Curso
Feature Engineering for Machine Learning in Python
4 h
38.8K
Embora a maioria das pessoas associe a Amazon a entregas e conteúdo de primeira linha, a empresa também é bem avaliada entre os desenvolvedores. Especificamente, a Amazon Web Services (AWS) oferece tecnologias de nuvem para mais de 1 milhão de usuários ativos, incluindo corporações e empresas de pequeno e médio porte.
Neste artigo, vamos nos concentrar no AWS SageMaker, uma plataforma dedicada para executar fluxos de trabalho de machine learning (ML) de ponta a ponta em grande escala, que faz parte do ecossistema da AWS. Ao final deste artigo, você terá um modelo implantado que poderá usar para enviar solicitações e gerar previsões para uma tarefa de classificação.
O Amazon SageMaker é um serviço totalmente gerenciado que fornece ferramentas e infraestrutura para a criação, o treinamento e a implantação de modelos de machine learning. Ele simplifica o fluxo de trabalho de machine learning, permitindo que os cientistas e desenvolvedores de dados criem, treinem e implementem modelos de forma rápida e eficiente.
Em um projeto típico de machine learning, você passará por vários estágios:
Cada estágio requer um conjunto diferente de ferramentas e uma equipe de especialistas qualificados para orquestrá-los perfeitamente. O Amazon SageMaker reúne todo esse processo em uma única plataforma. Aqui estão alguns de seus benefícios:
Esses benefícios fazem do Amazon SageMaker uma plataforma poderosa e flexível para a criação, o treinamento e a implementação de modelos de machine learning em escala.
Conforme mencionado, o SageMaker faz parte do ecossistema da AWS, que inclui muitas soluções de computação em nuvem que fornecem recursos de armazenamento, rede, bancos de dados, análise e machine learning. Todas essas soluções trabalham em sincronia com o SageMaker para unificar seu fluxo de trabalho de machine learning.
Por esse motivo, o SageMaker exige que você crie uma conta AWS, caso ainda não tenha uma.
Para criar sua conta, acesse https://aws.amazon.com/ e siga o processo para criar uma nova conta.
O processo de inscrição inclui adicionar informações de cobrança e verificar seu número de telefone. Não se preocupe - você não será cobrado até que realmente comece a usar alguma funcionalidade do SageMaker (o que, em geral, é econômico).
Depois de concluído, você será direcionado para o console do AWS, que normalmente se parece com a imagem a seguir. Observe que alguns dos widgets do console podem ser diferentes no seu caso.
Agora, criaremos uma sessão do JupyterLab para executar o código nas máquinas em nuvem da Amazon.
No console do AWS, pesquise o painel do SageMaker usando a barra de pesquisa na parte superior da tela:
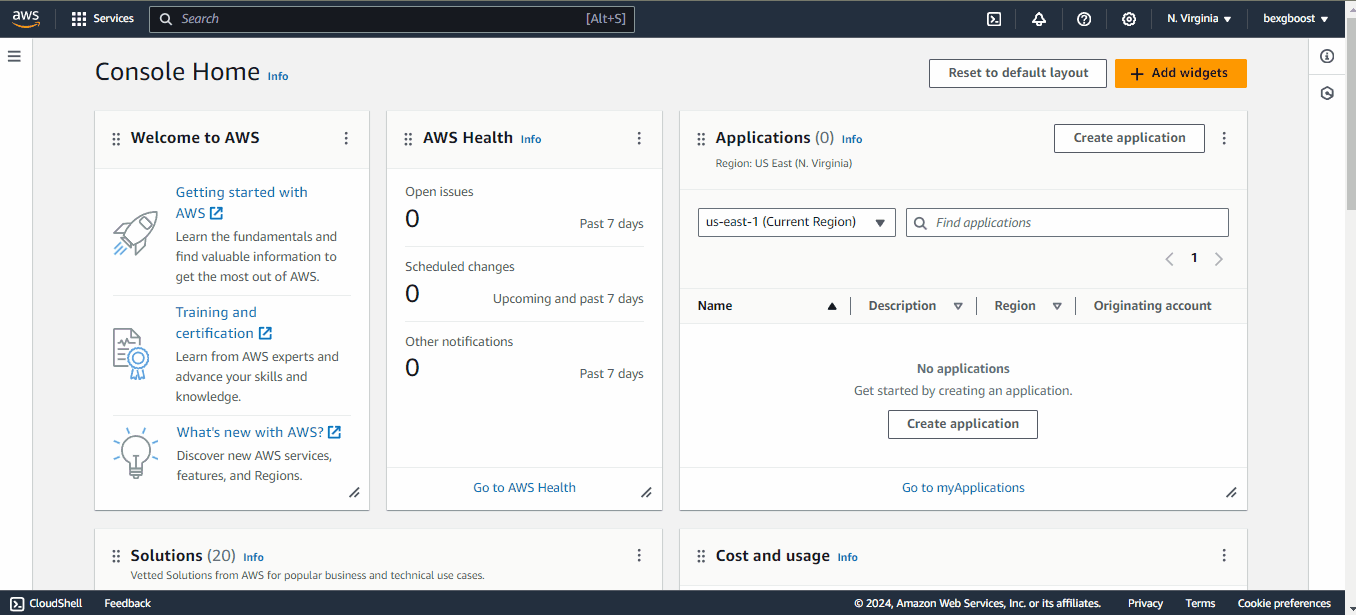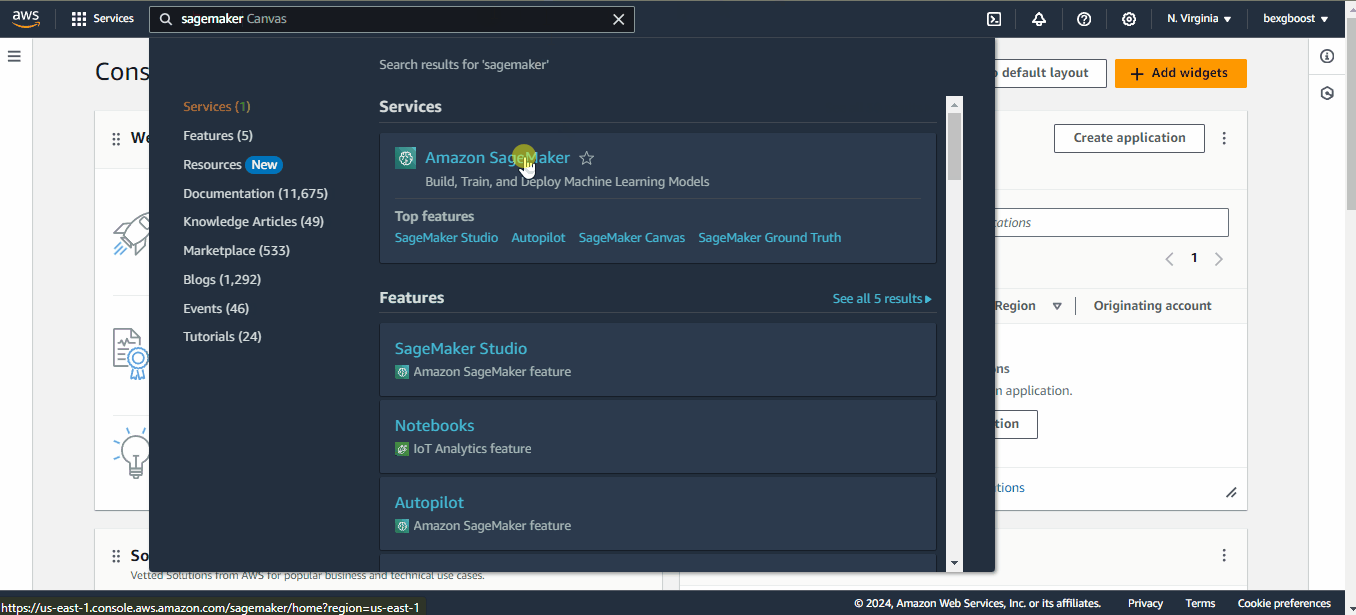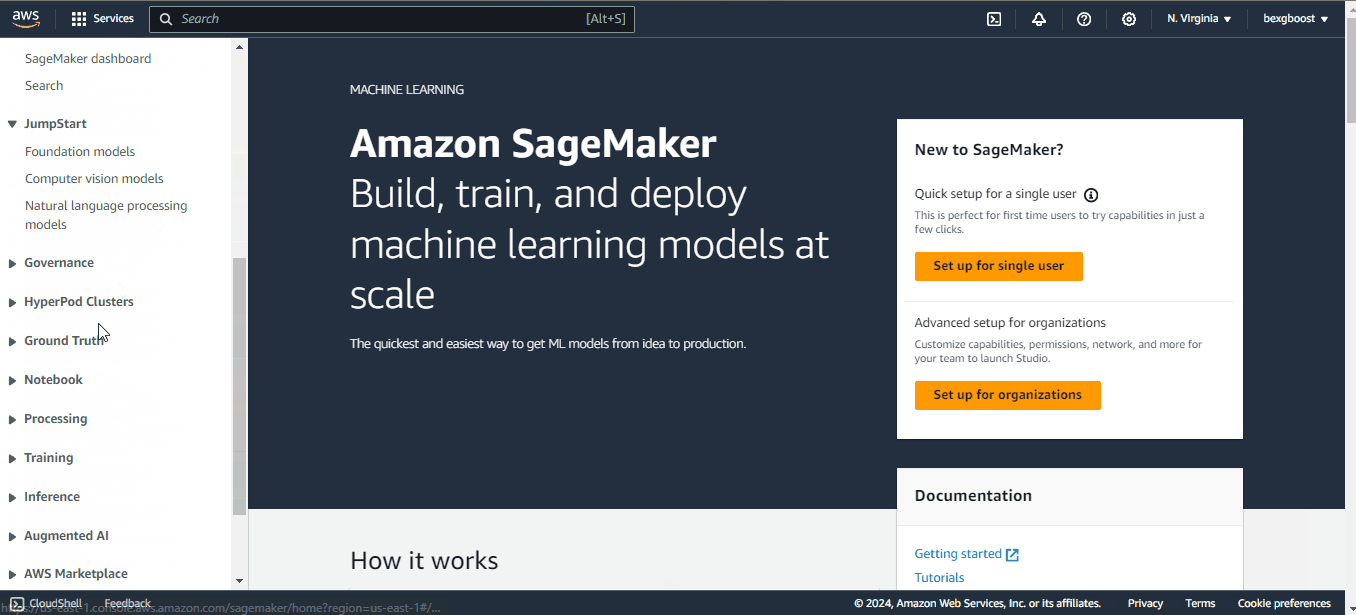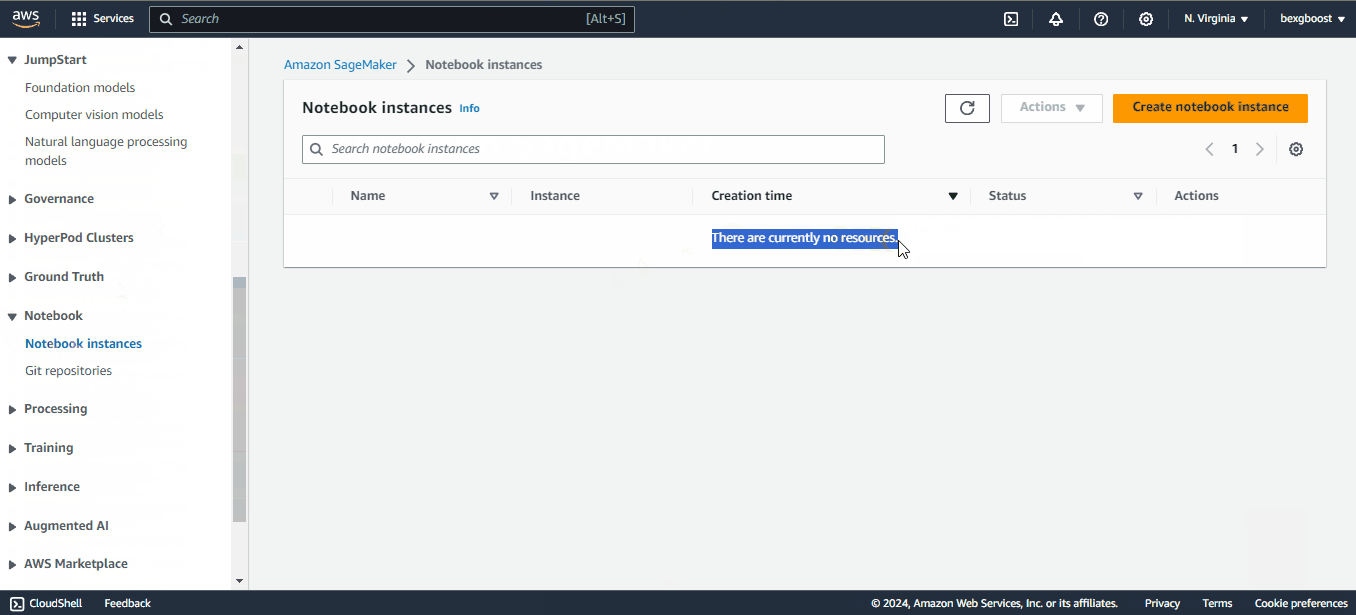
Em seguida, role a tela para baixo para encontrar a guia "Notebooks" e, dentro dela, a opção "Instâncias de notebooks". Você não verá nenhuma instância, portanto, precisamos criar uma:
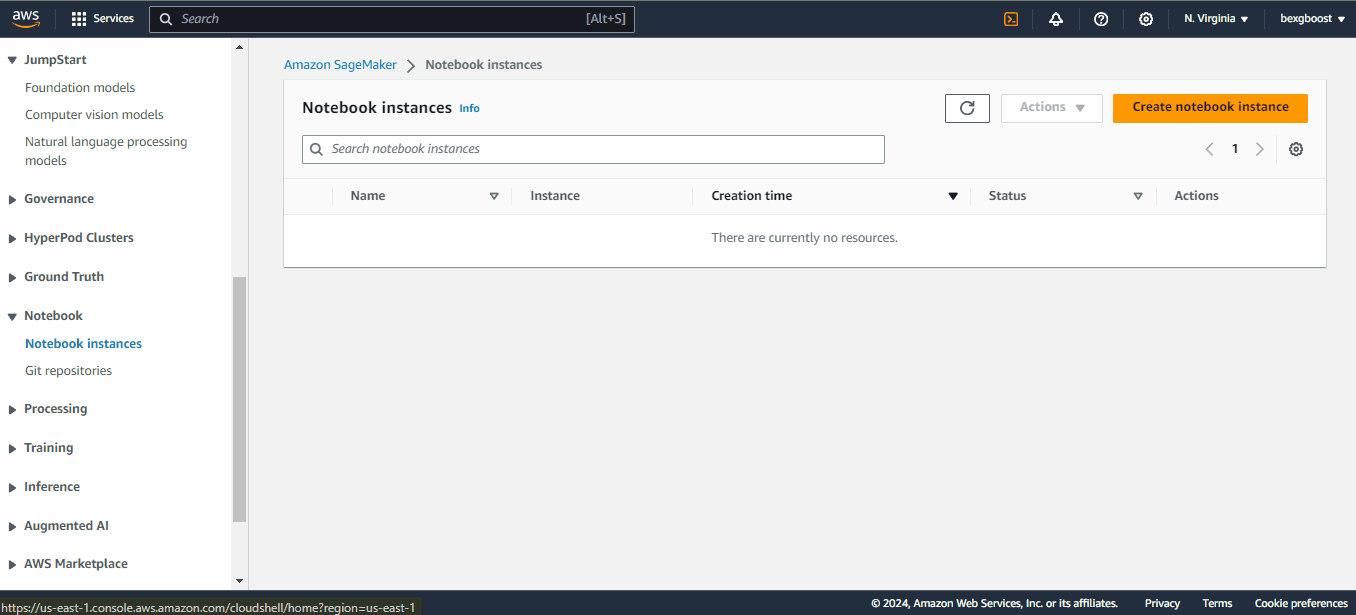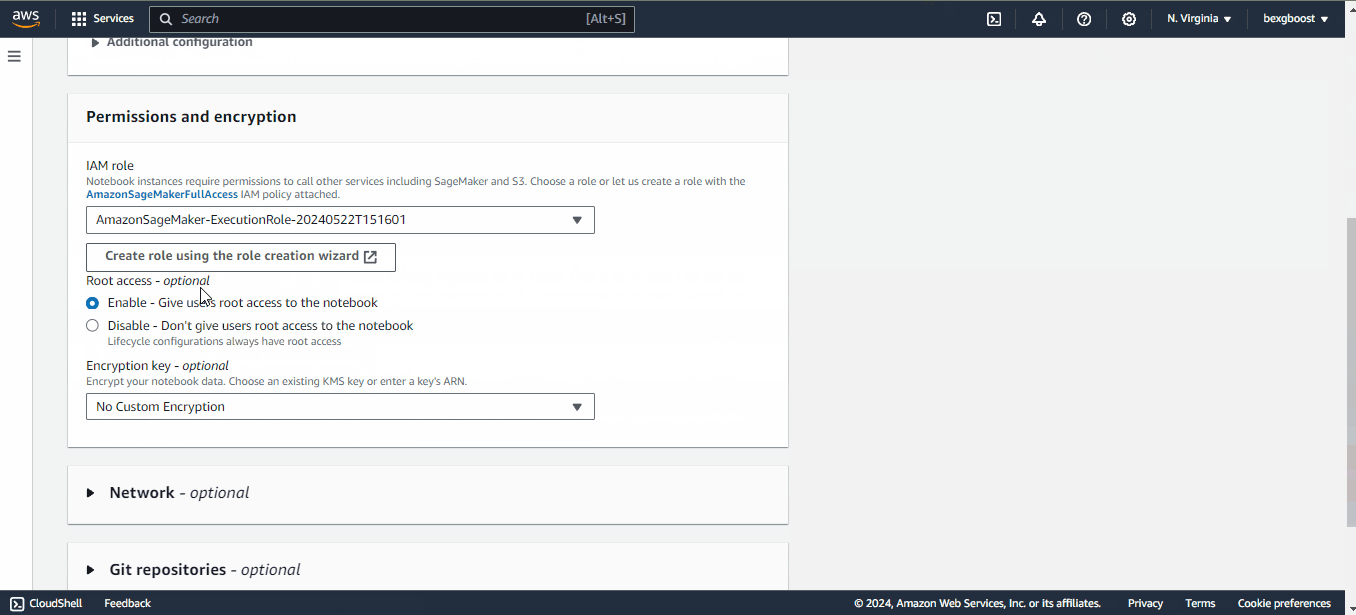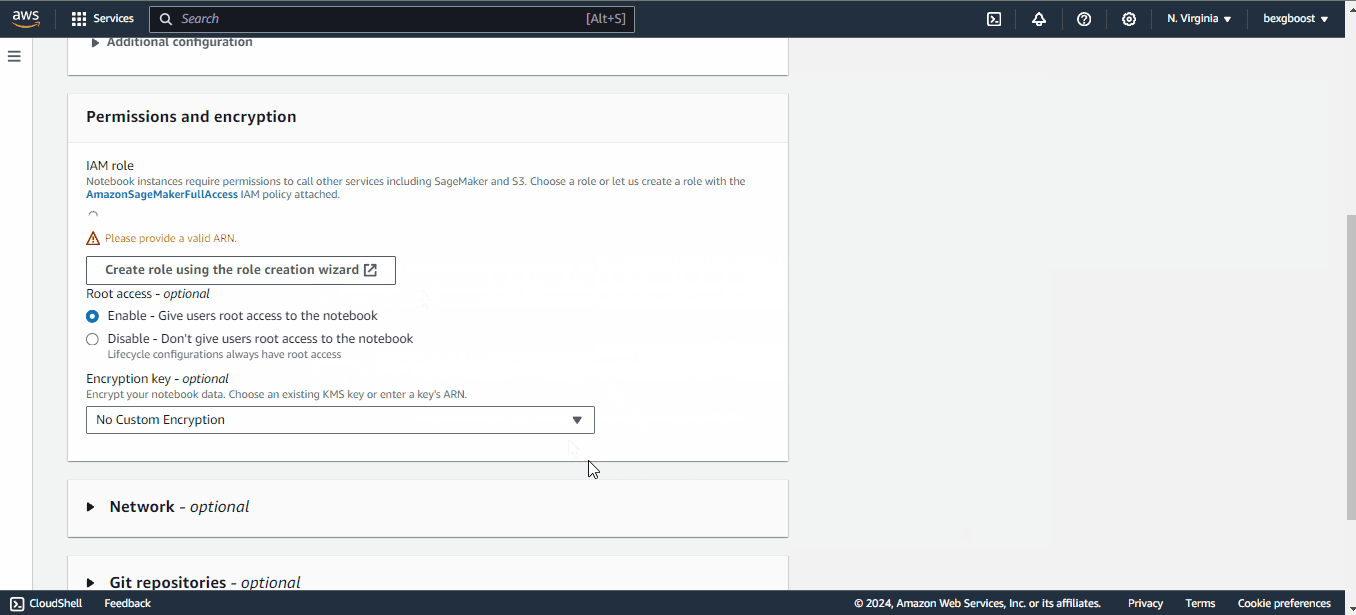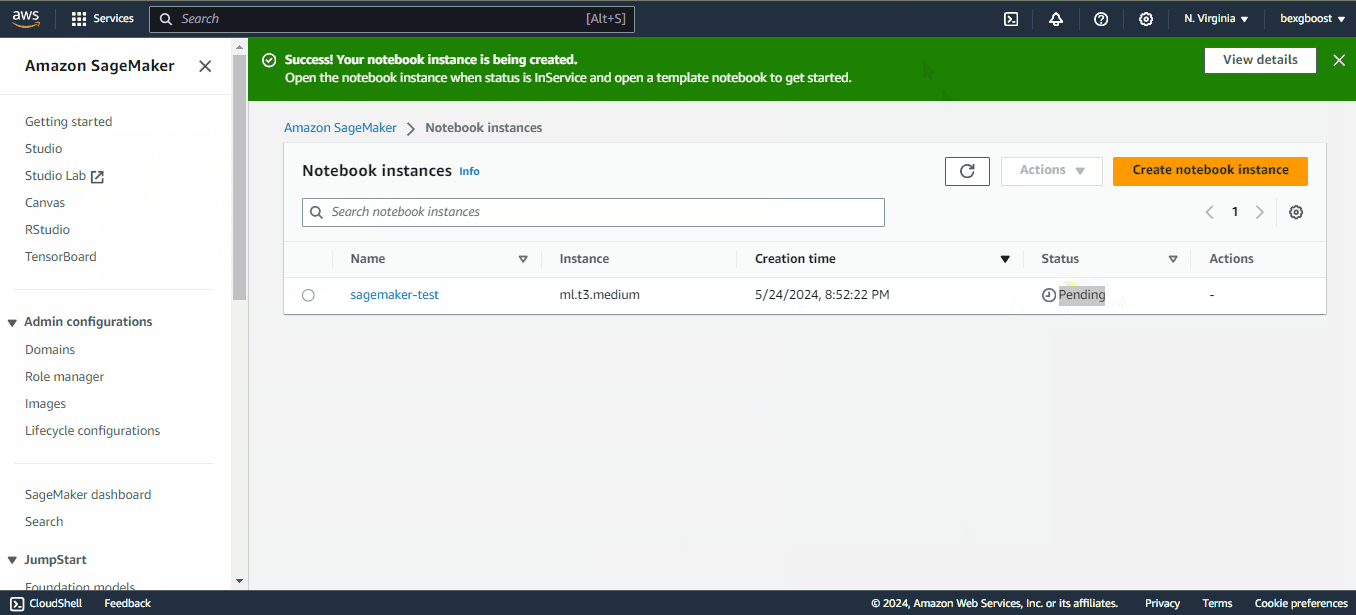
Para criar um novo notebook, clique em "Create notebook instance" (Criar instância de notebook) no canto superior direito da tela. Em seguida, preencha os campos a seguir:
sagemaker-test.Depois que você tiver preenchido todas as informações necessárias, clique em "Create notebook instance" (Criar instância de notebook).
Quando o status "Pending" mudar para "inService", você poderá iniciar o JupyterLab clicando no link "Open in JupyterLab" ao lado do notebook:
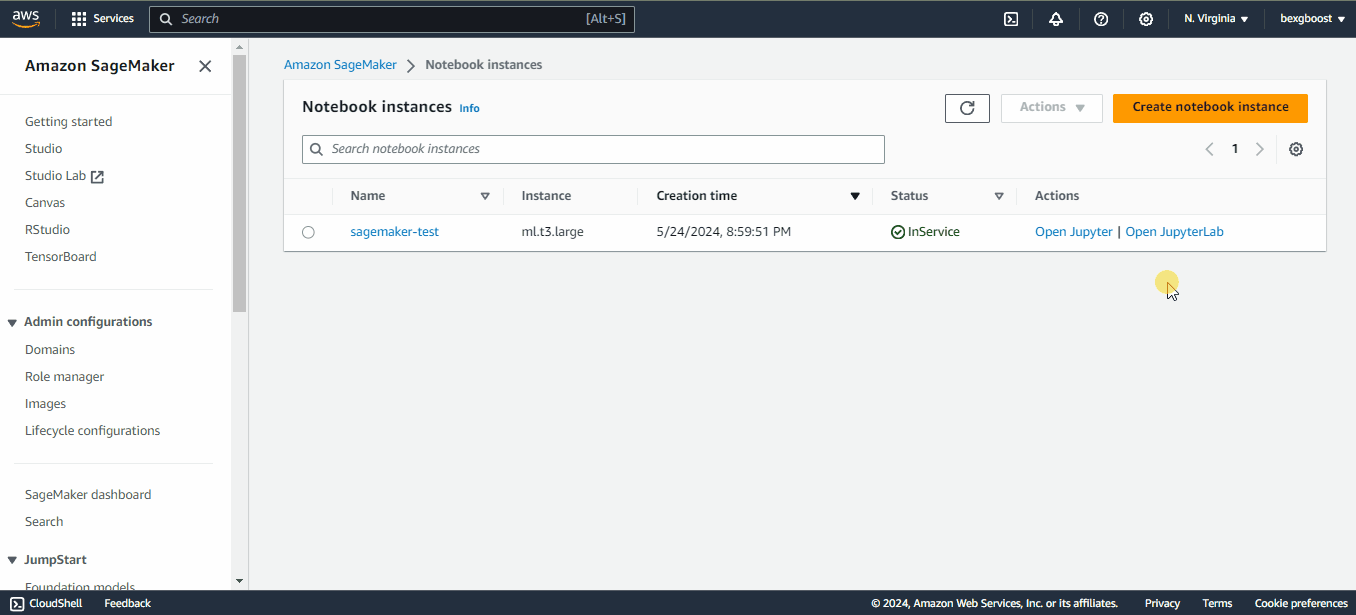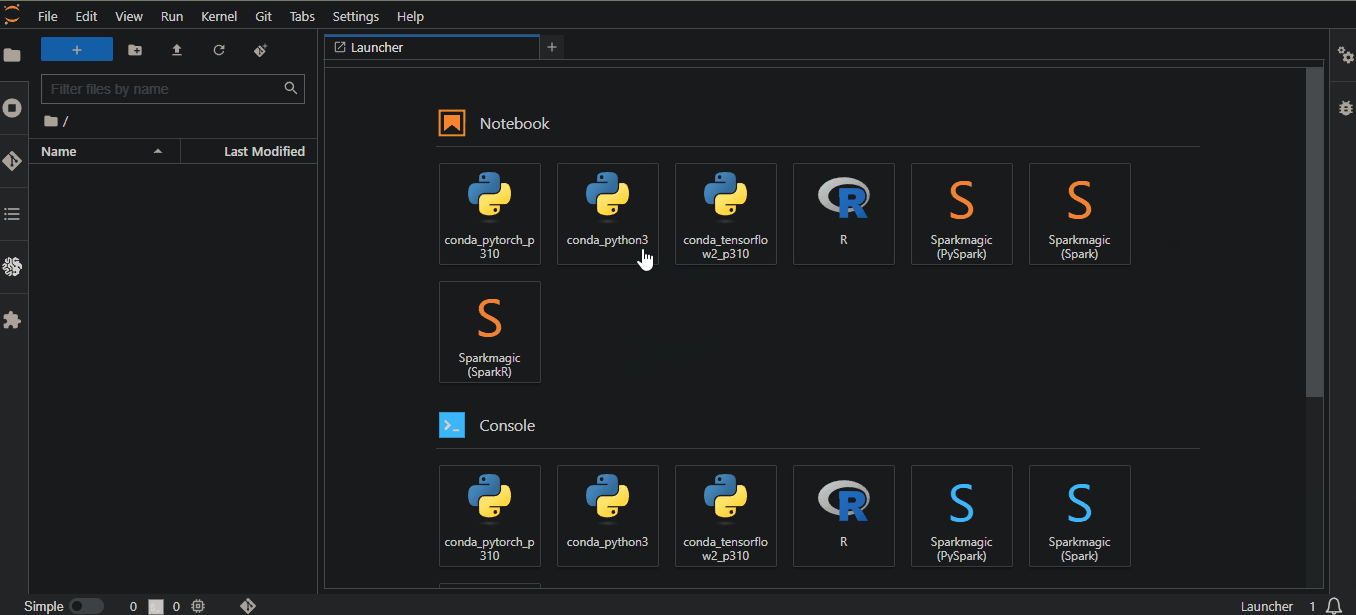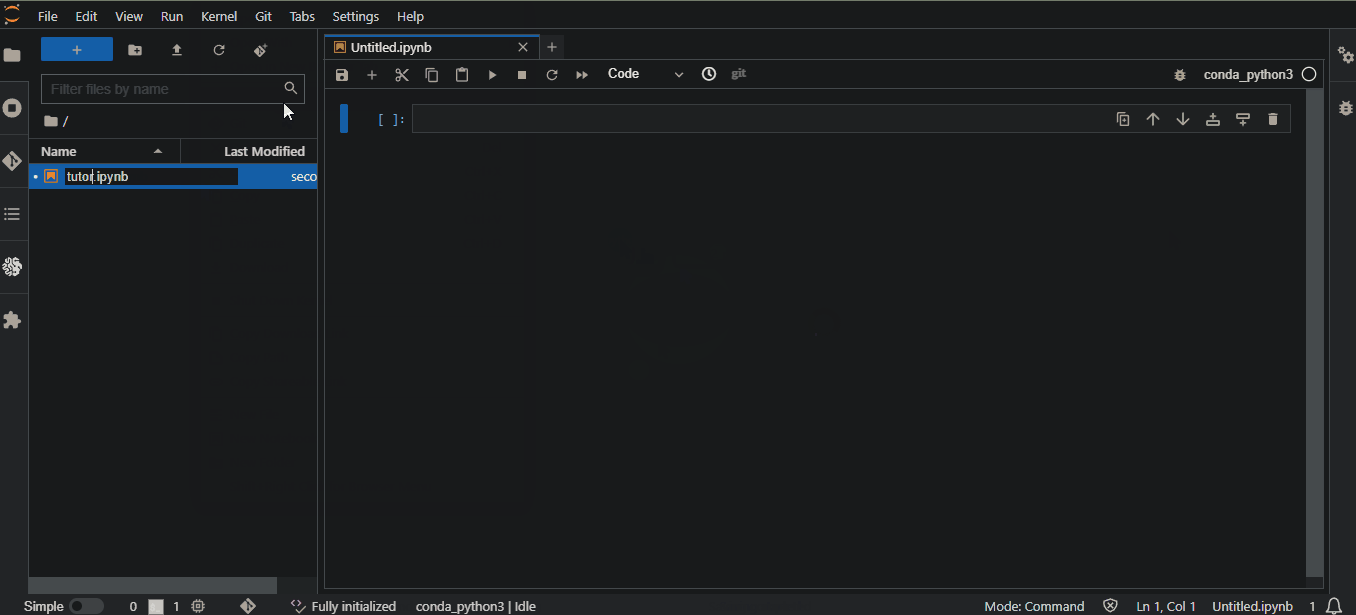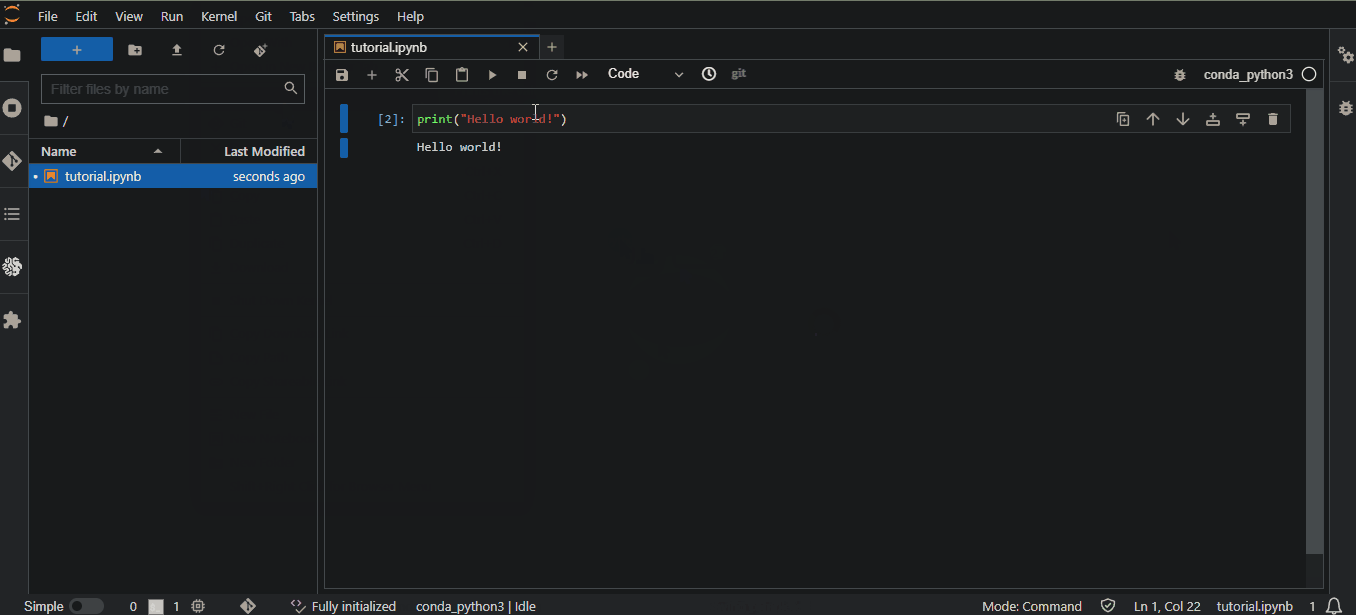
Assim que a instância estiver em serviço, o relógio começa a contar e a cobrança começa. Se você decidir fazer uma pausa, não se esqueça de interromper a instância clicando em "Ações" e depois em "Parar" para evitar custos desnecessários. O desligamento ocioso é de duas horas por padrão:
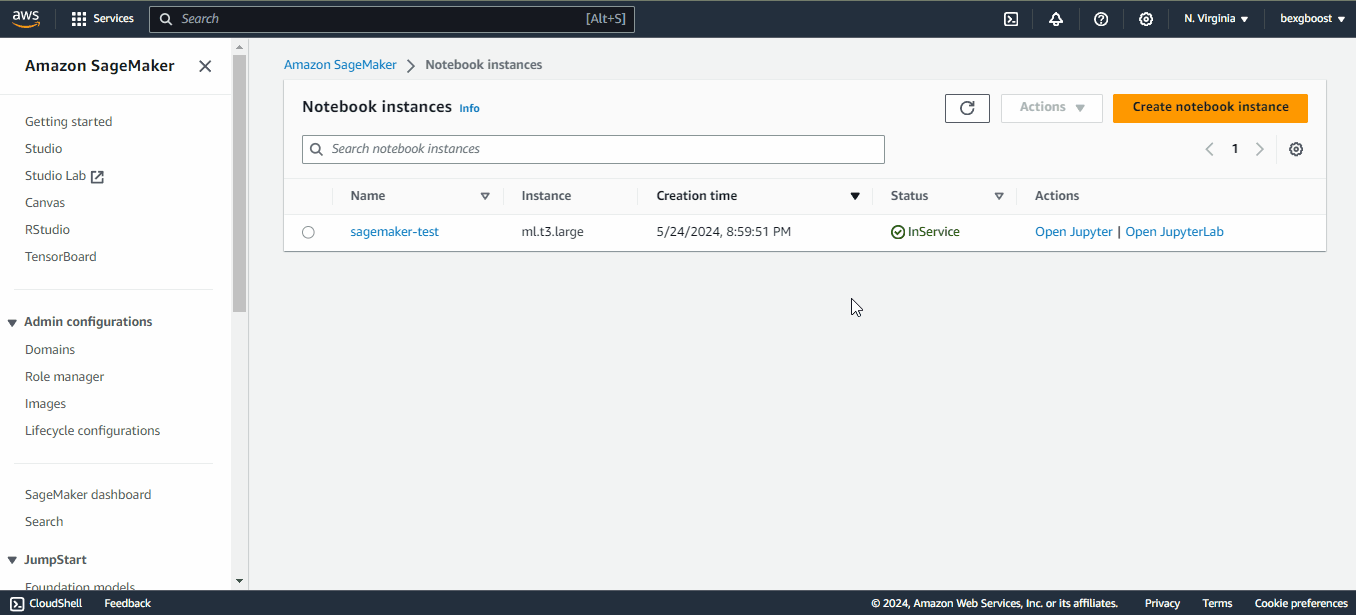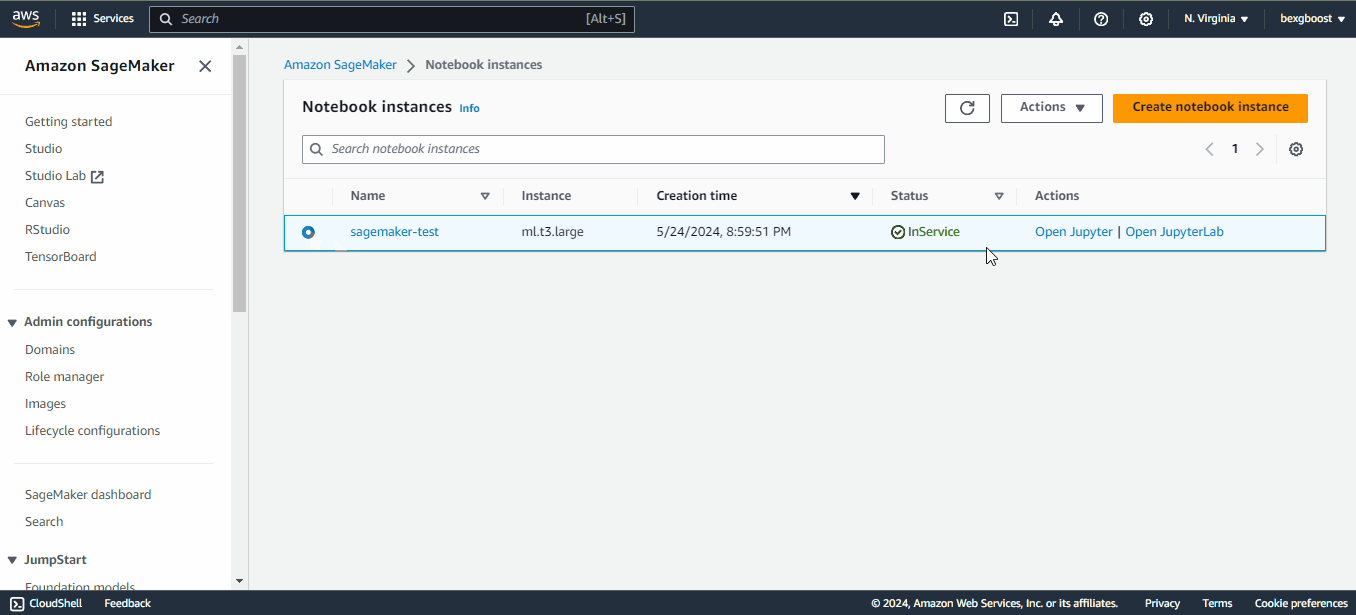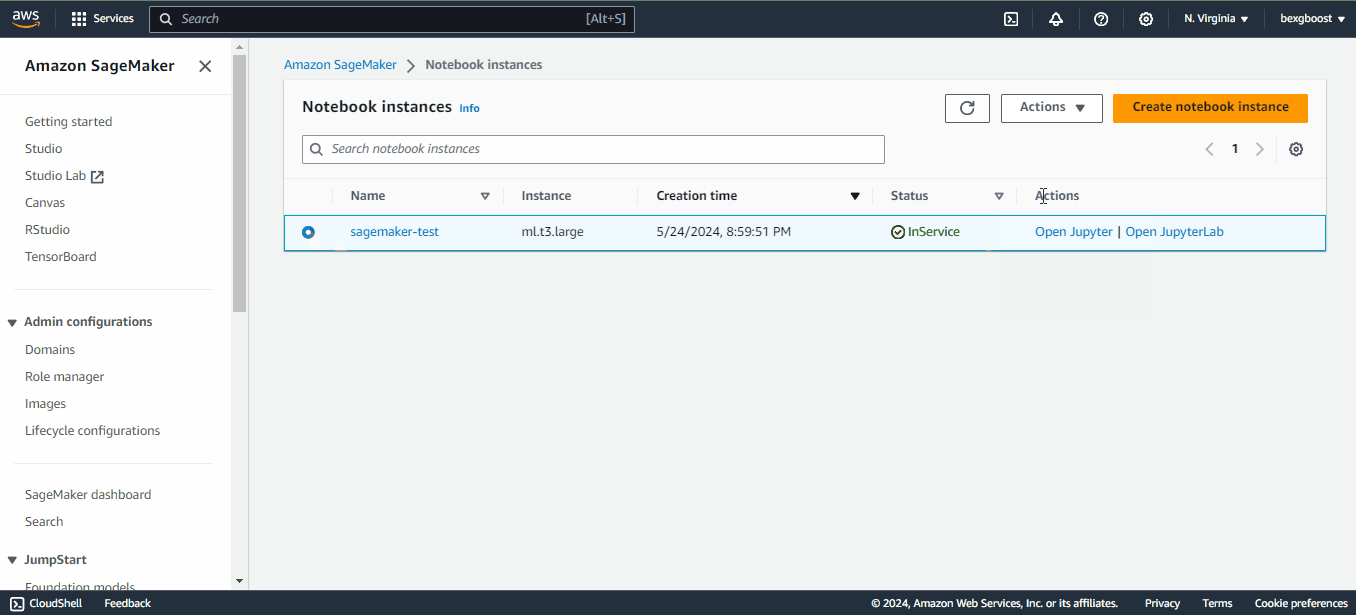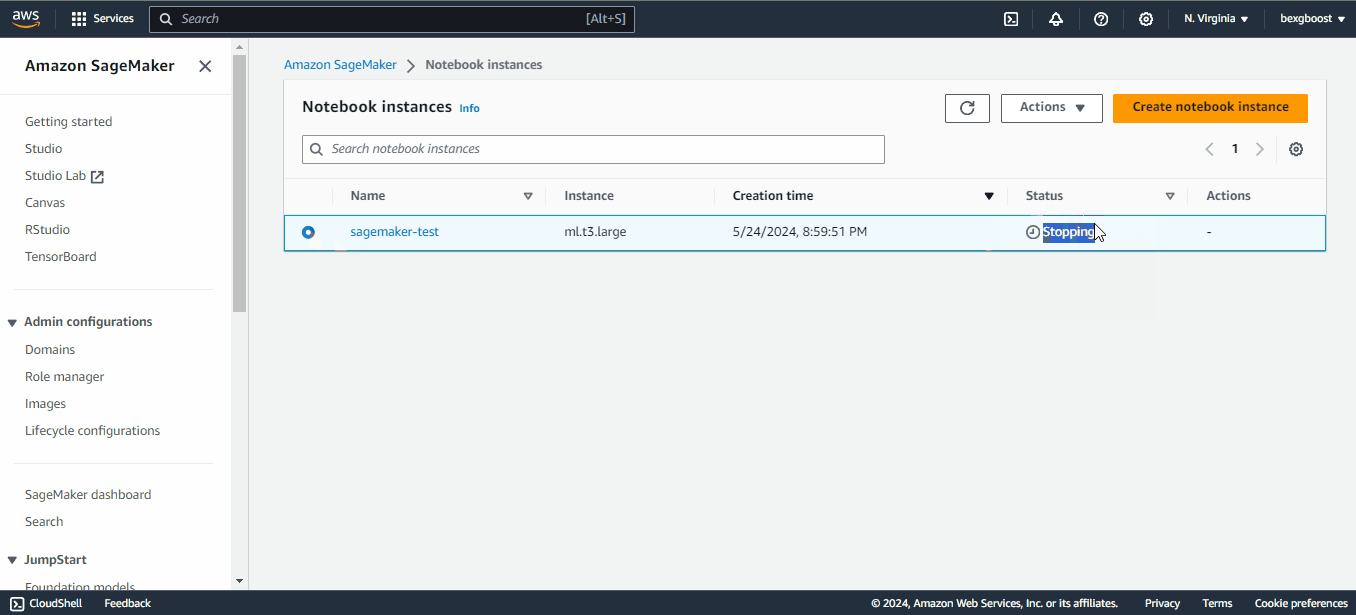
Se você interromper uma instância de notebook, poderá reiniciá-la novamente mais tarde. Seu ambiente será preservado.
Nesta seção, aprenderemos como fazer upload de um arquivo local para os servidores da Amazon, o que é um requisito para o SageMaker.
Criaremos um classificador de várias classes usando o conjunto de dados Dry Bean do repositório UCI ML. Ele contém 13 mil instâncias de feijões e suas 15 medidas numéricas.
A tarefa é classificá-los em sete tipos de feijão: Seker, Barbunya, Bombay, Cali, Dermosan, Horoz e Sira.

Os sete tipos de feijão: Seker, Barbunya, Bombay, Cali, Dermosan, Horoz e Sira.
Após o download, salve o arquivo do Excel dentro do ZIP baixado no diretório de dados local do JupyerLab e, em seguida, adicione o seguinte código ao notebook:
from pathlib import Path
cwd = Path.cwd()
data_path = cwd / "data" / "Dry_Bean_Dataset.xlsx"Em seguida, adicionando o código a seguir, podemos ler o arquivo do Excel com o pandas e salvá-lo como um CSV:
import pandas as pd
beans = pd.read_excel(data_path)
beans.to_csv(cwd / "data" / "dry_bean.csv", index=False)Nosso conjunto de dados deve estar dentro de um bucket S3 para que o SageMaker possa acessá-lo. O AWS S3 é uma solução de armazenamento em nuvem que permite que você mantenha objetos relacionados ao projeto em compartimentos hospedados nos servidores da Amazon.
Para criar um bucket, siga estas etapas:
dry-bean-bucket como eu fiz.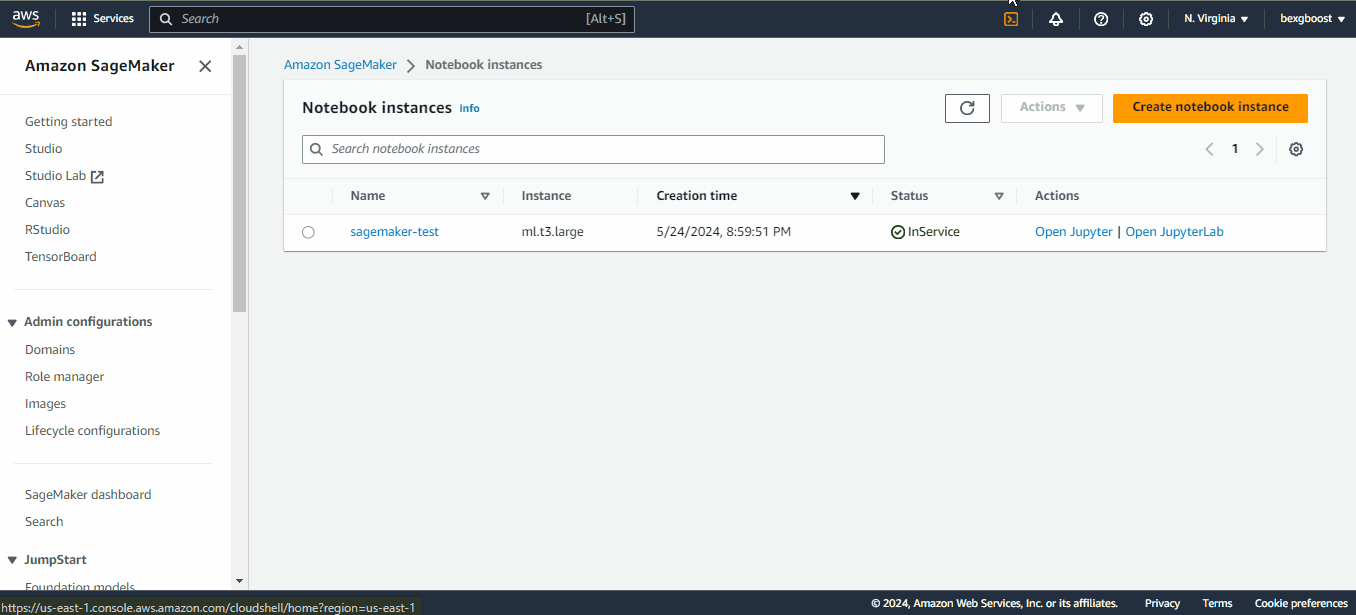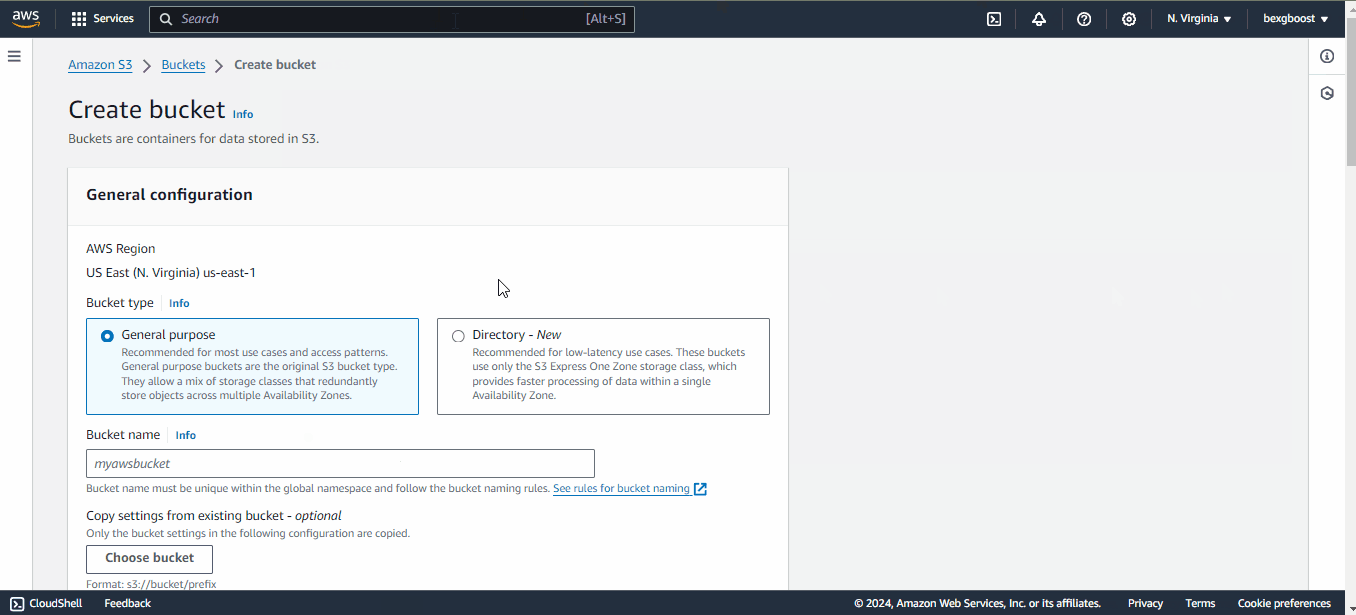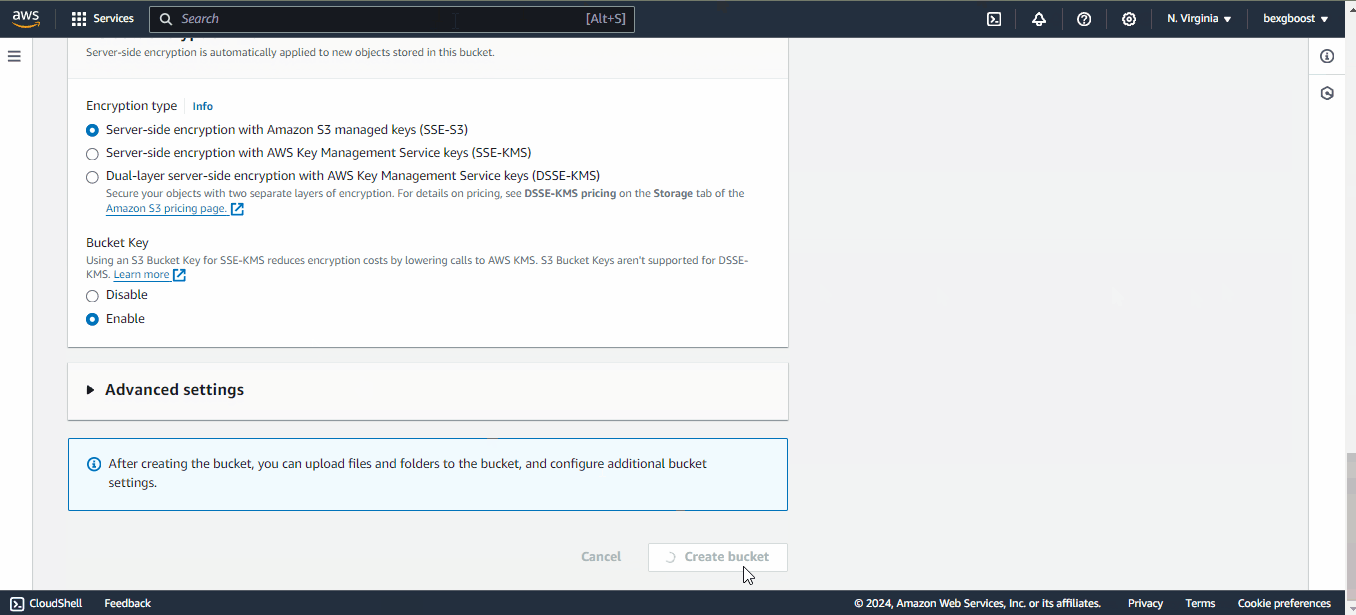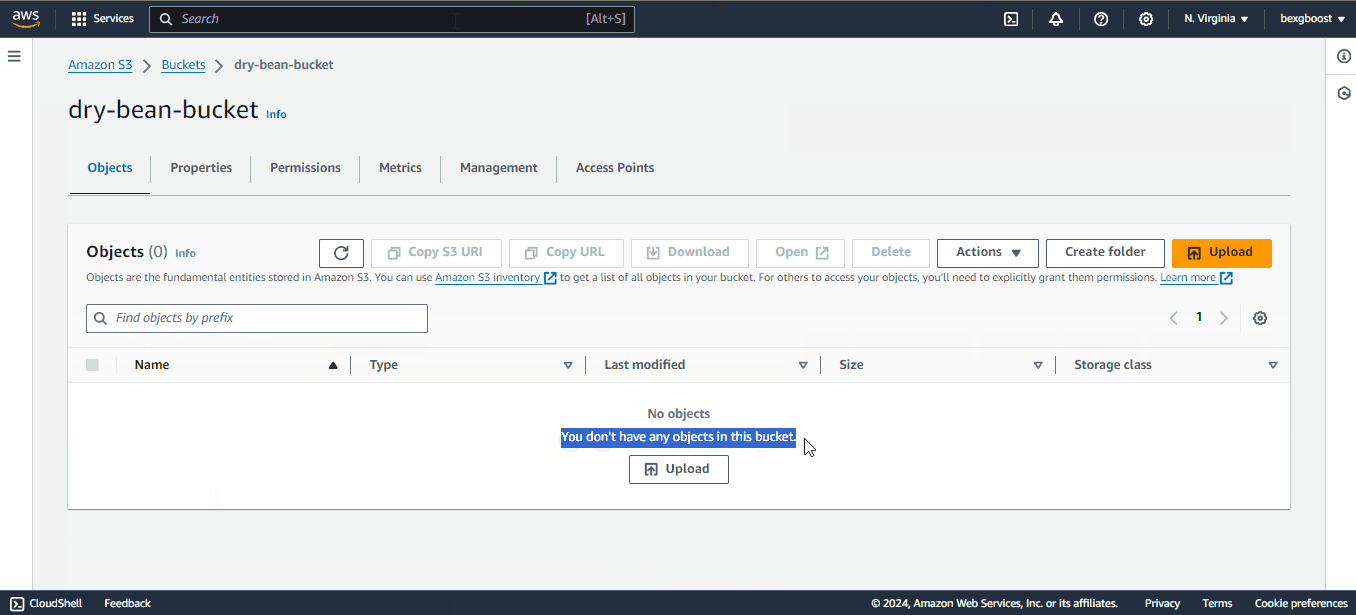
Depois que o bucket for criado, clique nele para carregar o arquivo CSV que salvamos anteriormente:
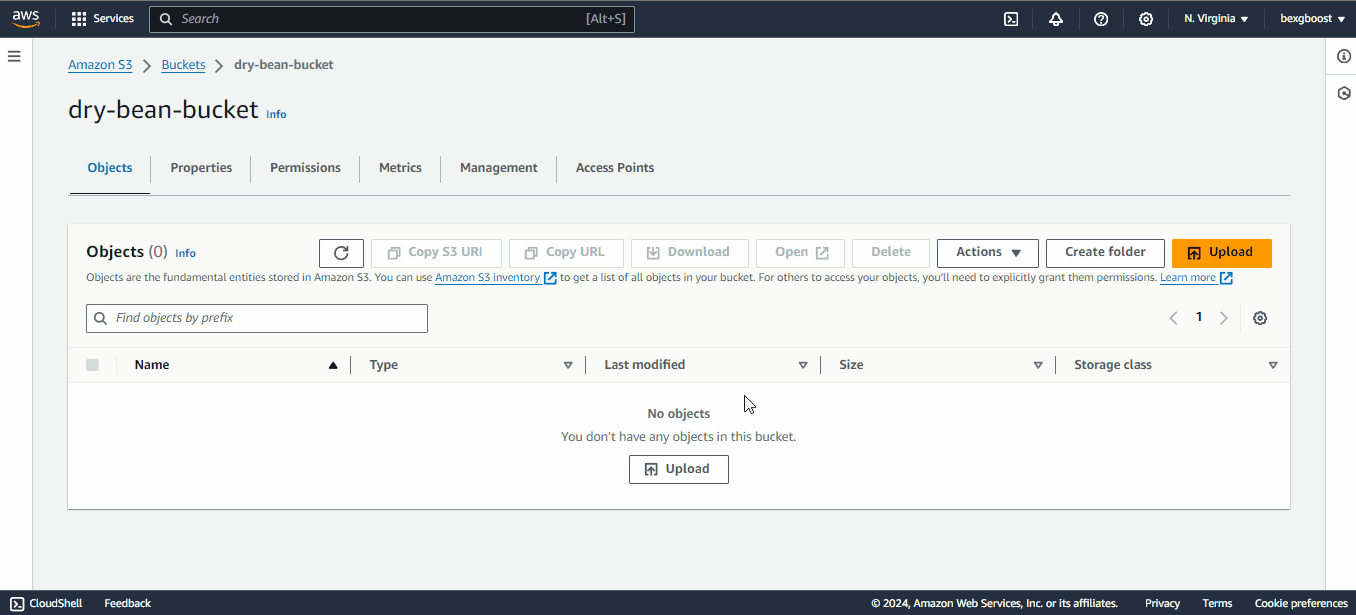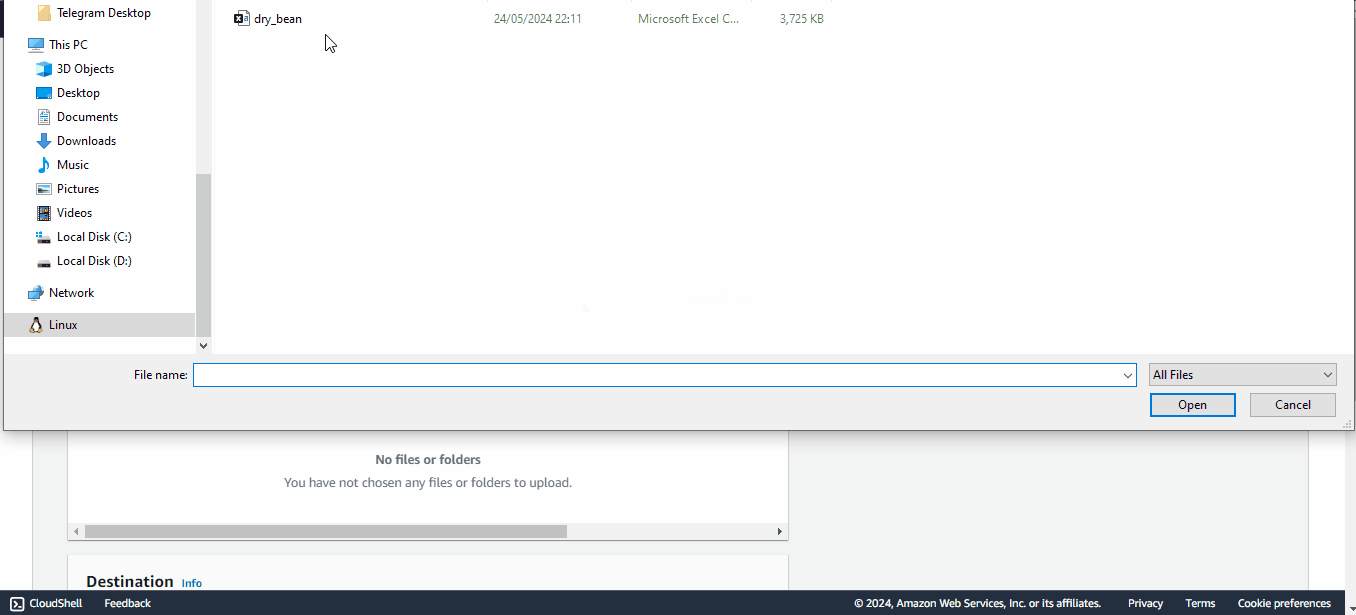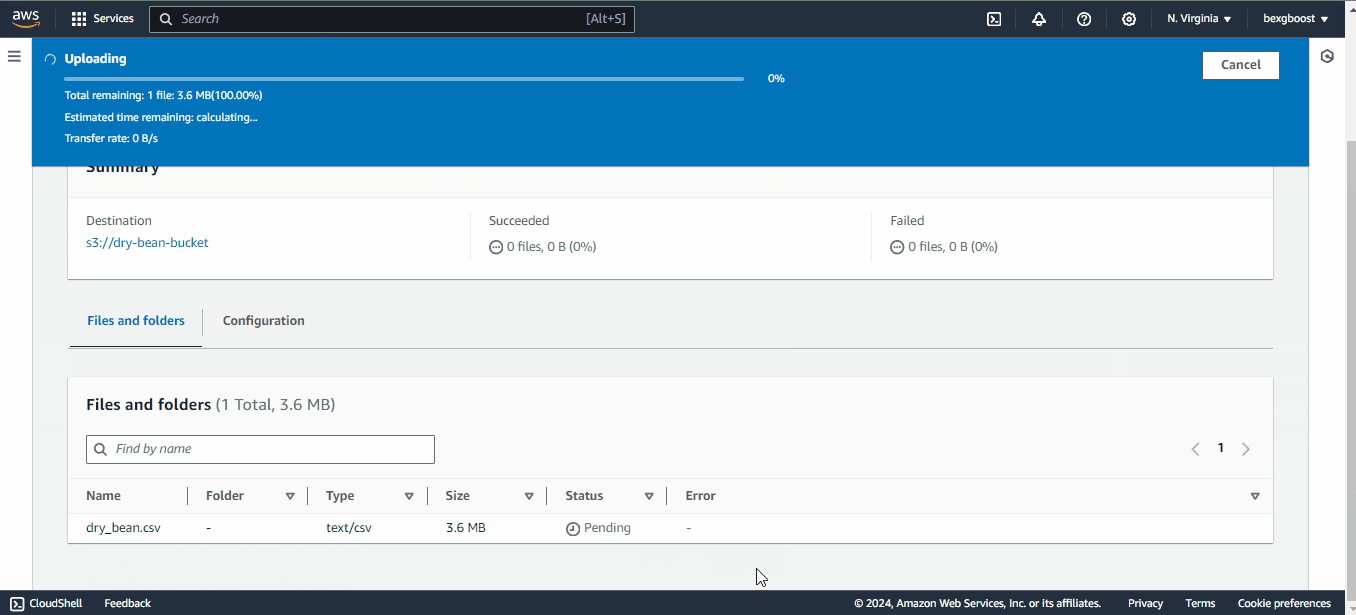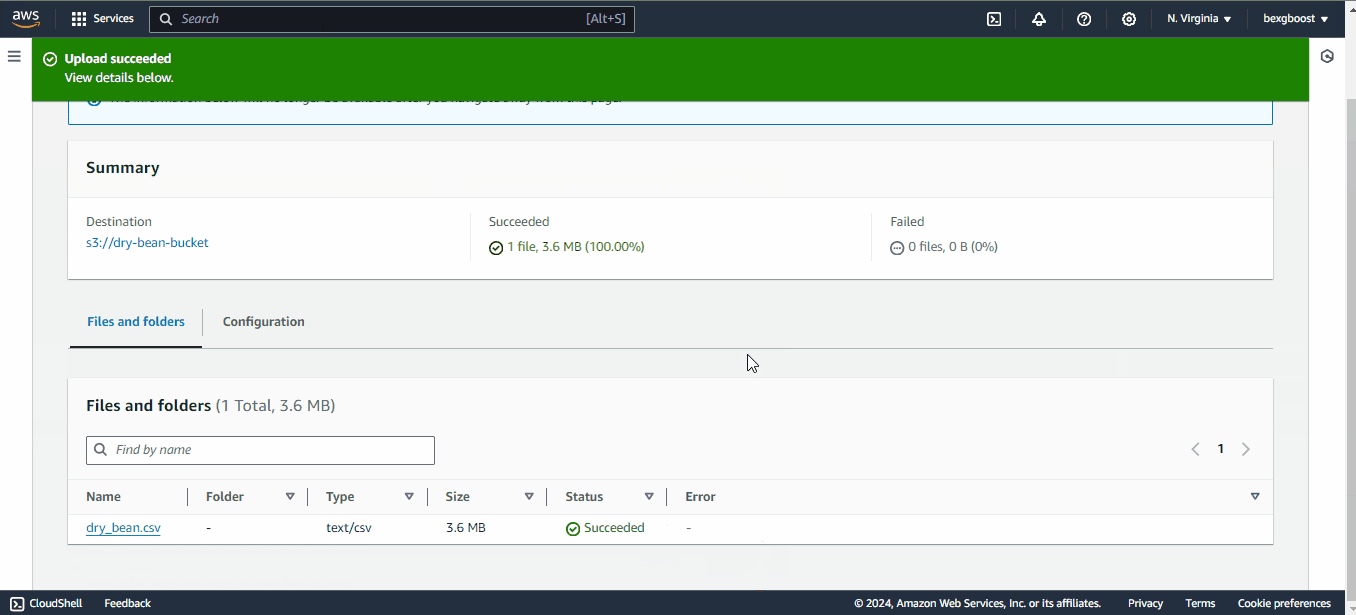
Depois disso, você pode retornar à interface do JupyterLab porque finalmente executaremos algum código!
Nesta seção, analisaremos um fluxo de trabalho de ponta a ponta que nos levará de um conjunto de dados CSV a um modelo implantado em um endpoint. Mas antes de nos perdermos nos detalhes técnicos, vamos parar um pouco para entender o que faremos em um nível elevado.
Fazer machine learning no SageMaker é um pouco diferente de fazê-lo em sua máquina local. Já abordamos as primeiras etapas:
Assim como os notebooks locais, as instâncias de notebook do SageMaker são para análise exploratória - limpeza de dados, exploração, ingestão e experimentação básica.
Quando você chega à fase de treinamento do modelo, o SageMaker espera que você siga as regras dele. Especificamente, para que o SageMaker implemente seus modelos personalizados como pontos de extremidade, é necessário um script de treinamento que faça o seguinte:
O script também deve aceitar dinamicamente quaisquer variáveis como argumentos de linha de comando. Portanto, tudo o que você quiser alterar no futuro dentro do script deve ser definido como argumentos de linha de comando (hiperparâmetros do modelo, caminhos de arquivo etc.).
Quando esse script estiver pronto, ele será alimentado em estimadores especiais fornecidos pelo SageMaker. Eles são companheiros de bibliotecas populares de ML, como scikit-learn, XGBoost, TensorFlow, PyTorch etc. Usando esses estimadores, o SageMaker cria contêineres do Docker em torno do seu script, implantando-o como um endpoint para atendê-lo em escala.
Todos os pontos anteriores começarão a fazer sentido à medida que os analisarmos passo a passo.
Vamos começar importando as bibliotecas necessárias dentro do notebook sagemaker-test que você criou anteriormente:
import boto3
import numpy as np
import pandas as pd
import sagemaker
from sagemaker import get_execution_role
from sklearn.model_selection import train_test_splitVeja o que algumas dessas importações fazem:
sagemaker é o SDK oficial do Python que treina e implementa modelos de machine learning no Amazon SageMaker. Com o SDK, você pode treinar e implantar modelos usando estruturas populares de aprendizagem profunda, algoritmos fornecidos pela Amazon ou seus algoritmos incorporados em imagens do Docker compatíveis com o SageMaker.boto3 é outro SDK oficial do Python, mas serve como uma ponte entre o seu código e todos os serviços da AWS, não apenas o SageMaker. Você pode saber mais sobre o boto3 neste curso. Após as importações, vamos criar alguns recursos de que você precisará ao longo do tutorial:
sm_boto3 = boto3.client("sagemaker")
sess = sagemaker.Session()boto3. Esses dois objetos nos permitem interagir com a plataforma SageMaker de diferentes maneiras.
Agora, vamos definir algumas variáveis globais de que você precisa:
region = sess.boto_session.region_name
BUCKET_URI = "s3://dry-bean-bucket"
BUCKET_NAME = "dry-bean-bucket"
DATASET_PATH = f"{BUCKET_URI}/dry_bean.csv"
TARGET_NAME = "Class"Essas variáveis são autoexplicativas e serão usadas em todo o tutorial.
Na maioria dos seus projetos de dados, o conjunto de dados de treinamento será armazenado em uma solução de armazenamento em nuvem, como BigQuery, GCS ou um bucket do AWS S3. Armazenamos o nosso no último, então vamos carregá-lo usando o pandas. Para fazer isso, adicione o seguinte código ao notebook e execute-o:
dry_bean = pd.read_csv(DATASET_PATH)
dry_bean.head()
Uma vantagem de trabalhar em um notebook Sagemaker é que podemos ler arquivos do S3 usando pandas diretamente. Todos os ambientes do SageMaker são configurados com suas credenciais para permitir que o pandas baixe o CSV do bucket. O código não teria funcionado se você o executasse localmente.
Passar algum tempo realizando a EDA (Análise Exploratória de Dados) deve fazer parte de todos os projetos em que você trabalha e este não é exceção. No entanto, não faremos uma análise profunda aqui, pois isso nos distrairá do tópico principal do artigo.
Vamos nos contentar em imprimir algumas estatísticas e gráficos resumidos:
dry_bean.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 13611 entries, 0 to 13610
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Area 13611 non-null int64
1 Perimeter 13611 non-null float64
2 MajorAxisLength 13611 non-null float64
3 MinorAxisLength 13611 non-null float64
4 AspectRation 13611 non-null float64
5 Eccentricity 13611 non-null float64
6 ConvexArea 13611 non-null int64
7 EquivDiameter 13611 non-null float64
8 Extent 13611 non-null float64
9 Solidity 13611 non-null float64
10 roundness 13611 non-null float64
11 Compactness 13611 non-null float64
12 ShapeFactor1 13611 non-null float64
13 ShapeFactor2 13611 non-null float64
14 ShapeFactor3 13611 non-null float64
15 ShapeFactor4 13611 non-null float64
16 Class 13611 non-null object
dtypes: float64(14), int64(2), object(1)
memory usage: 1.8+ MBAs informações acima nos dizem que há 16 recursos numéricos e um único alvo chamado Class. O conjunto de dados é pequeno, com apenas 13 mil instâncias, portanto, não precisaremos de máquinas potentes nem gastaremos muito dinheiro para treinar um modelo.
A seguir, vamos criar um gráfico de pares de alguns recursos importantes usando o seaborn:
import seaborn as sns
sns.pairplot(
dry_bean,
vars=["Area", "MajorAxisLength", "MinorAxisLength", "Eccentricity", "roundness"],
hue="Class",
);
Os gráficos acima mostram que os grãos são claramente distintos em termos de suas medidas físicas. Os feijões verdes (Bombay) são especialmente bem definidos.
Também podemos traçar uma matriz de correlação para ver a relação entre os recursos:
import matplotlib.pyplot as plt
correlation = dry_bean.corr(numeric_only=True)
# Create a square heatmap with center at 0
sns.heatmap(correlation, center=0, square=True, cmap="coolwarm", vmin=-1, vmax=1)
plt.show()
O gráfico mostra muitos recursos perfeitamente correlacionados (positivos e negativos), o que faz sentido, pois todos os recursos estão relacionados a medições físicas.
Neste ponto, deixarei que você continue a exploração.
Após a exploração, você deve resolver qualquer problema de qualidade ou lógico no conjunto de dados e criar novos recursos, se necessário, antes do treinamento.
O conjunto de dados Dry Bean é bastante limpo, portanto, nosso trabalho é fácil. Só precisamos codificar o destino porque ele contém texto. Para isso, usaremos o scikit-learn:
from sklearn.preprocessing import LabelEncoder
# For preprocessing
df = dry_bean.copy(deep=True)
# Encode the target
le = LabelEncoder()
df[TARGET_NAME] = le.fit_transform(df[TARGET_NAME])Uma vez concluído o pré-processamento, devemos dividir o conjunto de dados:
from sklearn.model_selection import train_test_split
# Split the data into two sets
train, test = train_test_split(df, random_state=1, test_size=0.2)Você pode dividir ainda mais os dados em um terceiro conjunto de validação, se preferir, mas vamos simplificar por enquanto.
Agora, vamos salvar os conjuntos de dados como CSVs:
train.to_csv("dry-bean-train.csv")
test.to_csv("dry-bean-test.csv")E carregue-os em nosso bucket S3:
# Send data to S3. SageMaker will take training data from s3
trainpath = sess.upload_data(
path="dry-bean-train.csv",
bucket=BUCKET_NAME,
key_prefix="sagemaker/sklearncontainer",
)
testpath = sess.upload_data(
path="dry-bean-test.csv",
bucket=BUCKET_NAME,
key_prefix="sagemaker/sklearncontainer",
)A função .upload_data() do objeto de sessão retorna o caminho completo para o arquivo carregado, que é armazenado nas variáveis trainpath e testpath, respectivamente. Usaremos esses caminhos mais tarde.
Em uma nova célula do bloco de notas, cole o seguinte código:
%%writefile script.py
import argparse
import os
import joblib
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import balanced_accuracy_score
if __name__ == "__main__":
print("extracting arguments")
parser = argparse.ArgumentParser()
# Hyperparameters sent by the client are passed as command-line arguments to the script.
parser.add_argument("--n-estimators", type=int, default=10)
parser.add_argument("--min-samples-leaf", type=int, default=3)
# Data, model, and output directories
parser.add_argument("--model-dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
parser.add_argument("--train", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
parser.add_argument("--test", type=str, default=os.environ.get("SM_CHANNEL_TEST"))
parser.add_argument("--train-file", type=str, default="dry-bean-train.csv")
parser.add_argument("--test-file", type=str, default="dry-bean-test.csv")
args, _ = parser.parse_known_args()
print("reading data")
train_df = pd.read_csv(os.path.join(args.train, args.train_file))
test_df = pd.read_csv(os.path.join(args.test, args.test_file))
print("building training and testing datasets")
X_train = train_df.drop("Class", axis=1)
X_test = test_df.drop("Class", axis=1)
y_train = train_df[["Class"]]
y_test = test_df[["Class"]]
# Train model
print("training model")
model = RandomForestClassifier(
n_estimators=args.n_estimators,
min_samples_leaf=args.min_samples_leaf,
n_jobs=-1,
)
model.fit(X_train, y_train)
# Print abs error
print("validating model")
bal_acc_train = balanced_accuracy_score(y_train, model.predict(X_train))
bal_acc_test = balanced_accuracy_score(y_test, model.predict(X_test))
print(f"Train balanced accuracy: {bal_acc_train:.3f}")
print(f"Test balanced accuracy: {bal_acc_test:.3f}")
# Persist model
path = os.path.join(args.model_dir, "model.joblib")
joblib.dump(model, path)
print("model persisted at " + path)O comando mágico %%writefile script.py no script acima converte o conteúdo da célula em um script Python, em vez de executá-lo. Você pode usar o comando mágico para converter o conteúdo da célula em um script Python em vez de executá-lo.
Agora, vamos analisar passo a passo o que está acontecendo no script:
import argparse
import os
import joblib
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import balanced_accuracy_scorePrimeiro, importamos algumas bibliotecas necessárias.
if __name__ == "__main__":
print("extracting arguments")
parser = argparse.ArgumentParser()
# Hyperparameters sent by the client are passed as command-line arguments to the script.
parser.add_argument("--n-estimators", type=int, default=10)
parser.add_argument("--min-samples-leaf", type=int, default=3)
# Data, model, and output directories
parser.add_argument("--model-dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
parser.add_argument("--train", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
parser.add_argument("--test", type=str, default=os.environ.get("SM_CHANNEL_TEST"))
parser.add_argument("--train-file", type=str, default="dry-bean-train.csv")
parser.add_argument("--test-file", type=str, default="dry-bean-test.csv")
args, _ = parser.parse_known_args()Em seguida, criamos um objeto analisador de argumentos para ler os argumentos da linha de comando. Como mencionei, qualquer valor que possa ser atualizado no futuro deve ser passado como argumentos da CLI. Esta seção define esses argumentos:
Se você prestar atenção aos valores padrão dos diretórios model-dir, train e test, verá algumas variáveis de ambiente. Esses dados foram retirados da documentação do SageMaker SDK, que também fornece instruções para você escrever esses arquivos de script.
print("reading data")
train_df = pd.read_csv(os.path.join(args.train, args.train_file))
test_df = pd.read_csv(os.path.join(args.test, args.test_file))
print("building training and testing datasets")
X_train = train_df.drop("Class", axis=1)
X_test = test_df.drop("Class", axis=1)
y_train = train_df[["Class"]]
y_test = test_df[["Class"]]Depois de definirmos os valores dinâmicos, lemos e criamos os conjuntos de dados de treinamento e teste. Como você pode ver, em vez de passar um caminho codificado, estamos usando os valores de args.argument.
# Train model
print("training model")
model = RandomForestClassifier(
n_estimators=args.n_estimators,
min_samples_leaf=args.min_samples_leaf,
n_jobs=-1,
)
model.fit(X_train, y_train)
# Print abs error
print("validating model")
bal_acc_train = balanced_accuracy_score(y_train, model.predict(X_train))
bal_acc_test = balanced_accuracy_score(y_test, model.predict(X_test))
print(f"Train balanced accuracy: {bal_acc_train:.3f}")
print(f"Test balanced accuracy: {bal_acc_test:.3f}")Ajustamos o modelo e o avaliamos nos conjuntos de dados de treinamento e teste e, em seguida, imprimimos o desempenho.
# Persist model
path = os.path.join(args.model_dir, "model.joblib")
joblib.dump(model, path)
print("model persisted at " + path)Por fim, salvamos o modelo no diretório do modelo usando joblib.
Quando você executar essa célula no notebook, o arquivo script.py aparecerá no ambiente do JupyterLab. Você pode verificar se ele está funcionando corretamente executando-o da seguinte forma:
! python script.py --n-estimators 100 \
--min-samples-leaf 2 \
--model-dir ./ \
--train ./ \
--test ./ \extracting arguments
reading data
building training and testing datasets
validating model
Train balanced accuracy: 1.000
Test balanced accuracy: 0.998
model persisted at ./modejoblibÓtimo, temos uma pontuação de precisão equilibrada de 99% - a melhor possível! Isso significa que podemos finalmente começar um trabalho de treinamento.
Agora, passaremos o script para um objeto de estimativa do SageMaker. No contexto do AWS, um trabalho de treinamento é um processo em que um modelo é treinado usando um algoritmo especificado, um conjunto de dados e recursos de computação fornecidos pelo AWS SageMaker. Ao contrário do treinamento em um computador local ou notebook, esse trabalho é executado na nuvem em uma infraestrutura dimensionável, o que permite mais potência computacional, processamento mais rápido e a capacidade de lidar com conjuntos de dados maiores.
Adicione o código a seguir em uma nova célula do bloco de notas:
# We use the Estimator from the SageMaker Python SDK
from sagemaker.sklearn.estimator import SKLearn
FRAMEWORK_VERSION = "0.23-1"
sklearn_estimator = SKLearn(
entry_point="script.py",
role=get_execution_role(),
instance_count=1,
instance_type="ml.c5.xlarge",
framework_version=FRAMEWORK_VERSION,
base_job_name="rf-scikit",
hyperparameters={
"n-estimators": 100,
"min-samples-leaf": 3,
},
)No código acima, a classe SKLearn lida com scripts do scikit-learn. Ele tem alguns parâmetros essenciais que precisam ser explicados:
entry_point: O caminho para o script.role: O nome de usuário que tem acesso ao SageMaker.instance_count: Quantas máquinas você deve rodar.instance_type: O tipo de máquina.Para hiperparâmetros, passe apenas os que você definiu no script de treinamento. Caso contrário, você receberá um erro.
Agora, podemos ajustar esse estimador aos nossos dados:
# Launch training job, with asynchronous call
sklearn_estimator.fit({"train": trainpath, "test": testpath}, wait=True)Se você se lembra das seções anteriores deste tutorial, trainpath e testpath são caminhos de bucket S3 que apontam para nossos arquivos CSV.
Quando você executar a célula com o código acima, o treinamento será iniciado:
INFO:sagemaker:Creating training-job with name: rf-scikit-2024-06-04-10-36-31-142
2024-06-04 10:36:31 Starting - Starting the training job...
2024-06-04 10:36:46 Starting - Preparing the instances for training...
2024-06-04 10:37:13 Downloading - Downloading input data...
2024-06-04 10:37:53 Training - Training image download completed. Training in progress...O SageMaker faz o download da imagem do Docker necessária que permite que você execute o código do scikit-learn e execute o seu script. Quando terminar, você verá a seguinte mensagem:
2024-06-04 10:38:17 Uploading - Uploading generated training model
2024-06-04 10:38:17 Completed - Training job completed
Training seconds: 65
Billable seconds: 65Se você acessar a seção "SageMaker" > "Treinamento" > "Trabalhos de treinamento" do seu painel do SageMaker, também verá o trabalho de treinamento listado lá.
Como nosso conjunto de dados é pequeno, conseguimos usar uma máquina de baixo custo e baixa configuração para treinamento: ml.c5.xlarge. No entanto, em seus próprios projetos, você pode ter que lidar com conjuntos de dados que contêm milhões de registros ou conjuntos de dados de imagens enormes. Nesses casos, você deve escolher máquinas que ofereçam significativamente mais potência e GPUs.
O uso dessas máquinas sob demanda pode ser muito caro. Para reduzir os custos, a Amazon oferece instâncias do Spot Training. Nessas instâncias, você pode escolher recursos de computação de alta potência por um preço baixo, com uma única ressalva: o treinamento não começará imediatamente. Em vez disso, o SageMaker espera até que a demanda esteja baixa e a máquina que você solicitou esteja disponível.
Para ativar o Spot Training, você precisa adicionar apenas algumas linhas ao último bloco de código:
spot_sklearn_estimator = SKLearn(
entry_point="script.py",
role=get_execution_role(),
instance_count=1,
instance_type="ml.c5.xlarge",
framework_version=FRAMEWORK_VERSION,
base_job_name="rf-scikit",
hyperparameters={
"n-estimators": 100,
"min-samples-leaf": 3,
},
use_spot_instances=True,
max_wait=7200,
max_run=3600,
)Ao definir use_spot_instances como True, você faz com que spot_sklearn_estimator use o treinamento pontual. Você também pode definir o tempo máximo de espera para que uma instância de ponto fique disponível e o tempo máximo de execução do treinamento.
O treinamento realmente começa quando você liga novamente para .fit():
# Launch training job, with asynchronous call
spot_sklearn_estimator.fit({"train": trainpath, "test": testpath}, wait=True)Usando o mesmo script de treinamento, podemos produzir um modelo ajustado por hiperparâmetros com um fluxo de trabalho semelhante.
Primeiro, importamos a classe IntegerParameter de sagemaker.tuner:
from sagemaker.tuner import IntegerParameterA classe IntegerParameter permite que o SageMaker defina intervalos de ajuste para parâmetros que aceitam valores inteiros. O módulo tuner contém classes para outros tipos de parâmetros:
CategoricalParameter: Define hiperparâmetros que assumem um conjunto discreto de valores categóricos.ContinuousParameter: Define intervalos de ajuste para hiperparâmetros que aceitam valores contínuos.Mas vamos nos ater a IntegerParameter neste tutorial, pois estamos ajustando apenas dois parâmetros do Random Forest:
# We use the Hyperparameter Tuner
from sagemaker.tuner import IntegerParameter
# Define exploration boundaries
hyperparameter_ranges = {
"n-estimators": IntegerParameter(20, 100),
"min-samples-leaf": IntegerParameter(2, 6),
}Em seguida, criamos um objeto tuner:
# Create Optimizer
Optimizer = sagemaker.tuner.HyperparameterTuner(
estimator=sklearn_estimator,
hyperparameter_ranges=hyperparameter_ranges,
base_tuning_job_name="RF-tuner",
objective_type="Maximize",
objective_metric_name="balanced-accuracy",
metric_definitions=[
{"Name": "balanced-accuracy", "Regex": "Test balanced accuracy: ([0-9.]+).*$"}
], # Extract tracked metric from logs with regexp
max_jobs=10,
max_parallel_jobs=2,
)Os parâmetros essenciais do Optimizersão:
estimator: O objeto estimador, compatível com seu script de treinamento.hyperparameter_ranges: O intervalo de parâmetros definidos com classes do módulo do sintonizador.objective_type: Se você deseja maximizar ou minimizar a métrica fornecida. A precisão equilibrada deve ser maximizada.metric_definitions: O nome das métricas a serem otimizadas e como elas podem ser recuperadas dos registros de treinamento.O parâmetro metric_definitions é um pouco complicado porque oferece muita flexibilidade na forma como você define as métricas.
No script de treinamento, estamos informando a precisão equilibrada usando a seguinte mensagem de registro:
print(f"Train balanced accuracy: {bal_acc_train:.3f}")
print(f"Test balanced accuracy: {bal_acc_test:.3f}")O que o metric_definitions nos pede é que capturemos essa mensagem usando expressões regulares. Portanto, temos o seguinte dicionário, que dá um nome personalizado à métrica capturada que começa com "Precisão equilibrada do teste".
{
"Name": "balanced-accuracy",
"Regex": "Test balanced accuracy: ([0-9.]+).*$",
}O restante do código é familiar:
Optimizer.fit({"train": trainpath, "test": testpath})INFO:sagemaker:Creating hyperparameter tuning job with name: RF-tuner-240604-1049Quando o otimizador terminar o ajuste, você poderá exibir seus resultados como um DataFrame:
# Get tuner results in a df
results = Optimizer.analytics().dataframe()
while results.empty:
time.sleep(1)
results = Optimizer.analytics().dataframe()
results.head()
Em seguida, você pode obter o melhor estimador:
best_estimator = Optimizer.best_estimator()Depois de decidir qual modelo você usará para seus experimentos, você pode carregá-lo no SageMaker com todos os seus artefatos. Essa tarefa pode ser feita usando o site boto3:
artifact_path = sm_boto3.describe_training_job(
TrainingJobName=best_estimator.latest_training_job.name
)["ModelArtifacts"]["S3ModelArtifacts"]
print("Model artifact persisted at " + artifact)Model artifact persisted at s3://sagemaker-us-east-1-496320894061/RF-tuner-240604-1049-009-38d75f35/output/model.tar.gzA função describe_training_job() pega um objeto estimador e o envia para um local S3 padrão fornecido pelo SageMaker. Acima, você pode ver que a função converteu o modelo em um tarball antes de fazer o upload.
Os modelos carregados ficarão visíveis para você na seção "Inference" (Inferência) > "Models" (Modelos) do seu painel do SageMaker:
Se você clicar em qualquer um deles, verá um botão "Create endpoint" (Criar endpoint) no canto superior direito da tela:
Você pode implantar o modelo usando esse botão ou pode fazê-lo com código, voltando à instância do notebook e usando o método .deploy():
from sagemaker.sklearn.model import SKLearnModel
model = SKLearnModel(
model_data=artifact_path,
role=get_execution_role(),
entry_point="script.py",
framework_version=FRAMEWORK_VERSION,
)Desta vez, estamos usando a classe SKLearnModel, que é usada para modelos já treinados. Ele requer o local do S3 onde os artefatos estão armazenados e o script usado para treiná-lo. Depois de fornecer essas informações, você pode executar o código para implantá-lo:
predictor = model.deploy(instance_type="ml.c5.large", initial_instance_count=1)
INFO:sagemaker:Creating model with name: sagemaker-scikit-learn-2024-06-04-11-03-54-465
INFO:sagemaker:Creating endpoint-config with name sagemaker-scikit-learn-2024-06-04-11-03-54-960
INFO:sagemaker:Creating endpoint with name sagemaker-scikit-learn-2024-06-04-11-03-54-960Depois disso, você deverá ver o endpoint listado na seção "Inference" (Inferência) > "Endpoints" (Endpoints) do seu painel do SageMaker:
Para usá-lo para previsão, você pode usar o método .predict() do objeto de endpoint do seu notebook:
preds = predictor.predict(test.sample(4).drop("Class", axis=1))
predsarray([3, 0, 1, 2])Parabéns, você acabou de implementar seu primeiro modelo com o SageMaker!
Quando você terminar de usá-lo, não se esqueça de excluir o ponto de extremidade, pois ele incorre constantemente em novos custos:
sm_boto3.delete_endpoint(EndpointName=predictor.endpoint)Não se esqueça de que cada instância de caderno que você cria no SageMaker vem com uma guia separada com cadernos de exemplo que mostram os diferentes recursos do SageMaker:

Além disso, consulte a documentação oficial do SageMaker Python SDK.
Hoje, aprendemos a usar uma das plataformas de machine learning empresarial mais populares: AWS SageMaker. Cobrimos tudo, desde a criação de uma conta do AWS até a implantação de modelos de ML como pontos de extremidade usando o SageMaker.
Assim como acontece com qualquer plataforma, estamos apenas arranhando sua superfície. Você pode fazer muito mais se combiná-lo com outras tecnologias da AWS em seus projetos. Aqui estão alguns recursos relacionados que você pode conferir:
Saiba mais sobre machine learning e AWS com estes cursos!
Curso
Curso
Curso
blog
Natassha Selvaraj
15 min
blog
Abid Ali Awan
5 min
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
