Curso
Entendendo a Arquitetura de Dados Moderna
2 h
22.4K
Com os recursos que acabamos de mencionar em mente, aqui está uma visão geral concisa das vantagens do Athena:
|
Benefício |
Recurso |
Descrição |
|
Eficiência de custo |
Modelo de pagamento por consulta |
Pague apenas pelos dados com os quais suas consultas interagem; sem custos iniciais ou licenças complexas; a otimização de custos é possível com particionamento, compactação de dados e formatos colunares. |
|
Facilidade de uso |
SQL sem servidor e padrão |
Não há necessidade de configurar ou gerenciar a infraestrutura; os usuários podem começar a consultar os dados em minutos usando a sintaxe SQL familiar, tornando-a acessível e simples de usar. |
|
Flexibilidade |
Suporte a vários formatos |
Ele oferece suporte a uma ampla variedade de formatos de dados (por exemplo, CSV, JSON, Parquet), permitindo que os usuários consultem dados em seu formato nativo diretamente do S3 sem a necessidade de processos de ETL. |
|
Insights rápidos |
Análise rápida e consultas diretas ao S3 |
Ele permite a análise imediata de dados com arquitetura sem servidor, possibilitando a extração rápida de insights diretamente dos dados armazenados no S3 e reduzindo o tempo de obtenção de valor para decisões orientadas por dados. |
Definimos o Athena e mencionamos seus recursos e benefícios, mas para que ele é usado? Nesta seção, analisaremos alguns dos casos de uso mais populares.
O Amazon Athena é usado com frequência para análise de logs, especialmente para consultar e analisar logs armazenados no Amazon S3. As organizações geralmente geram grandes volumes de dados de registro de várias fontes, como registros de aplicativos, registros de servidores e registros de acesso.
Ao armazenar esses logs no S3 e consultá-los usando o Athena, os usuários podem identificar rapidamente tendências, diagnosticar problemas e monitorar o desempenho do sistema sem a necessidade de uma configuração complexa.
A arquitetura sem servidor do Athena e o suporte para SQL padrão fazem dele uma excelente ferramenta para exploração de dados ad-hoc. Seja você um cientista de dados, analista ou engenheiro, o Athena permite que você consulte rapidamente os dados armazenados no S3 sem carregá-los em um banco de dados tradicional.
Como as organizações adotam cada vez mais os data lakes para armazenar grandes quantidades de dados brutos e processados, o Athena serve como um mecanismo de consulta avançado para esses data lakes. Ele permite que os usuários realizem análises diretamente nos dados armazenados no S3, tornando-o parte integrante de uma arquitetura moderna de data lake.
O Athena também é comumente usado como parte de uma pilha de business intelligence (BI), onde se integra a ferramentas de BI como o Amazon QuickSight para permitir a visualização de dados e a geração de relatórios. Ao consultar dados no S3 com o Athena e visualizá-los no QuickSight, as organizações podem criar painéis e relatórios interativos para a tomada de decisões.
Se você está familiarizado com o Amazon Redshift, pode se perguntar como ele difere do Athena.
Embora tanto o Athena quanto o Redshift lidem com conjuntos de dados, seus objetivos são diferentes. O principal caso de uso do Redshift é o warehouse de dados e a análise regular envolvendo big data. O AWS Athena está focado em permitir que os usuários realizem análises ad hoc nos dados armazenados no S3.
Aqui está uma comparação detalhada entre o Athena e o Redshift:
|
Critérios |
Amazon Athena |
Amazon Redshift |
|
Arquitetura |
Serviço de consulta sem servidor; executa consultas SQL diretamente nos dados armazenados no Amazon S3 com dimensionamento automático; sem gerenciamento de infraestrutura. |
Data warehouse totalmente gerenciado; requer um cluster de data warehouse com infraestrutura dedicada; pode ser dimensionado com base nas necessidades. A opção Redshift Serverless está disponível. |
|
Casos de uso |
É ideal para consultas e análises ad-hoc em dados S3 e para cenários que priorizam a flexibilidade e a economia sem transformação de dados. |
Adequado para análises e relatórios complexos e em grande escala; ideal para dados estruturados que exigem consultas e transformações frequentes. |
|
Estrutura de custos |
Modelo de pagamento por consulta: cobra com base nos dados verificados pelas consultas, o que o torna econômico para cargas de trabalho intermitentes ou variáveis. |
O preço é baseado no tamanho e no uso do cluster; o preço da instância reservada está disponível para consultas previsíveis e de alto volume. |
|
Desempenho |
Depende do tamanho e do formato dos dados; otimizado por particionamento e compactação; melhor para consultas menores e menos complexas. |
Alto desempenho para consultas complexas; usa armazenamento em colunas, processamento paralelo e otimização avançada para cargas de trabalho intensivas. |
|
Integração de dados |
Consulta diretamente os dados no S3 sem a necessidade de transformação ou carregamento; suporta vários formatos e conectores extensíveis, incluindo o Redshift. |
Ele exige que os dados sejam carregados no warehouse, integra-se aos serviços da AWS e oferece suporte a vários métodos de ingestão de dados, mas lê apenas os dados armazenados. |
É hora de você colocar a mão na massa, configurar o Athena e executar algumas consultas!
Para usar o AWS Athena, você precisa de uma conta do AWS. Se você não tiver um, deverá criar um. Para isso, siga as instruções do guia de configuração do AWS.
Embora não haja um nível gratuito para o AWS Athena, você deve ser capaz de executar de 2 a 3 consultas de teste pequenas (~10 MB de tamanho) para entender como o sistema funciona. Siga as instruções no portal e verifique sua identidade. Em seguida, faça login na sua conta do AWS.
Como todos os produtos Amazon AWS, o Athena utiliza políticas de IAM (gerenciamento de identidade e acesso) para permissões. Você será o usuário raiz da sua conta e deverá ter as permissões necessárias para executar consultas do Athena em seus próprios buckets do S3.
Você pode gerenciar as permissões de IAM pesquisando o serviço de IAM na barra de pesquisa superior do seu painel inicial do AWS e utilizando este guia completo de IAM. A documentação do AWS também fornece mais informações sobre a configuração específica do Athena.
Antes de executar as consultas, precisamos configurar um bucket S3 para armazenar nossos dados.
Amazon S3 significa Simple Storage Service (Serviço de Armazenamento Simples) e é um componente essencial de como o AWS gerencia o armazenamento e os dados no ambiente de nuvem. Seguindo este guia bem escrito sobre a criação de buckets do Amazon S3, podemos criar o ambiente de armazenamento para nossos dados e consultas.
Em resumo, você procurará o serviço S3 na barra de pesquisa para acessar a página inicial do S3:
Você verá um botão "Create Bucket" na barra lateral direita da página inicial. Seguindo as instruções desta página, você criará um bucket que permitirá que o serviço Athena armazene os resultados da consulta.
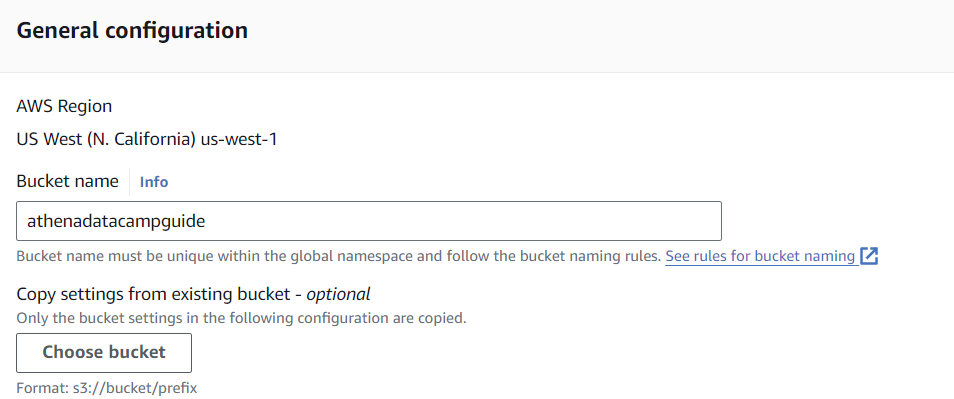
Criarei um bucket chamado "athenadatacampguide" usando todas as outras opções padrão. Como os buckets devem ser globalmente exclusivos na AWS, você deve escolher outro nome para este tutorial.
Agora, precisamos conectar esse bucket ao Athena. Vou acessar o console do Athena e clicar em "Edit Settings" (Editar configurações) na pequena barra de notificação próxima à parte superior.

Em seguida, selecionarei o bucket que acabei de criar. Para localizar seu bucket, use o botão "Browse S3" à direita ou digite o nome prefixado por "s3://".
Depois que o balde for selecionado, clique em "Save" (Salvar) e retorne-o ao Editor clicando nele na barra de ferramentas superior.

O AWS Athena organiza os dados de forma hierárquica. Ele utiliza "catálogos de dados", um grupo de bancos de dados também conhecido como esquema.
As tabelas reais que consultamos estão dentro dos bancos de dados. Para criar um novo catálogo de dados, você pode usar o Amazon Lambda e se conectar a uma fonte de dados externa. O catálogo de dados pode então ser salvo como um catálogo de dados Lambda, Hive ou Glue.
O padrão no AWS é usar o serviço Glue como o repositório central do catálogo de dados. Vamos nos concentrar na criação de um banco de dados que conterá nossas tabelas para consulta.
No Editor, vá para o painel Query Editor (Editor de consultas). É aqui que escreveremos nossas consultas para criar bancos de dados, consultar tabelas e executar análises.
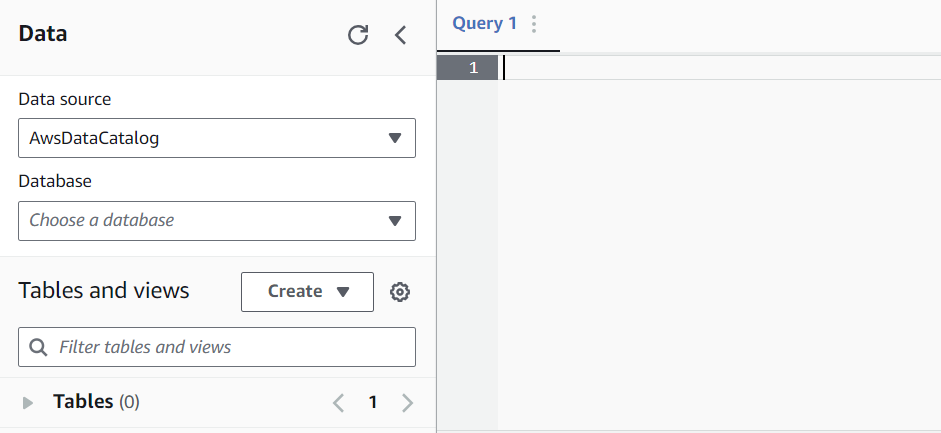
Para criar nosso primeiro banco de dados, executaremos a seguinte consulta:
CREATE DATABASE mydatabaseA execução dessa consulta permitirá que você selecione um banco de dados no menu suspenso abaixo de "Banco de dados" na barra lateral esquerda.
Agora que temos um banco de dados, vamos nos concentrar na criação de uma tabela para que você tenha algo para consultar!
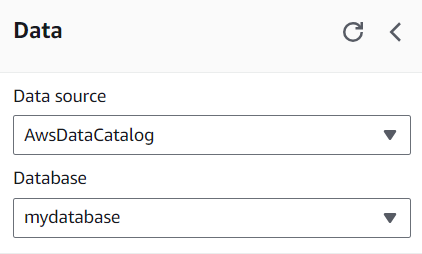
A obtenção de dados no banco de dados será um pouco diferente de acordo com a configuração do AWS. Você pode utilizar dados armazenados em um data warehouse como o Redshift ou dados de streaming utilizando o AWS Kinesis e o Lambda para gerar dados tabulares.
Hoje, usaremos dados de amostra de logs do AWS Cloudfront. Devido à complexidade dos dados, parte do processo de criação usa grupos RegEx para analisar os dados URl em colunas.
Usando o SQL a seguir, podemos criar uma tabela. Observação: abaixo, substitua "myregion" pela sua região da AWS.
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (
Date DATE,
Time STRING,
Location STRING,
Bytes INT,
RequestIP STRING,
Method STRING,
Host STRING,
Uri STRING,
Status INT,
Referrer STRING,
os STRING,
Browser STRING,
BrowserVersion STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)Se a tabela aparecer na barra lateral esquerda, você está pronto para começar a fazer consultas!
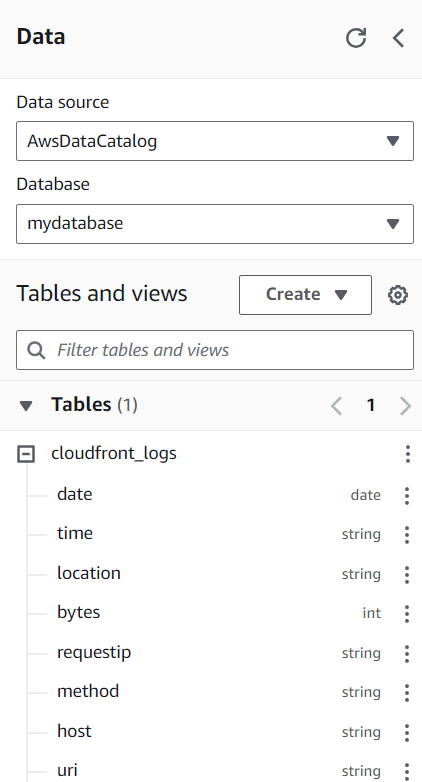
Ao escrever consultas no Athena, você se assemelha a escrever consultas no SQL tradicional. Você simplesmente escreve e envia a consulta ao Athena, e os resultados desejados são retornados.
Uma prática recomendada é escrever suas declarações FROM com a seguinte sintaxe: "DataSource". "banco de dados". "tabela". Dessa forma, nunca haverá confusão sobre a origem dos dados.
Vamos tentar uma declaração simples em SELECT para você começar.
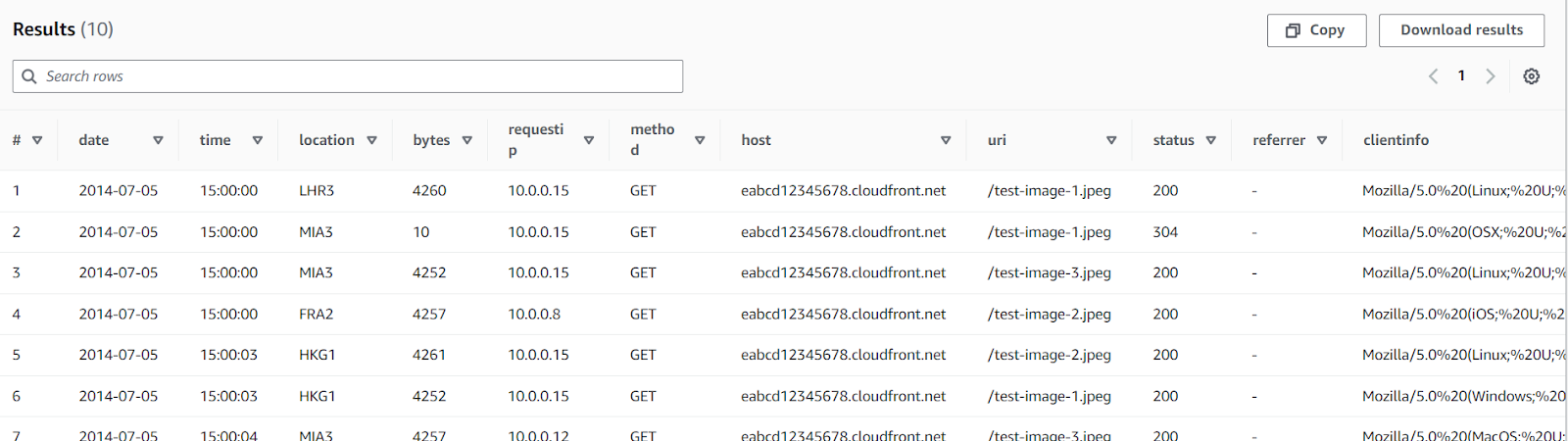
SELECT *
FROM "AwsDataCatalog"."mydatabase"."cloudfront_logs"
LIMIT 10Isso deve retornar uma tabela com 10 resultados. O Athena permite que você copie ou faça download dos resultados. Ao mesmo tempo, esses resultados são salvos no bucket S3 que você conectou ao seu serviço Athena.
Você pode até mesmo escrever consultas simples no site GROUP BY. Este, em particular, nos permite saber quantos requestip (não necessariamente exclusivos) estavam envolvidos com métodos HTTP específicos.
SELECT
method,
COUNT(requestip)
FROM "AwsDataCatalog"."mydatabase"."cloudfront_logs"
GROUP BY 1Uma ótima maneira de utilizar o Athena é para consultas mais complexas, como funções de janela. Graças à otimização do Athena, podemos realizar cálculos complicados com mais rapidez.
Por exemplo, podemos usar o Athena para gerar o ROW NUMBER() para cada registro particionado por sua região e data organizada por ordem decrescente de tempo. Em seguida, podemos selecionar o registro mais recente para cada região e data usando um filtro WHERE para selecionar a primeira linha.
SELECT *
FROM (
SELECT
location,
date,
time,
ROW_NUMBER() OVER(PARTITION BY location, date ORDER BY time DESC) row_num
FROM "AwsDataCatalog"."mydatabase"."cloudfront_logs"
)
WHERE row_num = 1
Isso é apenas o começo com a Athena. Você pode continuar a escrever qualquer consulta que acredite permitir que você aproveite os recursos do Athena.
O AWS Athena requer uma série de práticas recomendadas, como qualquer outra ferramenta de processamento de dados. Essas práticas não apenas facilitarão sua vida, mas também melhorarão seu desempenho.
Além disso, como o AWS é um serviço baseado em nuvem e os usuários são cobrados com base em vários fatores de armazenamento e computação, essas práticas podem levar a uma economia significativa de custos!
Vários formatos de dados são mais úteis para você utilizar no AWS Athena. Como o Athena extrai dados de um bucket S3, a escolha de um formato de dados que seja fácil de ler e compactado melhorará o desempenho e o custo.
Os dados brutos armazenados em CSV podem ser os mais simples, mas ineficientes. O armazenamento de nossos dados em um formato compactado, como o formato Parquet ou ORC, economizará os custos de leitura de dados.
Um benefício adicional do Parquet e do ORC é sua compactação baseada em colunas. O otimizador do Athena permite que você procure apenas por colunas de dados específicas em vez de trabalhar em toda a tabela para realizar cálculos.
Particionar dados significa dividir regularmente um conjunto de dados com base em uma chave específica, como uma data. Por exemplo, podemos ter partições diárias em que os dados são configurados para serem automaticamente divididos e armazenados por dias.
Quando nossos dados são particionados, o mecanismo SQL pode realizar uma otimização melhor, analisando as partições relevantes. Isso leva a uma melhoria direta na redução da quantidade de dados digitalizados, reduzindo o custo geral.
Embora seja esperada alguma complexidade ao realizar a análise de dados, a otimização das consultas pode ajudar a reduzir o tempo e o custo computacional. Alguns dos custos não são diretamente do Athena, mas de outros serviços que o AWS Athena utiliza.
O principal componente do custo do Athena é a digitalização e o processamento de dados, mas você pode incorrer em custos do S3 se salvar resultados enormes. Também podemos melhorar o desempenho da consulta e reduzir os custos, garantindo que as consultas sejam otimizadas de acordo com as práticas recomendadas usuais de SQL.
Por exemplo, todos os itens a seguir ajudarão na otimização:
SELECT * sempre que possívelLIMIT ao testar as consultasEssas práticas recomendadas melhorarão o desempenho da consulta e reduzirão os custos!
O AWS Athena pode se conectar ao Amazon CloudWatch para armazenar métricas de consulta. Podemos descobrir consultas ou problemas ineficientes observando os registros de desempenho de consultas.
Como mencionado, o AWS Athena se integra a vários outros serviços da AWS, aprimorando seus recursos de catalogação, visualização, processamento e warehouse de dados.
Veja abaixo como o Athena funciona com serviços como o AWS Glue, o Amazon QuickSight, o AWS Lambda e o Amazon Redshift.
Quando integrado ao AWS Athena, o AWS Glue é um repositório central de metadados que cataloga automaticamente os dados no Amazon S3. Essa integração elimina a necessidade de definições manuais de esquema, simplificando a consulta de dados no Athena.
O Glue também oferece recursos de ETL, transformando e preparando os dados para uma consulta otimizada no Athena, automatizando tarefas como compactação de dados, particionamento e conversão de formatos, garantindo um processamento de dados eficiente e eficaz.
O Amazon QuickSight se integra ao AWS Athena para transformar os resultados da consulta em painéis e relatórios interativos. Essa conexão permite que você visualize dados diretamente das consultas do Athena, possibilitando a criação rápida e fácil de insights visuais.
O QuickSight oferece suporte a recursos como atualizações automáticas de dados e análises avançadas, o que o torna uma ferramenta avançada para explorar e apresentar dados.
O AWS Lambda automatiza os fluxos de trabalho de processamento de dados com o Athena em um ambiente sem servidor. As funções Lambda podem acionar as consultas do Athena em resposta a eventos, como novos dados no S3, permitindo o processamento em tempo real.
O Lambda também pode automatizar ações subsequentes com base nos resultados da consulta, criando fluxos de trabalho dimensionáveis e orientados por eventos sem intervenção manual.
Embora o Athena seja ideal para consultas ad-hoc de dados S3, o Amazon Redshift oferece uma solução de análise robusta, estruturada e complexa. Você pode usar o Athena para análise rápida de dados brutos e o Redshift para consultas mais intensas e de alto desempenho.
A integração permite a movimentação de dados entre o S3 e o Redshift, aproveitando os pontos fortes de ambos os serviços para uma solução de análise abrangente.
O AWS Athena é um mecanismo de consulta avançado incorporado diretamente ao ecossistema do AWS. Ao permitir que os usuários acessem rapidamente os dados armazenados nos buckets do S3 e salvem os resultados da consulta nos buckets do S3, o AWS Athena permite que os usuários mergulhem em seus dados com mais flexibilidade. Ele colhe os benefícios de outros serviços da AWS, como ser sem servidor, escalável e direto.
Se você quiser saber mais sobre a AWS, a DataCamp oferece vários recursos:
Saiba mais sobre a AWS e a engenharia de dados com estes cursos!
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita
Tutorial
Sejal Jaiswal