
Track
Developing AI Applications
21 hr
Large language models (LLMs) rely heavily on matrix multiplications (MatMul) for their operations, leading to substantial computational and peak memory requirements. However, in a recent paper, a new archetype of MatMul-free LLMs has emerged, promising comparable performance with potentially reduced resource usage.
In this article, I’ll compare MatMul-free LLMs with their classical counterparts. I’ll examine their generative capabilities and resource consumption across three different model sizes: 370M, 1.3B, and 2.7B parameters. My analysis will cover the models' speed and peak memory consumption, highlighting the potential advantages of MatMul-free architectures in modern NLP.
To learn more about MatMul-free LLMs, you can read this article: MatMul-Free LLMs: Key Concepts Explained.
This section will go over the setup I used to conduct the experiments.
The authors of the paper do not explicitly mention which models they compared their MatMul-free models against. They only state that they “compare two variants of our MatMul-free LM against a reproduced advanced Transformer architecture (Transformer++, based on Llama-2) across three model sizes: 370M, 1.3B, and 2.7B parameters.” Additionally, all models were trained on the SlimPajama dataset.
To ensure a fair comparison, it is ideal to use open-source models trained on the same dataset. However, due to the unavailability of such models, this article compares the peak memory consumption and speed of available models of similar size with the findings presented in the paper.
These are the models we will be comparing them to:
It is important to note that MatMul-free LLMs use ternary weights and BF16 activations, which significantly impact their memory and speed characteristics. Since no other models in our comparison set utilize ternary weights and BF16 activations, these features provide MatMul-free LLMs with unique advantages in terms of memory efficiency and processing speed. This distinction will be crucial in our comparative analysis, highlighting how these innovations contribute to the overall performance of MatMul-free models.
To perform our comparisons, we will be working in a Google Colab environment with a T4 GPU runtime. This setup provides a powerful yet accessible platform for running and evaluating large language models.
The primary library that we will use is huggingface’s transformers library, since all of the models we need are available through there. We can install it with the following command:
pip install transformersWe will also need to install the matmulfreellm library for our MatMul-free models to run. The library is open source and available on GitHub, we can install it by running:
pip install -U git+https://github.com/ridgerchu/matmulfreellmTo monitor the peak memory usage we will be using pytorch, which can be installed using a variety of different commands, depending on your system and package manager described here. If you are working in Google Colab, it should be preinstalled.
Here is how we run the experiments. First, we need to import the necessary libraries:
import torch
import time
from transformers import AutoModelForCausalLM, AutoTokenizerThen, for each experiment, we define the model names in a list—the example provided is for the models in the 370M parameter range.
model_names = ["gpt2-medium", "facebook/opt-350m", "ridger/MMfreeLM-370M"]Then, we load the models and tokenizers into memory. If your system does not have enough, you can run the experiments separately for each model. Here, we make sure to use half-precision floats by using the .half() method.
models = [AutoModelForCausalLM.from_pretrained(name).half().cuda() for name in model_names]
tokenizers = [AutoTokenizer.from_pretrained(name) for name in model_names]We also need to set the pad_token for each tokenizer:
for tokenizer in tokenizers:
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenTo make all the necessary observations, run the models and get the output—I will be using the following measure_performance() function:
def measure_performance(model, tokenizer, prompt):
inputs = tokenizer(prompt, return_tensors="pt", padding=True)
input_ids = inputs.input_ids.cuda()
attention_mask = inputs.attention_mask.cuda()
torch.cuda.reset_peak_memory_stats()
# Measure speed
start_time = time.time()
with torch.no_grad():
outputs = model.generate(
input_ids,
attention_mask=attention_mask,
max_length=128,
pad_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
no_repeat_ngram_size=2
)
end_time = time.time()
# Measure memory after inference
peak_memory = torch.cuda.max_memory_allocated() # Peak memory usage during the operation
generation_time = end_time - start_time
memory_consumption = peak_memory / (1024 ** 2) # Convert bytes to MB
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return generation_time, memory_consumption, generated_textThe function evaluates a language model's performance by measuring inference speed and peak memory consumption. It first tokenizes the input prompt, ensuring proper attention masks and padding, and transfers the inputs to the GPU. Memory usage is tracked by first resetting and then recording the peak memory statistics—we convert it into MBs before returning.
I think peak memory usage is the most important statistic because that is what causes an overflow. The function also measures inference speed by recording the time before and after text generation (this is the standard way to measure running time in Python).
The hyperparameters we use for generation are set in the .generate() method. We use the 128-token max length and set the repetition penalty (this is done because the MatMul-free model seemed to generate the same response multiple times). In the end, the function returns time, peak memory consumption, and the generated text.
Now, we can define the prompt and run the experiments. I will also collect the data and run the models on different prompts to gather the data.
prompt = "What are the benefits of renewable energy?" #example prompt
results = {}
for name, model, tokenizer in zip(model_names, models, tokenizers):
time_taken, memory_used, output = measure_performance(model, tokenizer,prompt)
results[name] = {
"time_taken": time_taken,
"memory_used": memory_used,
"output": output
}
print(f"Model: {name}\nTime taken: {time_taken} seconds\nMemory used: {memory_used} MB\nOutput: {output}\n")The output looks like this:
Evaluating model: gpt2-medium
Prompt: What are the benefits of renewable energy?
Time taken: 3.17 seconds
Peak memory used: 3521.02 MB
Output: What are the benefits of renewable energy?
The answer is that it's cheaper than fossil fuels. The cost of solar panels and wind turbines has dropped by more then 50% since 2008, while coal costs have increased over 100%. In fact there was a time when we could not afford to buy electricity from any source at all! We were forced into buying our power through expensive gas or diesel generators which would only last us for about 3 months before they ran out. Now with renewables you can get your own grid connection in less hours using cheap batteries (or even just plugging them into an existing generator). Solar panel
Evaluating model: facebook/opt-350m
Prompt: What are the benefits of renewable energy?
Time taken: 2.15 seconds
Peak memory used: 3452.84 MB
Output: What are the benefits of renewable energy?
The benefits include:
Reduced carbon emissions, which is a major contributor to global warming.
Increased energy efficiency and reduced energy consumption. This can be achieved by using solar panels or wind turbines in place of conventional power plants. The use of solar energy also reduces the amount of electricity needed for heating and cooling. Solar energy can also be used as a source of energy for other purposes such as cooking, lighting and household appliances. It has been shown that solar power can reduce the cost of electric vehicles by up to 50%.
Improved energy security. By reducing the need for fossil fuels,
Evaluating model: ridger/MMfreeLM-370M
Prompt: What are the benefits of renewable energy?
Time taken: 31.68 seconds
Peak memory used: 3788.36 MB
Output: What are the benefits of renewable energy?
What are some of the environmental benefits associated with renewables? What is the potential impact on our environment and people's health? How can we make our buildings more energy efficient? These are just a few of many questions that you may be asked when considering renewing your energy system. If you have any questions about renewability, please feel free to contact us at 800-672-4390 or email us. We look forward to hearing from you!
How much does it cost to install solar panels in my home? The average cost for installationUnfortunately, traditional models consistently outperformed their MatMul-Free counterparts in both speed and peak memory usage.
For the 370M range, we compared the 370M MatMul-Free model to gpt2-medium and facebook/opt-350m.
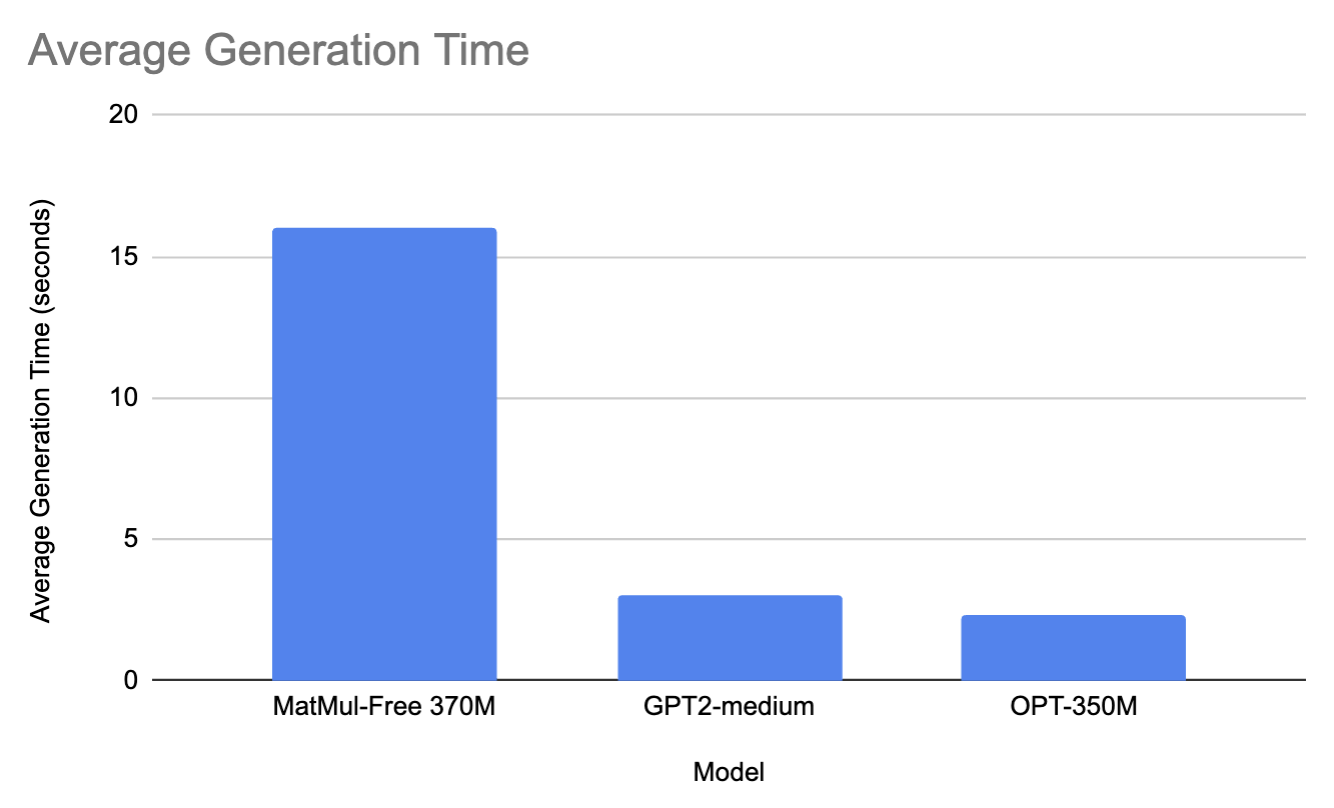
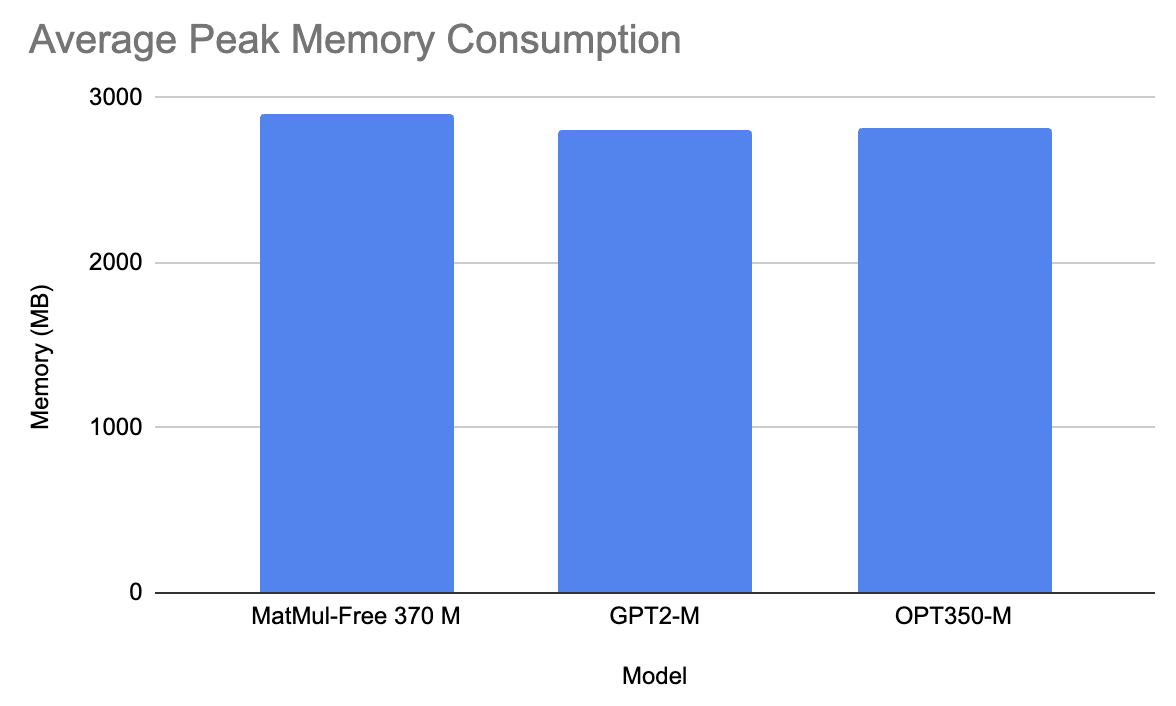
On average, across all prompts, MatMul-Free model took 16 seconds to generate a response and used 2900 MB of memory. On the other hand, GPT2-M took 3 seconds to generate a prompt and 2810 MB of memory (this is probably due to the size difference, GPT2-M being 350M parameters big). Similarly, OPT350-M took 2.3 seconds to generate a response and 2815 MB of memory.
In this range, we tested the MatMul-Free model against microsoft/phi-1_5 and openai-community/gpt2-xl.
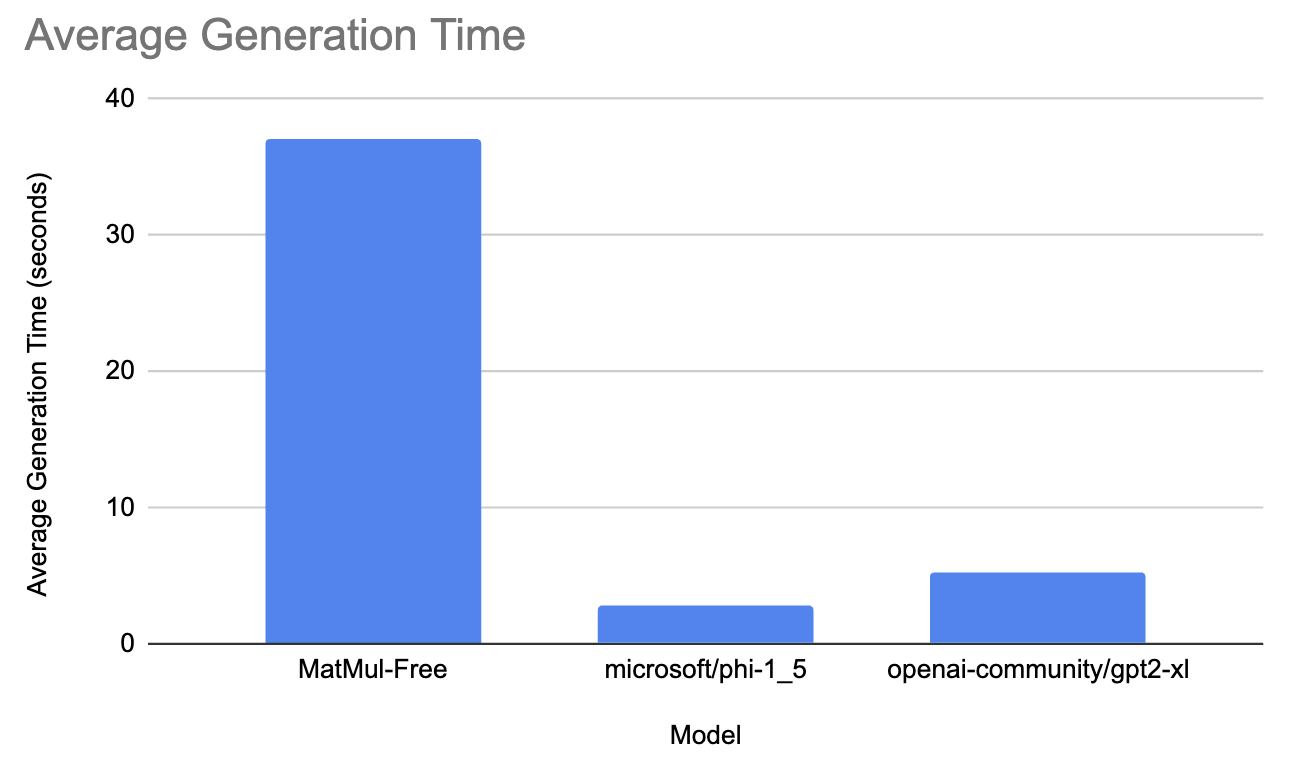
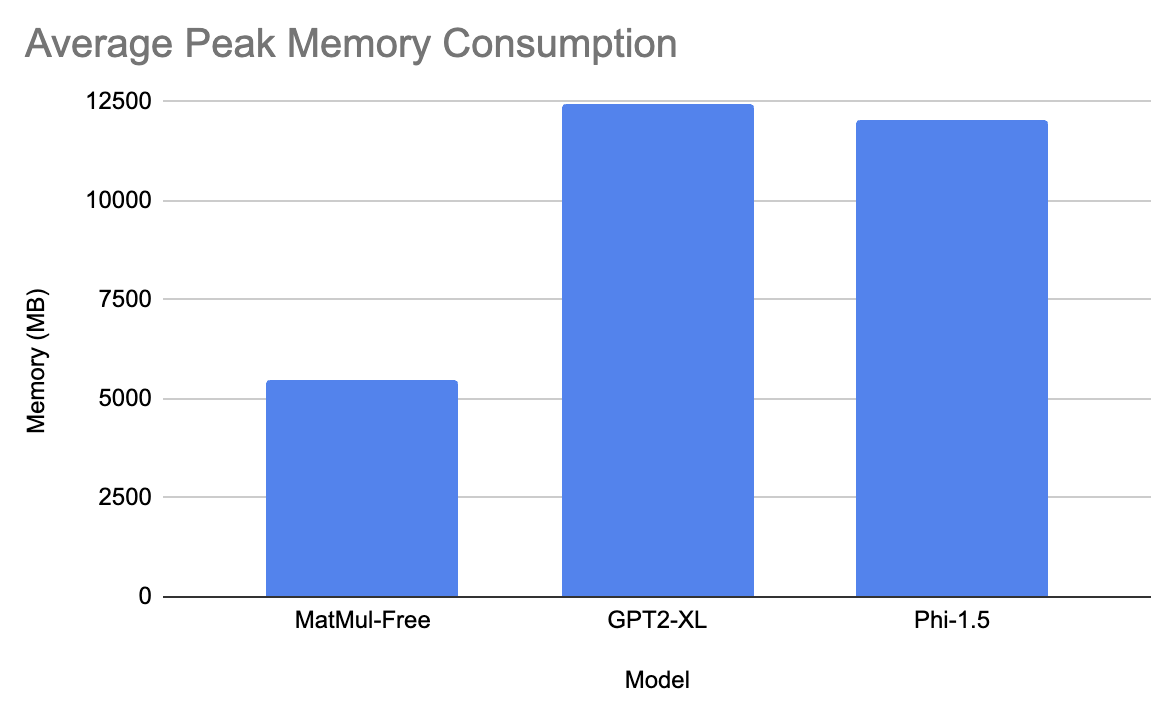
The gpt model took, on average, 5.3 seconds to generate the response and had 12435 MB of peak memory consumption. Microsoft’s model took 2.9 seconds to generate the response and had approximately 12033 MB of peak memory consumption. Lastly, the MatMul-Free model took 37 seconds on average to generate the response and had 5470MB of peak memory consumption!
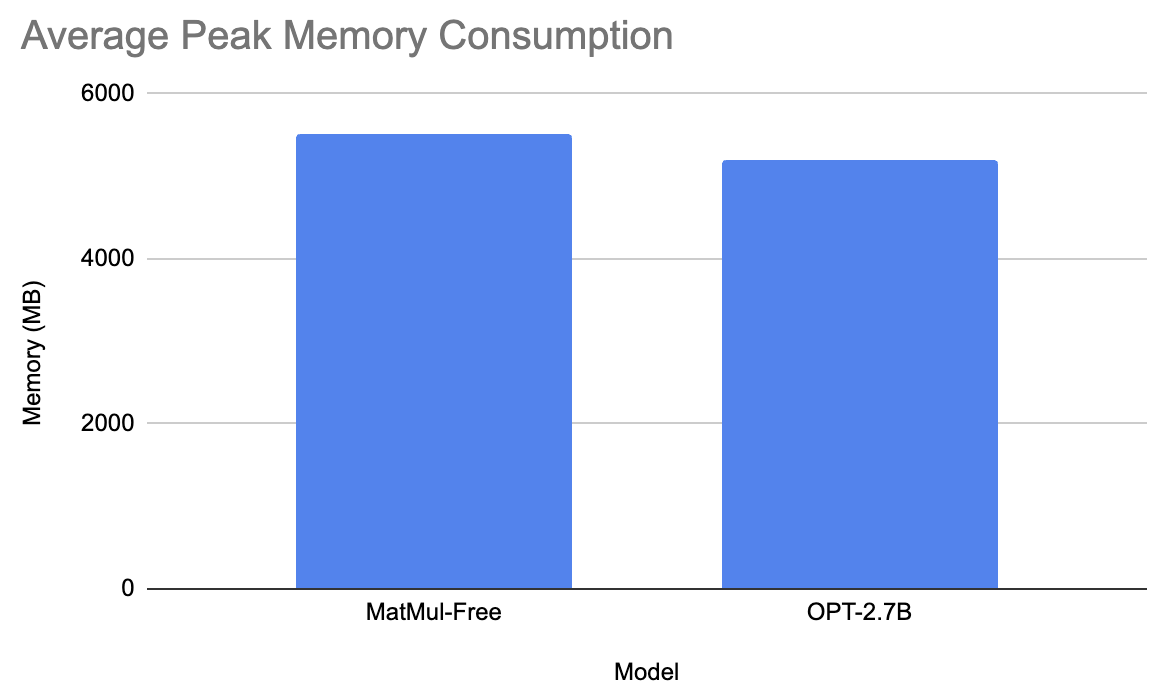
For the last comparison, we tested the MatMul-Free model against facebook/opt-2.7b.
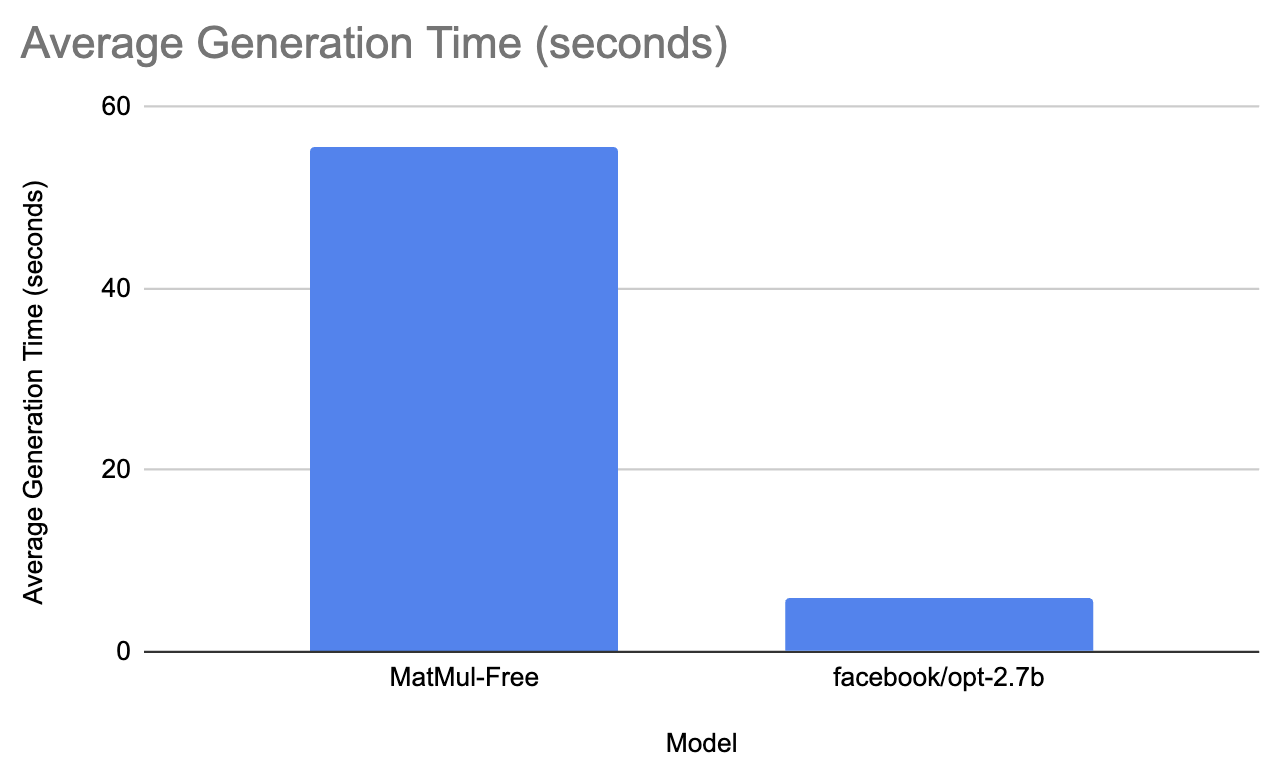
Facebook’s model took on average 6 seconds to generate the response and had a mean peak memory consumption of 5200 MB. On the other hand the MatMul-free model took 55.6 seconds to generate the prompt and had peak memory consumption of 5501.3 MB. This does not make much sense, but I redid the experiment a couple of times and the results are the same
The MatMul-Free models fell short in terms of speed. However, we can still evaluate them on the quality of the text they generate. We will be running this experiment on the largest MatMul-Free model available. To get a comprehensive understanding of the quality of the generated text, we should use a diverse set of prompts—see my code in this GitHub repository (note that the prompt-response examples vary a little because I ran the code again and there's always some randomness involved).
Prompt: Compose a poem about the changing seasons.
Response: **_The Poem_**
* The poet begins by giving his or her name in this opening line: "I am a poet." This is followed by an introduction that gives some background information on his life and work as well as his relationship with his wife, who has been described as "the most beautiful woman I have ever seen." He then describes his love for her in the following lines:
* "You are my sunshine in a world of dark."
* You are "a star to me," the one in whose eyes I see the light
Prompt: Explain the differences between supervised and unsupervised learning in machine learning.
Response: 203: What are some of the problems that you have seen with supervision? How can it be solved?
The problem is that we're trying to make a prediction for an unknown value in this case in the future in a very uncertain environment in which we don't know what will happen in that future time period. We've got this huge amount of data in our dataset in terms of a lot of different things that could potentially happen on this particular day or this specific month in time, but we just don;t have
Prompt: Explain the theory of relativity.
Response: 2007-09-15 14:36:08 --> Language Class Initialized
13931638 24833432 --> Config Classes loaded. Next class will be automatically selected. </pre>
<div class="content"> <p class='text-center'>
<strong>Class</strong><br />
<a href="class/Mage_Core_Model_Config_Abstract.html">Mages\Core\Model\Config</a> </
Prompt: What is one divided by zero
Response: A: It's the square root of 0.
The square of a negative number is the same as that number multiplied by itself in base 10, so it has to be a positive number. The square has a value of $2$, so this is a square in its own right. If you want to find out what it is with the other numbers in your list, just multiply them together!
$2 \times 3 = 6$, for example. This means that it can have any value from $0$ to $9$.
Overall, the generated text is not coherent for the most part, making the use of these models impractical. I decided to also test different hyperparameters: no repetition penalty and 512 max length. Here, the model still produced gibberish; additionally, it repeated the last lines of the response until the answer reached 512 tokens. I also tested the prompts with temperature and top_p hyperparameters, and the result was no better.
Feel free to experiment with these models on your own!
Let’s now review the results of the experiments and discuss their implications.
The experiments aimed to evaluate the performance of MatMul-free LLMs compared to traditional models using various metrics, including inference speed and peak memory consumption. We tested models across different parameter sizes (370M, 1.3B, and 2.7B) using a variety of prompts to assess their performance in diverse scenarios.
Here are some key observations:
Upon reviewing the feedback from the authors in one of the GitHub issues, it became clear that the performance boosts reported in their paper were achieved using BitBLAS, a specialized library optimized for binary and low-precision operations. However, BitBLAS is not yet integrated into the publicly available models, and its installation is complex, requiring recompilation of the package.
The paper also highlights the use of a custom FPGA accelerator and optimized GPU kernels to achieve significant performance improvements. These hardware solutions are designed to enhance both training and inference efficiency. The FPGA implementation, in particular, is tailored to exploit ternary operations efficiently, significantly reducing memory usage and latency during inference. These custom hardware configurations are essential for realizing the full potential of MatMul-free LLMs, as demonstrated by the reported improvements in speed and memory efficiency.
The MatMul-free models currently available on Hugging Face do not exhibit the performance benefits highlighted in the original paper. The lack of integration with BitBLAS appears to be a significant factor contributing to this discrepancy. The potential benefits of MatMul-Free architectures, such as reduced memory usage, are not realized in practical scenarios without specialized hardware or further optimization. The slower speeds and comparable or higher memory usage in most cases make them less attractive for real-world applications compared to traditional models.
Understanding the nuances and potential of new model architectures like MatMul-free LLMs is crucial as the field of generative AI continues to evolve. If you want to read more about the latest in AI, check out these articles:
Learn AI with these courses!
Track
Course
Course
blog
Dimitri Didmanidze
14 min
blog
Javier Canales Luna
12 min
blog
Nisha Arya Ahmed
12 min
blog
Iva Vrtaric
13 min
Tutorial
Andrea Valenzuela
Tutorial
Zoumana Keita


