Programa
Desenvolvimento de aplicativos de IA
21 h
O Llama 3.1 é uma boa opção para o RAG, uma técnica que combina sistemas de recuperação com os recursos de geração de texto dos modelos de linguagem para garantir resultados mais precisos e relevantes.
No RAG, um sistema de recuperação primeiro examina grandes conjuntos de dados para encontrar as informações mais relevantes, que o modelo de linguagem usa para gerar a resposta final. Isso é particularmente útil para tarefas como responder a perguntas, criar chatbots e lidar com tarefas com muitas informações, em que os modelos de linguagem tradicionais podem dar respostas desatualizadas ou irrelevantes.
Com sua capacidade de lidar com até 128 mil tokens e suporte a vários idiomas, o Llama 3.1 aprimora a qualidade e a confiabilidade do conteúdo gerado por IA nos sistemas RAG.
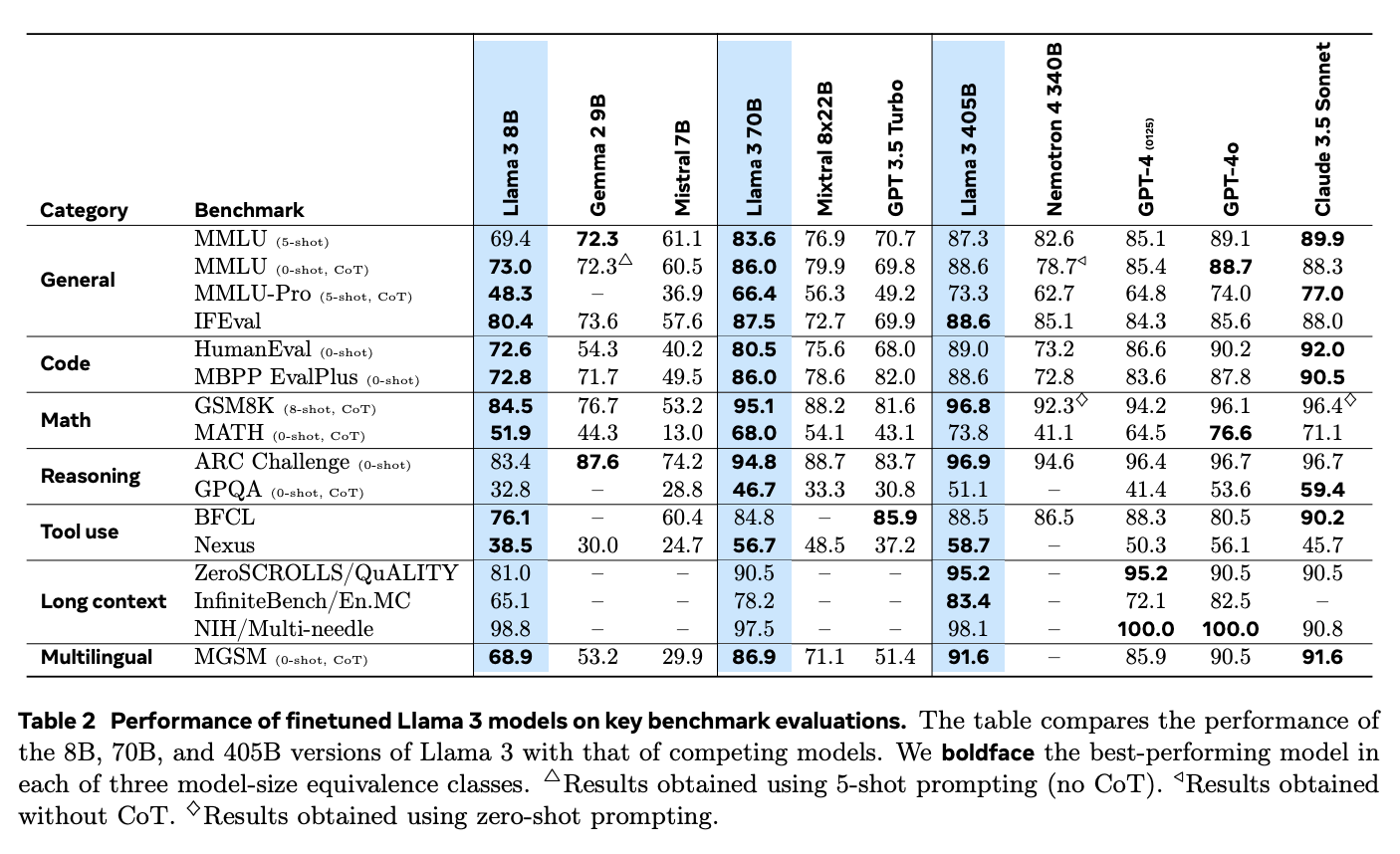
Fonte: O rebanho de modelos Llama 3
Além disso, o Llama 3.1 se destaca em aplicativos RAG quando comparado a modelos de código fechado como GPT-4o e Claude 3.5 Sonnet. Suas sólidas habilidades de raciocínio e sua capacidade de processar textos mais longos permitem que ele lide melhor com perguntas complexas e forneça respostas mais relevantes.
No benchmark Needle-in-a-Haystack (NIH), que testa a capacidade de um modelo de encontrar informações específicas ("agulhas") em grandes volumes de texto ("palheiros"), a Llama 3.1 se destaca com uma taxa de recuperação quase perfeita em todos os tamanhos de modelo. Isso demonstra sua capacidade de gerenciar tarefas de pesquisa complexas, tornando-o ideal para sistemas RAG que precisam extrair informações precisas de grandes conjuntos de dados.
O modelo também teve um desempenho excepcional no benchmark Multi-needle, que exige a recuperação de várias informações com precisão. Seus resultados quase perfeitos nesse teste comprovam ainda mais sua capacidade de lidar com tarefas de recuperação complexas.
Para configurar um aplicativo RAG com o Llama 3.1, são necessárias várias etapas. Isso inclui o download do modelo Llama 3.1 para o seu computador local, a configuração do ambiente, o carregamento das bibliotecas necessárias e a criação de um mecanismo de recuperação. Por fim, combinaremos isso com um modelo de linguagem para criar um aplicativo completo.
Abaixo está um guia claro e passo a passo para ajudar você a implementar um aplicativo RAG usando o Llama 3.1.
Primeiro, instale o aplicativo Ollama, que nos permite executar o Llama 3.1 e outros modelos de linguagem de código aberto em seu computador local. Você pode fazer o download do aplicativo Ollama em seu site oficial.
Depois que você instalar e abrir o Ollama, a próxima etapa é fazer o download do modelo Llama 3.1 para o computador local. Para este tutorial, usaremos a versão de parâmetro 8B. Para fazer o download, abra o terminal e execute a seguinte linha de comando:
ollama run llama3.1Depois que o download do modelo for concluído, estaremos prontos para conectá-lo usando o Langchain, e mostraremos a você como fazer isso em seções posteriores.
Antes de começar, verifique se você tem as bibliotecas Python corretas instaladas. Você precisará de bibliotecas como langchain, langchain_community, langchain-ollama, langchain_openai. Se você ainda não os instalou, pode fazê-lo usando pip com este comando:
pip install langchain langchain_community langchain-openai scikit-learn langchain-ollamaA primeira etapa na criação do sistema RAG é carregar os documentos que você deseja usar como base de conhecimento. Neste exemplo, usaremos páginas da Web como fonte.
Veja como você pode fazer isso:
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# List of URLs to load documents from
urls = [
"<https://lilianweng.github.io/posts/2023-06-23-agent/>",
"<https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/>",
"<https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/>",
]
# Load documents from the URLs
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]Aqui, o site WebBaseLoader é usado para buscar conteúdo de cada URL fornecido. As listas aninhadas de documentos resultantes são então combinadas em uma única lista plana chamada docs_list, o que nos dá uma lista de documentos.
Para tornar o processo de recuperação mais eficiente, dividimos os documentos em partes menores usando o RecursiveCharacterTextSplitter. Isso ajuda o sistema a lidar e pesquisar o texto com mais eficiência.
Podemos configurar o divisor de texto especificando o tamanho do bloco e a sobreposição. Por exemplo, no código abaixo, estamos configurando um divisor de texto com um tamanho de bloco de 250 caracteres e sem sobreposição.
# Initialize a text splitter with specified chunk size and overlap
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# Split the documents into chunks
doc_splits = text_splitter.split_documents(docs_list)Em seguida, precisamos converter os blocos de texto em embeddingsque são armazenados em um vetor de armazenamento, permitindo uma recuperação rápida e eficiente com base na similaridade.
Para isso, usamos o site OpenAIEmbeddings para gerar embeddings para cada trecho de texto, que são armazenados em um site SKLearnVectorStore. O armazenamento de vetores é configurado para retornar os quatro documentos mais relevantes para qualquer consulta, configurando-o com as_retriever(k=4).
from langchain_community.vectorstores import SKLearnVectorStore
from langchain_openai import OpenAIEmbeddings
# Create embeddings for documents and store them in a vector store
vectorstore = SKLearnVectorStore.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(openai_api_key="api_key"),
)
retriever = vectorstore.as_retriever(k=4)Nesta etapa, configuraremos o LLM e criaremos um modelo de prompt para gerar respostas com base nos documentos recuperados.
Primeiro, precisamos definir um modelo de prompt que instrua o LLM sobre como formatar suas respostas. Este modelo informa ao modelo que você deve usar os documentos fornecidos para responder às perguntas de forma concisa, usando no máximo três frases. Se o modelo não conseguir encontrar uma resposta, ele deve simplesmente declarar que não sabe.
from langchain_ollama import ChatOllama
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Define the prompt template for the LLM
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following documents to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Documents: {documents}
Answer:
""",
input_variables=["question", "documents"],
)Em seguida, estamos nos conectando ao modelo Llama 3.1 usando ChatOllama da Langchain, que configuramos com uma configuração de temperatura de 0 para obter respostas consistentes.
# Initialize the LLM with Llama 3.1 model
llm = ChatOllama(
model="llama3.1",
temperature=0,
)Por fim, criamos uma cadeia que combina o modelo de prompt com o LLM e usa o site StrOutputParser para garantir que a saída seja uma string simples e limpa, adequada para exibição.
# Create a chain combining the prompt template and LLM
rag_chain = prompt | llm | StrOutputParser()Nesta etapa, combinaremos o retriever e a cadeia RAG para criar um aplicativo RAG completo. Para isso, criaremos uma classe chamada RAGApplication que tratará tanto da recuperação de documentos quanto da geração de respostas.
A classe RAGApplication tem o método run que recebe a pergunta do usuário, usa o recuperador para encontrar documentos relevantes e, em seguida, extrai o texto desses documentos. Em seguida, ele passa a pergunta e o texto do documento para a cadeia RAG para gerar uma resposta concisa.
# Define the RAG application class
class RAGApplication:
def __init__(self, retriever, rag_chain):
self.retriever = retriever
self.rag_chain = rag_chain
def run(self, question):
# Retrieve relevant documents
documents = self.retriever.invoke(question)
# Extract content from retrieved documents
doc_texts = "\\n".join([doc.page_content for doc in documents])
# Get the answer from the language model
answer = self.rag_chain.invoke({"question": question, "documents": doc_texts})
return answerPor fim, estamos prontos para testar nosso aplicativo RAG com algumas perguntas de amostra para garantir que ele funcione corretamente. Você pode ajustar o modelo de prompt ou as configurações de recuperação para melhorar o desempenho ou adaptar o aplicativo a necessidades específicas.
# Initialize the RAG application
rag_application = RAGApplication(retriever, rag_chain)
# Example usage
question = "What is prompt engineering"
answer = rag_application.run(question)
print("Question:", question)
print("Answer:", answer)Question: What is prompt engineering
Answer: Prompt engineering refers to methods for communicating with Large Language Models (LLMs) to steer their behavior towards desired outcomes without updating the model weights. It's an empirical science that requires experimentation and heuristics, aiming at alignment and model steerability. The goal is to optimize prompts to achieve specific results, often using techniques like iterative prompting or external tool use.Os recursos avançados do Llama 3.1 e o suporte ao RAG o tornam ideal para vários aplicativos de impacto.
Para desenvolvimento de chatbotsSe você quiser desenvolver um chatbot, a integração do Llama 3.1 com o RAG permite que os chatbots forneçam respostas mais precisas e contextualizadas, acessando bancos de dados externos ou bases de conhecimento. Isso garante que as informações fornecidas aos usuários sejam atuais e relevantes, o que é particularmente importante em áreas como o atendimento ao cliente, em que respostas oportunas e precisas podem aumentar muito a satisfação e a eficiência do usuário. O suporte do Llama 3.1 a vários idiomas também o torna eficaz para atender a uma base de usuários diversificada.
Nos sistemas de resposta a perguntas, a Llama 3.1 aborda as limitações dos modelos de linguagem tradicionais que dependem apenas de seus conjuntos de dados internos. Ao usar o RAG para acessar informações atualizadas de fontes externas, o Llama 3.1 aumenta a precisão e a confiabilidade de suas respostas. Isso é especialmente útil em áreas como saúde e educaçãoonde informações precisas e atuais são essenciais.
Por exemplo, um assistente de IA médica com tecnologia Llama 3.1 pode fornecer aos profissionais da área de saúde as mais recentes pesquisas ou diretrizes de tratamento, consultando bancos de dados médicos em tempo real, ajudando assim a melhorar a tomada de decisões clínicas.
O Llama 3.1 também é altamente eficaz para tarefas que exigem muito conhecimento, como a geração de relatórios detalhados ou a realização de pesquisas completas. Ao usar o RAG para extrair informações de uma ampla variedade de fontes, os modelos do Llama 3.1 podem fornecer análises mais abrangentes e diferenciadas, tornando-os ferramentas valiosas para profissionais de áreas como pesquisa, finanças e planejamento estratégico.
A implementação de um aplicativo RAG com o Llama 3.1 usando o Ollama e o Langchain oferece uma boa solução para a criação de modelos de linguagem avançados e com reconhecimento de contexto.
Seguindo as etapas descritas - configuração do ambiente, carregamento e processamento de documentos, criação de embeddings e integração do recuperador com o LLM - você pode criar um sistema RAG funcional capaz de recuperar informações relevantes e fornecer respostas precisas.
A integração da Llama 3.1 com o RAG é particularmente valiosa para aplicativos do mundo real, como chatbots, sistemas de resposta a perguntas e ferramentas de pesquisa, em que o acesso a informações externas atualizadas é importante.
Aprenda a criar aplicativos de IA!
Programa
Curso
Curso
blog
Natassha Selvaraj
10 min
Tutorial
Moez Ali
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita



