Kurs
Einführung in R
4 Std.
3M
In diesem Lernprogramm werden wir Verteilungen von Daten visualisieren, indem wir mit der Programmiersprache R Histogramme erstellen. Wir werden uns damit beschäftigen, was ein Histogramm ist, wie man Daten in R liest, wie man ein Histogramm erstellt und wie man die Darstellung anpasst.
Wir werden die Basisprogrammiersprache R ohne zusätzliche Pakete verwenden. Dieser Ansatz ist besonders nützlich, wenn zusätzliche Pakete nicht verwendet werden können oder wenn du schnelle explorative Analysen suchst. In anderen Fällen kannst du ggplot2 verwenden, wie in unserem Tutorial How to Make a ggplot2 Histogram in R beschrieben.
Um den gesamten Beispielcode in diesem Tutorial einfach selbst auszuführen, kannst du eine kostenlose DataLab-Arbeitsmappe erstellen, auf der R vorinstalliert ist und die alle Codebeispiele enthält. Wenn du mehr darüber erfahren möchtest, wie du ein Histogramm in R erstellst, schau dir diese praktische DataCamp-Übung an.
Ein Histogramm ist ein sehr beliebtes Diagramm, das verwendet wird, um Häufigkeitsverteilungen über kontinuierliche (numerische) Variablen darzustellen. Mit Histogrammen kannst du die Anzahl der Beobachtungen in den Daten innerhalb der Bereiche sehen, die die Variable umfasst.
Histogramme sehen ähnlich aus wie Balkendiagramme. Ein wichtiger Unterschied zwischen den beiden ist, dass Balkendiagramme einen Wert haben, der mit einer bestimmten Kategorie oder diskreten Variable verbunden ist, während ein Histogramm Häufigkeiten für kontinuierliche Variablen visualisiert.
Wir werden diesen Wohnungsdatensatz verwenden, der Details zu verschiedenen Wohnungsangeboten enthält, einschließlich der Größe des Hauses, der Anzahl der Zimmer, des Preises und der Standortinformationen. Wir können die Daten mit der Funktion read.csv() lesen, entweder direkt von der URL oder indem wir die csv-Datei in ein Verzeichnis herunterladen und sie von unserem lokalen Speicher lesen. Wir können auch angeben, dass wir nur die Spalten speichern wollen, die uns in diesem Tutorial interessieren: Preis und Bedingung.
home_data <- read.csv("https://raw.githubusercontent.com/rashida048/Datasets/master/home_data.csv")[ ,c('price', 'condition')]Schauen wir uns die ersten Zeilen der Daten mit der Funktion head() an
head(home_data, 5)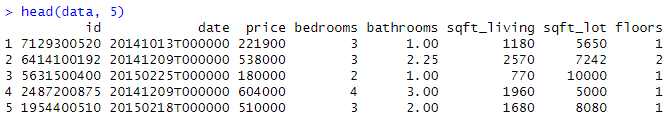
Als Nächstes werden wir mit der Funktion hist() ein Histogramm erstellen, um die Verteilung der Preise in unserem Datensatz zu betrachten.
hist(home_data$price)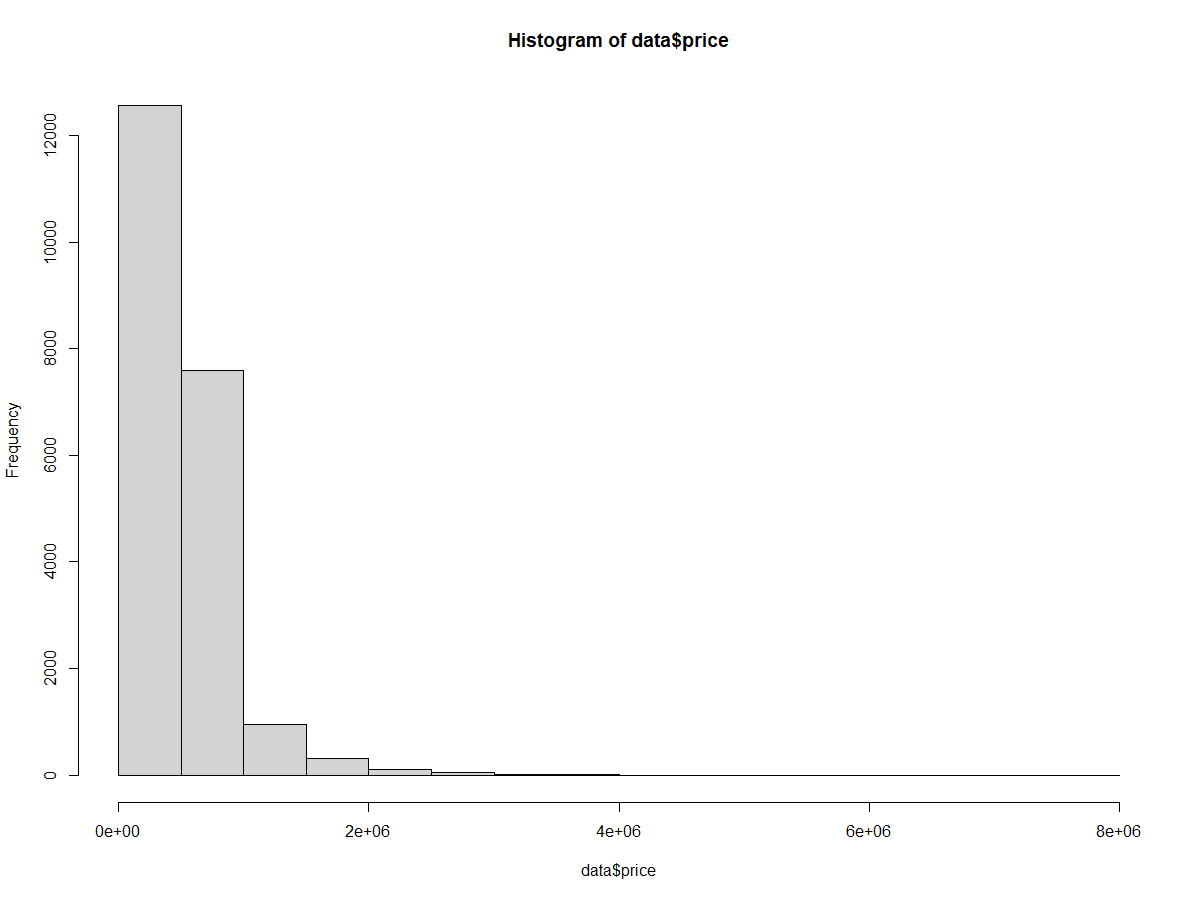
Grundlegendes Histogramm der Hauspreise. Bild vom Autor.
Mit der Funktion abline() können wir dem Histogramm eine deskriptive Statistik hinzufügen. Dies fügt dem Diagramm eine vertikale Linie hinzu.
v auf die Position auf der x-Achse für die vertikale Linie. Hier erhalten wir den durchschnittlichen Hauspreis mit mean().col legt die Linienfarbe fest, in diesem Fall rot.lwd legt die Linienbreite fest. Ein Wert von 3 erhöht die Dicke der Linie, damit sie besser zu sehen ist.hist(home_data$price)
abline(v = mean(home_data$price), col='red', lwd = 3)Um dem Histogramm eine Wahrscheinlichkeitsdichte-Linie hinzuzufügen, ändern wir zunächst die y-Achse so, dass sie auf die Dichte skaliert wird. Bei dem Aufruf von hist() setzen wir das Argument probability auf TRUE.
Die Wahrscheinlichkeitsdichtelinie wird mit einer Kombination aus density(), das die Position der Wahrscheinlichkeitsdichtekurve berechnet, und lines(), das die Linie zum bestehenden Diagramm hinzufügt, erstellt.
hist(home_data$price, probability = TRUE)
abline(v = mean(home_data$price), col='red', lwd = 3)
lines(density(home_data$price), col = 'green', lwd = 3)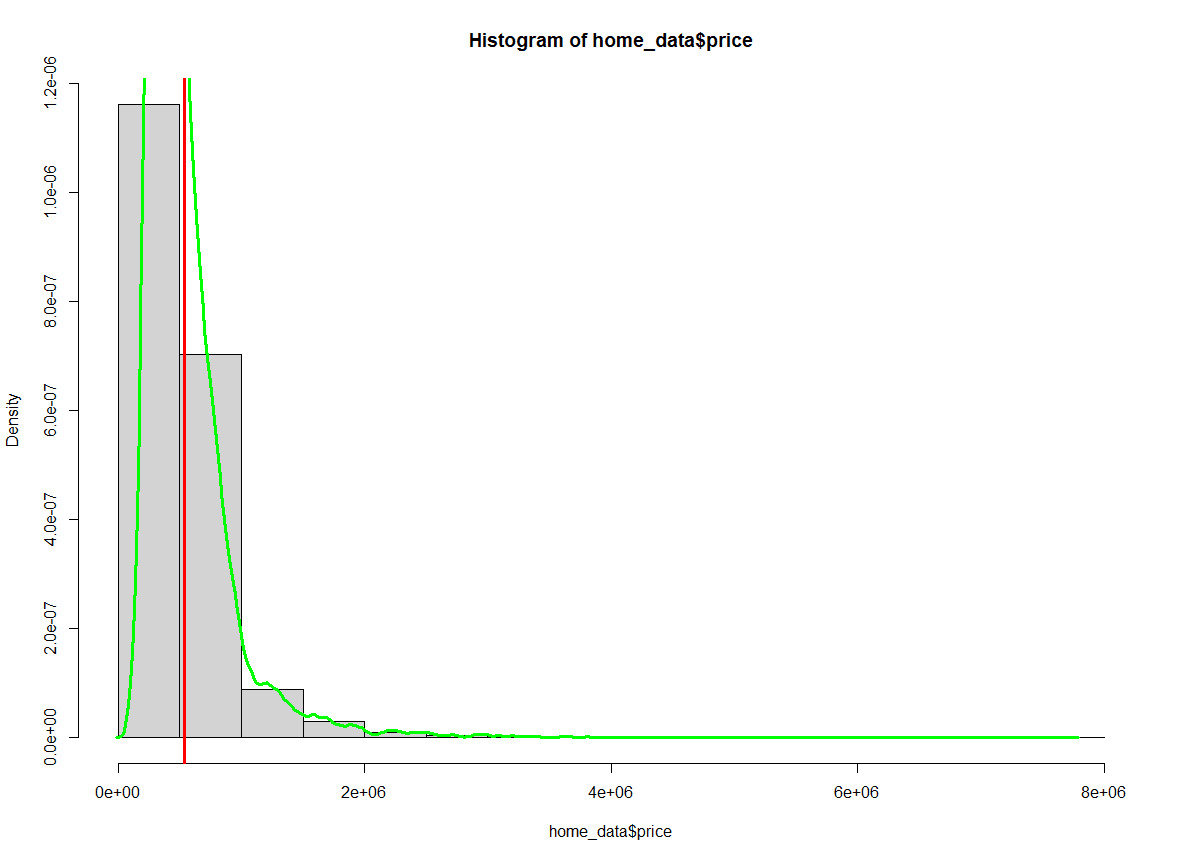
Histogramm der Eigenheimpreise, bei dem der Durchschnitt hervorgehoben ist. Bild vom Autor.
Beachte, dass sich die Zahlen auf der y-Achse verändert haben.
Wir können die Farben innerhalb der Bins im Histogramm ändern, indem wir den Parameter col der Funktion hist() verwenden. Wir ändern die Füllung in Blau. Wir können auch die Farbe der Umrandung der Balken mit dem Parameter border ändern. Wir ändern die Farbe der Umrisse in Weiß.
hist(home_data$price, col = 'blue', border = "white")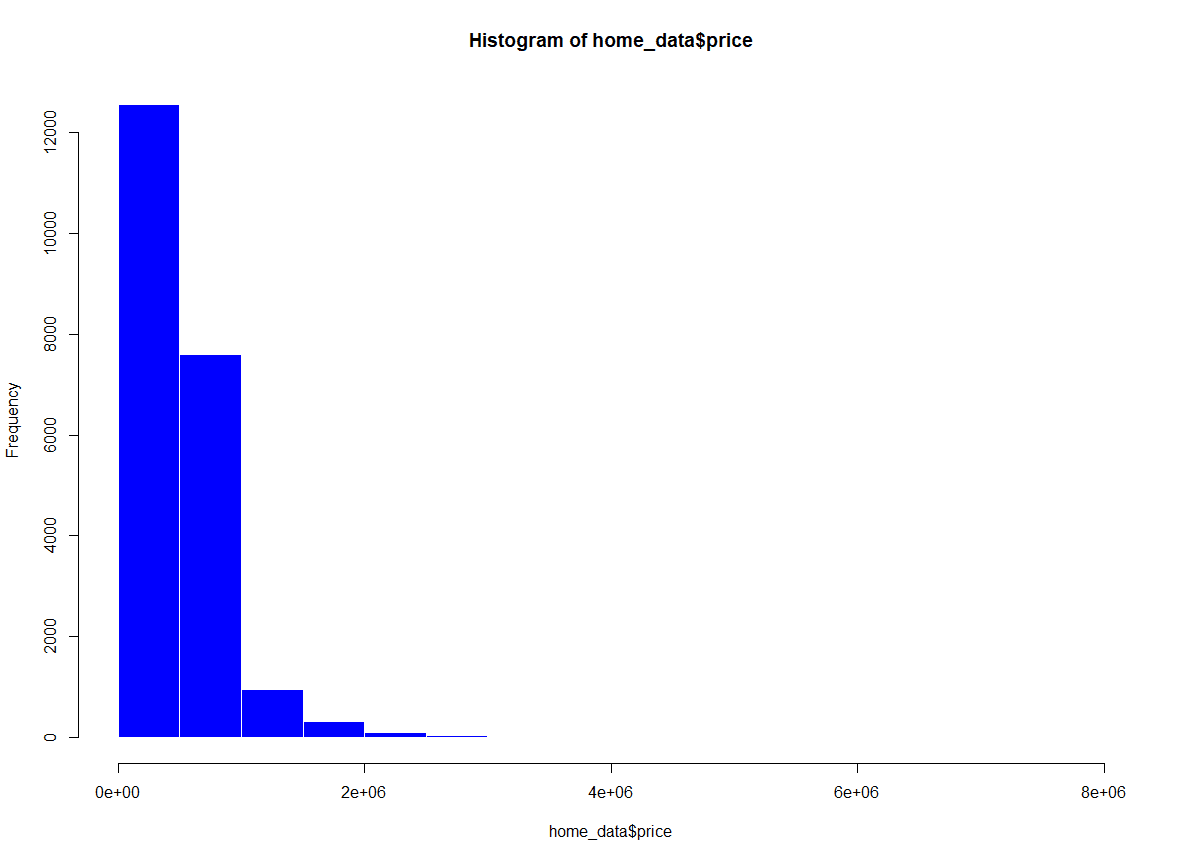 Histogramm der Hauspreise mit hinzugefügter Farbe. Bild vom Autor.
Histogramm der Hauspreise mit hinzugefügter Farbe. Bild vom Autor.
Wir können die Beschriftungen auf dem Plot ändern, um ihn lesbarer und präsentabler zu machen. Das ist nützlich, wenn du das Grundstück mit anderen teilst.
xlab setzt die Beschriftung der x-Achseylab setzt die Beschriftung der y-Achsemain setzt den Titel der Handlunghist(home_data$price, xlab = 'Price (USD)', ylab = 'Number of Listings', main = 'Distribution of House Prices')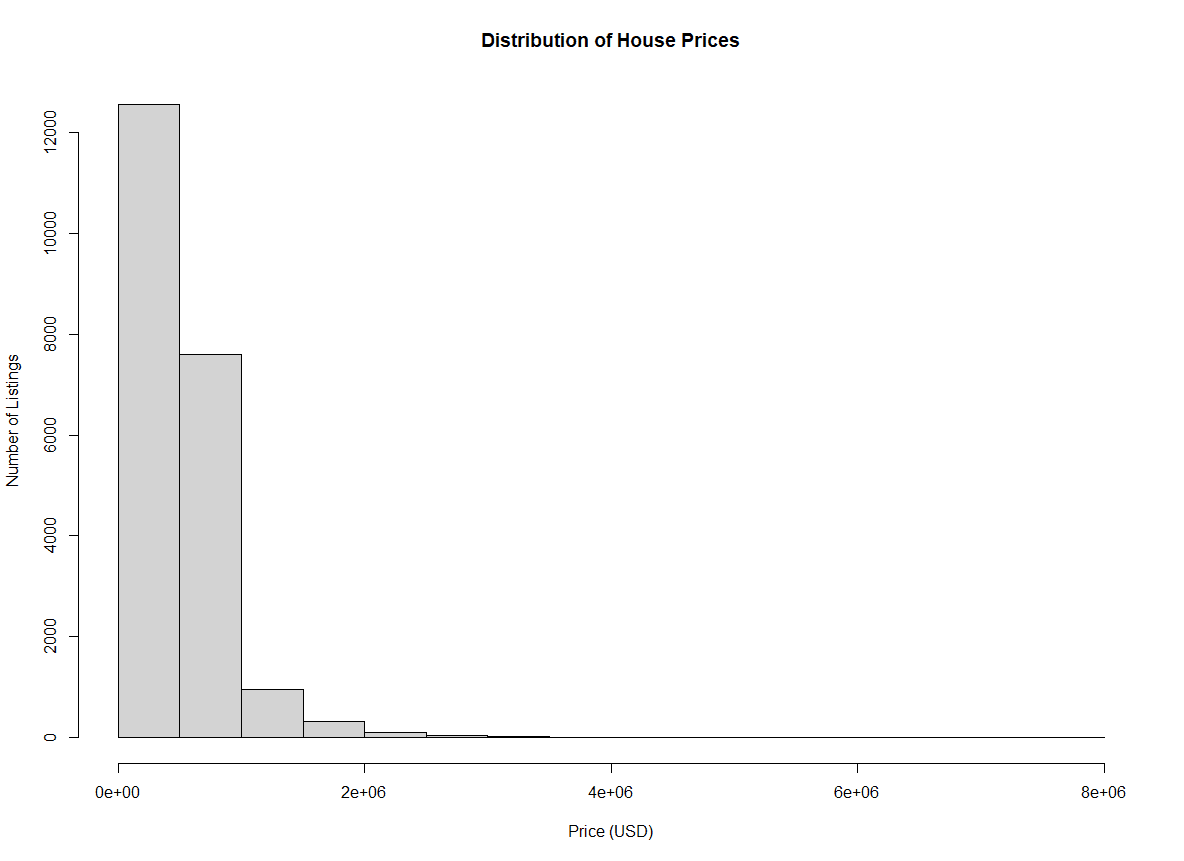 Histogramm der Hauspreise mit Achsenbeschriftungen. Bild vom Autor.
Histogramm der Hauspreise mit Achsenbeschriftungen. Bild vom Autor.
Mit den Standardargumenten ist es schwierig, die vollständige Verteilung der Wohnungspreise über die Preisspanne zu erkennen. Wir können sehen, dass sie in den ersten paar Bins zentralisiert sind, aber sie sind nicht sehr anschaulich.
Wir können mit dem Parameter breaks weitere Bins hinzufügen. Mit diesem Argument können wir einen Vektor mit bestimmten Haltepunkten, eine Funktion zur Berechnung der Haltepunkte, eine gewünschte Anzahl von Haltepunkten oder eine Funktion zur Berechnung der Anzahl von Zellen übergeben.
In diesem Beispiel geben wir die Anzahl der Bins an, die wir möchten. Diese Zahl ist kontextspezifisch und hängt davon ab, was du in deinem Diagramm zeigen willst.
hist(home_data$price, breaks = 100)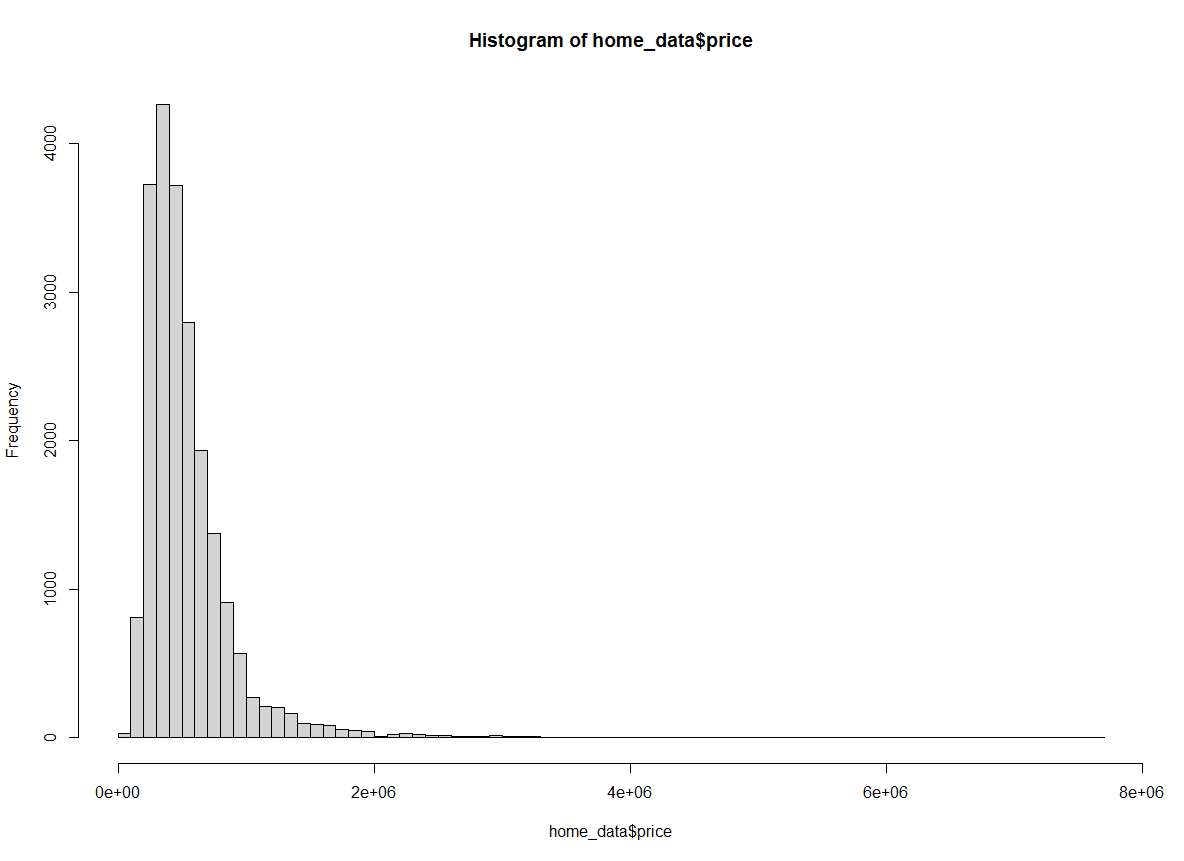 Histogramm der Hauspreise mit veränderter Bin-Breite. Bild vom Autor.
Histogramm der Hauspreise mit veränderter Bin-Breite. Bild vom Autor.
Wenn breaks auf 100 eingestellt ist, haben wir deutlich mehr Einblick in die Verteilung in den ersten paar Buckets.
Wir können auch die Anzahl der Brüche angeben, indem wir die Namen der gängigen Berechnungen zur Berechnung der optimalen Brüche in einem Histogramm verwenden. Standardmäßig verwendet hist() die Methode “Sturges”. Hier geben wir die Methode explizit an.
hist(home_data$price, breaks = "Sturges")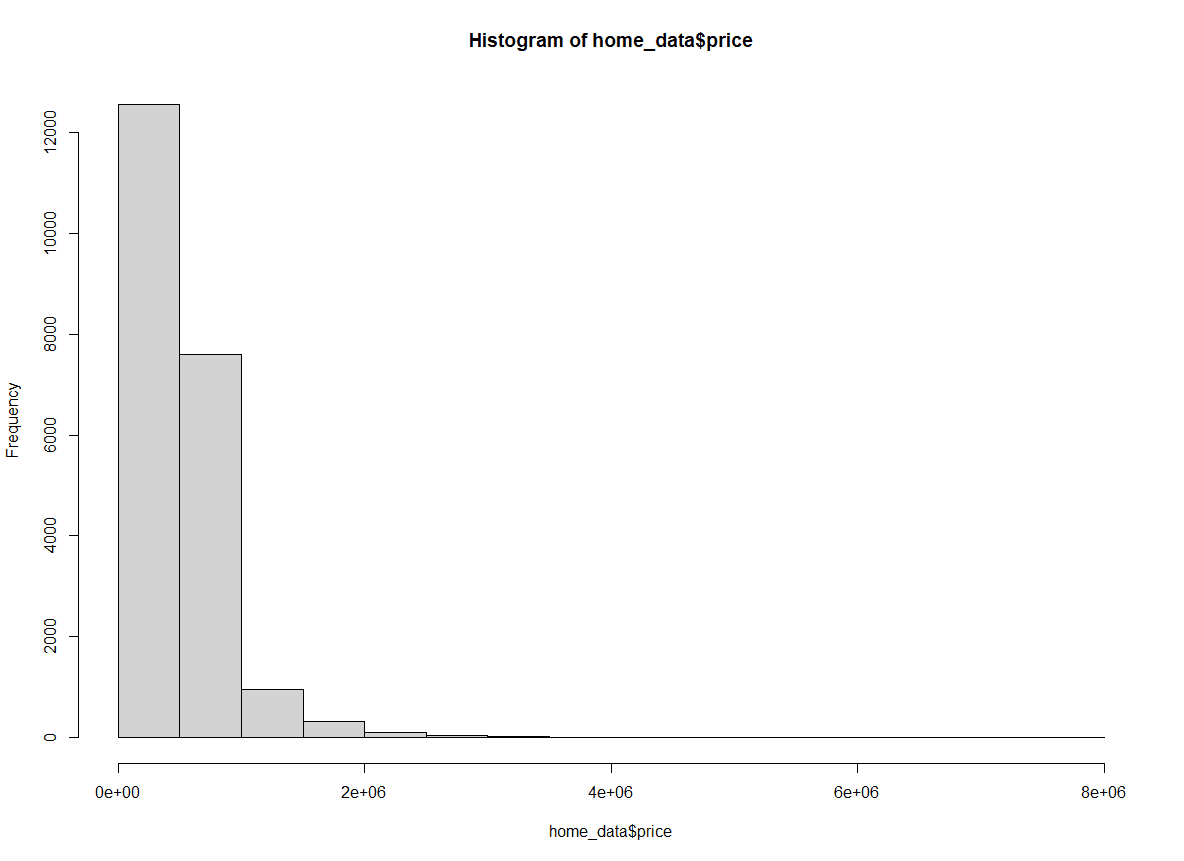 Histogramm der Hauspreise nach der Sturges-Methode. Bild vom Autor.
Histogramm der Hauspreise nach der Sturges-Methode. Bild vom Autor.
Wir können auch “Scott” als Argument für das Attribut breaks übergeben, um die Scott-Methode zu verwenden.
hist(home_data$price, breaks = "Scott")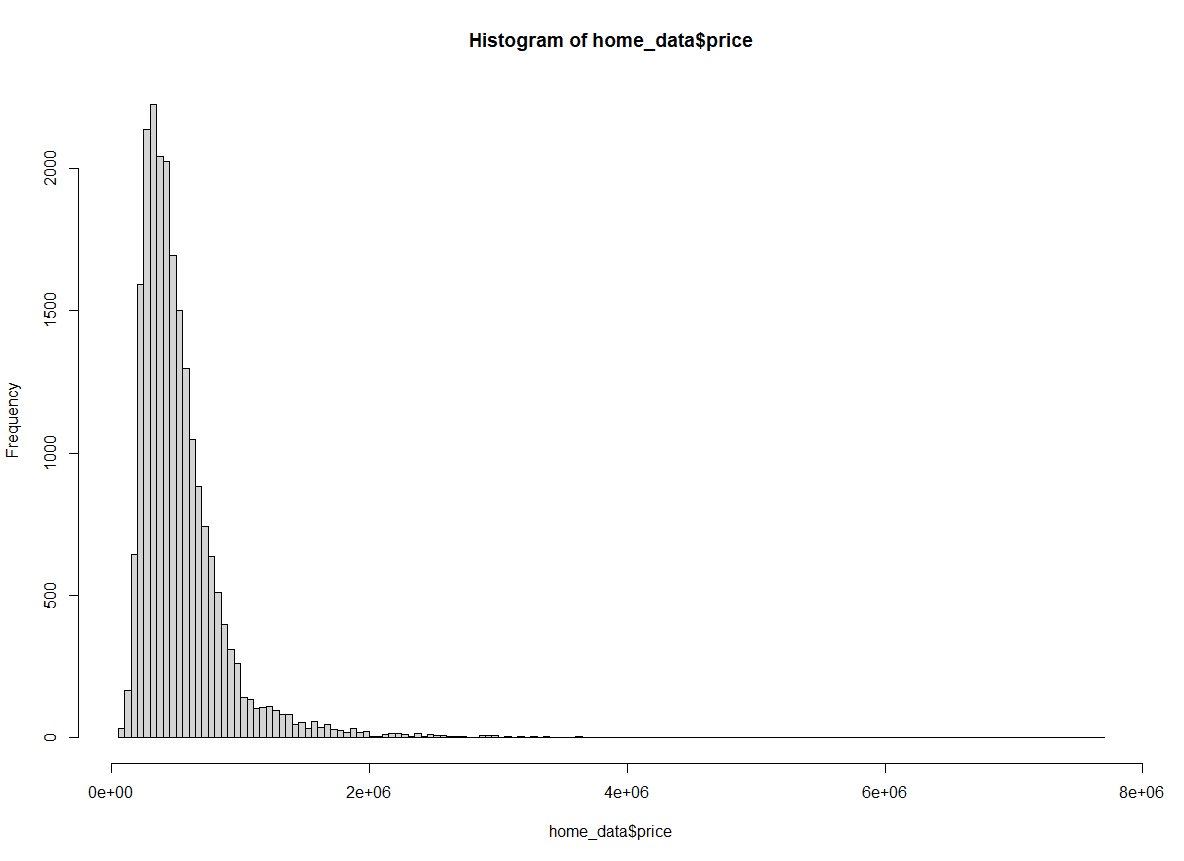
Histogramm der Hauspreise nach der Scott-Methode. Bild vom Autor.
Schließlich können wir auch die Freedman-Diaconis-Methode (FD) anwenden.
hist(home_data$price, breaks = "Freedman-Diaconis")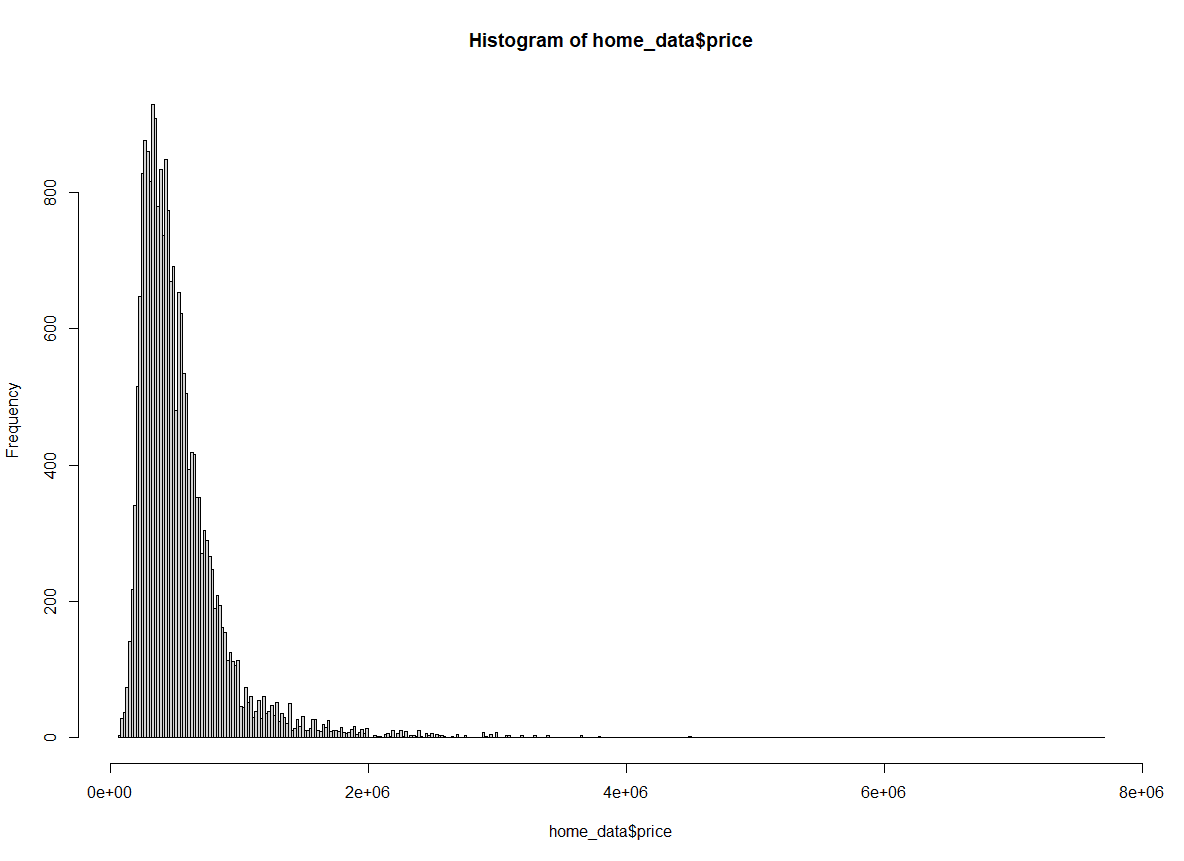 Histogramm der Hauspreise nach der Freedman-Diaconis-Methode. Bild vom Autor.
Histogramm der Hauspreise nach der Freedman-Diaconis-Methode. Bild vom Autor.
Mit dem Argument xlim können wir die Grenzen der x-Achse unseres Plots festlegen, um die Daten, die uns interessieren, zu vergrößern. Zum Beispiel ist es manchmal hilfreich, sich auf den zentralen Teil der Verteilung zu konzentrieren, anstatt auf den langen Schwanz, den wir sehen, wenn wir die gesamte Grafik betrachten.
Es ist auch möglich, die Grenzen der y-Achse zu ändern (mit dem Argument ylim ), aber das ist für Histogramme weniger nützlich, da die automatisch berechneten Werte fast immer ideal sind.
Wir zoomen auf Preise zwischen $0 und $2M.
hist(home_data$price, breaks = 100, xlim = c(0, 2000000))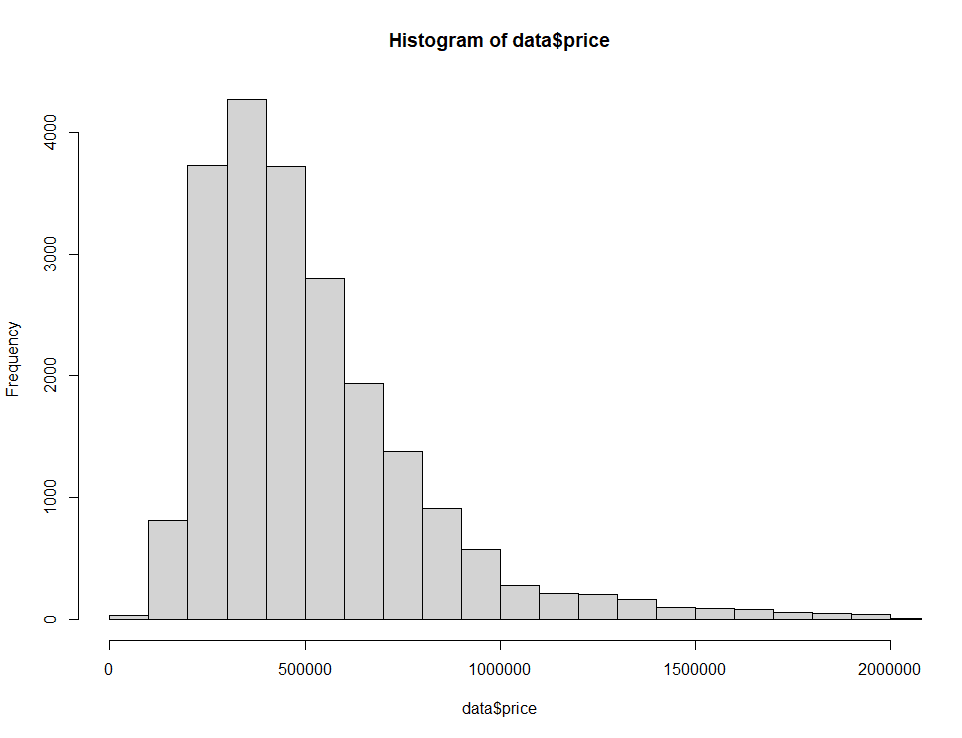 Histogramm der Eigenheimpreise mit veränderten Achsengrenzen. Bild vom Autor.
Histogramm der Eigenheimpreise mit veränderten Achsengrenzen. Bild vom Autor.
Wenn du dich mit R besser auskennst, kannst du leistungsfähigere Pakete ausprobieren, mit denen du noch interessantere und nützlichere Visualisierungen erstellen kannst. Eine sehr beliebte und einfach zu bedienende Bibliothek zum Plotten in R heißt ggplot2. Nachfolgend findest du eine interessante Übersicht über die Verteilung der Preise nach der Anzahl der Schlafzimmer im Haus.
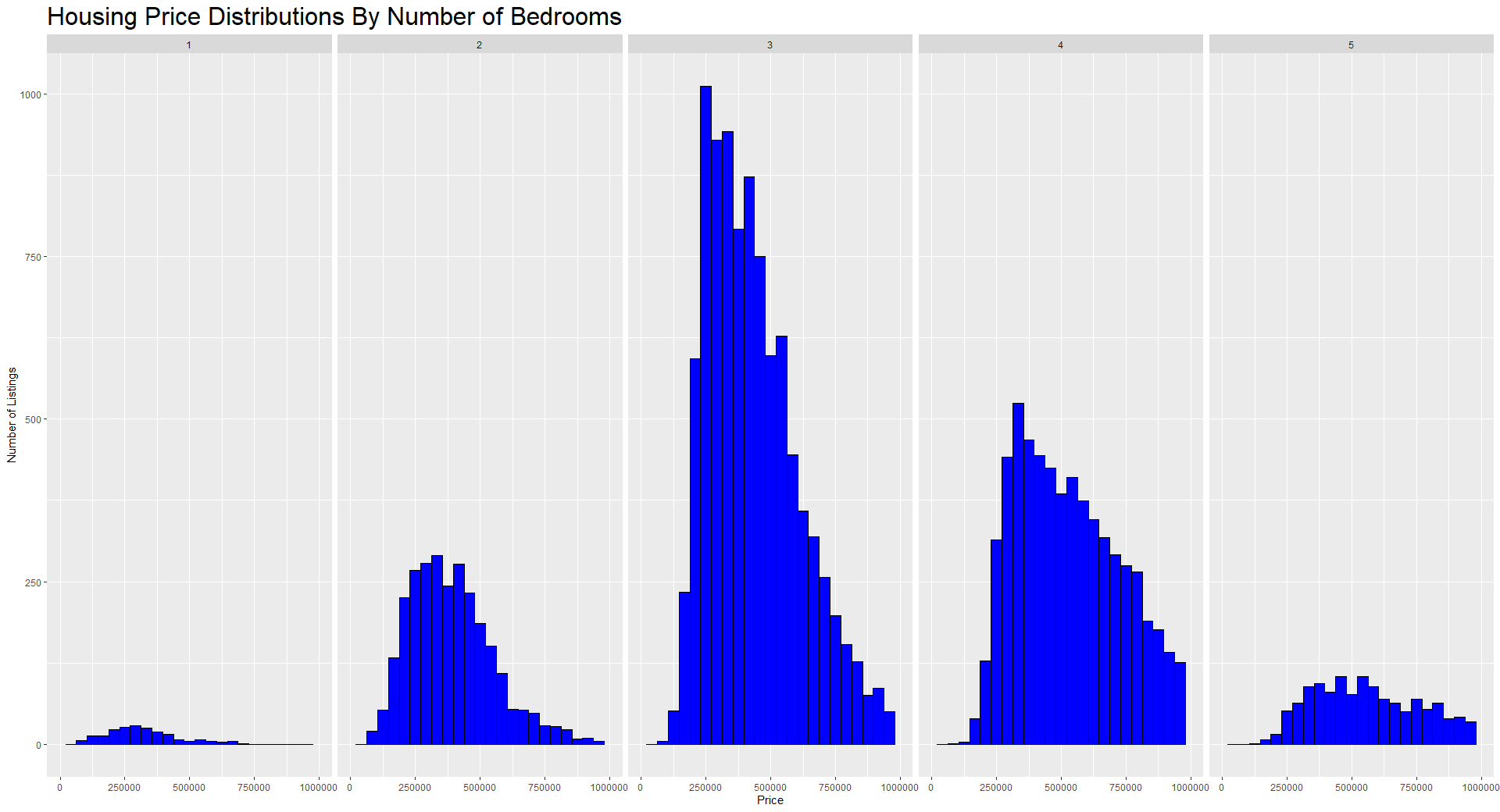 Histogramm der Hauspreise mit ggplot2. Bild vom Autor.
Histogramm der Hauspreise mit ggplot2. Bild vom Autor.
ggplot2 ist die beste Methode, um Daten in R zu visualisieren. Wie du damit Histogramme erstellst, erfährst du im Tutorial How to make a histogram in R in ggplot2. Schau dir unseren Kurs Einführung in ggplot2 und unseren Kurs Fortgeschrittene ggplot2 an, um zu lernen, wie du in R noch interessantere Visualisierungen erstellen kannst.
In diesem Tutorium haben wir gelernt, dass Histogramme großartige Visualisierungen sind, um Verteilungen von kontinuierlichen Variablen zu betrachten. Wir haben gelernt, wie man ein Histogramm in R erstellt, wie man zusammenfassende Statistiken über das Histogramm legt, wie man die Achsentitel und die Farbe anpasst, wie man die x-Achse binden kann und wie man die Achsen begrenzt. Zum Schluss haben wir einige der Möglichkeiten der ggplot2 Bibliothek demonstriert.
Weitere DataCamp-Lektüre und Ressourcen findest du in unseren interaktiven Kursen:
Lerne R mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Laiba Siddiqui
Tutorial
Sejal Jaiswal
Tutorial
Aditya Sharma
Tutorial
Allan Ouko

