Programa
Cientista de machine learning em Python
85 h
Como alguém que usa regularmente modelos avançados como o ChatGPT da OpenAI e o Claude da Anthropic, observei em primeira mão como o desempenho deles se degrada à medida que o tamanho do prompt de entrada aumenta, levando a problemas para manter a coerência e a relevância em textos extensos.
Para resolver essas limitações, pesquisadores da Microsoft e da Universidade de Illinois introduziram o SAMBA-uma nova arquitetura híbrida que combina modelos de espaço de estado (SSMs) com atenção de janela deslizante (SWA).
Sua abordagem aproveita os pontos fortes dos SSMs, que são excelentes para gerenciar dependências de longo prazo, e do SWA, que lida com janelas de contexto e mantém a traçabilidade computacional. Ao combinar essas técnicas, o SAMBA consegue uma modelagem de linguagem eficiente com umcomprimento de contexto praticamente ilimitado.
Neste artigo, exploraremos a arquitetura do SAMBA e sua capacidade exclusiva de lidar com longos períodos de texto sem perder o contexto. Também destacamos seu potencial para aprimorar significativamente os recursos dos modelos de linguagem no processamento e na geração de sequências estendidas, estabelecendo um novo padrão na modelagem de linguagem.
Para entender por que o SAMBA é tão inovador, primeiro precisamos entender os desafios que os modelos de linguagem tradicionais enfrentam ao lidar com sequências de texto longas.
Tradicionais Modelos baseados em transformadoresembora extremamente avançados, enfrentam desafios significativos ao lidar com sequências de texto longas devido à sua complexidade quadrática em relação ao comprimento do contexto. Essa complexidade quadrática decorre do mecanismo de mecanismo de autoatençãoque exige que cada token atenda a todos os outros tokens da sequência.
Como resultado, os custos computacionais e de memória crescem rapidamente com o aumento do comprimento da sequência, tornando esses modelos impraticáveis para tarefas que exigem o processamento de textos muito longos.
Essa limitação geralmente nos força a truncar as entradas ou a usar outras estratégias abaixo do ideal para atender às restrições do hardware disponível. Por fim, esse compromisso reduz a capacidade do modelo de manter o desempenho em sequências estendidas, um desafio que encontrei ao desenvolver um aplicativo que precisa processar documentos longos.
Os modelos de espaço de estado (SSMs) oferecem uma alternativa com complexidade linear, o que os torna mais eficientes do ponto de vista computacional para lidar com sequências longas. Os SSMs mantêm um estado em evolução, o que lhes permite lidar com dependências estendidas sem o custo proibitivo dos transformadores.
No entanto, os SSMs têm suas limitações. Devido à sua natureza markoviana, em que o estado atual depende apenas do estado anterior, eles costumam ter dificuldades com a recuperação da memória em sequências longas. Essa recuperação limitada da memória reduz sua eficácia na modelagem de contexto abrangente, especialmente em aplicativos que exigem a retenção e a referência de informações muito anteriores na sequência.
Considerando os pontos fortes e fracos dos transformadores e dos SSMs, há uma necessidade premente de abordagens híbridas que possam aproveitar as vantagens de cada um e, ao mesmo tempo, atenuar suas limitações. A combinação de SSMs com mecanismos de atenção apresenta uma solução promissora.
Essa abordagem híbrida utiliza a eficiência e as propriedades de dependência de longo alcance dos SSMs juntamente com o mecanismo de atenção dinâmica e concentrada dos Transformers. Ao integrar esses dois métodos, podemos criar um modelo que processa suavemente sequências longas com melhor recuperação da memória e compreensão contextual.
O SAMBA oferece uma solução elegante para esse gargalo de contexto, combinando os pontos fortes de duas abordagens distintas.
A ideia central do SAMBA é intercalar Mambaum SSM, com SwiGLU e camadas de atenção de janela deslizante (SWA). Essa estrutura híbrida captura tanto as estruturas recorrentes quanto a recuperação precisa da memória.
O SAMBA exemplifica essa abordagem, combinando os pontos fortes dos SSMs e dos mecanismos de atenção para gerenciar contextos longos e, ao mesmo tempo, reter informações detalhadas.
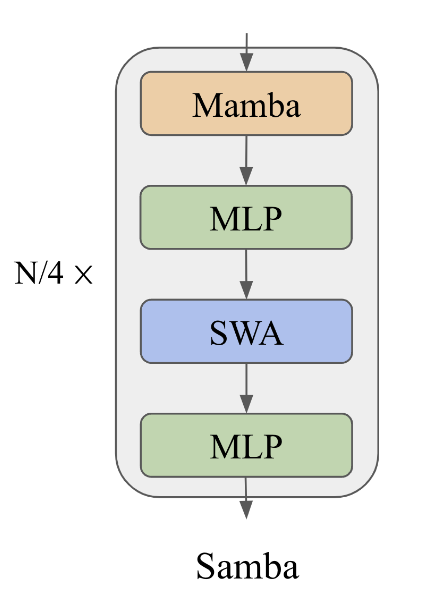
Um diagrama que ilustra a arquitetura SAMBA. Fonte: Ren et. al (2024)
As camadas do Mamba no SAMBA são capazes de capturar a semântica dependente do tempo, fornecendo uma estrutura robusta para lidar com dados sequenciais. Essas camadas operam mantendo e atualizando um estado que reflete as dependências temporais nos dados.
O Mamba consegue isso utilizando espaços de estado seletivos que permitem que o modelo se concentre em entradas relevantes e mantenha informações importantes em sequências longas. Esse mecanismo seletivo é fundamental para a decodificação rápida e garante que o modelo possa interpretar e prever padrões sequenciais com alta precisão e mínima sobrecarga computacional.
As camadas de atenção de janela deslizante complementam as camadas Mamba, abordando dependências complexas e não markovianas em uma janela de contexto limitada. O SWA opera em um tamanho de janela que desliza sobre a sequência de entrada, garantindo uma complexidade computacional linear.
Isso permite que o modelo recupere sinais de alta definição do histórico de médio e curto prazo que não podem ser capturados pelos estados recorrentes do Mamba. Ao ajustar dinamicamente o foco, as camadas de SWA permitem que o modelo mantenha a coerência e o contexto, especialmente em tarefas que exigem respostas contextualmente relevantes em entradas longas.
As camadas SwiGLU no SAMBA facilitam a transformação não linear e aprimoram a recuperação do conhecimento. Essas camadas introduzem a não linearidade no modelo, permitindo que ele capture padrões e interações mais complexos nos dados.
Além disso, as camadas SwiGLU garantem que o modelo possa processar e recuperar informações, contribuindo para sua robustez e versatilidade. Essa transformação não linear é essencial para a capacidade do modelo de generalizar dos dados de treinamento para os aplicativos do mundo real.
Depois de explorar a arquitetura do SAMBA, vamos examinar seu desempenho e eficiência em comparação com outros modelos.
O SAMBA demonstra bom desempenho em uma variedade de benchmarks de compreensão e raciocínio de linguagem, superando tanto os modelos baseados em atenção pura quanto os modelos baseados em SSM. Em particular, o SAMBA foi avaliado em tarefas como MMLU, GSM8K e HumanEval, obtendo uma pontuação de 71,2 para MMLU, 69,6 para GSM8K e 54,9 para HumanEval.
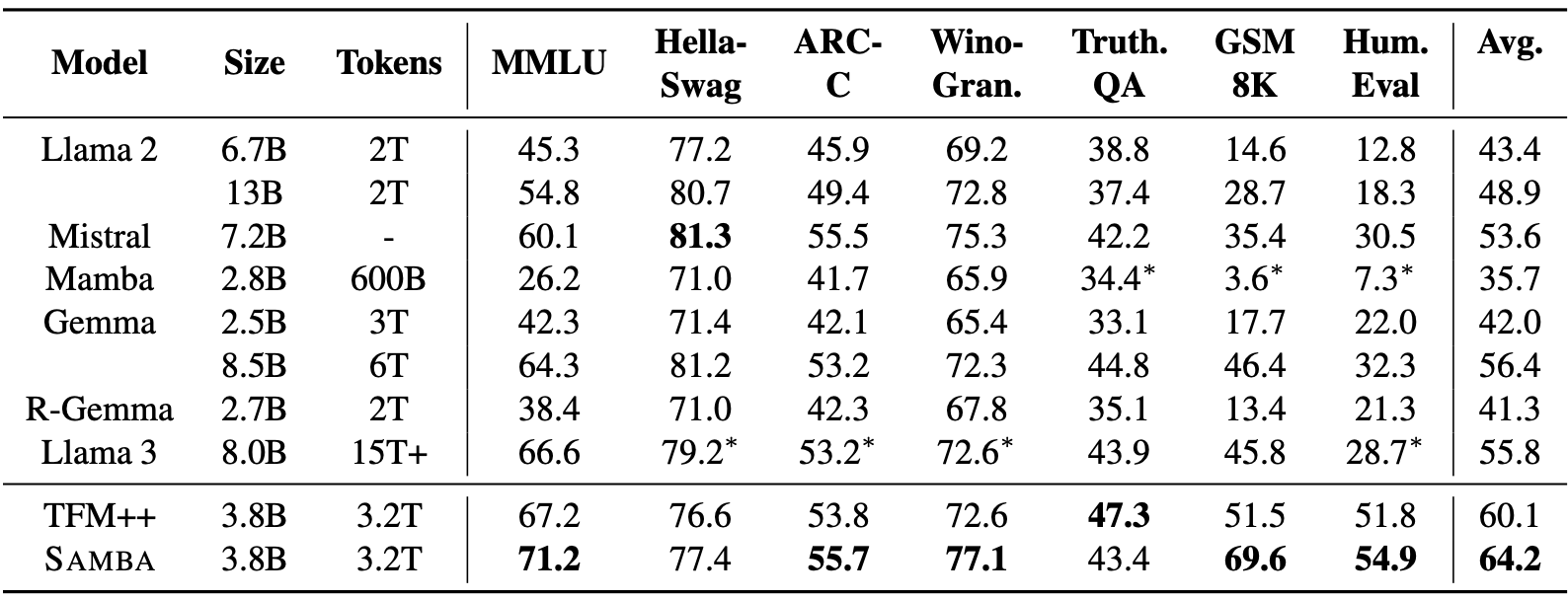
Fonte: Ren et. al (2024)
Esses resultados superam significativamente os de outros modelos de última geração, incluindo o TFM++ e o Llama-3, demonstrando a capacidade do SAMBA de lidar com diversas tarefas de compreensão de idiomas. Por exemplo, o SAMBA obteve uma precisão 18,1% maior no GSM8K em comparação com o TFM++, destacando a proficiência de sua arquitetura híbrida que combina SSM com mecanismos de atenção.
Um dos recursos mais notáveis do SAMBA é sua capacidade de lidar com comprimentos de contexto significativamente maiores, mantendo a eficiência. Apesar de ser pré-treinado em sequências de 4K de comprimento, o SAMBA pode extrapolar até 1 milhão de tokens com maior perplexidade e ainda manter a complexidade do tempo de decodificação linear.
Isso é obtido por meio da combinação em camadas dos espaços de estado seletivos do Mamba com o SWA, permitindo que o modelo mantenha o alto desempenho sem complexidade de computação quadrática.
Em termos práticos, o SAMBA atinge uma taxa de transferência de decodificação 3,64 vezes mais rápida em comparação com a arquitetura Llama-3, especialmente para sequências de até 128 mil tokens, demonstrando sua escalabilidade e capacidade de processar contextos longos.
A arquitetura híbrida do SAMBA amplia significativamente sua capacidade de recuperação de memória em comparação com os SSMs puros. Em testes como o Passkey Retrieval, o SAMBA demonstrou uma recuperação de memória quase perfeita até 256K de comprimento de contexto após o ajuste fino com apenas 500 etapas, enquanto os modelos baseados em SWA tiveram dificuldades além de 4K de comprimento.
Esse desempenho excepcional é atribuído aos pontos fortes combinados das estruturas recorrentes do Mamba para a semântica dependente do tempo e os recursos de recuperação de memória do SWA. Consequentemente, o SAMBA se destaca em tarefas de recuperação de memória de curto e longo prazo, o que o torna uma solução robusta para aplicativos que exigem ampla compreensão do contexto.
Vamos dar uma olhada mais de perto nas escolhas e estratégias específicas de design que contribuem para o desempenho impressionante do SAMBA.
O SAMBA emprega uma sofisticada estratégia de hibridização que combina as camadas Mamba, SWA e MLP (Multi-Layer Perceptron). Essa abordagem otimiza o desempenho da modelagem de linguagem de contexto longo, aproveitando as propriedades exclusivas de cada componente:
O documento SAMBA explora vários modelos lineares recorrentes e mecanismos de atenção para identificar a combinação mais ideal. Alternativas como Multi-Scale Retention e GLA foram consideradas possíveis substitutos para o Mamba. Você pode encontrar mais informações sobre a arquitetura do Mamba neste introdução ao guia de arquitetura do Mamba LLM.
Essas explorações visavam equilibrar a eficiência computacional e o desempenho em tarefas de modelagem de linguagem. A comparação revelou que, embora essas alternativas oferecessem alguns benefícios, a combinação do Mamba com camadas SWA e MLP obteve o melhor desempenho geral e escalabilidade.
A análise da entropia das distribuições de atenção levou a percepções valiosas sobre o desempenho do SAMBA e de modelos comparáveis, como o Mistral. A análise da entropia da atenção revelou que o SAMBA mantém uma recuperação de memória mais estável e confiável em contextos ampliados.
Por exemplo, na tarefa Passkey Retrieval, o SAMBA demonstrou uma recuperação quase perfeita de até 256 mil comprimentos de contexto, superando significativamente o Mistral. A análise do mapa de calor indicou que a arquitetura híbrida do SAMBA permite que ele mantenha uma alta precisão de recuperação em várias posições de chave de acesso, destacando seus excepcionais recursos de recuperação de longo alcance.
Devido à sua capacidade de processar sequências longas com eficiência, o SAMBA abre uma ampla gama de possíveis aplicativos.
A capacidade do SAMBA de lidar com o comprimento ilimitado do contexto abre possibilidades significativas para várias tarefas de contexto longo. Ele é capaz de manter a coerência e a relevância em sequências extensas, o que o torna particularmente adequado para aplicativos como:
A arquitetura do SAMBA foi projetada com a eficiência em mente, abordando as limitações típicas dos modelos baseados em atenção pura e em SSM. Alguns dos principais benefícios incluem:
Olhando para o futuro, há vários caminhos interessantes para trabalhos futuros que podem desenvolver ainda mais os recursos do SAMBA:
O SAMBA representa um avanço significativo na modelagem de idiomas, oferecendo uma nova arquitetura híbrida que combina SSMs com SWA deslizante e camadas MLP. As principais inovações e vantagens da arquitetura SAMBA incluem a hibridização dos mecanismos de atenção e SSM, a eficiência no tratamento de contextos longos e a recuperação aprimorada da memória.
Embora isso encerre nossa exploração da arquitetura SAMBA, uma ótima maneira de obter uma compreensão mais profunda da arquitetura SAMBA e de suas inovações é fazer experiências com a implementação disponível no GitHub.
Se você quiser saber mais sobre as últimas inovações em IA, recomendo estas publicações no blog:
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Nisha Arya Ahmed
12 min
blog
Abid Ali Awan
8 min
blog
Joleen Bothma
7 min
Tutorial
Zoumana Keita
Tutorial
Moez Ali

