Course
Introduction to R
4 hr
3M
In this tutorial, I'll walk you through creating and customizing histograms in the R programming language. We'll cover what a histogram is, how to set up your data, how to build a basic histogram, and how to adjust colors, labels, bins, and axis limits.
We will be using the base R programming language with no additional packages. This approach is especially useful when additional packages cannot be used or when you are looking for quick exploratory analyses. In other cases, you might consider using ggplot2, as covered in our How to Make a ggplot2 Histogram in R tutorial.
To easily run all the example code in this tutorial yourself, you can create a DataLab workbook for free that has R pre-installed and contains all code samples. For more practice on how to make a histogram in R, check out this hands-on DataCamp exercise.
Working with histograms in other tools? See our guides on Histograms in Matplotlib for Python and How to Create a Histogram in Excel.
Use hist(x) to create a basic histogram in base R with no extra packages
Customize appearance with col (fill color), border (outline), main (title), xlab, and ylab
Control binning with the breaks argument: pass a number, a vector of breakpoints, or a method name ("Sturges", "Scott", "Freedman-Diaconis")
Overlay descriptive statistics using abline() for the mean and lines(density()) for a density curve
For grouped or publication-quality histograms, switch to ggplot2
A histogram is a graph that shows frequency distributions across continuous (numeric) variables. Histograms allow us to see the count of observations in data within ranges that the variable spans.
Histograms look similar to bar charts. A key difference between the two is that bar charts have a value associated with a specific category or discrete variable, while a histogram visualizes frequencies for continuous variables.
We will be using this housing dataset which includes details about different house listings, including the size of the house, the number of rooms, the price, and location information. We can read the data using the read.csv() function, either directly from the URL or by downloading the csv file into a directory and reading it from our local storage. We can also specify that we only want to store the columns we are interested in for this tutorial: price and condition.
home_data <- read.csv("https://raw.githubusercontent.com/rashida048/Datasets/master/home_data.csv")[ ,c('price', 'condition')]Let’s look at the first few rows of data using the head() function.
head(home_data, 5)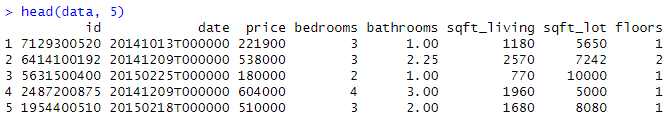
Next, we will create a histogram using the hist() function to look at the distribution of prices in our dataset.
hist(home_data$price)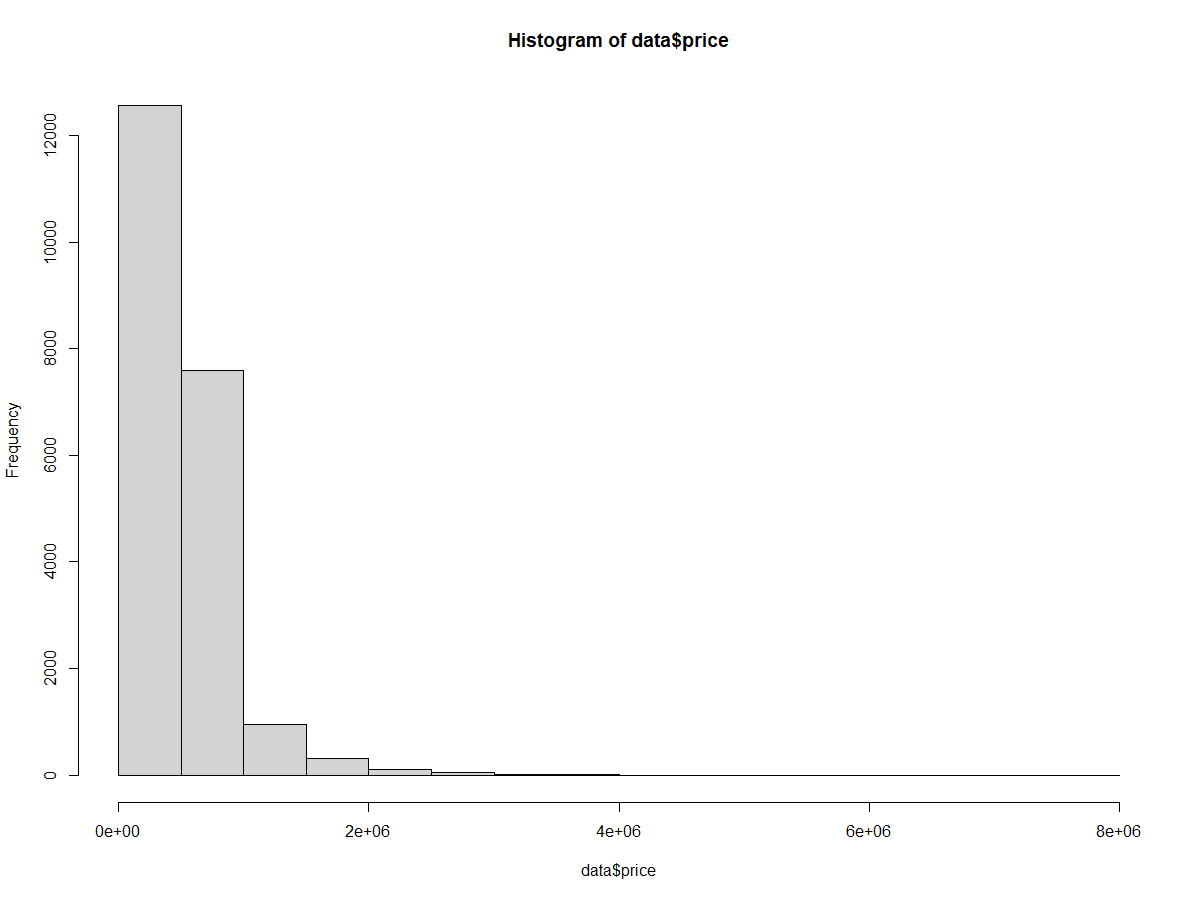
Basic histogram of home prices. Image by Author.
We can add descriptive statistics to the histogram using the abline() function. This adds a vertical line to the plot.
Set the v argument to the position on the x-axis for the vertical line. Here, we get the mean house price using mean().
The col argument sets the line color, in this case to red.
The lwd argument sets the line width. A value of 3 increases the thickness of the line to make it easier to see.
hist(home_data$price)
abline(v = mean(home_data$price), col='red', lwd = 3)To add a probability density line to the histogram, we first change the y-axis to be scaled to density. In the call to hist() , we set the probability argument to TRUE.
The probability density line is made with a combination of density(), which calculates the position of the probability density curve, and lines(), which adds the line to the existing plot.
hist(home_data$price, probability = TRUE)
abline(v = mean(home_data$price), col='red', lwd = 3)
lines(density(home_data$price), col = 'green', lwd = 3)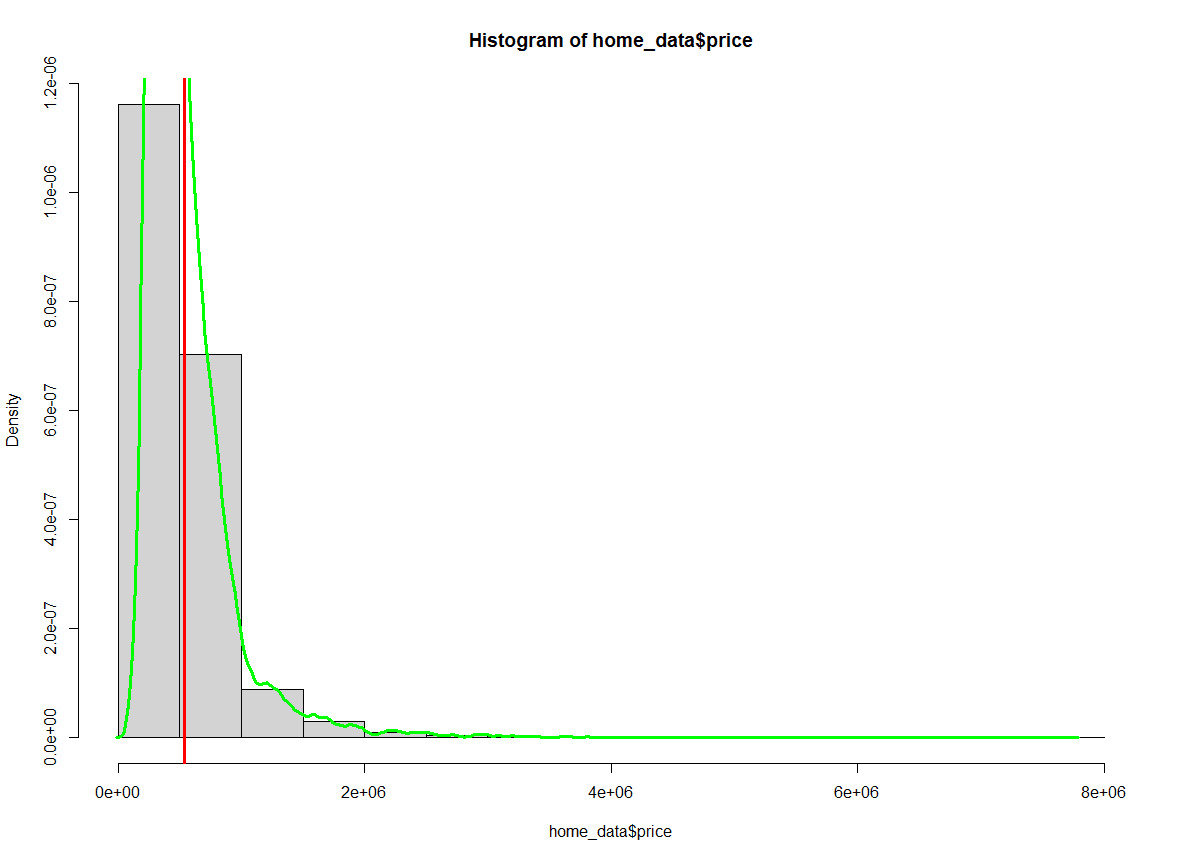
Histogram of home prices with the average highlighted. Image by Author.
Notice that the numbers on the y-axis have changed.
The col parameter of hist() sets the fill color of the bars, and border sets the outline color. Here I'll set the fill to blue and the borders to white.
hist(home_data$price, col = 'blue', border = "white")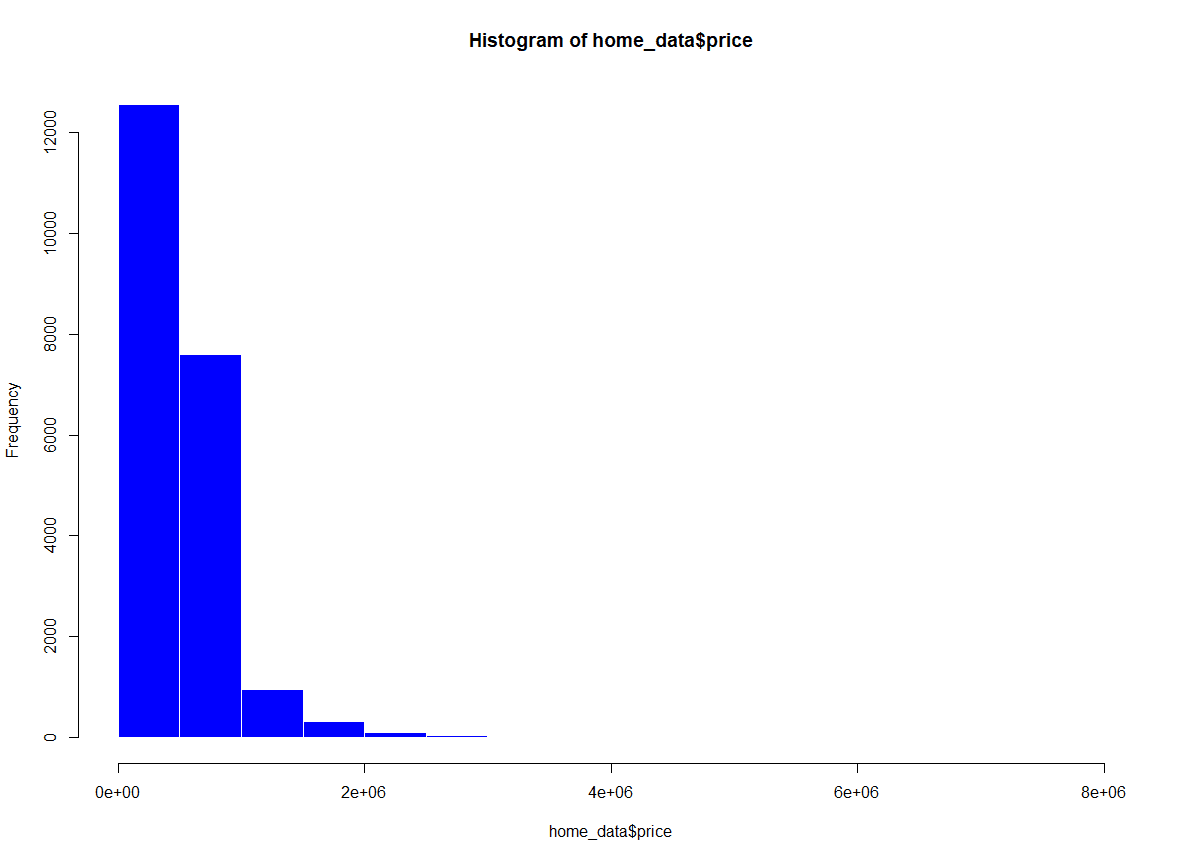 Histogram of home prices with color added. Image by Author.
Histogram of home prices with color added. Image by Author.
We can change the labels on the plot to make it more readable and presentable. This is useful if you share the plot with others.
xlab sets the x-axis label
ylab sets the y-axis label
main sets the plot title
hist(home_data$price, xlab = 'Price (USD)', ylab = 'Number of Listings', main = 'Distribution of House Prices')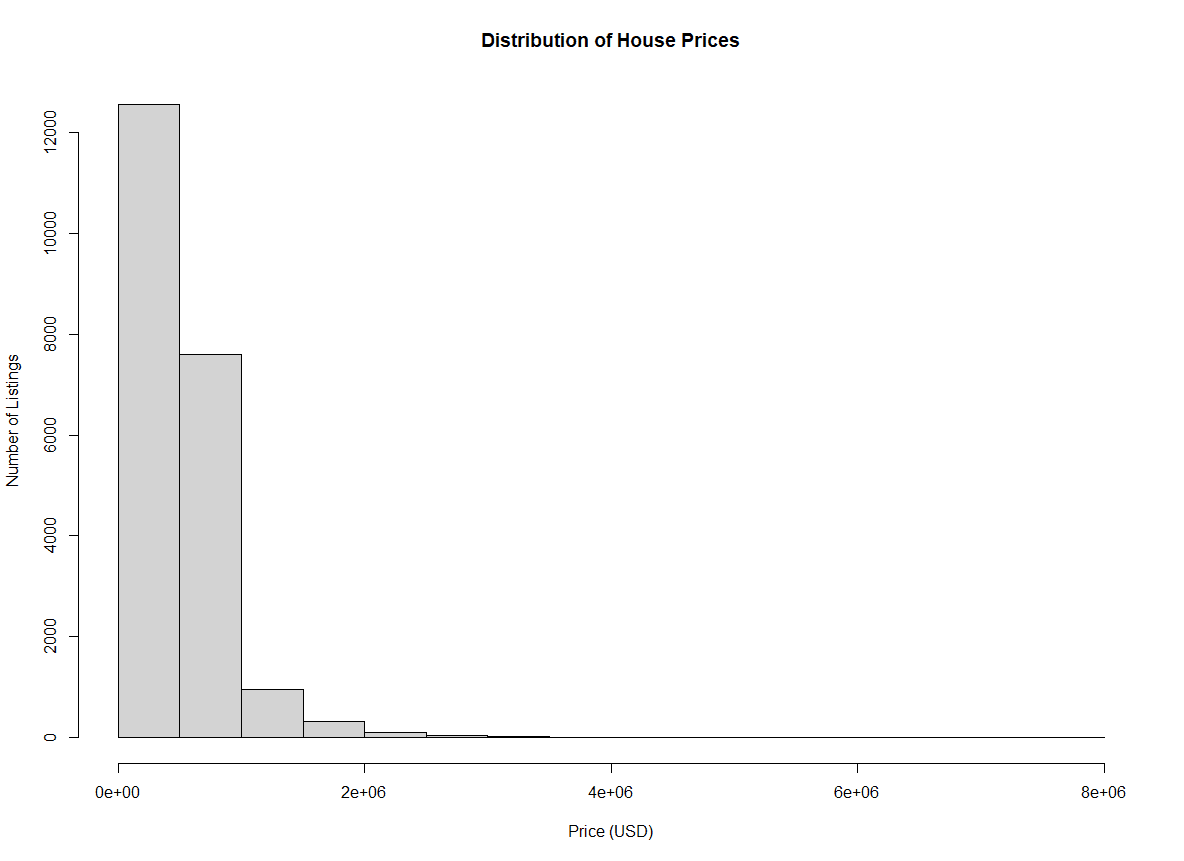 Histogram of home prices with axis labels. Image by Author.
Histogram of home prices with axis labels. Image by Author.
With the default arguments, it is challenging to see the full distribution of the housing prices across the range of prices. We can see they are centralized in the first few bins, but they are not very descriptive.
We can add more bins using the breaks parameter. With this argument, we can pass a vector of specific breakpoints to use, a function to compute the breakpoints, a number of breaks we would like, or a function to compute the number of cells.
For this example, we will pass the number of bins we would like. This number is context-specific based on what you are trying to show in your graph.
hist(home_data$price, breaks = 100)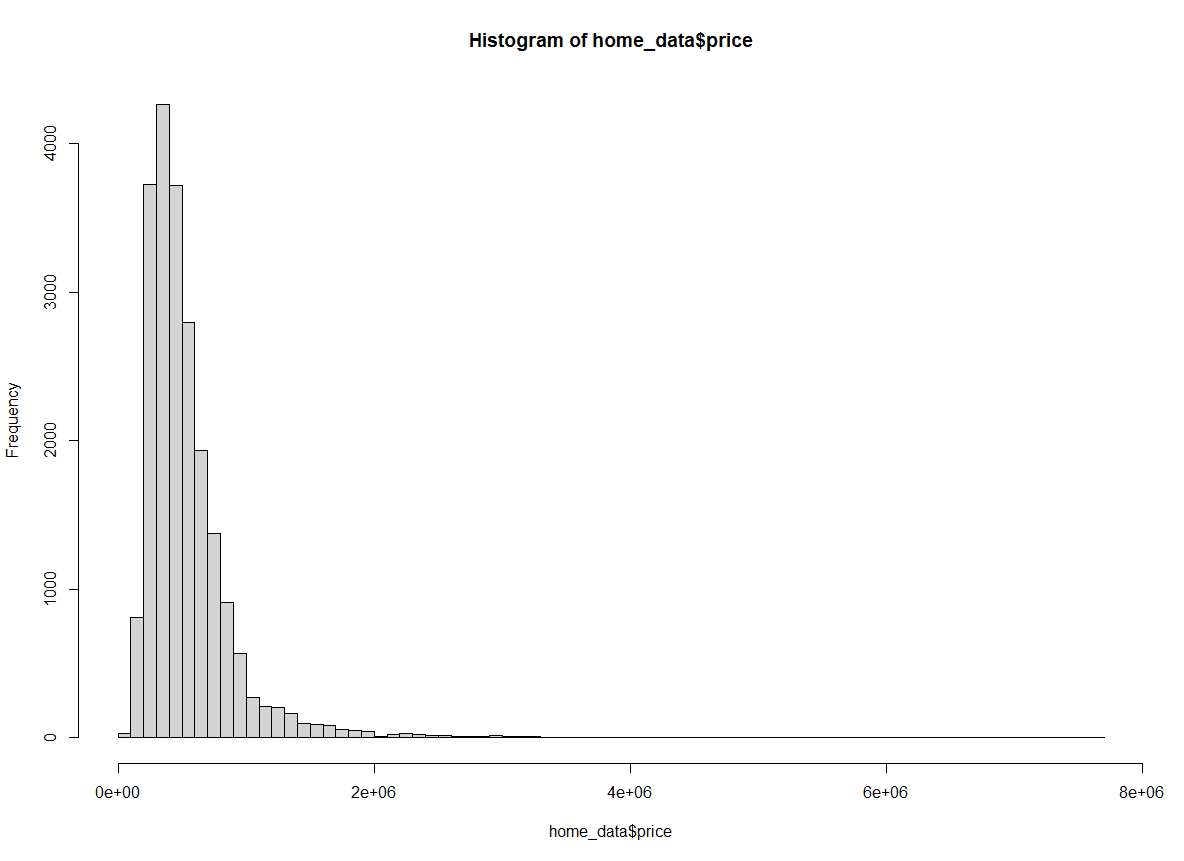 Histogram of home prices with bin width changed. Image by Author.
Histogram of home prices with bin width changed. Image by Author.
With breaks set to 100, we have significantly more visibility into the distribution in the first few buckets.
We can also specify the number of breaks using the names of common calculations for calculating optimal breaks in a histogram. By default, hist() uses the “Sturges” method. Here we specify the method explicitly.
hist(home_data$price, breaks = "Sturges")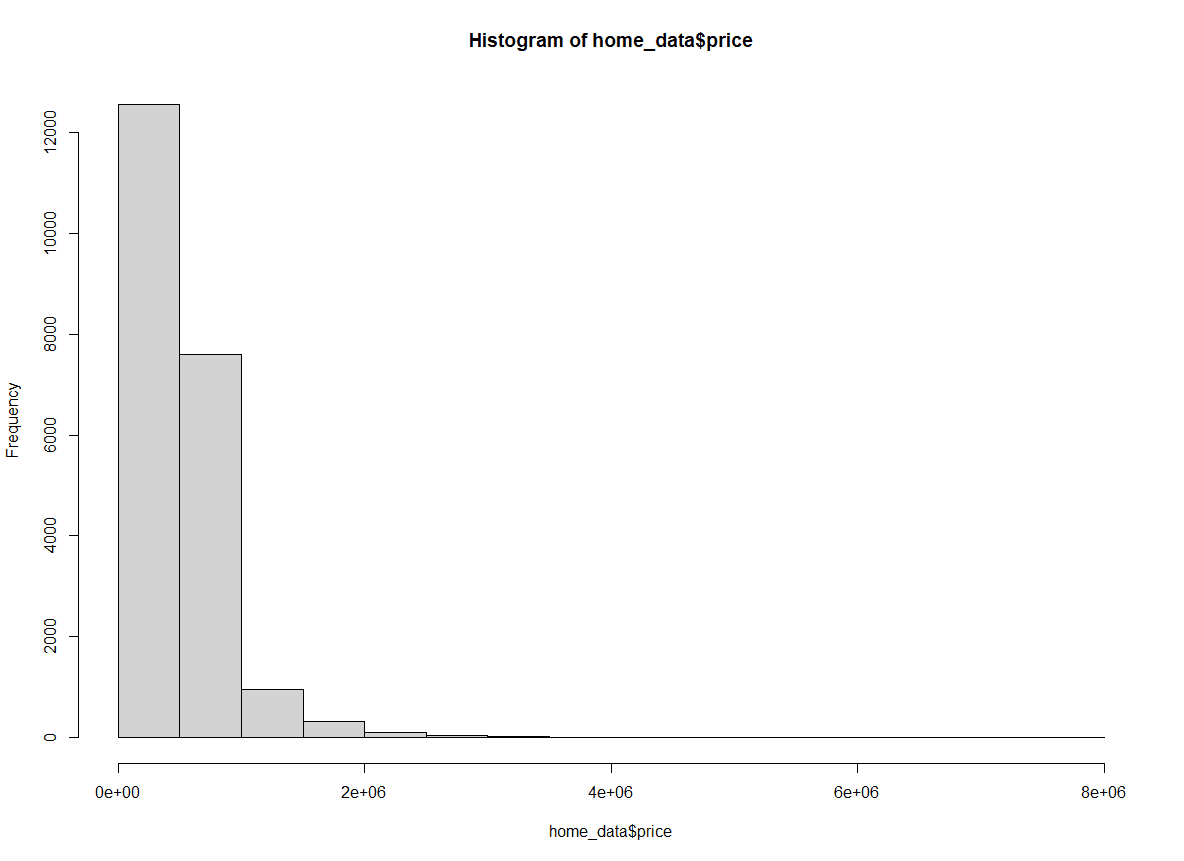 Histogram of home prices using the Sturges method. Image by Author.
Histogram of home prices using the Sturges method. Image by Author.
We can also pass “Scott” as an argument for the breaks attribute to use the Scott Method.
hist(home_data$price, breaks = "Scott")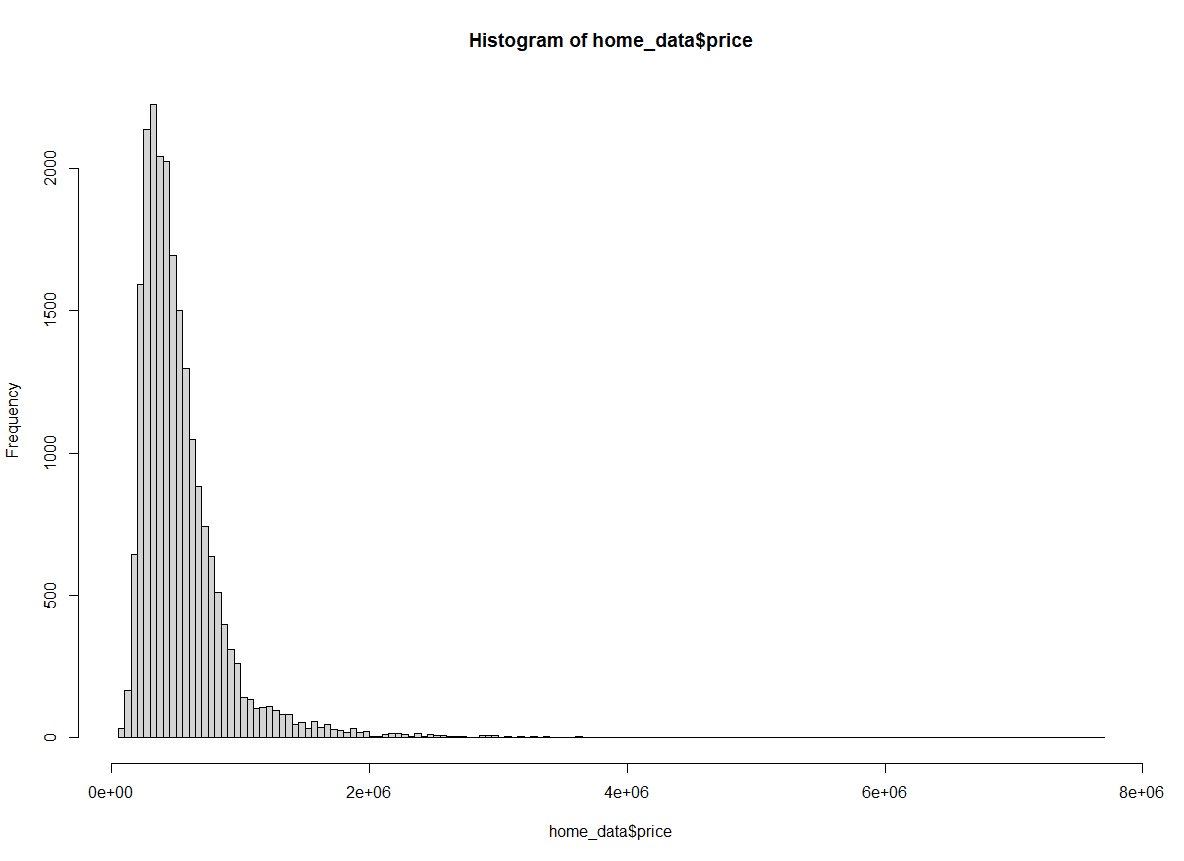
Histogram of home prices using the Scott method. Image by Author.
Finally, we could also use the Freedman-Diaconis (FD) method.
hist(home_data$price, breaks = "Freedman-Diaconis") Histogram of home prices using the Freedman-Diaconis method. Image by Author.
Histogram of home prices using the Freedman-Diaconis method. Image by Author.
The table below summarizes the three named break methods available in hist(). The default is Sturges.
| Method | How it works | Best for |
|---|---|---|
| Sturges | Bins = 1 + log₂(n). Assumes roughly normal data. | Small to medium datasets with near-normal distributions |
| Scott | Bin width = 3.49 × sd × n⁻¹ᐟ³. Minimizes integrated mean squared error. | Normally distributed data where variance matters |
| Freedman-Diaconis | Bin width = 2 × IQR × n⁻¹ᐟ³. Uses interquartile range instead of standard deviation. | Skewed data or distributions with outliers |
We can set the x-axis limits of our plot using the xlim argument to zoom in on the data we are interested in. For example, it is sometimes helpful to focus on the central part of the distribution, rather than on the long tail we currently see when we view the whole plot.
Changing the y-axis limits is also possible (using the ylim argument), but this is less useful for histograms since the automatically calculated values are almost always ideal.
We will zoom in on prices between $0 and $2M.
hist(home_data$price, breaks = 100, xlim = c(0, 2000000))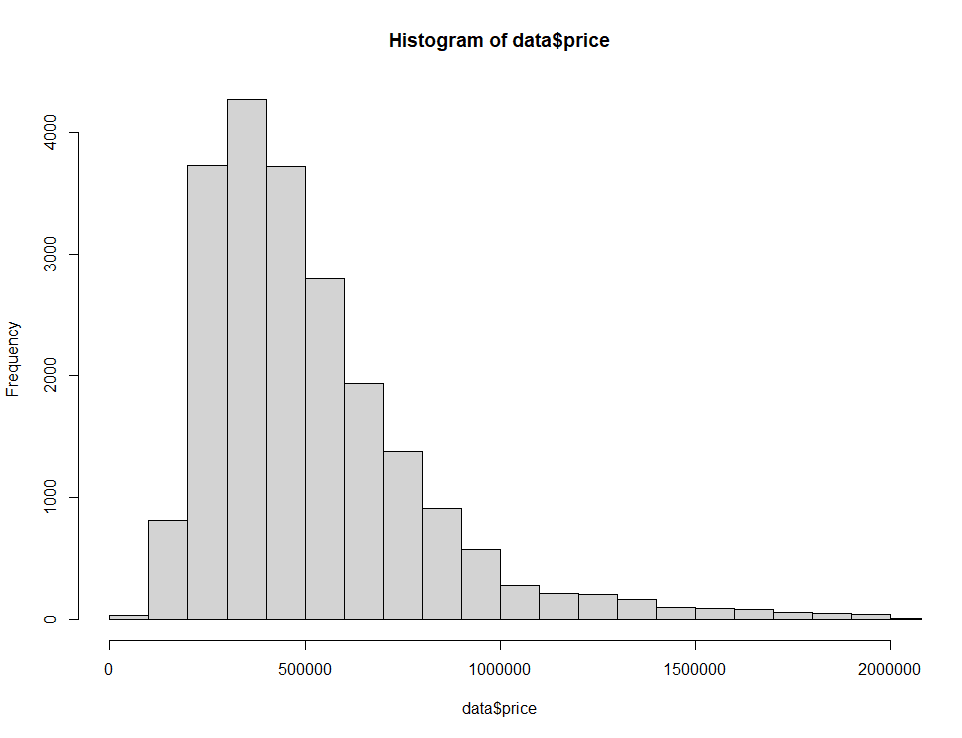 Histogram of home prices with the axis limits changed. Image by Author.
Histogram of home prices with the axis limits changed. Image by Author.
As you get more comfortable with R, you can try dedicated visualization packages that offer more control over aesthetics, layout, and interactivity. A very popular and easy-to-use library for plotting in R is called ggplot2. Below we create an interesting view of the distributions of prices based on the number of bedrooms in the house.
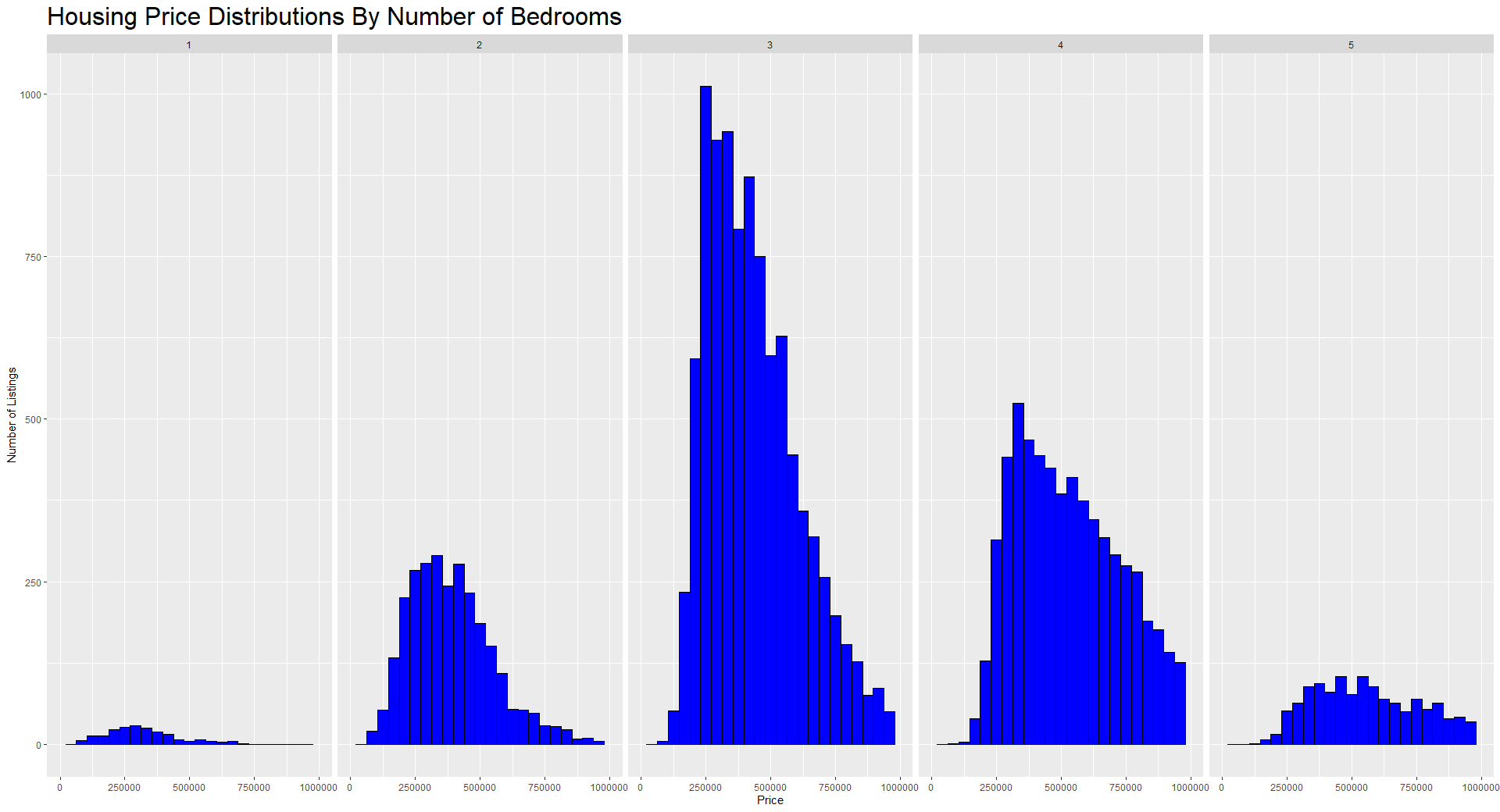 Histogram of home prices using ggplot2. Image by Author.
Histogram of home prices using ggplot2. Image by Author.
ggplot2 is the most widely used visualization package in R. You can learn to create histograms with it in our How to Make a ggplot2 Histogram in R tutorial, or explore the Graphics with ggplot2 tutorial for a broader introduction. Check out our Introduction to ggplot2 course and Intermediate ggplot2 course to go deeper.
In this tutorial, we learned that histograms are great visualizations for looking at distributions of continuous variables. We learned how to make a histogram in R, how to plot summary statistics on top of our histogram, how to customize features of the plot like the axis titles, the color, how we bin the x-axis, and how to set limits on the axes. Finally, we demonstrated some of the power of the ggplot2 library.
For further DataCamp reading and resources, check out our interactive courses:
Learn R with DataCamp
Course
Course
Course
Tutorial
Kevin Babitz
Tutorial
DataCamp Team
Tutorial
Karlijn Willems
Tutorial
Kurtis Pykes
Tutorial
Jachimma Christian
Tutorial
Aditya Sharma