
Course
Understanding Cloud Computing
2 hr
234.7K
Effective data storage is a critical component to the operational success of any business across all sectors. The more data is collected, the more crucial the need for scalable, reliable, and cost-effective storage solutions.
Choosing the right data storage can be challenging due to the vast number of options, whether in the cloud or on-premises, each with its advantages and limitations.
This article doesn't aim to cover all the possible options but focuses instead on scalable, reliable, and cost-effective services: Amazon Simple Storage Service (Amazon S3) and Amazon Elastic File System (EFS).
We’ll start by explaining why businesses should adopt storage services and continue by covering the fundamentals of storage services. We’ll then offer guidance on integrating storage services into an operational process. The last section is a deep dive into the advanced concepts, specifically focusing on performance and cost optimizations.
If you’re looking for a comprehensive introductory resource on Amazon Web Services (AWS), check out this Introduction to AWS course.
With all the storage options out there, it's important to provide the reasons why a business should use AWS for file storage, and that's the purpose of this section.
It starts by conducting a comparative analysis between AWS storage services and traditional ones, along with brief examples of real-world applications. This will hopefully reinforce the relevance of AWS S3 and EFS in various scenarios.
Traditional storage services and AWS storage services provide different sets of features and benefits. We do a comparative analysis in the table below:
|
Features |
Traditional storage |
AWS S3 & EFS |
|
Cost |
Capital expenditure on hardware and ongoing costs for maintenance—can be unpredictable over time. |
The pay-as-you-go pricing model reduces upfront costs and helps with better cost management based on usage. |
|
Compliance |
Achieved through internal controls and audits and may require additional resources to maintain standards. |
AWS complies with a vast range of industry standards such as HIPAA and GDPR, simplifying user compliance. |
|
Data Accessibility |
Mainly accessible from specific locations or networks. Accessing remotely can be less secure and complex. |
Globally accessible over the internet, with high availability and data redundancy. |
|
Data durability |
Prompt to physical damage, theft, or natural disasters. |
Offer 99.99999999999% (11 nines) durability by automatically replicating data across multiple availability zones. |
|
Management & Maintenance |
Requires a dedicated team for hardware maintenance, software updates, and troubleshooting. |
Handled by AWS. This reduces the administration burden on users. |
|
Performance |
Depends on the specific hardware and network infrastructure. Also, updates can be costly. |
Provide customizable performance options. S3 provides storage classes and acceleration features, while EFS supports bursting workloads and throughput models. |
|
Scalability |
Limited by physical infrastructure and requires manual interventions to scale. |
Highly scalable, allowing for easy adjustment to storage without upfront provisioning. |
|
Security |
Depends on local security measures. This requires a significant effort to ensure data safety and compliance. |
Offer comprehensive security controls, including data encryption (at rest and in transit) access management, and compliance certifications. |
Both S3 and EFS have a broad spectrum of applications across industries. Below are some examples of real-world use cases for both services, highlighting their relevance and utility in different scenarios.
Let’s first consider the Amazon Simple Storage Service (S3) use cases:
Let’s now consider the use cases of Amazon Elastic File System (EFS):
With all these insights about the S3 and EFS storage services, it's essential to know when to use which service, and that's the purpose of this section. We’ll first introduce block, file, and object storage and then dive into the comparative aspect of S3 and EFS.
Block storage, file storage, and object storage are three fundamental types of data storage systems. Each serves different purposes in cloud computing and data management.
Block storage segments data into blocks, each with a unique identifier, allowing for flexible and efficient data management. Amazon Elastic Block Store (EBS) and Instance Store Volumes are examples of block storage in the AWS ecosystem.
Instance Store provides ephemeral storage directly attached to a host computer, ideal for temporary data. In contrast, EBS offers persistent block-level storage, making it suitable for databases, applications, and filesystems that require durability and incremental backups through snapshots.
File storage organizes data into a hierarchical structure of files and folders, similar to a traditional file system on a computer. This intuitive method simplifies data access and management across various applications and services.
Amazon Elastic File System (EFS) is an example of file storage in the cloud. It provides a shared file system that automatically scales and supports simultaneous access from multiple instances.
EFS is particularly beneficial for applications that require shared access to files or for serving content that several users or systems need to access and edit.
Object storage, like Amazon S3, is designed to store vast amounts of unstructured data. Unlike block and file storage, object storage manages data as objects within buckets.
Each object includes the data, metadata, and a unique identifier, allowing for efficient data retrieval and management at any scale. S3 is versatile, supporting a wide range of use cases from static website hosting to data archiving with its various storage classes, including Standard, Standard-Infrequent Access (IA), Glacier Flexible Retrieval, and Glacier Deep Archive.
Choosing between Amazon S3 and Amazon Elastic File System (EFS) depends on the specific requirements of your application or workload. Let’s look at the differences between each:
|
Feature |
Amazon S3 |
Amazon EFS |
|
Data type |
Unstructured data like images, videos, logs, and backups. |
Shared files that need to be accessed by multiple EC2 instances simultaneously. |
|
Storage scale |
Designed for vast amounts of data, scalable to exabytes. |
Automatically scales with your storage needs without manual intervention. |
|
Access pattern |
Ideal for data with varying access patterns, from frequently accessed to archival. |
Suited for data that requires consistent and simultaneous access by multiple applications. |
|
Integration |
Integrates with AWS services for data processing, analytics, and content delivery. |
Supports applications requiring a traditional file system interface. |
|
Storage classes |
Multiple storage classes. |
Not applicable. |
|
Cost considerations |
Storage costs vary by class, with options for infrequent access to reduce costs. |
Cost based on storage capacity used with no upfront cost and automatic scaling. |
|
Scalability and flexibility |
Highly scalable for both storage capacity and performance. |
Flexibility in scaling without needing to provision storage, handling peak loads easily. |
Now that we have a better understanding of the file storage concept, it's time to get our hands dirty with some technical implementation.
This section covers the process of managing data with Amazon S3. Specifically, we’ll learn how to create a bucket for storage, organize data into folders, upload files, adjust permissions for public access when needed, apply metadata for management, and finally, delete the bucket and its contents to clear resources and avoid extra costs.
The main prerequisite to successfully completing this section is having an AWS account, which can be created from the AWS website.
The starting point of this section is the Amazon Web Services Management Console, as shown below:
This console helps manage all AWS resources, from compute instances like EC2 to message queuing services like SQS, including security management.
Once on the console, the first step is to create an S3 instance. This can be done using the following steps (you can follow the numbers in the image below):
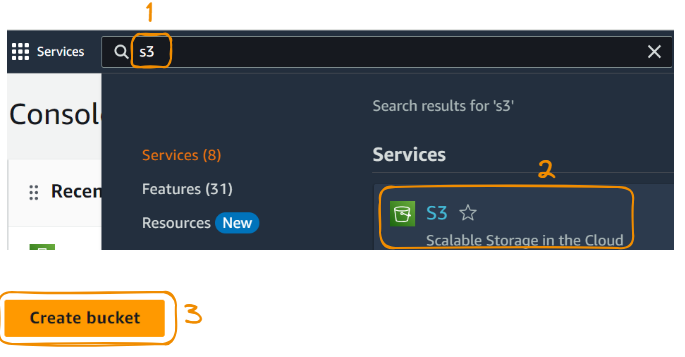
We now continue with a few more steps:
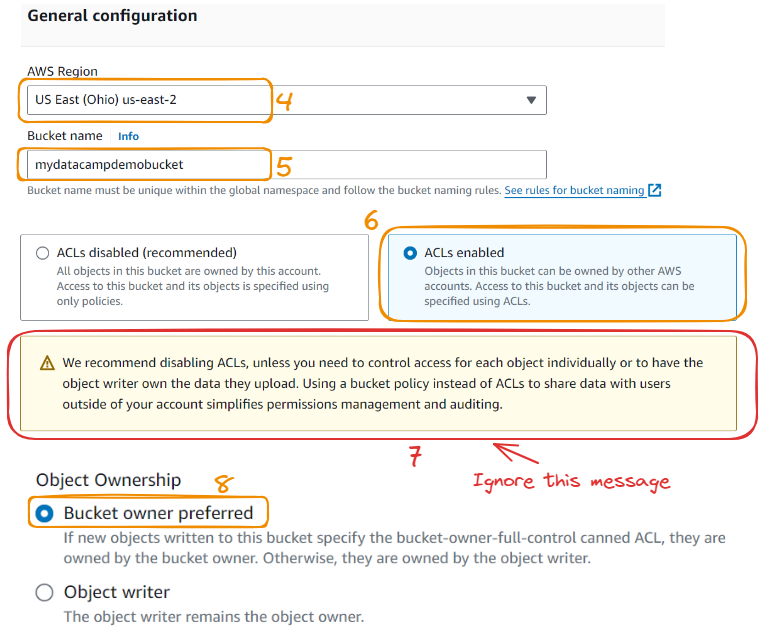
Let’s add a few notes to some of the steps we’ve covered:
Let’s create the bucket by taking three more steps:

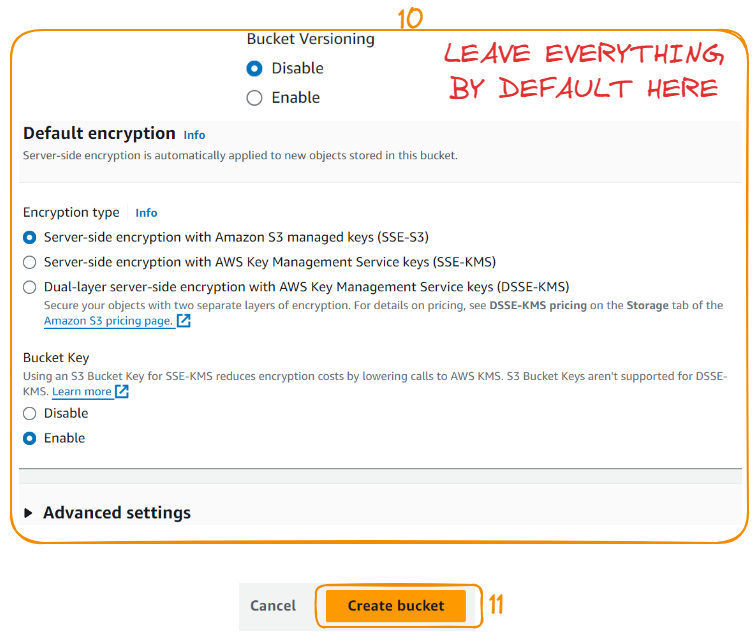
After creating the bucket, we can see the details below. A bucket is a container that can hold resources. Uploading resources starts with creating a folder. Let’s start by taking these two steps:
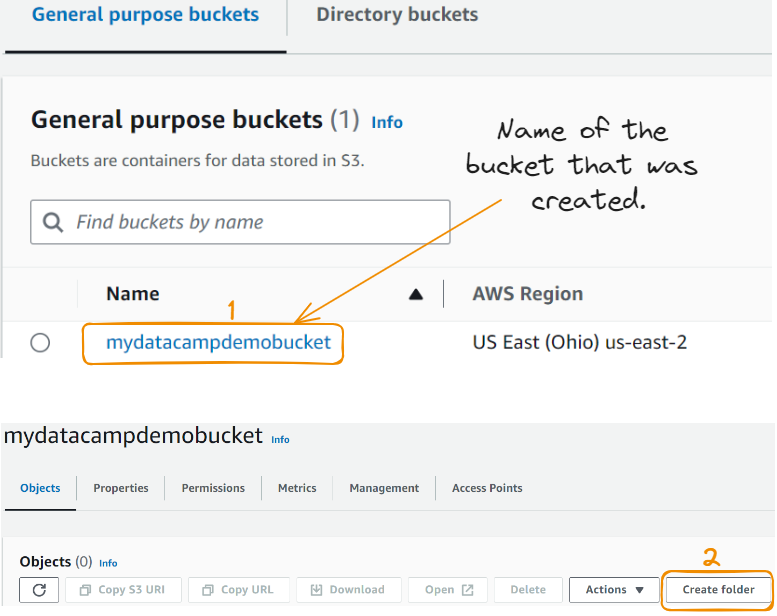
Let’s now create the folder:
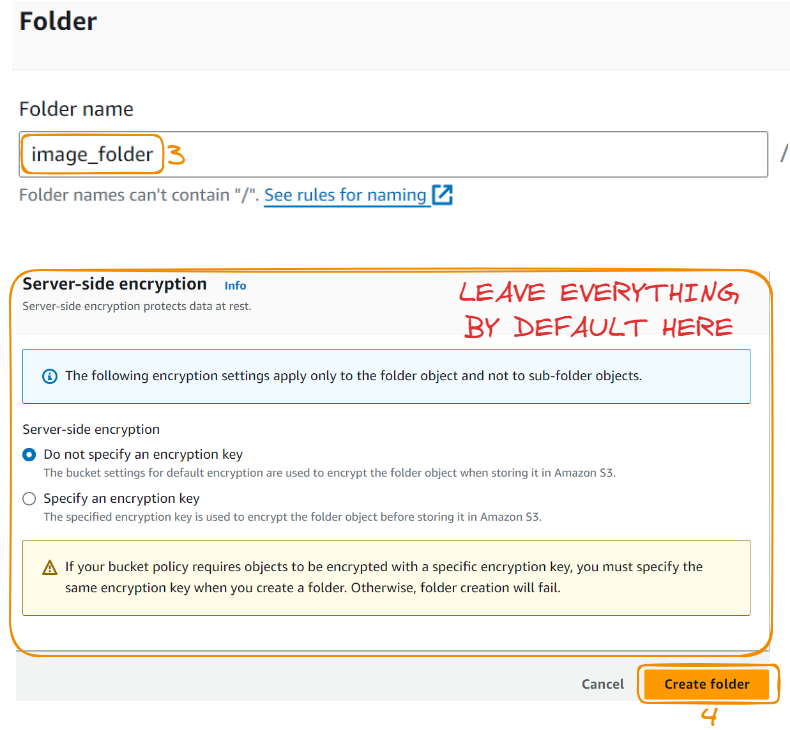
Notice that the folder has been created!

Now it's time to upload data in the folder. Let’s try uploading an image:
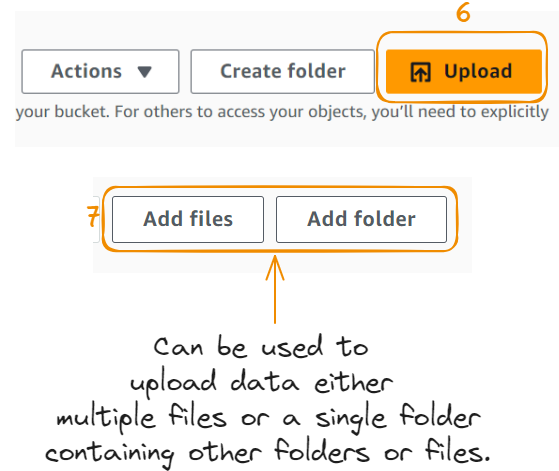
We uploaded the image successfully!
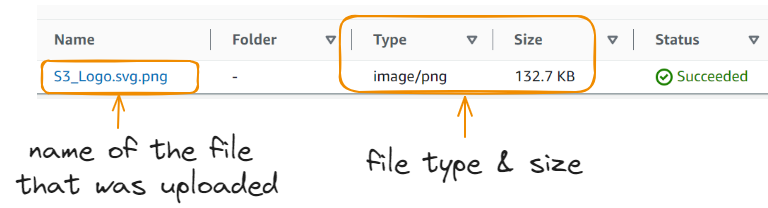
By default, all the files uploaded to the bucket are private and owned by the creator, and only the owner can view, edit, or download them. However, we may need to configure the bucket so anyone can access the file—this can be useful when everyone needs to view the photos on a website.
We can do this configuration by allowing all public access to the image. This should enable us to access the Object URL with public access, but unfortunately, we get an Access Denied message.
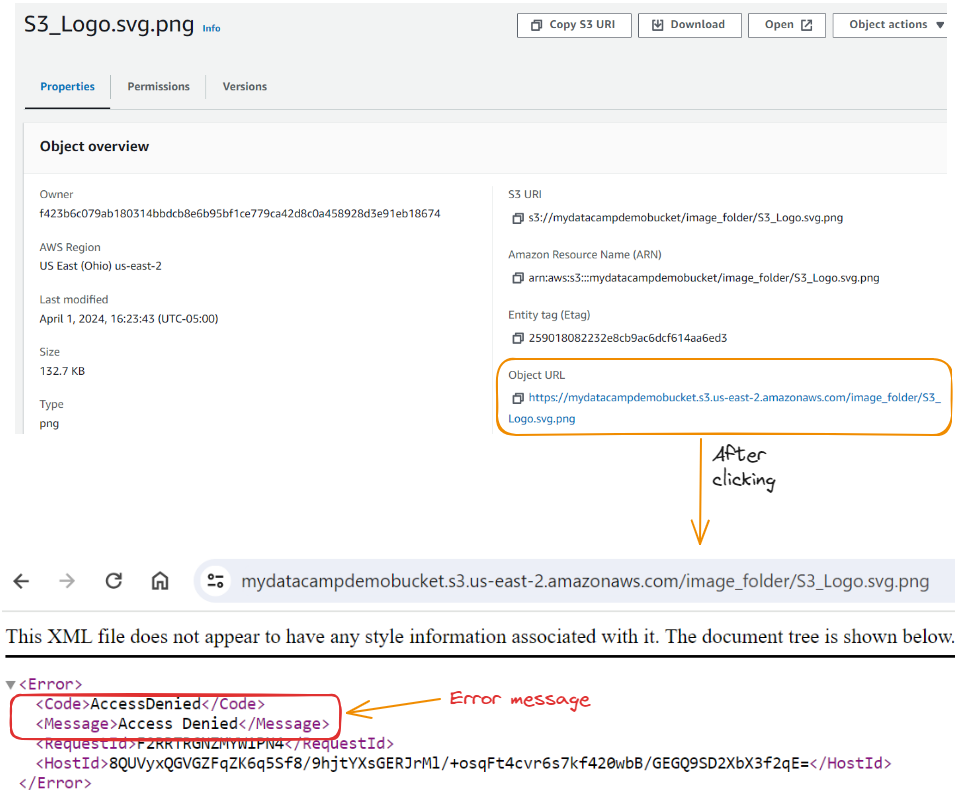
To fix this, we need to navigate to the Permissions tab at the buckets level and edit the Bucket Policy: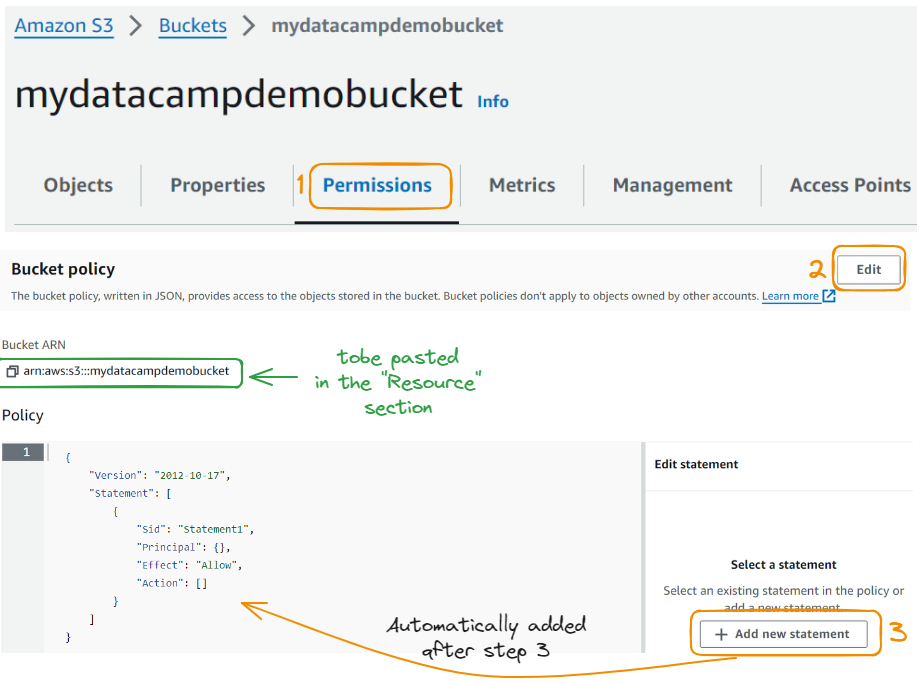
Now let’s edit the statement:
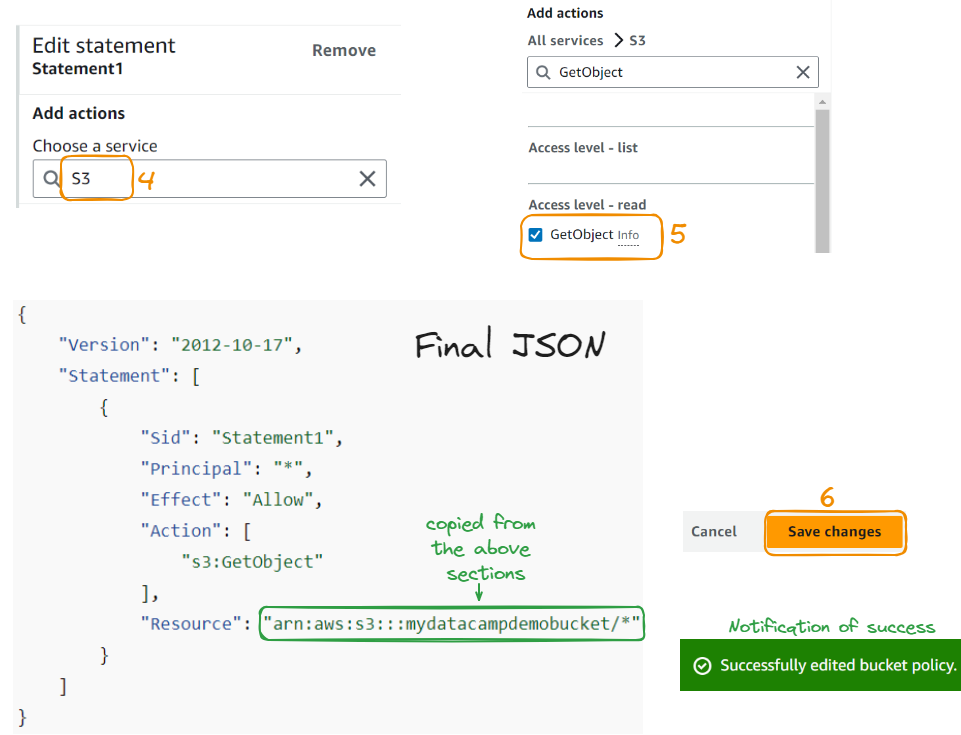 Now that we’ve made these changes, the image is finally displayed!
Now that we’ve made these changes, the image is finally displayed!

AWS logo after configuration of the access control
This section discusses creating an EFS file system, emphasizing performance and security settings.
We first create a security group by choosing the “Security Groups” option under the Security tab on the left banner.

Then, we:
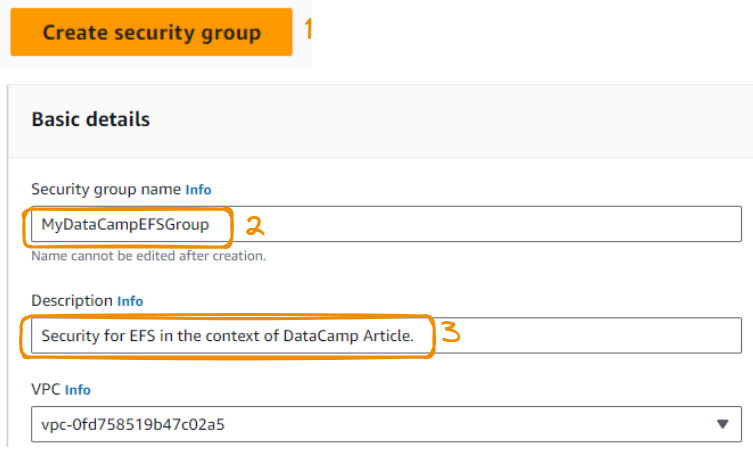
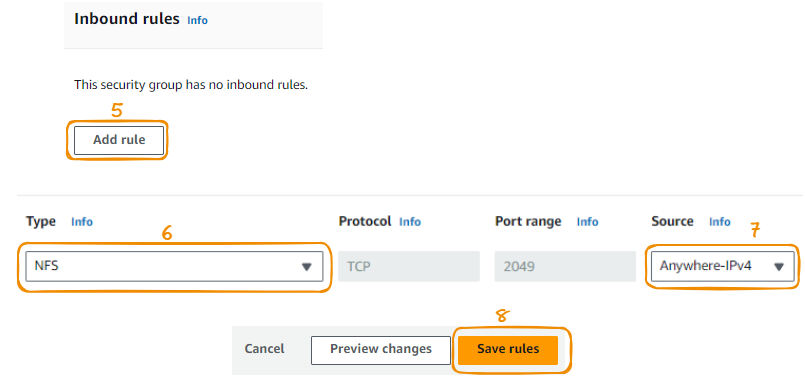
We don’t add any inbound rules:
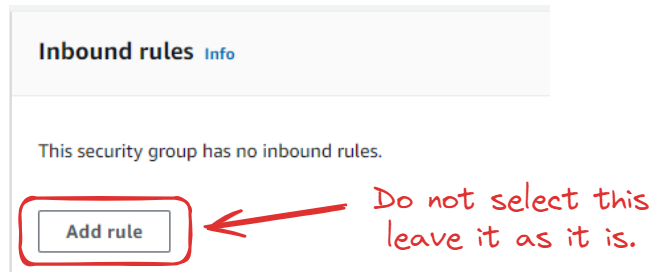
The type of Outbound rule 1 should be All traffic:
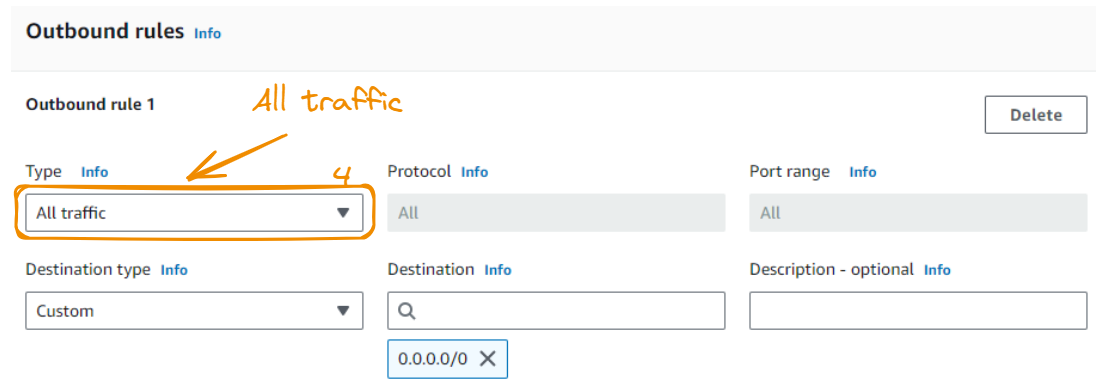
Now that we’re done with our configuration, we can click the Create security group button.
The newly created security group is displayed in the Security Groups section.
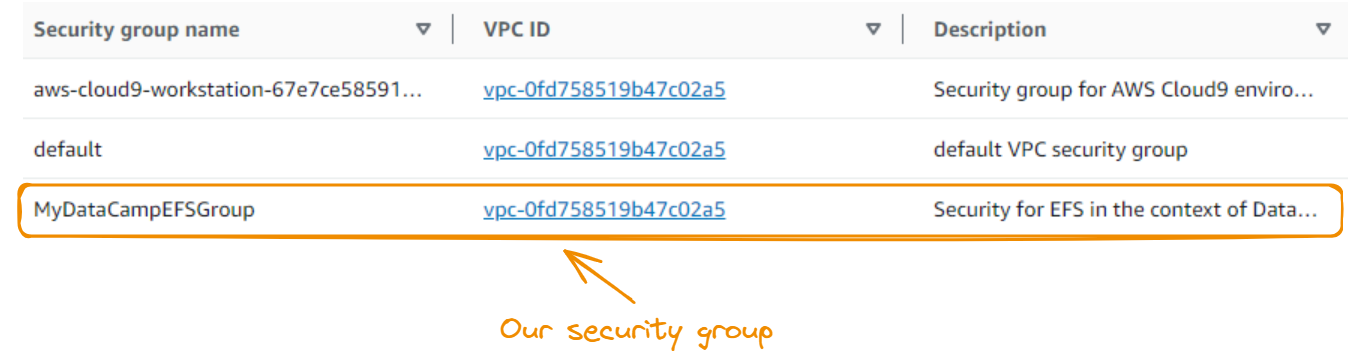
Next, we create an EFS file system. We start by searching and selecting EFS:
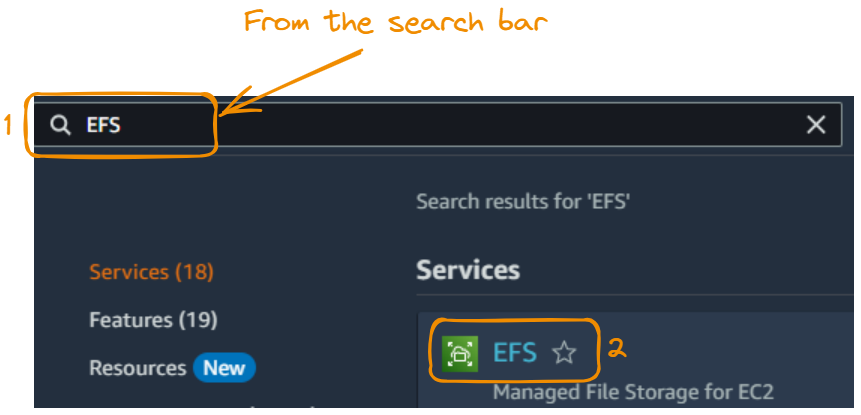
We now click on Create file system.
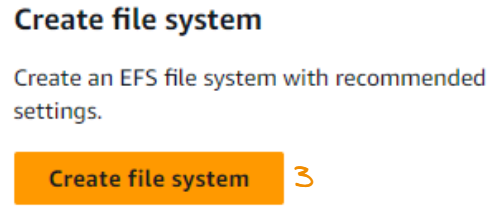
We use a meaningful name, leave the VPC section as it is, and then click on Customize.
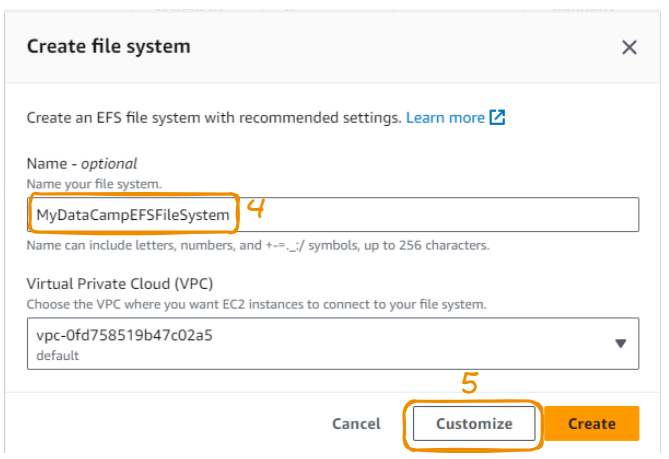
To access the network configuration page, we click Next.

We now fill out the security groups sections of each availability zone with MyDataCampEFSGroup.
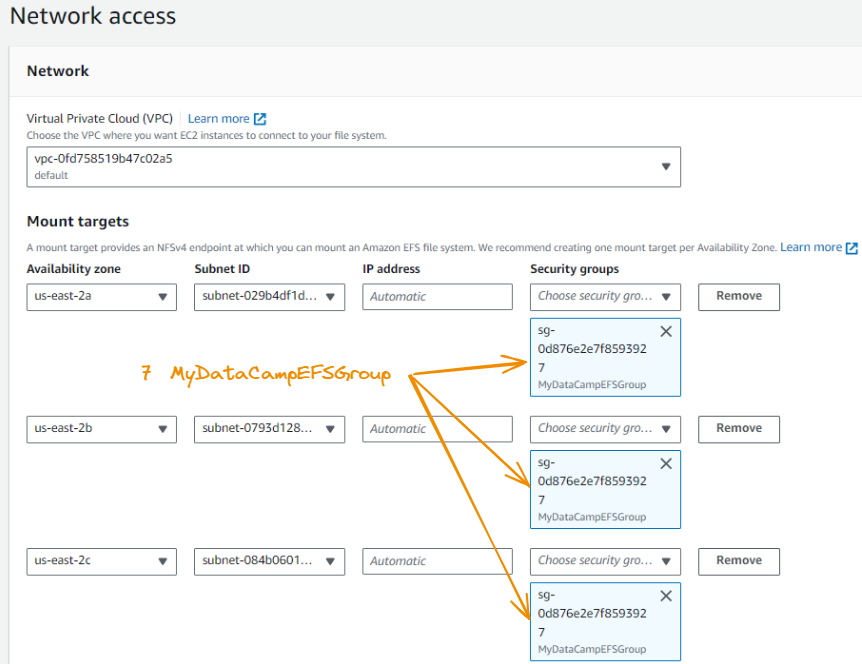
Once we’re done, we click on Next again.

The final step enables us to review the entire configuration. Once we’re satisfied with everything, we click on Create.
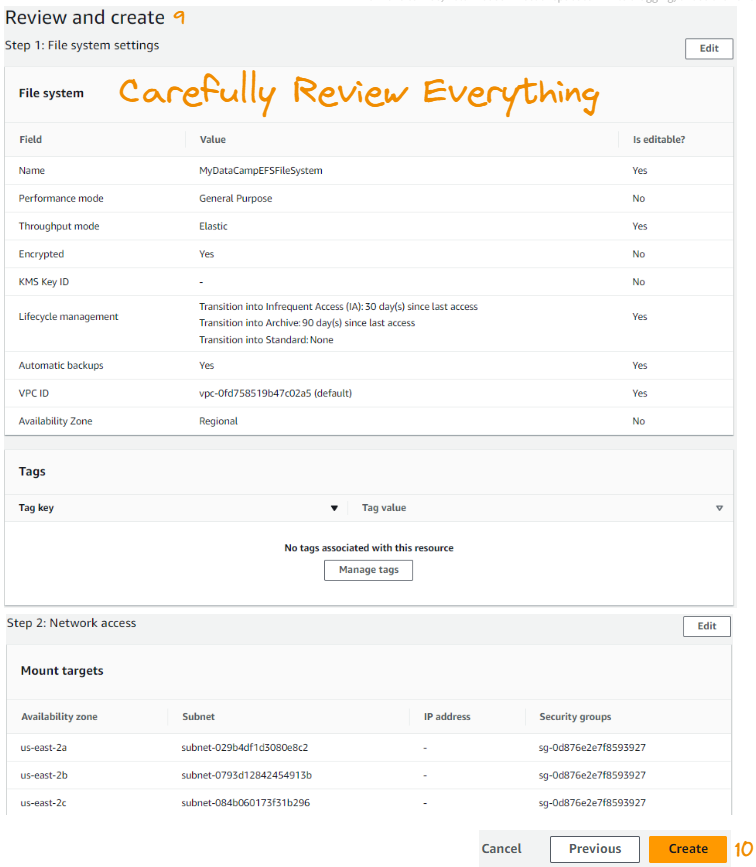
Once everything is successfully executed, we should see the newly created EFS file system in the File systems tab.
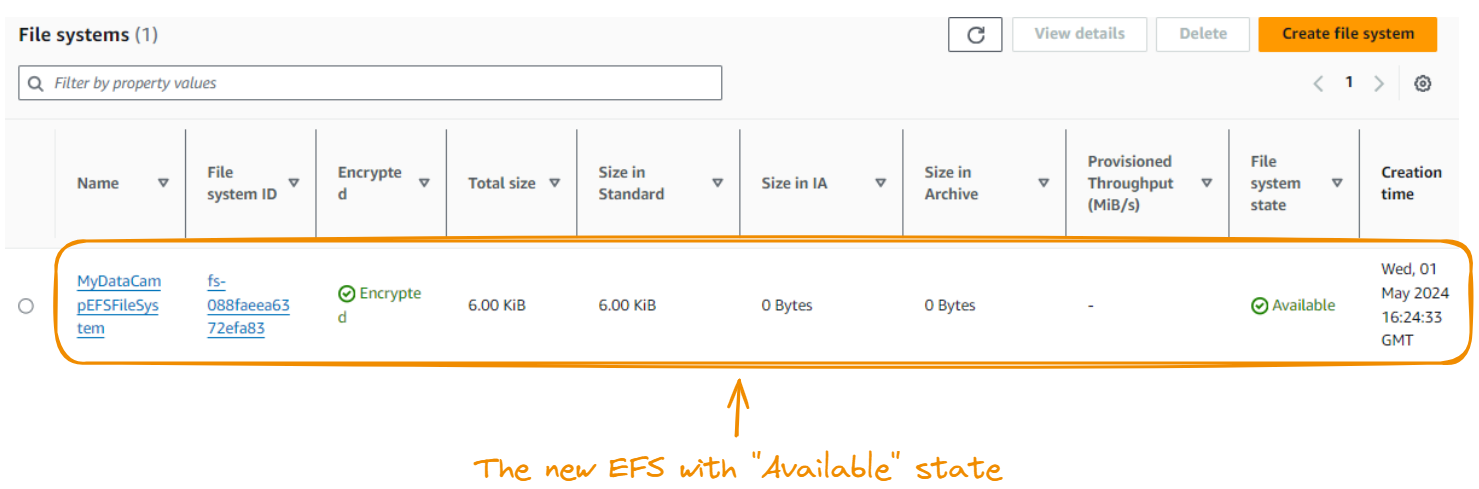
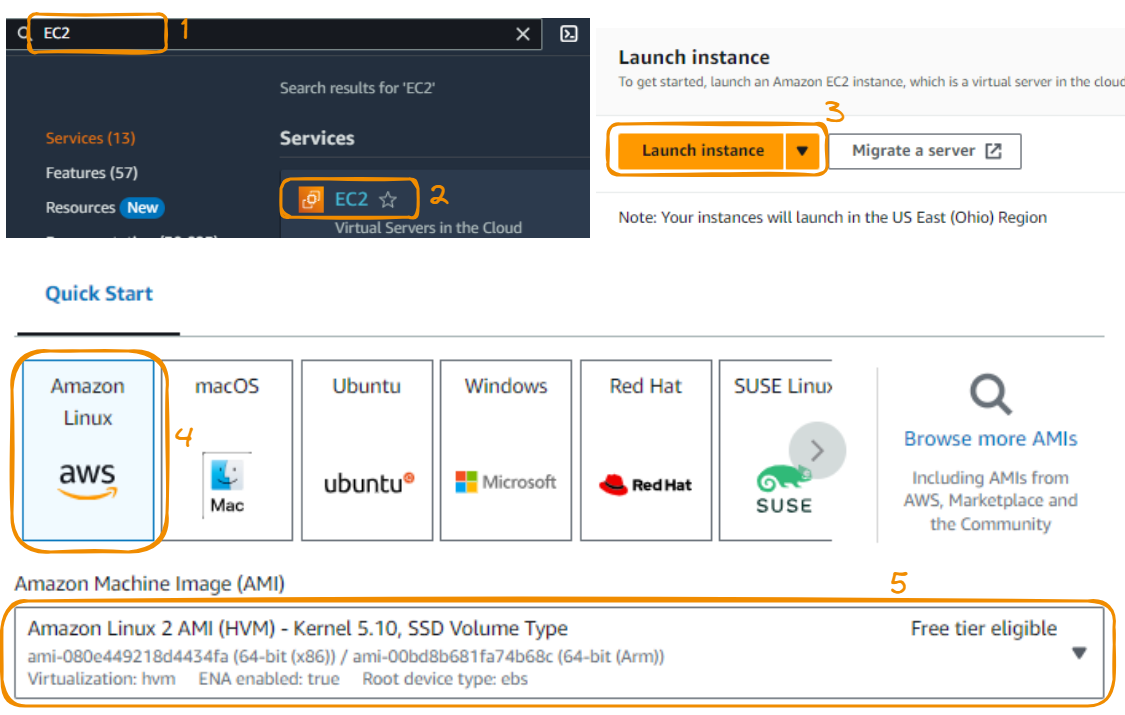
The next step is to create an EC2 instance, which provides EFS with the necessary computing environment and simultaneously accesses the same data.
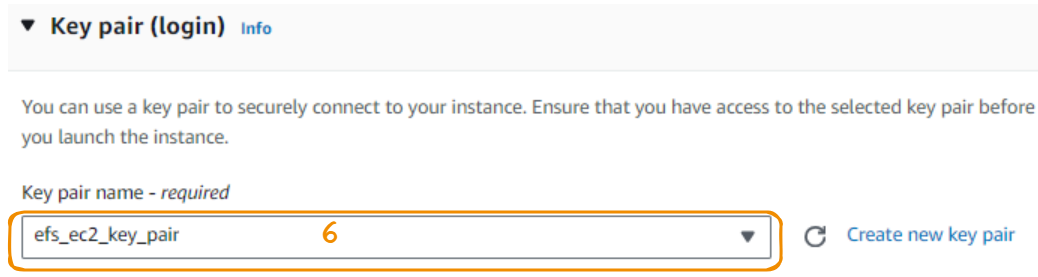
Let’s take everything step-by-step! We start by selecting an EC2 instance for the console. Then, we click on Launch instance. We’ll choose Amazon Linux 2, which comes eligible for a free tier.
We now create a key pair to securely connect to the instance. The one we make in this section has a .pem extension with the name efs_ec2_key_pair. This file is then downloaded and saved locally for further use.
The default storage capacity is 8GiB, which is enough for our scenario, and the number of instances is increased to 3. The final step is to launch the instance by clicking the Launch instance button, and the final result shows the newly created instances.
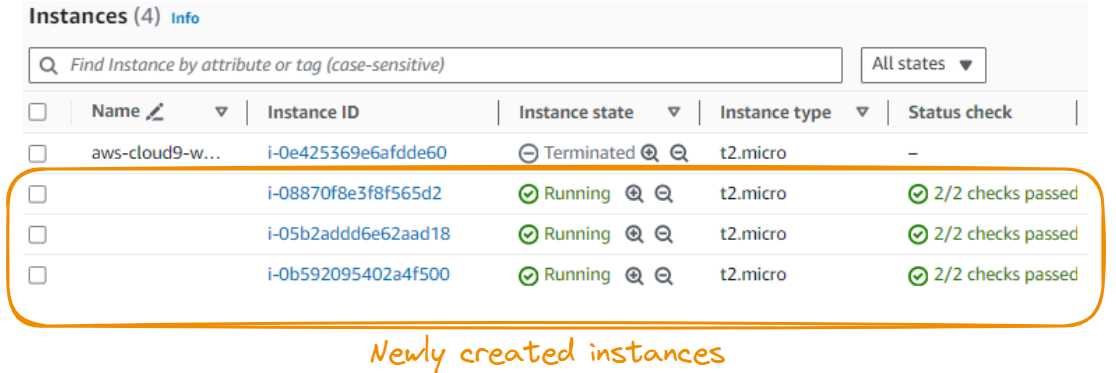
Before moving forward, let’s make sure connecting to the instances is possible. We’ll use the following SSH (Secure Shell) command:
ssh -i [path_to_the_key] ec2-user@[Public IPv4 address]Let’s break down this command step by step:
ssh: This is the command that initiates the SSH connection.-i [path_to_the_key]: This option specifies the path to our private SSH key file, which is required for authentication on the remote server.ec2-user: This is the default username for EC2 Linux instances. We can use a different username if configured.@: This symbol separates the username from the server's address.[Public IPv4 address]: This is the public IP address of our EC2 instance. We can find this address in the AWS Management Console.Let’s see the results of the connection to each instance through SSH.
 SSH connection result for the first instance.
SSH connection result for the first instance.
SSH connection result for the second instance.
SSH connection result for the third instance.
This final step allows the mounting of the EC2 instances created above. We can do this from the EFS general interface.
For simplicity’s sake, the mounting process is shown for only one instance, but the same approach applies to the remaining instances.
We start by installing the EFS mount helper for each instance by using the following command:
sudo yum install -y amazon-efs-utils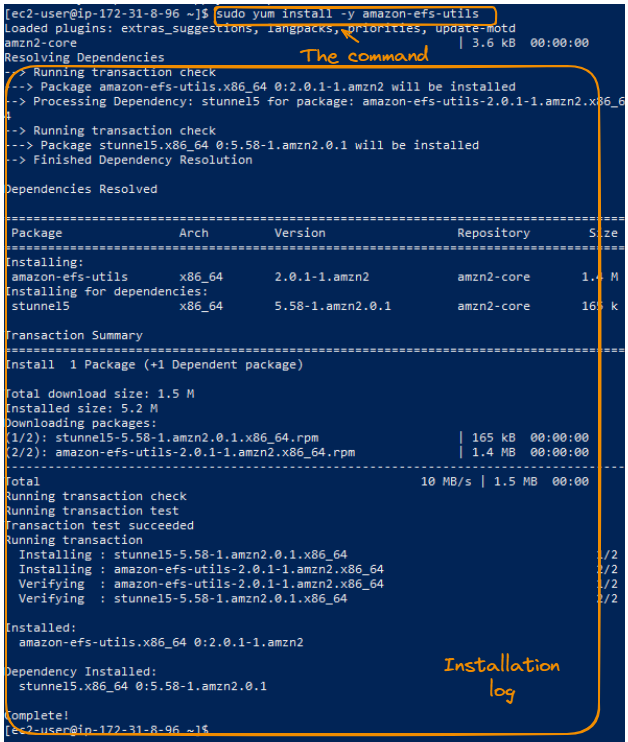
Installation of the Amazon EFS utilities—trace log.
We then create an efs folder in our instances at the root using sudo, making sure to use the same folder across all the instances.
sudo mkdir /efs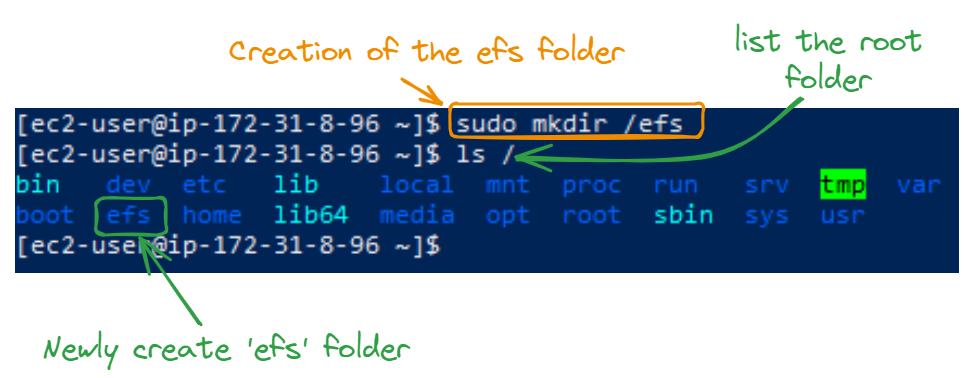
After successfully creating the folder, the next step is to mount it. The file system ID is the ID of the EFS we created in the EFS section, and we use it inside the sudo mount -t efs [file system ID]:/ /efs command:
sudo mount -t efs fs-088faeea6372efa83:/ /efs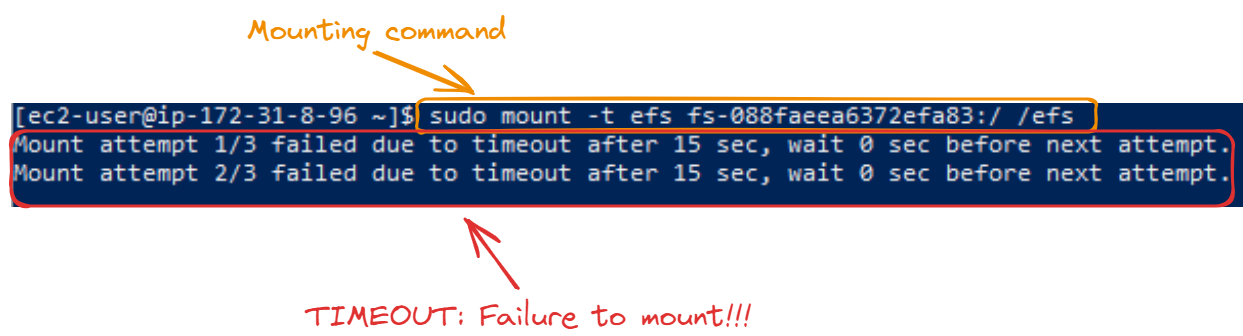
This timeout happens because the security group attached to the EFS system we created doesn’t allow any inbound traffic from our EC2 instances. We can fix this by enabling the security group to accept these inbound connections:
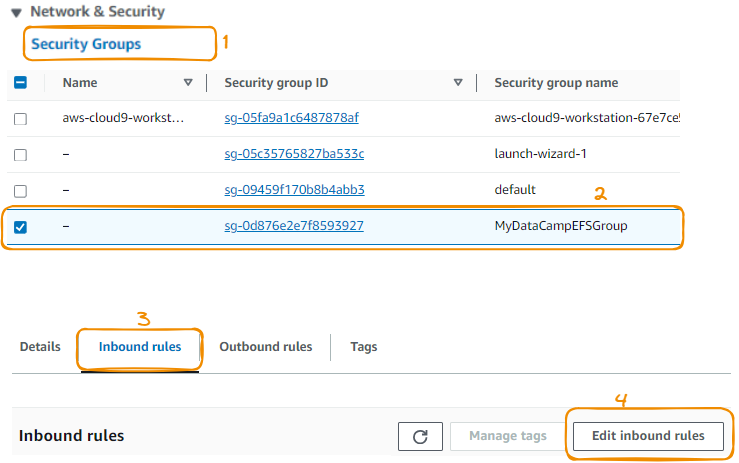
We now create a new inbound rule:
A more secure option is to create a separate security group for the EC2 instances, and only allow connection from that security group. That configuration is outside the scope of this article.
After successfully completing this process on each EC2 instance, the EFS system can accept connections from anywhere (including our EC2 instances). We don’t get any timeouts this time:

To make sure the mounting process was successful, we should be able to:
The illustration below shows how the my_DataCamp_data folder is created from the first EC2 instance, along with a README.txt file. The same README file can be seen across the remaining EC2 instances.

EFS file-sharing.
Thanks to the power of the EFS system configuration, a file created by one instance is accessible by the remaining instances.
To get a broader overview of the AWS ecosystem, check out this course on AWS Cloud Technology and Services.
Effective storage strategies are essential for managing data efficiently. Two key aspects of these strategies are performance optimization and cost optimization.
These strategies are particularly relevant to Amazon’s Simple Storage Service (S3) and Elastic File System (EFS).
Performance optimization in S3 and EFS involves selecting appropriate storage classes and throughput modes to enhance speed and efficiency.
Cost optimization involves using different storage tiers based on data access frequency and utilizing AWS monitoring tools for cost management. These strategies help in efficient data management and cost reduction in cloud storage.
Congratulations on getting this far! We hope this deep dive equips you to start using AWS storage.
One efficient way to master AWS services is to apply them to real-world scenarios—not only standalone but also by combining multiple services. If that sort of exercise sounds interesting to you, check out this course on Streaming Data with AWS Kinesis and Lambda.
If you’re looking to get a job in the AWS space, make sure to check out the relevant AWS certifications in 2024. Also, it could be very helpful to go through the top AWS interview questions and answers.
Learn more about AWS with these courses!
Course
Course
Course
blog
Joleen Bothma
12 min
Tutorial
Tim Lu
Tutorial
DataCamp Team
Tutorial
Zoumana Keita
Tutorial
Anneleen Rummens
Tutorial
Joleen Bothma
