Curso
Implementação de Soluções de IA nos Negócios
2 h
51.8K
O custo computacional do treinamento de grandes modelos de linguagem (LLMs) está ficando cada vez mais fora de controle. Por exemplo, o treinamento do GPT-4 custou à OpenAI aproximadamente 100 milhões de dólares. O custo vem principalmente das operações de multiplicação de matrizes (MatMul), e é natural que pesquisadores e desenvolvedores tenham tentado eliminá-lo completamente ou torná-lo mais eficiente.
O artigo "Scalable MatMul-free Language Modeling" apresenta uma abordagem inovadora que aborda esse problema de frente. Ao eliminar completamente o MatMul dos LLMs, os autores desenvolveram um modelo que mantém o desempenho competitivo e reduz significativamente os requisitos computacionais e de memória.
Fonte: Rui-Jie Zhu et. al
Todos os modelos do artigo estão disponíveis no HuggingFace - vocêpode testá-los on-line ou localmente usando as bibliotecas do HuggingFace. Além disso, os pesquisadores forneceram seu código no GitHub, permitindo que outros treinem seus modelos.
Se você quiser entender melhor a complexidade de tempo cúbico da multiplicação de matrizes, recomendo esta introdução à notação Big-O e à complexidade de tempo, que tem uma seção especial sobre a complexidade de tempo dos LLMs do MatMul.
Também fiz uma comparação entre o MatMul-free e o MatMul LLMs - você pode encontrá-la neste artigo: LLMs Matmul-Free vs MatMul: Velocidade e consumo de memória.
Os LLMs modernos baseados em transformadores dependem muito de operações de multiplicação de matrizes, que são fundamentais para seus componentes principais, como mecanismos de atenção e camadas de alimentação. Os custos computacionais e de memória associados às operações do MatMul são consideráveis, afetando as fases de treinamento e inferência. À medida que o tamanho dos LLMs aumenta, o número de parâmetros e a complexidade dos cálculos crescem, tornando o MatMul um grande gargalo.
Um exemplo comum desse problema é quando a VRAM de uma GPU é insuficiente para lidar com o tamanho do modelo, forçando os usuários a treinar ou executar a inferência em CPUs. As CPUs não são otimizadas para operações MatMul paralelizadas como as GPUs, o que leva a cálculos significativamente mais lentos. Isso cria um loop frustrante em que o hardware disponível não pode ser totalmente utilizado devido a restrições de memória, mesmo que a capacidade de computação seja adequada.
Ao longo dos anos, os pesquisadores exploraram várias estratégias para reduzir a carga computacional do MatMul. A quantização, que envolve a redução da precisão dos pesos e ativações, tem sido uma abordagem popular. Ao representar números com menos bits, a quantização pode reduzir o custo computacional e o espaço de memória das operações do MatMul.
No entanto, esse método geralmente sacrifica a precisão do modelo e não elimina completamente o MatMul. Esforços notáveis, como o BitNet da Microsoft, mostraram que é possível dimensionar LLMs com quantização binária ou ternária, mas esses modelos ainda dependem de operações MatMul para determinadas partes, como o mecanismo de autoatenção.
Arquiteturas alternativas também foram propostas para resolver as ineficiências do MatMul. Abordagens como a AdderNet substituem as multiplicações por adições em determinados componentes da rede, e as redes neurais binárias/ternárias utilizam operações aritméticas simplificadas
Embora esses métodos ofereçam alguns aprimoramentos, eles normalmente não conseguem remover totalmente o MatMul e visam apenas partes específicas do modelo. Como resultado, o custo computacional geral permanece alto, limitando a escalabilidade e a eficiência dos LLMs.
Para entender como funcionam as LMs sem MatMul, vamos examinar a arquitetura subjacente e os principais componentes.
Nas redes neurais tradicionais, as camadas densas (que conectam todos os neurônios entre duas camadas consecutivas) dependem do MatMul para transformar os dados de entrada. Os autores as substituem por camadas BitLinear, que usam pesos ternários. Em vez de ter pesos que podem ser qualquer número real, eles são limitados a apenas três valores: -1, 0 ou 1.
Os pesos são inicialmente treinados como valores de precisão total e, em seguida, durante o treinamento, são quantizados para valores ternários usando um processo chamado de "quantização por média absoluta". Esse processo dimensiona a matriz de peso por seu valor absoluto médio e, em seguida, arredonda cada elemento para o inteiro ternário mais próximo (-1, 0 ou 1).
Essa simplificação permite que eles substituam as multiplicações no MatMul por adições e subtrações. Por exemplo, multiplicar um número por -1 é o mesmo que negá-lo, multiplicar por 0 resulta em 0 e multiplicar por 1 deixa o número inalterado.
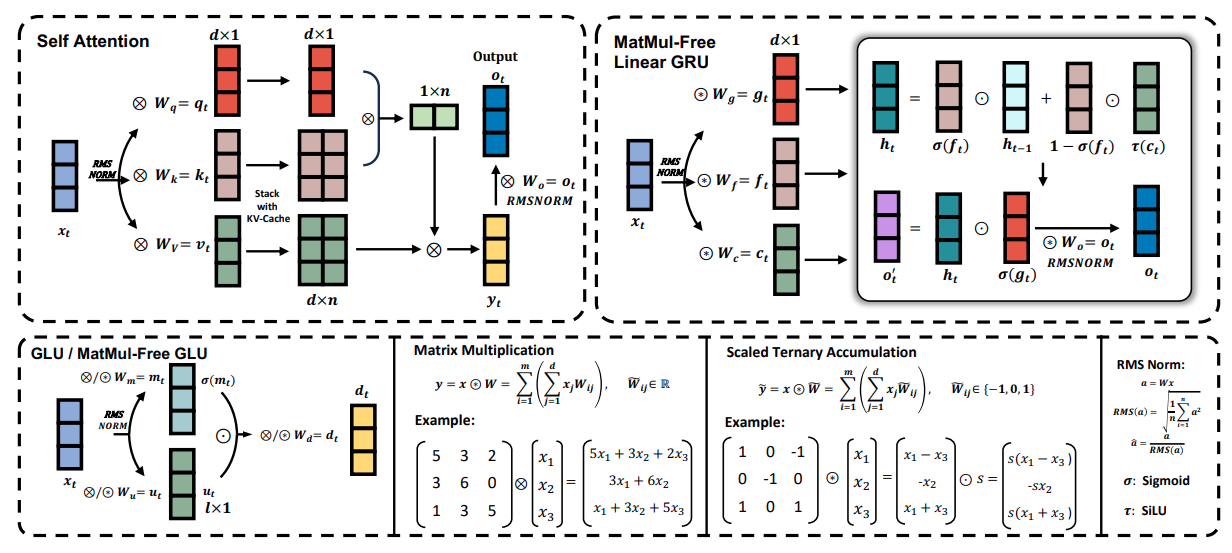
A figura abaixo apresenta uma visão geral dos principais componentes do modelo de linguagem MatMul-Free, incluindo a unidade de recorrência linear com passagem livre de MatMul (MLGRU) e a unidade linear com passagem livre de MatMul (GLU):
Fonte: Rui-Jie Zhu et. al
A figura é dividida em várias seções (do canto superior esquerdo ao canto inferior direito):
O MLGRU opera processando a sequência de entrada um token por vez. Em cada etapa, ele usa a incorporação do token atual e o estado oculto anterior como entrada. O estado oculto funciona como uma memória, armazenando informações de tokens anteriores. Em seguida, o MLGRU atualiza esse estado oculto usando uma série de operações com elementos e mecanismos de bloqueio. Essas portas, essencialmente vetores de números entre 0 e 1, controlam o fluxo de informações, determinando quais partes do estado oculto anterior e a incorporação do token atual são mais relevantes para a próxima etapa. Esse processo continua até que toda a sequência tenha sido processada.
A unidade linear fechada (GLU) sem MatMul é outro componente importante do modelo de linguagem sem MatMul. Ele mescla informações entre as diferentes dimensões da representação interna de palavras do modelo (embeddings). Em termos mais simples, ele ajuda o modelo a entender os diferentes aspectos ou recursos de cada palavra.
A GLU consegue isso usando um mecanismo de bloqueio para controlar o fluxo de informações entre diferentes canais de incorporação. Esse mecanismo de bloqueio é semelhante aos bloqueios do MLGRU, mas opera na dimensão do canal em vez de na dimensão do token.
O GLU sem MatMul é uma versão modificada do GLU padrão, adaptada para eliminar as multiplicações de matrizes usando camadas BitLinear, que são camadas densas que empregam pesos ternários (pesos que só podem assumir os valores -1, 0 ou 1). No GLU sem MatMul, a entrada é transformada primeiro usando duas camadas BitLinear separadas. A saída de uma camada é passada pela função de ativação SiLU e, em seguida, multiplicada por elementos com a saída da outra camada. Em seguida, essa saída com gated é passada por outra camada BitLinear para produzir a saída final.
Esta é apenas uma explicação de alto nível dos componentes MLGRU e GLU. Recomendo que você consulte o artigo de pesquisa original para obter uma compreensão mais detalhada do funcionamento interno e das formulações matemáticas.
A pesquisa investiga as leis de dimensionamento dos modelos sem MatMul, comparando seu desempenho com as arquiteturas tradicionais do Transformer à medida que o tamanho do modelo aumenta.
Surpreendentemente, os resultados revelam que a diferença de desempenho entre essas duas abordagens diminui à medida que o tamanho do modelo aumenta. Essa é uma observação importante, pois sugere que os modelos sem MatMul tornam-se cada vez mais competitivos com os Transformers tradicionais à medida que aumentam de escala, podendo superá-los em escalas muito grandes.
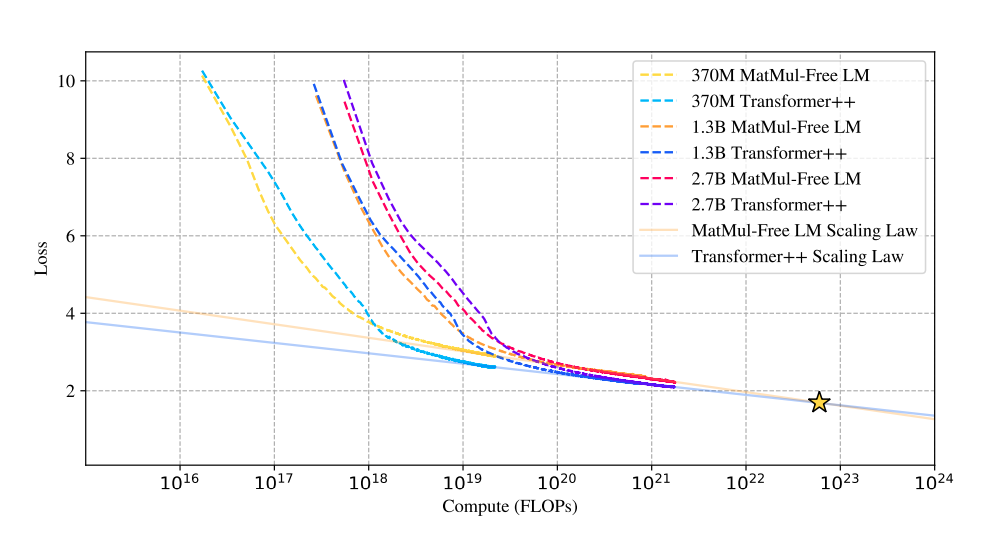
Fonte: Rui-Jie Zhu et. al
Esse gráfico sobre a comparação da lei de escalonamento mostra que as curvas de perda dos LMs sem MatMul e dos transformadores tradicionais convergem à medida que o número de operações de ponto flutuante (FLOPs) aumenta.
Inicialmente, os LMs sem MatMul apresentam maior perda devido às restrições dos pesos ternários. No entanto, essa diferença diminui à medida que o tamanho do modelo aumenta e, em um determinado ponto (estrela), as curvas de perda se cruzam, indicando um desempenho comparável. Isso sugere uma lei de escala mais acentuada para os modelos sem MatMul, o que significa que seu desempenho melhora mais rapidamente com o aumento do tamanho em comparação com os Transformers tradicionais.
O desempenho competitivo dos LMs sem MatMul é ainda mais reforçado por seu forte desempenho em vários benchmarks de aprendizado de zero-shot. Em tarefas como ARC-Easy, ARC-Challenge, Hellaswag, Winogrande, PIQA e OpenbookQA, esses modelos geralmente têm desempenho igual ou superior ao dos Transformers tradicionais, apesar de sua complexidade computacional significativamente reduzida. Essa é uma prova da eficácia das operações alternativas e das escolhas arquitetônicas empregadas nos LMs sem MatMul.
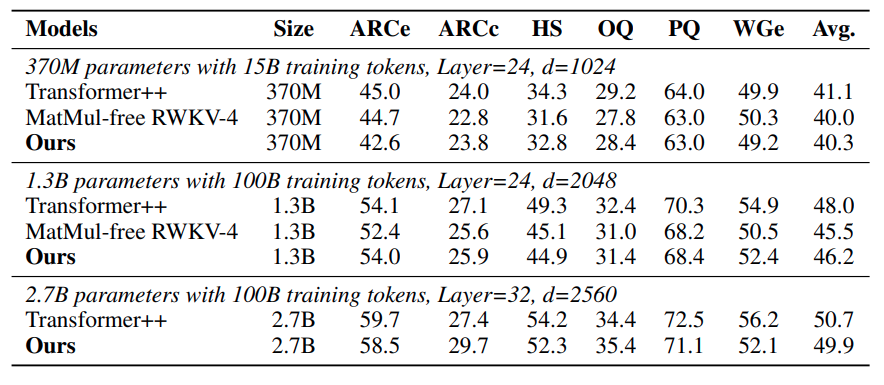
Fonte: Rui-Jie Zhu et. al
A tabela sobre a precisão do zero-shot mostra que os LMs sem MatMul têm um desempenho competitivo em várias tarefas. Por exemplo, no ARC-Challenge, um benchmark particularmente difícil, o LM sem MatMul de 2,7B parâmetros atinge uma precisão maior do que a de um modelo de transformador tradicional.
Da mesma forma, nas tarefas Winogrande e OpenbookQA, os LMs sem MatMul apresentam desempenho robusto, indicando que a eliminação do MatMul não compromete a capacidade do modelo de entender e gerar linguagem.
Uma das vantagens mais marcantes das LMs sem MatMul é sua excepcional eficiência de memória. Ao substituir as operações pesadas de multiplicação por adições e subtrações mais simples possibilitadas por pesos ternários, esses modelos conseguem reduções substanciais no uso da memória.
Durante o treinamento, uma implementação de GPU otimizada pode reduzir o consumo de memória em até 61% em comparação com modelos não otimizados. Na inferência, a economia de memória é ainda maior, com reduções de mais de dez vezes. Isso torna os LMs sem MatMul particularmente atraentes para a implantação em dispositivos com recursos limitados, como smartphones, em que a memória é frequentemente um fator limitante.
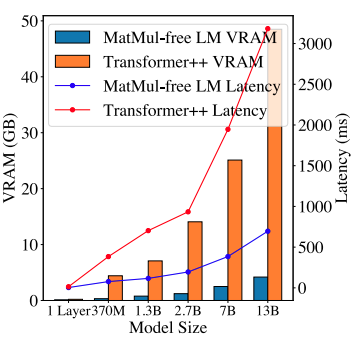
Fonte: Rui-Jie Zhu et. al
Este gráfico sobre a memória da GPU e a comparação de latência ilustra os ganhos de eficiência dos LMs sem MatMul. O consumo de memória de inferência de um LM sem MatMul de 2,7 bilhões de parâmetros é significativamente menor do que o de um transformador tradicional comparável. Esse espaço de memória reduzido não só permite a implementação de modelos maiores em hardware limitado, mas também se traduz em menor latência, tornando esses modelos mais adequados para aplicativos em tempo real em que a capacidade de resposta é crucial.
Um dos principais avanços apresentados no documento é a implementação otimizada da GPU de LMs sem MatMul. Os autores obtiveram um aumento de 25,6% na velocidade de treinamento e uma redução de até 61,0% no uso da memória usando kernels fundidos em sua própria implementação de GPU. Esses kernels combinam várias operações em um único processo mais eficiente, reduzindo a sobrecarga associada ao acesso à memória e à movimentação de dados.
Para explorar ainda mais as operações leves das LMs sem MatMul, os autores desenvolveram um acelerador FPGA personalizado em SystemVerilog. Os FPGAs (Field-Programmable Gate Arrays) oferecem uma plataforma de hardware flexível e eficiente para a implementação de tarefas computacionais especializadas.
O acelerador personalizado foi projetado para aproveitar a simplicidade das operações ternárias e dos produtos por elemento, obtendo ganhos substanciais de eficiência. A implementação do RTL (Nível de transferência de registro) é fundamental no processo de design do FPGA. Isso envolve a especificação do comportamento do hardware em um nível alto, que é então sintetizado na configuração real do FPGA. O projeto RTL personalizado para os LMs sem MatMul garante que o FPGA possa lidar eficientemente com as operações leves, reduzindo o consumo de energia e aumentando a produtividade.
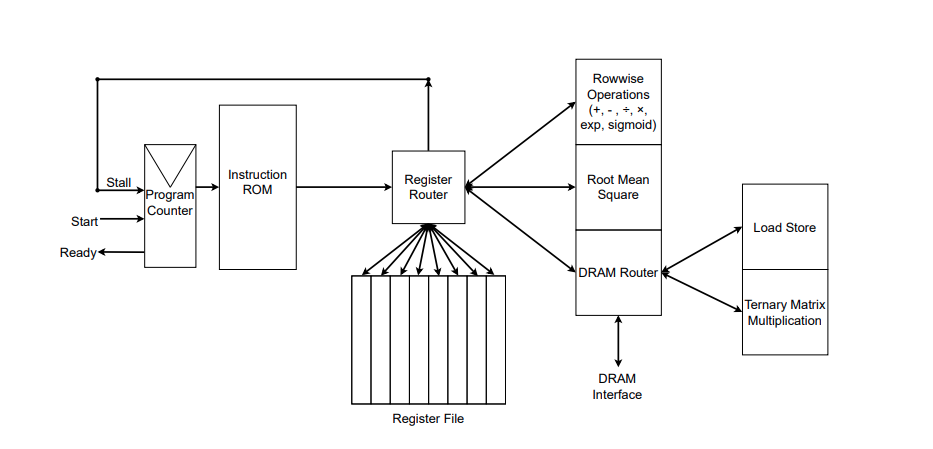
Fonte: Rui-Jie Zhu et. al
A figura ilustra a implementação RTL do acelerador FPGA personalizado. Você pode ver as funções que ele implementa à direita do roteador de registro. Os autores também desenvolveram seu próprio montador para converter arquivos de montagem com instruções personalizadas em uma ROM de instruções, que você pode ver à direita da figura. As instruções são fornecidas ao roteador de registros, que gerencia a memória (arquivo de registros) e executa as instruções.
Além disso, os autores mencionaram em um comentário na edição do GitHub que as especificações completas de sua implementação de FPGA ainda estão sendo otimizadas, e o código SystemVerilog será tornado público posteriormente.
A tabela abaixo mostra a utilização de recursos e as métricas de desempenho para a implementação do FPGA da geração de tokens sem MatMul.
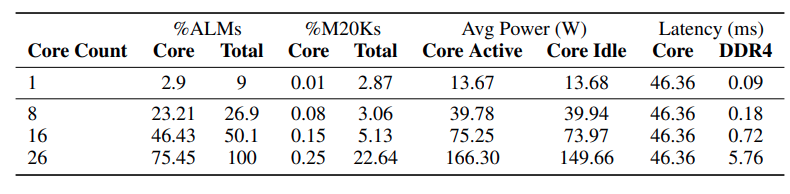
Fonte: Rui-Jie Zhu et. al
Os dados demonstram que, à medida que o número de núcleos (unidades de processamento) no FPGA aumenta, a latência geral permanece relativamente estável. No entanto, a latência aumenta significativamente de 16 para 26 núcleos, o que sugere que a interface DDR4, responsável pela transferência de dados, está se tornando um gargalo à medida que a demanda por transferência de dados aumenta com o número de núcleos.
Embora a operação de multiplicação da matriz ternária domine atualmente a latência geral, os autores preveem que a otimização dessa unidade em implementações futuras deslocará o gargalo para a interface DDR4.
Uma das afirmações mais intrigantes do artigo é que sua abordagem sem MatMul aproxima os LLMs da eficiência semelhante à do cérebro em termos de computação e consumo de energia. Os autores argumentam que seus modelos imitam a eficiência das redes neurais biológicas e atingem uma velocidade de leitura semelhante à humana.
No entanto, comparar diretamente a eficiência desses modelos com o intrincado funcionamento das redes neurais biológicas é uma questão complexa que requer mais investigação. Os mecanismos de computação do cérebro são muito diferentes e muito mais complexos do que as operações simplificadas usadas em LMs sem MatMul.
O artigo "Scalable MatMul-free Language Modeling" desafia uma suposição fundamental no processamento de linguagem natural: que a multiplicação de matrizes (MatMul) é essencial para a criação de LLMs de alto desempenho.
Ao demonstrar a viabilidade de arquiteturas sem MatMul, esta pesquisa abre uma nova fronteira no projeto de LLM, incentivando a exploração de operações alternativas e paradigmas computacionais. Isso pode levar a uma onda de inovação, com pesquisadores desenvolvendo novas arquiteturas de modelos.
Essa mudança para modelos sem MatMul não se refere apenas ao software, mas também ao hardware. Os chips tradicionais, como as GPUs, são excelentes para a multiplicação de matrizes, mas não são necessariamente os mais adequados para esses modelos novos e leves.
O acelerador FPGA personalizado criado pelos pesquisadores é um vislumbre do futuro do hardware de IA - chips especializados projetados para extrair cada grama de desempenho desses modelos eficientes. Isso pode levar a uma geração totalmente nova de dispositivos alimentados por IA que são mais rápidos, mais eficientes em termos de energia e acessíveis a um público mais amplo.
Como alguém que se preocupa com o meio ambiente, estou particularmente animado com o potencial dos modelos sem MatMul para reduzir a pegada de carbono da IA. O enorme consumo de energia dos grandes modelos de linguagem atuais é uma preocupação real. Ao reduzir significativamente as demandas computacionais, essa pesquisa pode abrir caminho para tecnologias de IA mais eficientes em termos de energia e com menor impacto ambiental.
Embora o artigo "Scalable MatMul-free Language Modeling" represente um avanço significativo, ele também abre vários caminhos para pesquisas futuras - explorar diferentes arquiteturas sem MatMul, avaliar seu desempenho em uma gama mais ampla de tarefas e compreender matematicamente os limites teóricos dessa abordagem são apenas algumas das interessantes direções de pesquisa.
Além disso, o desenvolvimento de benchmarks padronizados e métricas de avaliação especificamente para modelos sem MatMul facilitaria comparações justas e aceleraria o progresso nesse campo. A jornada rumo a uma IA realmente eficiente e acessível está apenas começando, e as possibilidades são ilimitadas. Além disso, estou pessoalmente muito animado para experimentar os futuros chatbots assistentes sem MatMul!
O artigo "Scalable MatMul-free Language Modeling" (Modelagem de linguagem escalável sem MatMul) faz uma contribuição significativa para o campo dos LLMs, introduzindo uma nova abordagem que elimina as operações de multiplicação de matrizes (MatMul).
Esse avanço aborda os gargalos computacionais e de memória associados aos LLMs tradicionais, abrindo caminho para modelos mais eficientes e dimensionáveis. Ao aproveitar as operações aditivas e os pesos ternários, os autores demonstram que é possível manter o desempenho competitivo e, ao mesmo tempo, reduzir significativamente as demandas de recursos.
O impacto potencial desta pesquisa sobre o futuro do desenvolvimento e da implementação do LLM é profundo. Os modelos sem MatMul oferecem uma alternativa viável às arquiteturas convencionais, permitindo a criação de modelos leves e eficientes que são adequados para ambientes com recursos limitados, como dispositivos de borda e plataformas móveis.
Se você quiser saber mais sobre inteligência artificial, confira estes cursos de IA.
Aprenda IA com estes cursos!
Curso
Curso
Curso
blog
Nisha Arya Ahmed
12 min
blog
Stanislav Karzhev
9 min
blog
Bhavishya Pandit
8 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
