode ser muito útil que você leia as principais perguntas e respostas das entrevistas da AWS.
Saiba mais sobre a AWS com estes cursos!
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Tim Lu
Tutorial
Bex Tuychiev
Tutorial
Javier Canales Luna
