Curso
Introdução ao R
4 h
3M
Neste tutorial, visualizaremos as distribuições de dados traçando histogramas usando a linguagem de programação R. Abordaremos o que é um histograma, como ler dados no R, como criar um histograma e como personalizar o gráfico.
Usaremos a linguagem de programação R básica, sem pacotes adicionais. Essa abordagem é especialmente útil quando pacotes adicionais não podem ser usados ou quando você está procurando análises exploratórias rápidas. Em outros casos, você pode considerar o uso de ggplot2, conforme abordado em nosso tutorial How to Make a ggplot2 Histogram in R.
Para executar facilmente todos os exemplos de código deste tutorial, você pode criar gratuitamente uma pasta de trabalho do DataLab que tenha o R pré-instalado e contenha todos os exemplos de código. Para que você possa praticar mais como criar um histograma no R, confira este exercício prático do DataCamp.
Um histograma é um gráfico muito popular usado para mostrar distribuições de frequência em variáveis contínuas (numéricas). Os histogramas nos permitem ver o número de observações nos dados dentro dos intervalos que a variável abrange.
Os histogramas são semelhantes aos gráficos de barras. Uma diferença importante entre os dois é que os gráficos de barras têm um valor associado a uma categoria específica ou variável discreta, enquanto um histograma visualiza frequências para variáveis contínuas.
Usaremos esse conjunto de dados de moradia que inclui detalhes sobre diferentes listagens de casas, inclusive o tamanho da casa, o número de cômodos, o preço e as informações de localização. Podemos ler os dados usando a função read.csv(), seja diretamente do URL ou baixando o arquivo csv em um diretório e lendo-o em nosso armazenamento local. Também podemos especificar que queremos armazenar apenas as colunas que nos interessam neste tutorial: preço e condição.
home_data <- read.csv("https://raw.githubusercontent.com/rashida048/Datasets/master/home_data.csv")[ ,c('price', 'condition')]Vamos examinar as primeiras linhas de dados usando a função head()
head(home_data, 5)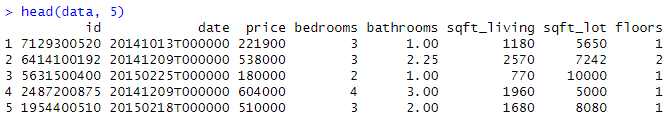
Em seguida, criaremos um histograma usando a função hist() para analisar a distribuição de preços em nosso conjunto de dados.
hist(home_data$price)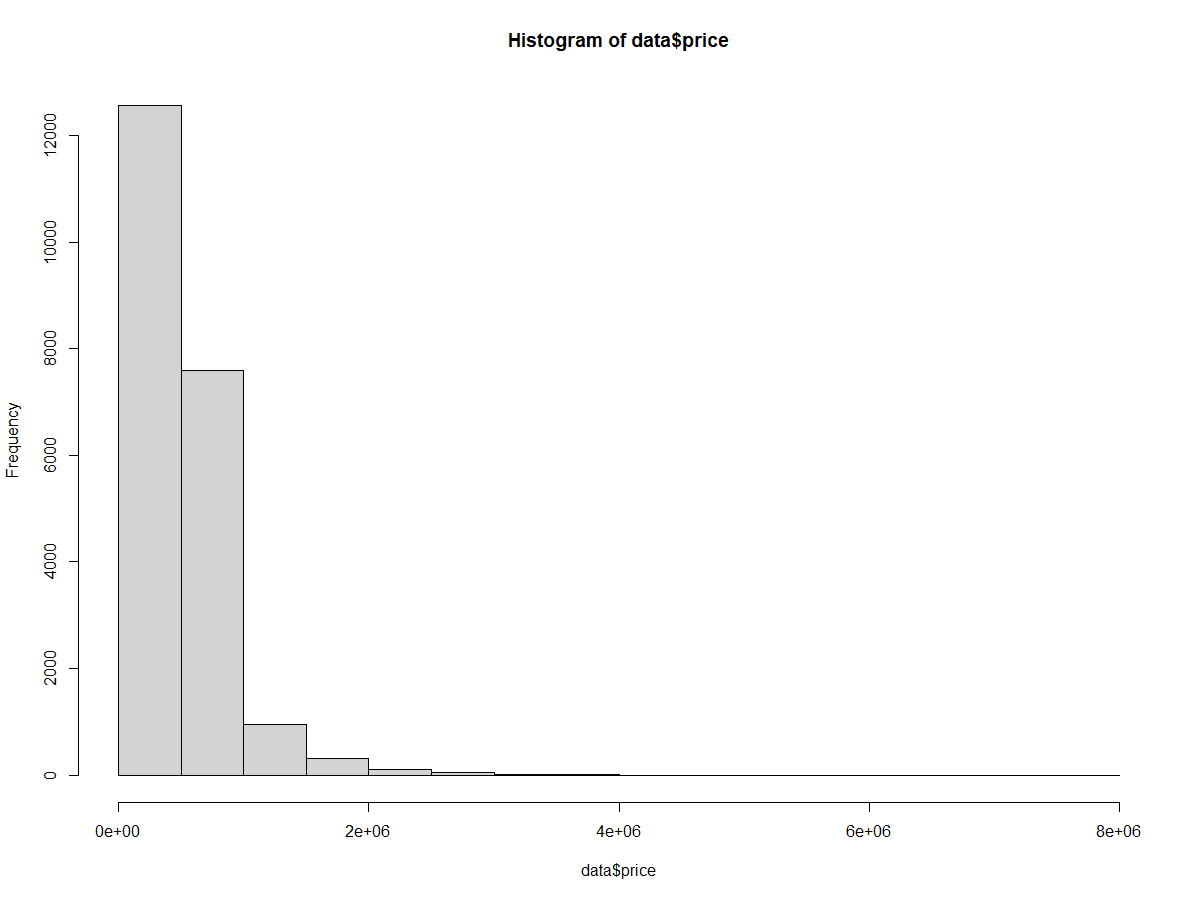
Histograma básico de preços de imóveis residenciais. Imagem do autor.
Podemos adicionar estatísticas descritivas ao histograma usando a função abline(). Isso adiciona uma linha vertical ao gráfico.
v como a posição no eixo x para a linha vertical. Aqui, obtemos o preço médio dos imóveis usando mean().col define a cor da linha, nesse caso, para vermelho.lwd define a largura da linha. Um valor de 3 aumenta a espessura da linha para facilitar a visualização.hist(home_data$price)
abline(v = mean(home_data$price), col='red', lwd = 3)Para adicionar uma linha de densidade de probabilidade ao histograma, primeiro alteramos o eixo y para que seja dimensionado de acordo com a densidade. Na chamada para hist(), definimos o argumento probability como TRUE.
A linha de densidade de probabilidade é criada com uma combinação de density(), que calcula a posição da curva de densidade de probabilidade, e lines(), que adiciona a linha ao gráfico existente.
hist(home_data$price, probability = TRUE)
abline(v = mean(home_data$price), col='red', lwd = 3)
lines(density(home_data$price), col = 'green', lwd = 3)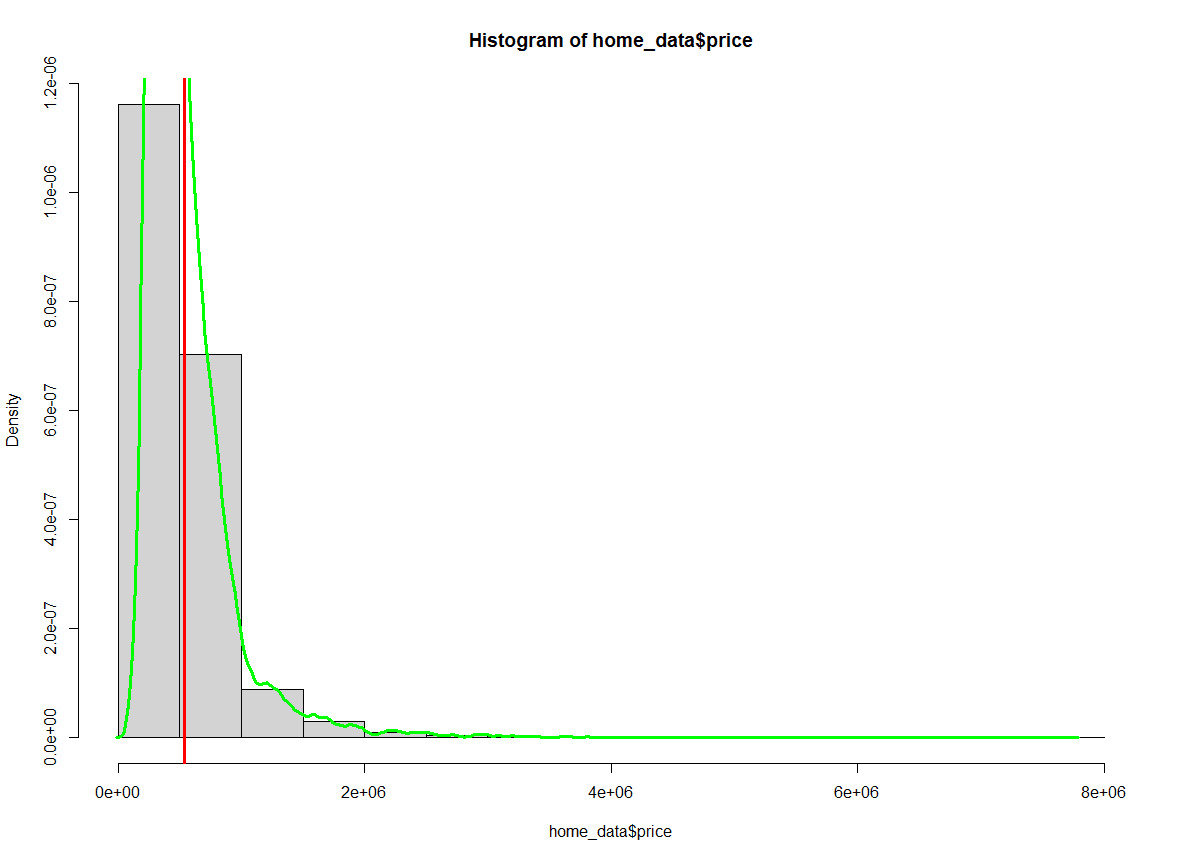
Histograma de preços de imóveis residenciais com a média destacada. Imagem do autor.
Observe que os números no eixo y foram alterados.
Podemos alterar as cores dentro dos compartimentos no histograma usando o parâmetro col da função hist(). Vamos alterar o preenchimento para azul. Você também pode alterar a cor do contorno das barras usando o parâmetro border. Alteraremos a cor dos contornos para branco.
hist(home_data$price, col = 'blue', border = "white")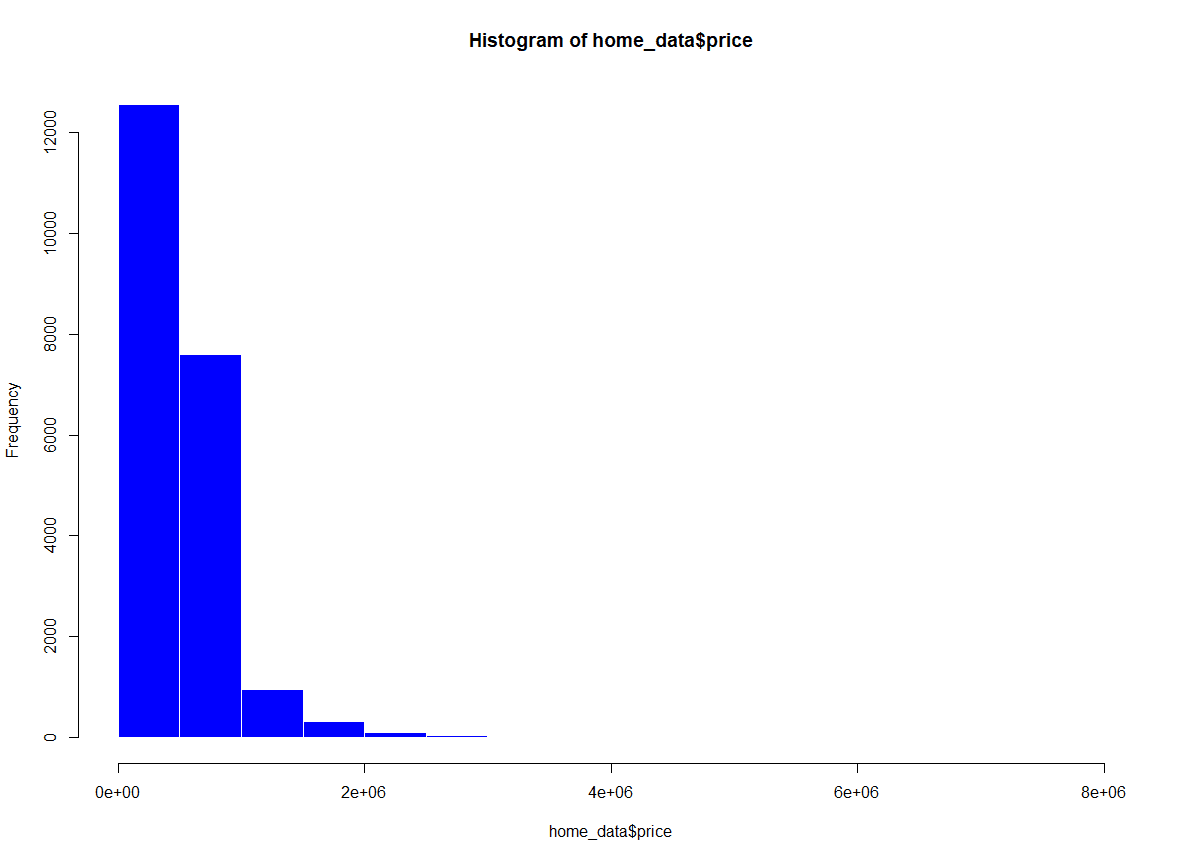 Histograma de preços de imóveis residenciais com adição de cor. Imagem do autor.
Histograma de preços de imóveis residenciais com adição de cor. Imagem do autor.
Podemos alterar os rótulos do gráfico para torná-lo mais legível e apresentável. Isso é útil se você compartilhar o gráfico com outras pessoas.
xlab define o rótulo do eixo xylab define o rótulo do eixo ymain define o título do gráficohist(home_data$price, xlab = 'Price (USD)', ylab = 'Number of Listings', main = 'Distribution of House Prices')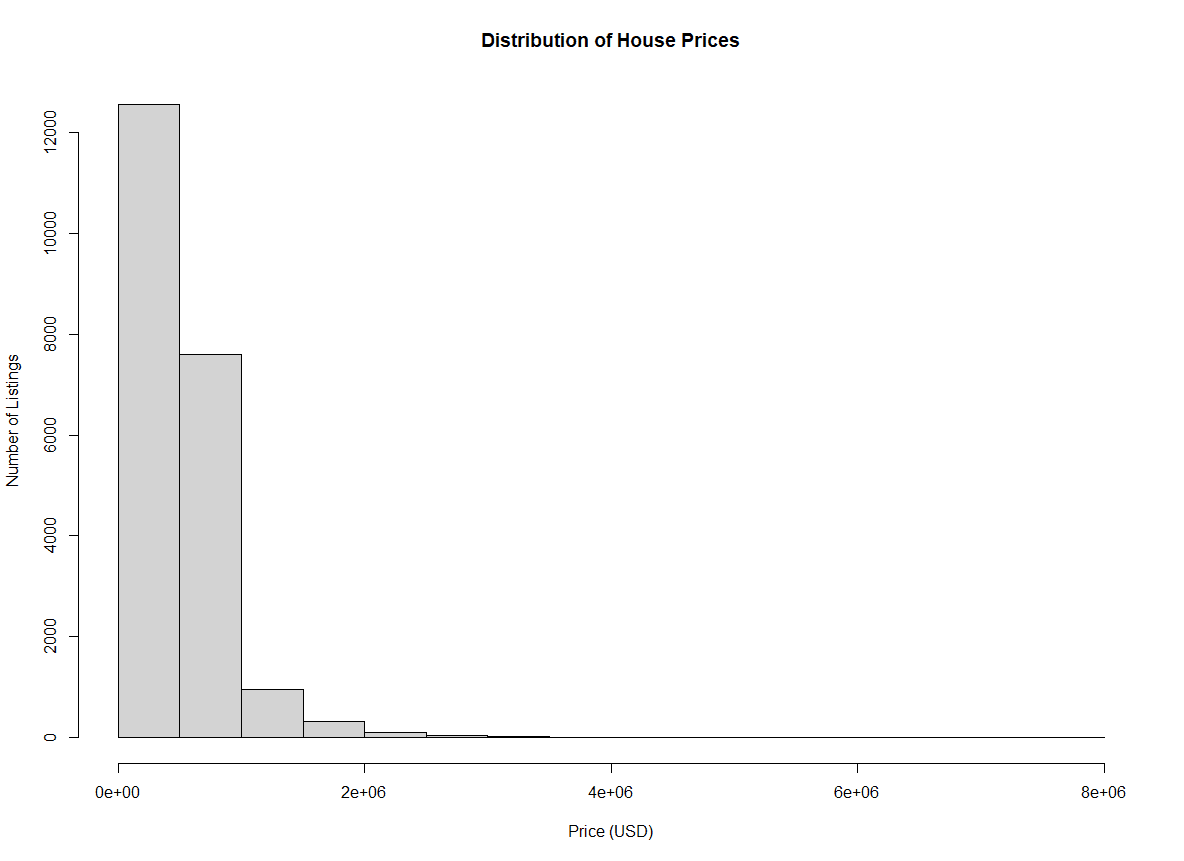 Histograma de preços de imóveis residenciais com rótulos de eixo. Imagem do autor.
Histograma de preços de imóveis residenciais com rótulos de eixo. Imagem do autor.
Com os argumentos padrão, é difícil ver a distribuição completa dos preços das moradias em toda a faixa de preços. Podemos ver que eles estão centralizados nos primeiros compartimentos, mas não são muito descritivos.
Você pode adicionar mais compartimentos usando o parâmetro breaks. Com esse argumento, podemos passar um vetor de pontos de interrupção específicos a serem usados, uma função para computar os pontos de interrupção, um número de interrupções que gostaríamos ou uma função para computar o número de células.
Para este exemplo, passaremos o número de compartimentos que você deseja. Esse número é específico do contexto, com base no que você está tentando mostrar no gráfico.
hist(home_data$price, breaks = 100)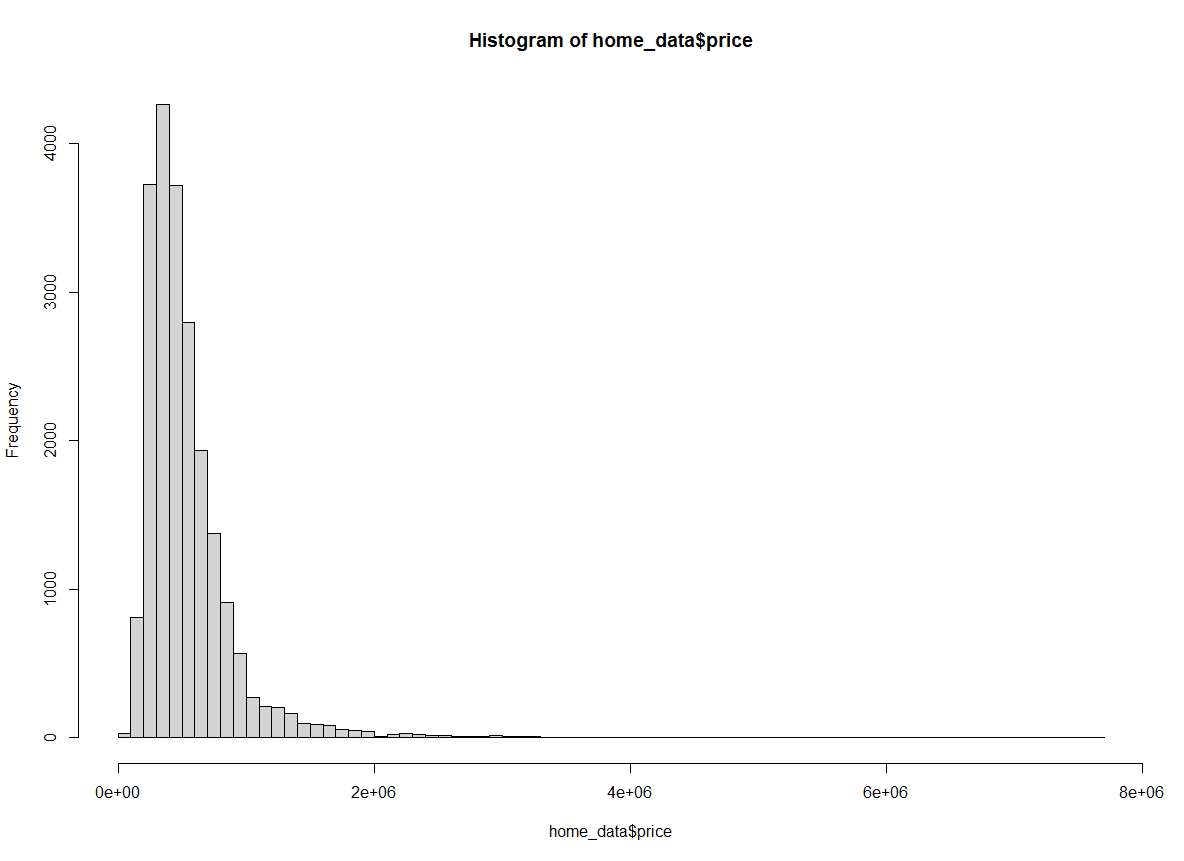 Histograma de preços de imóveis residenciais com a largura do compartimento alterada. Imagem do autor.
Histograma de preços de imóveis residenciais com a largura do compartimento alterada. Imagem do autor.
Com o breaks definido como 100, temos muito mais visibilidade da distribuição nos primeiros intervalos.
Também podemos especificar o número de quebras usando os nomes dos cálculos comuns para calcular as quebras ideais em um histograma. Por padrão, o site hist() usa o método “Sturges”. Aqui, especificamos o método explicitamente.
hist(home_data$price, breaks = "Sturges")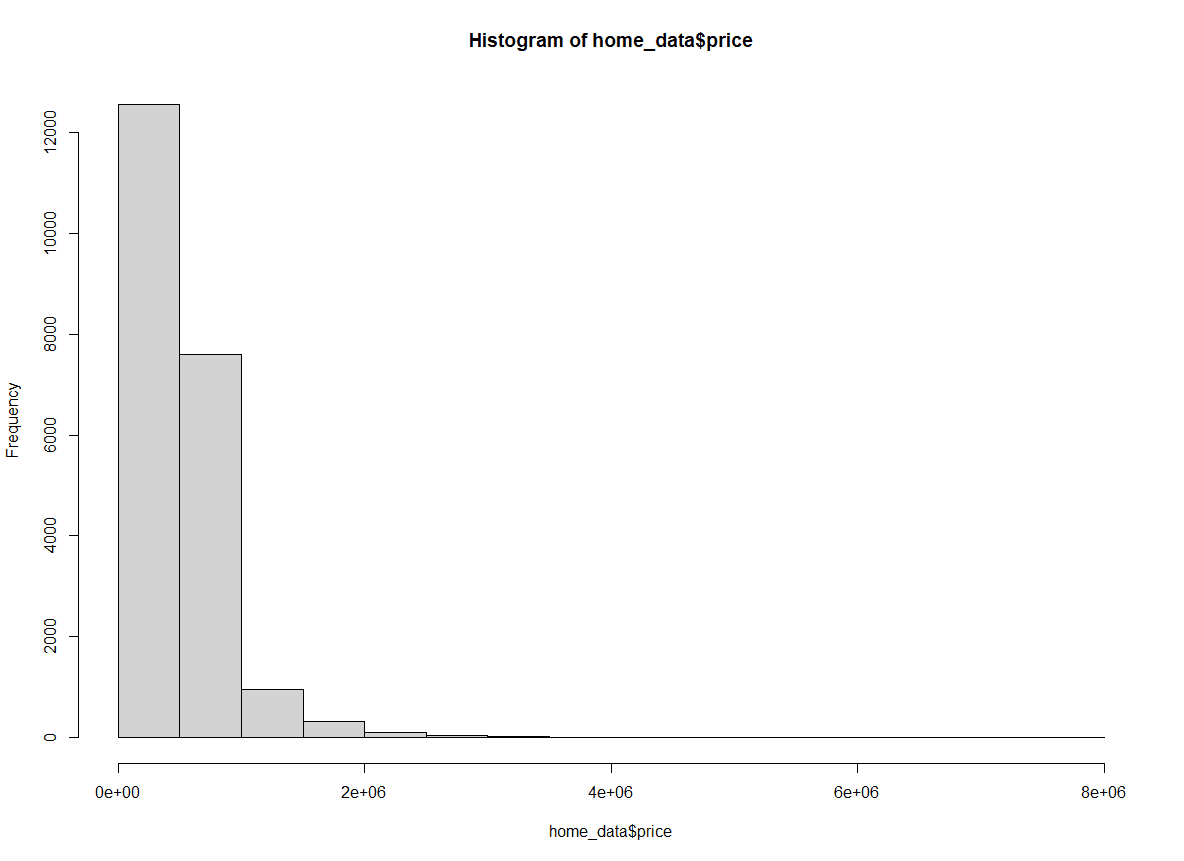 de Histograma de preços de imóveis residenciais usando o método de Sturges. Imagem do autor.
de Histograma de preços de imóveis residenciais usando o método de Sturges. Imagem do autor.
Você também pode passar “Scott” como um argumento para o atributo breaks para usar o método Scott.
hist(home_data$price, breaks = "Scott")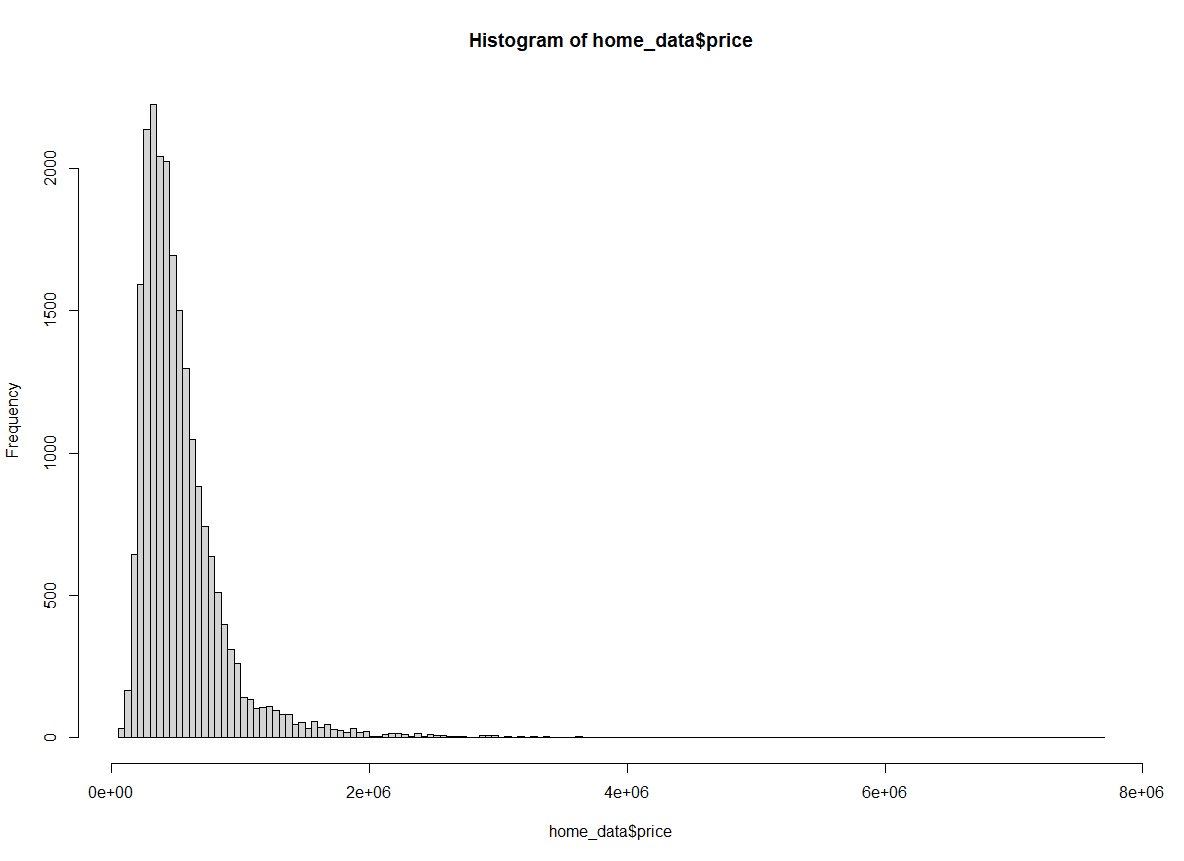 de
de
Histograma de preços de imóveis residenciais usando o método Scott. Imagem do autor.
Por fim, também podemos usar o método Freedman-Diaconis (FD).
hist(home_data$price, breaks = "Freedman-Diaconis")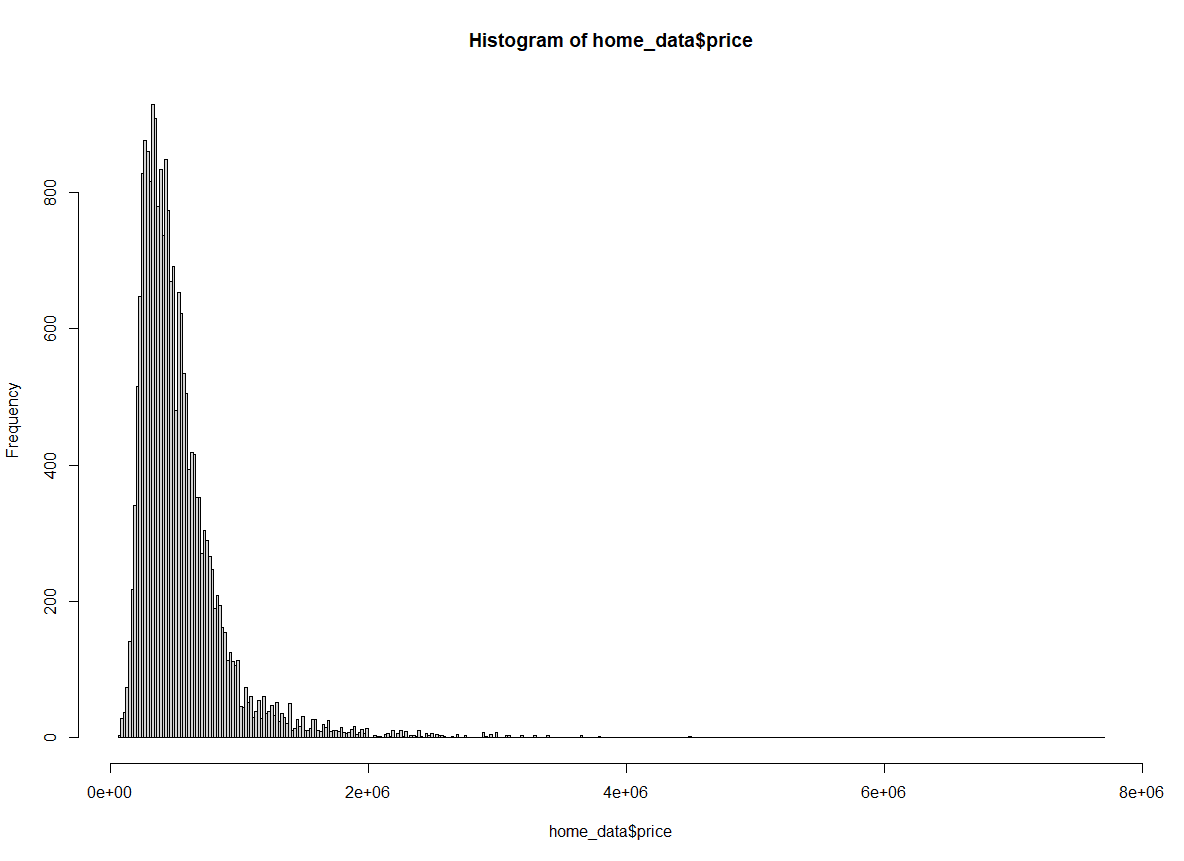 de Histograma de preços de imóveis residenciais usando o método Freedman-Diaconis. Imagem do autor.
de Histograma de preços de imóveis residenciais usando o método Freedman-Diaconis. Imagem do autor.
Podemos definir os limites do eixo x do nosso gráfico usando o argumento xlim para ampliar os dados nos quais estamos interessados. Por exemplo, às vezes é útil focar na parte central da distribuição, em vez de na cauda longa que vemos atualmente quando visualizamos o gráfico inteiro.
Também é possível alterar os limites do eixo y (usando o argumento ylim ), mas isso é menos útil para histogramas, pois os valores calculados automaticamente são quase sempre ideais.
Vamos nos concentrar nos preços entre US$ 0 e US$ 2 milhões.
hist(home_data$price, breaks = 100, xlim = c(0, 2000000))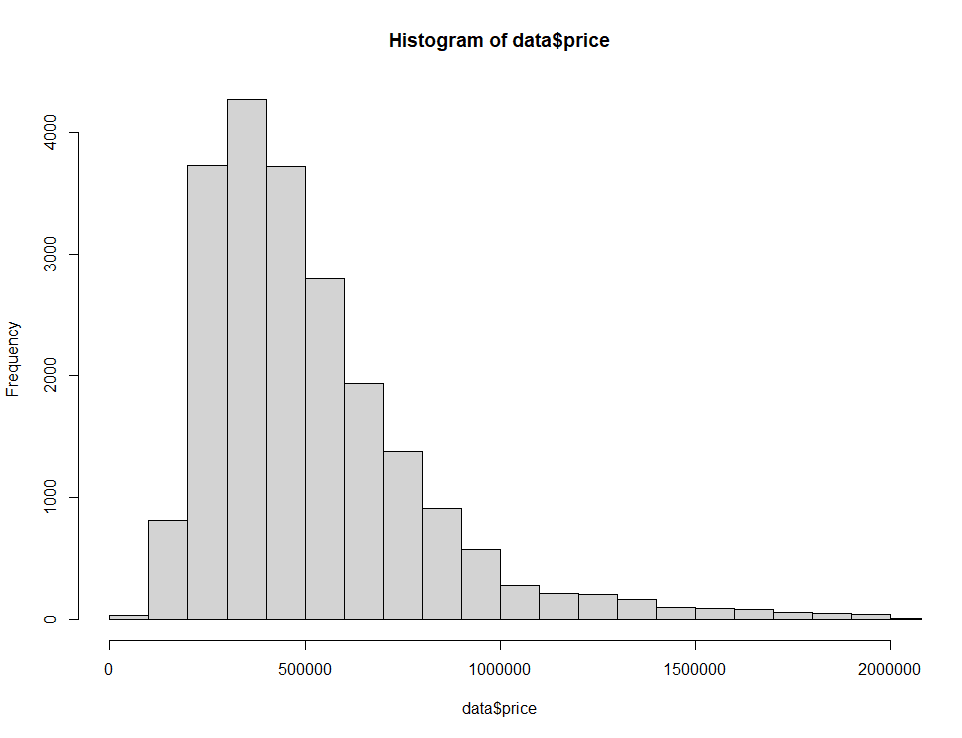 Histograma de preços de imóveis residenciais com os limites dos eixos alterados. Imagem do autor.
Histograma de preços de imóveis residenciais com os limites dos eixos alterados. Imagem do autor.
À medida que você se sentir mais à vontade com o R, poderá explorar pacotes mais avançados que facilitam a criação de visualizações mais interessantes e úteis. Uma biblioteca muito popular e fácil de usar para plotagem no R é chamada ggplot2. Abaixo, criamos uma visão interessante das distribuições de preços com base no número de quartos da casa.
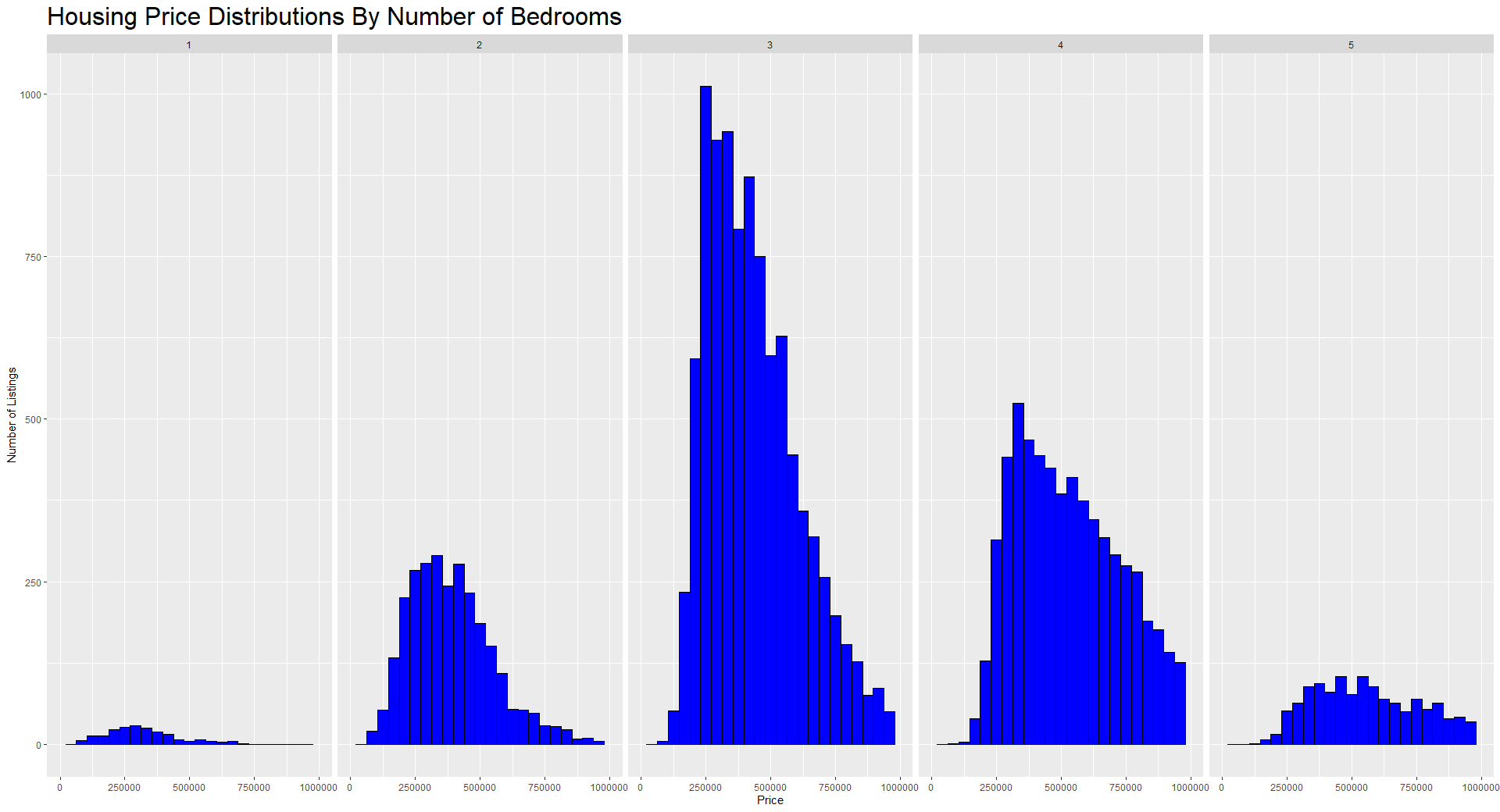 Histograma de preços de imóveis residenciais usando ggplot2. Imagem do autor.
Histograma de preços de imóveis residenciais usando ggplot2. Imagem do autor.
ggplot2 é a melhor maneira de visualizar dados no R, e você pode aprender a usá-lo para criar histogramas no tutorial How to make a histogram in R in ggplot2. Confira nosso curso Introdução ao ggplot2 e nosso curso Intermediário de ggplot2 para saber como fazer visualizações mais interessantes no R.
Neste tutorial, aprendemos que os histogramas são ótimas visualizações para examinar as distribuições de variáveis contínuas. Aprendemos a criar um histograma no R, a plotar estatísticas resumidas sobre o histograma, a personalizar os recursos do gráfico, como os títulos dos eixos, a cor, a forma como classificamos o eixo x e a definir limites nos eixos. Por fim, demonstramos alguns dos recursos da biblioteca ggplot2.
Para mais leituras e recursos do DataCamp, confira nossos cursos interativos:
Aprenda R com o DataCamp
Curso
Curso
Curso
Tutorial
Kevin Babitz
Tutorial
Aditya Sharma
Tutorial
Ryan Sheehy
Tutorial
Karlijn Willems
Tutorial
Eladio Montero Porras
Tutorial
DataCamp Team
