Programa
Engenheiro de dados Em Python
40 h
Os dados são a base das organizações modernas, mas o grande volume de informações coletadas e armazenadas pode ser um desafio para você gerenciar. A chave do sucesso está em organizar e analisar esses dados de forma eficaz para descobrir insights valiosos que impulsionem a tomada de decisões informadas.
É nesse ponto que entra o armazenamento de dados. É uma solução poderosa que permite que as empresas consolidem e otimizem seus dados para uma análise eficiente. E quando se trata de armazenamento de dados, o AWS Redshift se destaca como uma das principais opções.
Neste artigo, exploraremos os detalhes do AWS Redshift, juntamente com seus principais recursos, benefícios e práticas recomendadas para configuração, carregamento de dados, consultas, ajuste de desempenho, segurança e integrações.
Se você é um profissional de dados ou um líder de negócios que deseja aproveitar ao máximo seus dados, este artigo fornecerá o conhecimento e as ferramentas de que você precisa para ter sucesso com o AWS Redshift.
O armazenamento de dados é um processo de coleta, armazenamento e gerenciamento de grandes quantidades de dados estruturados de várias fontes em uma organização.
O principal objetivo de um data warehouse é fornecer um repositório centralizado de informações que possa ser facilmente acessado, analisado e usado para fins de relatórios e tomada de decisões.
Os data warehouses são projetados para dar suporte a consultas e análises de dados complexas, permitindo que as empresas obtenham insights valiosos de seus dados.
A adoção de um data warehouse pode proporcionar às organizações um número significativo de benefícios:
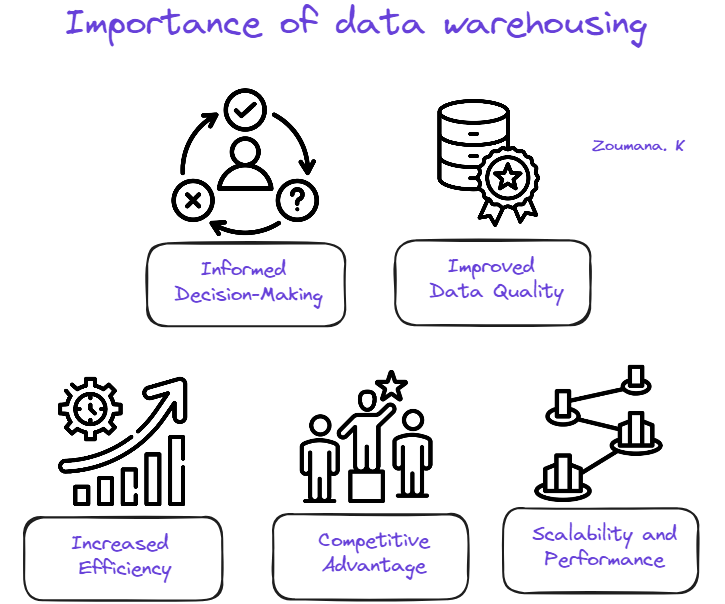
Importância do armazenamento de dados
O AWS Redshift é um serviço de armazenamento de dados totalmente gerenciado e baseado em nuvem que permite o armazenamento e a análise de conjuntos de dados em escala de petabytes. Com o AWS Redshift Serverless, os usuários podem acessar e analisar dados sem a necessidade de configuração manual de um data warehouse provisionado.
Amazon Redshift (Source)
O serviço provisiona automaticamente os recursos e dimensiona de forma inteligente a capacidade do data warehouse para garantir um desempenho rápido, mesmo para as cargas de trabalho mais exigentes e imprevisíveis. Os usuários pagam apenas pelos recursos que utilizam, pois não há cobranças quando o data warehouse está ocioso.
O AWS Redshift permite que os usuários carreguem dados e comecem a fazer consultas imediatamente usando o editor de consultas v2 do Amazon Redshift ou a ferramenta de business intelligence (BI) de sua preferência. O serviço oferece a melhor relação preço-desempenho e recursos SQL familiares em um ambiente de administração zero e fácil de usar.
Independentemente do tamanho do conjunto de dados, o AWS Redshift oferece desempenho de consulta rápido usando as mesmas ferramentas baseadas em SQL e aplicativos de business intelligence que são comumente usados atualmente.
O AWS Redshift oferece vários recursos e benefícios para ajudar as organizações a armazenar, gerenciar e analisar com eficiência grandes volumes de dados. Alguns dos principais recursos e benefícios estão ilustrados abaixo:

Recursos e benefícios do AWS Redshift
As seções anteriores se concentraram principalmente em uma compreensão geral do Redshift. Agora, vamos explorar os aspectos técnicos.
Esta seção primeiro ilustra os principais pré-requisitos para configurar o AWS Redshift com êxito e, em seguida, apresenta um processo passo a passo de criação de um cluster do Redshift antes. A última parte se concentra mais na explicação detalhada das principais configurações do cluster, como tipos de nós, número de nós e configuração de segurança.
Antes de nos aprofundarmos nos detalhes do caso de uso, vamos primeiro analisar os pré-requisitos necessários para uma implementação bem-sucedida:
Esta seção fornece todas as etapas para criar um cluster do Redshift por meio do AWS Management Console em 11 etapas simples, conforme ilustrado abaixo:
1. Pesquise Redshift no console e selecione "Amazon Redshift":
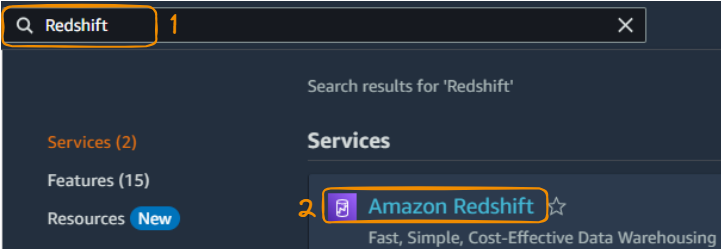
Pesquise e selecione Redshift no Management Console
2. Selecione o botão "Create Cluster" para começar a criar um cluster.
Botão Criar cluster
3. A partir da ação acima, podemos configurar o cluster fornecendo informações como o identificador do cluster, o tamanho do cluster, o tipo de nó, a escolha da zona de disponibilidade e o número de nós.
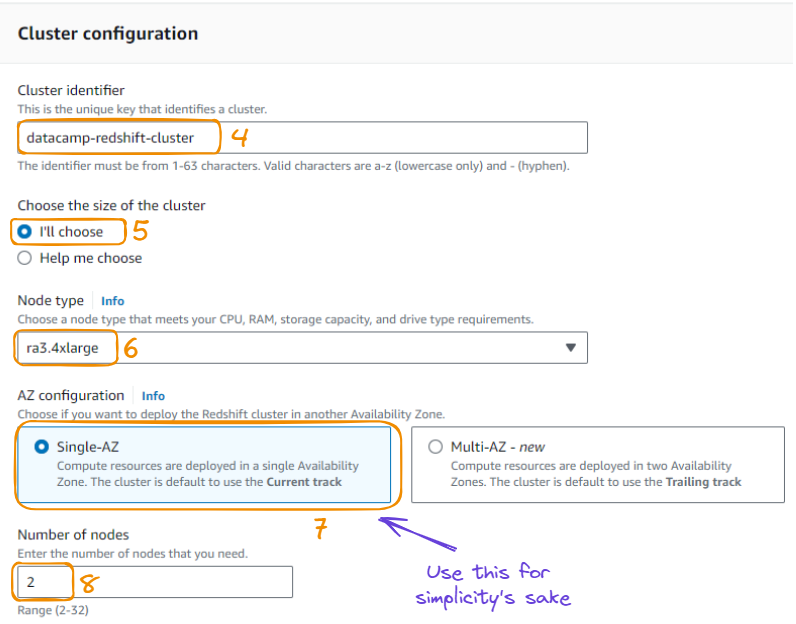
Configuração do cluster em 8 etapas
4. Em vez de usar dados de amostra, conforme sugerido na mesma página acima, estamos usando dados de um bucket do S3 para carregar dados no Redshift.
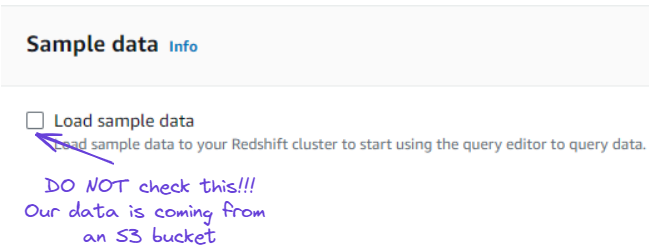
Ignorar a opção de carregar dados de amostra
5. Temos a opção de definir a permissão dos clusters fornecendo funções de IAM. Essa seção pode ser ignorada e abordada no futuro.
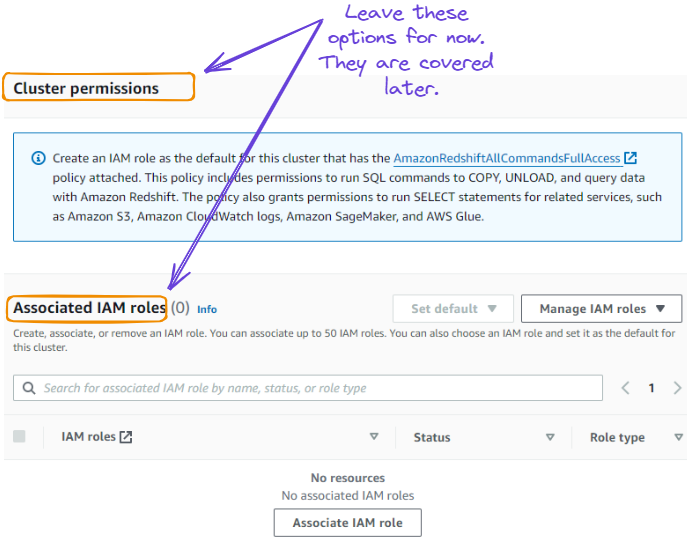
Ignorar permissões de cluster e funções de IAM
6. Deixe as configurações padrão de rede, segurança, backup, manutenção e selecione o botão "Create cluster" (Criar cluster) para criar o cluster.
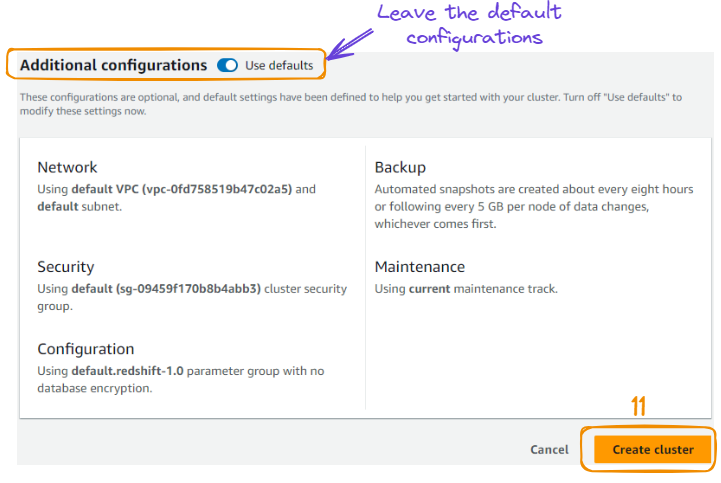
Criação do cluster
7. Após a ação acima, somos redirecionados para uma nova página que mostra o cluster recém-criado. Isso pode levar alguns minutos para criar o cluster com êxito e pode ser visto na seção "Status", que primeiro é "Creating" (Criando) antes de se tornar "Available" (Disponível).
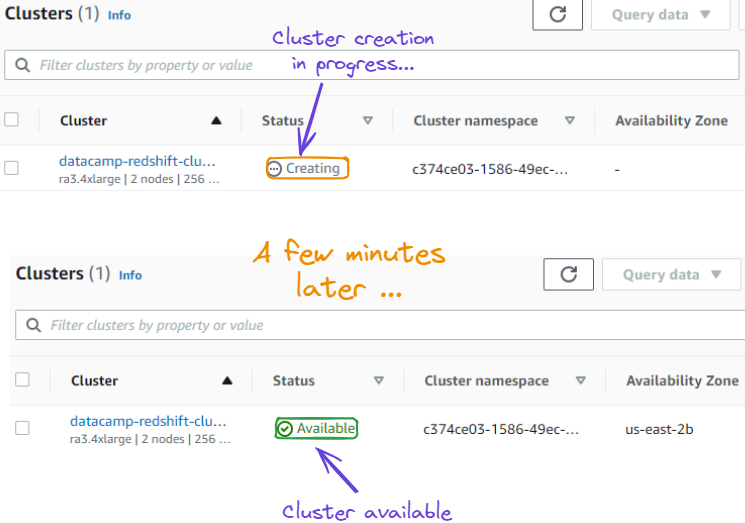
Estado do cluster de "Criando" para "Disponível"
Agora, criamos com sucesso nossos clusters do Redshift. Esta seção orienta você em todas as etapas, desde a escolha do conjunto de dados do PIB (Produto Interno Bruto) nacional, regional e mundial disponível em nosso DataLab até o upload em um bucket S3.
Nossos dados são originalmente provenientes do conjunto de dados do Banco Mundial. Trata-se do PIB de países, regiões e do mundo medido em dólares americanos ($) atuais. As regiões se referem a conjuntos de países, como a Europa e a Ásia Central.
As primeiras dez observações dos dados são assim:
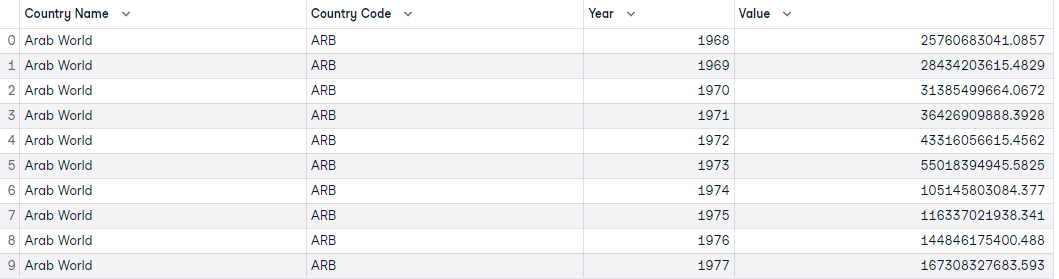
As dez primeiras observações dos dados do PIB
Para uma interação bem-sucedida entre o S3 e o Redshift, precisamos primeiro criar uma função IAM antes de criar um bucket S3 para armazenar dados.
A vantagem de criar uma função IAM é que ela cria uma conexão entre o nosso cluster Redshift e o bucket S3 onde os dados residem.
A criação da função de IAM é realizada da seguinte forma:
No Management Console, pesquise por "IAM" e selecione o logotipo "IAM" no resultado da pesquisa.
Serviço IAM do console de gerenciamento
Selecione "Roles" (Funções) para exibir todas as funções possíveis e escolha "Create role" (Criar função) para criar uma nova função.
Comece a criar uma nova função
Escolha "Serviço AWS" em "Tipo de entidade confiável", depois "Redshift" como "Caso de uso" e "Avançar" para continuar.
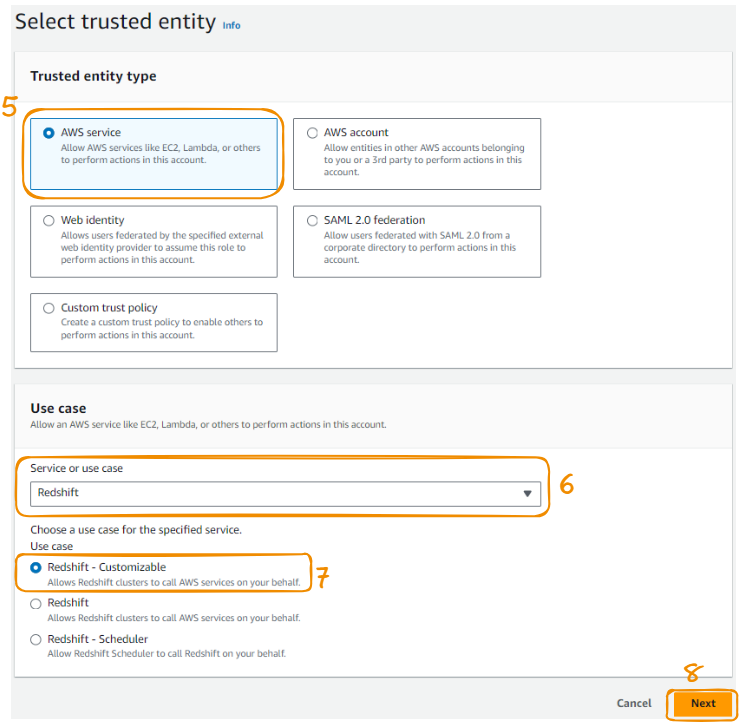
Etapas 5 a 8 da criação da função AMI
Localize "S3FullAccess" na guia de pesquisa, marque a opção e selecione "Next" (Avançar).
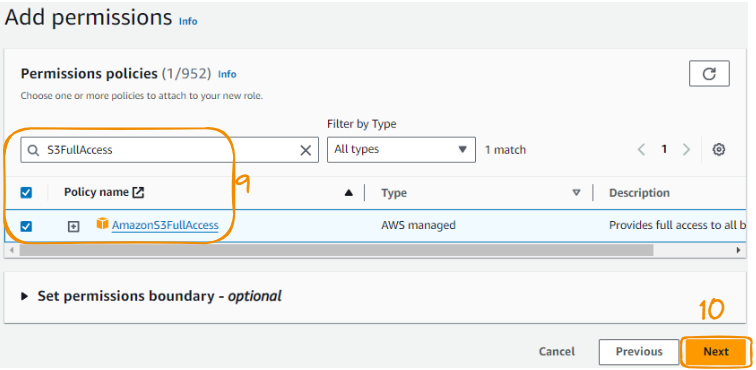
Etapas 9 a 10 da criação da função AMI
Por fim, nomeie a função, revise-a e selecione o botão "Criar função" para finalizar a criação da função.
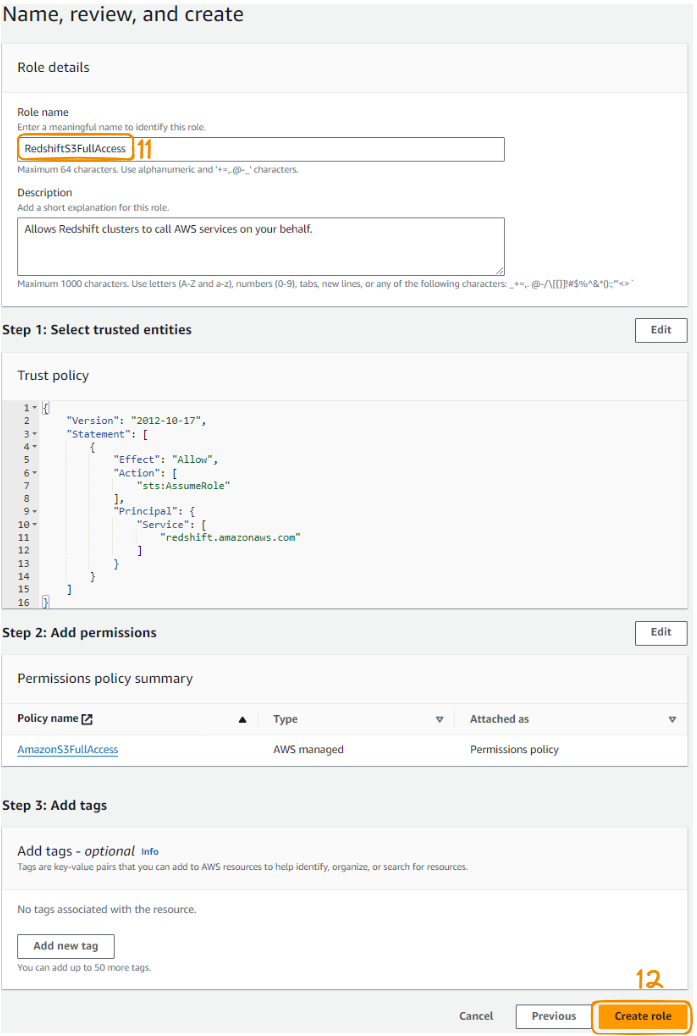
Etapas 11 a 12 da criação da função AMI
Quando tudo for bem-sucedido, a seguinte mensagem verde confirmando a criação da função será exibida no canto superior.

Mensagem de confirmação de criação de função
Agora que temos a função IAM, ela pode ser usada para vincular o cluster do Redshift criado inicialmente, e isso pode ser feito da seguinte forma:
Na seção de clusters, selecione o cluster do DataCamp criado e, na seção "Ações", escolha "Gerenciar funções do IAM".
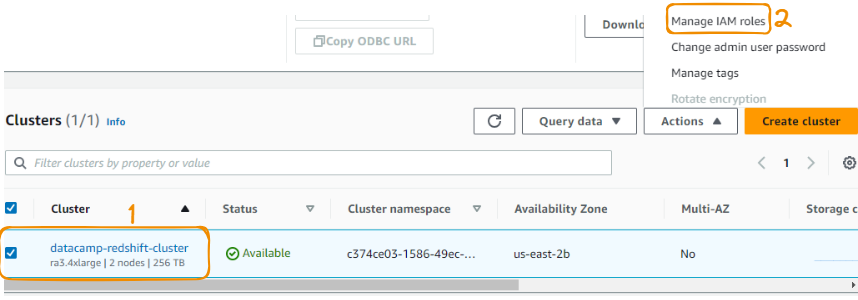
Vincular a função IAM ao Redshift - etapas 1 a 2
Nessa seção, escolha a função de IAM criada anteriormente e salve as alterações.
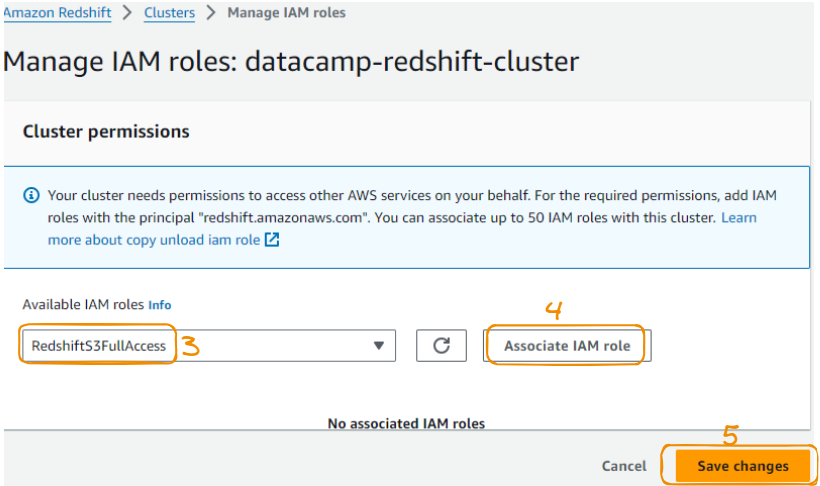
Vincular a função IAM ao Redshift - etapas 3 a 4
Várias ferramentas podem ser usadas para consultar dados do Redshift. Algumas dessas ferramentas podem fazer parte dos serviços da AWS ou ser externas. No escopo deste tutorial, estamos usando o editor de consultas do Redshift Dashboard.
Para que você possa usá-lo, primeiro precisamos criar uma conexão com o editor de consultas da seguinte forma, começando pela opção "Query in query editor" (Consultar no editor de consultas) na guia "Query data" (Dados da consulta):
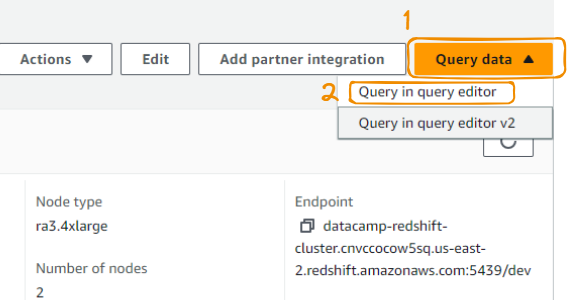
Editor de consultas a partir de dados de consulta
A ação acima leva à página a seguir, onde podemos nos conectar ao banco de dados depois de dar a ele um nome, juntamente com um nome de usuário, como segue:
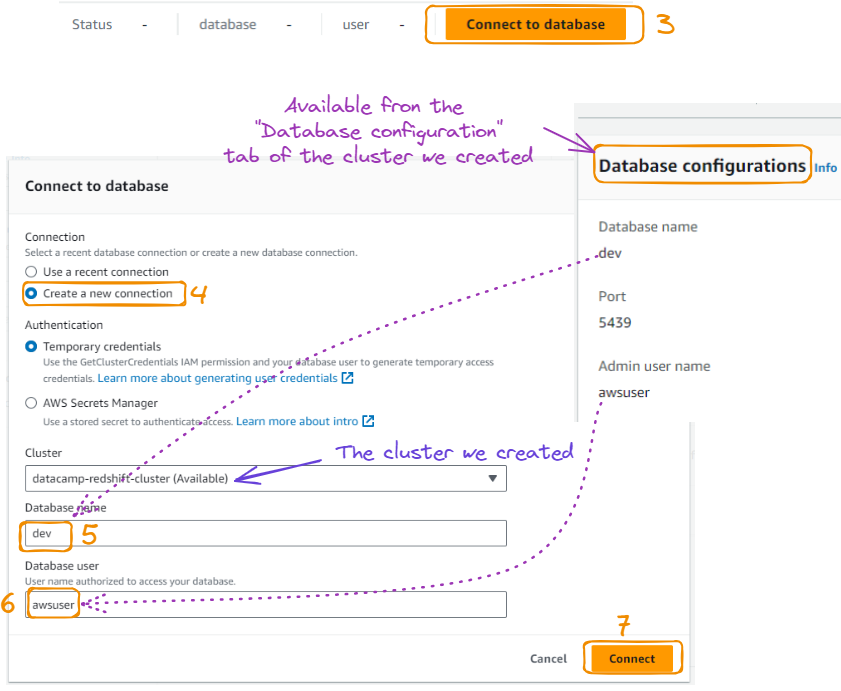
Conexão com o banco de dados do editor de consultas
Depois de pressionar o botão "Connect" (Conectar), você verá a guia verde "Connected" (Conectado) na parte superior e as informações do banco de dados à esquerda.
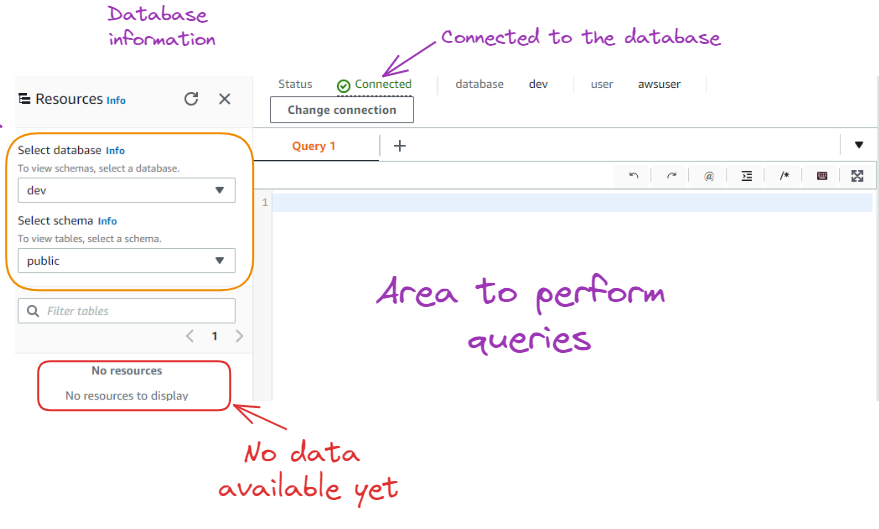
Resultado após a conexão com o banco de dados
Como podemos ver acima, ainda não há recursos/dados disponíveis no banco de dados. Antes de importar dados, primeiro precisamos criar uma tabela com as mesmas características dos dados que estão sendo importados.
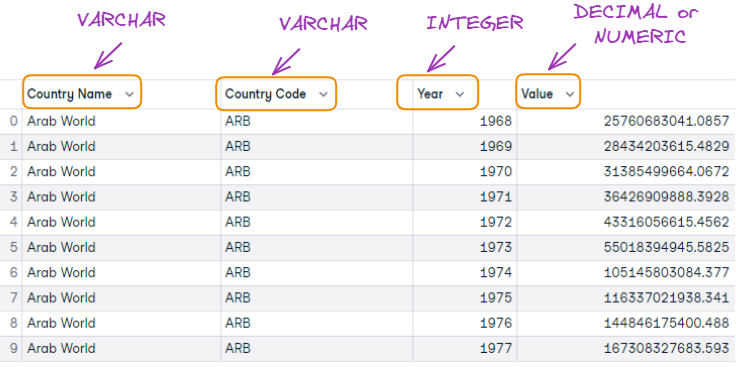
As primeiras 10 observações e o formato das colunas da tabela correspondem a você.
A tabela é criada usando a seguinte consulta SQL:
CREATE TABLE gdp_data (
id INTEGER PRIMARY KEY,
country_name VARCHAR(255),
country_code VARCHAR(10),
year INTEGER,
value DECIMAL(20,2)
);Aqui está uma explicação da consulta SQL em um ponto para cada coluna:
id INTEGER PRIMARY KEY: Cria uma coluna chamada "id" com o tipo de dados INTEGER e a define como a chave primária da tabela, garantindo valores exclusivos para cada linha.country_name VARCHAR(255): Cria uma coluna chamada "country_name" com o tipo de dados VARCHAR, permitindo o armazenamento de cadeias de até 255 caracteres.country_code VARCHAR(10): Cria uma coluna chamada "country_code" com o tipo de dados VARCHAR, permitindo o armazenamento de cadeias de até 10 caracteres.year INTEGER: Cria uma coluna chamada "year" com o tipo de dados INTEGER, adequado para armazenar números inteiros (nesse caso, anos).value DECIMAL(20,2): Cria uma coluna chamada "value" com o tipo de dados DECIMAL, permitindo o armazenamento de números decimais com uma precisão de 20 dígitos e 2 casas decimais.Agora, executamos a consulta para criar a tabela:
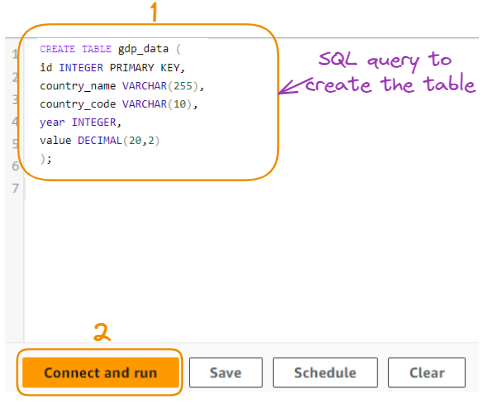
Consulta para criar a tabela
Essa consulta cria uma tabela chamada "gdp_data" com as colunas especificadas para armazenar dados do PIB, conforme mostrado abaixo:
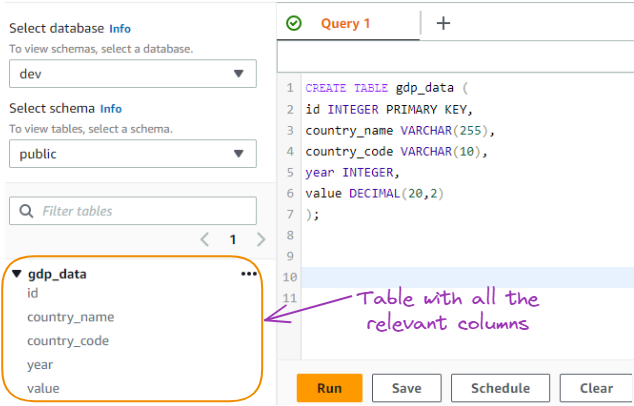
Tabela de dados do PIB criada a partir de uma consulta SQL
Os dados serão importados para a tabela a partir de um bucket S3. Nesta seção, abordamos todas as etapas da criação do bucket e do upload dos dados.
Localize o serviço S3 no Management Console, selecione o logotipo correspondente e dê um nome a ele, deixando todo o resto como padrão:
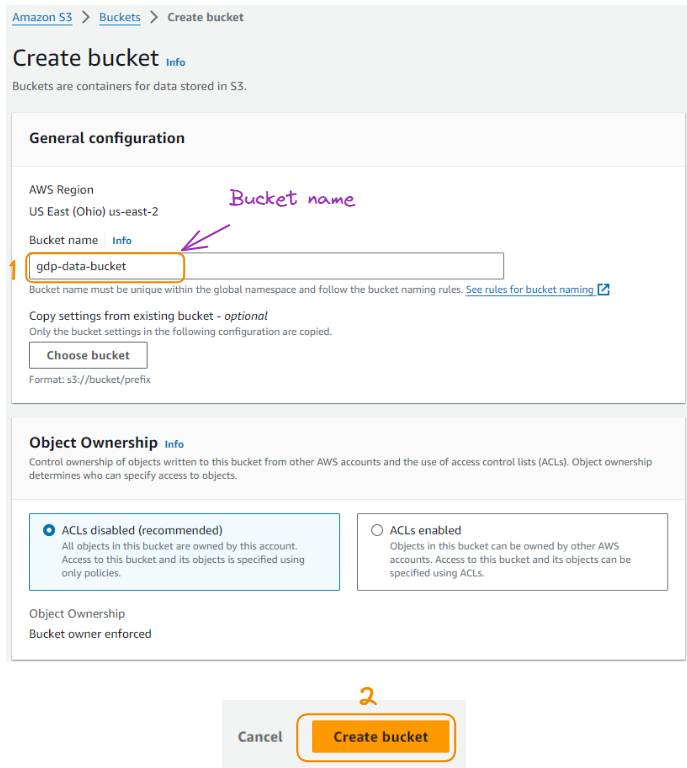
Criação de bucket S3
Depois que o compartimento é criado, ele fica disponível na lista de todos os compartimentos criados no passado.
O balde recém-criado
A partir daí, você pode selecionar o nome do intervalo e carregar os dados do PIB baixados localmente em um formato CSV.
Página para carregar dados no bucket
Após a importação bem-sucedida dos dados, eles ficam disponíveis conforme mostrado abaixo:
O CSV carregado no bucket
Parabéns por você ter chegado até aqui!
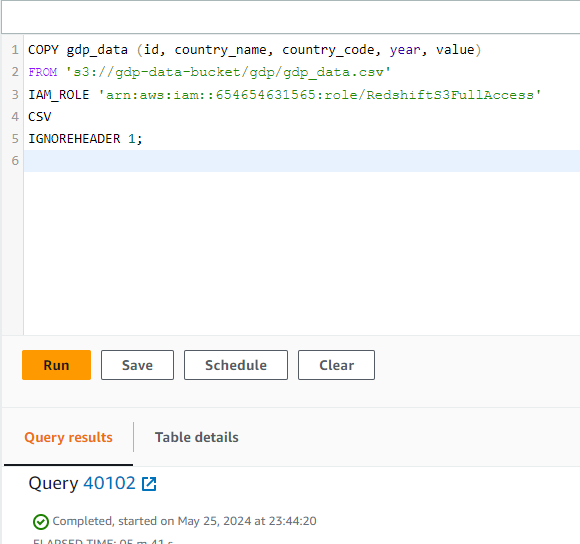
Esta seção ilustra como copiar os dados do S3 para o Redshift da seguinte forma.
COPY gdp_data (id, country_name, country_code, year, value)
FROM 's3://gdp-data-bucket/gdp/gdp_data.csv'
IAM_ROLE 'arn:aws:iam::654654631565:role/RedshiftS3FullAccess'
CSV
IGNOREHEADER 1;Vamos entender o que está acontecendo aqui:
O mesmo código do editor é fornecido abaixo, e a operação de cópia foi realizada com sucesso após alguns segundos:
Tarefa COPY concluída
Em vez de carregar todos os dados do CSV original, apenas uma amostra aleatória de cem observações foi carregada para simplificar. Você pode ter uma visualização dos dados selecionando a opção "Preview data" (Visualizar dados) da seguinte forma:
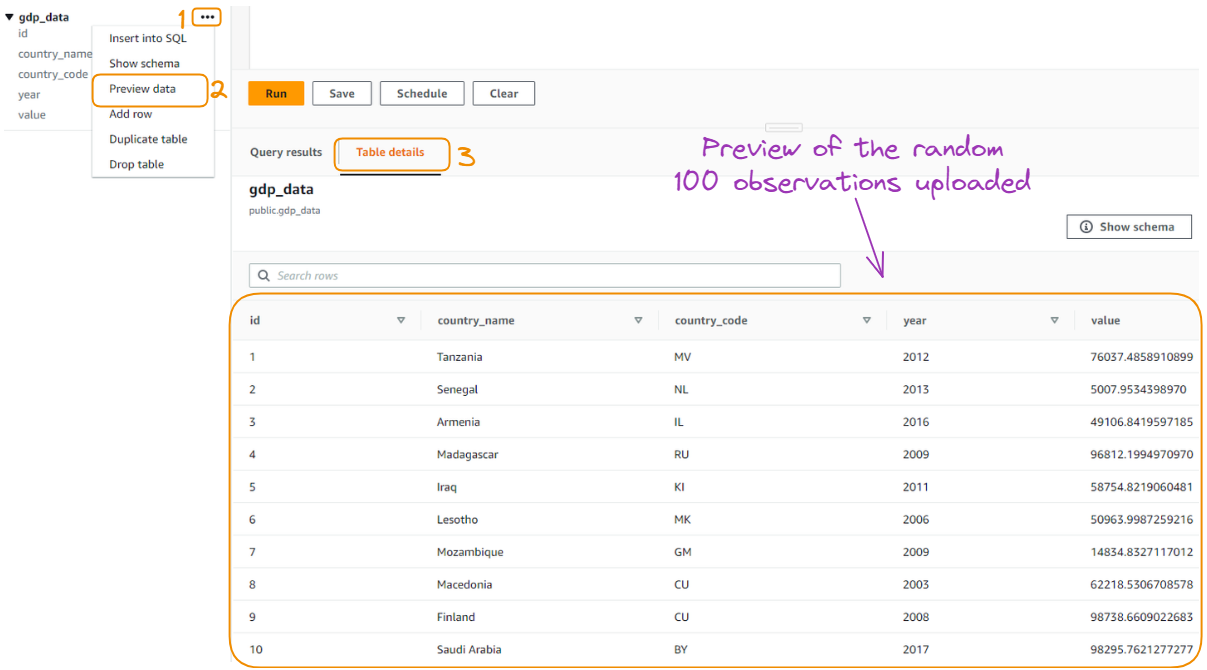
Visualização das 100 observações carregadas aleatoriamente
A visualização dos dados exibe apenas as primeiras dez observações dos dados. No entanto, talvez você queira interagir mais com os dados para obter mais informações, e é nesse ponto que pode ser útil ter habilidades em SQL.
Nesta seção, exploramos os dados por meio de algumas consultas SQL para explorar os dados.
Estamos usando cinco consultas SQL para interagir com os dados armazenados em nosso banco de dados, começando com a consulta mais comumente usada: selecionar os dados.
Selecionar todos os dados
SELECT *
FROM gdp_data;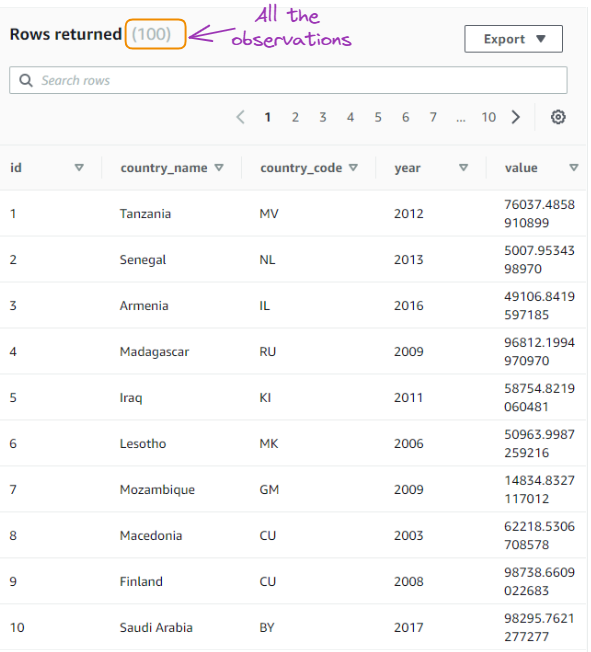
Resultado da primeira consulta
Selecione dados para um país específico:
SELECT * FROM gdp_data
WHERE country_name = 'Senegal';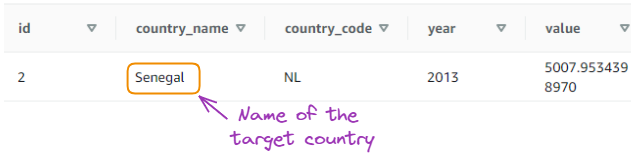
Resultado da segunda consulta
Calcule o valor médio do PIB para um ano específico:
SELECT year, AVG(value) as average_gdp
FROM gdp_data
WHERE year = 2020
GROUP BY year;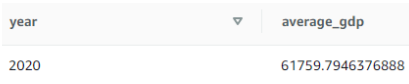
Resultado da terceira consulta
Encontre os 5 principais países com o maior PIB em um ano específico:
SELECT country_name, value
FROM gdp_data
WHERE year = 2020
ORDER BY value DESC
LIMIT 5;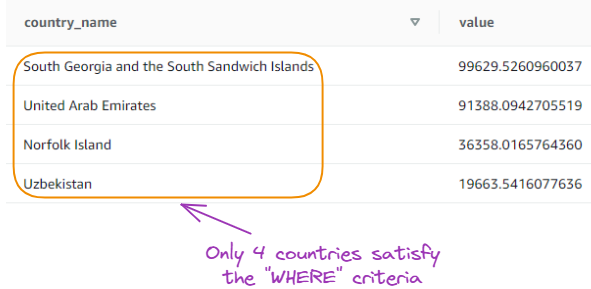
Resultado da quarta consulta
Conte o número de registros por ano:
SELECT year, COUNT(*) as record_count
FROM gdp_data
GROUP BY year
ORDER BY year;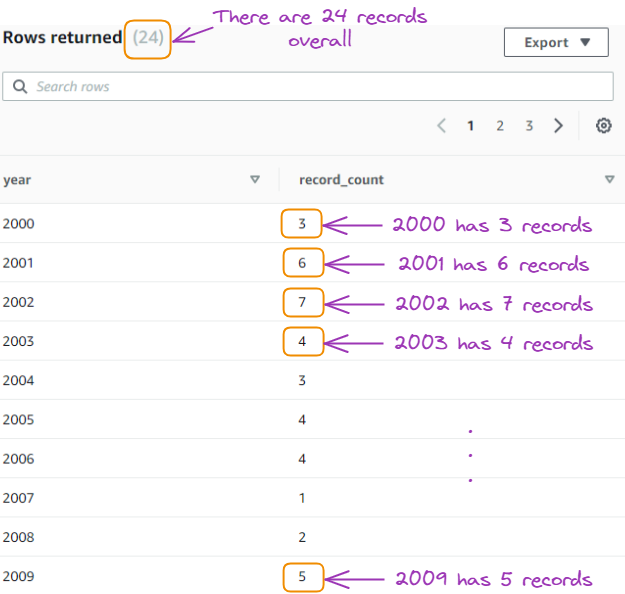
Resultado da quinta consulta
As consultas acima forneceram uma compreensão básica dos dados, e esta seção se concentra em abordar três técnicas avançadas de consulta.
Cálculo do total em execução: Essa consulta calcula o total em execução dos valores do PIB para cada país, ordenados por ano.
SELECT
country_name,
year,
value,
SUM(value) OVER (PARTITION BY country_name ORDER BY year) as running_total
FROM gdp_data;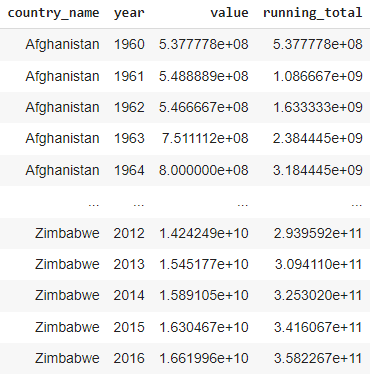
Resultado do total em execução
CTFs para filtragem e agregação: essa consulta usa um CTE para filtrar os dados e incluir apenas registros a partir do ano de 2020 e, em seguida, calcula o valor médio do PIB para cada país.
WITH recent_data AS (
SELECT
country_name,
year,
value
FROM gdp_data
WHERE year >= 2020
)
SELECT
country_name,
AVG(value) as average_gdp
FROM gdp_data
GROUP BY country_name;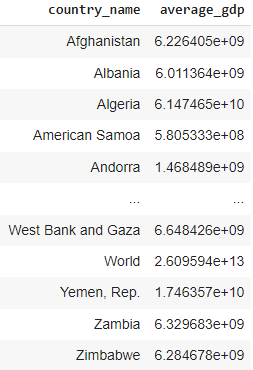
Resultado dos CTEs
Calcular o crescimento do PIB ano a ano: com essa consulta, calculamos o crescimento do PIB ano a ano para cada país.
SELECT
a.country_name,
a.year,
a.value as current_year_value,
b.value as previous_year_value,
(a.value - b.value) / b.value * 100 as growth_percentage
FROM gdp_data a
JOIN gdp_data b
ON a.country_name = b.country_name
AND a.year = b.year + 1;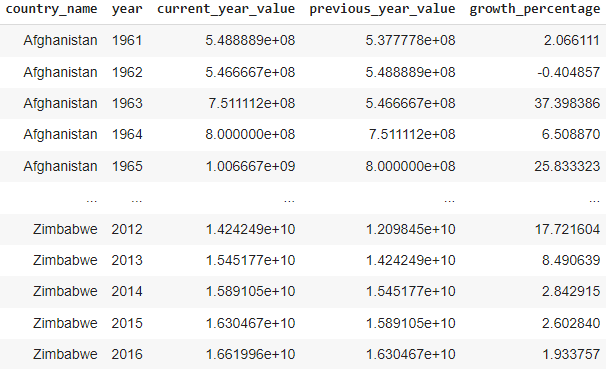
Resultado da consulta de junção automática
Para garantir um desempenho ideal e uma boa relação custo-benefício, é essencial entender os fatores que influenciam o desempenho do Redshift e implementar as práticas recomendadas para ajustar nosso cluster.
Nesta seção, exploraremos os principais aspectos do ajuste de desempenho do Redshift e forneceremos insights com base nas informações de cluster fornecidas.
O desempenho no Amazon Redshift é influenciado por vários fatores, desde as configurações de hardware até as técnicas de otimização de consultas, portanto, compreender esses fatores é fundamental para identificar gargalos e tomar decisões melhores para aprimorar o desempenho do nosso cluster.
Configuramos um cluster Redshift que consiste em dois nós ra3.4xlarge, e os dados que estão sendo usados são de apenas 391 KB.
Além disso, a imagem a seguir revela que a utilização da CPU do nosso cluster permanece próxima de 0% durante todo o período, indicando que o cluster não está sendo muito utilizado e pode estar com excesso de provisionamento para nossa carga de trabalho atual.

Utilização da CPU de nosso cluster
Vários fatores importantes que afetam o desempenho do Redshift incluem:
Para otimizar o desempenho do nosso cluster, é importante que você siga as práticas recomendadas de design de tabelas e gerenciamento de dados. Mesmo com um conjunto de dados pequeno, a implementação dessas práticas pode estabelecer uma base sólida para o crescimento futuro e a eficiência do desempenho.
O monitoramento e a manutenção regulares do cluster são essenciais para garantir o desempenho ideal e a eficiência de custo. A imagem a seguir fornece um detalhamento de nossos custos mensais do Redshift, revelando oportunidades de otimização de custos.
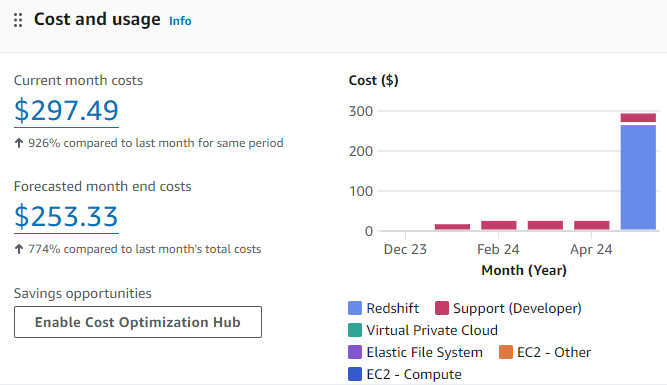
Gráfico de custo e uso para o caso de uso atual do Redshift
Com base na imagem acima, nosso cluster Redshift parece estar provisionado em excesso para nosso pequeno conjunto de dados atual, resultando em baixa utilização e ineficiências de custo.
Usando as ferramentas do AWS, como o Amazon CloudWatch e o AWS Management Console, podemos monitorar as principais métricas de desempenho, incluindo a utilização da CPU e o desempenho da consulta. Esses insights podem nos ajudar a identificar possíveis problemas e tomar decisões baseadas em dados para a otimização do cluster.
Dada a baixa utilização do nosso cluster, podemos considerar as seguintes estratégias de otimização de custos:
À medida que o volume de dados aumenta e a carga de trabalho evolui, monitore continuamente o desempenho do cluster e reavalie o dimensionamento da instância e as estratégias de otimização de acordo.
Ao trabalhar com dados confidenciais no Amazon Redshift, é importante garantir os mais altos padrões de segurança e conformidade. Como as organizações enfrentam exigências regulatórias cada vez maiores e a necessidade de proteger informações confidenciais, a implementação de medidas de segurança robustas e a adesão às diretrizes de conformidade tornam-se aspectos essenciais do gerenciamento do nosso cluster Redshift.
A conformidade com as normas específicas do setor e com as leis de proteção de dados é uma das principais prioridades das organizações que lidam com dados confidenciais. O Amazon Redshift oferece recursos e capacidades que nos ajudam a atender a esses requisitos de conformidade de forma eficaz.
Além das considerações de conformidade, a implementação de práticas recomendadas de segurança de dados no Amazon Redshift é crucial para proteger suas informações confidenciais contra acesso não autorizado e possíveis violações.
Práticas recomendadas para segurança de dados
A realização de auditorias de segurança regulares é essencial para identificar vulnerabilidades, avaliar a eficácia das medidas de segurança existentes e garantir a conformidade contínua. Considere as seguintes práticas de auditoria:
O mascaramento de dados é uma técnica que envolve o mascaramento de elementos de dados confidenciais, preservando a estrutura e o formato dos dados. Ao mascarar informações confidenciais, podemos protegê-las contra acesso não autorizado e manter a privacidade dos dados. Abaixo estão algumas abordagens para mascarar dados no Amazon Redshift:
A implementação de mecanismos robustos de controle de acesso é essencial para garantir que somente indivíduos autorizados possam acessar dados confidenciais em nosso cluster do Amazon Redshift. Esses mecanismos podem ser aplicados da seguinte forma:
Neste artigo, exploramos os aspectos fundamentais e avançados do uso do Amazon Redshift para armazenamento de dados. Começamos entendendo a importância do armazenamento de dados e como o Amazon Redshift oferece uma solução poderosa, escalável e econômica para analisar grandes conjuntos de dados usando SQL.
Em seguida, percorremos o processo de configuração de um cluster do Amazon Redshift, incluindo os pré-requisitos, a criação do cluster e as definições de configuração. Também nos aprofundamos nos detalhes do carregamento de dados no Redshift usando o AWS S3 e o comando COPY, fornecendo exemplos e explicações de sintaxe.
Além disso, abordamos os fundamentos da consulta de dados no Redshift, desde consultas SQL básicas até técnicas avançadas, como funções de janela e junções complexas. Também discutimos o ajuste de desempenho no Redshift, destacando as práticas recomendadas para otimizar o desempenho da consulta, como estilos de distribuição, chaves de classificação e codificação de compactação.
Por fim, enfatizamos a importância da segurança e da conformidade no Amazon Redshift, abordando recursos de segurança como criptografia e controle de acesso, bem como considerações de conformidade.
Para qualquer pessoa interessada em expandir seus conhecimentos e habilidades no trabalho com o Amazon Redshift e o AWS, vale a pena explorar os seguintes recursos do DataCamp:
Ao dominar o Amazon Redshift e aproveitar seus recursos, os usuários podem obter insights valiosos de seus dados e tomar decisões orientadas por dados.
Continue sua jornada de engenharia de dados hoje mesmo!
Programa
Programa
Curso
blog
Wendy Gittleson
15 min
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Javier Canales Luna
