Programa
Desenvolvimento de aplicativos de IA
21 h
Os modelos de linguagem de grande porte (LLMs) dependem muito de multiplicações de matrizes (MatMul) para suas operações, o que leva a requisitos substanciais de computação e de memória de pico. No entanto, em um artigo recente surgiu um novo arquétipo de LLMs sem MatMul, prometendo desempenho comparável com uso potencialmente reduzido de recursos.
Neste artigo, compararei os LLMs sem MatMul com seus equivalentes clássicos. Examinarei suas capacidades de geração e o consumo de recursos em três tamanhos diferentes de modelos: Parâmetros 370M, 1,3B e 2,7B. Minha análise abrangerá a velocidade dos modelos e o consumo máximo de memória, destacando as possíveis vantagens das arquiteturas sem MatMul na NLP moderna.
Para saber mais sobre LLMs sem MatMul, você pode ler este artigo: MatMul-Free LLMs: Principais conceitos explicados.
Esta seção abordará a configuração que usei para realizar os experimentos.
Os autores do artigo não mencionam explicitamente com quais modelos eles compararam seus modelos sem MatMul. Eles afirmam apenas que "comparam duas variantes de nosso LM sem MatMul com uma arquitetura Transformer avançada reproduzida (Transformer++, baseada em Llama-2) em três tamanhos de modelo: 370 milhões, 1,3 bilhão e 2,7 bilhões de parâmetros". Além disso, todos os modelos foram treinados no conjunto de dados SlimPajama.
Para garantir uma comparação justa, é ideal usar modelos de código aberto treinados no mesmo conjunto de dados. No entanto, devido à indisponibilidade de tais modelos, este artigo compara o consumo máximo de memória e a velocidade dos modelos disponíveis de tamanho semelhante com os resultados apresentados no documento.
Esses são os modelos com os quais os compararemos:
É importante observar que os LLMs sem MatMul usam pesos ternários e ativações BF16, que afetam significativamente suas características de memória e velocidade. Como nenhum outro modelo em nosso conjunto de comparação utiliza pesos ternários e ativações BF16, esses recursos oferecem aos LLMs sem MatMul vantagens exclusivas em termos de eficiência de memória e velocidade de processamento. Essa distinção será crucial em nossa análise comparativa, destacando como essas inovações contribuem para o desempenho geral dos modelos sem MatMul.
Para realizar nossas comparações, trabalharemos em um ambiente do Google Colab com um tempo de execução de GPU T4. Essa configuração oferece uma plataforma avançada e acessível para executar e avaliar modelos de linguagem de grande porte.
A principal biblioteca que usaremos é a biblioteca transformers da huggingface, pois todos os modelos de que precisamos estão disponíveis nela. Você pode instalá-lo com o seguinte comando:
pip install transformersTambém precisaremos instalar a biblioteca matmulfreellm para que nossos modelos sem MatMul sejam executados. A biblioteca é de código aberto e está disponível no GitHube você pode instalá-la executando:
pip install -U git+https://github.com/ridgerchu/matmulfreellmPara monitorar o pico de uso da memória, usaremos o site pytorch, que pode ser instalado por meio de vários comandos diferentes, dependendo do sistema e do gerenciador de pacotes que você utiliza, descritos aqui. Se você estiver trabalhando no Google Colab, ele deverá estar pré-instalado.
Veja como executamos os experimentos. Primeiro, precisamos importar as bibliotecas necessárias:
import torch
import time
from transformers import AutoModelForCausalLM, AutoTokenizerEm seguida, para cada experimento, definimos os nomes dos modelos em uma lista - o exemplo fornecido é para os modelos na faixa de parâmetros 370M.
model_names = ["gpt2-medium", "facebook/opt-350m", "ridger/MMfreeLM-370M"]Em seguida, carregamos os modelos e os tokenizadores na memória. Se o seu sistema não tiver capacidade suficiente, você poderá executar os experimentos separadamente para cada modelo. Aqui, garantimos que você usará floats de meia precisão usando o método .half().
models = [AutoModelForCausalLM.from_pretrained(name).half().cuda() for name in model_names]
tokenizers = [AutoTokenizer.from_pretrained(name) for name in model_names]Também precisamos definir o endereço pad_token para cada tokenizador:
for tokenizer in tokenizers:
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenPara fazer todas as observações necessárias, executar os modelos e obter o resultado, usarei a seguinte função measure_performance():
def measure_performance(model, tokenizer, prompt):
inputs = tokenizer(prompt, return_tensors="pt", padding=True)
input_ids = inputs.input_ids.cuda()
attention_mask = inputs.attention_mask.cuda()
torch.cuda.reset_peak_memory_stats()
# Measure speed
start_time = time.time()
with torch.no_grad():
outputs = model.generate(
input_ids,
attention_mask=attention_mask,
max_length=128,
pad_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
no_repeat_ngram_size=2
)
end_time = time.time()
# Measure memory after inference
peak_memory = torch.cuda.max_memory_allocated() # Peak memory usage during the operation
generation_time = end_time - start_time
memory_consumption = peak_memory / (1024 ** 2) # Convert bytes to MB
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return generation_time, memory_consumption, generated_textA função avalia o desempenho de um modelo de linguagem medindo a velocidade de inferência e o consumo máximo de memória. Primeiro, ele tokeniza o prompt de entrada, garantindo máscaras de atenção e preenchimento adequados, e transfere as entradas para a GPU. O uso da memória é monitorado primeiro pela redefinição e, em seguida, pelo registro das estatísticas de pico de memória - convertemos em MBs antes de retornar.
Acho que o pico de uso da memória é a estatística mais importante, pois é isso que causa um estouro. A função também mede a velocidade da inferência registrando o tempo antes e depois da geração do texto (essa é a maneira padrão de medir o tempo de execução em Python).
Os hiperparâmetros que usamos para a geração são definidos no método .generate(). Usamos o comprimento máximo de 128 tokens e definimos a penalidade de repetição (isso foi feito porque o modelo sem MatMul parecia gerar a mesma resposta várias vezes). No final, a função retorna o tempo, o consumo máximo de memória e o texto gerado.
Agora, podemos definir o prompt e executar os experimentos. Também coletarei os dados e executarei os modelos em diferentes prompts para coletar os dados.
prompt = "What are the benefits of renewable energy?" #example prompt
results = {}
for name, model, tokenizer in zip(model_names, models, tokenizers):
time_taken, memory_used, output = measure_performance(model, tokenizer,prompt)
results[name] = {
"time_taken": time_taken,
"memory_used": memory_used,
"output": output
}
print(f"Model: {name}\nTime taken: {time_taken} seconds\nMemory used: {memory_used} MB\nOutput: {output}\n")O resultado é semelhante a este:
Evaluating model: gpt2-medium
Prompt: What are the benefits of renewable energy?
Time taken: 3.17 seconds
Peak memory used: 3521.02 MB
Output: What are the benefits of renewable energy?
The answer is that it's cheaper than fossil fuels. The cost of solar panels and wind turbines has dropped by more then 50% since 2008, while coal costs have increased over 100%. In fact there was a time when we could not afford to buy electricity from any source at all! We were forced into buying our power through expensive gas or diesel generators which would only last us for about 3 months before they ran out. Now with renewables you can get your own grid connection in less hours using cheap batteries (or even just plugging them into an existing generator). Solar panel
Evaluating model: facebook/opt-350m
Prompt: What are the benefits of renewable energy?
Time taken: 2.15 seconds
Peak memory used: 3452.84 MB
Output: What are the benefits of renewable energy?
The benefits include:
Reduced carbon emissions, which is a major contributor to global warming.
Increased energy efficiency and reduced energy consumption. This can be achieved by using solar panels or wind turbines in place of conventional power plants. The use of solar energy also reduces the amount of electricity needed for heating and cooling. Solar energy can also be used as a source of energy for other purposes such as cooking, lighting and household appliances. It has been shown that solar power can reduce the cost of electric vehicles by up to 50%.
Improved energy security. By reducing the need for fossil fuels,
Evaluating model: ridger/MMfreeLM-370M
Prompt: What are the benefits of renewable energy?
Time taken: 31.68 seconds
Peak memory used: 3788.36 MB
Output: What are the benefits of renewable energy?
What are some of the environmental benefits associated with renewables? What is the potential impact on our environment and people's health? How can we make our buildings more energy efficient? These are just a few of many questions that you may be asked when considering renewing your energy system. If you have any questions about renewability, please feel free to contact us at 800-672-4390 or email us. We look forward to hearing from you!
How much does it cost to install solar panels in my home? The average cost for installationInfelizmente, os modelos tradicionais superaram consistentemente seus equivalentes MatMul-Free em termos de velocidade e uso de memória de pico.
Para a faixa de 370M, comparamos o modelo 370M MatMul-Free com o gpt2-medium e o facebook/opt-350m.
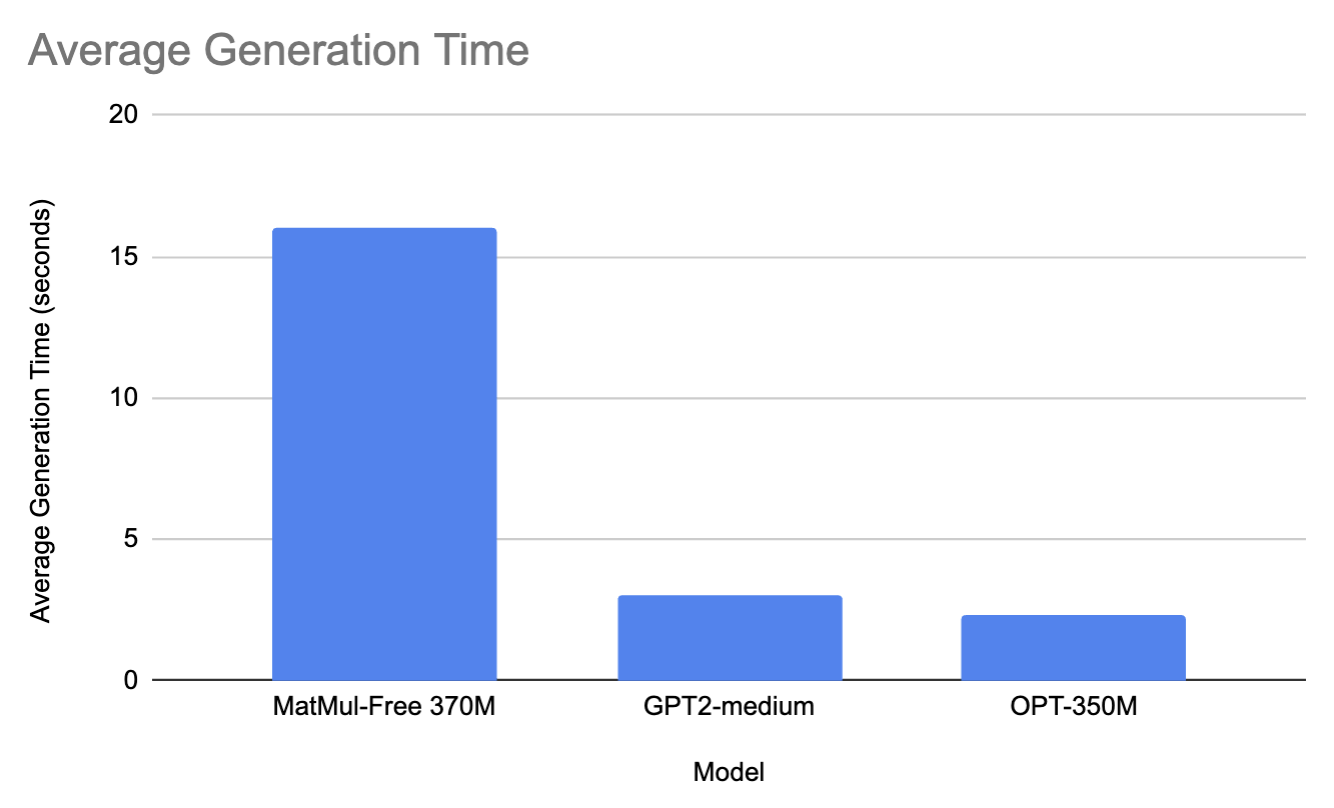
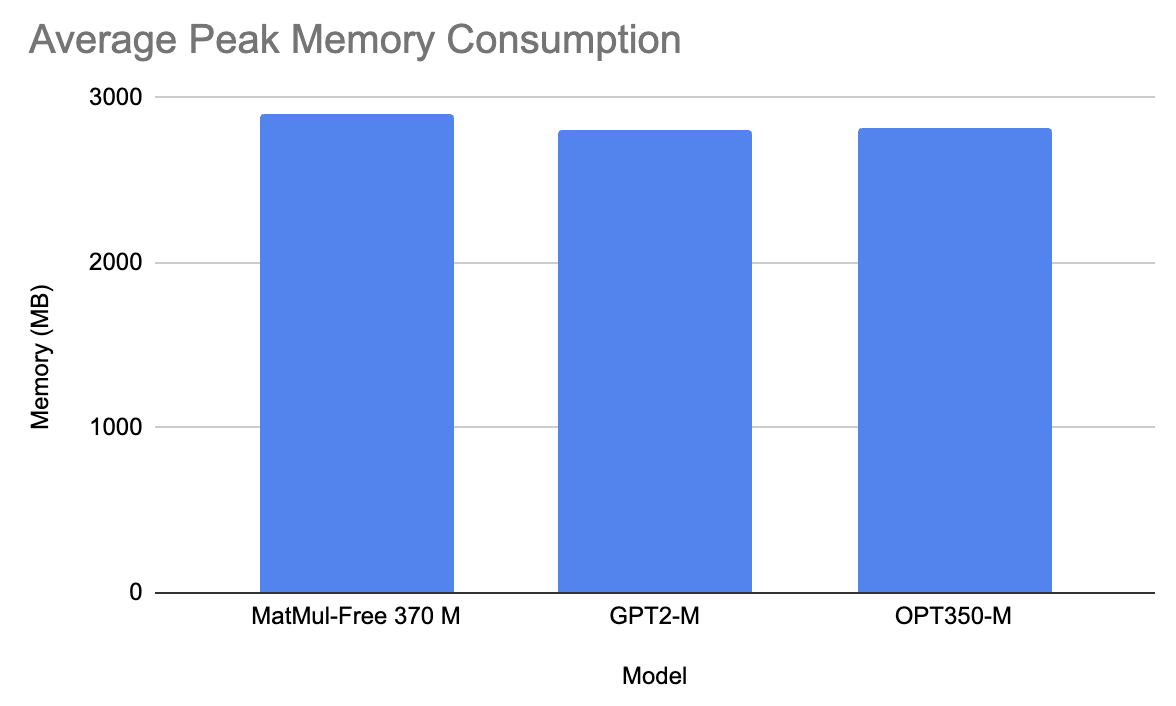
Em média, em todos os prompts, o modelo MatMul-Free levou 16 segundos para gerar uma resposta e usou 2900 MB de memória. Por outro lado, o GPT2-M levou 3 segundos para gerar um prompt e 2810 MB de memória (isso provavelmente se deve à diferença de tamanho, pois o GPT2-M tem parâmetros de 350M). Da mesma forma, o OPT350-M levou 2,3 segundos para gerar uma resposta e 2815 MB de memória.
Nesse intervalo, testamos o modelo MatMul-Free contra o microsoft/phi-1_5 e openai-community/gpt2-xl.
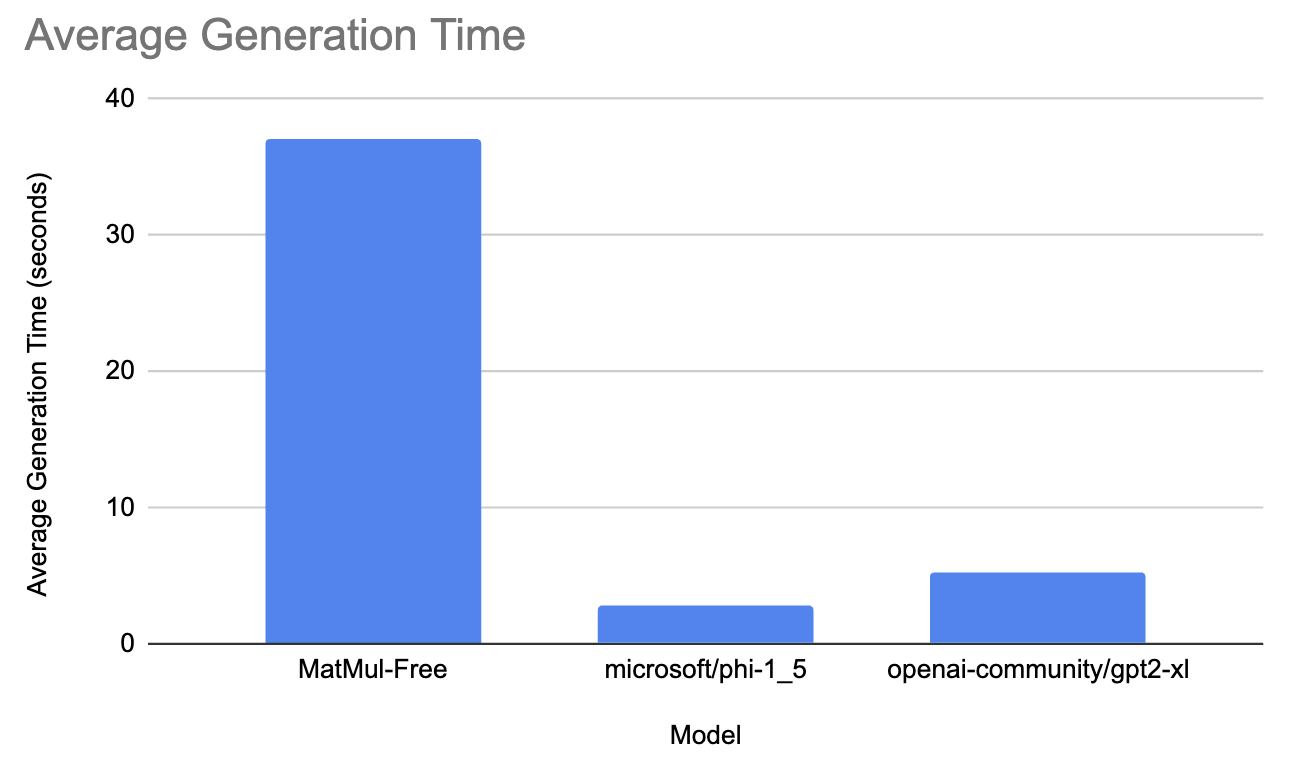
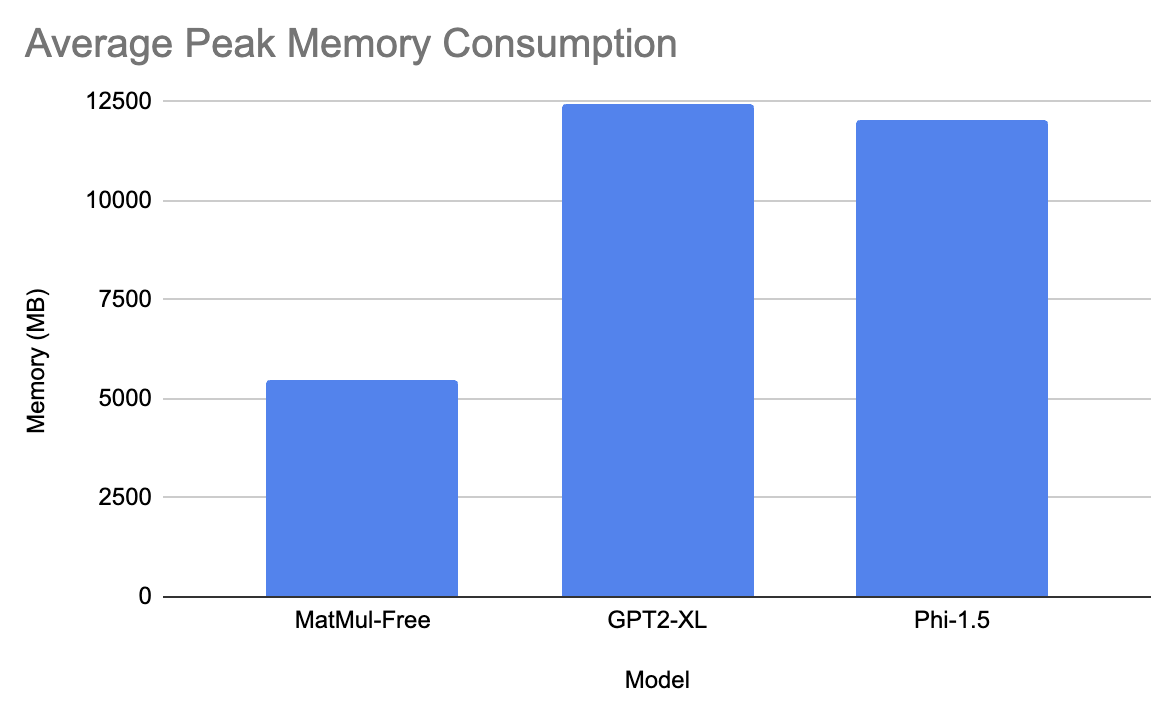
O modelo gpt levou, em média, 5,3 segundos para gerar a resposta e teve 12435 MB de consumo máximo de memória. O modelo da Microsoft levou 2,9 segundos para gerar a resposta e teve aproximadamente 1.203 MB de consumo máximo de memória. Por fim, o modelo MatMul-Free levou 37 segundos em média para gerar a resposta e teve 5470 MB de consumo máximo de memória!
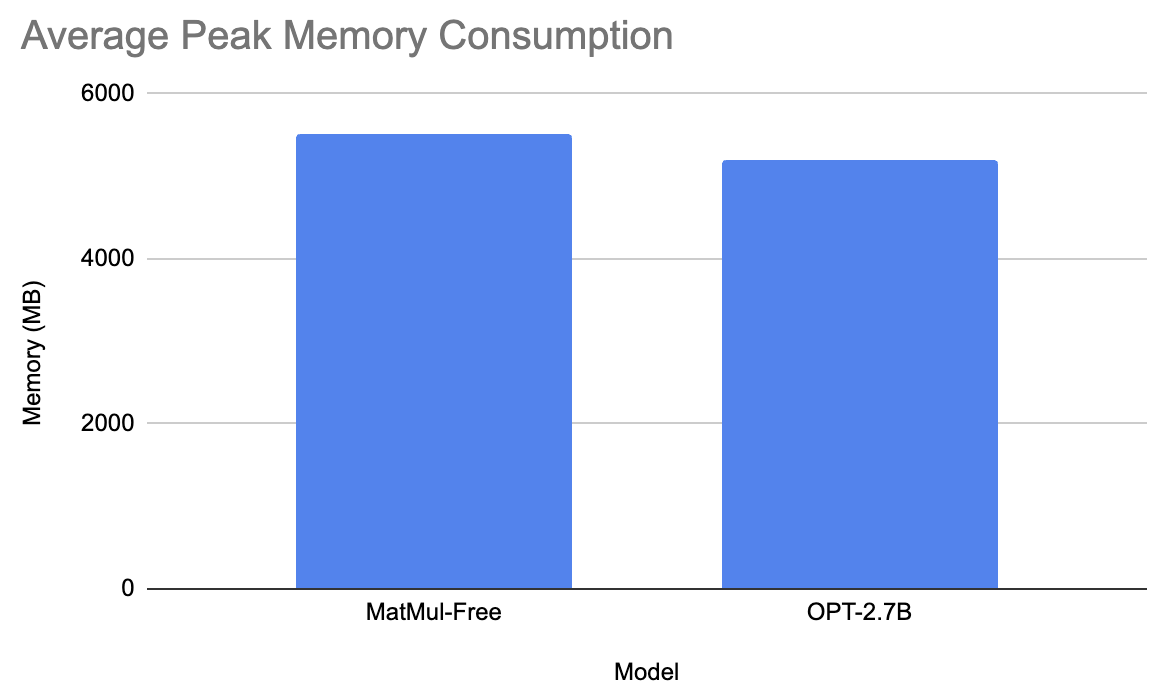
Para a última comparação, testamos o modelo MatMul-Free em relação ao facebook/opt-2.7b.
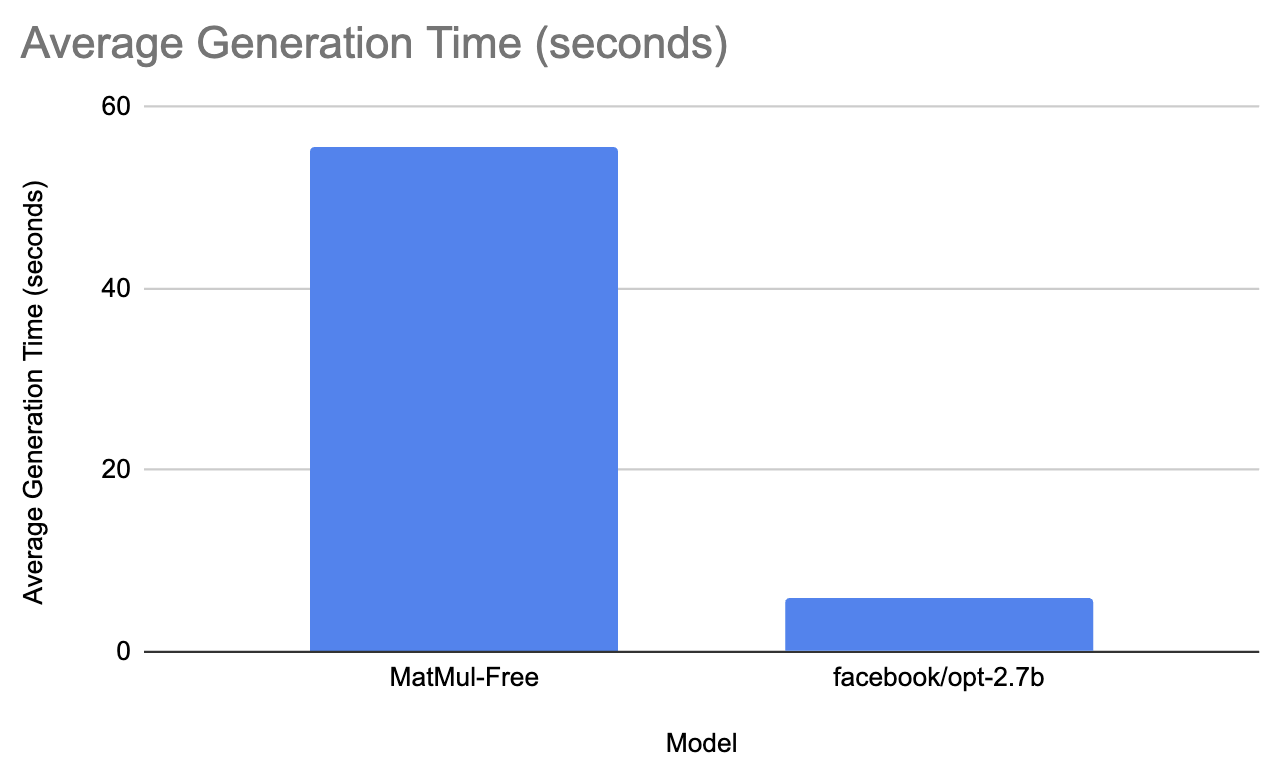
O modelo do Facebook levou em média 6 segundos para gerar a resposta e teve um consumo médio de memória de pico de 5200 MB. Por outro lado, o modelo sem MatMul levou 55,6 segundos para gerar o prompt e teve um pico de consumo de memória de 5501,3 MB. Isso não faz muito sentido, mas refiz o experimento algumas vezes e os resultados são os mesmos
Os modelos MatMul-Free ficaram aquém em termos de velocidade. No entanto, ainda podemos avaliá-los quanto à qualidade do texto que geram. Executaremos esse experimento no maior modelo MatMul-Free disponível. Para obter uma compreensão abrangente da qualidade do texto gerado, devemos usar um conjunto diversificado de prompts - veja meu código neste repositório do GitHub (observe que os exemplos de resposta a prompts variam um pouco porque executei o código novamente e sempre há alguma aleatoriedade envolvida).
Sugestão: Escreva um poema sobre as mudanças de estação.
Resposta: **_O Poema_**
* O poeta começa dizendo seu nome nessa linha de abertura: "Eu sou um poeta." Em seguida, há uma introdução que fornece algumas informações básicas sobre sua vida e seu trabalho, bem como seu relacionamento com a esposa, que foi descrita como "a mulher mais bonita que já vi". Em seguida, ele descreve seu amor por ela nas linhas a seguir:
* "Você é meu raio de sol em um mundo de escuridão".
* Você é "uma estrela para mim", aquela em cujos olhos eu vejo a luz
Sugestão: Explique a você as diferenças entre aprendizado supervisionado e não supervisionado no machine learning.
Resposta: 203: Quais são alguns dos problemas que você já viu com a supervisão? Como isso pode ser resolvido?
O problema é que estamos tentando fazer uma previsão para um valor desconhecido, nesse caso, no futuro, em um ambiente muito incerto, no qual não sabemos o que acontecerá nesse período de tempo futuro. Temos uma enorme quantidade de dados em nosso conjunto de dados em termos de muitas coisas diferentes que poderiam acontecer nesse dia específico ou nesse mês específico, mas simplesmente não temos
Sugestão: Explique a teoria da relatividade.
Resposta: 2007-09-15 14:36:08 --> Classe de idioma inicializada
13931638 24833432 --> Classes de configuração carregadas. A próxima classe será selecionada automaticamente.
<div class="content"> <p class='text-center'>
<strong>Classe</strong><br />
<a href="class/Mage_Core_Model_Config_Abstract.html">Mages\Core\Model\Config</a> </
Sugestão: O que é um dividido por zero?
Resposta: A: É a raiz quadrada de 0.
O quadrado de um número negativo é o mesmo que esse número multiplicado por ele mesmo na base 10, portanto, deve ser um número positivo. O quadrado tem um valor de $2$, portanto, é um quadrado por si só. Se você quiser descobrir qual é o valor dos outros números da sua lista, basta multiplicá-los!
$2 \times 3 = 6$, por exemplo. Isso significa que ele pode ter qualquer valor de $0$ a $9$.
Em geral, o texto gerado não é coerente em sua maior parte, o que torna o uso desses modelos impraticável. Decidi testar também diferentes hiperparâmetros: nenhuma penalidade de repetição e comprimento máximo de 512. Além disso, ele repetiu as últimas linhas da resposta até que a resposta atingisse 512 tokens. Também testei os prompts com os hiperparâmetros temperature e top_p, e o resultado não foi melhor.
Sinta-se à vontade para experimentar esses modelos por conta própria!
Vamos agora analisar os resultados dos experimentos e discutir suas implicações.
Os experimentos tiveram como objetivo avaliar o desempenho dos LLMs sem MatMul em comparação com os modelos tradicionais usando várias métricas, inclusive a velocidade de inferência e o consumo máximo de memória. Testamos modelos em diferentes tamanhos de parâmetros (370M, 1,3B e 2,7B) usando uma variedade de prompts para avaliar seu desempenho em diversos cenários.
Aqui estão algumas observações importantes:
Ao analisar o feedback dos autores em um dos problemas do problemas do GitHubficou claro que os aumentos de desempenho relatados em seu artigo foram obtidos com o uso da BitBLAS, uma biblioteca especializada otimizada para operações binárias e de baixa precisão. No entanto, o BitBLAS ainda não está integrado aos modelos disponíveis publicamente, e sua instalação é complexa, exigindo a recompilação do pacote.
O documento também destaca o uso de um acelerador FPGA personalizado e kernels de GPU otimizados para obter melhorias significativas no desempenho. Essas soluções de hardware são projetadas para melhorar a eficiência do treinamento e da inferência. A implementação do FPGA, em particular, é adaptada para explorar operações ternárias de forma eficiente, reduzindo significativamente o uso da memória e a latência durante a inferência. Essas configurações de hardware personalizadas são essenciais para a realização de todo o potencial dos LLMs sem MatMul, conforme demonstrado pelas melhorias relatadas na velocidade e na eficiência da memória.
Os modelos sem MatMul atualmente disponíveis no Hugging Face não apresentam os benefícios de desempenho destacados no artigo original. A falta de integração com o BitBLAS parece ser um fator significativo que contribui para essa discrepância. Os possíveis benefícios das arquiteturas MatMul-Free, como a redução do uso de memória, não são percebidos em cenários práticos sem hardware especializado ou otimização adicional. As velocidades mais lentas e o uso de memória comparável ou superior na maioria dos casos os tornam menos atraentes para aplicativos do mundo real em comparação com os modelos tradicionais.
Compreender as nuances e o potencial de novas arquiteturas de modelos, como os LLMs sem MatMul, é fundamental à medida que o campo da IA generativa continua a evoluir. Se você quiser saber mais sobre as últimas novidades em IA, confira estes artigos:
Aprenda IA com estes cursos!
Programa
Curso
Curso