Programa
Desenvolvimento de modelos de idiomas grandes
16 h
Imagine um grande modelo de linguagem (LLM, Large Language Model) em que as respostas que você obtém não são apenas relevantes; elas são muito bem selecionadas, priorizadas e refinadas para atender exatamente às suas necessidades. Embora os LLMs tenham revolucionado o campo da IA, enfrentam limitações. Problemas como alucinações e obsolescência de dados podem comprometer a precisão e a relevância dos resultados. É nesse ponto que entram em cena a geração aumentada por recuperação (RAG, Retrieval-Augmented Generation) e o reranking, oferecendo uma maneira de aprimorar os LLMs, integrando-os a processos dinâmicos e atualizados de recuperação de informações. Está curioso para saber as etapas desse procedimento? Continue lendo.
Os LLMs revolucionaram o campo da IA e ampliaram os limites do que podemos alcançar com o uso da IA. Eles se tornaram a ferramenta ideal para quem busca soluções versáteis de PLN em praticamente qualquer domínio, modelando uma série de tarefas de compreensão e geração de linguagem natural, conforme mostrado abaixo.
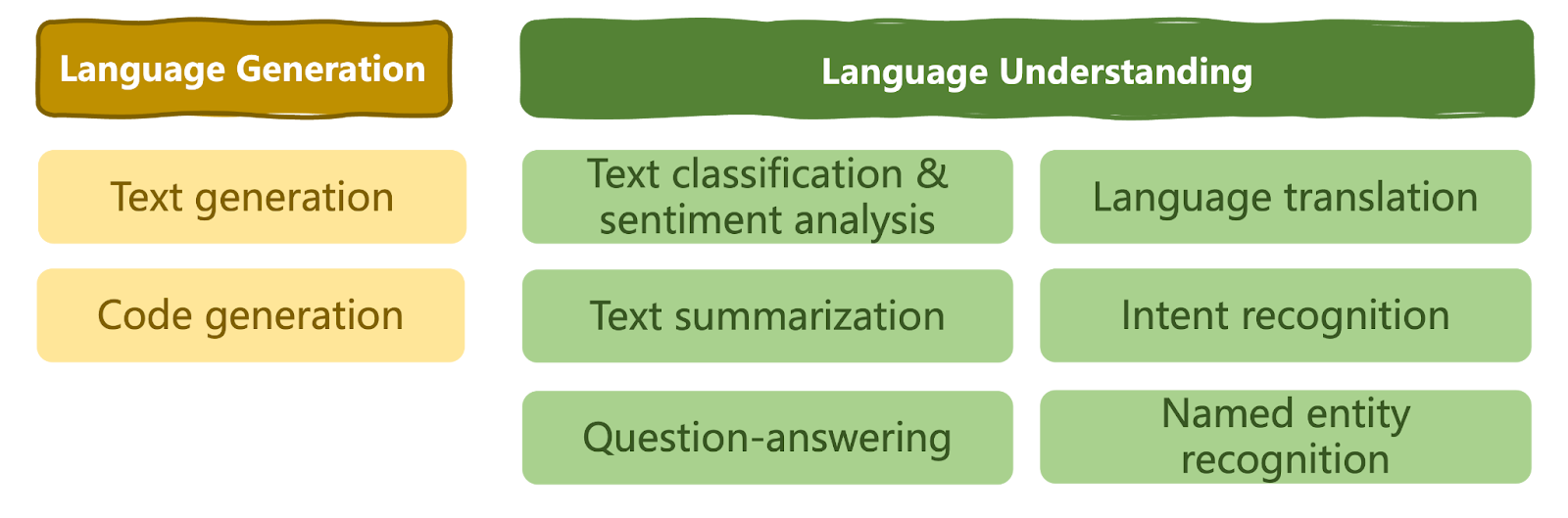
Taxonomia de tarefas de linguagem que podem ser solucionadas por LLMs | Iván Palomares
Apesar de seus recursos, os LLMs também têm limitações em determinadas situações. Dependendo do caso de uso específico e do conhecimento que aprenderam com o vasto conjunto de dados com que foram treinados, os LLMs às vezes não conseguem gerar um texto coerente, relevante ou adequado ao contexto. Às vezes, na ausência de dados verdadeiros relevantes para criar uma resposta às consultas do usuário, eles podem até gerar informações incorretas ou sem sentido como se fossem verdadeiras. Esse fenômeno é conhecido como alucinação.
Observe, por exemplo, a pergunta: "Quais são os sintomas comuns da gripe?"
Um LLM padrão pode gerar uma resposta com base no conhecimento geral, listando sintomas comuns como febre, tosse e dores no corpo.
No entanto, a menos que tenha sido treinado com dados sobre o vírus da gripe muito específicos do domínio, o LLM pode não considerar variações na gravidade dos sintomas ou distinguir entre cepas de gripe, fornecendo, assim, respostas bastante genéricas e até mesmo um pouco "automatizadas" para diferentes usuários, independentemente de suas circunstâncias ou necessidades.
Além disso, se, por exemplo, o modelo tiver sido treinado com dados clínicos de gripe coletados até dezembro de 2023 e uma nova cepa de gripe surgir e se espalhar rapidamente pela população em janeiro de 2024, um LLM autônomo não conseguirá fornecer respostas precisas devido à falta de conhecimento atualizado sobre o domínio do problema.
Esse problema de "obsolescência de dados" é conhecido como corte de conhecimento.
Em alguns casos, a solução para o problema acima poderia ser o retreinamento frequente e o ajuste fino do LLM com base em informações novas e atualizadas. Mas será que esse é necessariamente o melhor plano de ação?
Os LLMs (Large Language Models) são conhecidos por serem desafiadores e computacionalmente caros para treinar. Exigem de milhões a bilhões de instâncias de dados de texto e, muitas vezes, milhares de textos específicos do domínio para ajuste fino (veja o diagrama abaixo).
A maioria dos LLMs, mesmo os específicos de um domínio, costuma ser ajustada para funcionar em domínios de amplo escopo, como o da saúde. Portanto, a introdução de novos dados detalhados para dar conta de todas as nuances contextuais possíveis em todo o domínio pode não ser a solução mais eficiente.
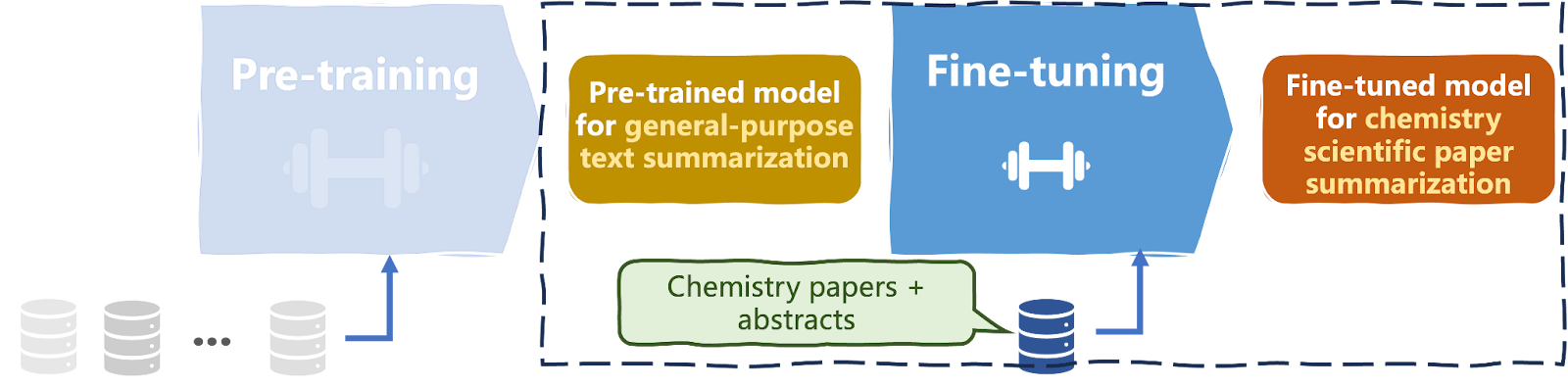
Pré-treinamento e ajuste fino de um LLM
É aí que o RAG (Retrieval Augmented Generation, geração aumentada por recuperação) entra para ajudar!
O RAG é um processo de recuperação de informações por meio do qual os resultados produzidos por um LLM são otimizados. Para gerar respostas, os LLMs dependem do conhecimento obtido com os dados usados para criá-los.
Enquanto isso, o RAG aponta para uma base de conhecimento externa.
Ao combinar as duas soluções, o RAG pode ser usado para melhorar a qualidade, a relevância para o usuário, a coerência e a veracidade do resultado "bruto" gerado pelo LLM, recuperando conhecimentos da base de conhecimento mencionada anteriormente.
Como resultado, a necessidade de retreinar continuamente o LLM para adaptá-lo a novos contextos e situações sempre surgem é em grande parte eliminada.
O fluxo de trabalho geral de um sistema de RAG é descrito de forma simplificada abaixo:
Voltando ao exemplo da gripe, vemos que, com o RAG, o modelo pode recuperar informações atualizadas e relevantes de bancos de dados médicos ou artigos recentes, permitindo gerar uma resposta mais detalhada e precisa à consulta do paciente ou do médico.
Ele pode incluir informações úteis sobre as cepas de gripe atuais, variações regionais nos sintomas ou padrões emergentes, fornecendo assim uma resposta mais relevante e coerente à consulta do usuário.
O reranking é um processo de recuperação de informações em que um conjunto inicial de resultados recuperados é reordenado para aumentar a relevância para a consulta, as necessidades e o contexto do usuário, melhorando assim a qualidade geral do resultado. Veja como funciona:
O diagrama a seguir ilustra o processo de reranking:
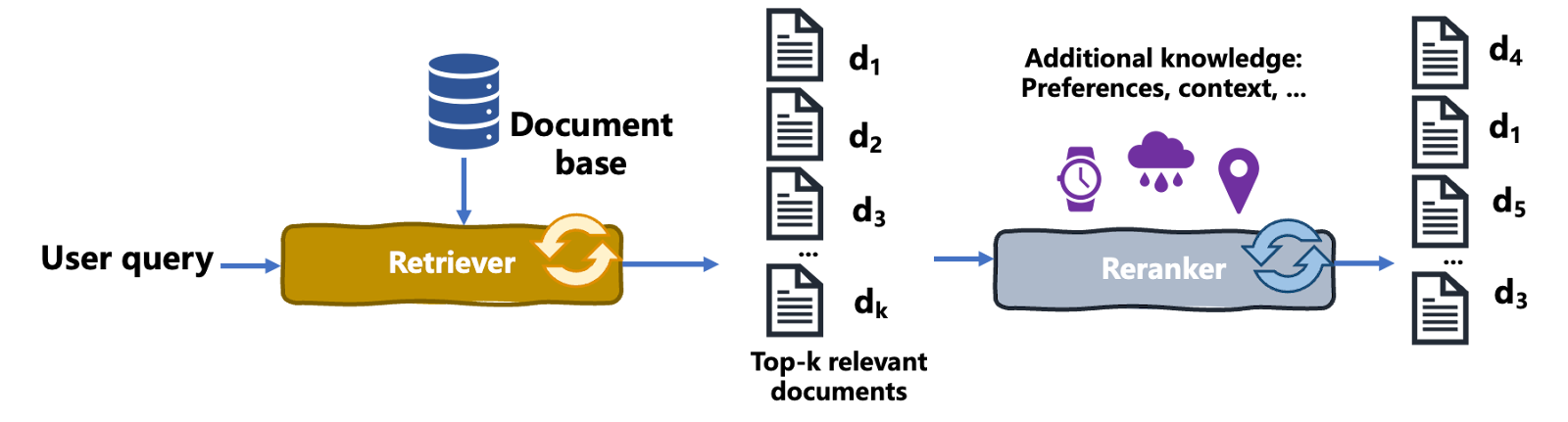
Processo de reranking | Iván Palomares
Vamos esclarecer um ponto importante aqui: o reranking reordena os documentos recuperados com base em vários critérios, como as preferências do usuário. No entanto, o reranking é diferente dos mecanismos de recomendação, como os que sugerem produtos relevantes para compra em sites de comércio eletrônico.
O reranking é usado em casos de uso de pesquisa em que um usuário fornece uma consulta de entrada em tempo real.
Por outro lado, os mecanismos de recomendação criam proativamente sugestões personalizadas para os usuários com base em suas interações e preferências ao longo do tempo.
Vamos voltar ao exemplo da gripe.
Considere uma situação em que um profissional de saúde pesquisa "melhores tratamentos para sintomas de gripe". Um sistema de recuperação inicial pode retornar uma lista de documentos, incluindo informações gerais sobre a gripe, diretrizes de tratamento e artigos de pesquisa.
Mas um modelo de reranking, possivelmente usando mais dados específicos do paciente e informações contextuais, pode reordenar esses documentos para priorizar os protocolos de tratamento mais relevantes e recentes, dicas de cuidados com o paciente e estudos de pesquisa revisados por pares que abordam diretamente os sintomas da gripe e seu tratamento, priorizando assim os resultados que vão "direto ao ponto".
Em resumo, o reranking reorganiza uma lista de documentos recuperados com base em outros critérios de relevância para exibir primeiro os mais relevantes para o usuário específico.
O reranking é útil sobretudo em grandes modelos de linguagem (LLMs) que contam com RAG (Retrieval-Augmented Generation). O RAG combina LLMs com recuperação de documentos externos para dar respostas mais embasadas e precisas.
Após a recuperação inicial de documentos com base em uma consulta, um processo de reranking pode refinar a seleção, garantindo que o LLM trabalhe com as informações mais relevantes e de alta qualidade.
Esse processo aprimora o desempenho geral do LLM, melhorando a precisão e a relevância das respostas, principalmente em domínios especializados em que informações precisas são essenciais.
Não existe uma receita única para implementar um reranker. Várias abordagens foram estabelecidas, entre elas:
Agora que entendemos os benefícios de incorporar o RAG aos LLMs, bem como os mecanismos de reranking para recuperação de conhecimento, é hora de integrar esses elementos e vê-los em ação.
Este exemplo usa a biblioteca Langchain (versão comunitária) para criar um pipeline RAG simples com reranking. Descubra muito mais sobre o desenvolvimento de aplicativos LLM com o Langchain no curso Desenvolvimento de Aplicativos LLM e neste tutorial sobre como criar aplicativos LLM com o Langchain.
O código foi implementado em um notebook do Google Colab.
pip install -U langchain-communityPrimeiro, instalamos o langchain-community em nosso notebook.
Em seguida, importamos os pacotes, as classes e as funções necessárias.
import os
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import Document
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from sklearn.metrics.pairwise import cosine_similarity
import numpy as npA função a seguir é definida para carregar uma lista de documentos (arquivos .txt) de um diretório local que o seu notebook de código seja capaz de ler. Esses serão os documentos a serem recuperados e reclassificados para aprimorar os resultados do LLM:
# Function to load documents from a directory
def load_documents_from_directory(directory_path):
documents = []
for filename in os.listdir(directory_path):
if filename.endswith(".txt"):
with open(os.path.join(directory_path, filename), 'r') as file:
documents.append(file.read())
return documents
# Load documents from the specified directory
directory_path = "./sample_data"
documents = load_documents_from_directory(directory_path)
Para otimizar o desempenho da incorporação de representações de documentos de texto, limitamos seu tamanho a 1.000 e dividimos documentos com extensões maiores em partes menores. A classe CharacterTextSplitter ajuda a fazer isso.
O argumento chunk_overlap é definido como 0 para evitar a sobreposição de partes do texto nos blocos.
# Split documents into chunks for better embedding performance
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
Usaremos as incorporações (embeddings) da OpenAI para criar nosso armazenamento de vetores de incorporações. Observe que, dependendo do ambiente em que você estiver executando o código, talvez seja necessário obter uma chave de validação da OpenAI definida em OPENAI_API_KEY.
# Initialize OpenAI embeddings
embeddings = OpenAIEmbeddings()
# Build FAISS vector store upong document chunk embeddings
vector_store = FAISS.from_documents(docs, embeddings)
# Load and initialize OpenAI LLM
llm = OpenAI(model="text-davinci-003", temperature=0.7)O FAISS cria um armazenamento de vetores a partir das incorporações. Precisamos passar dois argumentos na função from_documents(). Os blocos de documentos e a instância de incorporações inicializada com a ajuda do OpenAIEmbeddings.
Depois disso, trazemos ao palco um dos atores principais: o LLM! Usamos o OpenAI para carregar o modelo text-davinci-003, definindo uma temperatura de modelo moderadamente alta de 0,7 para permitir algum grau de originalidade na geração de textos.
Vamos dar mais alguns passos:
# Define the prompt template for the LLM
prompt_template = PromptTemplate(template="Answer the question based on the context: {context}\n\nQuestion: {question}\nAnswer:")
# Define the RAG chain with reranking using a QA chain
qa_chain = load_qa_with_sources_chain(llm, prompt_template=prompt_template, retriever=vector_store.as_retriever())
# Example question
question = "What are the common symptoms of the flu and how can it be treated?"
# Generate an answer using the QA chain
response = qa_chain(question=question)
print(response)O código acima define primeiro um modelo de prompt de resposta a perguntas. Em seguida, ele chama a função load_qa_with_sources_chain() para criar um pipeline de perguntas e respostas (ou cadeia, no jargão da Langchain). Seu argumento retriever permite incorporar um componente de recuperação no pipeline do LLM, possibilitando assim o RAG.
Finalmente, uma pergunta é formulada e executamos o pipeline qa_chain definido. Voila!
Aqui está o resultado (depende dos documentos usados na leitura):
"Os sintomas comuns da gripe incluem febre, tosse, dor de garganta, coriza ou nariz entupido, dores no corpo, dor de cabeça, calafrios e fadiga. Algumas pessoas podem apresentar vômitos e diarreia, principalmente crianças. A gripe pode ser tratada com medicamentos antivirais, que podem tornar a doença mais branda e encurtar a duração da enfermidade. Os medicamentos antivirais também podem evitar complicações graves, como a pneumonia. O tratamento imediato é recomendado para indivíduos muito doentes ou com alto risco de complicações."
O exemplo anterior parecia bom, exceto pelo fato de não ter incluído a fase de reranking. É relativamente simples modificar o código para incluir o reranking.
A lista de importações é a mesma, pois já havíamos feito na versão anterior todas as importações necessárias para a fase de reranking, embora ainda não tivéssemos usado algumas delas:
# Previous code here
#...
# Define the prompt template for the LLM
prompt_template = PromptTemplate(template="Answer the question based on the context: {context}\n\nQuestion: {question}\nAnswer:")
# Reranking function
def rerank_documents(question, retrieved_docs, top_n=5):
question_embedding = embeddings.embed_text(question)
doc_embeddings = [doc.embedding for doc in retrieved_docs]
similarities = cosine_similarity([question_embedding], doc_embeddings)[0]
ranked_indices = np.argsort(similarities)[::-1] # Sort by descending similarity
ranked_docs = [retrieved_docs[i] for i in ranked_indices[:top_n]]
return ranked_docsComo vemos, o que fazemos primeiro é definir uma função rerank_documents que usa a similaridade de cosseno nas incorporações para calcular a similaridade entre a incorporação da pergunta e as incorporações do documento, retornando os n documentos mais bem classificados.
# Custom QA chain with reranking
class CustomQAWithReranking:
def __init__(self, llm, retriever, prompt_template, top_n=5):
self.llm = llm
self.retriever = retriever
self.prompt_template = prompt_template
self.top_n = top_n
def __call__(self, question):
retrieved_docs = self.retriever.retrieve_documents(question)
ranked_docs = rerank_documents(question, retrieved_docs, self.top_n)
context = "\n".join([doc.page_content for doc in ranked_docs])
prompt = self.prompt_template.format(context=context, question=question)
return self.llm(prompt)A classe CustomQAWithReranking integra no LLM as etapas de recuperação e reranking no pipeline do LLM, que serão invocadas chamando a função call () nessa classe.
# Define the custom QA chain with reranking
qa_chain = CustomQAWithReranking(llm, vector_store.as_retriever(), prompt_template)
# Example question
question = "What are the benefits of using multi-vector rerankers?"
# Generate an answer using the custom QA chain
response = qa_chain(question)Tudo o que você precisa fazer é instanciar again qa_chain. Observe que, desta vez, faremos isso definindo um objeto da classe que acabamos de criar, que encapsula a maior parte da lógica da versão anterior, além do mecanismo de reranking personalizado.
Por fim, formulamos a pergunta e invocamos a cadeia para obter uma resposta.
No âmbito dos LLMs e da IA como um todo, o RAG veio para ficar. Fazer com que um LLM acesse e recupere conhecimento de fontes externas como parte do processo de geração de respostas tornou-se uma alternativa amplamente aceita ao constante retreinamento e ajuste fino dos LLMs.
Este artigo discutiu o reranking como uma abordagem útil para incorporar a recuperação eficaz de informações como parte de um pipeline de LLM. Destacou como funciona o processo de reranking, os diferentes tipos de rerankers e um exemplo prático usando o Langchain e a API OpenAI.
Tem interesse em saber mais? Dê uma olhada nestes recursos complementares:
Saiba mais sobre LLMs
Programa
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Abid Ali Awan
8 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
